
事務隔離級別遺留問題: 在讀已提交的級別下,事務B可以讀到事務A持有寫鎖的的記錄,且讀到的是未更新前的,為何寫讀沒有衝突? 可重覆讀級別,事務B可以更新事務A理論上應該已經獲取讀鎖的記錄,且更新後,事務A依然可以讀到數據,為何讀-寫-讀沒有衝突? 在可重覆讀級別,幻讀沒有產生 其中,前兩個問題就是因 ...
事務隔離級別遺留問題:
-
在讀已提交的級別下,事務B可以讀到事務A持有寫鎖的的記錄,且讀到的是未更新前的,為何寫讀沒有衝突?
-
可重覆讀級別,事務B可以更新事務A理論上應該已經獲取讀鎖的記錄,且更新後,事務A依然可以讀到數據,為何讀-寫-讀沒有衝突?
- 在可重覆讀級別,幻讀沒有產生
其中,前兩個問題就是因為mvcc機制(讀鎖的一種優化機制),通過不加讀鎖,避免讀寫衝突,進而提高了性能。
為什麼要有MVCC機制?
-
在讀已提交的級別下,由於是給讀加鎖來保證讀已提交, 如果事務A持有寫鎖,為了保證讀已提交,事務B必須等待事務A提交之後才可以讀;其他的讀事務也是這樣的情況,效率太低
-
在可重覆讀級別,為了保證可重覆讀,如果事務A持有讀鎖,為了第二次讀到的一樣,其他所有寫事務必須等待讀完才可以,同樣效率低
那麼很自然的想到,無論讀事務是先產生還是後產生,如果這個時候還存在寫事務沒有執行,或者需要執行;那麼就應該讓讀事務讀到目前最新的值,且寫事務可以更新;只不過讀事務在寫事務提交更新後,依據隔離級別是否可見最新更新即可。這就是MVCC機制的核心能力,將讀鎖幹掉。
MVCC機制核心組件
MVCC機制由版本鏈、undolog、readview三大核心構成版本鏈
猜測很多人第一次看到MVCC的版本都是和我一樣在各種各樣的博客文章上,或者可能是在一些課程專欄或者《高性能mysql》這本書的mvcc部分看到的,那麼在你的理解中,版本的底層是什麼樣子呢? innodb引擎資料庫中的每一條記錄上,我們都可以認為上面有3個隱藏欄位,分別是DB_ROW_ID(不在此次討論範圍),DB_TRX_ID和DB_ROLL_PTR,如下圖一樣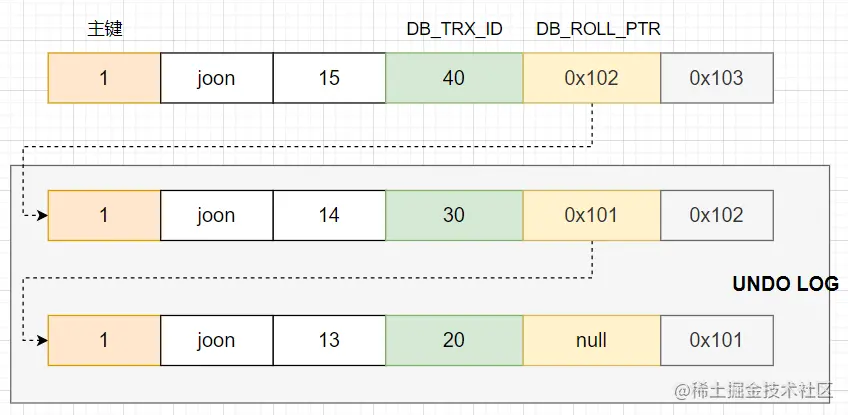
在我的理解中, DB_TRX_ID就是插入或者更新時,當前事務的trx_id,由全局事務管理器分配的遞增的一個id; DB_ROLL_PTR存儲的undolog中當前記錄上一個版本的指針,先姑且記住這是一個指針。 當插入一條記錄時 在這條記錄的DB_TRX_ID填入當前事務的id,由於沒有歷史版本,所以DB_ROLL_PTR為空 當更新一條記錄時 由於這個時候存在歷史版本,所以需要將老版本的數據寫到undolog里,然後構建指針,將DB_TRX_ID更新為當前事務的id,將DB_ROLL_PTR更新為剛纔構建的指針,以及更新需要更新的欄位。 當刪除一條記錄時(這個不太確定,主觀猜測) 猜測是將老記錄寫到undolog,然後構建指針,新記錄DB_TRX_ID更新為當前事務的id,將DB_ROLL_PTR更新為剛纔構建的指針,但是沒有需要更新的欄位。而且mysql不會立即刪除,記錄上有一個info_bits欄位,會標記上刪除標識(REC_INFO_DELETED_FLAG),後續由purge線程(不瞭解,姑且認為是個scheduleTask吧)刪除 這樣,當多次更新之後,新記錄存儲的永遠都是最新操作的事務id,並通過指針指向了老版本,老版本還指向了更老的版本...等等,最終構成了一個版本鏈
Readview
理論:
在周志明老師的鳳凰架構(或者極客時間的‘周志明的軟體架構課’)中對mvcc簡單介紹到隔離級別是可重覆讀:總是讀取 CREATE_VERSION 小於或等於當前事務 ID 的記錄,在這個前提下,如果數據仍有多個版本,則取最新(事務 ID 最大)的。 隔離級別是讀已提交:總是取最新的版本即可,即最近被 Commit 的那個版本的數據記錄。在mysql官網中是這麼描述的
If the transaction isolation level is翻譯: 隔離級別是可重覆讀:在同一個事務中,一致性讀總是去讀在該事務第一次讀取時生成的快照。 隔離級別是讀已提交:事務中的每次讀取都取自己新生成的快照。REPEATABLE READ(the default level), all consistent reads within the same transaction read the snapshot established by the first such read in that transaction. You can get a fresher snapshot for your queries by committing the current transaction and after that issuing new queries. WithREAD COMMITTEDisolation level, each consistent read within a transaction sets and reads its own fresh snapshot.
相比之下,周老師形容的更貼近隔離級別的概念上,官方的描述則是底層的具體實現邏輯。 兩者結合一下就是 可重覆讀:通過在每個事物只讀取第一次select時生成的快照和undolog比較,根據一個可見性規則判斷,是否可以讀當前版本的記錄,可以就返回,不行就繼續比較再上一個版本,直到最老的版本; 讀已提交:除了每次讀取都會使用最新的快照,後面的都和可重覆讀的邏輯一樣。 為什麼我這裡說的是可見性規則呢? 是因為周老師描述里“總是讀取 CREATE_VERSION 小於或等於當前事務 ID 的記錄” 很容易錯誤的理解為當前版本記錄里的trx_id<=快照創建時的事務id(create_trx_id)就都可見,真正的判斷邏輯並不只是一個create_trx_id就能搞定的。 但這裡先不展開講,自己想一下為什麼不行,下麵的圖可能會給你一點靈感,接下來我們先去讀一下“可見性規則”的底層源碼。
可見性規則底層實現
ReadView類
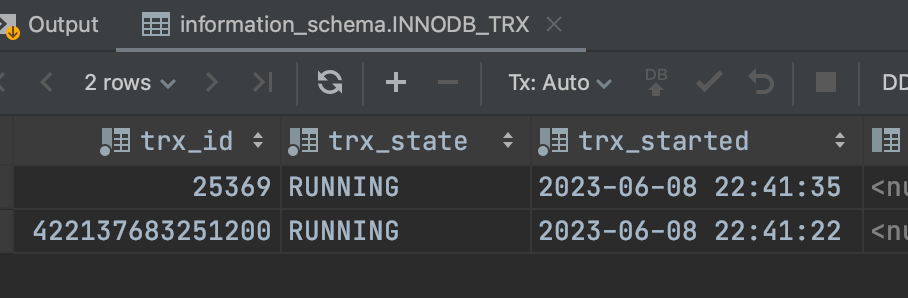
storage/innobase/include/read0types.h:47 //ReadView類 class ReadView { ... private: /** trx id of creating transaction, set to TRX_ID_MAX for free views. */ //創建快照的時候,快照對應的事務id,只有含有寫操作的才會分配真正的事務id trx_id_t m_creator_trx_id; /** Set of RW transactions that was active when this snapshot was taken */ //活躍的讀寫事務id列表,從trx_sys->rw_trx_ids抄過來的 ids_t m_ids; /** The read should not see any transaction with trx id >= this value. In other words, this is the "high water mark". */ //賦值是即將分配的下一個事務id,所以大於等於這個id的記錄對當前事務來說都是不可見的 trx_id_t m_low_limit_id; /** The read should see all trx ids which are strictly smaller (<) than this value. In other words, this is the low water mark". */ //m_ids不為空就是ids.get(0),為空則是m_low_limit_id,所以小於這個事務id的就代表著快照建立的時候 //已經不是活躍事務了,即已經提交了,所以一定可以看到這些事務的改動記錄 trx_id_t m_up_limit_id; .... }
初始化賦值的時候
//read0read.cc //row_search_mvcc -> trx_assign_read_view -> MVCC::view_open -> void ReadView::prepare(trx_id_t id) { ut_ad(trx_sys_mutex_own()); m_creator_trx_id = id; m_low_limit_no = trx_get_serialisation_min_trx_no(); m_low_limit_id = trx_sys_get_next_trx_id_or_no(); ut_a(m_low_limit_no <= m_low_limit_id); if (!trx_sys->rw_trx_ids.empty()) { copy_trx_ids(trx_sys->rw_trx_ids); } else { m_ids.clear(); } /* The first active transaction has the smallest id. */ m_up_limit_id = !m_ids.empty() ? m_ids.front() : m_low_limit_id; ut_a(m_up_limit_id <= m_low_limit_id); ut_d(m_view_low_limit_no = m_low_limit_no); m_closed = false; }
判斷某個版本的記錄是否可見?
//read0types.h bool changes_visible(trx_id_t id, const table_name_t &name) const { ut_ad(id > 0); //如果當前版本記錄上的事務id(DB_TRX_ID)小於低水位或者等於當前事務, //那麼要麼就是自己更改的,要麼就是歷史上已經提交了的,所以可以讀到 if (id < m_up_limit_id || id == m_creator_trx_id) { return (true); } check_trx_id_sanity(id, name); //如果當前版本記錄上的事務id(DB_TRX_ID)大於高水位,那麼就是在當前快照生成後生成的事務,一律看不到 if (id >= m_low_limit_id) { return (false); //這一步我沒有理解, } else if (m_ids.empty()) { return (true); } const ids_t::value_type *p = m_ids.data(); //二分查找,如果活躍的事務裡面沒有,那麼就返回true //這裡我是這麼理解的,[低水位,高水位]包含活水和死水,即活躍的事務和已經提交的事務 //假如存在事務1是活躍的,事物2是已提交的,事務3是活躍的,我們在事務4的時候開啟快照,很明顯我們只能讀到事務2或者事務4的變更 //假如正在判斷的是事務2,因為已經經過了上面的校驗, //所以我們知道當前版本記錄的事務m_low_limit_id(高水位)>id>=m_up_limit_id(低水位),且不是當前事務; //所以就需要判斷事務只要不是活躍的,那麼就一定是已經提交的事務,那麼就可讀 return (!std::binary_search(p, p + m_ids.size(), id)); }
//row0sel.cc#row_search_mvcc if (srv_force_recovery < 5 && !lock_clust_rec_cons_read_sees(rec, index, offsets, trx_get_read_view(trx))) { rec_t *old_vers; /* The following call returns 'offsets' associated with 'old_vers' */ err = row_sel_build_prev_vers_for_mysql( trx->read_view, clust_index, prebuilt, rec, &offsets, &heap, &old_vers, need_vrow ? &vrow : nullptr, &mtr, prebuilt->get_lob_undo()); if (err != DB_SUCCESS) { goto lock_wait_or_error; } if (old_vers == nullptr) { /* The row did not exist yet in the read view */ goto next_rec; } rec = old_vers; prev_rec = rec; ut_d(prev_rec_debug = row_search_debug_copy_rec_order_prefix( pcur, index, prev_rec, &prev_rec_debug_n_fields, &prev_rec_debug_buf, &prev_rec_debug_buf_size)); } //lock0lock.cc#lock_clust_rec_cons_read_sees bool lock_clust_rec_cons_read_sees( const rec_t *rec, /*!< in: user record which should be read or passed over by a read cursor */ dict_index_t *index, /*!< in: clustered index */ const ulint *offsets, /*!< in: rec_get_offsets(rec, index) */ ReadView *view) /*!< in: consistent read view */ { ut_ad(index->is_clustered()); ut_ad(page_rec_is_user_rec(rec)); ut_ad(rec_offs_validate(rec, index, offsets)); /* Temp-tables are not shared across connections and multiple transactions from different connections cannot simultaneously operate on same temp-table and so read of temp-table is always consistent read. */ if (srv_read_only_mode || index->table->is_temporary()) { ut_ad(view == nullptr || index->table->is_temporary()); return (true); } /* NOTE that we call this function while holding the search system latch. */ trx_id_t trx_id = row_get_rec_trx_id(rec, index, offsets); return (view->changes_visible(trx_id, index->table->name)); }
事務的trx_id
在我還沒開始看mysql源碼,只是跟著博客學習寫用例測試的時候,我發現,開啟事務進行了第一次查詢之後,確實有生成事務id,但後面我執行了一條更新語句之後,原來的事務id變了;就像下麵這個圖一樣,最開始只有查詢的時候是比較長的這個id,但執行了一條update語句後,事務id變成了一個短的。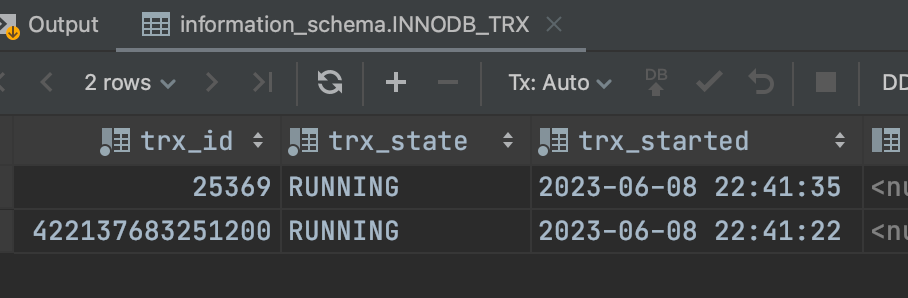
select * from information_schema.INNODB_TRX;
//trx0trx.cc#trx_start_low //這裡可以看到只有讀寫事務才真正分配了id else { trx->id = 0; if (!trx_is_autocommit_non_locking(trx)) { /* If this is a read-only transaction that is writing to a temporary table then it needs a transaction id to write to the temporary table. */ if (read_write) { trx_sys_mutex_enter(); ut_ad(!srv_read_only_mode); trx->state.store(TRX_STATE_ACTIVE, std::memory_order_relaxed); trx->id = trx_sys_allocate_trx_id(); trx_sys->rw_trx_ids.push_back(trx->id); trx_sys_mutex_exit(); trx_sys_rw_trx_add(trx); } else { trx->state.store(TRX_STATE_ACTIVE, std::memory_order_relaxed); } } else { ut_ad(!read_write); trx->state.store(TRX_STATE_ACTIVE, std::memory_order_relaxed); } } //trx0trx.ic //這裡是在展示的時候對只讀事務的id做了處理 /** Retreieves the transaction ID. In a given point in time it is guaranteed that IDs of the running transactions are unique. The values returned by this function for readonly transactions may be reused, so a subsequent RO transaction may get the same ID as a RO transaction that existed in the past. The values returned by this function should be used for printing purposes only. @param[in] trx transaction whose id to retrieve @return transaction id */ static inline trx_id_t trx_get_id_for_print(const trx_t *trx) { /* Readonly and transactions whose intentions are unknown (whether they will eventually do a WRITE) don't have trx_t::id assigned (it is 0 for those transactions). Transaction IDs in information_schema.innodb_trx.trx_id, performance_schema.data_locks.engine_transaction_id, performance_schema.data_lock_waits.requesting_engine_transaction_id, performance_schema.data_lock_waits.blocking_engine_transaction_id should match because those tables could be used in an SQL JOIN on those columns. Also trx_t::id is printed by SHOW ENGINE INNODB STATUS, and in logs, so we must have the same value printed everywhere consistently. */ /* DATA_TRX_ID_LEN is the storage size in bytes. */ static const trx_id_t max_trx_id = (1ULL << (DATA_TRX_ID_LEN * CHAR_BIT)) - 1; ut_ad(trx->id <= max_trx_id); /* on some 32bit architectures casting trx_t* (4 bytes) directly to trx_id_t (8 bytes unsigned) does sign extension and the resulting value has highest 32 bits set to 1, so the number is unnecessarily huge. Also there is no guarantee that we will obtain the same integer each time. Casting to uintptr_t first, and then extending to 64 bits keeps the highest bits clean. */ return (trx->id != 0 ? trx->id : trx_id_t{reinterpret_cast<uintptr_t>(trx)} | (max_trx_id + 1)); }
生成快照時機(不太確定)
可重覆讀:只生成一次,後面繼續使用ReadView *trx_assign_read_view(trx_t *trx) /*!< in/out: active transaction */ { ut_ad(trx_can_be_handled_by_current_thread_or_is_hp_victim(trx)); ut_ad(trx->state.load(std::memory_order_relaxed) == TRX_STATE_ACTIVE); if (srv_read_only_mode) { ut_ad(trx->read_view == nullptr); return (nullptr); } else if (!MVCC::is_view_active(trx->read_view)) { trx_sys->mvcc->view_open(trx->read_view, trx); } return (trx->read_view); }讀已提交:用完就關,所以每次再獲取就得新開,但是這裡的關有兩個地方調
ha_innodb.cc#store_lock 和ha_innodb.cc#external_lock if (lock_type != TL_IGNORE && trx->n_mysql_tables_in_use == 0) { trx->isolation_level = innobase_trx_map_isolation_level(thd_get_trx_isolation(thd)); if (trx->isolation_level <= TRX_ISO_READ_COMMITTED && MVCC::is_view_active(trx->read_view)) { /* At low transaction isolation levels we let each consistent read set its own snapshot */ mutex_enter(&trx_sys->mutex); trx_sys->mvcc->view_close(trx->read_view, true); mutex_exit(&trx_sys->mutex); } }
在學習瞭解MVCC機制中遇到的問題:
- 為什麼更新操作必須使用當前讀?
- 只讀事務突然更新的話,因為更新必須使用當前讀,那是否需要重新生成事務id?
- 只讀事務分配的事務id是什麼東西?如何參與運作?
- readview的範圍
- 知道了mvcc底層是undolog和readview後,怎麼理解“版本”這個概念
- 在只讀視圖能查到其他事務已經刪除並且提交的記錄嗎?
怎麼解決的幻讀?
在只讀事務下,如上文所說的事務1讀不到事務2的更新是因為事務2的版本號要大於當前快照的高水位,那對於新增的記錄來說,其版本號也是同樣的道理,因此事務1讀不到比當前快照里的高水位高的,也就避免了幻讀這種情況。參考資料:
MySQL 8.0 MVCC 源碼解析 - 掘金 https://dev.mysql.com/doc/refman/8.0/en/innodb-consistent-read.html MySQL事務ID的分配時機_mysql事務id什麼時候分配_哲學長的博客-CSDN博客 MYSQL innodb中的只讀事物以及事物id的分配方式_ITPUB博客 Mysql如何實現隔離級別 - 可重覆讀和讀提交 源碼分析_mysql 可重覆度源碼_擇維士的博客-CSDN博客本文來自博客園,作者:起司啊,轉載請註明原文鏈接:https://www.cnblogs.com/qisi/p/mvcc.html


