
`MySQL8高級之架構和優化` 讓  # 第01章 Linux下MySQL的安裝與使用 ## 1、安裝 ### 1.1、docker安裝 ```shell dock ...
MySQL8高級之架構和優化 讓

第01章 Linux下MySQL的安裝與使用
1、安裝
1.1、docker安裝
docker run -d \
-p 3309:3306 \
-v /atguigu/mysql/mysql8/conf:/etc/mysql/conf.d \
-v /atguigu/mysql/mysql8/data:/var/lib/mysql \
-e MYSQL_ROOT_PASSWORD=123456 \
--name atguigu-mysql8 \
--restart=always \
mysql:8.0.29
1.2、查看是否啟動
docker ps
1.3、測試遠程鏈接
測試連接:MySQL 8 版本,圖形連接時還會出現如下問題
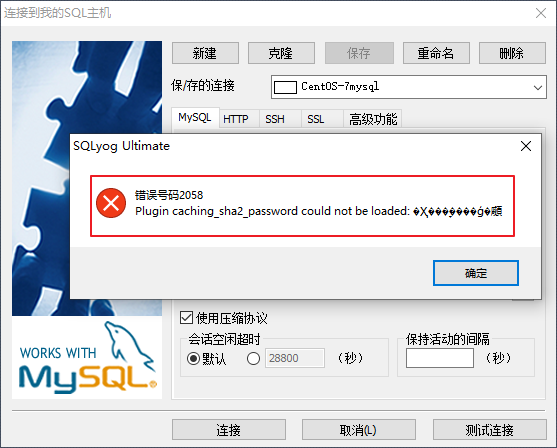
配置新連接報錯:錯誤號碼 2058,出現這個原因是MySQL 8 之前的版本中加密規則是mysql_native_password,而在MySQL 8之後,加密規則是caching_sha2_password。
解決方案有兩種,一種是升級SQLyog和Navicat(因此,新版SQLyog和Navicat不會出現此問題),另一種是把MySQL用戶登錄密碼加密規則還原成mysql_native_password。
解決方法:登錄你的 MySQL 資料庫
#進入容器:env LANG=C.UTF-8 避免容器中顯示中文亂碼
docker exec -it atguigu-mysql8 env LANG=C.UTF-8 /bin/bash
#進入容器內的mysql命令行
mysql -uroot -p
#修改預設密碼校驗方式
ALTER USER 'root'@'%' IDENTIFIED WITH mysql_native_password BY '123456';
然後再重新配置SQLyog的連接,重新填寫密碼,則可連接成功了。
2、字元集
2.1、預設字元集
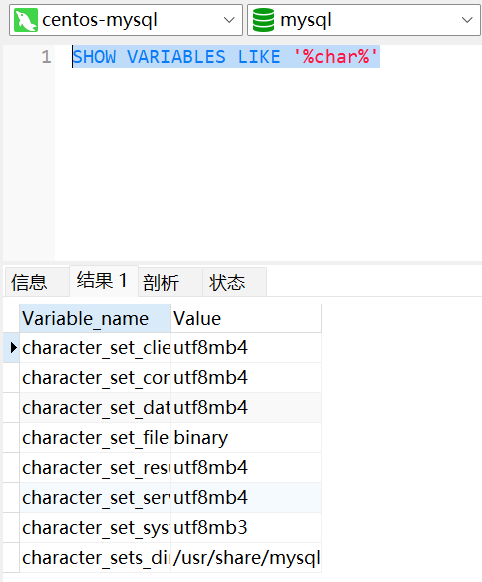
MySQL 8版本之前,預設字元集為 latin1(ISO-8859-1) ,不支持中文,使用前必須設置字元集為utf8(utf8mb3)或utf8mb4。從MySQL 8開始,資料庫的預設字元集為 utf8mb4 ,從而避免中文亂碼的問題。
SHOW VARIABLES LIKE '%char%';
2.2、utf8與utf8mb4
utf8 字元集表示一個字元需要使用1~4個位元組,但是我們常用的一些字元使用1~3個位元組就可以表示了。而字元集表示一個字元所用的最大位元組長度,在某些方面會影響系統的存儲和性能,所以設計MySQL的設計者偷偷的定義了兩個概念:
utf8mb3 :閹割過的 utf8 字元集,只使用1~3個位元組表示字元。(無法存儲emoji表情)
MySQL5.7中的utf8是utf8mb3字元集
utf8mb4 :正宗的 utf8 字元集,使用1~4個位元組表示字元。
MySQL8.0中的utf8是utf8mb4字元集
3、 SQL大小寫規範
3.1、Windows和Linux的區別
Windows環境:
全部不區分大小寫
Linux環境:
1、資料庫名、表名、表的別名、變數名嚴格區分大小寫;
2、列名與列的別名不區分大小寫。
3、關鍵字、函數名稱不區分大小寫;
3.2、Linux下大小寫規則設置(瞭解)
在MySQL 8中設置的具體步驟為:
1、停止MySQL服務
2、刪除數據目錄,即刪除 /var/lib/mysql 目錄
3、在MySQL配置文件(/etc/my.cnf )的 [mysqld] 中添加 lower_case_table_names=1
4、初始化數據目錄 mysqld --initialize --user=mysql
5、啟動MySQL服務 systemctl start mysqld
註意:不建議在開發過程中修改此參數,將會丟失所有數據
4、sql_mode
4.1、寬鬆模式 vs 嚴格模式
寬鬆模式:
執行錯誤的SQL或插入不規範的數據,也會被接受,並且不報錯。
嚴格模式:
執行錯誤的SQL或插入不規範的數據,會報錯。MySQL5.7版本開始就將sql_mode預設值設置為了嚴格模式。
4.2、查看和設置sql_mode
查詢sql_mode的值:
SELECT @@session.sql_mode;
SELECT @@global.sql_mode;
-- 或者
SHOW VARIABLES LIKE 'sql_mode'; --session級別

臨時設置sql_mode的值:
SET GLOBAL sql_mode = 'mode1,model2,...'; --全局,要重新啟動客戶端生效,重啟MySQL服務後失效
SET SESSION sql_mode = 'mode1,model2,...'; --當前會話生效效,關閉當前會話就不生效了。可以省略SESSION關鍵字
在mysql配置文件中配置,永久生效:在宿主機上執行以下命令,創建配置文件:
vim /atguigu/mysql/mysql8/conf/my.cnf
編輯配置文件
[mysqld]
sql-mode = "mode1,model2,..."
重啟mysql容器
docker restart atguigu-mysql8
4.3、錯誤開發演示
建表並插入數據:
CREATE DATABASE atguigudb;
USE atguigudb;
CREATE TABLE employee(id INT, `name` VARCHAR(16),age INT,dept INT);
INSERT INTO employee VALUES(1,'zhang3',33,101);
INSERT INTO employee VALUES(2,'li4',34,101);
INSERT INTO employee VALUES(3,'wang5',34,102);
INSERT INTO employee VALUES(4,'zhao6',34,102);
INSERT INTO employee VALUES(5,'tian7',36,102);
需求:查詢每個部門年齡最大的人
-- 錯誤演示
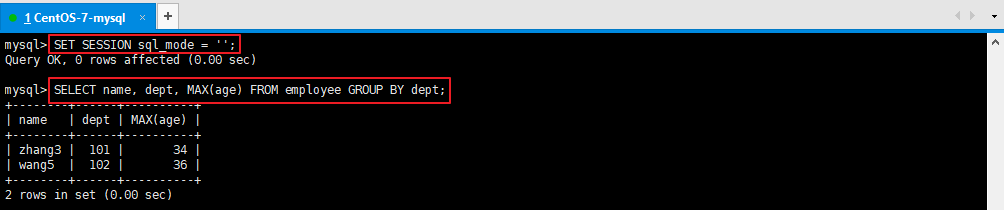
SELECT `name`, dept, MAX(age) FROM employee GROUP BY dept;
以上查詢語句在 “ONLY_FULL_GROUP_BY” 模式下查詢出錯,因為select子句中的name列並沒有出現在group by子句中,也沒有出現在函數中:

在非 “ONLY_FULL_GROUP_BY” 模式下可以正常執行,但是得到的是錯誤的結果:
SET SESSION sql_mode = '';
正確的查詢方式:查詢應該分兩個步驟
1、查詢每個部門最大的年齡
2、查詢人
正確的語句:
SELECT e.*
FROM employee e
INNER JOIN (SELECT dept, MAX(age) age FROM employee GROUP BY dept) AS maxage
ON e.dept = maxage.dept AND e.age = maxage.age;
測試完成後再將sql_mode設置回來:
SET SESSION sql_mode = 'ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION';
4.4、sql_mode常用值(瞭解)
ONLY_FULL_GROUP_BY:對於GROUP BY聚合操作,SELECT子句中只能包含函數和 GROUP BY 中出現的欄位。- STRICT_TRANS_TABLES:
- 對於支持事務的表,如果發現某個值缺失或非法,MySQL將拋出錯誤,語句會停止運行並回滾。
- 對於不支持事務的表,不做限制,提高性能。
- NO_ZERO_IN_DATE:不允許
日期和月份為零。 - NO_ZERO_DATE:MySQL資料庫不允許插入零日期,插入零日期會拋出錯誤而不是警告。
- ERROR_FOR_DIVISION_BY_ZERO:在INSERT或UPDATE過程中,如果數據被零除,則產生錯誤而非警告。如果未給出該模式,那麼數據被零除時MySQL返回NULL。
- NO_ENGINE_SUBSTITUTION:如果需要的存儲引擎被禁用或不存在,那麼拋出錯誤。不設置此值時,用預設的存儲引擎替代。
第02章 邏輯架構
1、邏輯架構剖析
1.1、伺服器處理客戶端請求
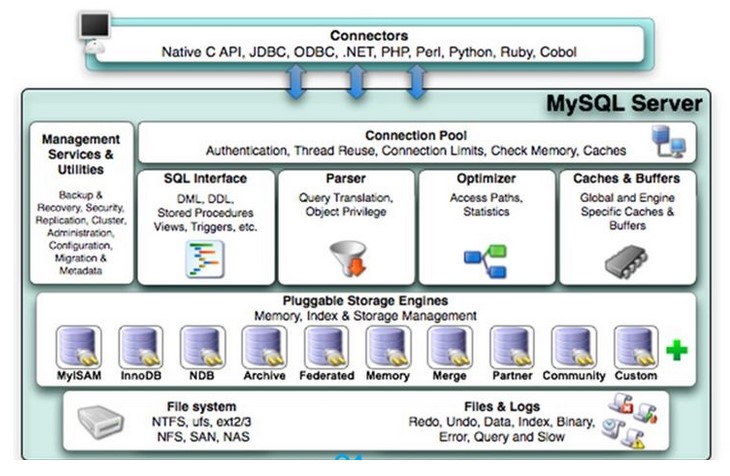
下麵是MySQL5.7使用的經典架構圖,MySQL 8中去掉了Caches&Buffers部分:
1.2、Connectors(客戶端)
MySQL伺服器之外的客戶端程式,與具體的語言相關,例如Java中的JDBC,圖形用戶界面SQLyog等。本質上都是在TCP連接上通過MySQL協議和MySQL伺服器進行通信。
1.3、MySQL Server(伺服器)
第1層:連接層
- 客戶端訪問 MySQL 伺服器前,做的
第一件事就是建立 TCP 連接。 - 經過三次握手建立連接成功後, MySQL 伺服器對 TCP 傳輸過來的賬號密碼做
身份認證、許可權獲取。- 用戶名或密碼不對
,會收到一個Access denied for user錯誤,客戶端程式結束執行 用戶名密碼認證通過,會從許可權表查出賬號擁有的許可權與連接關聯,之後的許可權判斷邏輯,都將依賴於此時讀到的許可權
- 用戶名或密碼不對
- TCP 連接收到請求後,必須要分配給一個線程專門與這個客戶端的交互。所以還會有個線程池,去走後面的流程。每一個連接從線程池中獲取線程,省去了創建和銷毀線程的開銷。
第2層:服務層
Management Serveices & Utilities: 系統管理和控制工具
SQL Interface:SQL介面:
接收用戶的SQL命令,並且返回用戶需要查詢的結果。比如SELECT ... FROM就是調用SQL Interface- MySQL支持DML(數據操作語言)、DDL(數據定義語言)、存儲過程、視圖、觸發器、自定義函數等多種SQL語言介面
Parser:解析器:
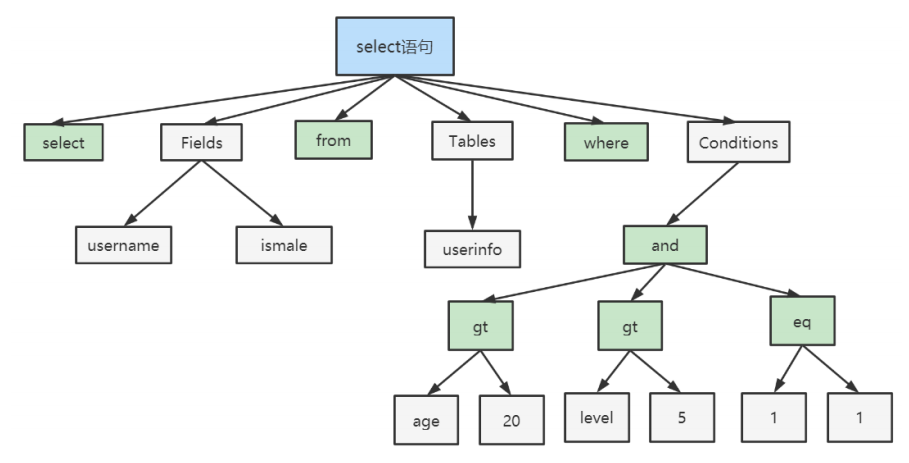
在SQL命令傳遞到解析器的時候會被解析器驗證和解析。解析器中SQL 語句進行詞法分析、語法分析、語義分析,併為其創建語法樹。
-
詞法分析:將整個語句拆分成一個個欄位
-
語法分析:將詞法分析拆分出的欄位,按照MySQl語法規則,生成解析樹
-
語義分析:
檢查解析樹是否合法,比如查看表是否存在,列是否存在
典型的解析樹如下:
Optimizer:查詢優化器:
- SQL語句在語法解析後、查詢前會使用查詢優化器對查詢進行優化,
確定SQL語句的執行路徑,生成一個執行計劃。
Caches & Buffers: 查詢緩存組件:
- MySQL內部維持著一些Cache和Buffer,比如Query Cache用來緩存一條SELECT語句的執行結果,如果能夠在其中找到對應的查詢結果,那麼就不必再進行查詢解析、查詢優化和執行的整個過程了,直接將結果反饋給客戶端。
- 這個緩存機制是由一系列小緩存組成的。比如表緩存,記錄緩存,key緩存,許可權緩存等 。
- 這個查詢緩存可以在不同客戶端之間共用 。
- 問:大多數情況查詢緩存就是個雞肋,為什麼呢?
- 只有相同的SQL語句才會命中查詢緩存。兩個查詢請求在任何字元上的不同(例如:空格、註釋、大小寫),都會導致緩存不會命中。
- 在兩條查詢之間 有 INSERT 、 UPDATE 、 DELETE 、 TRUNCATE TABLE 、 ALTER TABLE 、 DROP TABLE 或 DROP DATABASE 語句也會導致緩存失效
- 因此 MySQL的查詢緩存命中率不高。
所以在MySQL 8之後就拋棄了這個功能。
第3層:引擎層
存儲引擎層( Storage Engines),負責MySQL中數據的存儲和提取,對物理伺服器級別維護的底層數據執行操作,伺服器通過API與存儲引擎進行通信。不同的存儲引擎具有的功能不同,管理的表有不同的存儲結構,採用的存取演算法也不同,這樣我們可以根據自己的實際需要進行選取。例如MyISAM引擎和InnoDB引擎。
1.4、存儲層
所有的數據、資料庫、表的定義、表的每一行的內容、索引,都是存在文件系統 上,以文件的方式存在,並完成與存儲引擎的交互。
1.5、查詢流程說明
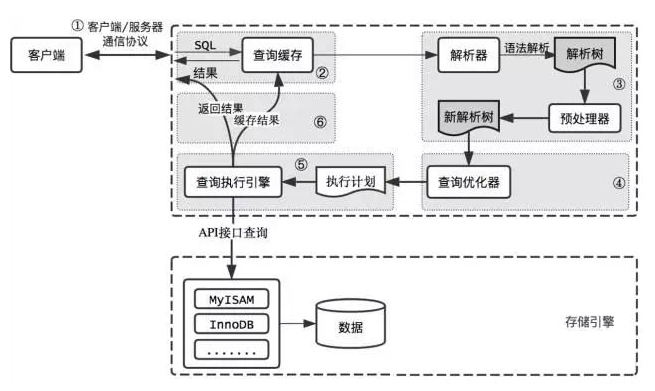
首先,MySQL客戶端通過協議與MySQL伺服器建連接,通過SQL介面發送SQL語句,先檢查查詢緩存,如果命中,直接返回結果,否則進行語句解析。也就是說,在解析查詢之前,伺服器會先訪問查詢緩存,如果某個查詢結果已經位於緩存中,伺服器就不會再對查詢進行解析、優化、以及執行。它僅僅將緩存中的結果返回給用戶即可,這將大大提高系統的性能。
接下來是解析過程,MySQL解析器通過關鍵字將SQL語句進行解析,並生成一棵對應的解析樹,解析器使用MySQL語法規則驗證和解析SQL語句。例如,它將驗證是否使用了錯誤的關鍵字,或者使用關鍵字的順序是否正確,引號能否前後匹配等;預處理器則根據MySQL規則進一步檢查解析樹是否合法,例如,這裡將檢查數據表和數據列是否存在,還會解析名字和別名,看是否有歧義等,並生成一棵新解析樹,新解析樹可能和舊解析樹結構一致。
然後是優化過程,MySQL優化程式會對我們的語句做一些優化,將查詢的IO成本和CPU成本降到最低。優化的結果就是生成一個執行計劃。這個執行計劃表明瞭應該使用哪些索引執行查詢,以及表之間的連接順序是啥樣,必要時將子查詢轉換為連接、表達式簡化等等。我們可以使用EXPLAIN語句來查看某個語句的執行計劃。
最後,進入執行階段。完成查詢優化後,查詢執行引擎會按照生成的執行計劃調用存儲引擎提供的介面執行SQL查詢並將結果返回給客戶端。在MySQL8以下的版本,如果設置了查詢緩存,這時會將查詢結果進行緩存,再返回給客戶端。
2、SQL執行流程
利用SHOW VARIABLES 可以查看SQL的執行流程。使用前需要先開啟該功能:
2.1、MySQL8
1.開啟profiling
確認profiling是否開啟
SHOW VARIABLES LIKE '%profiling%';

profiling=0 代表關閉,我們需要把 profiling 打開,即設置為 1:
SET profiling = 1; -- profiling = ON

2.顯示查詢
執行任意SQL語句:
SELECT * FROM atguigudb.employee;
SELECT * FROM atguigudb.employee WHERE id = 5;
顯示最近的幾次查詢:
SHOW PROFILES;

3.查看執行流程
查看最後一個SQL的執行流程:
SHOW PROFILE;
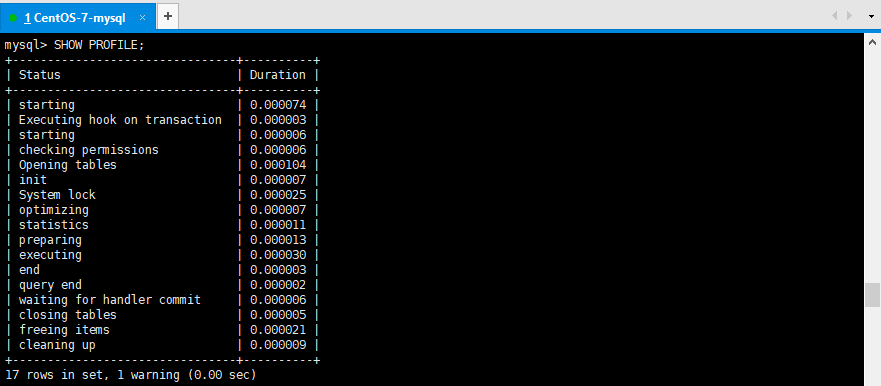
查看指定SQL的執行流程:查詢指定的 Query ID
SHOW PROFILE FOR QUERY 3;
查詢更豐富的內容:
SHOW PROFILE cpu,block io FOR QUERY 3;
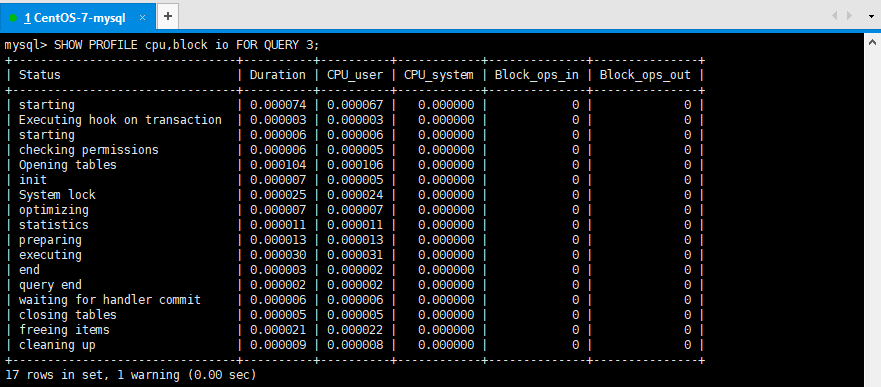
- SHOW PROFILE 的常用查詢參數:
- ①ALL:顯示所有的開銷信息。
-
②BLOCK IO:顯示塊IO開銷。 - ③CONTEXT SWITCHES:上下文切換開銷。
-
④CPU:顯示CPU開銷信息。 - ⑤IPC:顯示發送和接收開銷信息。
- ⑥MEMORY:顯示記憶體開銷信息。
- ⑦PAGE FAULTS:顯示頁面錯誤開銷信息。
- ⑧SOURCE:顯示和Source_function,Source_file,Source_line相關的開銷信息。
- ⑨SWAPS:顯示交換次數開銷信息。
2.2、MySQL5.7(瞭解)
1. 查看查詢緩存是否啟用
SHOW VARIABLES LIKE '%query_cache_type%';
2. 開啟查詢緩存
修改配置文件:vim /etc/my.cnf
新增一行:query_cache_type=1
重啟MySQL:systemctl restart mysqld
3. 執行SQL並查看執行流程
參考MySQl8中執行流程的啟用和查看方式,在MySQL5.7中查看執行流程
- 第一次執行查詢SQL:
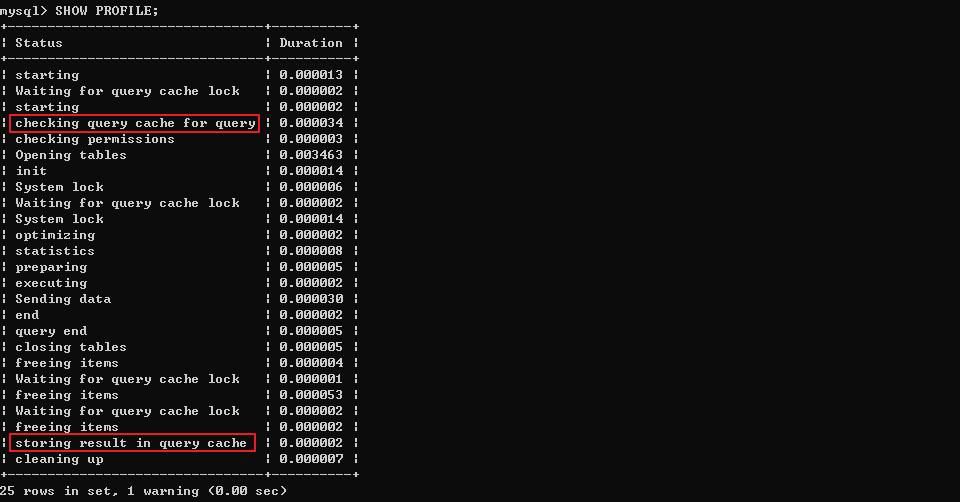
- 第二次執行相同的SQL:

3、存儲引擎
3.1、查看存儲引擎
查看MySQL提供什麼存儲引擎
SHOW ENGINES;
下麵的結果表示MySQL中預設使用的存儲引擎是InnoDB,支持事務,行鎖,外鍵,支持分散式事務(XA),支持保存點(回滾)
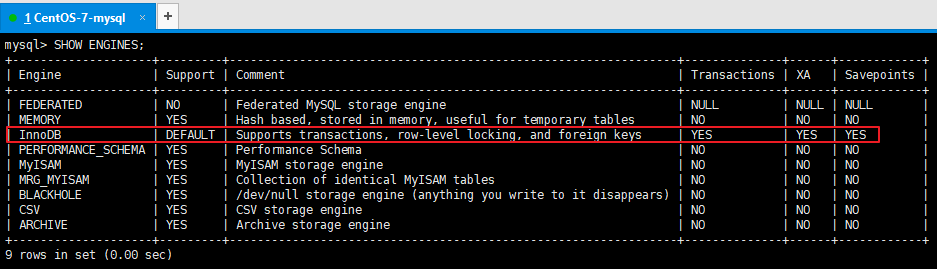
也可以通過以下語句查看預設的存儲引擎:
SHOW VARIABLES LIKE '%default_storage_engine%';

3.2、設置存儲引擎(瞭解)
方法1:
設置預設存儲引擎:
SET DEFAULT_STORAGE_ENGINE=MyISAM;
方法2:
或者修改 my.cnf 文件:vim /etc/my.cnf
在[mysqld]節點下新增一行:default-storage-engine=MyISAM
重啟MySQL:systemctl restart mysqld
方法3:
我們可以為 不同的表設置不同的存儲引擎
CREATE TABLE 表名( 建表語句 ) ENGINE = 存儲引擎名稱;
ALTER TABLE 表名 ENGINE = 存儲引擎名稱;
-- 例如:
CREATE TABLE student(id INT, `name` VARCHAR(16),age INT,dept INT) ENGINE = MyISAM;
3.3、各種引擎介紹
1. InnoDB存儲引擎
-
InnoDB是MySQL的預設事務型引擎,它被設計用來
處理大量的短期(short-lived)事務。可以確保事務的完整提交(Commit)和回滾(Rollback)。 -
除非有非常特別的原因需要使用其他的存儲引擎,否則
應該優先考慮InnoDB引擎。 -
InnoDB不僅緩存索引還要緩存真實數據, 對記憶體要求較 高 ,而且記憶體大小對性能有決定性的影響。
2. MyISAM存儲引擎
-
MyISAM提供了大量的特性,包括全文索引、壓縮、空間函數(GIS)等,但
MyISAM不支持事務和行級鎖,有一個毫無疑問的缺陷就是崩潰後無法安全恢復。 -
優勢是訪問的 速度快 ,對事務完整性沒有要求或者以SELECT、INSERT為主的應用。
-
MyISAM只緩存索引,不緩存真實數據。
3. Archive引擎
Archive檔案存儲引擎只支持INSERT和SELECT操作。- Archive表適合日誌和數據採集(檔案)類應用。
- 根據英文的測試結論來看,Archive表比MyISAM表要小大約75%,比支持事務處理的InnoDB表小大約83%。
4. Blackhole引擎(黑洞)
Blackhole引擎沒有實現任何存儲機制,它會丟棄所有插入的數據,不做任何保存。- 但伺服器會記錄Blackhole表的日誌,所以可以用於複製數據到備庫,或者簡單地記錄到日誌。但這種應用方式會碰到很多問題,因此並不推薦。
5. CSV引擎
CSV引擎可以將普通的CSV文件作為MySQL的表來處理,但不支持索引。- CSV引擎可以作為一種數據交換的機制,非常有用。
- CSV存儲的數據直接可以在操作系統里,用文本編輯器,或者excel讀取。
6. Memory引擎
- 如果需要快速地訪問數據,並且這些數據不會被修改,重啟以後丟失也沒有關係,那麼使用Memory表是非常有用。
- Memory表至少比MyISAM表要快一個數量級。
7. Federated引擎
Federated引擎是訪問其他MySQL伺服器的一個代理(跨庫關聯查詢),儘管該引擎看起來提供了一種很好的跨伺服器的靈活性,但也經常帶來問題,因此預設是禁用的。
3.4、MyISAM和InnoDB的區別
| 對比項 | MyISAM | InnoDB |
|---|---|---|
| 外鍵 | 不支持 | 支持 |
| 事務 | 不支持 | 支持 |
| 行表鎖 | 表鎖,即使操作一條記錄也會鎖住整個表,不適合高併發的操作 | 行鎖,操作時只鎖某一行,不對其它行有影響,適合高併發的操作 |
| 緩存 | 只緩存索引,不緩存真實數據 | 不僅緩存索引還要緩存真實數據,對記憶體要求較高,而且記憶體大小對性能有決定性的影響。支持聚簇索引 |
| 關註點 | 併發查詢,節省資源、消耗少、簡單業務 | 併發寫、事務、更大更複雜的資源操作 |
| 預設使用 | N | Y |
| 自帶系統表使用 | Y | N |
第03章 SQL預熱
1、創建測試數據
CREATE TABLE `t_dept` (
`id` INT NOT NULL AUTO_INCREMENT,
`deptName` VARCHAR(30) DEFAULT NULL,
`address` VARCHAR(40) DEFAULT NULL,
PRIMARY KEY (`id`)
);
CREATE TABLE `t_emp` (
`id` INT NOT NULL AUTO_INCREMENT,
`name` VARCHAR(20) DEFAULT NULL,
`age` INT DEFAULT NULL,
`deptId` INT DEFAULT NULL,
`empno` INT NOT NULL,
PRIMARY KEY (`id`),
KEY `idx_dept_id` (`deptId`)
#CONSTRAINT `fk_dept_id` FOREIGN KEY (`deptId`) REFERENCES `t_dept` (`id`)
);
INSERT INTO t_dept(id,deptName,address) VALUES(1,'華山','華山');
INSERT INTO t_dept(id,deptName,address) VALUES(2,'丐幫','洛陽');
INSERT INTO t_dept(id,deptName,address) VALUES(3,'峨眉','峨眉山');
INSERT INTO t_dept(id,deptName,address) VALUES(4,'武當','武當山');
INSERT INTO t_dept(id,deptName,address) VALUES(5,'明教','光明頂');
INSERT INTO t_dept(id,deptName,address) VALUES(6,'少林','少林寺');
INSERT INTO t_emp(id,NAME,age,deptId,empno) VALUES(1,'風清揚',90,1,100001);
INSERT INTO t_emp(id,NAME,age,deptId,empno) VALUES(2,'岳不群',50,1,100002);
INSERT INTO t_emp(id,NAME,age,deptId,empno) VALUES(3,'令狐沖',24,1,100003);
INSERT INTO t_emp(id,NAME,age,deptId,empno) VALUES(4,'洪七公',70,2,100004);
INSERT INTO t_emp(id,NAME,age,deptId,empno) VALUES(5,'喬峰',35,2,100005);
INSERT INTO t_emp(id,NAME,age,deptId,empno) VALUES(6,'滅絕師太',70,3,100006);
INSERT INTO t_emp(id,NAME,age,deptId,empno) VALUES(7,'周芷若',20,3,100007);
INSERT INTO t_emp(id,NAME,age,deptId,empno) VALUES(8,'張三豐',100,4,100008);
INSERT INTO t_emp(id,NAME,age,deptId,empno) VALUES(9,'張無忌',25,5,100009);
INSERT INTO t_emp(id,NAME,age,deptId,empno) VALUES(10,'韋小寶',18,NULL,100010);
2、常見七種JOIN查詢
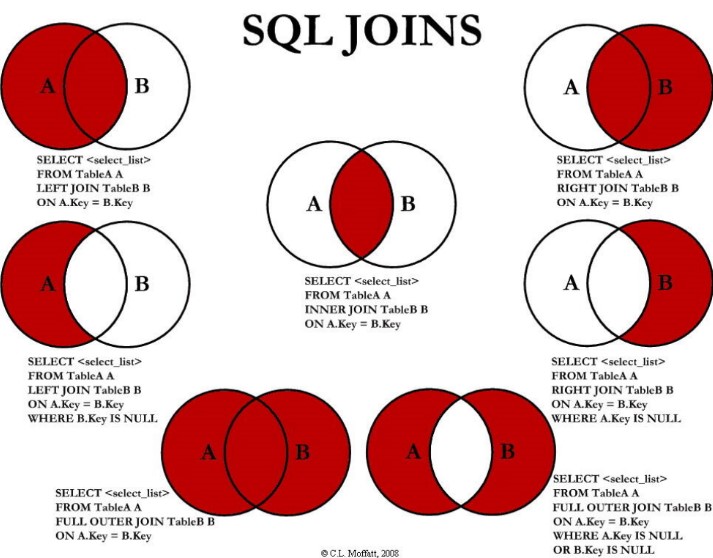
需求1:查詢所有有部門的員工信息以及他所在的部門信息
在A、和B中都存在的數據 => 查詢A、B兩表交集
SELECT * FROM t_emp a INNER JOIN t_dept b ON a.deptid = b.id;
需求2:查詢所有用戶,並顯示其部門信息(如果員工沒有所在部門,也會被列出) => 查詢A的全集
SELECT *
FROM t_emp a
LEFT JOIN t_dept b ON a.deptid = b.id;
需求3:列出所有部門,並顯示其部門的員工信息(如果部門沒有員工,也會被列出)=> 查詢B的全集
SELECT *
FROM t_emp a
RIGHT JOIN t_dept b ON a.deptid = b.id;
需求4:查詢沒有加入任何部門的員工(先查詢所有員工,再過濾掉包含部門的數據) => 查詢A且不包含B
SELECT * FROM t_emp a
LEFT JOIN t_dept b ON a.deptid = b.id
WHERE b.id IS NULL;
需求5:查詢沒有任何員工的部門 => 查詢B且不包含A
SELECT * FROM t_emp a
RIGHT JOIN t_dept b ON a.deptid = b.id
WHERE a.id IS NULL;
需求6:查詢所有員工和所有部門 => AB全有
MySQL FULL JOIN 的實現:因為MySQL不支持FULL JOIN,下麵是替代方法
LEFT JOIN + UNION(合併並去重) + RIGHT JOIN
註意:
- UNION和UNION ALL要求欄位數量和順序都一致
- 如果確定兩表結果不會重覆,則使用UNION ALL提升效率
SELECT *
FROM t_emp a
LEFT JOIN t_dept b ON a.deptid = b.id
UNION
SELECT *
FROM t_emp a
RIGHT JOIN t_dept b ON a.deptid = b.id;
需求7:查詢沒有加入任何部門的員工,以及查詢出部門下沒有任何員工的部門 => A的獨有+B的獨有
SELECT *
FROM t_emp a
LEFT JOIN t_dept b ON a.deptid = b.id
WHERE b.id IS NULL
UNION ALL
SELECT *
FROM t_emp a
RIGHT JOIN t_dept b ON a.deptid = b.id
WHERE a.id IS NULL;
3、擴展掌門人
3.1、增加掌門人欄位
ALTER TABLE t_dept ADD CEO INT(11);
UPDATE t_dept SET CEO=2 WHERE id=1;
UPDATE t_dept SET CEO=4 WHERE id=2;
UPDATE t_dept SET CEO=6 WHERE id=3;
UPDATE t_dept SET CEO=8 WHERE id=4;
UPDATE t_dept SET CEO=9 WHERE id=5;
3.2、練習
需求1:求各個門派對應的掌門人
SELECT b.deptname, a.name FROM t_dept b LEFT JOIN t_emp a ON b.ceo = a.id;
需求2:求所有掌門人的平均年齡
SELECT AVG(a.age) FROM t_emp a INNER JOIN t_dept b ON a.id = b.ceo;
需求3:求所有人物對應的掌門名稱(4種寫法分析)
- 三表左連接方式
-- 員工表(t_emp)、部門表(t_dept)、ceo(t_emp)表 關聯查詢
SELECT emp.name, ceo.name AS ceoname
FROM t_emp emp
LEFT JOIN t_dept dept ON emp.deptid = dept.id
LEFT JOIN t_emp ceo ON dept.ceo = ceo.id;
- 子查詢方式
SELECT
emp.name,
(SELECT ceo.name FROM t_emp ceo WHERE ceo.id = dept.ceo) AS ceoname
FROM t_emp emp
LEFT JOIN t_dept dept ON emp.deptid = dept.id
- 臨時表連接方式1
SELECT emp_with_ceo_id.name, emp.name AS ceoname FROM
-- 查詢所有員工及對應的ceo的id
(
SELECT emp.name, dept.ceo
FROM t_emp emp
LEFT JOIN t_dept dept ON emp.deptid = dept.id
) emp_with_ceo_id
LEFT JOIN t_emp emp ON emp_with_ceo_id.ceo = emp.id;
- 臨時表連接方式2
SELECT emp.name, ceo.ceoname FROM t_emp emp LEFT JOIN
-- 查詢並創建臨時表ceo:包含ceo的部門id和ceo的name
(
SELECT emp.deptId AS deptId, emp.name AS ceoname
FROM t_emp emp
INNER JOIN t_dept dept ON emp.id = dept.ceo
) ceo
ON emp.deptId = ceo.deptId;
第04章 MySQL索引
1、索引簡介
1.1、什麼是索引☆
MySQL官方對索引的定義為:索引(Index)是幫助MySQL高效獲取數據的數據結構。
索引的本質:索引是數據結構。你可以簡單理解為“排好序的快速查找數據結構”。這些數據結構以某種方式指向數據, 可以在這些數據結構的基礎上實現高級查找演算法 。
1.2、索引的優缺點☆
優點:
(1)提高數據檢索的效率,降低資料庫的IO成本
(2)保證表中每條記錄的唯一性 。

缺點:
(1)創建索引和維護索引要耗費時間 。
(2)索引是存儲在磁碟上的,因此需要占用磁碟空間 。
1.3、索引分類☆
- 從功能邏輯上劃分,索引主要有 4 種,分別是
普通索引、唯一索引、主鍵索引、全文索引。 - 按照作用欄位個數劃分,索引可以分為
單列索引和聯合索引。 - 按照物理實現方式劃分 ,索引可以分為 2 種,分別是
聚簇索引和非聚簇索引。
2、樹
2.1、二叉樹
二叉樹
樹有很多種,每個節點最多只能有兩個子節點的一種形式稱為二叉樹。二叉樹的子節點分為左節點和右節點。
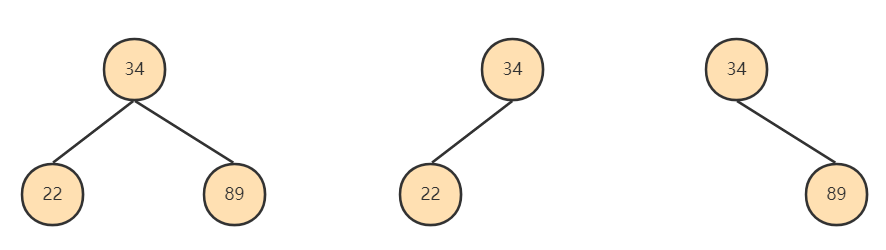
二叉搜索樹BST
BST(Binary Sort(Search) Tree):對於二叉排序樹的任何一個非葉子節點,要求左子節點的值比當前節點的值小,右子節點的值比當前節點的值大。
特別說明:如果有相同的值,可以將該節點放在左子節點或右子節點。
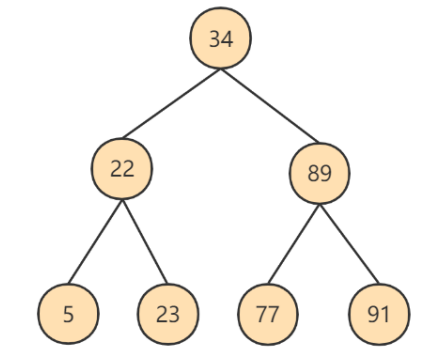
BST的生成演示:https://www.cs.usfca.edu/~galles/visualization/BST.html
下圖就是一種可能的索引方式示例:
- 左邊是數據表,一共有兩列七條記錄,最左邊的是數據記錄的物理地址:
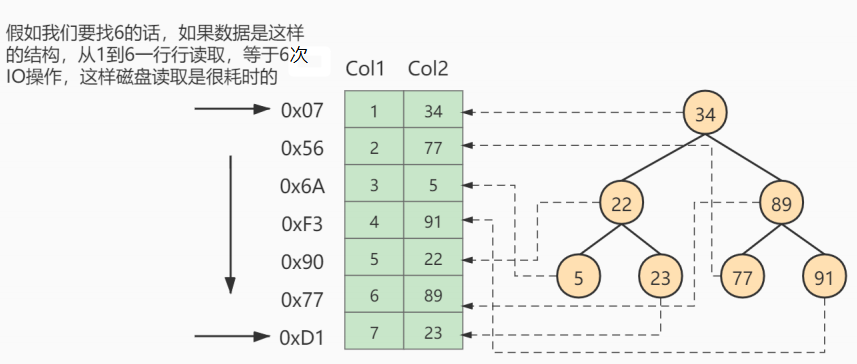
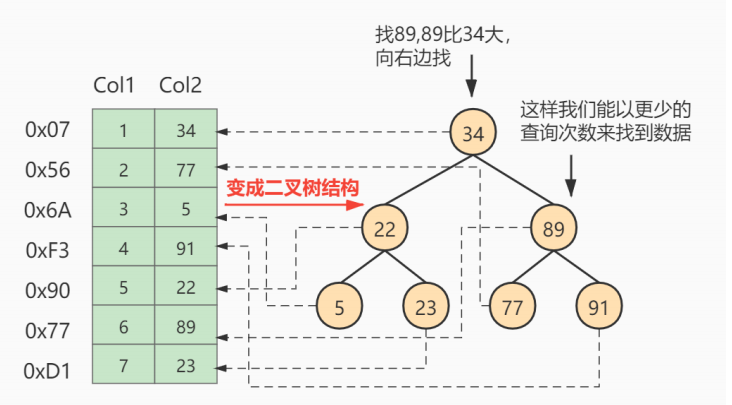
- 為了加快Col2的查找,可以維護一個右邊所示的二叉查找樹,每個節點分別包含索引鍵值和一個指向對應數據記錄物理地址的指針,這樣就可以運用二叉查找獲取到相應數據,從而快速的檢索出符合條件的記錄:
BST的問題
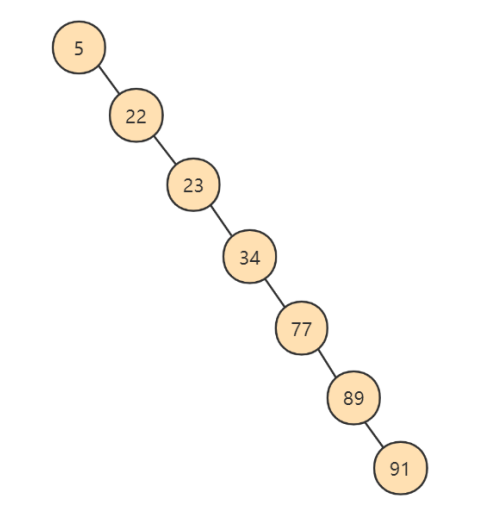
- 上面演示的實際上是一個特殊的
二叉搜索樹,叫做平衡 二叉搜索樹, 如果二叉樹不平衡,例如左子樹全部為空,從形式上看,更像一個單鏈表,不能發揮BST的優勢。 解決方案:平衡二叉樹(AVL)
平衡二叉樹(AVL)
AVL樹全稱G.M. Adelson-Velsky和E.M. Landis,這是兩個人的人名。
平衡二叉樹也叫平衡二叉搜索樹(Self-balancing binary search tree)又被稱為AVL樹, 可以保證查詢效率較高。
具有以下特點:
- 它是一棵空樹或它的左右兩個子樹的高度差的絕對值不超過1
- 並且左右兩個子樹都是一棵平衡二叉樹。
AVL的生成演示:https://www.cs.usfca.edu/~galles/visualization/AVLtree.html
AVL的問題
眾所周知,IO操作的效率很低,在大量數據存儲中,查詢時我們不能一下子將所有數據載入到記憶體中,只能逐節點載入(一個節點一次IO)。如果我們利用二叉樹作為索引結構,那麼磁碟的IO次數和索引樹的高度是相關的。平衡二叉樹由於樹深度過大而造成磁碟IO讀寫過於頻繁,進而導致效率低下。
為了提高查詢效率,就需要 減少磁碟IO數 。為了減少磁碟IO的次數,就需要儘量降低樹的高度 ,需要把原來“瘦高”的樹結構變的“矮胖”,樹的每層的分叉越多越好。針對同樣的數據,如果我們把二叉樹改成 三叉樹:
上面的例子中,我們將二叉樹變成了三叉樹,降低了樹的高度。如果能夠在一個節點中存放更多的數據,我們還可以進一步減少節點的數量,從而進一步降低樹的高度。這就是多叉樹。
2.2、B樹
B-Tree即B樹,Balance Tree,平衡樹,B樹就是典型的多叉樹,它的高度遠小於平衡二叉樹的高度。B樹的階:節點的最多子節點個數。
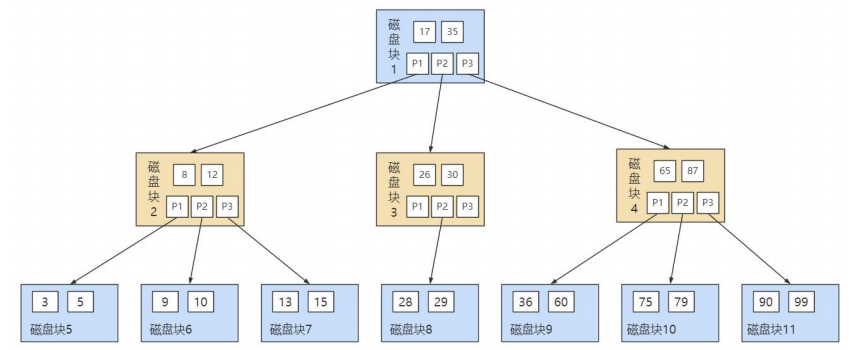
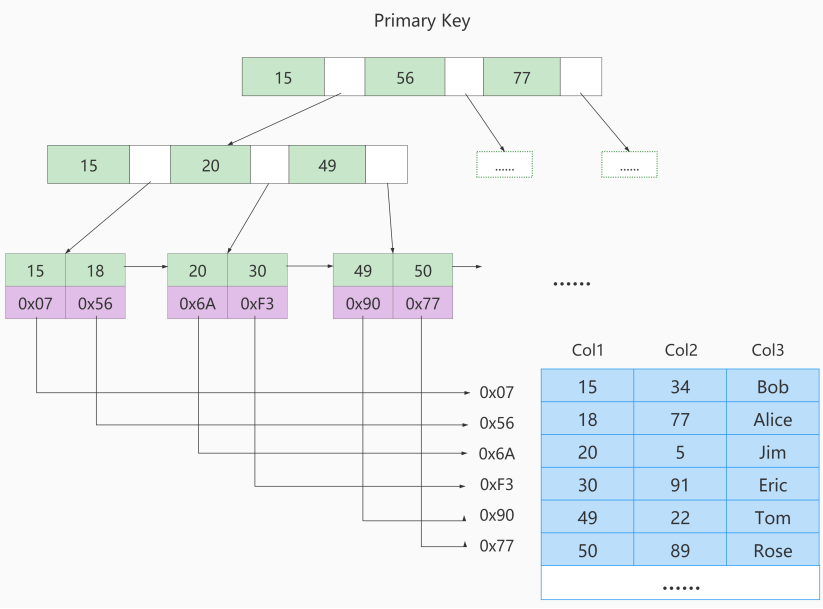
上圖所表示的 B 樹就是一棵 3 階的 B 樹。假設一個磁碟塊可以存儲一個節點的數據。我們可以看下磁碟塊 2,裡面的關鍵字為(8,12),它有 3 個孩子 (3,5),(9,10) 和 (13,15),你能看到 (3,5) 小於 8,(9,10) 在 8 和 12 之間,而 (13,15)大於 12,三節點的子樹的值大小仍然遵守 BST 二叉排序樹的規則。
假設我們想要 查找的數據項是 9 ,那麼步驟可以分為以下幾步:
- 第一次磁碟IO:找到根節點磁碟塊1,讀入記憶體,執行二分查找,9 小於 17 ,得到指針 P1;
- 第二次磁碟IO:按照指針P1找到磁碟塊 2,讀入記憶體,執行二分查找, 9 在 8 和 12 之間,得到指針 P2;
- 第三次磁碟IO:按照指針P2找到磁碟塊 6,讀入記憶體,執行二分查找, 找到了數據項 9。
你能看出來在 B 樹的搜索過程中,我們比較的次數並不少,但如果把數據讀取出來然後在記憶體中進行比較,這個時間就是可以忽略不計的。而讀取磁碟塊本身需要進行 I/O 操作,消耗的時間比在記憶體中進行比較所需要的時間要多,是數據查找用時的重要因素。 B 樹相比於平衡二叉樹來說磁碟 I/O 操作要少 ,在數據查詢中比平衡二叉樹效率要高。所以只要樹的高度足夠低,IO次數足夠少,就可以提高查詢性能 。
再舉例:
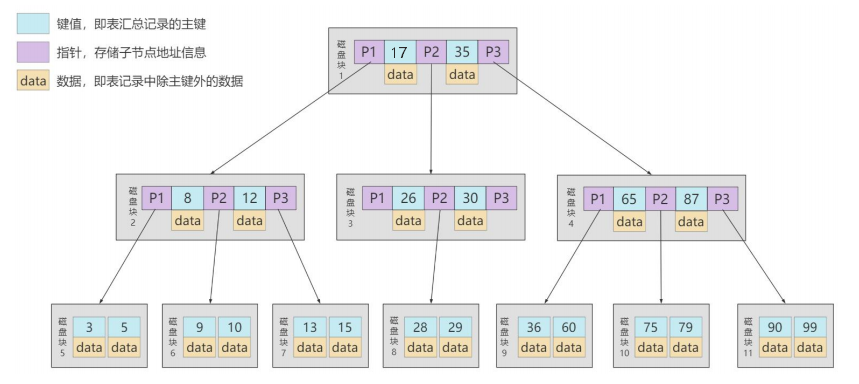
假設使用B樹作為索引結構,存放MySQL中的數據:
藍色部分表示數據的主鍵,黃色部分表示除主鍵外的其他數據,紫色部分表示指向子節點的指針
3、MySQL的索引結構:B+tree
3.1、InnoDB中的索引
3.1.1、設計索引
假設有一個表index_demo,表中有2個INT類型的列,1個CHAR(1)類型的列,c1列為主鍵:
CREATE TABLE index_demo(c1 INT,c2 INT,c3 CHAR(1),PRIMARY KEY(c1)) ;
index_demo表的簡化的行格式示意圖如下:
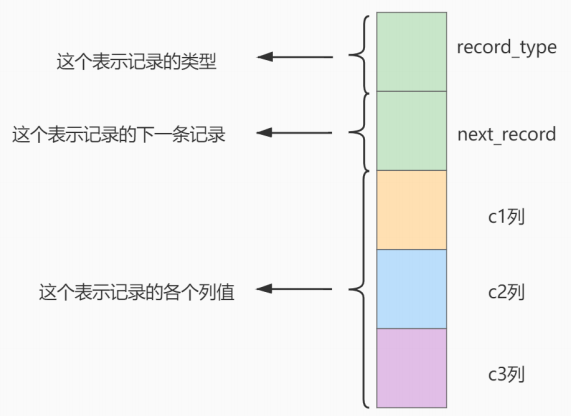
record_type:表示記錄的類型, 0是普通記錄、 2是最小記錄、 3 是最大記錄、1是B+樹非葉子節點記錄。next_record:表示下一條記錄的相對位置,我們用箭頭來表明下一條記錄。各個列的值:這裡只記錄在 index_demo 表中的三個列,分別是 c1 、 c2 和 c3 。
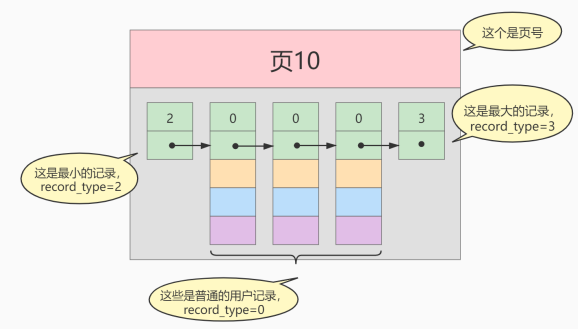
把一些記錄放到頁里的示意圖就是(這裡一頁就是一個磁碟塊,代表一次IO):
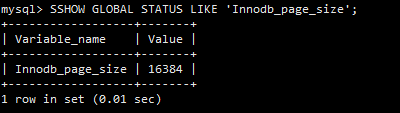
MySQL InnoDB的預設的頁大小是16KB:
-- 查看預設頁的大小
SHOW GLOBAL STATUS LIKE 'Innodb_page_size';
因此數據存儲在磁碟中,可能會占用多個數據頁。如果各個頁中的記錄沒有規律,我們就不得不依次遍歷所有的數據頁。如果我們想快速的定位到需要查找的記錄在哪些數據頁中,我們可以這樣做 :
下一個數據頁中用戶記錄的主鍵值必須大於上一個頁中用戶記錄的主鍵值- 給所有的頁建立目錄項
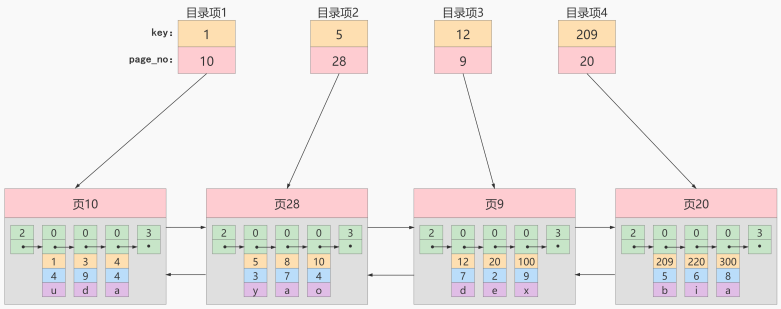
以頁28為例,它對應目錄項2 ,這個目錄項中包含著該頁的頁號28以及該頁中用戶記錄的最小主鍵值 5。我們只需要把幾個目錄項在物理存儲器上連續存儲(比如:數組),就可以實現根據主鍵值快速查找某條記錄的功能了。比如:查找主鍵值為 20 的記錄,具體查找過程分兩步:
- 先從目錄項中根據二分法快速確定出
主鍵值為20的記錄在目錄項3中(因為 12 ≤ 20 < 209 ),對應頁9。 - 再到頁9中根據二分法快速定位到主鍵值為 20 的用戶記錄。
至此,針對數據頁做的簡易目錄就搞定了。這個目錄有一個別名,稱為索引 。
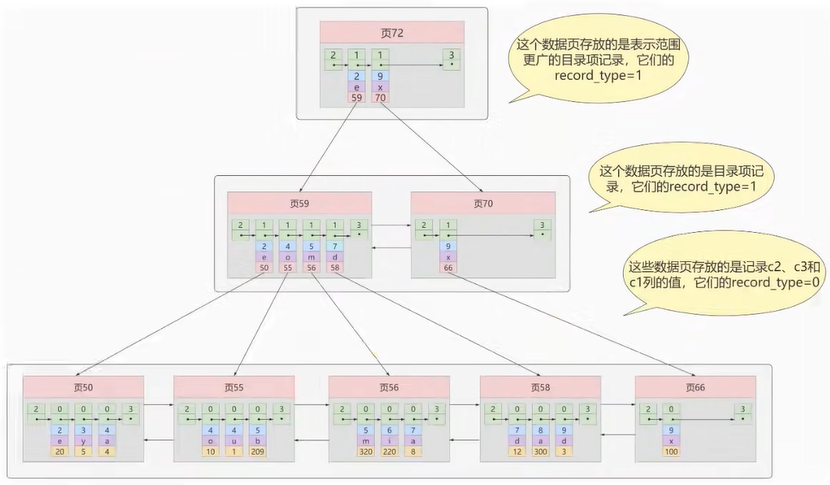
3.1.2、InnoDB中的索引方案
我們新分配一個編號為30的頁來專門存儲目錄項記錄,頁10、28、9、20專門存儲用戶記錄:
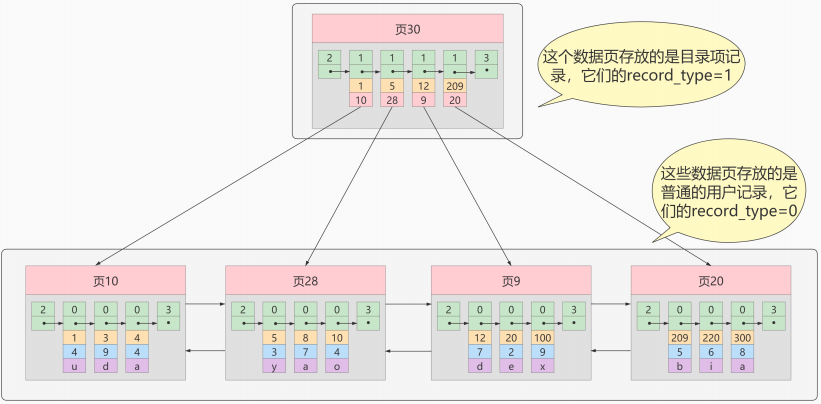
目錄項記錄和普通的用戶記錄的不同點:
- 目錄項記錄 的 record_type 值是1,而 普通用戶記錄 的 record_type 值是0。
- 目錄項記錄只有主鍵值和頁的編號兩個列,而普通的用戶記錄的列是用戶自己定義的,包含很多列,另外還有InnoDB自己添加的隱藏列。
現在查找主鍵值為 20 的記錄,具體查找過程分兩步:
- 先到頁30中通過二分法快速定位到對應目錄項,因為 12 ≤ 20 < 209 ,就是頁9。
- 再到頁9中根據二分法快速定位到主鍵值為 20 的用戶記錄。
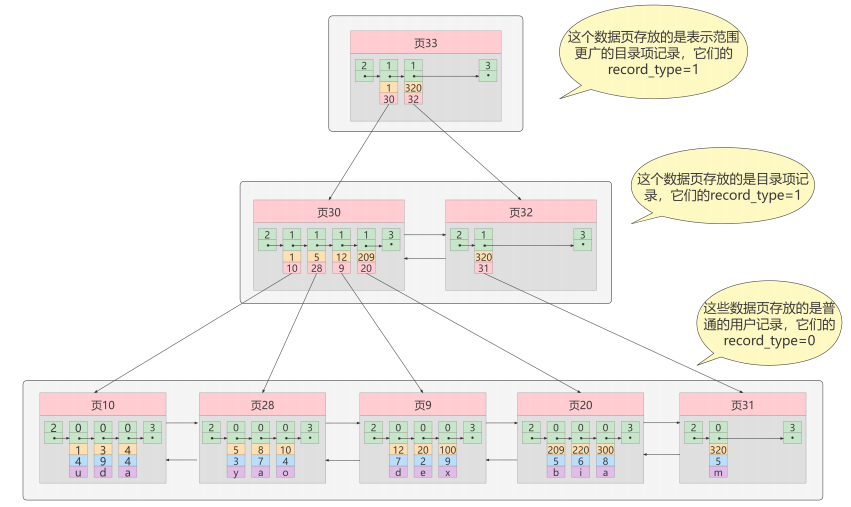
更複雜的情況如下:
我們生成了一個存儲更高級目錄項的 頁33 ,這個頁中的兩條記錄分別代表頁30和頁32,如果用戶記錄的主鍵值在 [1, 320) 之間,則到頁30中查找更詳細的目錄項記錄,如果主鍵值 不小於320 的話,就到頁32中查找更詳細的目錄項記錄。這個數據結構,它的名稱是 B+樹 。
3.2、B樹和B+樹對比☆
B+ 樹和 B 樹的差異:
-
B+樹中非葉子節點僅用於索引,不保存數據記錄,跟記錄有關的信息都放在葉子節點中。而B樹中, 非葉子節點既保存索引,也保存數據記錄 。
-
B+樹中所有關鍵字都在葉子節點出現,葉子節點構成一個有序鏈表,而且葉子節點本身按照關鍵字的大小從小到大順序鏈接。
-
B+樹中非葉子節點的關鍵字也會同時存在於子節點中,並且是在子節點中所有關鍵字的最小值。
B+樹為什麼IO的次數會更少:
真實環境中一個頁存放的記錄數量是非常大的(預設16KB),假設指針與鍵值占大約10位元組,數據占 1 kb 的空間:- 如果B+樹只有1層,也就是只有1個用於存放用戶記錄的節點,則最多能存放 16 條記錄。
- 如果B+樹有2層,最多能存放約
1600×16=25600條記錄。 - 如果B+樹有3層,最多能存放約
1600×1600×16=40960000條記錄。 - 如果存儲千萬級別的數據,只需要三層就夠了
B+樹的非葉子節點不存儲用戶記錄,只存儲目錄記錄,相對B樹每個節點可以存儲更多的記錄,樹的高度會更矮胖,IO次數也會更少。
3.3、聚簇索引☆
特點:
-
索引和數據保存在同一個B+樹中 -
頁內的記錄是按照主鍵的大小順序排成一個單向鏈表。 -
頁和頁之間也是根據頁中記錄的主鍵的大小順序排成一個雙向鏈表。 -
非葉子節點存儲的是記錄的
主鍵+頁號。 -
葉子節點存儲的是
完整的用戶記錄。
優點:
- 數據訪問更快 ,因為
索引和數據保存在同一個B+樹中,因此從聚簇索引中獲取數據比非聚簇索引更快。 - 聚簇索引對於主鍵的
排序查找和範圍查找速度非常快。 - 按照聚簇索引排列順序,查詢顯示一定範圍數據的時候,由於
數據都是緊密相連,資料庫可以從更少的數據塊中提取數據,節省了大量的IO操作。
缺點:
- 插入速度嚴重依賴於插入順序 ,按照主鍵的順序插入是最快的方式,否則將會出現頁分裂,嚴重影響性能。因此,對於InnoDB表,我們一般都會定義一個
自增的ID列為主鍵。 - 更新主鍵的代價很高 ,因為將會導致被更新的行移動。因此,對於InnoDB表,我們一般定義
主鍵為不可更新。
限制:
- 只有InnoDB引擎支持聚簇索引,
MyISAM不支持聚簇索引。 - 由於數據的物理存儲排序方式只能有一種,所以
每個MySQL的表只能有一個聚簇索引。 - 如果沒有為表定義主鍵,InnoDB會選擇
非空的唯一索引列代替。如果沒有這樣的列,InnoDB會隱式的定義一個主鍵作為聚簇索引。 - 為了充分利用聚簇索引的聚簇特性,InnoDB中表的
主鍵應選擇有序的id,不建議使用無序的id,比如UUID、MD5、HASH、字元串作為主鍵,無法保證數據的順序增長。
3.4、非聚簇索引☆
(二級索引、輔助索引)
聚簇索引,只能在搜索條件是主鍵值時才發揮作用,因為B+樹中的數據都是按照主鍵進行排序的,如果我們想以別的列作為搜索條件,那麼需要創建非聚簇索引。
例如,以c2列作為搜索條件,那麼需要使用c2列創建一棵B+樹,如下所示:
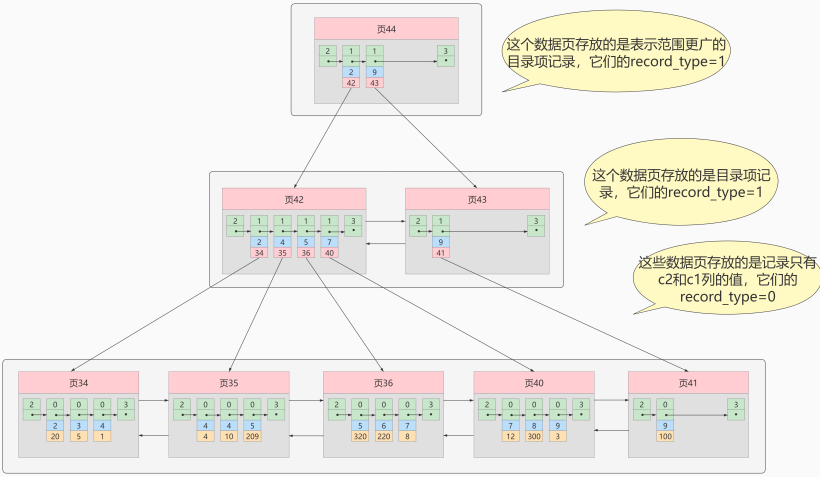
這個B+樹與聚簇索引有幾處不同:
-
頁內的記錄是按照從c2列的大小順序排成一個單向鏈表。 -
頁和頁之間也是根據頁中記錄的c2列的大小順序排成一個雙向鏈表。 -
非葉子節點存儲的是記錄的
c2列+頁號。 -
葉子節點存儲的並不是完整的用戶記錄,而只是
c2列+主鍵這兩個列的值。
例如:根據c2列的值查找c2=4的記錄,查找過程如下:
- 根據
根頁面44定位到頁42(因為2 ≤ 4 < 9) - 由於
c2列沒有唯一性約束,所以c2=4的記錄可能分佈在多個數據頁中,又因為2 ≤ 4 ≤ 4,所以確定實際存儲用戶記錄的頁在頁34和頁35中。 - 在頁34和35中
定位到具體的記錄。 - 但是這個B+樹的葉子節點
只存儲了c2和c1(主鍵)兩個列,所以我們必須再根據主鍵值去聚簇索引中再查找一遍完整的用戶記錄。
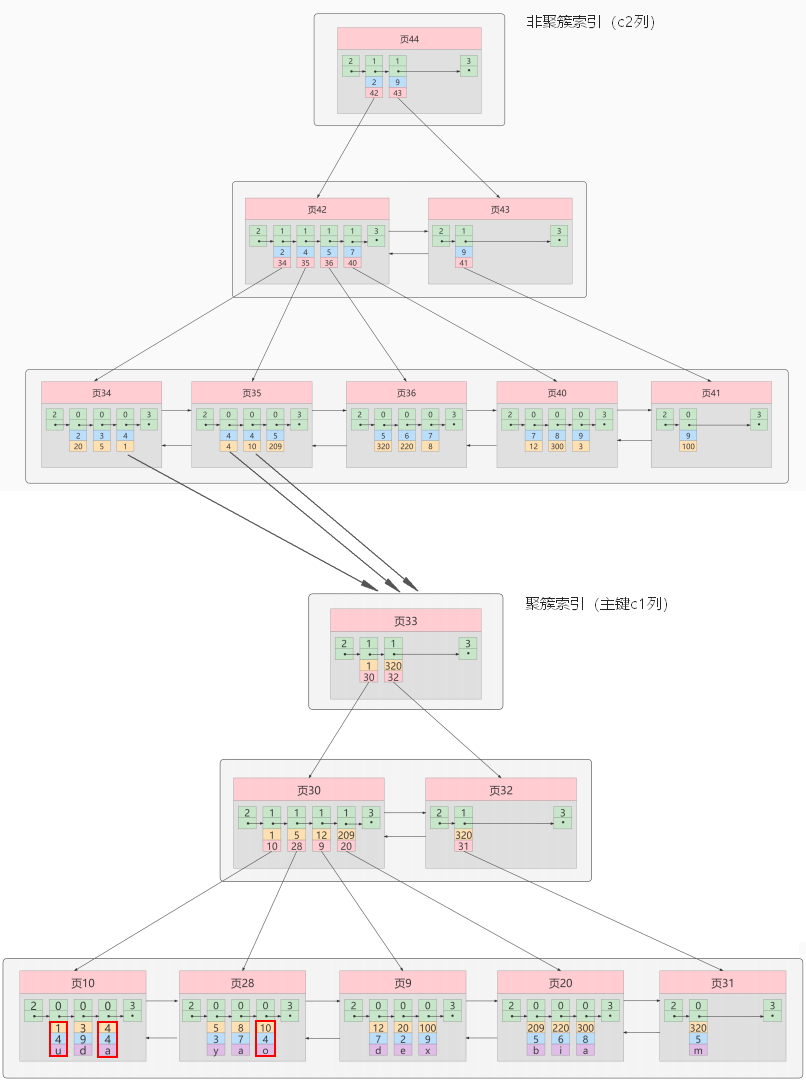
概念:回表
我們根據這個以c2列大小排序的B+樹只能確定我們要查找記錄的主鍵值,所以如果我們想根據c2列的值查找到完整的用戶記錄的話,仍然需要到聚簇索引中再查一遍,這個過程稱為回表 。也就是根據c2列的值查詢一條完整的用戶記錄需要使用到 2棵B+樹!
問題:
為什麼我們還需要一次回表操作呢?直接把完整的用戶記錄放到葉子節點不OK嗎?
回答:
如果把完整的用戶記錄放到葉子節點是可以不用回表。但是太占地方了,相當於每建立一棵B+樹都需要把所有的用戶記錄再都拷貝一遍,這就有點太浪費存儲空間了。
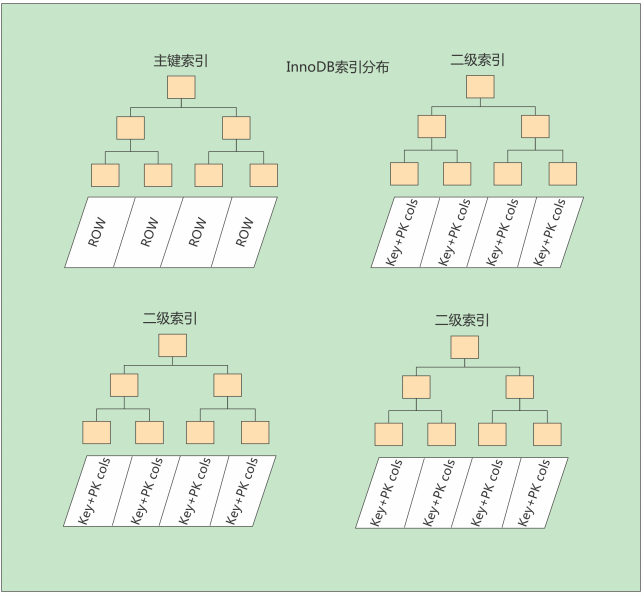
一張表可以有多個非聚簇索引:
3.5、聯合索引
為c2和c3列建立聯合索引:
-
各個頁中的記錄按照
c2列進行排序。 -
在記錄的
c2列相同的情況下,採用c3列進行排序 -
B+樹葉子節點處的記錄由
c2列、c3列和主鍵c1列組成 -
本質上也是二級索引
3.6、覆蓋索引☆
如果能通過讀取索引就可以得到想要的數據,那就不需要讀取用戶記錄,或者不用再做回表操作了。一個索引包含了滿足查詢結果的數據就叫做覆蓋索引。
例如,如果為前面例子中的資料庫表創建c2列索引,則如下SQL會使用覆蓋索引
SELECT c1, c2 from index_demo where c2 = 5;
3.7、MyISAM中的索引☆
MyISAM引擎使用 B+Tree 作為索引結構,葉子節點的data域存放的是數據記錄的地址 。
下圖是MyISAM索引的原理圖(索引和數據分開存儲,是非聚簇索引):
如果我們在Col2上建立一個二級索引,則此索引的結構如下圖所示(是非聚簇索引):
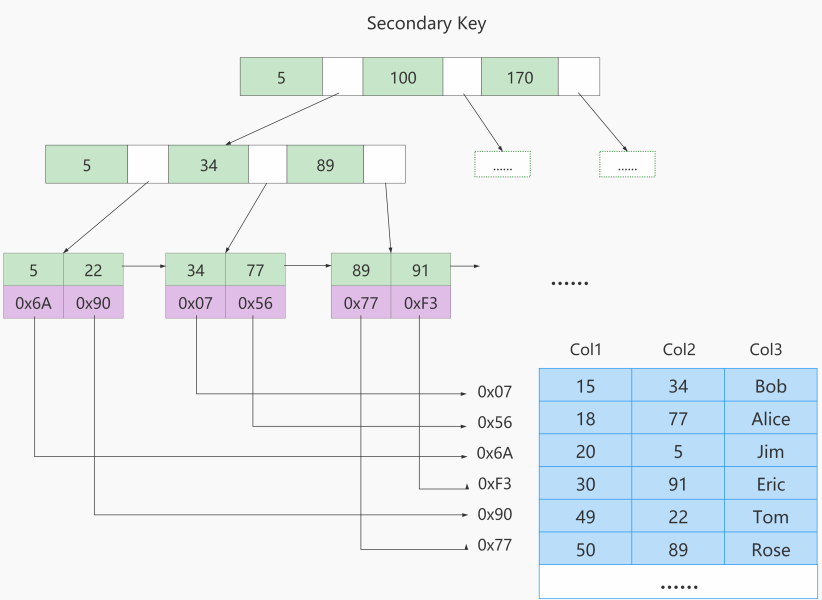
3.8、MyISAM與InnoDB對比☆
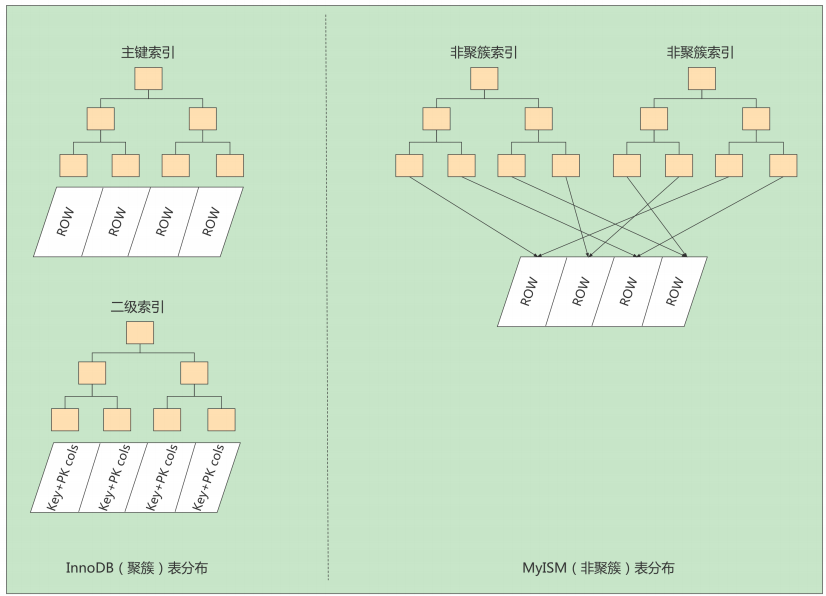
-
InnoDB的數據文件本身就是索引文件,而MyISAM索引文件和數據文件是分離的:
- InnoDB的表在磁碟上存儲在以下文件中:
.ibd(表結構、索引和數據都存在一起,MySQL5.7表結構放在.frm中) - MyISAM的表在磁碟上存儲在以下文件中:
*.sdi(描述表結構,MySQL5.7是.frm)、*.MYD(數據),*.MYI(索引)
- InnoDB的表在磁碟上存儲在以下文件中:
-
InnoDB中主鍵索引是聚簇索引,葉子節點中存儲完整的數據記錄;其他索引是非聚簇索引,存儲相應記錄主鍵的值 。
-
InnoDB要求表必須有主鍵 ( MyISAM可以沒有 )。如果沒有顯式指定,則MySQL系統會自動選擇一個可以
非空且唯一標識數據記錄的列作為主鍵。如果不存在這種列,則MySQL自動為InnoDB表生成一個隱含欄位作為主鍵。 -
MyISAM中無論是主鍵索引還是非主鍵索引都是非聚簇的,葉子節點記錄的是數據的地址。
-
MyISAM的回表操作是十分快速的,因為是拿著地址偏移量直接到文件中取數據的,反觀InnoDB是通過獲取主鍵之後再去聚簇索引里找記錄,雖然說也不慢,但還是比不上直接用地址去訪問。
4、索引操作
4.1、創建索引
- 隨表一起創建索引:
CREATE TABLE customer (
id INT UNSIGNED AUTO_INCREMENT,
customer_no VARCHAR(200),
customer_name VARCHAR(200),
PRIMARY KEY(id), -- 主鍵索引:列設定為主鍵後會自動建立索引,唯一且不能為空。
UNIQUE INDEX uk_no (customer_no), -- 唯一索引:索引列值必須唯一,允許有NULL值,且NULL可能會出現多次。
KEY idx_name (customer_name), -- 普通索引:既不是主鍵,列值也不需要唯一,單純的為了提高查詢速度而創建。
KEY idx_no_name (customer_no,customer_name) -- 複合索引:即一個索引包含多個列。
);
- 單獨建創索引:
CREATE TABLE customer1 (
id INT UNSIGNED,
customer_no VARCHAR(200),
customer_name VARCHAR(200)
);
-- 建表後創建索引
ALTER TABLE customer1 ADD PRIMARY KEY customer1(id); -- 主鍵索引
CREATE UNIQUE INDEX uk_no ON customer1(customer_no); -- 唯一索引
CREATE INDEX idx_name ON customer1(customer_name); -- 普通索引
CREATE INDEX idx_no_name ON customer1(customer_no,customer_name); -- 複合索引
ALTER TABLE customer1 MODIFY id INT UNSIGNED AUTO_INCREMENT, ADD PRIMARY KEY customer1(id); --創建自增的主鍵索引
- 使用ALTER命令:
ALTER TABLE customer1 ADD PRIMARY KEY (id); -- 主鍵索引
ALTER TABLE customer1 ADD UNIQUE INDEX uk_no (customer_no); -- 唯一索引
ALTER TABLE customer1 ADD INDEX idx_name (customer_name); -- 普通索引
ALTER TABLE customer1 ADD INDEX idx_no_name (customer_no,customer_name); -- 複合索引
4.2、查看索引
SHOW INDEX FROM customer;
4.3、刪除索引
DROP INDEX idx_name ON customer; -- 刪除單值、唯一、複合索引
ALTER TABLE customer MODIFY id INT UNSIGNED, DROP PRIMARY KEY; -- 刪除主鍵索引(有主鍵自增)
ALTER TABLE customer1 DROP PRIMARY KEY; -- 刪除主鍵索引(沒有主鍵自增)
5、索引的使用場景☆
哪些情況適合創建索引:
-
頻繁作為WHERE查詢條件的欄位
-
經常GROUP BY 和 ORDER BY的列
-
欄位的值有唯一性的限制
-
DISTINCT欄位需要創建索引
-
多表JOIN時,對連接欄位創建索引
-
使用字元串首碼創建索引
例如一個欄位 address varchar(120),我們可以創建索引的長度為(12)個字元,節省索引空間
-
區分度高的列(重覆的數據少)適合作為索引
-
使用頻繁的列,放到聯合索引的左側
哪些情況不要創建索引:
- WHERE、GROUP BY 、ORDER BY里用不到的欄位不創建索引
- 表的數據記錄太少
- 有大量重覆數據的列上
- 避免對經常增刪改的表創建索引
- 不要定義冗餘或重覆的索引
第05章 索引優化
1、資料庫優化方案
問題:
哪些方法可以進行資料庫調優?
解決方案:
-
索引失效,沒有充分利用到索引:
索引建立 -
關聯查詢太多JOIN(設計缺陷或不得已的需求):
SQL優化 -
數據過多:分庫分表
-
伺服器調優及各個參數設置(緩衝、線程數等):調整my.cnf
2、性能分析(EXPLAIN)
2.1、EXPLAIN是什麼
查看SQL執行計劃:使用EXPLAIN關鍵字可以模擬優化器執行SQL查詢語句,從而知道MySQL是如何處理你的SQL語句的。分析你的查詢語句或是表結構的性能瓶頸。
用法:
EXPLAIN + SQL語句
2.2、數據準備
USE atguigudb;
CREATE TABLE t1(id INT(10) AUTO_INCREMENT, content VARCHAR(100) NULL, PRIMARY KEY (id));
CREATE TABLE t2(id INT(10) AUTO_INCREMENT, content VARCHAR(100) NULL, PRIMARY KEY (id));
CREATE TABLE t3(id INT(10) AUTO_INCREMENT, content VARCHAR(100) NULL, PRIMARY KEY (id));
CREATE TABLE t4(id INT(10) AUTO_INCREMENT, content1 VARCHAR(100) NULL, content2 VARCHAR(100) NULL, PRIMARY KEY (id));
CREATE INDEX idx_content1 ON t4(content1); -- 創建普通索引
# 以下新增sql多執行幾次,以便演示
INSERT INTO t1(content) VALUES(CONCAT('t1_',FLOOR(1+RAND()*1000)));
INSERT INTO t2(content) VALUES(CONCAT('t2_',FLOOR(1+RAND()*1000)));
INSERT INTO t3(content) VALUES(CONCAT('t3_',FLOOR(1+RAND()*1000)));
INSERT INTO t4(content1, content2) VALUES(CONCAT('t4_',FLOOR(1+RAND()*1000)), CONCAT('t4_',FLOOR(1+RAND()*1000)));
2.3、各欄位解釋
2.3.1、table
- 單表:顯示這一行的數據是關於哪張表的
EXPLAIN SELECT * FROM t1;

- 多表:關聯查詢中,顯示在執行計劃第一行的是驅動表,第二行是被驅動表
EXPLAIN SELECT * FROM t1, t2 WHERE t1.id = t2.id;

2.3.2、id
在一個完整的查詢語句中,每個SELECT關鍵字,都對應一個唯一的id。同時通過id也可以知道操作表的順序。
- id相同:一個SELECT,id都是1
EXPLAIN SELECT * FROM t1, t2, t3;

- id不同:三個SELECT,id是1、2、3
EXPLAIN SELECT t1.id FROM t1 WHERE t1.id =(
SELECT t2.id FROM t2 WHERE t2.id =(
SELECT t3.id FROM t3 WHERE t3.content = '000'
)
);
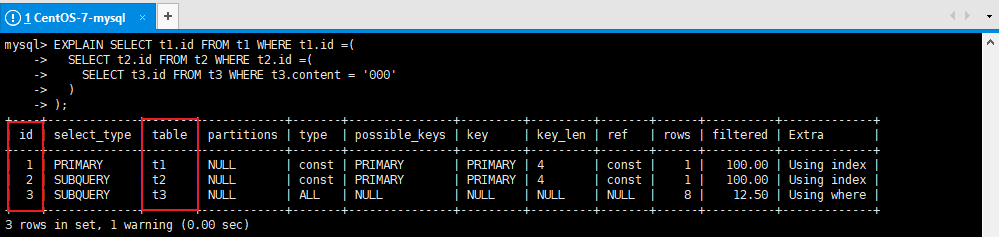
註意:如果t3表查詢無結果,則table列t1和t2處為NULL
註意:查詢優化器可能對涉及子查詢的語句進行優化,轉為連接查詢
EXPLAIN SELECT * FROM t1 WHERE content IN (SELECT content FROM t2 WHERE content = 'a');

- id為NULL:把t1和t2的查詢結果合併,並創建名為<union1,2>的臨時表,然後對結果去重
EXPLAIN SELECT * FROM t1 UNION SELECT * FROM t2;

因此包含UNION ALL的執行計劃中就沒有這條記錄
EXPLAIN SELECT * FROM t1 UNION ALL SELECT * FROM t2;

小結:
- id如果相同,可以認為是一組,
從上往下順序執行 - 在所有組中,
id值越大,越先執行 - 關註點:每個id號碼,表示一趟獨立的查詢,
一個sql的查詢趟數越少越好
2.3.3、select_type
查詢的類型,主要是用於區別普通查詢、聯合查詢、子查詢等的複雜查詢。
- SIMPLE:簡單查詢。查詢中不包含子查詢或者UNION。
EXPLAIN SELECT * FROM t1;

- PRIMARY:主查詢。查詢中若包含子查詢,則最外層查詢被標記為PRIMARY。
- SUBQUERY:子查詢。在SELECT或WHERE列表中包含了子查詢。
EXPLAIN SELECT * FROM t3 WHERE id = ( SELECT id FROM t2 WHERE content= 'a');

- DEPENDENT SUBQUREY:如果包含了子查詢,並且查詢語句不能被優化器轉換為連接查詢,並且子查詢是
相關子查詢(子查詢基於外部數據列),則子查詢就是DEPENDENT SUBQUREY。
EXPLAIN SELECT * FROM t3 WHERE id = ( SELECT id FROM t2 WHERE content = t3.content);


