
上節討論瞭如何保障數據中台的數據質量,讓數據“準”。除了“快”和“準”,數據中台還離不開“省”。隨數據規模越來越大,成本越來越高,如不合理控製成本,還沒等你挖掘出數據應用價值,企業利潤就被消耗完。 能否做到精細化成本管理,關乎數據中台項目成敗。 某電商業務數據建設資源增長趨勢(CU= 1vcpu + ...
上節討論瞭如何保障數據中台的數據質量,讓數據“準”。除了“快”和“準”,數據中台還離不開“省”。隨數據規模越來越大,成本越來越高,如不合理控製成本,還沒等你挖掘出數據應用價值,企業利潤就被消耗完。
能否做到精細化成本管理,關乎數據中台項目成敗。
某電商業務數據建設資源增長趨勢(CU= 1vcpu + 4G memory):
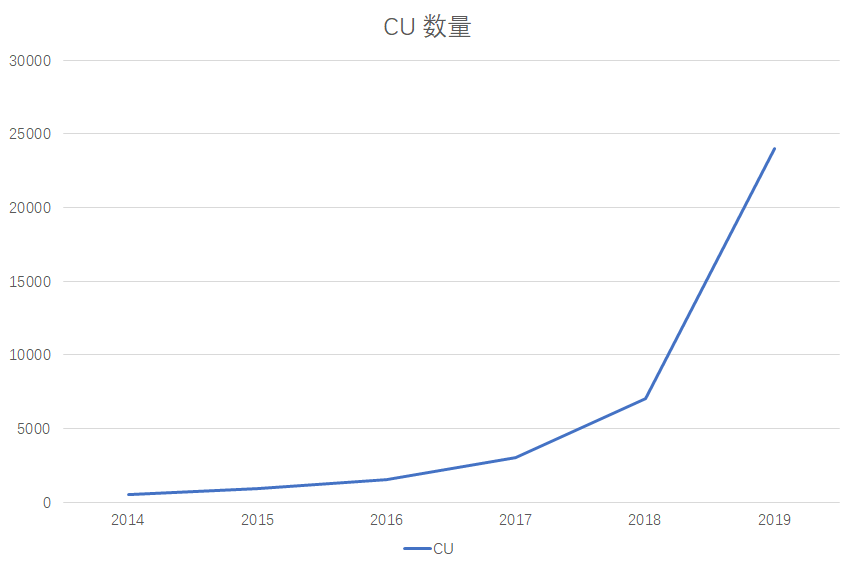
某電商平臺的大數據資源消耗增長趨勢,2019全年資源規模25000CU,全年機器預算3500W。對創業企業顯然不小開支。
一天,數據團隊負責人李好看被CEO叫到了辦公室:
- 這3500W花在什麼業務?
- 你們做了哪些成本優化的舉措,效果如何?
把李問懵,他心想:團隊的成本是按機器又不是數據應用核算。在數據中臺中,數據應用之間的底層數據是復用的,那具體每個數據產品或者報表花了多少錢,自己沒有這樣的數據啊,咋可能知道。
可對CEO這些很重要,因為資源有限,他須確保資源都用在戰略目標的關鍵節點。如電商團隊今年核心KPI是提升單個註冊會員在平臺的消費額,老闆角度,他須確保資源都投入與KPI相關業務,如基於數據對註冊會員精準化營銷,提升會員在平臺的消費額。
自己所在的團隊是否發生過類似的事情? 數據部門是企業的成本中心,如要展現自己的價值:
- 支撐好業務,獲得業務的認可
- 精簡成本,為公司省錢
所以,今天重點在省錢,聊數據中台的精細化成本管理。
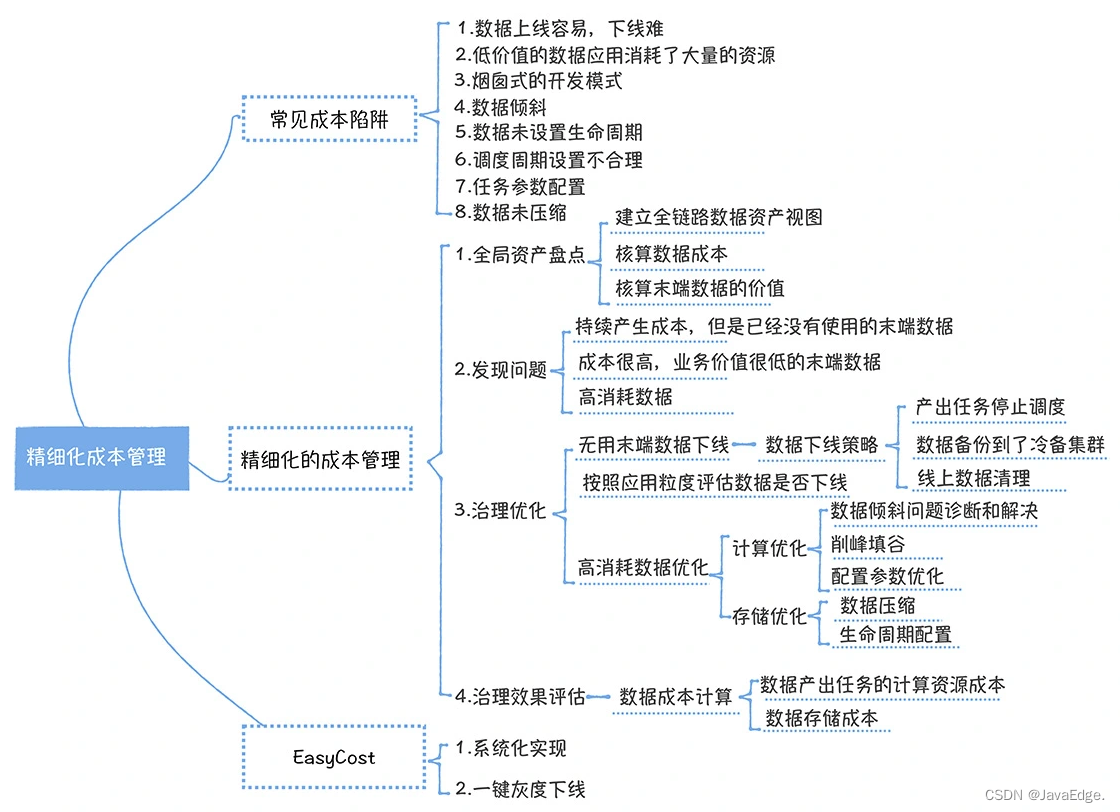
1 成本陷阱
一開始建設數據中台時,你往往會關註新業務的接入,數據的整合,數據價值的挖掘上,忽略成本管控的問題,從而落入陷阱中,造成成本爆炸式的增長。所以,有必要深入瞭解有哪些陷阱,儘量在日常開發中避免。
這裡總結8種陷阱:
- 1~3廣泛存在,但易被忽略
- 4~8涉及數據開發中一些技能,開發時註意就可
“知其然,更要知其所以然”,才能發現問題本質,深入掌握解決問題的方法。
1.1 數據上線容易,下線難
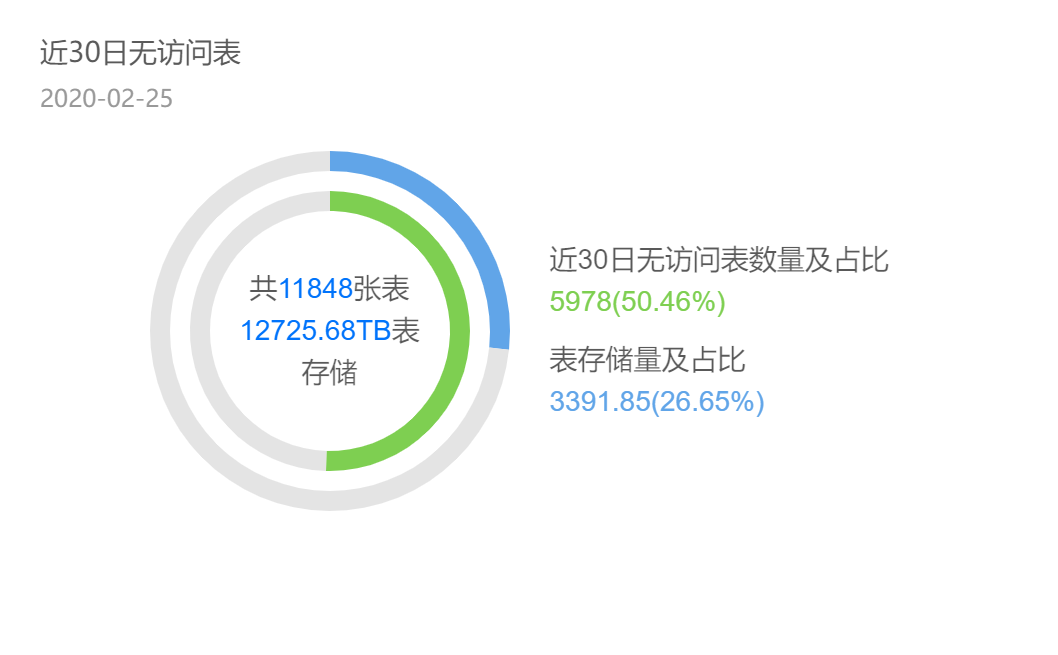
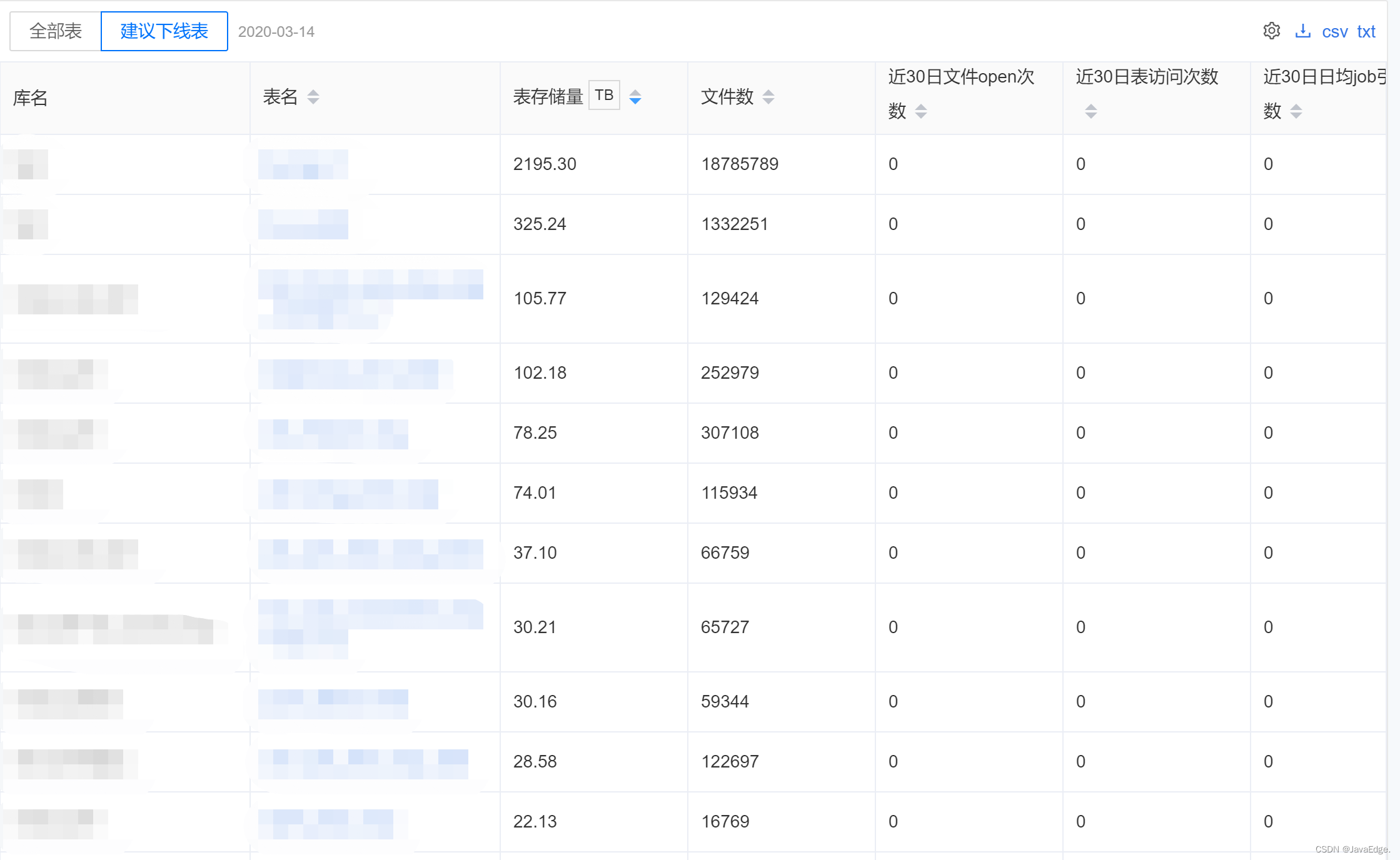
某數據中台項目,表相關的使用統計。一半的表30d內都沒有訪問,而這些表占26%存儲。如把這些表的產出任務單獨拎出,高峰期需消耗5000Core CPU計算資源,換算成伺服器需125台(按一臺伺服器可分配CPU 40Core計算),成本一年近500W。自己竟然有這麼多無用數據?我經常把數據比作手機中的圖片,我們不斷拍照生圖,卻懶得清,最終手機存儲經常不夠。
無法及時清數據,數據開發也有苦衷。他們不知道一個表:
- 還有哪些任務在引用
- 還有哪些人在查詢
自然不敢停止這個表的數據加工,導致數據上線易,下線難。
1.2 低價值的數據應用消耗了大量的資源
數據看上去每天都被訪問,但究竟產出多少價值,ROI值得嗎?
有個寬表(擁有很多列的表,經常出現在數據中臺下游的彙總層數據中),加上上游加工鏈路的任務,每天加工這張寬表要消耗6000塊錢,一年200W,可追查後我們發現,這張寬表實際每天只有一個人在使用,還是一個運營的實習生。顯然,投入和產出極不匹配。
間接說明,數據部門比較關註新的數據產品帶給業務的價值,卻忽略已存產品或報表是否還存在價值,最終導致低價值的應用仍大量耗資源。
1.3 煙囪式的開發模式
不僅研發效率低,因數據重覆加工,還資源浪費。一張500T表,加工這表,計算任務需高峰期消耗300Core,摺合7台伺服器(按一臺伺服器可分配CPU 40Core計算),加上存儲盤成本(按照0.7 元/TB*天計算),一年消耗40W。
而這張表每復用一次,就可節省40W。所以模型復用,還可實現省錢。
第四,數據傾斜。
數據傾斜會讓任務性能變差,也會浪費大量的資源,那什麼是數據傾斜呢?
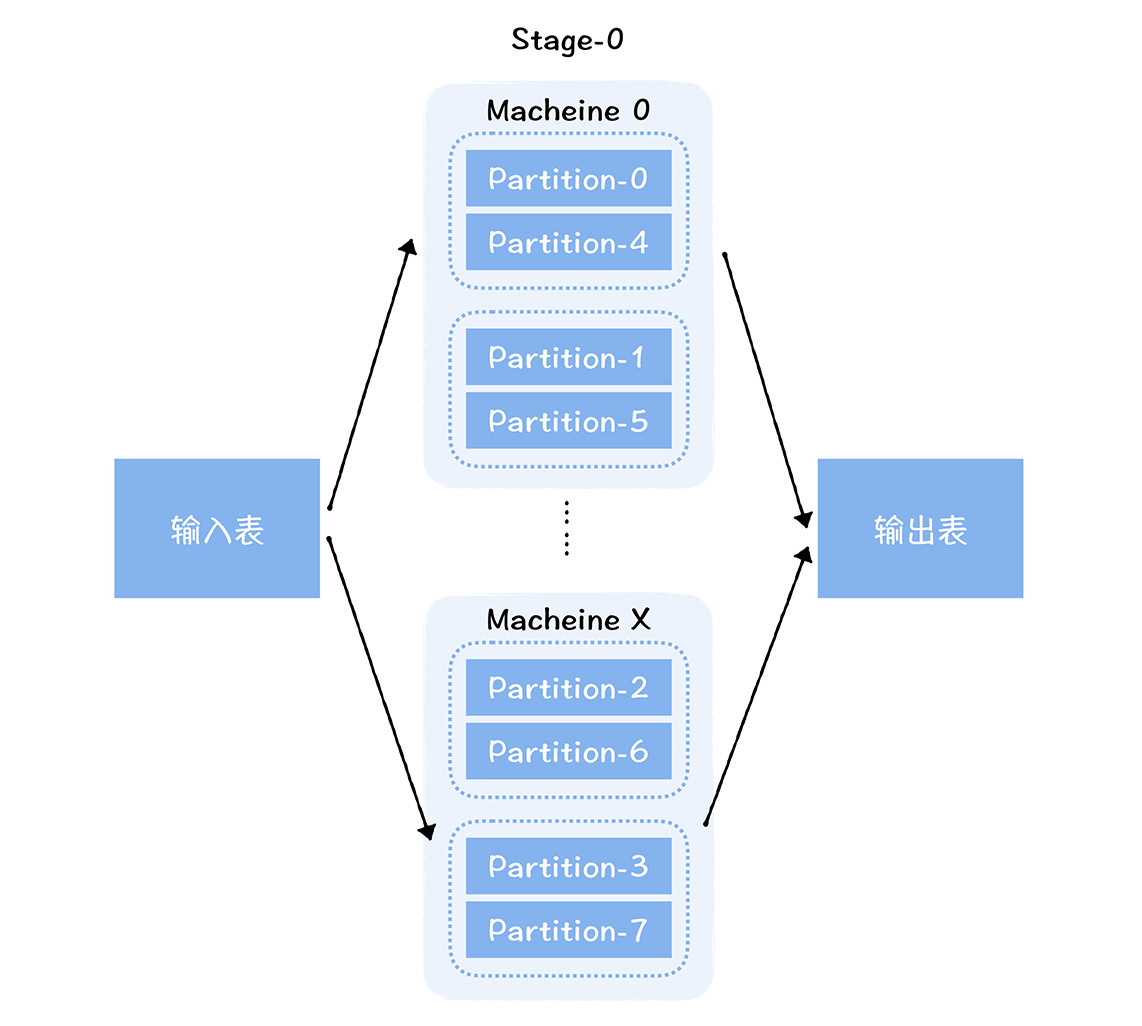
你肯定聽說過木桶效應吧?一個木桶裝多少水,主要取決於最短的那塊板。對於一個分散式並行計算框架來說,這個效應同樣存在。對於Spark計算引擎來說,它可以將海量的數據切分成不同的分片(Partition),分配到不同機器運行的任務中,進行並行計算,從而實現計算能力水平擴展。
但是整個任務的運行時長,其實取決於運行最長的那個任務。因為每個分片的數據量可能不同,每個任務需要的資源也不相同。由於不同的任務不能分配不同的資源,所以,總任務消耗資源=max{單個任務消耗的資源} * 任務數量。這樣一來,數據量小的任務會消耗更多的資源,就會造成資源的浪費。
我們還是舉個電商場景的例子。
假設你需要按照商戶粒度統計每個商戶的交易金額,此時,我們需要對訂單流水錶按照商戶進行group by計算。在平臺上,每個商戶的訂單交易量實際差距很大,有的訂單交易量很多,有的卻比較少。
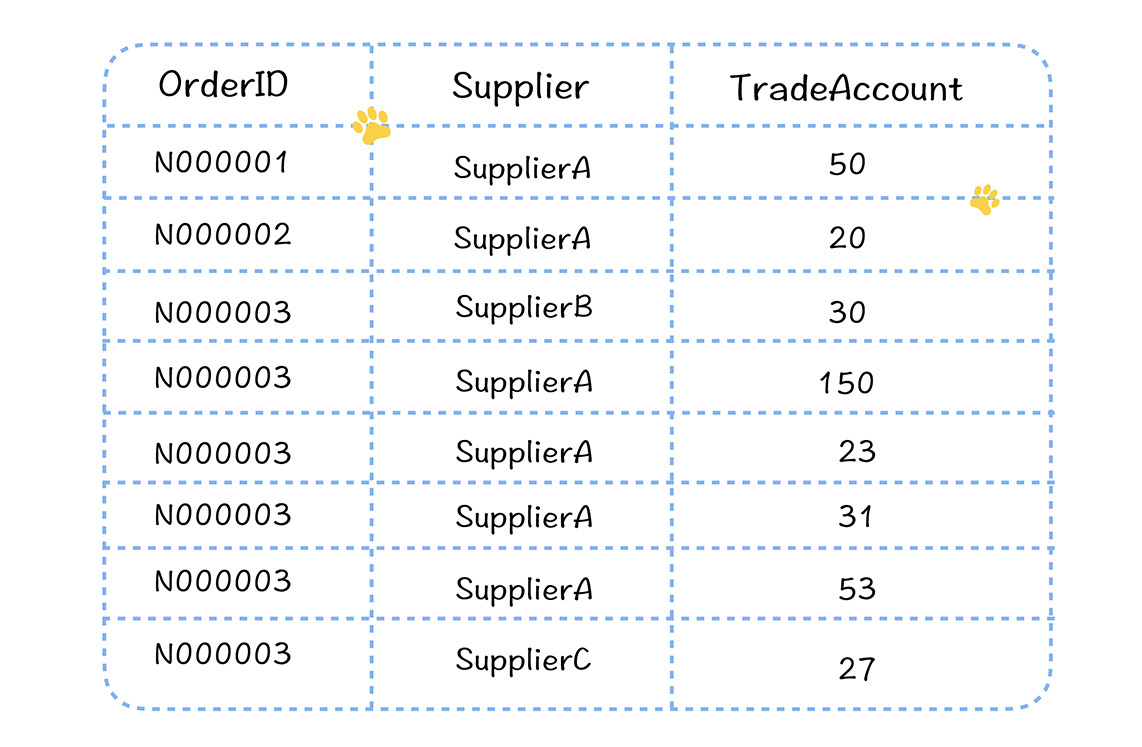
我們利用Spark SQL完成計算過程。
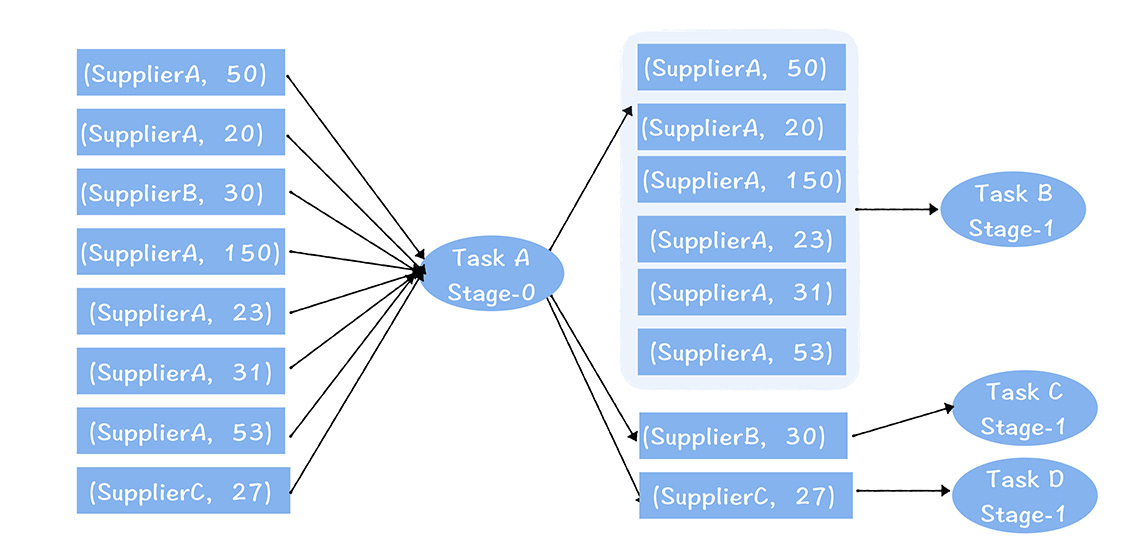
在上圖中,任務A 讀取了左邊某個分片的數據,按照供應商進行聚合,然後輸出給下一個Stage的B、C、D任務。
你可以看到,聚合後,B、C和D任務輸入的數據量有很大的不同,B處理的數據量比C和D多,消耗的記憶體自然更多,假設單個Executor需要分配16G,而B、C、D不能設置不同的記憶體大小,所以C和D也都設置了16G。可實際上,按照C和D的數據量,只需要4G就夠了。這就造成了C和D 任務資源分配的浪費。
第五,數據未設置生命周期。
在06講中,我強調,一般原始數據和明細數據,會保留完整的歷史數據。而在彙總層、集市層或者應用層,考慮到存儲成本,數據建議按照生命周期來管理,通常保留幾天的快照或者分區。如果存在大表沒有設置生命周期,就會浪費存儲資源。
第六,調度周期不合理。
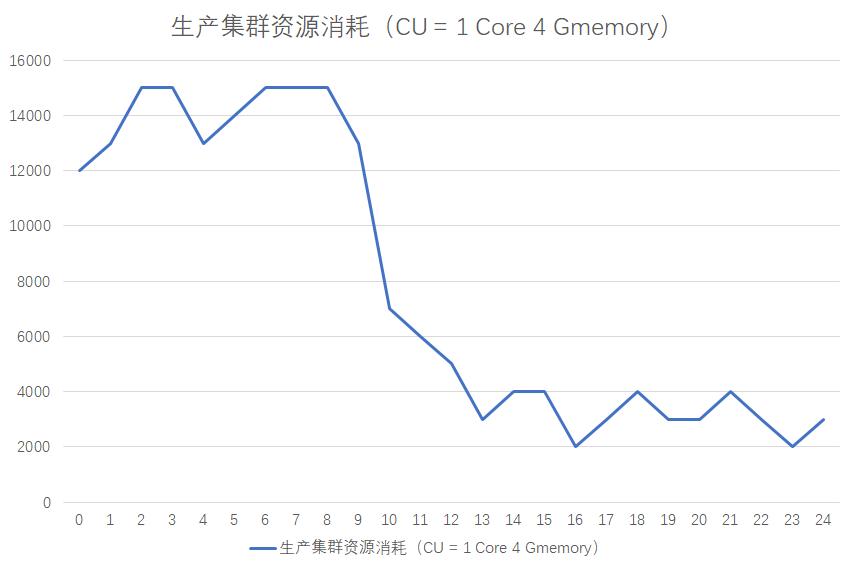
通過這張圖你可以看到,大數據任務的資源消耗有很明顯的高峰和低谷效應,一般晚上12點到第二天的9點是高峰期,9點到晚上12點,是低谷期。
雖然任務有明顯的高峰低谷效應,但是伺服器資源不是彈性的,所以就會出現伺服器在低谷期比較空閑,在高峰期比較繁忙的情況,整個集群的資源配置取決於高峰期的任務消耗。所以,把一些不必要在高峰期內運行任務遷移到低谷期運行,也可以節省資源的消耗。
第七,任務參數配置。
任務參數配置的不合理,往往也會浪費資源。比如在Spark中,Executor 記憶體設置的過大;CPU設置的過多;還有Spark 沒有開啟動態資源分配策略,一些已經運行完Task的Executor 不能釋放,持續占用資源,尤其是遇到數據傾斜的情況,資源浪費會更加明顯。
第八,數據未壓縮。
Hadoop 的HDFS 為了實現高可用,預設數據存儲3副本,所以大數據的物理存儲量消耗是比較大的。尤其是對於一些原始數據層和明細數據層的大表,動輒500多T,摺合物理存儲需要1.5P(三副本,所以實際物理存儲5003),大約需要16台物理伺服器(一臺伺服器可分配存儲按照128T計算),如果不啟用壓縮,存儲資源成本會很高。
另外,在Hive或者Spark 計算過程中,中間結果也需要壓縮,可以降低網路傳輸量,提高Shuffer (在Hive或者Spark 計算過程中,數據在不同節點之間的傳輸過程)性能。
你看,我為你列舉了8個典型的成本陷阱,那你可能會問了,老師,我已經中招了,該怎麼辦呢? 別急,接下來我們就看一看,如何進行精細化的成本管理。
2 如何實現精細化成本管理?
成本治理應遵循全局盤點、發現問題、治理優化和效果評估四步。
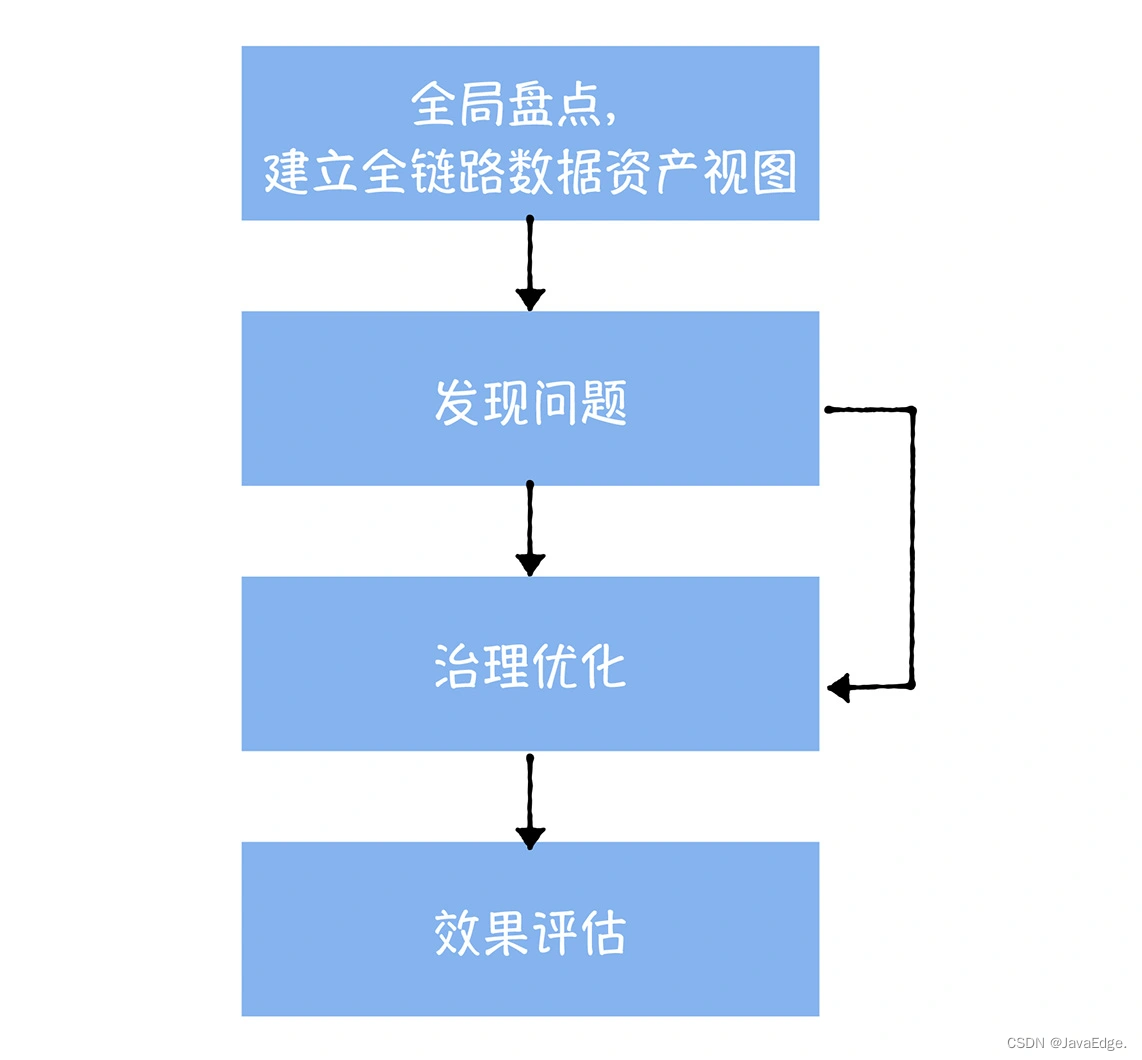
2.1 全局資產盤點
對數據中臺中,所有的數據進行一次全面盤點,基於元數據中心提供的數據血緣,建立全鏈路的數據資產視圖。
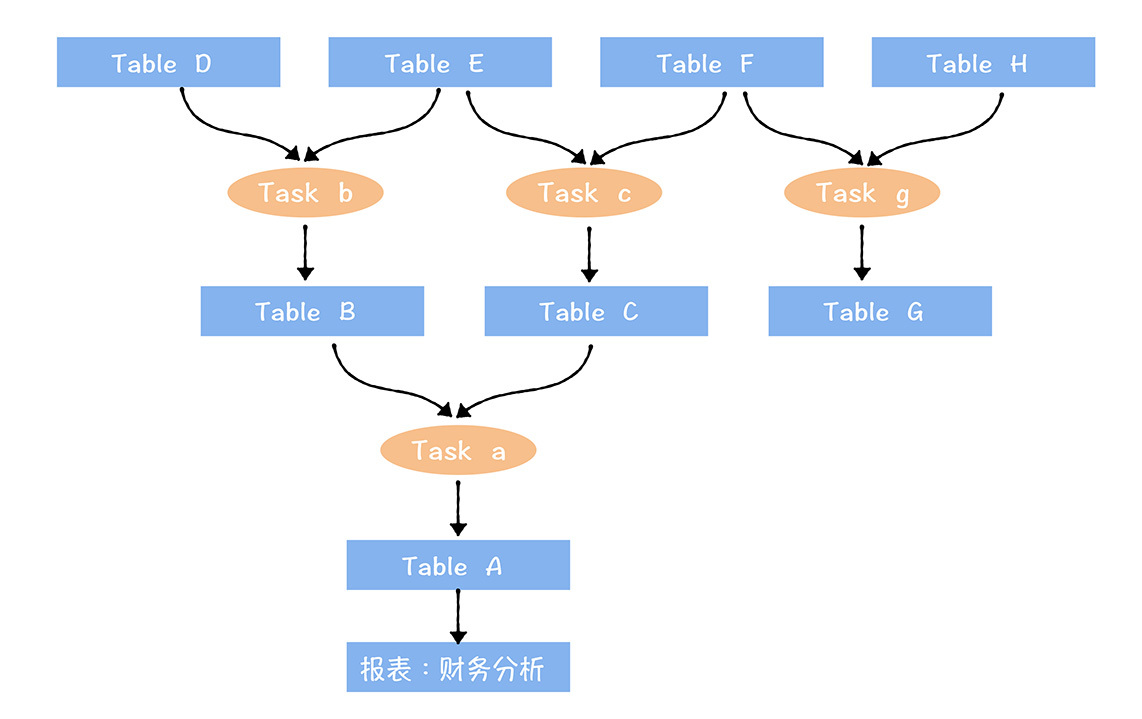
全鏈路數據資產視圖:
- 下游末端關聯到數據應用(報表:財務分析)
- 上游起點是剛進入數據中台的原始數據
- 數據之間通過任務進行連接
計算全鏈路數據資產視圖中,末端數據的成本和價值(末端數據就是加工鏈路最下游的表,例如圖中TableA,Table G)。
為什麼一定要從末端開始? 因為中間數據在計算價值時,還要考慮下游表被使用的情況,較難計算清楚,所以從末端數據開始。這與下線表的順序也一致,如數據的價值很低,成本很高,也從末端數據開始下線。
數據成本該如何計算?
對上圖中財務分析報表核算成本,這報表上游鏈路中涉及a,b,c,3個任務,A,B,C,D,E,F, 6張表:
這張報表的成本=3個任務加工消耗的計算資源成本+6張表消耗的存儲資源的成本。
如一個表被多個下游應用復用,那這個表的存儲資源成本以及產出任務消耗的成本,需分攤給多個應用。
那價值又該如何計算?
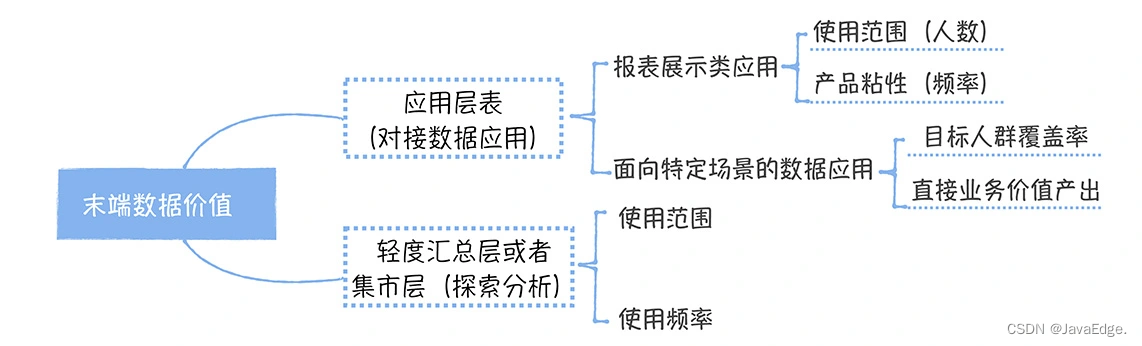
如末端數據是一張應用層的表,它對接的是一個數據報表,那衡量這數據價值主要看報表的使用範圍和使用頻率。
計算使用範圍時,通常用周活評估,同時還要考慮不同管理級別的人權重,對老闆,他一個人權重可相當1000個普通員工。所以這樣設計考慮到管理級別越高,做出商業決策影響越大,自然價值越大。使用頻率一般使用單個用戶每周查看報表的次數來衡量,次數越高,說明報表價值越大。
如末端數據對接的不是一個數據報表,而是面向特定場景的數據應用(比如我之前提到過的供應鏈分析決策系統,它面向的人群主要是供應鏈部門)。衡量這類產品的價值,主要考慮目標人群的覆蓋率和直接業務價值產出。什麼是直接業務價值產出呢?,在供應鏈決策系統中,就是通過系統自動生成的採購訂單占所有採購訂單的比例。
末端數據可能還是一張集市層的表,主要用於提供給分析師做探索式查詢。這類表的價值看它被哪些分析師使用,使用頻率。使用範圍評估時,也要對分析師按級別加權。
2.2 發現問題
全局盤點為發現問題提供數據支撐,關註:
-
持續產生成本,但已沒有使用的末端數據(一般指30天內無訪問)
沒有使用,但一直在消耗成本的表,對應的就是我提到的陷阱1
-
數據應用價值很低,成本卻很高,這些數據應用上游鏈路上的所有相關數據
低價值產出,高成本的數據應用,對應的是陷阱2
-
高峰期高消耗的數據
高成本的數據,對應陷阱4~8
陷阱3實際是在第6節模型設計中解決的。
2.3 治理優化
針對這三類問題制訂相應策略。
第一類,應對錶下線。 數據下線要謹慎,參考數據下線的執行過程圖:
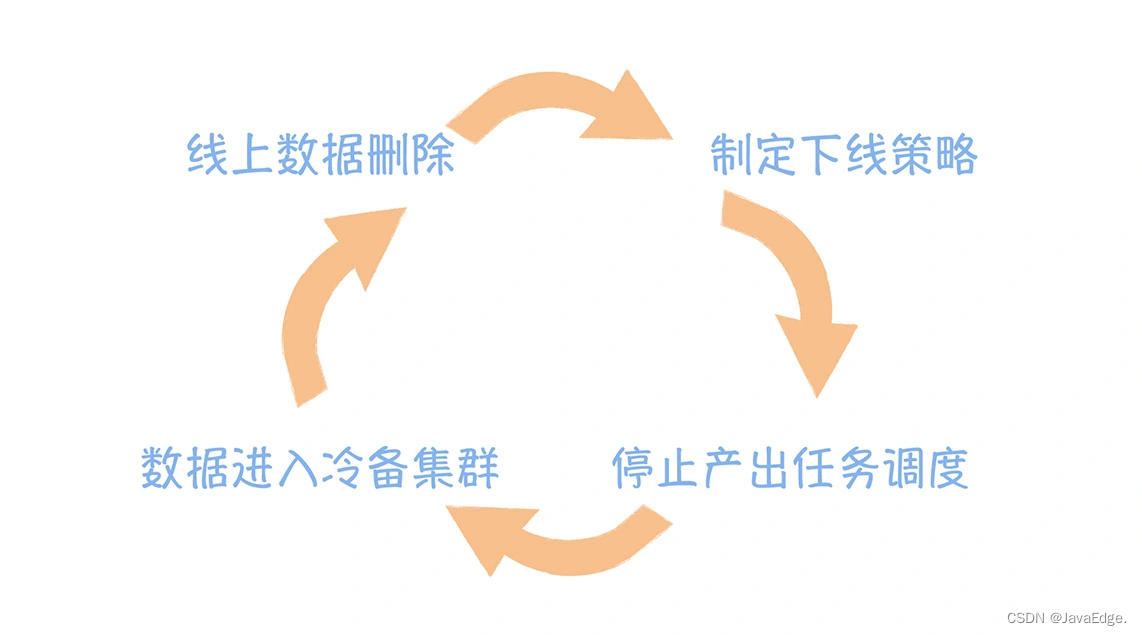
末端數據刪除後,原先末端數據的上游數據會成為新的末端數據,同樣還要按發現問題到治理優化進行重覆,直到所有的末端數據都不滿足下線策略為止。
對第二類問題,我們需要按照應用粒度評估應用是否還有存在的必要。對於報表,可以按照30天內沒有訪問的應用自動下線的策略,先對報表進行銷毀,然後對報表上游的表進行下線,如果該表還被其他的應用引用,就不能下線。下線步驟可以參考前面的下線步驟。
第三類問題,主要是針對高消耗的數據,又具體分為產出數據的任務高消耗和數據存儲高消耗。對於產出任務高消耗,首先要考慮是不是數據傾斜。具體怎麼判斷呢?其實你可以通過MR或者Spark日誌中,Shuffer的數據量進行判斷。如果有某一個Task 數據量非常大,其他的很少,就可以判定出現了數據傾斜。
圖 Spark task shuffer records:
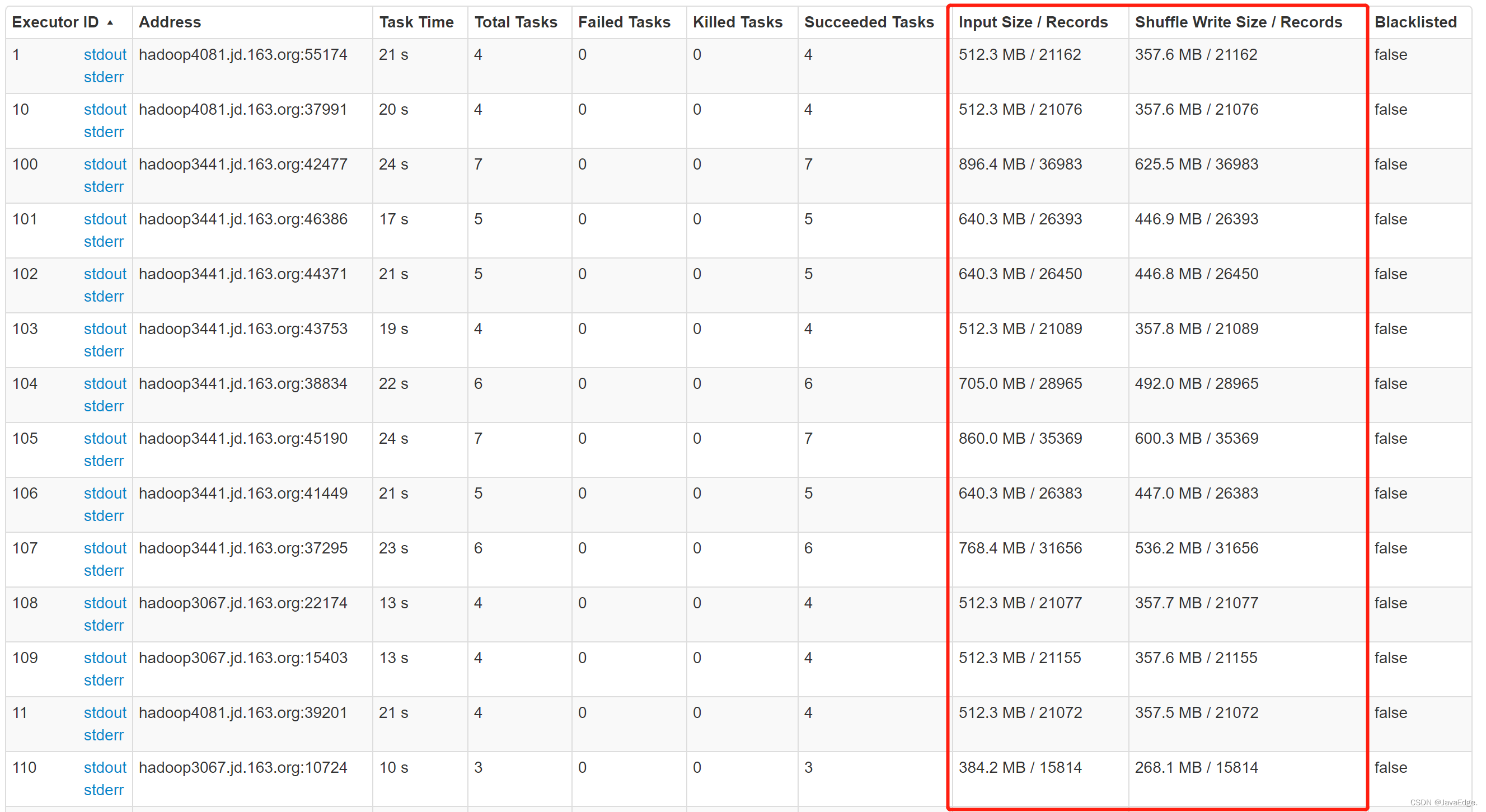
圖 MR reduce task records:
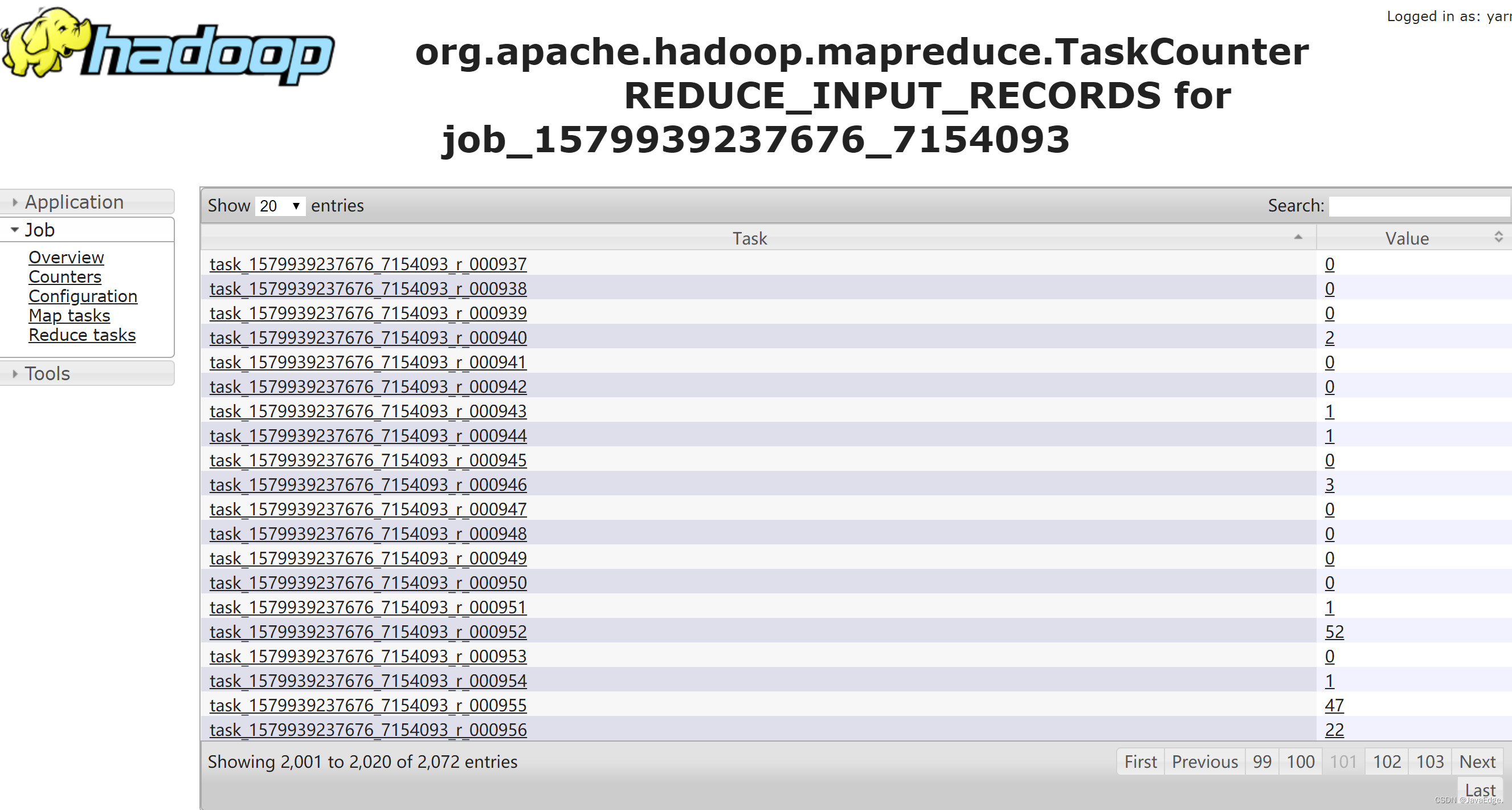
數據傾斜處理?
不同的場景有一些適用的解決方案:
- 如一些大表和小表關聯時,Key分佈不均造成數據傾斜,可使用mapjoin
- 較通用的處理方式,如把熱點Key單獨處理,然後對剩下的Key進行處理,然後對結果進行並集
除數據傾斜,還應該查任務的配置參數。如Spark執行引擎:
- Executor個數是否過大
- executor-cores和executor-memory是否過多,利用率較低
一般executors-memorty 設4G-8G,executor-cores設2-4個(實踐過利用率最高的配置項)。
還要考慮任務是否真有必要在高峰期執行,可根據集群負載情況,儘量將任務遷移到非高峰期執行,“削峰填谷”。
上面幾點是產出任務高消耗的情況。
對存儲消耗比較大的任務,先考慮是否要壓縮,尤其對原始數據層和明細數據層,建議壓縮
壓縮方式

- 小文件的壓縮,不考慮split,gzip較合適
- 大文件,推薦lzo,支持split,在保證壓縮效率前提下,有相對穩定壓縮比
還要考慮生命周期是否設置:
- ODS原始數據層和DWD 明細數據層,適合用永久保留策略
- 一些商品、用戶維表,可考慮3、5年保留策略
整體上,底層表都是長期保留。關註重點應是彙總層以上的表(包括彙總層),一般可根據數據的重要性,制訂7天,1個月保留策略。
治理效果評估
量化治理成果 - 省了多少錢
若直接拿伺服器數量來衡量,不能真實反應治理效果,因為還要考慮業務增長原因,可圍繞任務和數據的成本考慮:
- 下線了多少任務和數據
- 這些任務每日消耗了多少資源
- 數據占用了多少存儲空間
拿這些資源來計算成本,就能算出省了多少錢。如開頭案例,任務A運行3h,在運行過程中,共消耗5384503 cpu*s,37007892 GB *s, 假設我們1個CU (1 cpu, 4g memeory)一年是1300元成本,摺合每天為3.5元(計算公式為1300/365)。
不論是優化或下線任務,只統計高峰時間段內,因為優化低峰時間無法實際節省資源。
高峰時間段為8h,那摺合每s費用0.00012153,則該任的費用為max{5384503*0.00012153, 37007892/4 * 0.00012153} = max{654, 1124} = 1124 。下線這任務後節省1124元,再加上表A占用的存儲空間大小乘以每GB的成本,可得數據表A下線節省費用。
成本治理中心
成本治理不是一勞永逸的工作,需要持之以恆,不斷發現問題,然後治理優化,建立長久運行機制的前提是必須降低成本治理的門檻,接下來,看一下網易的一個成本治理的平臺,EasyCost。
系統提供了數據診斷的功能,可以按照訪問時間、訪問頻率、關聯的應用,設置下線策略,支持一鍵灰度下線,大幅提高了管理的效率。
可通過系統化方式沉澱到產品,然後通過產品提高管理效率,實現治理機制的長久落地。
總結
通過數據中台:
- 可獲得大數據作為資產中心帶來的紅利
- 也可能陷入成本的深淵,為野蠻增長的大數據費用買單
從常見成本陷阱入手,分析可能造成成本浪費的原因,然後介紹精細化成本管理的方法,最後強調:
- 無用數據的下線應該從全鏈路數據資產視圖的末端入手,然後抽絲剝繭,一層一層,向數據加工鏈路的上游推進。
- 應用層表的價值應該以數據應用的價值來衡量,對於低價值產出的應用,應該以應用為粒度進行下線。
- 對高消耗任務的優化只要關註集群高峰期的任務,項目的整體資源消耗只取決於高峰期的任務消耗,當然,如果你使用的是公有雲的資源,可以高峰和低谷實施差異化的成本結算,那低谷期的也是要關註的。
FAQ
在數據中台的集市層,存在一些大寬表,幾百個欄位,上游可能數十個表,如計算這個表的成本會非常高。這表中,欄位訪問頻率不同,優化這張寬表?
-
垂直切分:將寬表按照欄位的訪問頻率劃分,將訪問頻率高的欄位單獨劃分為一張表,訪問頻率低的欄位單獨劃分為一張表。這樣可以減少查詢時掃描的欄位數,提高查詢效率
-
水平切分:將寬表按照行進行切分,將每個切分後的表中的欄位數控制在可接受的範圍內,這樣可以減少單個表的欄位數,提高查詢效率
-
建立索引:對於寬表中的訪問頻率高的欄位,可以建立索引,這樣可以加快查詢速度
-
緩存機制:對於查詢頻率高的數據,可以採用緩存機制,將數據緩存在記憶體中,這樣可以減少查詢時間
-
數據壓縮:對於寬表中的冷數據,可以採用數據壓縮技術,減少存儲空間,提高查詢效率
可根據實際情況選擇合適的優化方式來提高查詢效率。
本文由博客一文多發平臺 OpenWrite 發佈!


