
[toc] # 一、爬取目標 您好,我是[@馬哥python說](https://www.zhihu.com/people/13273183132),一名10年程式猿。 本次爬取的目標是:[百度熱搜榜](https://top.baidu.com/board?tab=realtime) 
分別爬取每條熱搜的:
熱搜標題、熱搜排名、熱搜指數、描述、鏈接地址。
下麵,對頁面進行分析。
經過分析,此頁面有XHR鏈接,可以針對介面進行爬取。
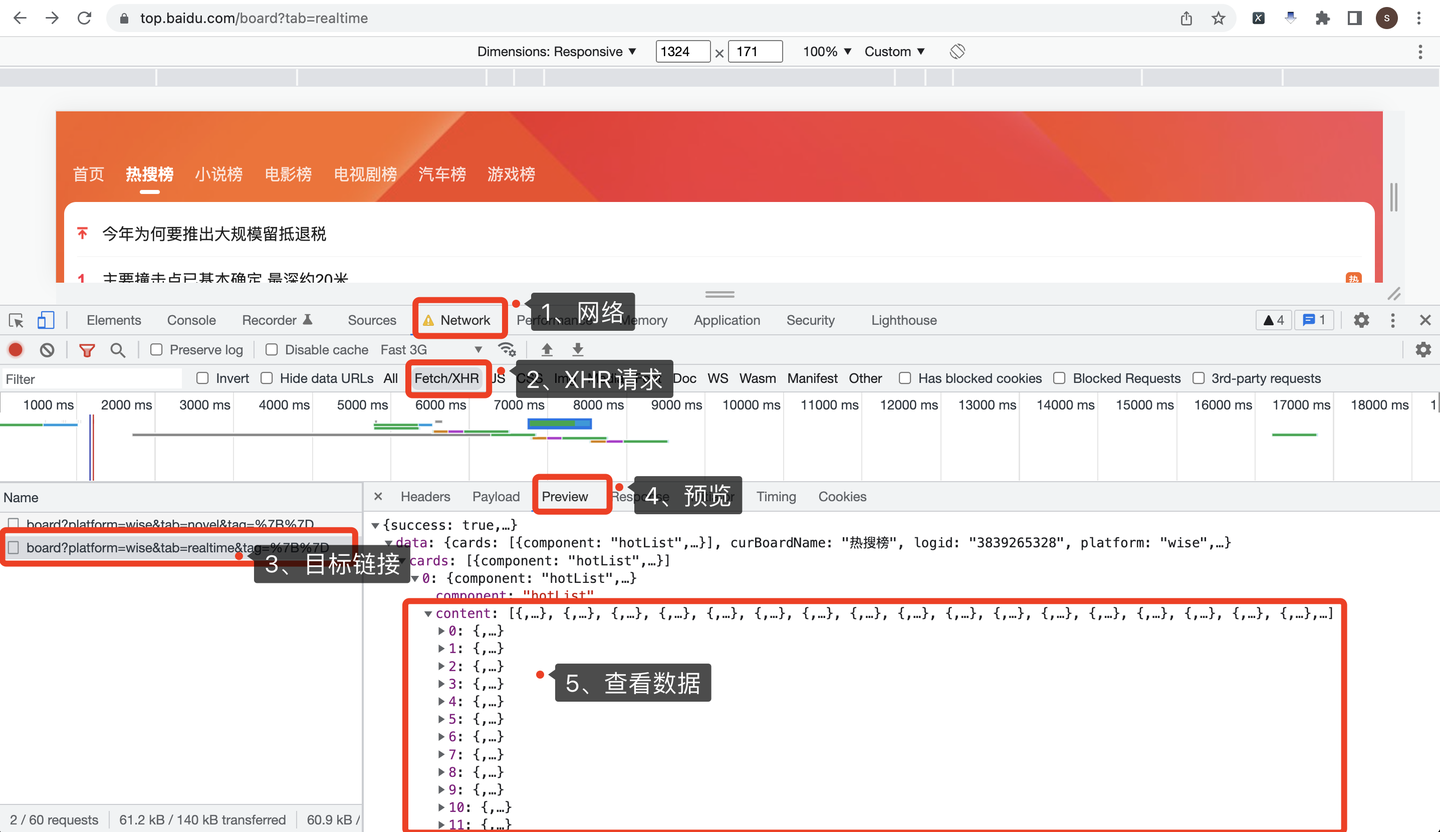
打開Chrome瀏覽器,按F12進入開發者模式,依次點擊:
- 點擊Network,選擇網路
- 點擊XHR,選擇XHR請求
- 選擇目標鏈接地址
- 擊Preview,選擇預覽
- 查看返回數據
操作過程,如下圖所示:
二、編寫爬蟲代碼
首先,導入需要用到的庫:
import requests # 發送請求
import pandas as pd # 存入excel數據
定義一個百度熱搜榜介面地址:
# 百度熱搜榜地址
url = 'https://top.baidu.com/api/board?platform=wise&tab=realtime'
構造一個請求頭,偽裝爬蟲:
# 構造請求頭
header = {
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Mobile Safari/537.36',
'Host': 'top.baidu.com',
'Accept': 'application/json, text/plain, */*',
'Accept-Language': 'zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7',
'Accept-Encoding': 'gzip, deflate, br',
'Referer': 'https://top.baidu.com/board?tab=novel',
}
向百度頁面發送requests請求:
# 發送請求
r = requests.get(url, header)
返回的數據是json格式的,直接用r.json()接收:
# 用json格式接收請求數據
json_data = r.json()
這裡,需要註意的是,頁面上有2種熱搜:
百度熱搜榜最上面一條是置頂熱搜,下麵從1到30是普通熱搜,介面返回的數據也是區分開的:
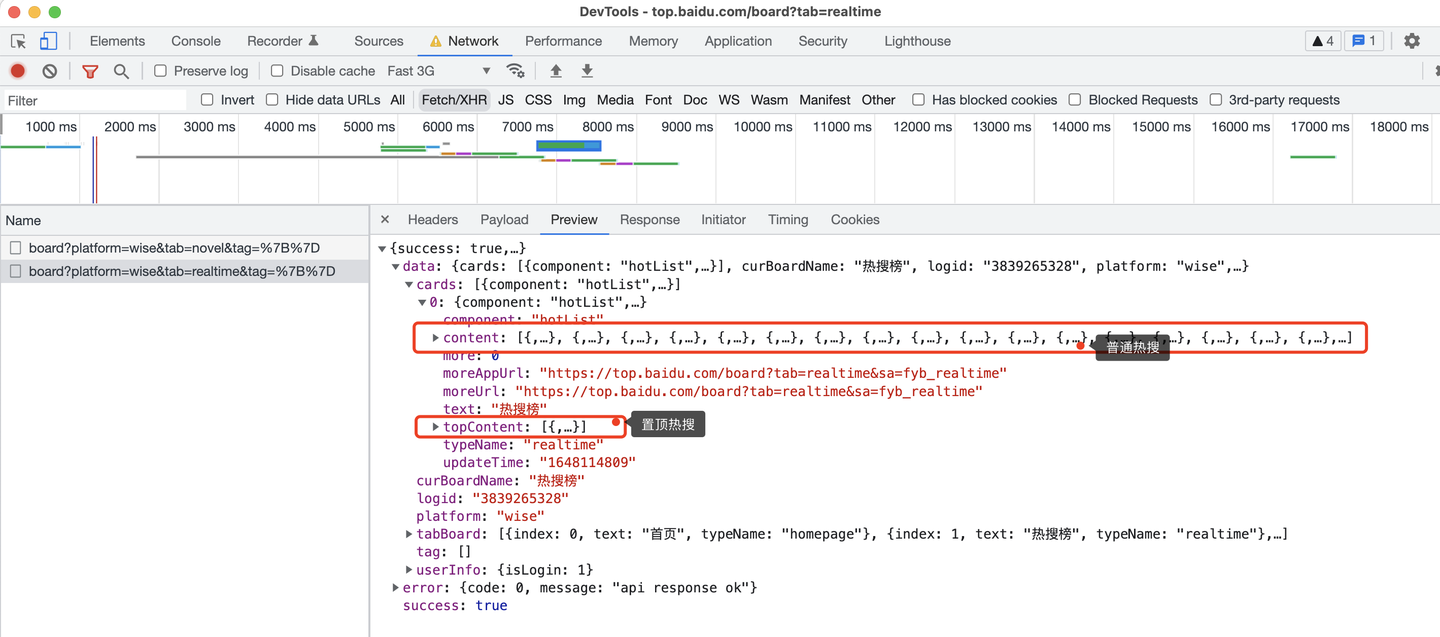
所以,爬蟲代碼需要分開處理邏輯:
置頂熱搜:
# 爬取置頂熱搜
top_content_list = json_data['data']['cards'][0]['topContent']
普通熱搜:
# 爬取普通熱搜
content_list = json_data['data']['cards'][0]['content']
然後再分別進行json解析,對應的欄位(標題、排名、熱搜指數、描述、鏈接地址)。
最後,保存結果數據到excel即可。
df = pd.DataFrame( # 拼裝爬取到的數據為DataFrame
{
'熱搜標題': title_list,
'熱搜排名': order_list,
'熱搜指數': score_list,
'描述': desc_list,
'鏈接地址': url_list
}
)
df.to_excel('百度熱搜榜.xlsx', index=False) # 保存結果數據
最後,查看一下爬取到的數據:

一共31條數據(1條置頂熱搜+30條普通熱搜)。
每條數據包含:熱搜標題、熱搜排名、熱搜指數、描述、鏈接地址。
三、同步視頻講解
講解視頻:https://www.zhihu.com/zvideo/1490668062617161728
四、完整源碼
get完整源碼:【爬蟲案例】用Python爬取百度熱搜榜數據!
我是@馬哥python說,持續分享python源碼乾貨中!

