
現實世界中,大量存在著對數據壓縮的需求。為此,python內置了zlib壓縮庫,可以方便的對任意對象進行壓縮。 ...
使用zlib對數據進行壓縮
現實世界中,大量存在著對數據壓縮的需求。為此,python內置了zlib壓縮庫,可以方便的對任意對象進行壓縮。
下述代碼演示了對字元串進行壓縮:
import zlib # 壓縮一段中文 originstr = '神龜雖壽,猶有竟時;騰蛇乘霧,終為土灰。老驥伏櫪,志在千里;烈士暮年,壯心不已。盈縮之期,不但在天;養怡之福,可得永年。幸甚至哉,歌以詠志。' print(len(originstr)) str_compression = zlib.compress(originstr.encode('utf-8'), level=8) print(len(str_compression)) print(str_compression) decompress_str = zlib.decompress(str_compression) print(decompress_str) print(decompress_str.decode('utf-8')) # 壓縮一段英文 originstr = 'The World Health Organization officially declared on Saturday that the current multi-country monkeypox outbreak outside of the traditional endemic areas in Africa has already turned into a public health emergency of international concern (PHEIC).' print(len(originstr)) str_compression = zlib.compress(originstr.encode('utf-8'), level=8) print(len(str_compression)) print(str_compression) decompress_str = zlib.decompress(str_compression) print(decompress_str) print(decompress_str.decode('utf-8'))
運行上述代碼後,會發現壓縮並不一定會減少位元組數,壓縮的效率取決於壓縮內容中的冗餘程度。對於第一句的中文壓縮後反而增加了位元組數。但第二段英文則有明顯的壓縮比(246/180)。此外,在壓縮時不指定level則使用預設的壓縮級別(大約是6),是一個在速度與壓縮比間的平衡值。level的設定如下:
-
level=0,效果是不壓縮。
-
level=1,速度最快
-
level=9,速度最慢,壓縮比最高
-
level=-1,預設值
壓縮一個文件的操作類似,示例代碼如下:
import zlib def compress(inputfile,outputfile): with open(inputfile,'rb') as input: with open(outputfile,'wb') as output: data = input.read() compressdata = zlib.compress(data) output.write(compressdata) def decompress(inputfile,outputfile): with open(inputfile,'rb') as input: with open(outputfile,'wb') as output: data = input.read() compressdata = zlib.decompress(data) output.write(compressdata) compress(r'd:\dev\sensor.dat',r'd:\dev\sensor.zlib') decompress(r'd:\dev\sensor.zlib',r'd:\dev\sensor_d.dat')
使用vscode的hex editor可以打開三個文件如下圖所示:
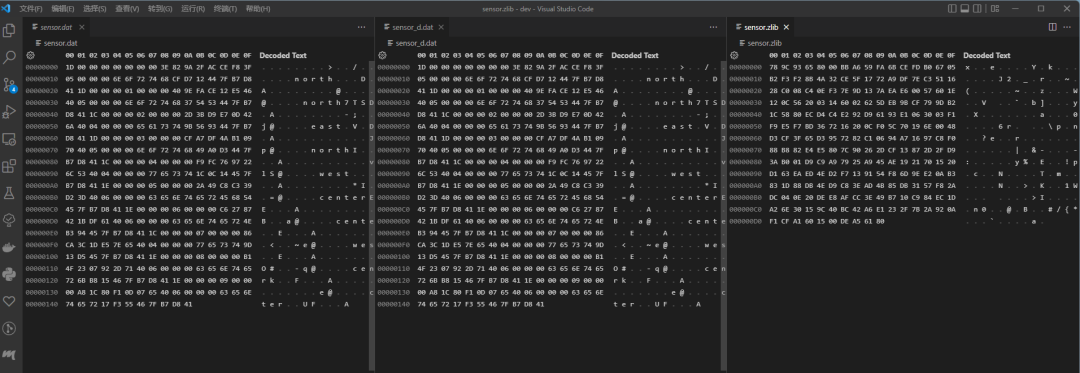
首先源文件與壓縮解壓後的文件完全一樣。其次,壓縮後的文件確實小多了。最後可以看出,從某種意義上來說,壓縮也相當於加密。


