
**往期系列回顧** - [圖文結合系列之帶你搞懂MySQL日誌系列](http://mp.weixin.qq.com/s?__biz=MzkzMTIzMDgwMg==&mid=2247496981&idx=1&sn=ec496da6e52e19ee505483a15fb54f6b&chksm=c2 ...
往期系列回顧
很多小伙伴使用了GreatSQL,但是對GreatSQL的底層原理還不是很瞭解,今天就帶大家一起揭開GreatSQL體系架構的神秘面紗!
首先來回顧一張經典的體系架構圖:
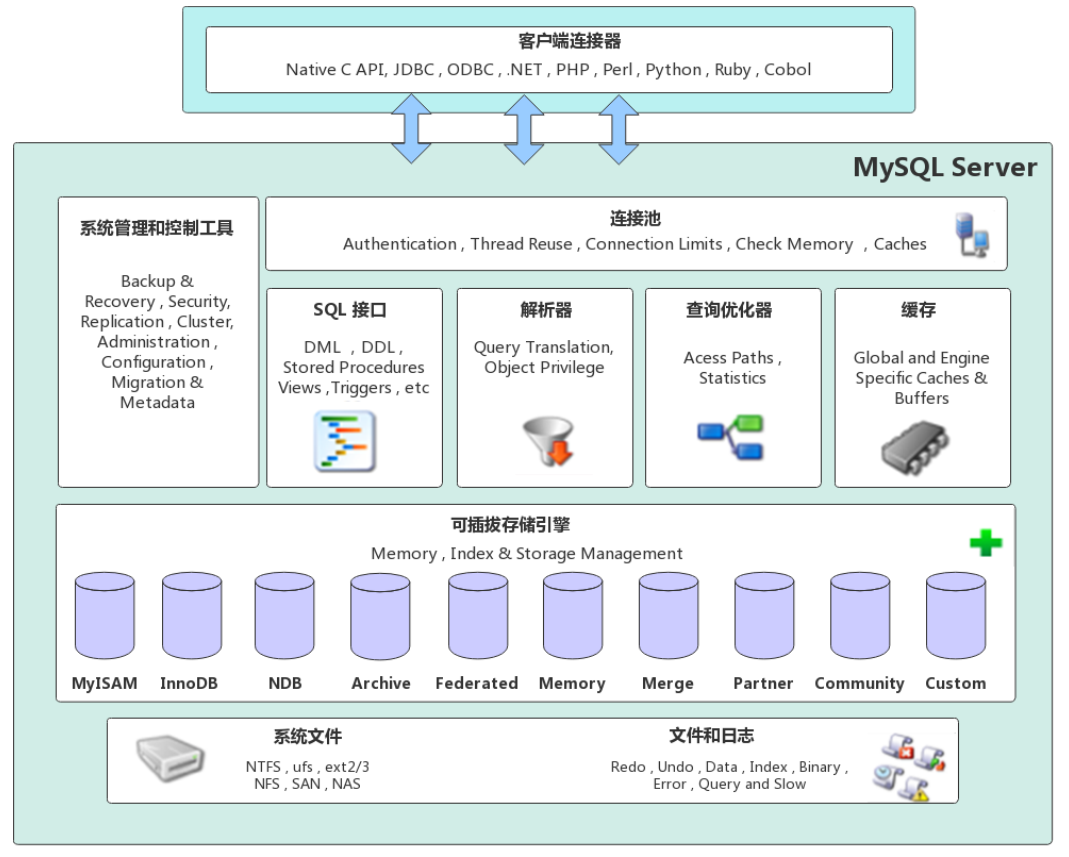
圖1_GreatSQL5.7 版本體系架構圖
由此可以發現,GreatSQL5.7 由以下幾部分組成
- 連接池組件
- 系統管理和控制工具
- SQL介面組件
- 查詢解析器
- 查詢優化器
- 緩存組件
- 可插拔存儲引擎
- 系統和日誌文件
GreatSQL資料庫區別於其他資料庫的一個特點就是其可插拔的表存儲引擎,特別需要註意的是,存儲引擎是基於表的,而不是資料庫。
然而,經典同時也意味著這幅圖已經相當陳舊了。在GreatSQL8.0 及更高版本中,查詢緩存這一功能已經被移除。
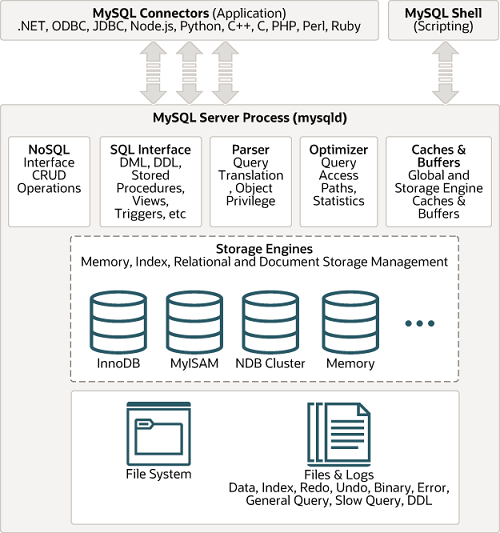 圖2_GreatSQL8.0 版本體系架構圖
圖2_GreatSQL8.0 版本體系架構圖
總體來說,GreatSQL8.0 可以分為連接層、服務層、存儲引擎層。
一、連接層(Client Connectors)
連接層又名為客戶端連接器(Client Connectors)作用是提供與GreatSQL伺服器建立的支持。
客戶端通過TCP/IP協議與GreatSQL伺服器建立連接,每個連接對應一個線程。連接管理還包括了連接池技術,以復用已經建立好的連接,減少重覆建立連接的開銷。
而且幾乎支持所有主流的服務端編程技術,主要完成一些類似於連接處理、授權認證、及相關的安全方案。
會對從 TCP 傳輸過來的賬號密碼做身份認證、許可權獲取
- 用戶名或密碼不對,會收到
Access denied for user錯誤,客戶端程式結束執行
例如:
$ mysql -uroot -p
ERROR 1045 (28000): Access denied for user 'root'@'localhost' (using password: NO)
- 用戶名密碼認證通過,會從許可權表查出賬號擁有的許可權與連接關聯,之後的許可權判斷邏輯,都將依賴於此時讀到的許可權
二、服務層(GreatSQL Server)
服務層是GreatSQL Server的核心,主要包含連接器、分析器、優化器、執行器等,涵蓋 GreatSQL 的大多數核心服務功能,以及所有的內置函數(如日期、時間、數學和加密函數等),所有跨存儲引擎的功能都在這一層實現,比如存儲過程、觸發器、視圖等。
Ⅰ.SQL Interface: SQL介面
接收用戶的SQL命令,並且返回用戶需要查詢的結果。比如SELECT … FROM就是調用SQL Interface,GreatSQL支持DML、DDL、存儲過程、視圖、觸發器、自定義函數等多種SQL語言介面
同時還支持NoSQL,NoSQL泛指非關係型資料庫和數據存儲。隨著互聯網平臺的規模飛速發展,傳統的關係型資料庫已經越來越不能滿足需求。從5.6版本開始,GreatSQL就開始支持簡單的NoSQL存儲功能。GreatSQL8.0 版本對這一功能做了優化,以更靈活的方式實現NoSQL功能,不再依賴模式(schema)。
Ⅱ.Parser: 解析器
在解析器中對 SQL 語句進行語法分析、語義分析。將 SQL 語句分解成數據結構,並將這個結構傳遞到後續步驟,以後 SQL 語句的傳遞和處理就是基於這個結構的,並且判斷你輸入的這個 SQL 語句是否滿足 GreatSQL 語法。
Ⅲ.Optimizer: 查詢優化器
在開始執行之前,還要先經過優化器的處理。
SQL語句在語法解析之後、查詢之前會使用查詢優化器確定 SQL 語句的執行路徑,生成一個執行計劃,可以使用EXPLAIN命令查看執行計劃。
這個執行計劃表明應該使用哪些索引進行查詢(全表檢索還是使用索引檢索),表之間的連接順序如何,最後會按照執行計劃中的步驟調用存儲引擎提供的方法來真正的執行查詢,並將查詢結果返回給用戶。
例如下麵的 JOIN 語句:
SELECT * FROM tb1 JOIN tb2 USING(ID) WHERE tb1.a=1 and tb2.a=2;
那就有兩種方法可以選擇:
- 第一種,
先取表 tb1里 a=1 的記錄的ID值,再根據 ID 關聯表 tb2 ,然後再判斷 tb2 裡面 a 的值是否等於 2 - 第二種,
先取表 tb2裡面的 a=2 記錄的 ID 值,在根據 ID 值關聯 tb1 ,再判斷 tb1 裡面 a 的值是否等於 10
執行的結果肯定是一致的,但是效率就大不相同了,所以我們要選擇用小的數據集去驅動大的數據集,也就是小表驅動大表。
Ⅳ.Caches & Buffers:查詢緩存組件
GreatSQL 內部維持著一些 Cache 和 Buffer,比如 Query Cache 用來緩存一條 SELECT 語句的執行結果,如果能夠在其中找到對應的查詢結果,那麼就不必再進行查詢解析、優化和執行的整個過程了,直接將結果反饋給客戶端。
但是在 GreatSQL 8.0 版本及以上中刪除了查詢緩存功能,因為查詢緩存必須要兩條SQL語句完全一模一樣,否則是不能觸發查詢緩存,非常的雞肋~
三、引擎層(Storage Engines)
Ⅰ.存儲引擎層
真正的負責了 GreatSQL 中數據的存儲和提取,對物理伺服器級別維護的底層數據執行操作,伺服器通過API與存儲引擎進行通信。
存儲引擎的優勢在於,各式各樣的存儲引擎都具備獨特的特性,從而能夠針對特定的應用需求建立不同存儲引擎表。
GreatSQL 支持的存儲引擎如下:
greatsql> SHOW ENGINES;
+--------------------+---------+----------------------------------------------------------------------------+--------------+------+------------+
| Engine 引擎名稱 | Support 支持情況 | Comment 引擎的說明 | Transactions 事務支持 | XA 分散式事務支持 | Savepoints 保存點 |
+--------------------+---------+----------------------------------------------------------------------------+--------------+------+------------+
| FEDERATED | NO | Federated MySQL storage engine | NULL | NULL | NULL |
| PERFORMANCE_SCHEMA | YES | Performance Schema | NO | NO | NO |
| InnoDB | DEFAULT | Percona-XtraDB, Supports transactions, row-level locking, and foreign keys | YES | YES | YES |
| MEMORY | YES | Hash based, stored in memory, useful for temporary tables | NO | NO | NO |
| MyISAM | YES | MyISAM storage engine | NO | NO | NO |
| MRG_MYISAM | YES | Collection of identical MyISAM tables | NO | NO | NO |
| BLACKHOLE | YES | /dev/null storage engine (anything you write to it disappears) | NO | NO | NO |
| CSV | YES | CSV storage engine | NO | NO | NO |
| ARCHIVE | YES | Archive storage engine | NO | NO | NO |
+--------------------+---------+----------------------------------------------------------------------------+--------------+------+------------+
9 rows in set (0.00 sec)
得益於 GreatSQL 資料庫的開源特性,用戶得以依據存儲引擎介面自行編寫個性化的存儲引擎。當對某一種存儲引擎的性能或功能存有疑慮時,可通過優化代碼實現所需特性,這正展示了開源所賦予我們的便捷與力量。
Ⅱ.存儲層
所有的數據,資料庫、表的定義,表的每一行的內容,索引,都是存在 文件系統上,以文件的方式存在的,並完成與存儲引擎的交互。當然有些存儲引擎比如InnoDB,也支持不使用文件系統直接管理裸設備,但現代文件系統的實現使得這樣做沒有必要了。在文件系統之下,可以使用本地磁碟,可以使用DAS、NAS、SAN等各種存儲系統。
總結
所以可以把 GreatSQL 的架構圖簡化如下:
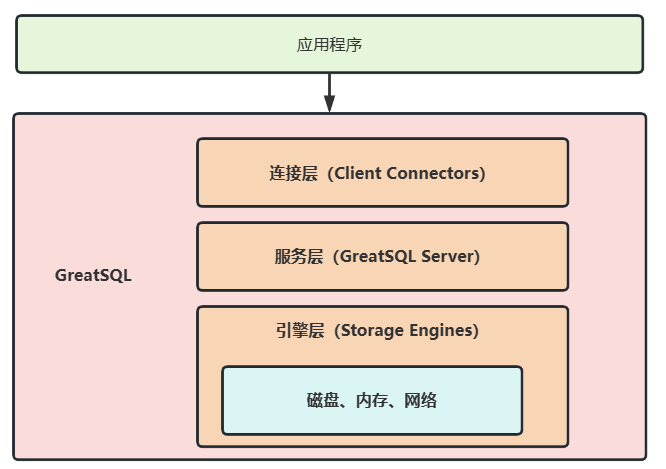
要把架構圖牢牢記住,對於以後深入理解 GreatSQL 資料庫會有極大幫助!
Enjoy GreatSQL


