
 > 版本說明: > > SeaTunnel:apache-seatunnel-2.3.2-SNAPHOT ...

版本說明:
SeaTunnel:apache-seatunnel-2.3.2-SNAPHOT
引擎說明:
Flink:1.16.2
Zeta:官方自帶
前言
近些時間,我們正好接手一個數據集成項目,數據上游方是給我們投遞到Kafka,我們一開始的技術選型是SpringBoot+Flink對上游數據進行加工處理(下文簡稱:方案一),由於測試不到位,後來到線上,發現數據寫入效率完全不符合預期。後來將目光轉到開源項目SeaTunnel上面,發現Source支持Kafka,於是開始研究測試,開發環境測試了500w+數據,發現效率在10000/s左右。果斷放棄方案一,採取SeaTunnel對數據進行集成加工(下文簡稱:方案二)。在SeaTunnel研究的過程中,總結了兩種方法,方法二相較於方法一,可以實現全場景使用,無需擔心欄位值裡面各種意想不到的字元對數據落地造成錯位現象的發生。
對比

在方案二的基礎上又衍生出兩種方法

所以,在經過長時間的探索和我們線上驗證得出結論,建議使用方案二的方法二。
好了,我們進入正文,主篇幅主要介紹方案二中的兩種方法,讓大家主觀的感受SeaTunnel的神奇。
方案一 Springboot+Flink實現Kafka 複雜JSON的解析
網上案例很多,在此不做過多介紹。
方案二 SeaTunnel實現Kafka複雜JSON的解析
在開始介紹之前,我們看一下我們上游方投遞Kafka的Json樣例數據(對部分數據進行了敏感處理),如下:
"magic": "a***G",
"type": "D***",
"headers": null,
"messageSchemaId": null,
"messageSchema": null,
"message": {
"data": {
"LSH": "187eb13****l0214723",
"NSRSBH": "9134****XERG56",
"QMYC": "01*****135468",
"QMZ": "1Zr*****UYGy%2F5bOWtrh",
"QM_SJ": "2023-05-05 16:42:10.000000",
"YX_BZ": "Y",
"ZGHQ_BZ": "Y",
"ZGHQ_SJ": "2023-06-26 16:57:17.000000",
"SKSSQ": 202304,
"SWJG_DM": "",
"SWRY_DM": "00",
"CZSJ": "2023-05-05 16:42:10.000000",
"YNSRSBH": "9134****XERG56",
"SJTBSJ": "2023-06-26 19:29:59.000",
"SJCZBS": "I"
},
"beforeData": null,
"headers": {
"operation": "INSERT",
"changeSequence": "12440977",
"timestamp": "2023-06-26T19:29:59.673000",
"streamPosition": "00****3.16",
"transactionId": "000***0006B0002",
"changeMask": "0FFF***FF",
"columnMask": "0F***FFFF",
"transactionEventCounter": 1,
"transactionLastEvent": false
}
}
}
方法一、不通過UDF函數實現
存在問題:欄位值存在分隔符,例如‘,’ 則數據在落地的時候會發生錯位現象。
該方法主要使用官網 transform-v2的各種轉換插件進行實現,主要用到的插件有 Replace、Split以及Sql實現
ST腳本:(ybjc_qrqm.conf)
env {
execution.parallelism = 100
job.mode = "STREAMING"
job.name = "kafka2mysql_ybjc"
execution.checkpoint.interval = 60000
}
source {
Kafka {
result_table_name = "DZFP_***_QRQM1"
topic = "DZFP_***_QRQM"
bootstrap.servers = "centos1:19092,centos2:19092,centos3:19092"
schema = {
fields {
message = {
data = {
LSH = "string",
NSRSBH = "string",
QMYC = "string",
QMZ = "string",
QM_SJ = "string",
YX_BZ = "string",
ZGHQ_BZ = "string",
ZGHQ_SJ = "string",
SKSSQ = "string",
SWJG_DM = "string",
SWRY_DM = "string",
CZSJ = "string",
YNSRSBH = "string",
SJTBSJ = "string",
SJCZBS = "string"
}
}
}
}
start_mode = "earliest"
#start_mode.offsets = {
# 0 = 0
# 1 = 0
# 2 = 0
#}
kafka.config = {
auto.offset.reset = "earliest"
enable.auto.commit = "true"
# max.poll.interval.ms = 30000000
max.partition.fetch.bytes = "5242880"
session.timeout.ms = "30000"
max.poll.records = "100000"
}
}
}
transform {
Replace {
source_table_name = "DZFP_***_QRQM1"
result_table_name = "DZFP_***_QRQM2"
replace_field = "message"
pattern = "[["
replacement = ""
#is_regex = true
#replace_first = true
}
Replace {
source_table_name = "DZFP_***_QRQM2"
result_table_name = "DZFP_***_QRQM3"
replace_field = "message"
pattern = "]]"
replacement = ""
#is_regex = true
#replace_first = true
}
Split {
source_table_name = "DZFP_***_QRQM3"
result_table_name = "DZFP_***_QRQM4"
# 存在問題: 如果欄位值存在分隔符 separator,則數據會錯位
separator = ","
split_field = "message"
# 你的第一個欄位包含在zwf5裡面,,前五個占位符是固定的。
output_fields = [zwf1,zwf2,zwf3,zwf4,zwf5,nsrsbh,qmyc,qmz,qm_sj,yx_bz,zghq_bz,zghq_sj,skssq,swjg_dm ,swry_dm ,czsj ,ynsrsbh ,sjtbsj ,sjczbs]
}
sql{
source_table_name = "DZFP_***_QRQM4"
query = "select replace(zwf5 ,'fields=[','') as lsh,nsrsbh,trim(qmyc) as qmyc,qmz,qm_sj,yx_bz, zghq_bz,zghq_sj,skssq,swjg_dm ,swry_dm ,czsj ,ynsrsbh ,sjtbsj ,replace(sjczbs,']}]}','') as sjczbs from DZFP_DZDZ_QRPT_YWRZ_QRQM4 where skssq <> ' null'"
result_table_name = "DZFP_***_QRQM5"
}
}
sink {
Console {
source_table_name = "DZFP_***_QRQM5"
}
jdbc {
source_table_name = "DZFP_***_QRQM5"
url = "jdbc:mysql://localhost:3306/dbname?serverTimezone=GMT%2b8"
driver = "com.mysql.cj.jdbc.Driver"
user = "user"
password = "pwd"
batch_size = 200000
database = "dbname"
table = "tablename"
generate_sink_sql = true
primary_keys = ["nsrsbh","skssq"]
}
}
正常寫入數據是可以寫入了。
寫入成功如下:
● kafka源數據:
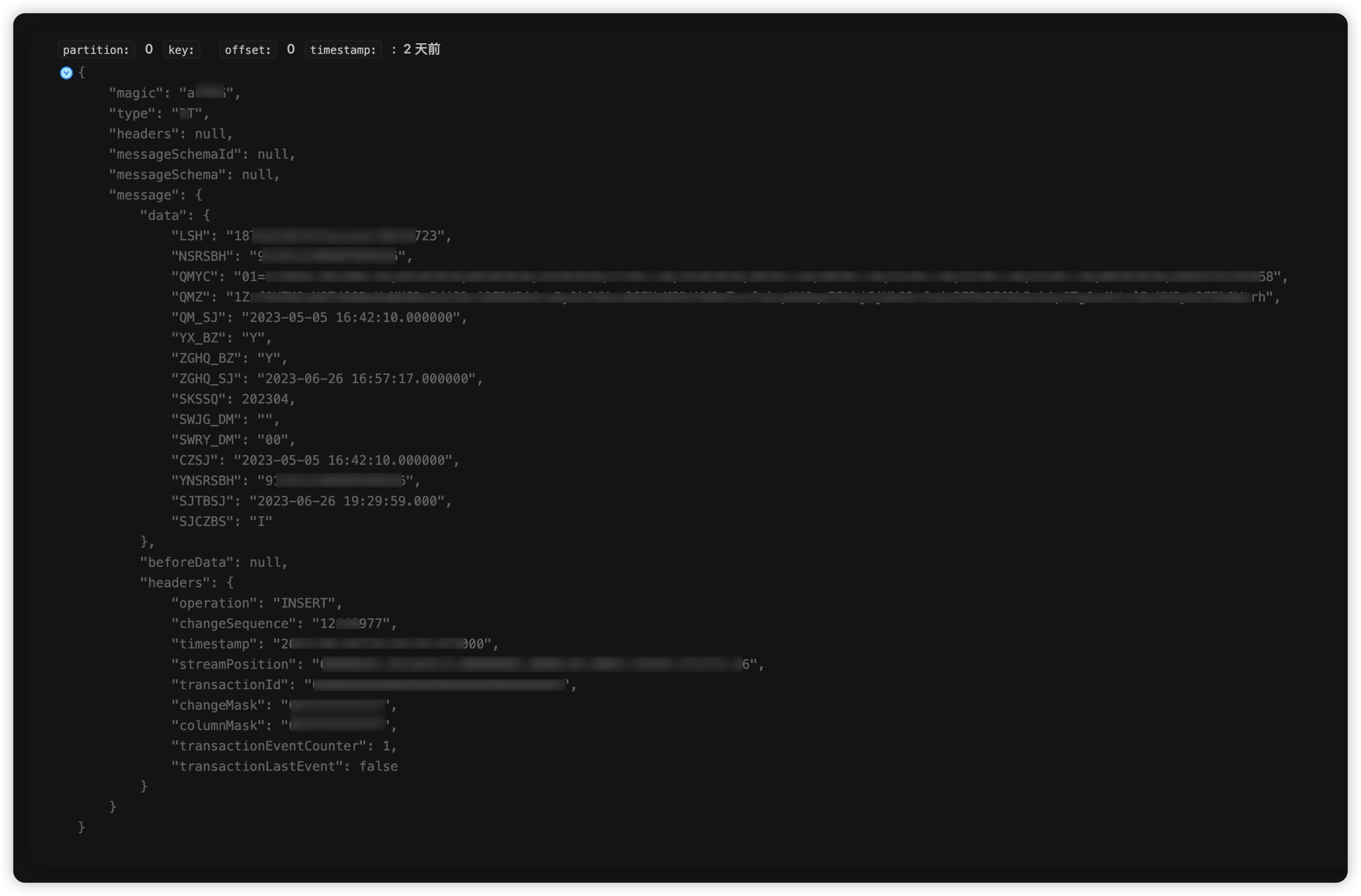
● tidb目標數據:

現在我們模擬給kafka發送一條數據,其中,SJTBSJ欄位我在中間設置一個, 是逗號。
原始值:2023-06-26 19:29:59.000 更改之後的值2023-06-26 19:29:59.0,00
往topic生產一條數據命令
kafka-console-producer.sh --topic DZFP_***_QRQM --broker-list centos1:19092,centos2:19092,centos3:19092
發送如下:
"magic": "a***G",
"type": "D***",
"headers": null,
"messageSchemaId": null,
"messageSchema": null,
"message": {
"data": {
"LSH": "187eb13****l0214723",
"NSRSBH": "9134****XERG56",
"QMYC": "01*****135468",
"QMZ": "1Zr*****UYGy%2F5bOWtrh",
"QM_SJ": "2023-05-05 16:42:10.000000",
"YX_BZ": "Y",
"ZGHQ_BZ": "Y",
"ZGHQ_SJ": "2023-06-26 16:57:17.000000",
"SKSSQ": 202304,
"SWJG_DM": "",
"SWRY_DM": "00",
"CZSJ": "2023-05-05 16:42:10.000000",
"YNSRSBH": "9134****XERG56",
"SJTBSJ": "2023-06-26 19:29:59.0,00",
"SJCZBS": "I"
},
"beforeData": null,
"headers": {
"operation": "INSERT",
"changeSequence": "12440977",
"timestamp": "2023-06-26T19:29:59.673000",
"streamPosition": "00****3.16",
"transactionId": "000***0006B0002",
"changeMask": "0FFF***FF",
"columnMask": "0F***FFFF",
"transactionEventCounter": 1,
"transactionLastEvent": false
}
}
}
寫入之後,發現數據錯位了。
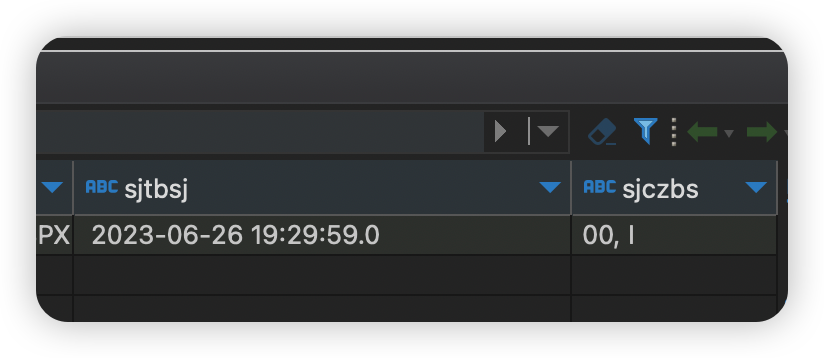
結論:其實這個問題線上還是能遇到的,比如地址欄位裡面含有逗號,備註信息裡面含有逗號等等,這種現象是不可避免的,所以此種方案直接pass。對數據危害性極大!可以處理簡單的數據,當做一種思路。
方法二:通過UDF函數實現
該方法通過UDF函數擴展(https://seatunnel.apache.org/docs/2.3.2/transform-v2/sql-udf)的方式,實現嵌套kafka source json源數據的解析。可以大大簡化ST腳本的配置
ST腳本:(ybjc_qrqm_yh.conf)
env {
execution.parallelism = 5
job.mode = "STREAMING"
job.name = "kafka2mysql_ybjc_yh"
execution.checkpoint.interval = 60000
}
source {
Kafka {
result_table_name = "DZFP_***_QRQM1"
topic = "DZFP_***_QRQM"
bootstrap.servers = "centos1:19092,centos2:19092,centos3:19092"
schema = {
fields {
message = {
data = "map<string,string>"
}
}
}
start_mode = "earliest"
#start_mode.offsets = {
# 0 = 0
# 1 = 0
# 2 = 0
#}
kafka.config = {
auto.offset.reset = "earliest"
enable.auto.commit = "true"
# max.poll.interval.ms = 30000000
max.partition.fetch.bytes = "5242880"
session.timeout.ms = "30000"
max.poll.records = "100000"
}
}
}
transform {
sql{
source_table_name = "DZFP_***_QRQM1"
result_table_name = "DZFP_***_QRQM2"
# 這裡的qdmx就是我自定義的UDF函數,具體實現下文詳細講解。。。
query = "select qdmx(message,'lsh') as lsh,qdmx(message,'nsrsbh') as nsrsbh,qdmx(message,'qmyc') as qmyc,qdmx(message,'qmz') as qmz,qdmx(message,'qm_sj') as qm_sj,qdmx(message,'yx_bz') as yx_bz,qdmx(message,'zghq_bz') as zghq_bz,qdmx(message,'zghq_sj') as zghq_sj,qdmx(message,'skssq') as skssq,qdmx(message,'swjg_dm') as swjg_dm,qdmx(message,'swry_dm') as swry_dm,qdmx(message,'czsj') as czsj,qdmx(message,'ynsrsbh') as ynsrsbh, qdmx(message,'sjtbsj') as sjtbsj,qdmx(message,'sjczbs') as sjczbs from DZFP_DZDZ_QRPT_YWRZ_QRQM1"
}
}
sink {
Console {
source_table_name = "DZFP_***_QRQM2"
}
jdbc {
source_table_name = "DZFP_***_QRQM2"
url = "jdbc:mysql://localhost:3306/dbname?serverTimezone=GMT%2b8"
driver = "com.mysql.cj.jdbc.Driver"
user = "user"
password = "pwd"
batch_size = 200000
database = "dbname"
table = "tablename"
generate_sink_sql = true
primary_keys = ["nsrsbh","skssq"]
}
}
執行腳本:查看結果,發現並沒有錯位,還在原來的欄位(sjtbsj)上面。
這種方法,是通過key獲取value值。不會出現方法一中的按照逗號分割出現數據錯位現象。
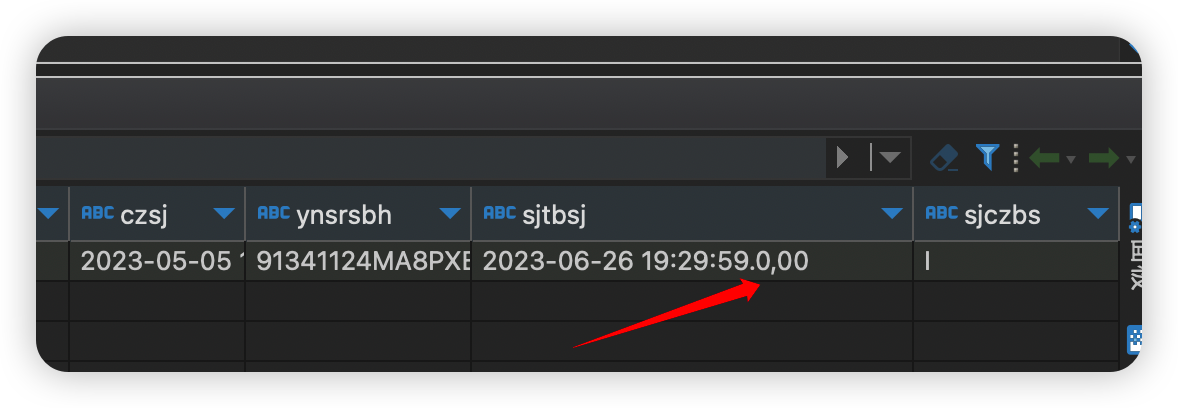
具體UDF函數編寫如下。
maven引入如下:
<dependencies>
<dependency>
<groupId>org.apache.seatunnel</groupId>
<artifactId>seatunnel-transforms-v2</artifactId>
<version>2.3.2</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.seatunnel</groupId>
<artifactId>seatunnel-api</artifactId>
<version>2.3.2</version>
</dependency>
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.20</version>
</dependency>
<dependency>
<groupId>com.google.auto.service</groupId>
<artifactId>auto-service-annotations</artifactId>
<version>1.1.1</version>
<optional>true</optional>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>com.google.auto.service</groupId>
<artifactId>auto-service</artifactId>
<version>1.1.1</version>
<optional>true</optional>
<scope>compile</scope>
</dependency>
</dependencies>
UDF具體實現java代碼如下:
package org.seatunnel.sqlUDF;
import cn.hutool.core.util.StrUtil;
import cn.hutool.json.JSONObject;
import cn.hutool.json.JSONUtil;
import com.google.auto.service.AutoService;
import org.apache.seatunnel.api.table.type.BasicType;
import org.apache.seatunnel.api.table.type.SeaTunnelDataType;
import org.apache.seatunnel.transform.sql.zeta.ZetaUDF;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
@AutoService(ZetaUDF.class)
public class QdmxUDF implements ZetaUDF {
@Override
public String functionName() {
return "QDMX";
}
@Override
public SeaTunnelDataType<?> resultType(List<SeaTunnelDataType<?>> list) {
return BasicType.STRING_TYPE;
}
// list 參數實例:(也就是kafka 解析過來的數據)
//SeaTunnelRow{tableId=, kind=+I, fields=[{key1=value1,key2=value2,.....}]}
@Override
public Object evaluate(List<Object> list) {
String str = list.get(0).toString();
//1 Remove the prefix
str = StrUtil.replace(str, "SeaTunnelRow{tableId=, kind=+I, fields=[{", "");
//2 Remove the suffix
str = StrUtil.sub(str, -3, 0);
// 3 build Map key value
Map<String, String> map = parseToMap(str);
if ("null".equals(map.get(list.get(1).toString())))
return "";
// 4 return the value of the key
return map.get(list.get(1).toString());
}
public static Map<String, String> parseToMap(String input) {
Map<String, String> map = new HashMap<>();
// 去除大括弧 在字元串階段去除
// input = input.replaceAll("[{}]", "");
// 拆分鍵值對
String[] pairs = input.split(", ");
for (String pair : pairs) {
String[] keyValue = pair.split("=");
if (keyValue.length == 2) {
String key = keyValue[0].trim().toLowerCase();
String value = keyValue[1].trim();
map.put(key, value);
}
}
return map;
}
}
然後打包,打包命令如下:
mvn -T 8 clean install -DskipTests -Dcheckstyle.skip -Dmaven.javadoc.skip=true
查看META-INF/services, 看註解@AutoService 是否生成對應的spi介面:
如下:則打包成功!
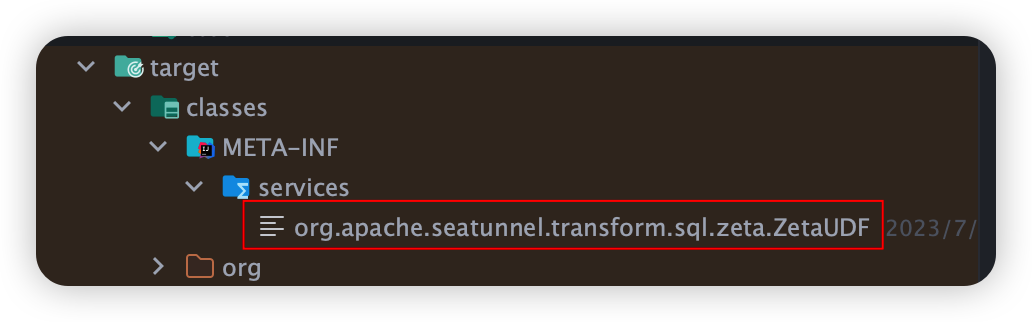
如果沒有,則打包失敗,UDF函數無法使用.
可以參考我的打包插件:
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-site-plugin</artifactId>
<version>3.7</version>
<dependencies>
<dependency>
<groupId>org.apache.maven.doxia</groupId>
<artifactId>doxia-site-renderer</artifactId>
<version>1.8</version>
</dependency>
</dependencies>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.1</version>
<configuration>
<annotationProcessorPaths>
<path>
<groupId>com.google.auto.service</groupId>
<artifactId>auto-service</artifactId>
<version>1.1.1</version>
</path>
</annotationProcessorPaths>
</configuration>
</plugin>
</plugins>
</build>
最終打成的jar包放到 ${SEATUNNEL_HOME}/lib目錄下,由於我的UDF函數引入了第三方jar包,也需要一併上傳。如果是Zeta集群,需要重啟Zeta集群才能生效。其他引擎實時生效。
最終上傳成功如下:
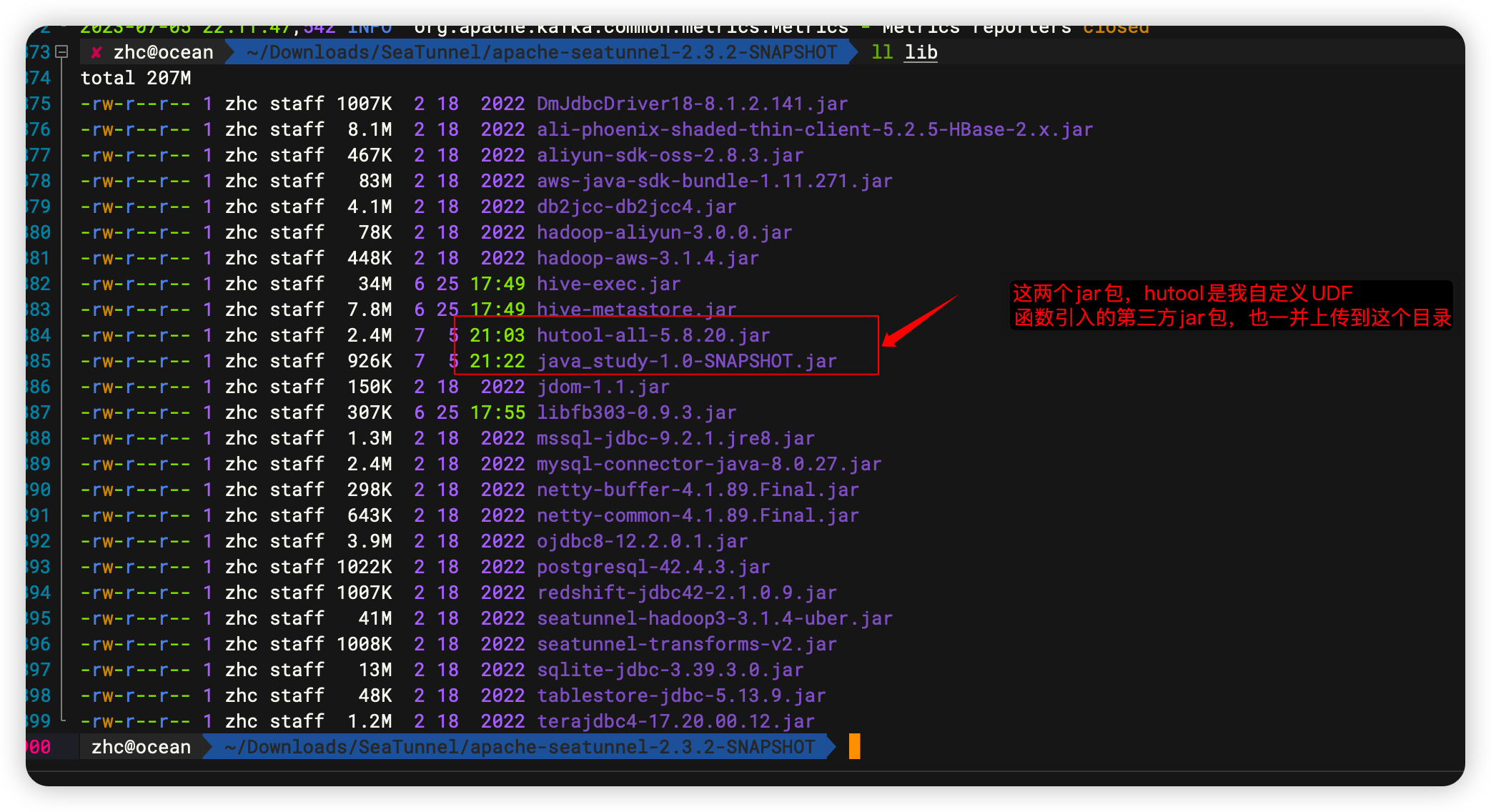
說明:這個hutool-all的jar包可以含在java_study這個項目裡面,我圖方便,上傳了兩個。
綜上,推薦使用通過UDF函數擴展的方式,實現嵌套kafka source json源數據的解析。
本文由 白鯨開源 提供發佈支持!


