
摘要:此篇文章分別從sql執行過程、執行計劃、索引數據結構、索引查詢提速原理、聚焦索引、左首碼優化原則、自增主鍵索引這些角度談一談我們對資料庫優化的理解。 本文分享自華為雲社區《工程應用中資料庫性能優化經驗小結》,作者: 葉工 。 1、前言 現階段交付的演算法產品,絕大多數涉及到資料庫的使用。它承載的 ...
摘要:此篇文章分別從sql執行過程、執行計劃、索引數據結構、索引查詢提速原理、聚焦索引、左首碼優化原則、自增主鍵索引這些角度談一談我們對資料庫優化的理解。
本文分享自華為雲社區《工程應用中資料庫性能優化經驗小結》,作者: 葉工 。
1、前言
現階段交付的演算法產品,絕大多數涉及到資料庫的使用。它承載的內容包括:用戶許可權管理、數據集信息、非同步推論的結果、個性化配置等等。
在OCR場景下,數據集體量通常較大(一個數據集幾十萬張圖片),而資料庫往往部署在客戶共用資料庫中(同時運行大量其他業務),甚至只能和演算法鏡像共用同一臺伺服器,因此在後臺研發中尤其要關心資料庫性能瓶頸。
此篇文章分別從 sql執行過程、執行計劃、索引數據結構、索引查詢提速原理、聚焦索引、左首碼優化原則、自增主鍵索引這些角度談一談我們對資料庫優化的理解。
2、ORM場景下如何獲得完整SQL語句
1. 線上環境可以通過連接池進行慢SQL攔截,併發出告警通知
2. 測試階段,因為使用預編譯語句或ORM框架,無法獲取完整SQL時可以使用資料庫日誌方式獲取
set global general_log=on; show variables where Variable_name="general_log_file";
2.1 SQL執行過程
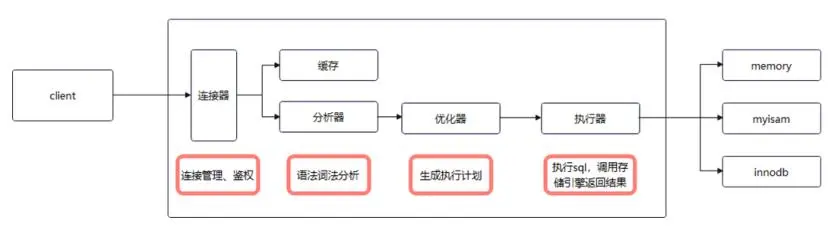
分析器:分析SQL,需要使用哪些表,使用哪些條件(知道要乾什麼)
優化器: 對各種執行過程做性能評估,挑選代價最小的執行過程,代價只是優化器認為的,不一定正確 (怎麼樣做最快)
執行器:調用引擎介面,返回數據,引擎是插件式,類似編程時多態,在創建表時可以選擇相應的存儲 引擎
2.2 執行計劃
SQL前加explain關鍵詞可以得到SQL的執行計劃,根據執行計劃可以判斷執行過程是否符合預期
explain SELECT db_dataset.uuid AS db_dataset_uuid, db_dataset.NAME AS db_dataset_name, db_dataset.updated_at AS db_dataset_updated_at, db_dataset.created_at AS db_dataset_created_at, db_dataset.volume_dir AS db_dataset_volume_dir, db_dataset.max_data_count AS db_dataset_max_data_count, db_dataset.description AS db_dataset_description FROM db_dataset LEFT OUTER JOIN db_manifest ON db_manifest.dataset_id = db_dataset.id AND db_manifest.dataset_version = 'annotation_v0' LEFT OUTER JOIN db_ai_data ON db_manifest.id = db_ai_data.manifest_id AND db_ai_data.deleted = '0' WHERE db_dataset.deleted = 0 GROUP BY db_dataset.id

執行計劃反饋列的解釋:
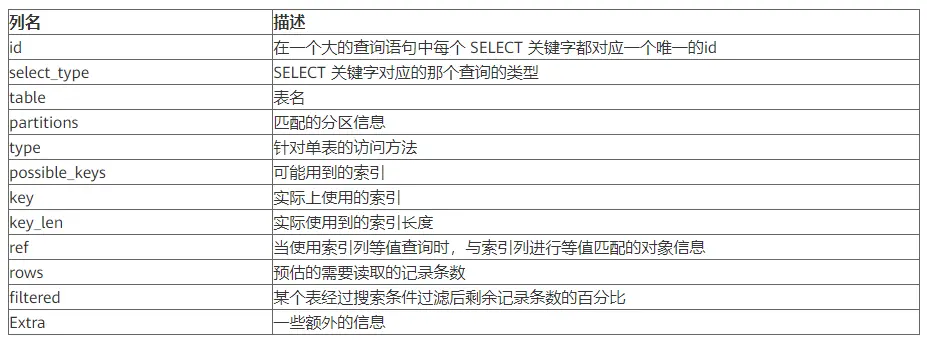
select_type詳解:
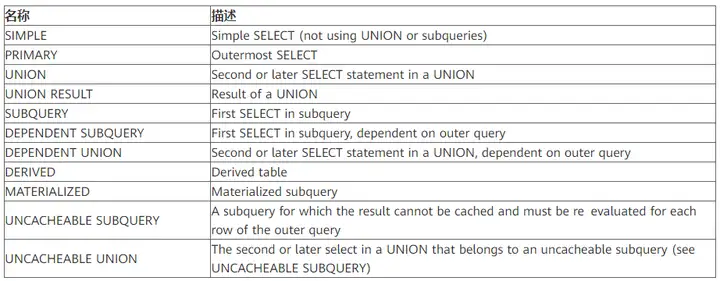
type詳解:
查詢使用了何種類型,它在 SQL優化中是一個非常重要的指標,以下性能從好到壞依次是: system > const > eq_ref > ref > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
system :當表僅有一行記錄時(系統表),數據量很少,往往不需要進行磁碟 IO,速度非常 快。
const :表示查詢時命中 primary key 主鍵或者 unique 唯一索引,或者被連接的部分是一個常量 (const)值。這類掃描效率極高,返回數據量少,速度非常快。
eq_ref :查詢時命中主鍵 primary key 或者 unique key 索引, type 就是 eq_ref。
ref :區別於 eq_ref,ref 表示使用非唯一性索引,會找到很多個符合條件的行。
ref_or_null :這種連接類型類似於 ref,區別在於 MySQL 會額外搜索包含 NULL 值的行。
index_merge :使用了索引合併優化方法,一個查詢使用了兩個以上的索引。
EXPLAIN SELECT * FROM user_robot_relate WHERE id > 1 AND user_id = 2;
unique_subquery :替換下麵的 IN 子查詢,子查詢返回不重覆的集合。
value IN (SELECT primary_key FROM single_table WHERE some_expr)
index_subquery :區別於 unique_subquery,用於非唯一索引,可以返回重覆值。
value IN (SELECT key_column FROM single_table WHERE some_expr)
range :使用索引選擇行,僅檢索給定範圍內的行。簡單點說就是針對一個有索引的欄位,給定 範圍檢索數據。在 where 語句中使用 bettween...and、<、>、<=、in 等條件查詢 type 都是 range。 從結果中看到只有對設置了索引的欄位,做範圍檢索 type 才是 range。
EXPLAIN SELECT * FROM user_robot_relate WHERE id BETWEEN 2 AND 3;
index :Index 與 ALL 其實都是讀全表,區別在於 index 是遍歷索引樹讀取,而 ALL 是從硬碟中 讀取。
ALL :將遍歷全表以找到匹配的行,性能最差。
Extra :不適合在其他列中顯示的信息,Explain 中的很多額外的信息會在 Extra 欄位顯示。
Using index:我們在相應的 select 操作中使用了覆蓋索引,通俗一點講就是查詢的列被索引覆蓋,使 用到覆蓋索引查詢速度會非常快,SQL 優化中理想的狀態。
Using where:查詢時未找到可用的索引,進而通過 where 條件過濾獲取所需數據,但要註意的是並不 是所有帶 where 語句的查詢都會顯示 Using where。
Using temporary:表示查詢後結果需要使用臨時表來存儲,一般在排序或者分組查詢時用到。
Using filesort:表示無法利用索引完成的排序操作,也就是 ORDER BY 的欄位沒有索引,通常這樣的 SQL 都是需要優化的。
Using join buffer:在我們聯表查詢的時候,如果表的連接條件沒有用到索引,需要有一個連接緩衝區 來存儲中間結果。
2.3 索引
索引時幫助MySQL高效獲取數據的排好序的數據結構
索引數據結構:
二叉樹
紅黑樹
HashTable
B-Tree
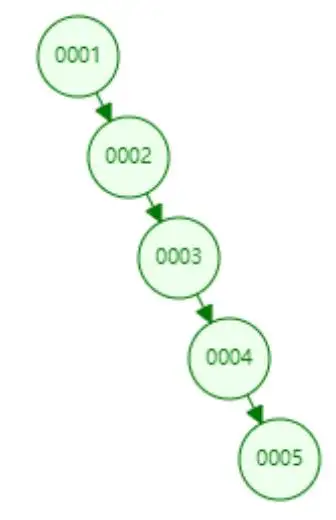
一般不用二叉樹的原因:有序數據將退化成鏈表,深度不可控,如下圖所示
通常也不能用紅黑樹的原因:雖然壓縮了深度,但深度還是不可控,海量數據查找複雜度極高
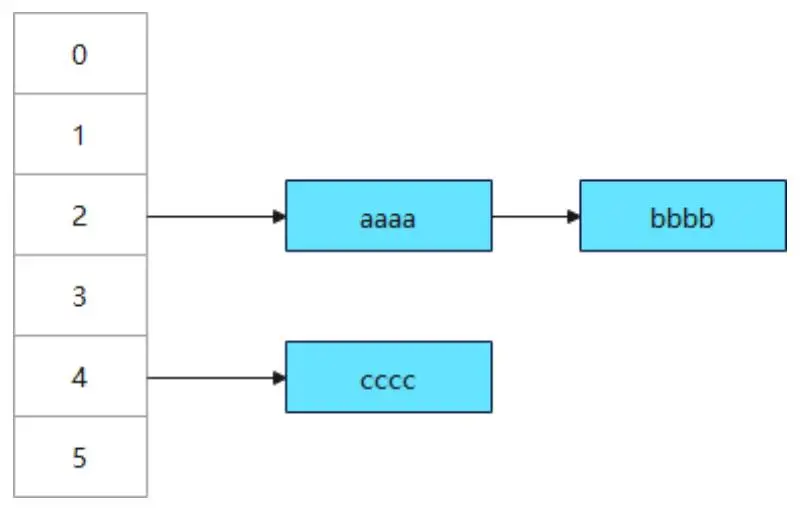
Hash表:僅支持IN查新,不支持RANGE查詢。使用hash演算法將內容進行hash處理 hash(aaaa) = 2 hash(bbbb) = 2 hash(cccc) = 4
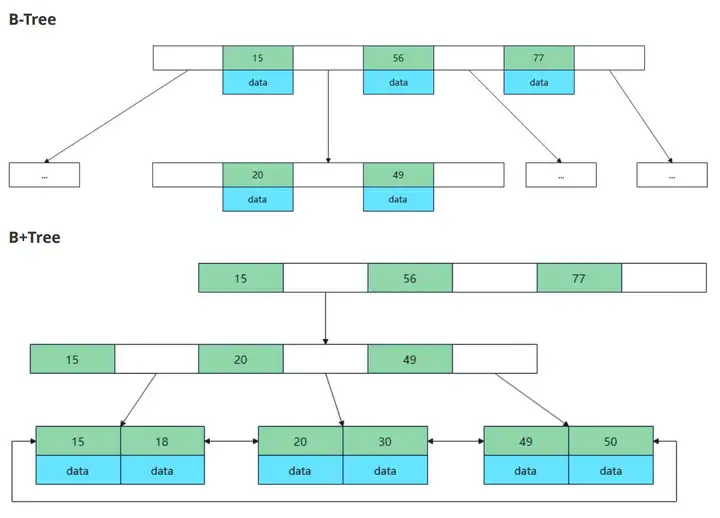
B+ 樹:主流的索引結構
查找過程:
1. 讀取根節點所有元素,因為是有序的,可以利用二分查找,高效查找到指定區間
2. 根據指定區間文件地址找到二級節點,讀取所有元素。
3. 找到葉子節點中指定元素位置。
2.4 索引查詢提速原理
以B+樹索引為例,
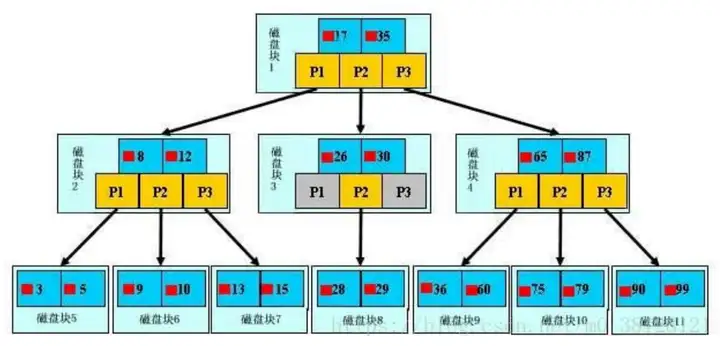
如果要查找數據項目29
1、首先進入1號塊,1號塊數據載入如記憶體,發生一次I/O
2、在記憶體中進行二分查找,發現29在17和35之前,於是鎖定P2指針,將3號塊數據載入到記憶體,又發生一次I/O
3、同理在3號塊中走P2指針鎖定8號數據塊,將8號數據塊載入到記憶體,最後發生一次I/O
4、遍歷8號塊的數據就能找到29號數據
如果沒有索引,最壞的情況是整個表格的數據塊都需要載入到記憶體,然後遍歷出結果,將產生大量的I/O開銷和對整表數據的遍歷。
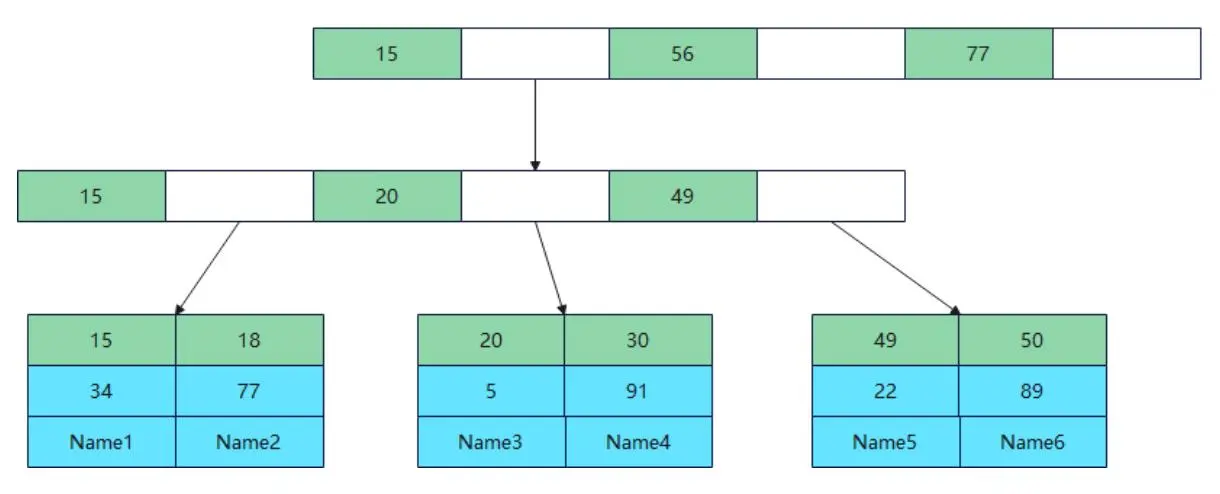
2.5 聚焦索引
聚焦索引尤其適合需要進行RANGE查找的列,這是因為他的葉子節點存放的是有序的數據行。在查詢過程中可以根據WHERE的條件定位到兩端葉子節點,然後將他們之間的整個鏈表結構取出。
2.6 左首碼優化原則
工程應用中經常有一些核心表需要按照多種形式查詢,如果為每一種查詢方式都建一個索引會影響表插入和更新的性能。
考慮到聯合索引在創建時每個子列都是排好序的,比如數據表A上有一個聯合縮影(a, b, c) , 那麼查詢where a = xxx ; where a = xxx and b = xxx都將命中縮影,因此可以利用這種特性按照業務需求設置少量聯合索引覆蓋多種查詢需求。
假設有表A, 有如下3種高頻查詢
select xx from A where a = xxx; select xx from A where b = xxx; select xx from A where a = xxx and b = xxx;
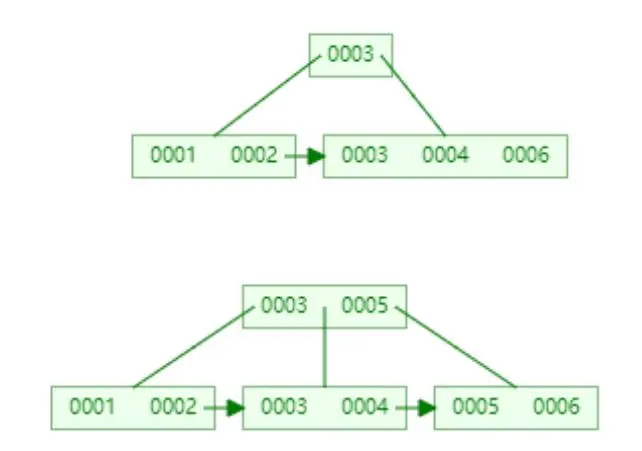
最簡單的辦法是 分別給a b (a, b) 建索引,但這就過於啰嗦。按照左首碼原則,最合理的索引建法應該是 b 和 (a, b)。
2.7 自增主鍵索引
1、InnoDB所有數據都是基於B+Tree存儲的,如果沒有主鍵mysql會在所有列中選擇可能唯一的列用作索 引id,如果查找不到會預設增加rowid列。
2、索引查找過程中會有大量數據比對的場景,如果使用uuid會逐位比對,效率會非常低,占用空間也會非 常大,占用過多ssd空間,存儲費用增大。
3、b+tree是有序樹,自增索引數據可以一直向後插入性能高,如果使用非自增索引,可能導致插入過程中 帶來樹分裂及平衡問題,帶來額外的性能損失。
3、常規資料庫優化順序
1、檢查SQL,查看執行計劃,是否命中索引?是否存在大量大表關聯?查詢的每個欄位都是必須的?...
2、加索引
3、分區
4、分表
5、改表結構,減少查詢種的關聯,增加冗餘欄位
6、加伺服器,彈性主機加U加記憶體換SSD...

