
這篇技術博客探討了為什麼不推薦在頭文件中直接定義函數。它解釋了在將函數定義放在頭文件中的潛在問題,並提供了更好的替代方案。通過避免在頭文件中定義函數,讀者可以更好地管理代碼的複雜性,並提高代碼的可讀性和可維護性 ...
為什麼不推薦在頭文件中直接定義函數?
1. 函數的分文件編寫
在C++中,函數的分文件編寫是一種讓代碼結構更加清晰的方法,通常可以分為以下幾個步驟:
- 創建尾碼名為
.h的頭文件,在頭文件中寫函數的聲明,以及可能用到的其他頭文件或命名空間 - 創建尾碼名為
.cpp的源文件,在源文件中寫函數的定義,同時引入自定義頭文件,將頭文件與源文件綁定 - 在需要使用函數的地方,引入自定義頭文件,然後直接調用函數,無需再寫函數的實現
例如,如果要編寫一個求兩個數最大值的函數,可以這樣做:
- 創建一個
max.h頭文件,在其中寫入以下內容:
#pragma once // 防止頭文件重覆包含
#include <iostream> // 引入輸入輸出流頭文件
using namespace std; // 使用標準命名空間
// 函數聲明
int max(int a, int b);
- 創建一個
max.cpp源文件,在其中寫入以下內容:
#include "max.h" // 引入自定義頭文件
// 函數定義
int max(int a, int b) {
return a > b ? a : b; // 三目運算符,返回最大值
}
- 在需要使用函數的地方,例如
main.cpp文件中,引入自定義頭文件,並調用函數:
#include "max.h" // 引入自定義頭文件
int main() {
int a = 10;
int b = 20;
cout << "The max of " << a << " and " << b << " is " << max(a, b) << endl; // 調用函數並輸出結果
system("pause"); // 暫停程式
return 0;
}
文件結構如圖所示:
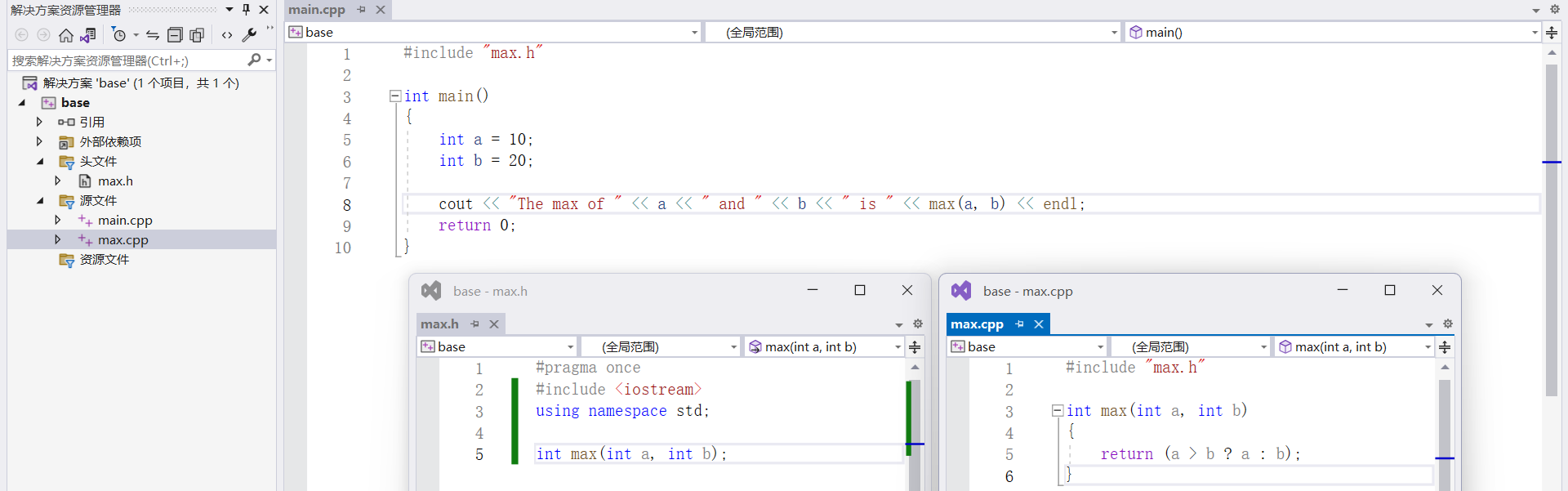
2. 頭文件中不推薦直接定義函數
在頭文件中直接寫函數的定義是不推薦的,有以下幾個原因:
- 在頭文件中寫函數的定義會導致重覆定義的錯誤,如果這個頭文件被多個源文件包含。因為每個源文件都會把頭文件的內容複製過來,相當於在多個地方定義了同一個函數,這違反了單定義原則
- 在頭文件中寫函數的定義會增加編譯的時間,如果這個頭文件被頻繁修改。因為每次修改頭文件後,所有包含這個頭文件的源文件都需要重新編譯,這對於大型項目來說非常耗時
- 在頭文件中寫函數的定義會降低代碼的可讀性和可維護性,如果這個頭文件包含了很多函數的定義。因為頭文件的主要作用是提供函數的聲明和介面,而不是實現細節。把函數的定義放在源文件中,可以讓代碼結構更清晰,也便於隱藏實現細節和保護數據
2.1 單定義原則
在頭文件中寫函數的定義會導致重覆定義的錯誤,如果這個頭文件被多個源文件包含。比如,假設有一個頭文件 max.h,其中定義了一個求兩個數最大值的函數:
// max.h
#pragma once
#include <iostream>
using namespace std;
int max(int a, int b) {
return a > b ? a : b;
}
然後,有兩個源文件 main1.cpp 和 main2.cpp,都包含了這個頭文件,並且都調用了這個函數:
// main1.cpp
#include "max.h"
int foo() {
cout << "The max of 10 and 20 is " << max(10, 20) << endl;
return 0;
}
// main2.cpp
#include "max.h"
int main() {
cout << "The max of 30 and 40 is " << max(30, 40) << endl;
return 0;
}
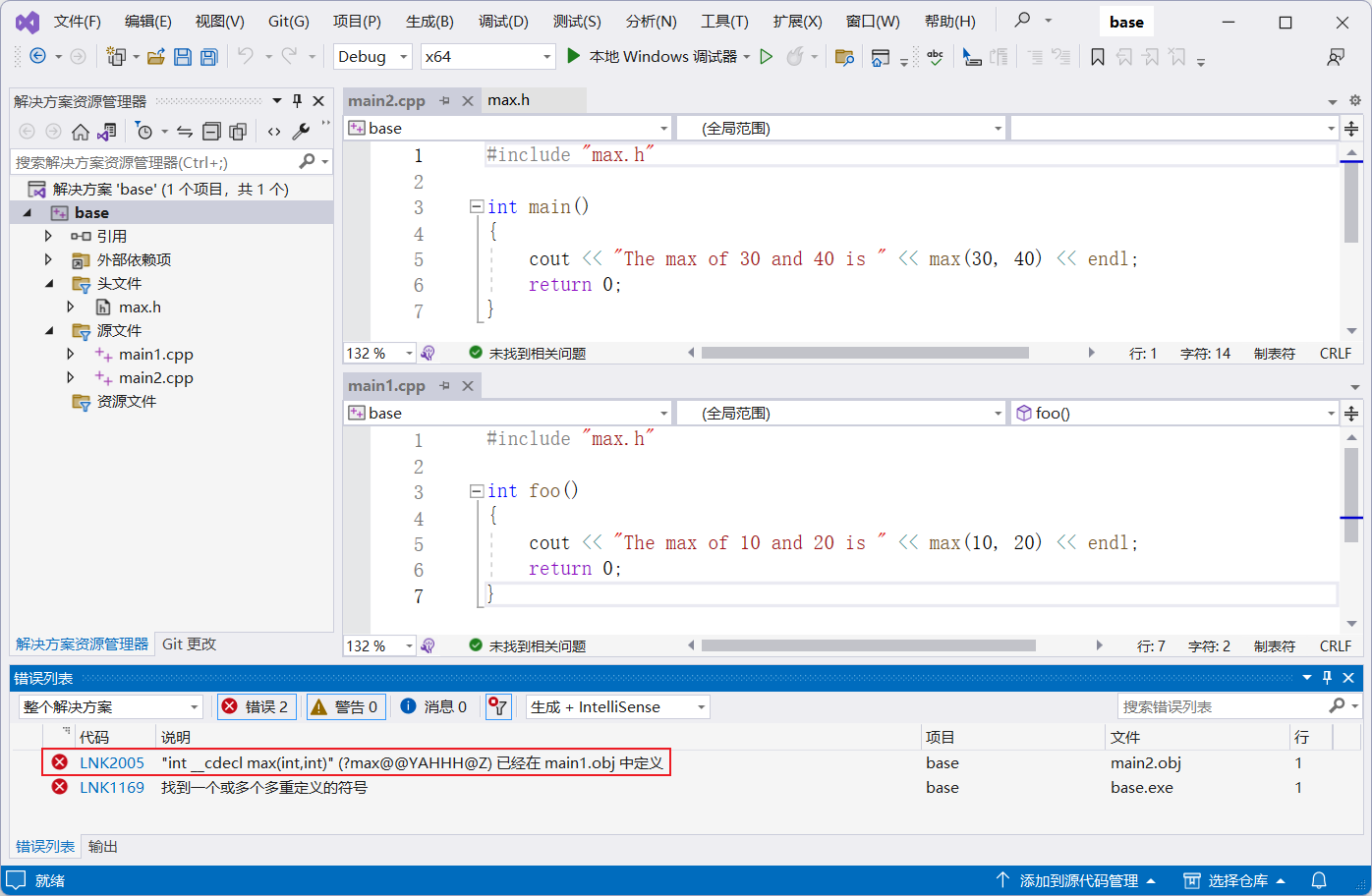
看到這裡可能會有個疑問,編譯的時候
main1.cpp調用max.h中的函數,但是main2.cpp中的主函數中沒有調用main1.cpp中的函數,為什麼還是會編譯不通過呢?兩個不同的文件定義同一個函數也會衝突嗎?即使其中一個文件和另一個文件沒有任何關係?
編譯時,每個源文件會生成一個目標文件,然後鏈接生成可執行文件。即使 main2.cpp 沒有調用 main1.cpp 的函數,但 main1.cpp 中包含了 max.h,相當於在 main1.cpp 中定義了max函數,與 main2.cpp 中的max函數衝突。當鏈接時,如果出現同名的函數,就會出現重覆定義的錯誤。因此,每個函數應該只在一個源文件中定義,或者使用命名空間或靜態修飾符來避免衝突
為瞭解決這個問題,我們應該把函數的定義放在另一個源文件 max.cpp 中,然後在頭文件中只聲明函數:
// max.h
#pragma once
#include <iostream>
using namespace std;
int max(int a, int b); // 函數聲明
// max.cpp
#include "max.h"
int max(int a, int b) { // 函數定義
return a > b ? a : b;
}
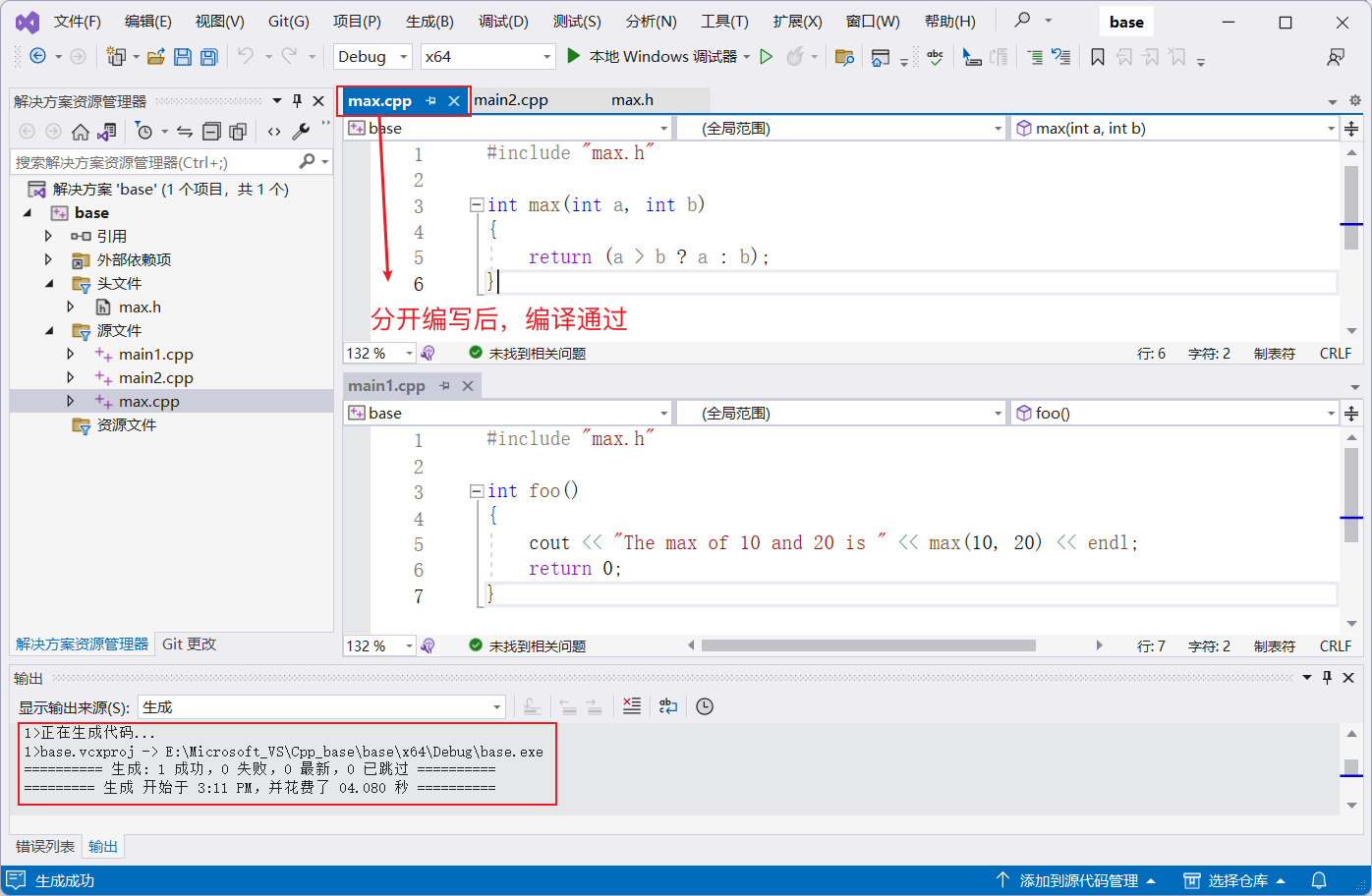
這樣就可以避免重覆定義的錯誤了
2.2 減少編譯時間
在頭文件中寫函數的定義會增加編譯的時間,如果這個頭文件被頻繁修改。比如,假設有一個頭文件 math.h,其中定義了一些數學相關的函數:
// math.h
double sin(double x) {
// some code to calculate sin(x)
}
double cos(double x) {
// some code to calculate cos(x)
}
double tan(double x) {
// some code to calculate tan(x)
}
然後,有很多源文件都包含了這個頭文件,並且都調用了這些函數。如果我們想要修改或添加某個函數的實現細節,比如改進 sin 函數的演算法,那麼我們就需要修改頭文件 math.h。但是這樣一來,所有包含了這個頭文件的源文件都需要重新編譯,因為它們都依賴於頭文件的內容。這對於大型項目來說非常耗時。為瞭解決這個問題,我們應該把函數的定義放在另一個源文件 math.cpp 中,然後在頭文件中只聲明函數:
// math.h
double sin(double x); // 函數聲明
double cos(double x); // 函數聲明
double tan(double x); // 函數聲明
// math.cpp
#include "math.h"
double sin(double x) { // 函數定義
// some code to calculate sin(x)
}
double cos(double x) { // 函數定義
// some code to calculate cos(x)
}
double tan(double x) { // 函數定義
// some code to calculate tan(x)
}
這樣就可以減少編譯的時間了,因為只有修改或添加了函數的源文件才需要重新編譯
簡單來說,分為兩種情況
第一種:在頭文件中定義函數。如果有很多源文件都引用了這個頭文件,那麼當頭文件修改後,所有引用頭文件的源文件都要重新編譯,對於大型項目非常耗時
第二種:把函數的定義和聲明放在不同的文件中。這樣做可以使得當源文件中定義的函數發生修改時,只需要重新編譯被修改的源文件就可以了,不需要所有引用這個頭文件的源文件重新編譯,節省了非常多的時間
為什麼在頭文件中定義的函數發生改變時,所有包含該頭文件的源文件需要重新編譯?
還是借用以上的例子,我的猜想是這樣的
假如在 main.cpp 源文件中引用 math.h 頭文件,相當於把頭文件中的內容複製到了源文件里
那麼如果 math.h 頭文件中定義函數,並且 main.cpp 源文件中引用了 math.h 頭文件,則相當於把 math.h 中的定義的函數複製到 main.cpp 源文件里,一旦頭文件中的函數發生改變,那麼就相當於源文件發生了改變
因此所有包含 math.h 頭文件的源文件都需要重新編譯
此外,多個源文件包含同一個定義函數的頭文件,會導致重定義的錯誤。這裡只是舉個例子假設編譯器允許這樣的操作,實際上編譯不會通過
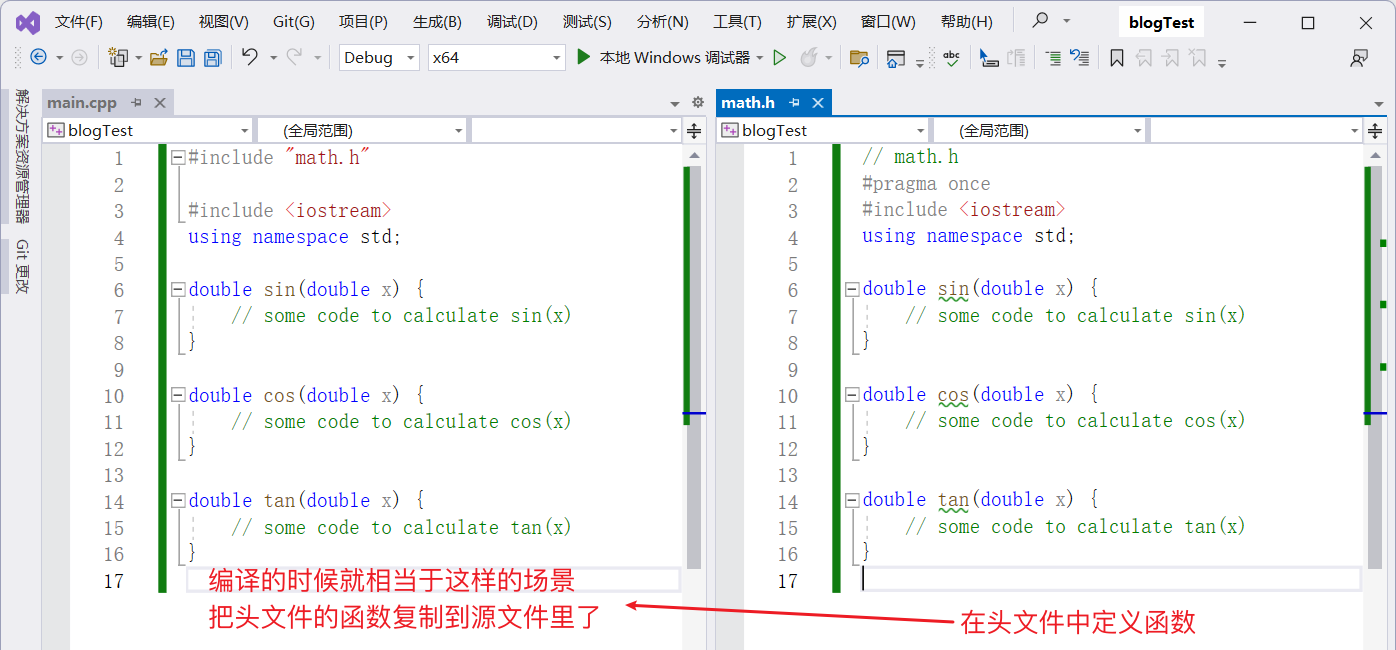
調用函數時的索引順序:
在源文件中調用函數的時候,是先到頭文件里找聲明的函數,然後再通過鏈接的過程找到對應的源文件里的函數
如下圖所示,main.cpp 調用函數時,先到 math.h 中找到聲明的函數,然後再通過鏈接的過程找到對應的源文件 math.cpp 里的函數
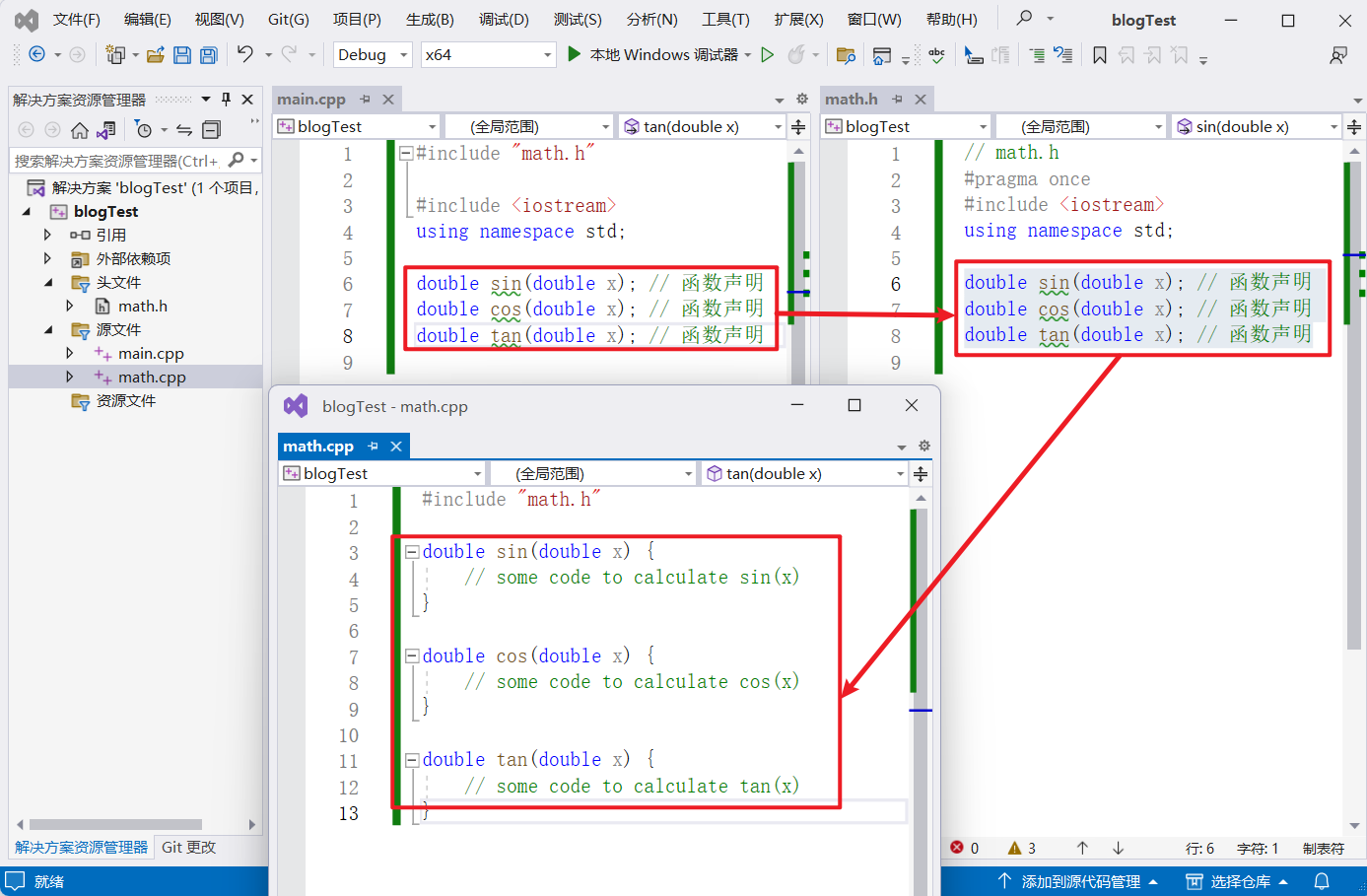
這個過程可以看作是查字典,頭文件相當於目錄,對應著每個函數所在的位置
2.3 可讀性與安全性
在頭文件中寫函數的定義會降低代碼的可讀性和可維護性,如果這個頭文件包含了很多函數的定義。比如,假設有一個頭文件 utils.h,其中定義了一些工具類的函數:
// utils.h
#include <string>
#include <vector>
using namespace std;
string trim(string s) {
// some code to trim the whitespace of s
}
vector<string> split(string s, char delim) {
// some code to split s by delim
}
string join(vector<string> v, char delim) {
// some code to join v by delim
}
bool is_number(string s) {
// some code to check if s is a number
}
int to_int(string s) {
// some code to convert s to int
}
string to_string(int x) {
// some code to convert x to string
}
這個頭文件包含了很多函數的定義,這會讓代碼看起來很冗長,也不容易找到想要的函數。而且,如果我們想要修改或添加某個函數的實現細節,比如改進 trim 函數的效率,那麼我們就需要修改頭文件 utils.h。但是這樣會影響到所有包含了這個頭文件的源文件,也會增加代碼的複雜度和出錯的風險。為瞭解決這個問題,我們應該把函數的定義放在另一個源文件 utils.cpp 中,然後在頭文件中只聲明函數:
// utils.h
#include <string>
#include <vector>
using namespace std;
string trim(string s); // 函數聲明
vector<string> split(string s, char delim); // 函數聲明
string join(vector<string> v, char delim); // 函數聲明
bool is_number(string s); // 函數聲明
int to_int(string s); // 函數聲明
string to_string(int x); // 函數聲明
// utils.cpp
#include "utils.h"
string trim(string s) {
// some code to trim the whitespace of s
}
vector<string> split(string s, char delim) {
// some code to split s by delim
}
string join(vector<string> v, char delim) {
// some code to join v by delim
}
bool is_number(string s) {
// some code to check if s is a number
}
int to_int(string s) {
// some code to convert s to int
}
string to_string(int x) {
// some code to convert x to string
}

