### 1.進程 進程是一個具有一定獨立功能的程式在一個數據集上的一次動態執行的過程,是操作系統進行資源分配和調度的一個獨立單位,是應用程式運行的載體。進程是一種抽象的概念,從來沒有統一的標准定義。進程一般由程式、數據集合和進程式控制制塊三部分組成。程式用於描述進程要完成的功能,是控制進程執行的指令集; ...
1.進程
進程是一個具有一定獨立功能的程式在一個數據集上的一次動態執行的過程,是操作系統進行資源分配和調度的一個獨立單位,是應用程式運行的載體。進程是一種抽象的概念,從來沒有統一的標准定義。進程一般由程式、數據集合和進程式控制制塊三部分組成。程式用於描述進程要完成的功能,是控制進程執行的指令集;數據集合是程式在執行時所需要的數據和工作區;程式控制塊包含進程的描述信息和控制信息是進程存在的唯一標誌。
進程具有的特征:
- 動態性:進程是程式的一次執行過程,是臨時的,有生命期的,是動態產生,動態消亡的。
- 併發性:任何進程都可以同其他進程一起併發執行。
- 獨立性:進程是系統進行資源分配和調度的一個獨立單位。
- 結構性:進程由程式、數據和進程式控制制塊三部分組成。
實現多進程
import multiprocessing
import time
def run1(sleep_time):
while True:
print("-- 1 --")
time.sleep(sleep_time)
def run2(sleep_time):
while True:
print("-- 2 --")
time.sleep(sleep_time)
def main():
# 創建進程對象。
# target:指定線程調用的函數名。註:等號後跟方法名不能加括弧,如果加了也能執行函數但threading功能無效
# args:指定調用函數時傳遞的參數。註:args是一個數組變數參數,只傳一個參數時,需要在參數後面添加逗號
p1 = multiprocessing.Process(target=run1, args=(1,))
p2 = multiprocessing.Process(target=run2, args=(1,))
# 啟用子進程
p1.start()
p2.start()
# join方法等待子進程執行結束
p1.join()
p2.join()
print("子進程結束")
if __name__ == "__main__":
main()
運行上面代碼,查看任務管理器python的啟動進程數。

代碼中只啟動了兩個子進程,但是為什麼有3個python進程?這是因為,python會創建一個主進程(第1個進程),當運行到p1.start()時會創建一個子進程(第2個進程),當運行到p2.start()時又會創建一個子進程(第3個進程)
2.進程池
進程的創建和刪除是需要消耗電腦資源的,如果有大量任務需要多進程完成,則可能需要頻繁的創建刪除進程,這會給電腦帶來較多的資源消耗。進程池的出現解決了這個問題,它的原理是創建適當的進程放入進程池,等待待處理的事件,當處理完事件後進程不會銷毀,仍然在進程池中等待處理其他事件,直到事件全部處理完畢,進程退出。 進程的復用降低了資源的消耗。
實現進程池
import time, os
from multiprocessing import Pool
def worker(msg):
start_time = time.time()
print(F"{msg}開始執行,進程pid為{os.getpid()}")
time.sleep(1)
end_time = time.time()
print(F"{msg}執行完畢,耗時{end_time - start_time}")
def main():
po = Pool(3) # 定義進程池最大進程數為3
for i in range(10):
# 每次迴圈會用空閑出的子進程調用目標
po.apply_async(worker, args=(i,)) # 若調用的函數報錯,進程池中不會列印報錯信息
po.close() # 關閉進程池,關閉後,不再接收新的目標
po.join() # 等待進程池中所有子進程執行完,必須放在close()之後。若沒有join()操作,主進程執行完後直接關閉
print("--end--")
if __name__ == "__main__":
main()
3.線程
在早期的操作系統中並沒有線程的概念,進程是擁有資源和獨立運行的最小單位,也是程式執行的最小單位。任務調度採用的是時間片輪轉的搶占式調度方式,而進程是任務調度的最小單位,每個進程有各自獨立的一塊記憶體,使得各個進程之間記憶體地址相互隔離。後來,隨著電腦的發展,對CPU的要求越來越高,進程之間的切換開銷較大,已經無法滿足越來越複雜的程式的要求了。於是就發明瞭線程,線程是程式執行中一個單一的順序控制流程,是程式執行流的最小單元,是處理器調度和分派的基本單位。一個進程可以有一個或多個線程,各個線程之間共用程式的記憶體空間(也就是所在進程的記憶體空間)。一個標準的線程由線程ID,當前指令指針PC,寄存器和堆棧組成。而進程由記憶體空間(代碼,數據,進程空間,打開的文件)和一個或多個線程組成。
實現多線程
import time
import threading
def say(sleep_time):
for i in range(5):
print(f"說{i+1}下")
time.sleep(sleep_time)
def dance():
for i in range(10):
print(f"跳{i+1}下")
time.sleep(1)
def main():
# 創建線程對象
# target:指定線程調用的函數名。註:等號後跟方法名不能加括弧,如果加了也能執行函數但threading功能無效
# args:指定調用函數時傳遞的參數。註:args是一個數組變數參數,只傳一個參數時,需要在參數後面添加逗號
t1 = threading.Thread(target=say, args=(1,))
t2 = threading.Thread(target=dance)
# 啟動線程
t1.start()
t2.start()
# 查看正在運行的線程
while True:
now_threading = threading.enumerate()
print(now_threading)
# 當子線程全部運行結束後,僅剩1個主線程
if len(now_threading) <= 1:
break
time.sleep(1)
if __name__ == "__main__":
main()
多線程的資源競爭問題
因為多線程共用全局變數,當線程還沒執行完當前任務,操作系統就自動輪流調度執行其他任務,就可能會產生資源競爭的問題。
比如下例中,執行 g_num+=1 時,會將其分成3步執行:1.取值;2.運算;3.保存運算結果,在CPU執行任務時,若剛運行1 2 步就交替執行下一個任務,再返回來保存結果,因為共用全局變數,此時運算結果可能已被重新賦值。
import time
import threading
g_num = 0
def sum1(num):
global g_num
for i in range(num):
g_num += 1
print(F"sum1:{g_num}")
def sum2(num):
global g_num
for i in range(num):
g_num += 1
print(F"sum2:{g_num}")
def main():
t1 = threading.Thread(target=sum1, args=(1000000,))
t2 = threading.Thread(target=sum2, args=(1000000,))
t1.start()
t2.start()
time.sleep(2)
print(g_num) # 執行後,預期結果為2000000;實際不是
if __name__ == "__main__":
main()
執行結果
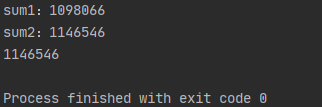
從結果可以看出,sum1和sum2不為1000000,總和不為2000000,這就是上面說的資源競爭問題
互斥鎖解決資源競爭問題
import threading
import time
# 定義一個全局變數
g_num = 0
# 創建一個互斥鎖,預設是沒有上鎖的
mutex = threading.Lock()
def sum1(num):
global g_num
# mutex.acquire() # 若在此處上鎖,要等下麵迴圈執行完才會解鎖,若迴圈時間太長,會導致另外的線程堵塞等待。
for i in range(num):
# 上鎖,如果之前沒有被上鎖,那麼此時上鎖成功。 上鎖原則:一般對產生資源競爭的代碼上鎖。如果上鎖之前 已經被上鎖了,那麼此時會堵塞在這裡,直到 這個鎖被解開為止。
mutex.acquire()
g_num += 1
# 解鎖
mutex.release()
print("-----in test1 g_num=%d----" % g_num)
def sum2(num):
global g_num
for i in range(num):
mutex.acquire()
g_num += 1
mutex.release()
print("-----in test2 g_num=%d=----" % g_num)
def main():
t1 = threading.Thread(target=sum1, args=(1000000,))
t2 = threading.Thread(target=sum2, args=(1000000,))
t1.start()
t2.start()
# 等待上面的2個線程執行完畢....
time.sleep(2)
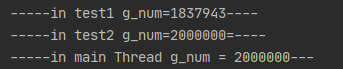
print("-----in main Thread g_num = %d---" % g_num)
if __name__ == "__main__":
main()
運行結果
死鎖
線上程間共用多個資源的時候,如果兩個線程分別占用部分資源並且同時等待對方的資源,就會造成死鎖。儘管死鎖很少發生,但一旦發生就會造成應用停止響應。下麵看一個死鎖例子。
import time
import threading
# 創建多個鎖
mutexA = threading.Lock()
mutexB = threading.Lock()
def print1():
mutexA.acquire()
time.sleep(2) # 等待B鎖穩定
print("列印A1")
mutexB.acquire()
print("列印B1")
mutexB.release()
mutexA.release()
def print2():
mutexB.acquire()
time.sleep(1) # 等待A鎖穩定
print("列印B2")
mutexA.acquire()
print("列印A2")
mutexA.release()
mutexB.release()
def main():
t1 = threading.Thread(target=print1)
t2 = threading.Thread(target=print2)
t1.start()
t2.start()
if __name__ == "__main__":
main()
執行結果

避免死索辦法:1、添加超時時間;2、銀行家演算法(讓鎖按預期上鎖和解鎖)
4.協程
協程,又稱微線程。協程的作用是在執行函數A時可以隨時中斷去執行函數B,然後中斷函數B繼續執行函數A(可以自由切換)。但這一過程並不是函數調用,這一整個過程看似像多線程,然而協程只有一個線程執行。
協程的優勢:
- 執行效率極高,因為子程式切換(函數)不是線程切換,由程式自身控制,沒有切換線程的開銷。所以與多線程相比,線程的數量越多,協程性能的優勢越明顯。
- 不需要多線程的鎖機制,因為只有一個線程,也不存在同時寫變數衝突,在控制共用資源時也不需要加鎖,因此執行效率高很多。
gevent
gevent是第三方庫,通過 greenlet 實現 coroutine,創建、調度的開銷比 線程(thread) 還小,因此程式內部的 執行流 效率高。
其基本思想是:當一個greenlet遇到IO操作時,比如訪問網路,就自動切換到其他的greenlet,等到IO操作完成,再在適當的時候切換回來繼續執行。由於IO操作非常耗時,經常使程式處於等待狀態,有了gevent為我們自動切換協程,就保證總有greenlet在運行,而不是等待IO。
gevent常用方法:
- gevent.spawn() 創建一個普通的Greenlet對象並切換
- gevent.spawn_later(seconds=3) 延時創建一個普通的Greenlet對象並切換
- gevent.spawn_raw() 創建的協程對象屬於一個組
- gevent.getcurrent() 返回當前正在執行的greenlet
- gevent.joinall(jobs) 將協程任務添加到事件迴圈,接收一個任務列表
- gevent.wait() 可以替代join函數等待迴圈結束,也可以傳入協程對象列表
- gevent.kill() 殺死一個協程
- gevent.killall() 殺死一個協程列表裡的所有協程
- monkey.patch_all() 非常重要,會自動將python的一些標準模塊替換成gevent框架
import gevent
def task(n):
for i in range(n):
print(gevent.getcurrent(), i)
if __name__ == '__main__':
g1 = gevent.spawn(task, 3)
g2 = gevent.spawn(task, 3)
g3 = gevent.spawn(task, 3)
g1.join()
g2.join()
g3.join()
運行結果
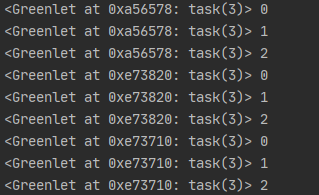
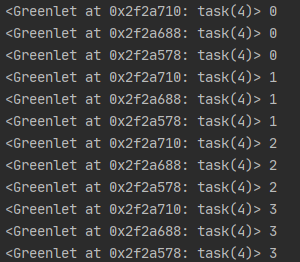
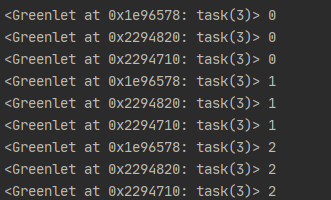
可以看到3個greenlet是依次運行而不是交替運行。要讓greenlet交替運行,可以通過gevent.sleep()交出控制權:
import gevent
def task(n):
for i in range(n):
print(gevent.getcurrent(), i)
gevent.sleep(1)
if __name__ == '__main__':
g1 = gevent.spawn(task, 3)
g2 = gevent.spawn(task, 3)
g3 = gevent.spawn(task, 3)
g1.join()
g2.join()
g3.join()
運行結果
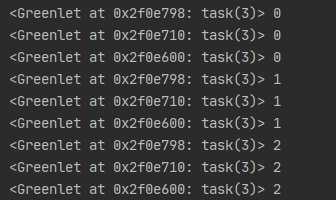
當然在實際的代碼里,我們不會用gevent.sleep()去切換協程,而是在執行到IO操作時gevent會自動完成,所以gevent需要將Python自帶的一些標準庫的運行方式由阻塞式調用變為協作式運行。這一過程在啟動時通過monkey patch完成:
import time
import gevent
from gevent import monkey
# 猴子補丁,會自動將python的一些標準模塊替換成gevent框架。慎用,它創造了“隱式的副作用”,如果出現問題 它很多時候是極難調試的。
monkey.patch_all() # 註意:若導出的模塊函數不會被替換,比如from time import sleep,sleep不會被替換
def task(n):
for i in range(n):
print(gevent.getcurrent(), i)
time.sleep(1) # 會被gevent自動替換為gevent.sleep()
if __name__ == '__main__':
g1 = gevent.spawn(task, 3)
g2 = gevent.spawn(task, 3)
g3 = gevent.spawn(task, 3)
g1.join()
g2.join()
g3.join()
執行結果
上面的流程看起來比較繁瑣,可以使用 gevent.joinall() 方法簡化流程:
import time
import gevent
from gevent import monkey
# 猴子補丁,會自動將python的一些標準模塊替換成gevent框架。慎用,它創造了“隱式的副作用”,如果出現問題 它很多時候是極難調試的。
monkey.patch_all() # 註意:若導出的模塊函數不會被替換,比如from time import sleep,sleep不會被替換
'''
學習中遇到問題沒人解答?小編創建了一個Python學習交流群:711312441
尋找有志同道合的小伙伴,互幫互助,群里還有不錯的視頻學習教程和PDF電子書!
'''
def task(n):
for i in range(n):
print(gevent.getcurrent(), i)
time.sleep(1) # 會被gevent自動替換為gevent.sleep()
if __name__ == '__main__':
gevent.joinall([
gevent.spawn(task, 4),
gevent.spawn(task, 4),
gevent.spawn(task, 4),
])
執行結果