
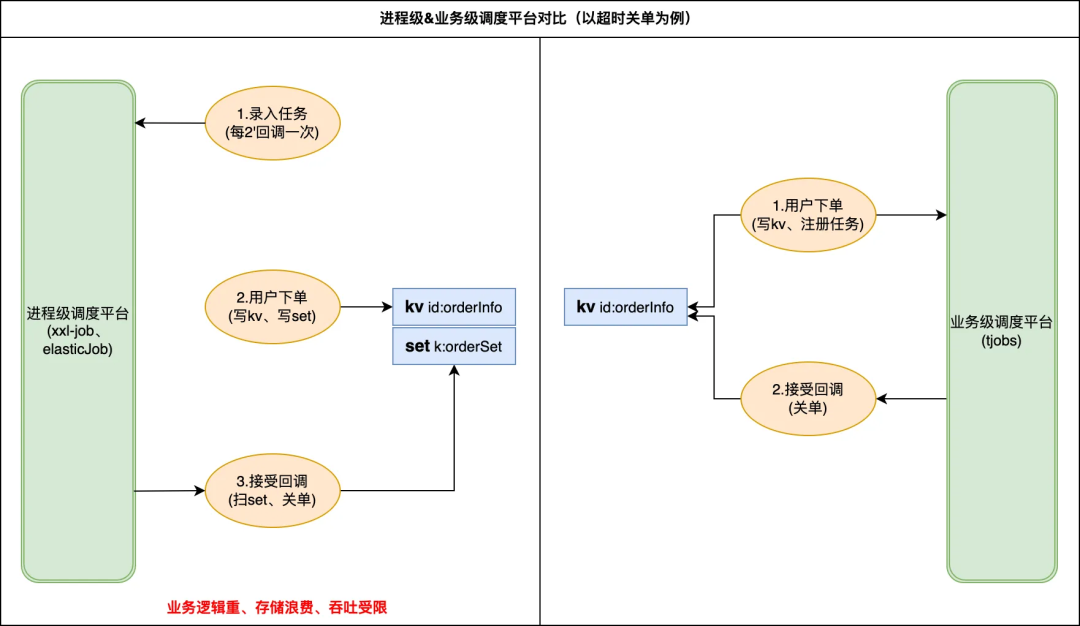
在日常開發中會經常遇到一些需要非同步定時執行的業務訴求,典型的使用場景如:超時未支付訂單關單、每隔 2h 更新好友排行榜、3.22 日 17 點《xx》劇上線等。目前業務側多基於以下思路來快速搭建一個調度系統,mysql 或者 redis 隊列存儲待執行任務,通過 crontab 定時觸發應用完成“撈... ...

背景
在日常開發中會經常遇到一些需要非同步定時執行的業務訴求,典型的使用場景如:超時未支付訂單關單、每隔 2h 更新好友排行榜、3.22 日 17 點《xx》劇上線等。目前業務側多基於以下思路來快速搭建一個調度系統,mysql 或者 redis 隊列存儲待執行任務,通過 crontab 定時觸發應用完成“撈取、計算、執行等操作”。不難看出存在幾類亟待解決問題:
1)缺少統一的調度平臺導致各業務重覆開發;
2)簡易版調度實現在任務吞吐、調度時效上缺少保障;
3)業務和調度數據強耦合存儲給線上穩定性引入大 key、慢 sql 風險。
目前存在多類開源解決方案如 XXL-Job 、 Elastic-Job、quartz 調度等,但這些都屬於進程級調度平臺,很難滿足更細粒度的業務調用。基於上述的業務訴求和司內現狀,我們準備搭建一套通用的分散式任務調度平臺(以下統稱為 tjobs 平臺)以滿足業務高可靠、低延遲的海量任務調度訴求。
整體設計
設計目標
旨在提供一個易用、可靠、高性能、低時延的海量任務管理、調度平臺,幫助開發工程師專註於面向業務編碼設計,而不再擔心定時任務的吞吐量、可靠性等非功能需求。由此衍生的功能和非功能訴求分別為:
功能性訴求:
任務管理:包括任務註冊、任務啟停、任務更新等,
任務查詢:主要用於任務追蹤、問題排查、調度統計等,
任務回調:由業務提供 spi 回調實現,tjobs 平臺定時調用觸發
非功能性訴求
tjobs 定位為高可靠、高性能、低延遲、簡單易用的任務調度平臺,在滿足核心功能的基礎上提供以下非功能性保障:
平臺化:支持多業務接入、百億級任務註冊
易用性:自助化接入、運維,使用成本遠低自建
高可靠:全年 3 個 9 可用性、p99(時延)<1s
高性能:支持 100w+TPM 的任務觸發
多協議:支持多協議、組播、單播多種回調方式
綜合看需要 tjobs 設計支持百億級任務量和百萬 TPM 併發執行,併在此基礎上滿足三個 SLA:
-
註冊\觸發可用性>99.95%
-
任務觸達率>99.99%
-
p99(觸達延時)<1s
設計思路
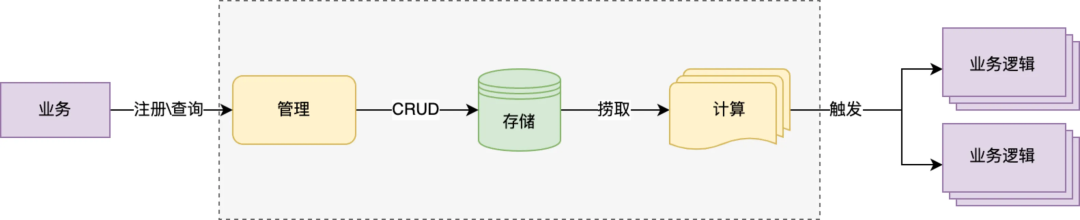
如上圖所示描述了對任務註冊、觸發流程的抽象,不難看出 tjobs 平臺為達成上述任務量級和三個 SLA,需要在海量數據存儲、高併發、觸發時效以及高可用上做出相應的設計保障,下麵分別講述一下:
數據存儲:重點解決兩個問題數據可靠和海量存儲,可靠的存儲保障任務不丟、任務高觸達率,鑒於 mysql 在持久化以及 master-slave 部署架構對高可用支持表現,優先選用 mysql 作為底層存儲;但單 DB 在 TPS 性能、數據量上存在瓶頸,這裡選用分庫分表策略,通過增加資料庫實例打平數據分佈以提升整體性能和存儲上限;
實時性:類似多級緩存的思路,為保障任務觸發時效(p99<1s)這裡的設計思路“任務前置”,拆解任務觸發步驟,將任務撈取、計算工作儘量提前完成,通過毫秒級延遲的記憶體時間輪最終觸發,保障任務的觸發時效性;
高併發:採用可伸縮架構設計,存儲層儘量拆分為多個邏輯庫,前期通過合併部署降低成本但保留多個邏輯庫隔離能力,未來支持快速遷移獨立部署以提升性能;應用層採用多級調度思路,按數據分片將大任務拆分成小粒度任務動態根據計算節點數完成分配,實現通過增加計算節點快速提升任務觸發能力;
高可用:MTTR 分段治理思路,架構層在設計階段考慮到單點、單機房風險,不管是存儲層還是應用層都採用多機多活架構,並支持 HA 自動切換大大縮短 MTTF 時效;立體化的監控+撥測能力,覆蓋從註冊到觸發全流程波動、成功率、耗時、延遲多維度監控,縮短 MTTI 時效;
整體流程
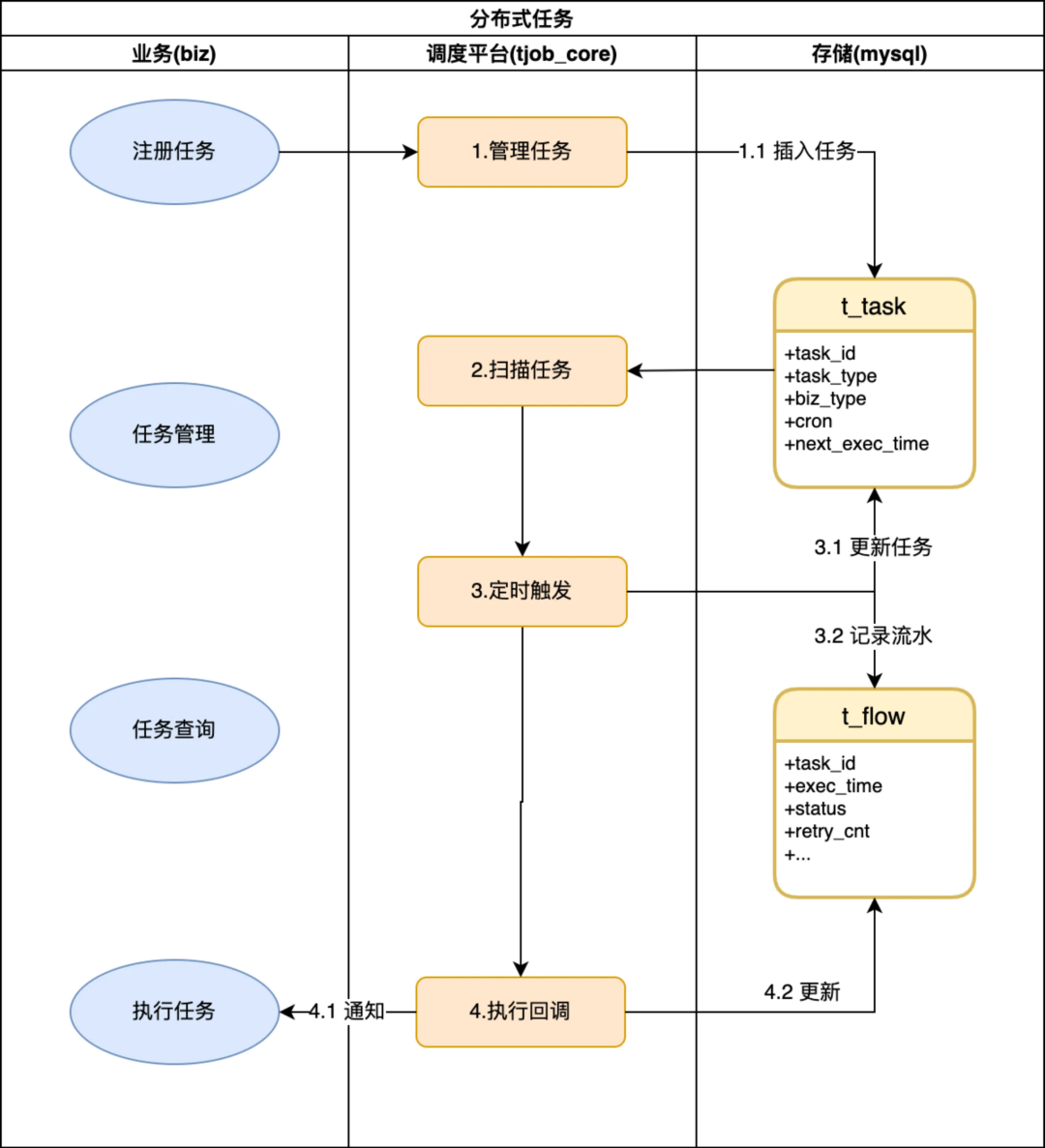
如上圖所示一個任務執行流程和生命周期,大概分成四個階段:
● 初始化:tjobs 提供任務註冊介面,完成任務校驗、計算並持久化到 mysql 存儲,業務根據實際場景選擇 CronCycleTask、IntervalCycleTask、FixedTimeSingleTask、DelayedTimeSingleTask 等不同任務類型提交註冊即可;
● 待執行:tjobs 會每隔 5min 執行一次,撈取未來 5min 內所有待執行的任務,註冊到一個記憶體 TimingWheels.中,由 timewheel 通過 callBackFunc 實現定時回調從而實現毫秒級延遲觸發業務回調;
● 執行中:首先會產生一條 init 狀態的調度流水、並根據任務類型、任務周期計算下一次調度時間,將 insert flow 和 update task 兩個操作合併到一個事務中更新到 DB,通過事務保證每次任務肯定能被調度到;
● 已觸發:根據 init flow 查找業務的回調配置,支持 http、trpc、videopacket-jce 多種協議,支持單播、組播多種類型的回調業務 spi,由業務完成響應的業務操作即完成了一次完整的任務調度。
詳細設計
領域模型
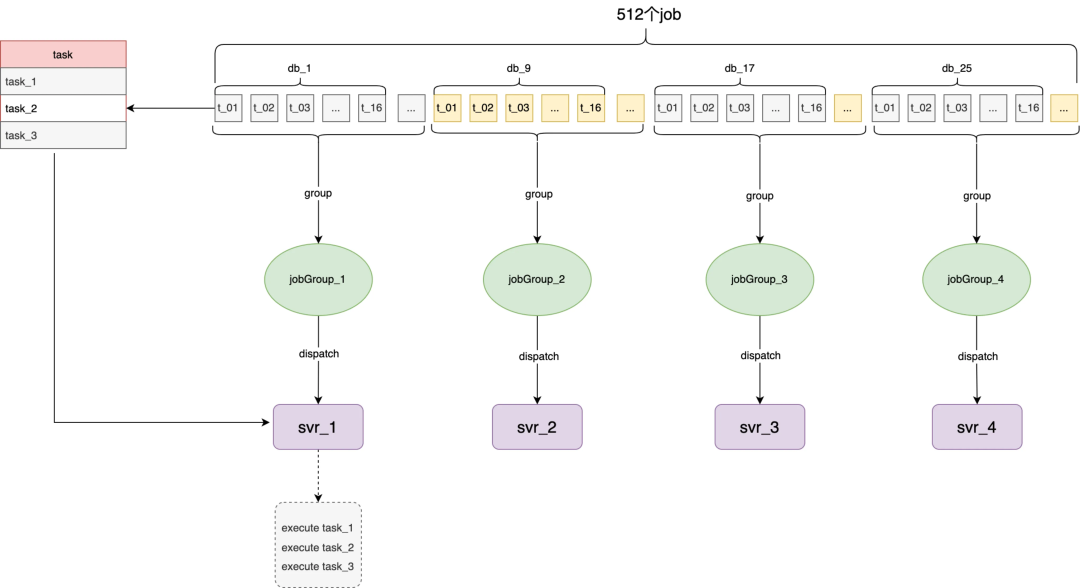
按照整體流程描述,tjobs 的主要職責管理好業務的定時任務調度,為此 tjobs 內部也需要會有一系列的跑批任務來保障調度的實時性,所以這裡 tjobs 對兩類任務分別做了抽象,如上圖所示 tjobs 內部的跑批任務統稱為 job、業務定時調度任務稱為 task。tjobs 會將整個跑批任務拆分為 512 個最小的執行單元,按照當前可調度機器數打包成不同的 jobGroup 然後分發給 svr。由此衍生的幾個關鍵模型說明:
JobGroup:tjobs 內部分發調度和容災最小單元,會根據當前 svr 數量動態生成
Job:tjobs 任務最小執行單元,goroutine 協程調度單位(協程模型會詳細介紹工作)
JobParam:每個 job 批次執行時的輸入參數,批任務的執行模式類似 CyclicBarrier,每個周期有每個周期的執行參數
Task:業務註冊的定時調度任務,分周期任務、單次任務等(下圖以 cron 為例展示 19:01 時模型快照)
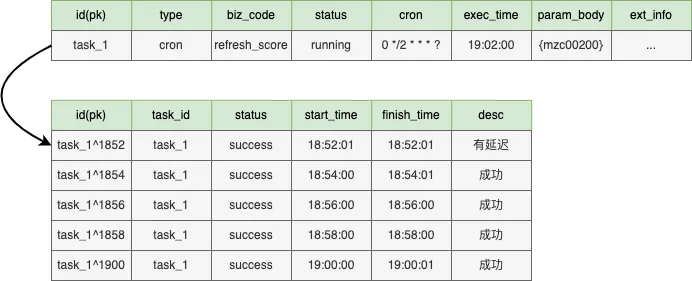
tjobs 的跑批任務的 timeline 原理如下圖所示,假設 tjobs 按照 cron(0 0/5 * * ?)執行,在 19:00 時發起調度會拉取 taskA-taskE 任務平均分配給當前可運行的 svr1-svr5 機器上,19.05 以此類推,當 19.10 調度時 svr4 宕機,這會將 taskN 任務和 taskO 任務分配到 svr5 上完成對 svr_4 的容災。
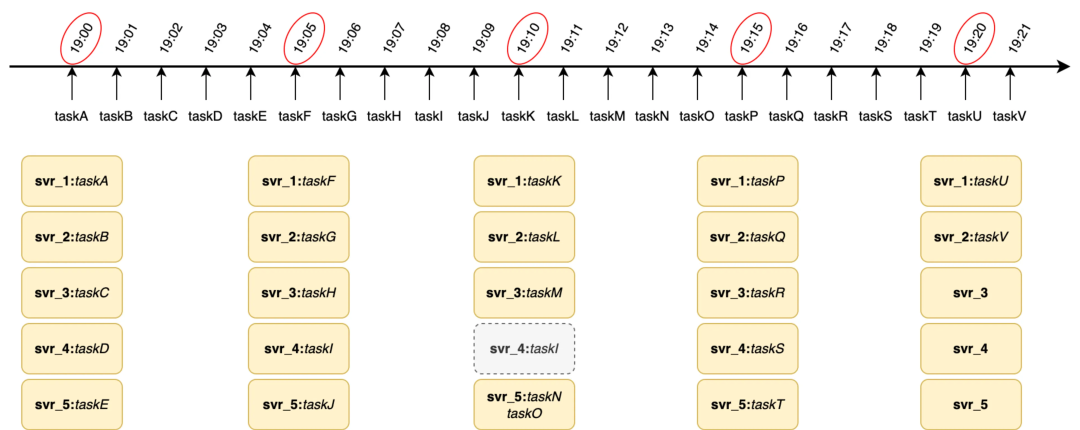
分庫分表
由於 redis 記憶體型存儲,在持久化、事務上保障不足導致生產環境很容易出現丟任務或重覆調度的情況,所以本次底層存儲不在依賴 redis 存儲而選用 mysql 資料庫存儲。按照百萬 TPM 觸發和百億任務存儲設計要求需通過分庫分表來支持橫向擴展能力。
如下圖所示,我們生產環境部署了 8 個 DB 實例,每個實例上部署了 4 個邏輯庫(目前先通過合併部署減少成本,未來如有更高 TPS 訴求每個邏輯庫單獨部署即可),每個邏輯庫中拆分成 16 個表(拆分多表的目的是保障百億級任務存儲時單表行數不超過 2000w)以保障索引效率和查詢性能。
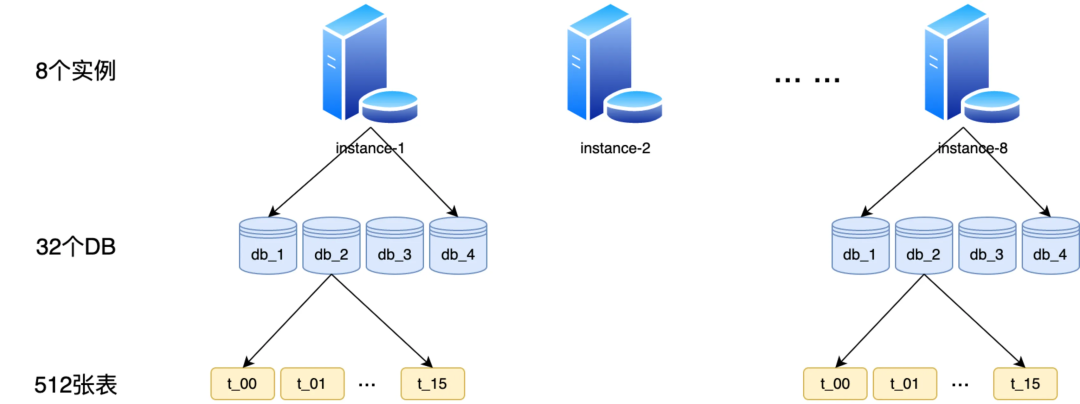
多級調度
解決了 DB 存儲的性能問題,接下來需要解決應用層單機性能限制,這裡我們選擇“多級調度模型”,物理上充分利用多機資源通過多機併發執行突破單機並行線程的限制,最大化提升任務觸發的 TPS 上限。實現原理上將一個大的跑批任務拆解成多個小跑批任務分發到多台機器上執行。可以將內部跑批任務分成兩個階段,階段一為 job 任務打包和派發、階段二為 job 任務撈取和執行,多級調度主要實現階段一。
如上圖所示,詳細的執行流程分成 4 個步驟:
-
基於定時調度平臺,每個 5min 做一次 cron 調度通知一臺 tjobs 機器
-
tjobs 通過名字服務查詢當前服務下所有可用機器供後續分包、調度
-
tjobs 根據當前可調度的機器數(n)將 512 個 job 打包成 n 個 jobGroup
-
將每個 jobGroup 綁定到一個機器上,通過指定 ip 方式通知服務執行階段二(階段二的詳細實現見下節)
如領域模型中描述 tjobs 跑批任務採用 CyclicBarrier 柵格模式運行,這樣做的目的 1)、期望每個周期各個 job 都能完成所有待觸發任務(即 T1 周期完成 T1 時間之前所有的任務)防止任務積壓;2)、每個任務都以相同的執行周期和參數運行可以冪等,防止任務被重覆調度,從平臺側儘力提供 only once 的觸發保障。
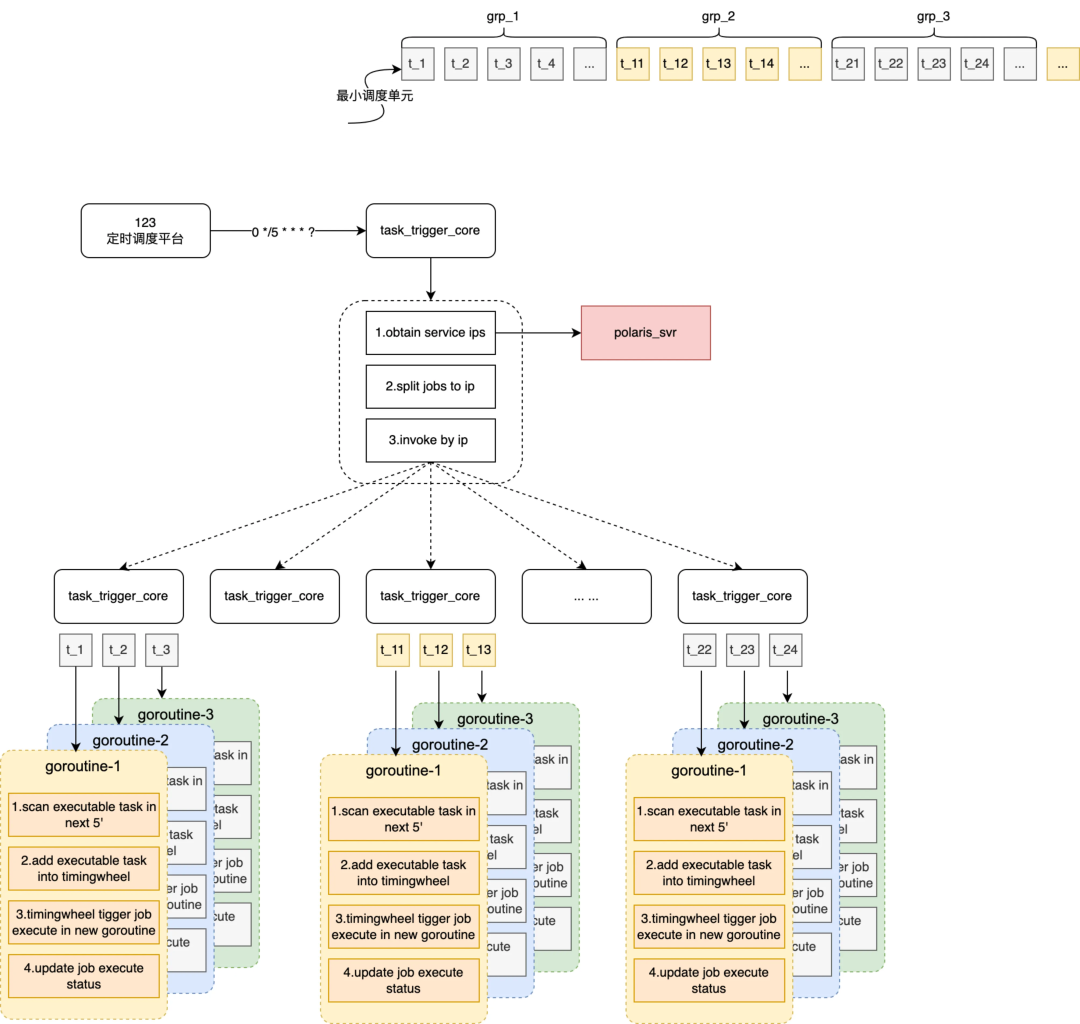
線程模型
本節接上節會詳細介紹一下階段二每個協程內單個 job 的詳細執行流程,如下圖所示會拆解 5 個步驟:
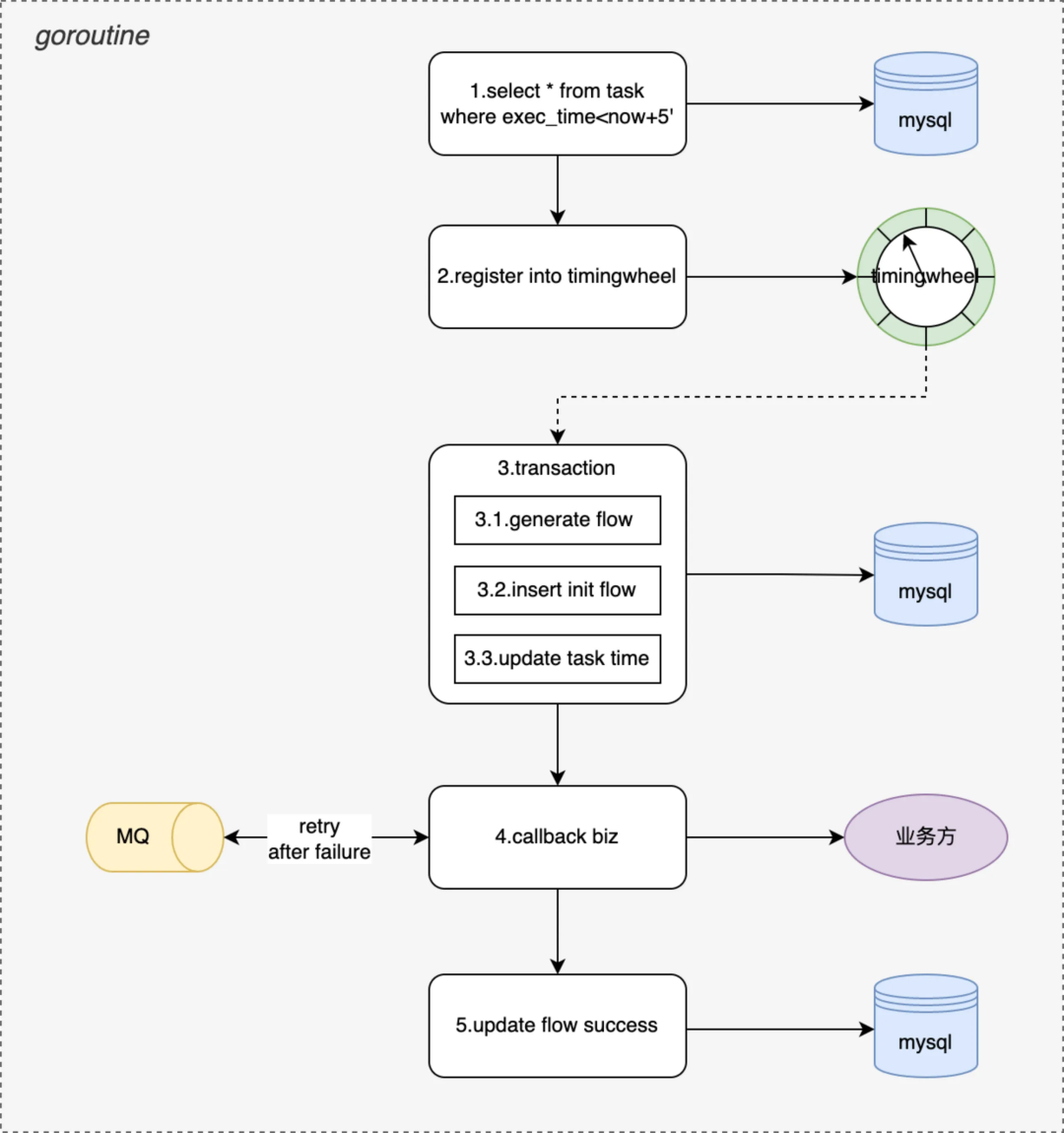
-
掃描本周期內所有待執行的任務,task 在註冊、執行後都會更新下次待執行時間
-
將掃描出來的任務按照待觸發時間註冊到 timingwheel 中(timingwheel 為秒級)
-
timingwheel 到指定時間觸發業務主要完成兩個操作:生成調度流水並更新 task 下次執行狀態 + 執行業務回調
-
根據業務回調配置(包括協議類型、回調方式、超時時間、重試次數等),執行業務回調通知
-
更新調度流水狀態,調度成功後或達到重試次數後推進流水到終態
tjobs 的跑批執行周期 5‘,業務 task 可能會按照 30''調度,這裡會生成 10 個待執行任務註冊到 timingwheel 中。
通過 mysql 事務保障,生成流水和更新 task 下次執行狀態在一個事務內,保障任務肯定能被觸發到。
tjobs 會有兜底協程持續掃描未到終態的調度流水持續推進,保證任務觸達率>99.99%。
HA 支持
作為一個任務調度平臺,系統的高可用性和功能的完整性同樣重要,所以對外承諾三個核心 SLA(全年可用性>99.95%、任務觸達率>99.99%、p99(延遲)<1s)。達成上述 SLA 就需要底層存儲、外部依賴均保持高可用外,應用自身架構需要有更強魯棒性。
DB 容災
DB 實例按照一主兩備部署,依賴 DB 持久化能力、以及主備半同步複製能力,存儲層在主庫故障時能自動 failover 到備庫且保證數據 rpo=0(不丟數據),能應對存儲層單機故障,同時兩個備庫分別部署到兩個可用區機房,從而支持同城跨機房災備能力(考慮成本問題暫不支持跨城容災)。
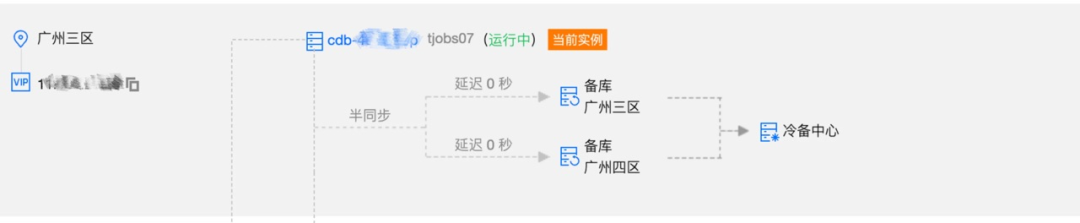
因此從 DB 層看平臺的可用性 SLA 滿足>99.99%,並且任務 RPO=0 滿足不丟任務 SLA,主備切換分鐘級 RTO 基本滿足全年 P99(延遲)<1s 的 SLA。
應用容災
根據多機調度模型原理,每隔固定周期執行一次跑批任務,將未來待執行的任務緩存到應用記憶體中由 timingwheel 觸發,其中涉及四個應用服務(定時調度、名字服務、資料庫和 tjobs 應用)協作,資料庫實例容災上節已分析基本滿足 SLA,名字通過增加本地緩存實現弱依賴也能滿足 SLA,現需要對定時調度平臺和 tjobs 應用兩個強依賴服務做容災能力保障。
定時調度平臺不可用或調度延遲直接導致任務不能被準時調度,這裡應對思路有:
-
依賴 linux 的 corntab 觸發,存在應用單點問題,導致整體可用性無法保障
-
基於調度平臺分鐘級 RTO,通過增大調度周期減少對調度平臺依賴度
為達成 p99 延遲<1s,tjobs 會提前將待觸發任務緩存到應用記憶體中,這樣如果 tjobs 應用伺服器宕機則該伺服器上本周期內任務都不能被正常調度,只能等下個執行周期被重新撈起調度,導致 p99(任務延遲)<1s 不達標,這裡應對思路有:
-
縮短調度周期(5'->30''),最多影響單機上 30‘’任務的調度延遲,降低延遲概率但不能徹底解決問題,且縮短周期會和調度平臺交互更強(有悖減少調度平臺依賴)
-
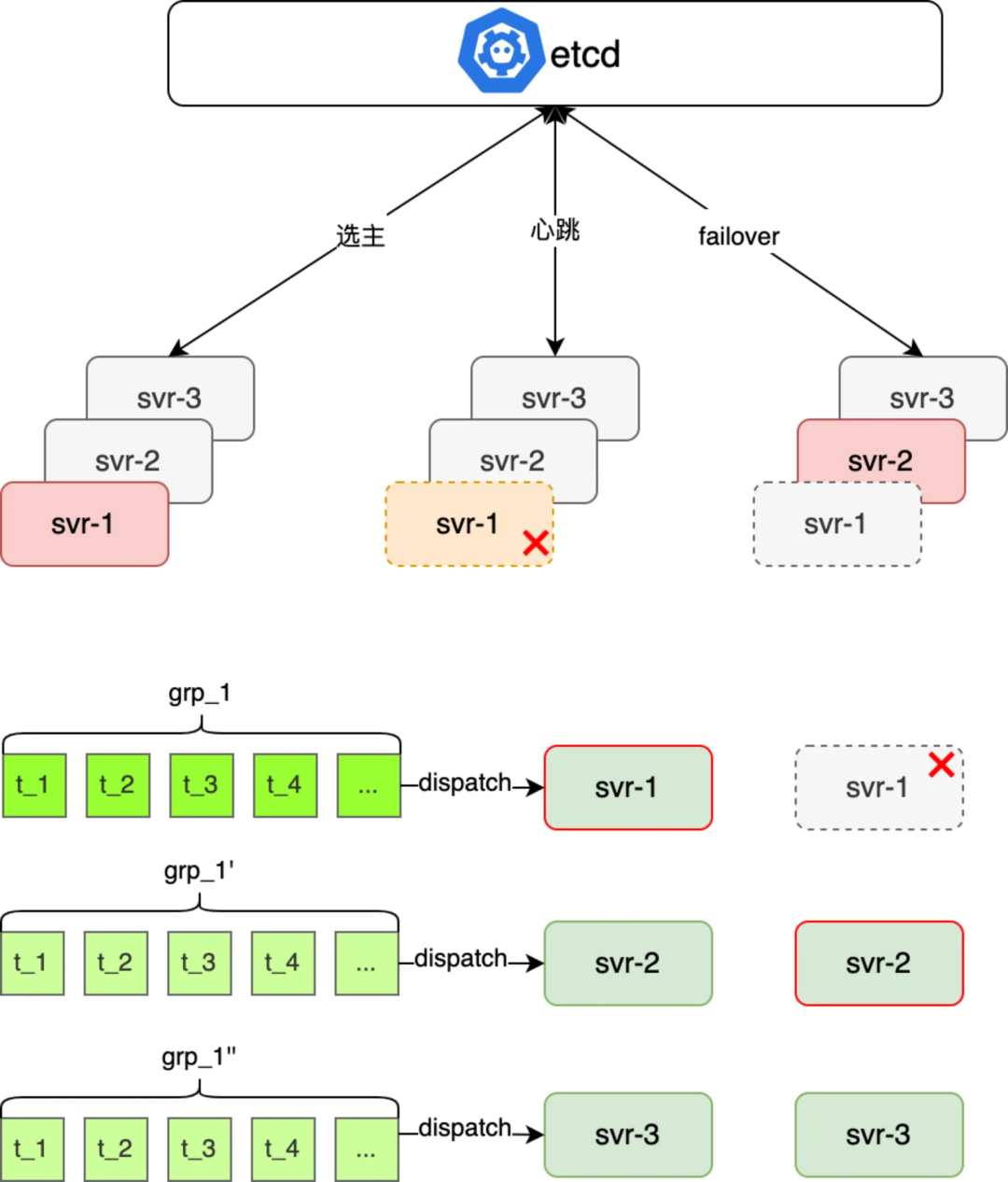
伺服器支持主備 failover,每個任務組派發到多個伺服器上,通過 etcd 選主一臺伺服器執行,如果伺服器宕機自動 failover 到備機執行,max 延遲就是選主耗時
綜合上述分析看,要提升保障平臺整體的 P99(延遲)、和 99.95%的可用性 SLA,最優方案是“基於調度平臺+應用伺服器主備 failover”,具體的實現思路(如下圖所示),每個周期內待調度的 jobGroup 分被分配到三個不同應用 svr 上,應用層一主兩備的部署運行時,然後三個應用 svr 鏈接 etcd,利用 etcd 的選主和自動 failover 能力,既保障了任務運行的 only once 又能保障單機故障時該機上待執行任務的準時觸發
Misfire 策略
tjobs 平臺會有兜底的 misfire 策略以防止任務不能被準時調度時兜底調度過期任務,以保障所有任務觸達率不低於 99.99%,目前提供兩類 Misfire 策略:
1. 馬上觸發一次,已過期任務馬上觸發一次業務回調(預設用於 singleTask)
2. 儘快觸發一次,忽略已過期任務觸發回調,本周期內儘快執行一次業務回調(預設用於 cronTask 和 intervalTask)
部署落地
部署架構
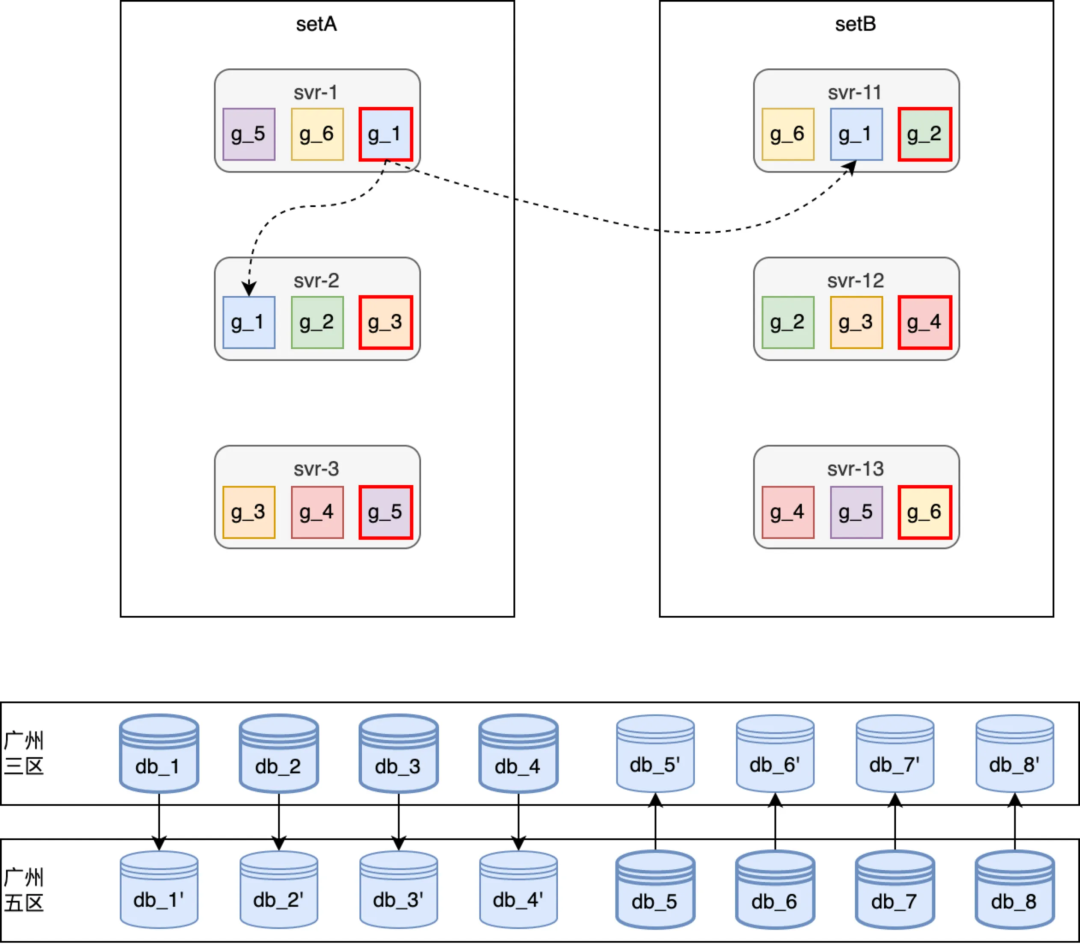
非容災模式線上運行快照(如上圖所示),針對常見的單機宕機或者重啟在 HA 章節已經介紹過,比如 svr-2 宕機或重啟時 g_3 這個跑批任務組會自動 failover 到 svr-12 或者 svr-3 上繼續斷點執行,從而保障高可用性。
針對常見的單機房故障,在任務 dispatch 環節會將一個任務 jobGroup 的主備執行機器分配到不同的 set,從而保障單機房故障時從應用到 DB 都能自動 failover 到其他可用區機房;針對日常的停機發佈,由於應用支持分 set 主備 failover,因此發佈時按 a、b set 依次發佈即可。
性能壓測
詳細的壓測執行過程不在展開,這裡只同步一下壓測結論
壓測摸高峰值:任務註冊 1.5w/s、任務觸發 2.2w/s
應用&DB 峰值:
| 機型配置 | 機器數量 | 峰值負載 | 說明 | |
|---|---|---|---|---|
| 應用伺服器 | 4C8G | 20 | 45% | 支持橫向擴展,通過擴容保留 20 倍容量空間 |
| 資料庫服務 | 8C32G | 8 | 75% | 目前合併部署,通過調整部署保留 4 倍空間通過 DB 升配保留 8 倍的容量空間 |
峰值 SLA:可用性>99.99%、1s 內觸發占比>99.95%、任務觸達率~100%。
總結
tjobs 作為一個高性能、低延遲的分散式任務調度平臺,在滿足通用的任務註冊、查詢、觸發等基本功能同時,也通過可伸縮的架構、HA 能力、體系化可用性建設保障系統在百億任務量、百萬 TPM 觸發能力下滿足系統可用性、延遲、觸達率 SLA。
支持將任務劃分到不同的分片分配到不同的應用機器上執行,既保留了高峰時百萬 TPM 的觸發能力、也支持低峰時合併部署以節省成本;通過任務前置使用定時任務掃描、記憶體時間輪保證任務及時觸發,保證了任務執行的低延遲;通過主備熱活、自動 failover 能力建設保證系統整體從存儲層到應用的全棧高可用。
附錄
etcd 選主實現故障主備秒級切換高可用架構 | KL 博客
作者:timgc
本文來自博客園,作者:古道輕風,轉載請註明原文鏈接:https://www.cnblogs.com/88223100/p/How-to-Design-a-Massive-Task-Scheduling-System.html


