
來源:https://developer.aliyun.com/article/705239 1 什麼是KeyDB? KeyDB是Redis的高性能分支,專註於多線程,記憶體效率和高吞吐量。除了多線程之外,KeyDB還具有僅在Redis Enterprise中可用的功能,例如Active Replic ...
來源:https://developer.aliyun.com/article/705239
1 什麼是KeyDB?
KeyDB是Redis的高性能分支,專註於多線程,記憶體效率和高吞吐量。除了多線程之外,KeyDB還具有僅在Redis Enterprise中可用的功能,例如Active Replication,FLASH存儲支持以及一些根本不可用的功能,例如直接備份到AWS S3。
KeyDB與Redis協議,模塊和腳本保持完全相容性。這包括腳本和事務的原子性保證。由於KeyDB與Redis開發保持同步,因此KeyDB是Redis功能的超集,從而使KeyDB取代了現有Redis部署。
在相同的硬體上,KeyDB每秒可以執行的查詢數量是Redis的兩倍,而延遲卻降低了60%。Active-Replication簡化了熱備用故障轉移,使您可以輕鬆地在副本上分配寫操作並使用基於TCP的簡單負載平衡/故障轉移。KeyDB的高性能可讓您在更少的硬體上做更多的事情,從而降低了運營成本和複雜性。
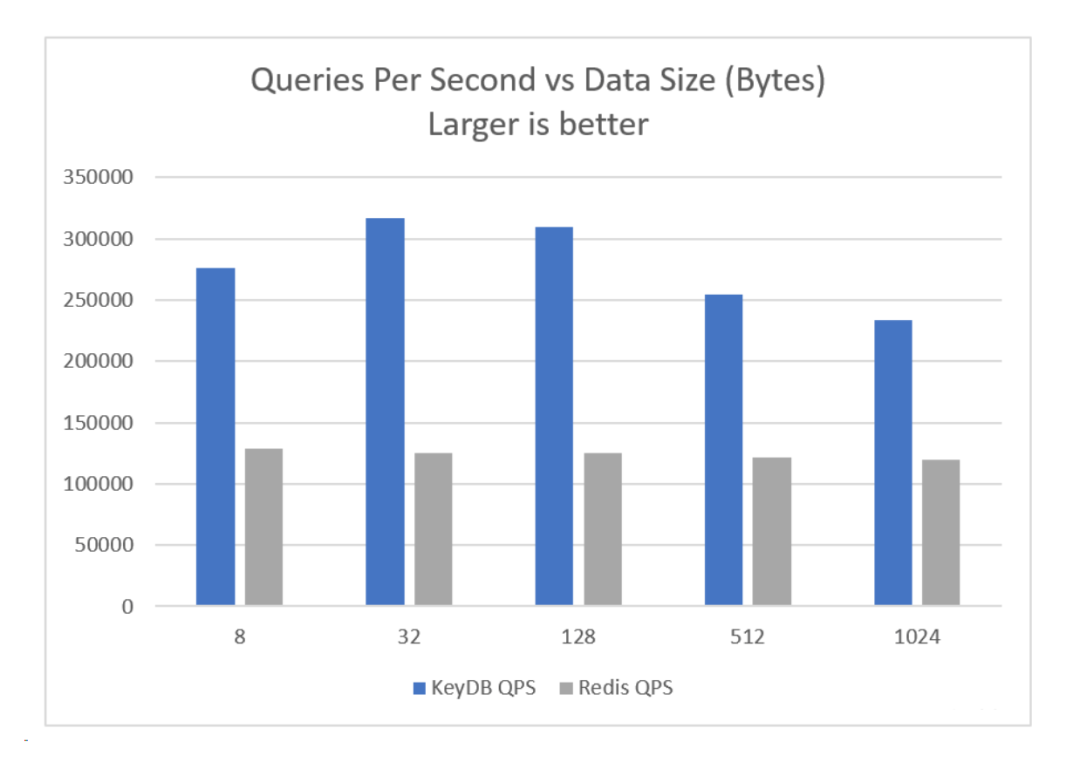
在此處查看完整的基準測試結果和設置信息:
2 走進KeyDB
KeyDB項目是從redis fork出來的分支。眾所周知redis是一個單線程的kv記憶體存儲系統,而KeyDB在100%相容redis API的情況下將redis改造成多線程。
項目git地址:
網上公開的技術細節比較少,本文基本是通過閱讀源碼總結出來的,如有錯漏之處歡迎指正。
推薦一個開源免費的 Spring Boot 最全教程:
多線程架構
線程模型
KeyDB將redis原來的主線程拆分成了主線程和worker線程。每個worker線程都是io線程,負責監聽埠,accept請求,讀取數據和解析協議。如圖所示:

KeyDB使用了SO_REUSEPORT特性,多個線程可以綁定監聽同個埠。
每個worker線程做了cpu綁核,讀取數據也使用了SO_INCOMING_CPU特性,指定cpu接收數據。
解析協議之後每個線程都會去操作記憶體中的數據,由一把全局鎖來控制多線程訪問記憶體數據。
主線程其實也是一個worker線程,包括了worker線程的工作內容,同時也包括只有主線程才可以完成的工作內容。在worker線程數組中下標為0的就是主線程。
主線程的主要工作在實現serverCron,包括:
- 處理統計
- 客戶端鏈接管理
- db數據的resize和reshard
- 處理aof
- replication主備同步
- cluster模式下的任務
鏈接管理
在redis中所有鏈接管理都是在一個線程中完成的。在KeyDB的設計中,每個worker線程負責一組鏈接,所有的鏈接插入到本線程的鏈接列表中維護。鏈接的產生、工作、銷毀必須在同個線程中。每個鏈接新增一個欄位
int iel; /* the event loop index we're registered with */
用來表示鏈接屬於哪個線程接管。
KeyDB維護了三個關鍵的數據結構做鏈接管理:
clients_pending_write:線程專屬的鏈表,維護同步給客戶鏈接發送數據的隊列clients_pending_asyncwrite:線程專屬的鏈表,維護非同步給客戶鏈接發送數據的隊列clients_to_close:全局鏈表,維護需要非同步關閉的客戶鏈接
分成同步和非同步兩個隊列,是因為redis有些聯動api,比如pub/sub,pub之後需要給sub的客戶端發送消息,pub執行的線程和sub的客戶端所線上程不是同一個線程,為了處理這種情況,KeyDB將需要給非本線程的客戶端發送數據維護在非同步隊列中。
同步發送的邏輯比較簡單,都是在本線程中完成,以下圖來說明如何同步給客戶端發送數據
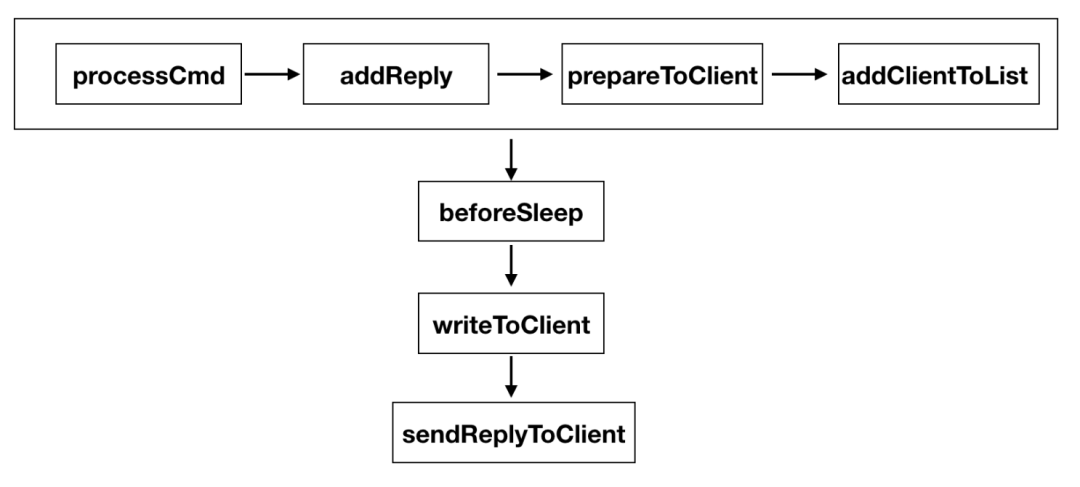
如上文所提到的,一個鏈接的創建、接收數據、發送數據、釋放鏈接都必須在同個線程執行。非同步發送涉及到兩個線程之間的交互。KeyDB通過管道在兩個線程中傳遞消息:
int fdCmdWrite; //寫管道
int fdCmdRead; //讀管道
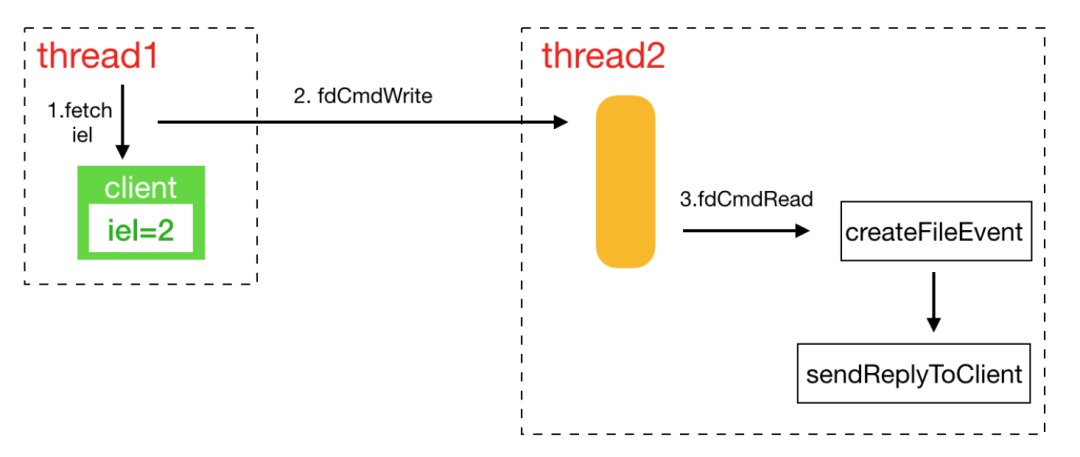
本地線程需要非同步發送數據時,先檢查client是否屬於本地線程,非本地線程獲取到client專屬的線程ID,之後給專屬的線程管到發送AE_ASYNC_OP::CreateFileEvent的操作,要求添加寫socket事件。專屬線程在處理管道消息時將對應的請求添加到寫事件中,如圖所示:
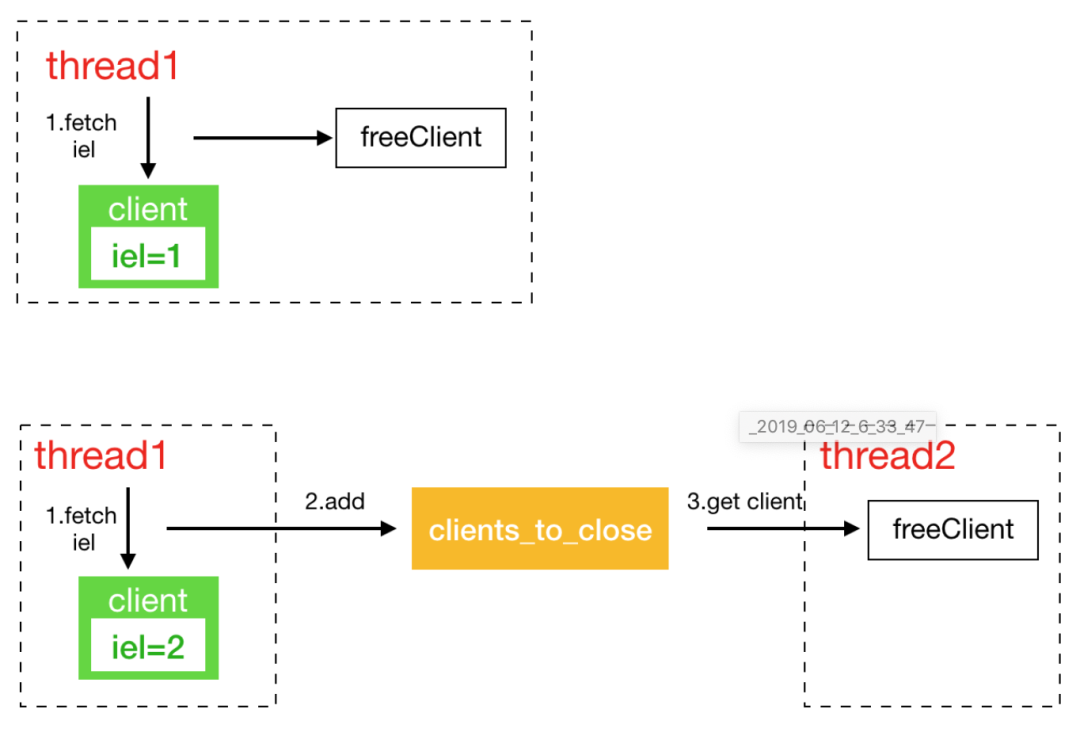
redis有些關閉客戶端的請求並非完全是在鏈接所在的線程執行關閉,所以在這裡維護了一個全局的非同步關閉鏈表。
鎖機制
KeyDB實現了一套類似spinlock的鎖機制,稱之為fastlock。
fastlock的主要數據結構有:
struct ticket
{
uint16_t m_active; //解鎖+1
uint16_t m_avail; //加鎖+1
};
struct fastlock
{
volatile struct ticket m_ticket;
volatile int m_pidOwner; //當前解鎖的線程id
volatile int m_depth; //當前線程重覆加鎖的次數
};
使用原子操作__atomic_load_2,__atomic_fetch_add,__atomic_compare_exchange來通過比較m_active=m_avail判斷是否可以獲取鎖。fastlock提供了兩種獲取鎖的方式:
- try_lock:一次獲取失敗,直接返回
- lock:忙等,每
1024 * 1024次忙等後使用sched_yield主動交出cpu,挪到cpu的任務末尾等待執行。
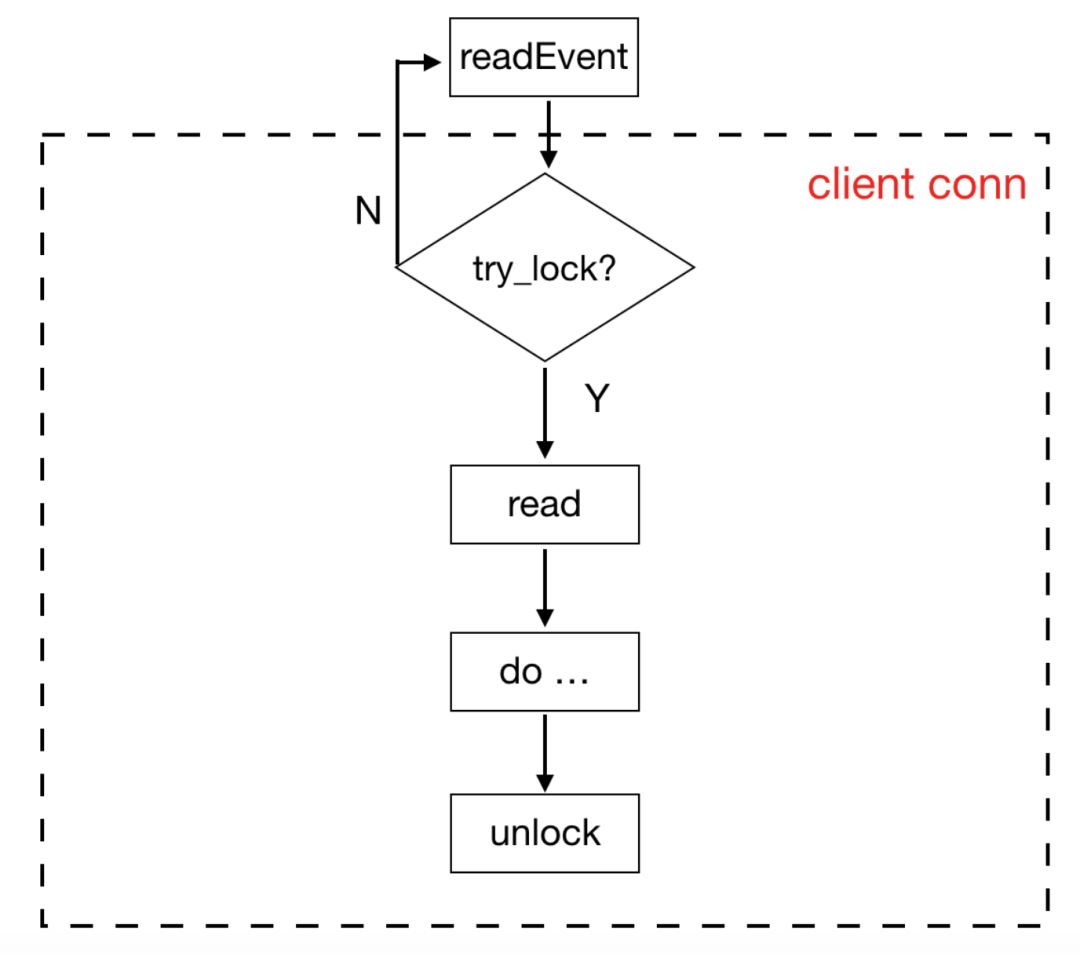
在KeyDB中將try_lock和事件結合起來,來避免忙等的情況發生。每個客戶端有一個專屬的lock,在讀取客戶端數據之前會先嘗試加鎖,如果失敗,則退出,因為數據還未讀取,所以在下個epoll_wait處理事件迴圈中可以再次處理。
Active-Replica
KeyDB實現了多活的機制,每個replica可設置成可寫非只讀,replica之間互相同步數據。主要特性有:
- 每個replica有個uuid標誌,用來去除環形複製
- 新增加rreplay API,將增量命令打包成rreplay命令,帶上本地的uuid
- key,value加上時間戳版本號,作為衝突校驗,如果本地有相同的key且時間戳版本號大於同步過來的數據,新寫入失敗。採用當前時間戳向左移20位,再加上後44位自增的方式來獲取key的時間戳版本號。
參考文檔:https://docs.keydb.dev/docs/commands
近期熱文推薦:
1.1,000+ 道 Java面試題及答案整理(2022最新版)
4.別再寫滿屏的爆爆爆炸類了,試試裝飾器模式,這才是優雅的方式!!
覺得不錯,別忘了隨手點贊+轉發哦!

