
## 前言 首先java語言的特性是不需像C和C++那樣自己手動釋放記憶體,因為java本身有垃圾回收機制(垃圾回收稱為GC),**顧名思義就是釋放垃圾占用的空間,防止記憶體泄露。JVM運行時占用記憶體最大的空間就是堆記憶體,另外棧區和方法區也會占用空間但是占用有限本章就不探究了。那麼堆中的空間又分為年輕代 ...
前言
首先java語言的特性是不需像C和C++那樣自己手動釋放記憶體,因為java本身有垃圾回收機制(垃圾回收稱為GC),顧名思義就是釋放垃圾占用的空間,防止記憶體泄露。JVM運行時占用記憶體最大的空間就是堆記憶體,另外棧區和方法區也會占用空間但是占用有限本章就不探究了。那麼堆中的空間又分為年輕代和老年代,所以我們粗略的把垃圾回收分為兩種:年輕代的垃圾回收稱為Young GC,老年代的垃圾回收稱為Full GC,實際上此處的Full GC也包含了新生代,老年代,元空間等的回收。
因為Full GC的回收過程會使系統的所有線程STW(Stop The World),那麼我們一定希望讓系統儘量不要進行Full GC,或者必須要進行FullGC的時候執行的時間越短越好。下麵我們主要探究Full GC的角度出發分析我在開發運營後臺的時候遇到的頻繁Full GC過程。
事件背景
項目介紹:
我們團隊做的是一個後臺管理系統,因為針對不同用戶負責的功能不同那麼需要的許可權也就不一樣,所以引入了主流的shiro框架做許可權控制,該框架可以控制菜單欄,按鈕,操作框等。在引入這個框架時一併引入了輔助組件shiro-redis,該組件是一個緩存層方便管理用戶登錄信息,記憶體泄漏的問題也是就現在這個輔助組件上。
事件還原:
在周五的中午11:30分收到了監控的報警信息提示系統在頻繁Full GC,此時我們立刻做兩件事情:
第一:登錄公司的UMP監控平臺(開源監控可以參考:【Prometheus+grafana監控】)查看該機器的系統指標,發現確實在頻繁FullGC從11點持續到了11點半

第二:保留一臺機器作為證據收集,其他機器進行重啟保障業務能正常訪問,重啟後full gc正常
第三:堆棧信息操作指令 ./jmap -F -dump:live,format=b,file=/jmapfile.hprof 18362 (-F操作是強制導出堆棧信息,18362是應用pid,通過 top -c 指令獲取)
第四:因為個人無許可權導出堆棧信息,馬上電話聯繫運維通過上面指令導出該機器上的堆棧文件,就是抓取現場證據,因為過了這個時間堆記憶體可能就正常了
根據JVM知識分析,常見Full GC時的五種情況如下:
1. 老年代記憶體不足(大對象過多或記憶體泄漏)
2. Metaspace 空間不足
3. 代碼主動觸發 System.gc()
4. YGC 時的悲觀策略
5. dump live 的記憶體信息時,比如 jmap -dump:live
分析原因
1、查看公司SGM監控平臺(開源監控可以參考:【Prometheus+grafana監控】),元空間最大記憶體256M,FullGC發生前後為117M,排除Metaspace不足造成的原因

2、在系統中搜索第三方jar包,沒有主動執行System.gc()操作的代碼
3、查看JVM啟動參數中有下麵兩個參數,所以排除了YGC時候的悲觀策略原因
-XX:CMSInitiatingOccupancyFraction=70 # 堆記憶體達到 70%進行 FullGC
-XX:+UseCMSInitiatingOccupancyOnly # 禁止 YGC 時的悲觀策略(YGC 前後判斷是否需要 FullGC),只有達到閾值才進行 FullGc
4、通過和運維、研發組溝通沒有人主動執行dump操作,查看系統的歷史執行指令也沒有dump操作,主動dump的原因排除
初步分析結果:
通過上面依靠監控平臺、JVM啟動參數、代碼排除、指令分析,最終嫌疑最大的就是老年代記憶體空間不足造成頻繁Full GC,但是作為技術者,排除法顯然不能作為原因定位的依據,我們還需要繼續確定我們的猜想,下麵會結合JVM啟動參數,Tomcat啟動參數,堆棧文件三大關鍵要素做具體分析。
下圖是進行FullGC時候的老年代記憶體情況,把下麵的72%、1794Mb、2496Mb、448Mb先記住,下麵會跟這些值做對比

指標信息:
JVM核心參數:
-Xms2048M # 系統啟動初始化堆空間
-Xmx4096M # 系統最大堆空間
-Xmn1600M # 年輕代空間(包括 From 區和 To),From 和 To 預設占年輕代 20%
-XX:MaxPermSize=256M # 最大非堆記憶體,按需分配
-XX:MetaspaceSize=256M # 元空間大小,JDK1.8 取消了永久代(PermGen)新增元空間,元空間並不在虛擬機中,而是使用本地記憶體。因此,預設情況下,元空間的大小僅受本地記憶體限制,存儲類和類載入器的元數據信息
-XX:CMSInitiatingOccupancyFraction=70 # 堆記憶體達到 70%進行 FullGC
-XX:+UseCMSInitiatingOccupancyOnly # 禁止 YGC 時的悲觀策略(YGC 前後判斷是否需要 FullGC),只有達到閾值才進行 FullGc
-XX:+UseConcMarkSweepGC # 使用 CMS 作為垃圾收集器
Tomcat核心參數:
maxThreads=750 # Tomcat 線程池最多能起的線程數
minSpareThreads=50 # Tomcat 初始化的線程池大小或者說 Tomcat 線程池最少會有這麼多線程
acceptCount=1000 # Tomcat 維護最大的隊列數
通過上邊的指標信息我們能對系統的性能瓶頸有大致瞭解,首先根據JVM參數分析結果如下:
堆最大空間4096M
年輕代占用空間1600M(包括Eden區1280M,Survivor From160M,Survivor To160M)
老年代最大占用空間2496M(跟上面的2496Mb對應)
系統初始化堆記憶體2048M
那麼老年代初始記憶體(448M) (跟上面的448Mb對應)= 初始化堆記憶體(2048M) - 年輕代記憶體(1600M)
根據JVM啟動參數確定堆記憶體達到70時進行垃圾回收, 系統進行垃圾回收時堆記憶體占比72%(跟上面的72%對應)一直大於70%,那麼使用記憶體是0.72 * 2496Mb ≈ 1794Mb(跟上面的1794Mb對應)
堆棧分析:
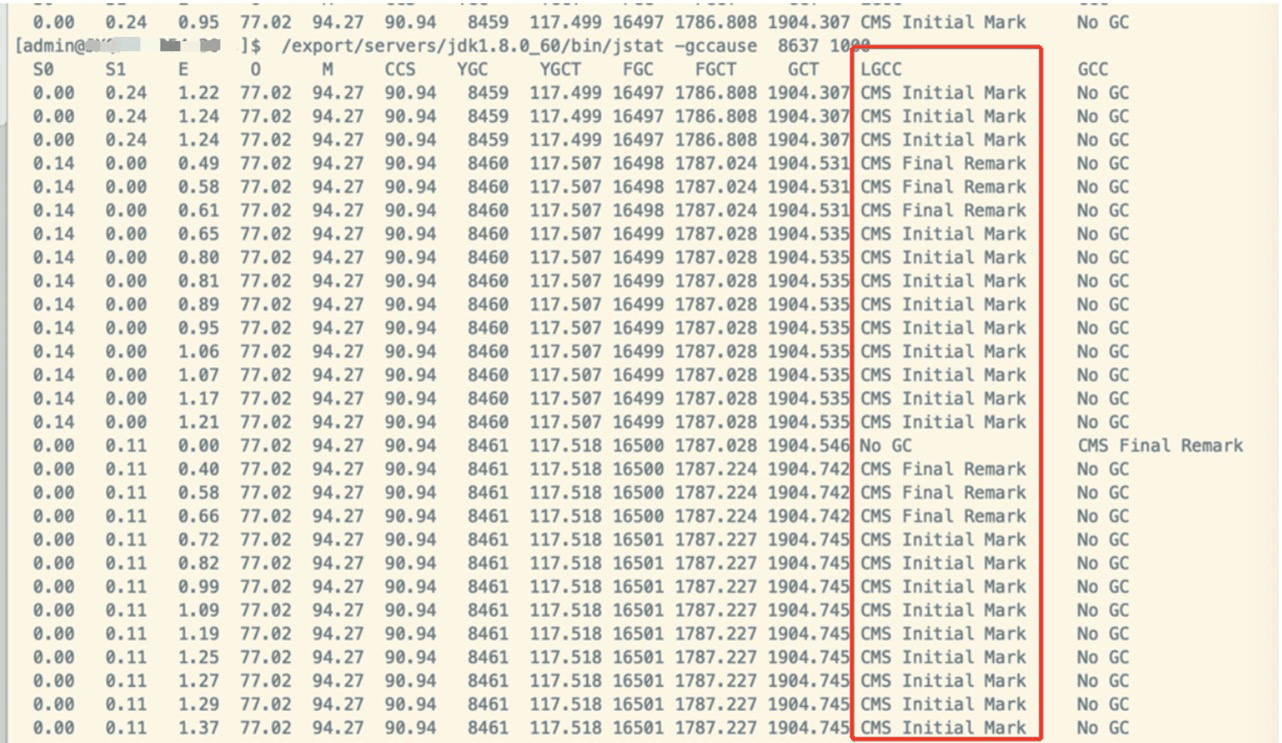
在查詢堆棧前執行GC原因指令:jstat -gccause [pid] 1000,執行結果如下圖,可以看到 LGCC 這一列代表了最後執行 gc 的原因。CMS Initial Mark 和 CMS Final Remark 這兩個階段是 CMS 垃圾回收的初始標記和最終標記階段是耗時最長也是造成 STW(Stop The World)的兩個階段
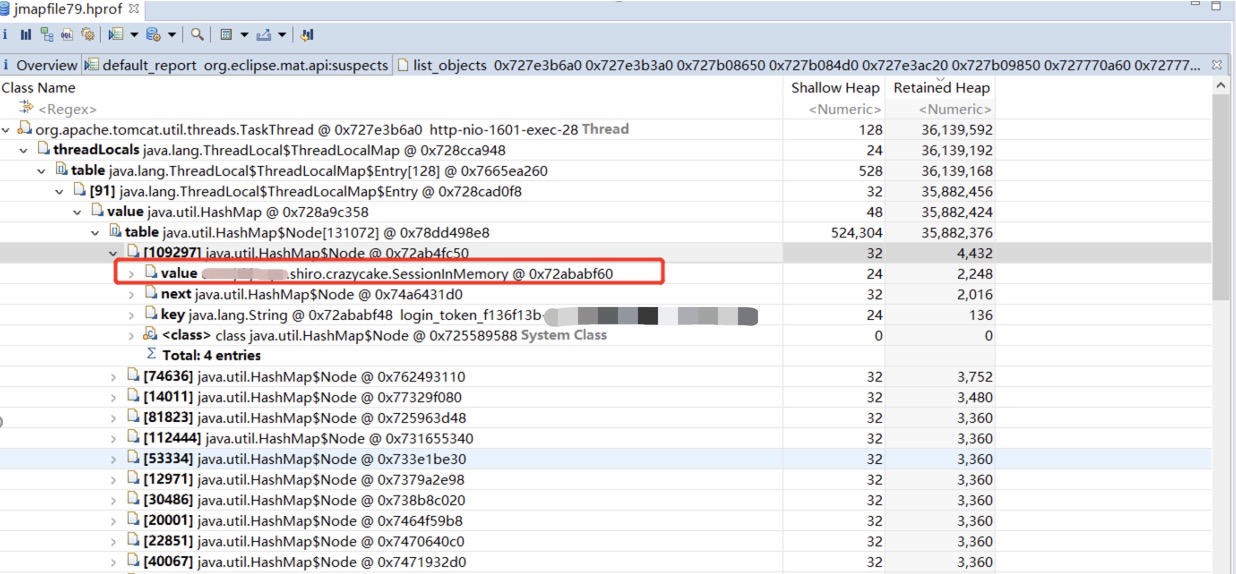
導出堆棧指令:jmap -dump:live,format=b,file=jmapfile.hprof [pid]。導出的文件需要使用MAT軟體分析,全稱 MemoryAnalyzer,主要分析堆記憶體。參考下載鏈接:http://eclipse.org/mat/downloads.php
從堆棧文件分析結果中發現有50個org.apache.tomcat.util.threads.TaskThread占用空間很大。共占用空間96.16%

每個TaskThread實例占用空間36M左右

查看記憶體詳情保存最大最多的對象是ThreadLocal中存儲的SessionInMemory對象
最終原因:
通過分析上面的JVM參數、Tomcat參數、堆棧文件,記憶體泄漏的原因是每個線程中有一個ThreadLocal存儲大量 SessionInMemory,因為Tomcat的啟動核心線程數是50個,每個線程的記憶體占用 36M 左右,共占用 1.8G,老年代記憶體達到 70%也就是 2496 * 0.7 = 1747.2M 就會進行垃圾回收,1.8G 剛好比 1747.2M 稍微大一些。但是線程中的對象又沒辦法被回收,所以就會看到系統再頻繁 FullGC。
定位問題
通過上面記憶體分析已經定位到記憶體泄漏的原因是每個線程中有大量 SessionInMemory,下麵步驟就認真分析代碼找到其中創建如此多對象還不銷毀的原因。
經過初步分析發現 SessionInMemory 是引用 shiro-redis 的工具包裡面的對象,主要封裝Session 信息和創建時間。主要作用是在當前線程的jvm中做一層緩存當系統頻繁獲取 Session 時不用去 redis 獲取了。SessionInMemary對象是shiro判斷用戶登錄成功時候存儲的數據,主要包括用戶信息,認證信息,許可權信息等,因為用戶登錄成功後不會重覆認證,shiro會對不同用戶做許可權判斷
分析代碼發現處理本地緩存Session的流程有明顯問題,我畫了一個簡易的流程圖,在介紹流程圖前我先描述一下Session和用戶登錄操作如何聯繫起來
我們都知道運營後臺需要用戶登錄,登錄成功後會生成一個cookie保存到瀏覽器中,cookie存儲一個關鍵欄位sessionId用來標識用戶的狀態和信息,當用戶訪問頁面調用介面的時候shiro會從請求Request中獲取cookie中的sessionId,根據這個唯一標識生成Session來存儲用戶的登錄態和登錄信息等,這些信息會保存到redis中。shiro-redis組件負責從redis中獲取的Session信息通過ThreadLoca做到線程隔離。

上圖流程概括就是:用戶訪問頁面先從本地緩存獲取Session,如果存在且沒有超過一秒就返回結果,如果沒有Session或者過期了就把現在的Session刪除並新建一個返回結果。整體看思路清晰,先獲取Session,如果沒有就新建返回,如果過期了就刪除再新建返回。
流程圖隱藏的問題(核心問題)
1、多個線程會複製多份相同Session使記憶體成倍增加(Session一樣線程不同)
舉個例子:用戶登錄後臺生成一個Session,假設請求都到一臺機器上,第一次請求到線程 1,第二個請求到線程 2,因為Session一樣但是線程之間是隔離的,所以線程 1 和線程 2 都會創建一份相同 Session 存儲到 ThreaLocal 中,Tomcat 最小空閑線程數越多複製的 Session 份數也越多。因為Tomcat的核心線程數不會關閉,所以裡面的資源也不會釋放。此處有個疑問ThreadLocad的key是弱引用但是為什麼沒回收呢?下麵統統解答
2、舊Session無法清除(線程一樣Session不同)
舉個例子1:假設所有請求都到一臺機器的同一個線程,用戶第一次登錄後臺生成Session1,第一次請求到線程 1,1 秒內所有請求都執行完了,此時 Session 沒有移除(因為Session移除策略是懶刪除,需要等下次同一個Session訪問時判斷過期條件再刪除),用戶重新登錄,生成了Session2,因為Session2線上程1中還沒有就會重新創建,導致第一次登錄時候用到的 Session1 就一直保存到該線程中了
舉個例子2:參考例子1的思路,如果用戶用Session1沒有在1秒內把所有請求執行完,就會執行懶刪除操作,但是刪除後又新建了一個,那麼用戶重新登錄後剛纔新建的那個Session還是沒有被刪除,所以總結出來只要用戶重新登錄必定有一個舊的Session會保留到線程中
代碼分析
1、在RedisSessionDAO.java文件中定義了一個ThreadLocal變數作為線程隔離

2、用戶訪問介面、js 文件、css 文件等資源的時候會進入 shiro 的攔截機制。在攔截過程中會頻繁調用 doReasSession()方法獲取用戶的 Session 信息,主要是獲取信息校驗用戶的許可權控制等。
下麵的方法主要整合了獲取Session操作和設置Session操作,如果從ThreadLocal中沒有獲取到或者本地緩存超過1秒了就返回null,判斷為null之後就會從redis中獲取並新建一個Session存儲到ThreadLoca中

3、從ThreadLocal中取出sessionMap,根據sessionId在sessionMap中尋找Session,如果沒找到直接返回null,如果找到了再判斷時間是否超過了1秒,如果沒超過返回Session,如果超過了移除返回null

4、從ThreadLocal中獲取sessionMap,如果為null就新建一個保存起來,因為用戶第一次訪問的時候線程中的sessionMap還沒有呢所以要新建。然後向sessionMap中存儲Session對象

所以代碼的完成流程總結:獲取 Session 的操作是調用 getSessionFromThreadLocal()方法,如果沒有獲取到 Session 就返回 null,調用 setSessionToThreadLocal()方法會重新設置一個 Session。如果 Session 在當前線程的保存時間超過 1 秒就 remove。
通過上面分析JVM、Tomat、堆棧、代碼已經把問題定位了,因為shiro-redis中存儲的SessionInMemory對象處理不當導致線程間存儲越來越多,最終使記憶體泄漏進而導致了頻繁FullGC。因為我們引用的shiro-redis版本是3.2.2版本,所以存在這個漏洞,作者已於2019年3月升級jar包到3.2.3版本把該問題解決。備註:3.2.2及以下版本存在該問題
解決問題
解決問題的方案目前有四種。 針對我們系統使用的是方案 1+方案 4
| 序號 | 方案描述 | 優點 | 缺點 |
|---|---|---|---|
| 方案1 | 每次設置session時遍歷刪除以前過期或者為null的session | 主動刪除,刪除頻次依賴用戶的訪問頻次 | 如果在1秒內有大量用戶訪問,總session很多無效session很少,遍歷所有session做了很多無用功導致訪問變慢 |
| 方案2 | 取消threadLocal策略,所有請求直接查詢緩存(redis) | 減少本地記憶體使用 | 訪問緩存耗時比本地長,經過測試發現一個介面會調用16次左右的獲取session操作,一個頁面幾十個介面,直接查詢緩存性能存在問題 |
| 方案3 | 使用本地緩存(guavaCache或者EhCache等),並對緩存做移除策略 | 多個線程共用一份記憶體,節省記憶體空間,提升系統性能 | 對框架有深入瞭解,接入需要開發成本 |
| 方案4 | 把tomcat的核心線程數減小,比如把原來的50改成 5 | 減少系統資源,減少相同Session的複製份數,大於5的線程銷毀資源也一起回收 | 處理併發能力略低 |
疑問解答
Q:在 RedisSessionDAO 裡面只定義了一個 ThreadLocal 的變數 sessionsInThread,怎麼就會是 50 個線程把相同的 Session 複製 50 份呢?
A:首先我們先理解 ThreadLocal 的結構,ThreadLocal 有一個靜態類 ThreadLocalMap,ThreadLocalMap 裡面還有一個 Entry,我們的 key 和 value 就是保存在 Entry 的,key 是一個弱引用的 ThreadLocal 類型,,這個 key 在所有的線程中都是一樣的,實際上就是我們定義的靜態 sessionsInThread。那又是怎麼做到線程隔離的呢?
這就講到Thread中的一個成員變數threadLocals,這個對象就是ThreadLocal.ThreadLocalMap類型,也就是每次創建一個線程都會new一個ThreadLocalMap,所以每個線程中的 ThreadLocalMap 都是不同的,但是裡面 Entry 存儲的 key 都是一樣的,也就是我們前面定義的 sessionsInThread 靜態變數。
當一個線程需要獲取 Entry 中存儲的 value 時候,調用 sessionsInThread.get()方法,這個方法做了三件事情,一是獲取當前線程的實例,二是從線程實例中獲取 ThreadLocalMap,三是從 ThreadLocalMap 中根據 ThreadLocal 這個 key 獲取指定的 value

獲取 Thread 中的 ThreadLocalMap

從 ThreadLocalMap 中獲取指定的 value,又有個疑問,獲取 Entry 為什麼還要從一個 table數組中拿呢?這個很好理解一個線程不一定只有一個 ThreadLocal 變數吧,多個 ThreadLocal變數就是有多個 key,所以就放到 table 數組裡面了

Q:都說 ThreadLocal 的 key 是一個弱引用,如果記憶體不足了會被垃圾回收,咱們的 key 從堆棧看並沒有回收呀?
A:這是個好問題,首先我們的 RedisSessionDAO 是 Spring 註入的單例模式,ThreadLocal被定義成一個靜態變數,靜態變數在記憶體中是不會回收的。 補充:一般我們在使用 ThreadLocal 的時候都會定義成靜態變數,如果定義成非靜態變數創建一個對象就會 new 一個 ThreadLocal,那麼 ThreadLocal 就沒有存在的意義了。
Q:已經結束的線程,為什麼還會存活,裡面的對象也不會消失?
A:因為設置的最小空閑線程數是50,業務量不大併發數沒有超過50,tomcat會保留最小的線程數量不會新建也不用回收,ThreadLocalMap是線程中的成員變數所以不會回收
Q:訪問一次介面就會生成一個 sessionId 嗎?
A:訪問介面先判斷用戶信息是否有效,無效才會重新登錄獲取新的 sessionId
Q:shiro-redis在本地保存Session為什麼設置1秒過期時間?
A:因為運營後臺不同於業務介面會持續調用,後臺介面大部分的場景是用戶訪問一個頁面並停留在頁面上做一些操作,訪問一個頁面的時候瀏覽器會載入多個資源,包括靜態資源html,css,js等,和介面的動態數據,整個資源載入過程儘量保持在一秒內完成,如果超過一秒的話系統體驗性能較差,所以本地緩存一秒足夠了。
收穫總結
報警前:
1.熟悉第三方jar包的工作原理,尤其是個人開發工具包,因為沒有經過市場檢驗使用前要格外小心
2.可以使用jvisualvm進行本地壓測觀察jvm情況
3.關註監控報警,掌握監控平臺操作,能夠從監控中查詢系統各項指標信息
4.根據業務合理配置JVM參數和Tomcat參數
報警後:
1.能夠第一時間抓取系統的JVM信息,比如堆棧,GC信息,線程棧等
2.通過使用MAT記憶體輔助軟體幫助自己分析問題原因
作者:京東科技 郭銀利
來源:京東雲開發者社區

