
摘要:索引就是數據表中數據和相應的存儲位置的列表,利用索引可以提高在表或視圖中的查找數據的速度。 本文分享自華為雲社區《資料庫開髮指南(六)索引和視圖的使用技巧、方法與綜合應用》,作者: bluetata 。 一、索引 1.1 什麼是索引 索引就是數據表中數據和相應的存儲位置的列表,利用索引可以提高 ...
摘要:索引就是數據表中數據和相應的存儲位置的列表,利用索引可以提高在表或視圖中的查找數據的速度。
本文分享自華為雲社區《資料庫開髮指南(六)索引和視圖的使用技巧、方法與綜合應用》,作者: bluetata 。
一、索引
1.1 什麼是索引
索引就是數據表中數據和相應的存儲位置的列表,利用索引可以提高在表或視圖中的查找數據的速度。它類似於書籍的索引,可以幫助快速定位和檢索數據。在資料庫中,索引是對一個或多個列的值進行排序和存儲的結構,它們包含指向實際數據位置的指針。
1.2 索引分類
資料庫中索引主要分為兩類:聚集索引和非聚集索引。SQL Server 還提供了唯一索引、索引視圖、全文索引、XML 索引等等。聚集索引和非聚集索引是資料庫引擎中索引的基本類型,是理解其他類型索引的基礎。
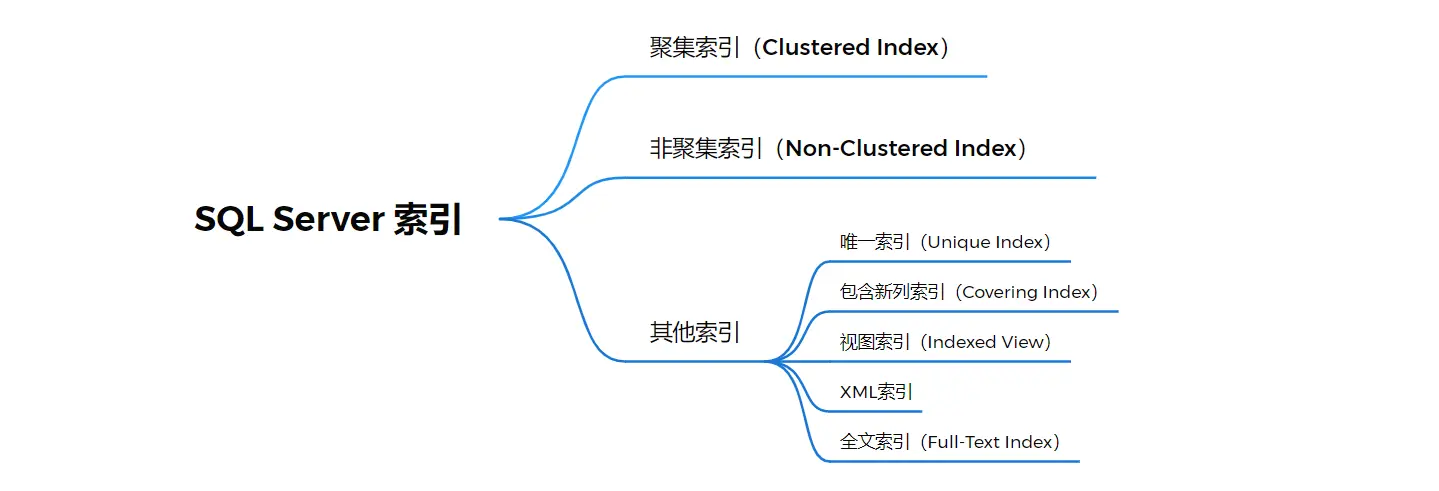
1.2.1 聚集索引
聚集索引是值表中數據行的物理存儲順序和索引的存儲順序完全相同。聚集索引根據索引順序物理地重新排列了用戶插入到表中的數據,因此,每個表只能創建一個聚集索引。聚集索引經常創建在表中經常被搜索到的列或按順序訪問的列上。在預設情況下,主鍵約束自動創建聚集索引。
1.2.2 非聚集索引
非聚集索引不改變表中數據列的物理存儲位置,數據與索引分開存儲,通過索引指向的地址與表中的數據發生關係。
非聚集索引沒有改變表中物理行的位置,索引可以在以下情況下使用非聚集索引:
- 如果某個欄位的數據唯一性比較高
- 如果查詢所得到的數據量比較少
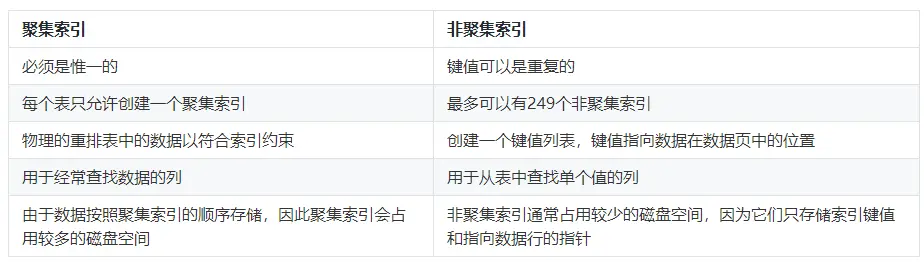
1.2.3 聚集索引和非聚集索引的區別
這裡用一個表格簡單的總結一下聚集索引和非聚集索引的區別:
1.2.4 其他類型索引
除了以上索引,還有以下類型索引:
- 唯一索引:如果希望索引鍵都不同,可以創建唯一索引。聚集索引和非聚集索引都可以是唯一索引。
- 包含新列索引:索引列的最大數量是16個,索引列的位元組總數的最高值是900。如果當多個列的位元組總數大於900,切又想在這些劣種都包含索引是,可以使用包含新列索引
- 視圖索引:提供視圖查詢效率,可以視圖的索引物理化,也就是說將結果集永久存儲在索引中,可以創建視圖索引。
- XML索引:是與xml數據關聯的索引形式,是XML二進位blob的已拆分持久表示形式
- 全文索引:一種特殊類型的基於標記的功能性功能,用於幫助在字元串中搜索賦值的詞
1.3 創建索引
1.3.1 語法
create [unique] [clustered | noclustered]
index index_name
on table_name (column_name ...)
[with fillfactor=x]
參數解釋
unique 唯一索引
clustered 聚集索引
noclustered 非聚集索引
fillfactor 填充因數大小,範圍在 0-100 直接,表示索引頁填滿的空間所占的百分比。
1.3.2 創建索引的命名規則最佳實踐
在 MSSQL 中,索引的命名規則的最佳實踐可以有一些常見的準則,以提高可讀性和維護性。這個潛在的要求不僅試用於 SQL Server 資料庫,同樣在其他資料庫例如 MySQL、Oracle 中都同樣值得註意。
下麵是個人總結的一些命名規則與建議:
- 命名應該具有描述性:索引的名稱應該能夠清晰地表達其作用和關聯的列或表。使用有意義的名稱可以使其他開發人員更容易理解索引的用途。
- 包含表名和列名:在索引名稱中包含相關表名和列名(長表名可適當縮寫,但要確保可以定位到表),可以使索引更具可讀性,並且可以避免在不同表之間使用相同名稱的索引時的衝突。
- 使用統一的命名約定:為了提高一致性,可以定義一套命名約定,併在整個資料庫中使用。例如,可以使用特定的首碼或尾碼來標識索引的類型(如 idx_ 表示非聚集索引)。
- 避免過長的名稱:索引名稱不應該過長,以免在使用索引時引起不便。儘量使用簡潔但描述性的名稱。
- 避免使用保留關鍵字和特殊字元:確保索引名稱不與 MSSQL 的保留關鍵字或特殊字元衝突,以避免語法錯誤。
1.3.3 創建索引示例
-- 普通索引 if (exists (select * from sys.indexes where name = 'idx_stu_name')) drop index student.idx_stu_name go create index idx_stu_name on student(name); -- 聯合索引 if (exists (select * from sys.indexes where name = 'idx_uqe_clu_stu_name_age')) drop index student.idx_uqe_clu_stu_name_age go create unique clustered index idx_uqe_clu_stu_name_age on student(name, age); if (exists (select * from sys.indexes where name = 'idx_cid')) drop index student.idx_cid go if (exists (select * from sys.indexes where name = 'idx_cid')) drop index student.idx_cid go -- 非聚集索引 create nonclustered index idx_cid on student (cid) with fillFactor = 30; --填充因數 -- 聚集索引 if (exists (select * from sys.indexes where name = 'idx_sex')) drop index student.idx_sex go create clustered index idx_sex on student(sex); -- 聚集索引 if (exists (select * from sys.indexes where name = 'idx_name')) drop index student.idx_name go create unique index idx_name on student(name);
1.4 適合的創建索引的列
一般情況,可以選擇那些對查詢性能有積極影響的列進行索引創建,下麵進行一定的總結:
列的選擇性:選擇性是指列中不同值的數量與總行數的比例。如果某列具有較高的選擇性,即不同的值較多,那麼為該列創建索引可能會有更好的效果。例如,在表示性別的列上創建索引可能沒有太大的幫助,因為只有兩個可能的值。
查詢頻率:觀察經常用於查詢條件的列。如果某個列經常用於搜索、過濾或連接操作,那麼為該列創建索引可以提高查詢性能。
數據表的大小:對於大型表,創建索引的影響可能更加顯著。較小的表可能不需要太多的索引,因為全表掃描的開銷相對較小。
數據更新頻率:索引的創建和維護也會增加對數據的寫操作的開銷。如果某個列的數據經常發生變化,那麼創建索引可能會帶來一定的性能開銷。
查詢性能優化需求:通過分析查詢執行計劃,可以確定是否存在潛在的性能瓶頸,並考慮為相關的列創建索引以改善查詢性能。
請註意過多的索引也可能會帶來維護開銷和存儲成本,因此需要在權衡索引數量和性能提升之間找到平衡點。定期監控和評估索引的使用情況也是重要的,以確保索引仍然對資料庫性能產生積極影響。
1.5 不適合創建索引的列
雖然在某些情況下創建索引可以提高查詢性能,但並不是所有列都適合創建索引。以下是一些不適合創建索引的列的情況:
低選擇性列:如果某個列的選擇性很低,即該列的不同值較少,創建索引可能不會帶來明顯的性能提升。例如,對於性別這樣只有幾個可能值的列,創建索引可能不會有太大意義。
經常更新的列:如果某個列的值經常被修改,那麼為該列創建索引可能會帶來額外的維護成本和性能開銷。每次更新操作都需要更新索引,這可能會影響寫入性能。在這種情況下,需要仔細評估是否真的需要為該列創建索引。
過於頻繁的查詢列:某些列可能經常被查詢,但它們的選擇性較低,即不同的值較少。在這種情況下,儘管查詢頻率高,但為該列創建索引可能不會帶來明顯的性能提升,因為索引的使用效果有限。
大文本或大二進位列:對於存儲大文本或大二進位數據的列,如長文本欄位或圖像欄位,創建索引的效果通常較差。這是因為索引本身需要占用額外的存儲空間,並且對於大型數據的索引操作可能變得非常耗時。
不常用的列:對於很少用於查詢的列,創建索引可能沒有太大意義。如果一個列很少用於查詢條件或連接操作,那麼為其創建索引可能只會增加額外的開銷而不帶來實際的性能提升。
需要註意的是,以上列舉的情況只是一般性的指導原則,具體是否適合創建索引還取決於具體的資料庫結構、查詢模式和性能需求。在設計和創建索引時,應根據具體情況進行評估,併進行性能測試和優化以確保索引的有效性。
二、視圖
2.1 什麼是視圖
視圖就是一個虛擬的數據表,該數據表中的數據記錄是由一條查詢語句的查詢結果得到的。
2.2 為什麼要使用視圖,而不是表(面試可能會被問到)
如果你在面試的時候被問到這個問題,建議從下麵這個流程來回答一下麵試官。
首先介紹一下表的作用(比如表是直接存儲結構化數據,可以擴展增刪改之類的),之後在介紹一下視圖是什麼,之後從兩個切入點來講解視圖的好處以及必要性,這兩個切入點是:復用性和安全性,這裡來簡單總結一下:
- 簡化查詢,提高復用性
想象一下,一個人員寬表,裡面有幾百個欄位,但是你每次只需要用到這個表中的姓名、性別、年齡這三個欄位,那麼你可以創建一個視圖來直接使用,或者你這個人員表經常和另外一個履歷表 join 組合在一起,而只取了其中的部分欄位,並且頻繁使用這幾個欄位。那麼無疑創建視圖是一個好做法。當然這種情況也可以說明使用視圖能夠簡化查詢。 - 提高安全性
- 通過視圖,可以限制用戶對敏感數據的直接訪問。視圖可以控制用戶可以看到和操作的數據的範圍,提供更好的安全性和隱私保護。這裡還拿剛纔我講的姓名、性別、年齡三個欄位,假如年齡是一個比較敏感的欄位,那麼對某些資料庫用戶只能查詢姓名和性別的話,那麼就可以設置一個視圖分配給這個用戶。
- 另外就是如果你要更新視圖的時候,也只能更新視圖所見的欄位,用戶對視圖不可以隨意的更改和刪除,可以一定程度的保證數據的安全性。
講解完上述的兩個大的關鍵點後,也可以適當自行發揮,比如視圖你可以調整表欄位的顯示順序,或者欄位名字等等。這些也是優點。可以適當進行講解。
2.3 創建視圖
創建視圖的時候,對命名視圖大家一般也有預設的規則,一般情況可以使用 v_ 或 view_ + 表名(表縮寫)的形式。
例如:v_student
--創建視圖 if (exists (select * from sys.objects where name = 'v_student')) drop view v_student go create view v_student as select id, name, age, sex from student;
2.4 創建視圖準則
創建視圖需要考慮一下準則:
- 視圖名稱必須遵循標識符的規則,該名稱不得與該架構的任何表的名稱相同。
- 你可以對其他視圖創建視圖。允許嵌套視圖,但嵌套不得超過32層。視圖最多可以有1024個欄位。
- 不能將規則和 default 定義於視圖相關聯。
- 視圖的查詢不能包含 compute 子句、compute by 子句或 into 關鍵字。
- 定義視圖的查詢不能包含 order by 子句,除非在 select 語句的選擇列表中還有 top 子句。
下列情況必須指定視圖中每列的名稱:
- 有列順序需求(在某些情況下,您可能希望定義視圖的結果集中列的順序,並且這與基礎表中的順序不同。)
- 視圖中的任何列都是從算術表達式、內置函數或常量派生而來
- 視圖中有兩列或多列具有相同名稱(通常由於視圖定義包含聯接,因此來自兩個或多個不同的列具有相同的名稱)
- 有指定列別名的需求。註意無論是否重命名,視圖列都需繼承原列的數據類型
2.5 修改視圖
修改視圖和修改表有點類似,可以直接使用 alter 關鍵字進行修改,示例如下:
alter view v_student as select id, name, sex from student; alter view v_student(編號, 名稱, 性別) as select id, name, sex from student go select * from v_student; select * from information_schema.views;
2.6 加密視圖
如果你對某一個視圖有保護查詢邏輯、防止修改或者查詢加密的需求的時候,可以使用加密視圖操作。
在 SQL Server 中 使用with encryption後,可以在創建視圖時對其定義的 SQL 查詢進行加密。也就是說 MSSQL 會對該視圖的定義中的查詢語句進行加密。這意味著其他人無法直接查看或分析該視圖的查詢邏輯。壓根就看不到這個視圖內部結構了。
-- 加密視圖 if (exists (select * from sys.objects where name = 'v_student_info')) drop view v_student_info go create view v_student_info with encryption --加密 as select id, name, age from student go --view_definition is null select * from information_schema.views where table_name like 'v_student';
如何解密被加密的視圖,或者修改已經被加密的視圖:
一般情況一個視圖被加密後,你需要修改它,那麼大致有3個方法:
- 重新創建視圖(先刪除已加密的視圖,然後使用新的查詢邏輯重新創建視圖。)。
- 創建新視圖(創建一個新的,視圖名稱不同,之後調用這個新的)。
- 暴力解密之後修改(一般需要藉助第三方工具或輔助,該方式個人不推薦)
2.7 視圖能否被更新 update (面試可能會被問到)
視圖可以被更新嗎?什麼情況下可以被更新?
如果面試官問了這兩個問題,那麼他還算友好的提醒了你,如果直接問了一句話“視圖可以被更新嗎?”,那麼我感覺有被挖坑的嫌疑。
視圖可以被更新,但不是所有的情況都可以。
視圖更新必須遵循以下規則:
- 當視圖的欄位是通過欄位表達式(Field Expression)或常數(Constant)計算得出的結果時,對該視圖執行 INSERT 和 UPDATE 操作是不允許的,但可以執行 DELETE 操作。
- 若視圖的欄位是來自庫函數,則此視圖不允許更新;
- 若視圖的定義中有 GROUP BY 子句或聚集函數時,則此視圖不允許更新;
- 若視圖的定義中有 DISTINCT 任選項,則此視圖不允許更新;
- 若視圖的定義中有嵌套查詢,並且嵌套查詢的 FROM 子句中涉及的表也是導出該視圖的基表,則此視圖不允許更新;
- 若視圖是由兩個以上的基表導出的,此視圖不允許更新(源表單一才可以被更新);
- 一個不允許更新的視圖上定義的視圖也不允許更新;
- 由一個基表定義的視圖,只含有基表的主鍵或候補鍵,並且視圖中沒有用表達式或函數定義的屬性,才允許更新。


