
很多小微型應用程式也需要一些數據處理和計算能力,如果集成一個資料庫就顯得太沉重了,這種情況下 SQLite 是一個不錯的選擇,它架構簡單,集成方便,可持久化存儲數據,並提供 SQL 實現計算能力。 但是,對於某些較複雜的場景,SQLite 仍有不足之處。 ...

數據源支持
複雜計算
select * from (select *, row_number() over (partition by Client order by Amount desc) as row_number from Orders) where row_number<=3
select max(continuousdays)
from (
select count(*) continuousdays
from (
select sum(risingflag) over (order by day) norisingdays
from (
select day, case when price>lag(price) over (order by day) then 0 else 1 end risingflag
from tbl
)
) group by norisingdays
)SQL 很難直接表達連續上漲的概念,只能換個方法變相實現,即通過累計不漲天數來計算連續上漲天數,這種方法技巧性強,編寫難度大且不易理解。而且 SQL 難以調試,導致維護困難。
with A as
(select client,amount,row_number() over (order by amount) ranknumber
from sales)
select client,amount
from (select client,amount,sum(amount) over (order by ranknumber) acc
from A)
where acc>(select sum(amount)/2 from sales)
order by amount desSQL 很難處理恰好要過線的客戶,只能換個方法變相實現,即計算銷售額從小到大的累計值,反過來找出累計值不在後一半的客戶。這種方法技巧性強,代碼冗長,而且難以調試。
流程處理
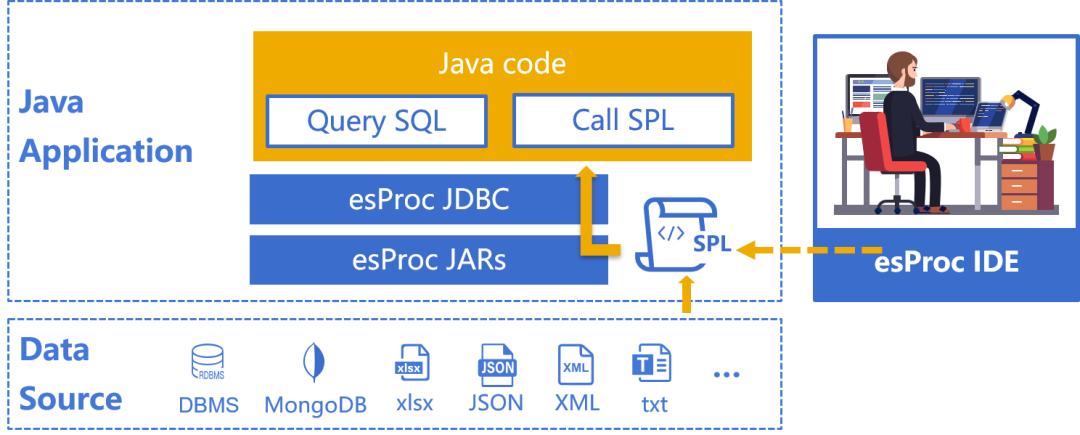
Class.forName("com.esproc.jdbc.InternalDriver");
Connection conn =DriverManager.getConnection("jdbc:esproc:local://");
Statement statement = conn.createStatement();
ResultSet result = statement.executeQuery("=T(\"D:/Orders.csv\").select(Amount>1000 && like(Client,\"*s*\"))");SPL 支持數據持久化,可以將數據保存到自有數據格式(集文件)中,比如批量新增記錄:
| A | |
| 1 | =create(OrderID,Client,SellerID,Amount,OrderDate) |
| 2 |
=A1.record([201,"HDR",9,2100.0,date("2021-01-01"), 203,"APPLE",4,1900,date("2021-01-03")]) |
| 3 | =file("d:/Orders.btx").export@ab(A2) |
除了直接持久化,也可以先處理記憶體中的序表(SPL 的結構化數據對象,可類比為 SQL 結果集),再將序表覆蓋寫入集文件,具體做法是將 export@ab 改為 export@b。這種方式性能不如 SQLite,但小微型應用的數據量普遍不大,覆寫的速度通常可接受。
組表是 SPL 的另一種自有數據格式,支持高性能批量增刪改,適用於大數據量高性能計算(這不是本文重點)。
除了自有格式,SPL 也可以將數據保存到 csv 文件中,只要把 A3 改為:
file("d:/Orders.csv").export@tc(A2)
SPL 有足夠的計算能力,支持各類 SQL 式計算,包括分組後計算(視窗函數):
| A | B | |
| 1 | =Orders.new(Client,Amount) | // 選出部分欄位 |
| 2 | =Orders.select(Amount>1000 && like(Client,\"*s*\")) | // 模糊查詢 |
| 3 | = Orders.sort(Client,-Amount) | // 排序 |
| 4 | = Orders.id(Client) | // 去重 |
| 5 | =Orders.groups(year(OrderDate):y,Client;sum(Amount):amt).select(amt>3000) | // 分組彙總 |
| 6 | =[Orders.select(Amount>3000),A1.select(year(OrderDate)==2009)].union() | // 並集 |
| 7 | =Orders.groups(year(OrderDate):y,Client;sum(Amount):amt).select(like(Client,\"*s*\")) | // 子查詢 |
| 8 | =A5.derive(amt/amt[-1]-1: rate) | // 跨行 |
SPL 提供了基本的 SQL 語法,比如分組彙總:
$select year(OrderDate) y,month(OrderDate) m, sum(Amount) s,count(1) c from {Orders} Where Amount>=? and Amount<? ;arg1,arg2數據源支持
SPL 讀取 csv 文件只需一步,在 Java 里嵌入下麵的 SPL 代碼:T("d:/Orders.csv").select(Amount>2000 && Amount<=3000)
json(file("d:/xml/emp_orders.json").read()).select(Amount>2000 && Amount<=3000)
json(httpfile("http://127.0.0.1:6868/api/orders").read()).select(Amount>2000 && Amount<=3000)XML 文件:
| A | |
| 1 | =file("d:/xml/emp_orders.xml").read() |
| 2 | =xml(A1,"xml/row") |
| 3 | =A2.select(Amount>1000 && Amount<=2000 && like@c(Client,"*business*")) |
| A | |
| 1 | =ws_client("http://127.0.0.1:6868/ws/RQWebService.asmx?wsdl") |
| 2 | =ws_call(A1,"RQWebService":"RQWebServiceSoap":"getEmp_orders") |
| 3 | =A2.select(Amount>1000 && Amount<=2000 && like@c(Client,"*business*")) |
跨源計算
SPL 開放性較好,可以直接計算多種數據源,這些數據源可以和 SPL 集文件進行跨源計算。比如,對集文件和 csv 進行內關聯分組彙總:
join(T("d:/Orders.btx"):o,SellerId; T("d:/Emp.csv"):e,EId).groups(e.Dept;sum(o.Amont))
join@1(json(httpfile("http://127.0.0.1:6868/api/orders").read()):o,SellerId; T("d:/Emp.csv"):e,EId)
| A | |
| 1 | =Orders=json(httpfile("http://127.0.0.1:6868/api/orders").read()) |
| 2 | =Employees=T("d:/Emp.csv") |
| 3 | =join@1(Orders:o,SellerId;Employees:e,EId) |
任意數據源的持久化
file("d:/Orders.csv").export@t(A2) //csv文件
file("d:/Orders.xlsx").xlsexport@t(A2) //xls文件
file("d:/Orders.json").write(json(A2)) //json文件| A | B | |
| 1 | =connect("orcl") | / 連接外部 oracle |
| 2 | =T=A1.query("select * from salesR where SellerID=?",10) | / 批量查詢,序表 T |
| 3 | =NT=T.derive() | / 複製出新序表 NT |
| 4 | =NT.field("SELLERID",9) | / 批量修改新序表 |
| 5 | =A1.update(NT:T,sales;ORDERID) | / 持久化 |
資料庫的持久化以序表為媒介,其優點相當明顯:函數 update 可自動比對修改(增改刪)前後的序表,能夠方便地實現批量數據地持久化。
計算能力
Orders.group(Client).(~.top(3;Amount))
| A | |
| 1 | =tbl.sort(day) |
| 2 | =t=0,A1.max(t=if(price>price[-1],t+1,0)) |
再看個例子,求銷售額占到一半的前 n 個客戶:
| A | B | |
| 2 | =sales.sort(amount:-1) | / 銷售額逆序排序,可在 SQL 中完成 |
| 3 | =A2.cumulate(amount) | / 計算累計序列 |
| 4 | =A3.m(-1)/2 | / 最後的累計即總額 |
| 5 | =A3.pselect(~>=A4) | / 超過一半的位置 |
| 6 | =A2(to(A5)) | / 按位置取值 |
SPL 集合化成更徹底,可以用變數方便地表達集合,併在下一步用變數引用集合繼續計算,因此特別適合多步驟計算。將大問題分解為多個小步驟,可以方便地實現複雜的計算目標,代碼不僅簡短,而且易於理解。此外,多步驟計算天然支持調試,無形中提高了開發效率。
流程處理
| A | B | |
| 2 | … | |
| 3 | if T.AMOUNT>10000 | =T.BONUS=T.AMOUNT*0.05 |
| 4 | else if T.AMOUNT>=5000 && T.AMOUNT<10000 | =T.BONUS=T.AMOUNT*0.03 |
| 5 | else if T.AMOUNT>=2000 && T.AMOUNT<5000 | =T.BONUS=T.AMOUNT*0.02 |
| A | B | |
| 1 | =db=connect("db") | |
| 2 | =T=db.query@x("select * from sales where SellerID=? order by OrderDate",9) | |
| 3 | for T | =A3.BONUS=A3.BONUS+A3.AMOUNT*0.01 |
| 4 | =A3.CLIENT=CONCAT(LEFT(A3.CLIENT,4), "co.,ltd.") | |
| 5 | … | |
上述代碼之外,SPL 還有更多針對結構化數據的流程處理功能,可進一步提高開發效率,比如:每輪迴圈取一批而不是一條記錄;某欄位值變化時迴圈一輪。
Class.forName("com.esproc.jdbc.InternalDriver");
Connection conn =DriverManager.getConnection("jdbc:esproc:local://");
CallableStatement statement = conn.prepareCall("{call queryOrders()}");
statement.execute();GitHub:https://github.com/SPLWare/esProc
作者|GitHubDaily
本文來自博客園,作者:古道輕風,轉載請註明原文鏈接:https://www.cnblogs.com/88223100/p/A-database-artifact-that-works-better-than-SQLite.html

