
實時同步是 ChunJun 的⼀個重要特性,指在數據同步過程中,數據源與⽬標系統之間的數據傳輸和更新⼏乎在同⼀時間進⾏。 在實時同步場景中我們更加關註源端,當源系統中的數據發⽣變化時,這些變化會⽴即傳輸並應⽤到⽬標系統,以保證兩個系統中的數據保持⼀致。這個特性需要作業運⾏過程中 source 插件不 ...
實時同步是 ChunJun 的⼀個重要特性,指在數據同步過程中,數據源與⽬標系統之間的數據傳輸和更新⼏乎在同⼀時間進⾏。
在實時同步場景中我們更加關註源端,當源系統中的數據發⽣變化時,這些變化會⽴即傳輸並應⽤到⽬標系統,以保證兩個系統中的數據保持⼀致。這個特性需要作業運⾏過程中 source 插件不間斷地頻繁訪問源端。在⽣產場景下,對於這類⻓時間運⾏、資源可預估、需要穩定性的作業,我們推薦使⽤ perjob 模式部署。
插件⽀持 JSON 腳本和 SQL 腳本兩種配置⽅式,具體的參數配置請參考「ChunJun連接器文檔」:https://sourl.cn/vxq6Zp
本文將為大家介紹如何使用 ChunJun 實時同步,以及 ChunJun ⽀持的 RDB 實時採集插件的特性、採集邏輯及其原理,幫助大家更好地理解 ChunJun 與實時同步。
如何使用 ChunJun 實時同步
為了讓⼤家能更深⼊瞭解如何使⽤ ChunJun 做實時同步,我們假設有這樣⼀個場景:⼀個電商⽹站希望將其訂單數據從 MySQL 資料庫實時同步到 HBase 資料庫,以便於後續的數據分析和處理。
在這個場景中,我們將使⽤ Kafka 作為中間消息隊列,以實現 MySQL 和 HBase 之間的數據同步。這樣做的好處是 MySQL 表中變更可以實時同步到 HBase 結果表中,⽽不⽤擔⼼歷史數據被修改後 HBase 表未被同步。
如果在⼤家的實際應用場景中,不關⼼歷史數據是否變更(或者歷史數據根本不會變更),且業務表有⼀個遞增的主鍵,那麼可以參考本⽂之後的 JDBC-Polling 模式⼀節的內容。
· 數據源組件的部署以及 ChunJun 的部署這⾥不做詳細描述
· 案例中的腳本均以 SQL 腳本為例,JSON 腳本也能實現相同功能,但在參數名上可能存在出⼊,使⽤ JSON 的同學可以參考上文 「ChunJun 連接器」⽂檔中的參數介紹
採集 MySQL 數據到 Kafka
● 數據準備
⾸先,我們在 Kafka 中創建⼀個名為 order_dml 的 topic,然後在 MySQL 中創建⼀個訂單表,並插⼊⼀些測試數據。創建表的 SQL 語句如下:
-- 創建⼀個名為ecommerce_db的資料庫,⽤於存儲電商⽹站的數據
CREATE DATABASE IF NOT EXISTS ecommerce_db;
USE ecommerce_db;
-- 創建⼀個名為orders的表,⽤於存儲訂單信息
CREATE TABLE IF NOT EXISTS orders (
id INT AUTO_INCREMENT PRIMARY KEY, -- ⾃增主鍵
order_id VARCHAR(50) NOT NULL, -- 訂單編號,不能為空
user_id INT NOT NULL, -- ⽤戶ID,不能為空
product_id INT NOT NULL, -- 產品ID,不能為空
quantity INT NOT NULL, -- 訂購數量,不能為空
order_date TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP -- 訂單⽇期,預設值為當前時間
戳,不能為空
);
-- 插⼊⼀些測試數據到orders表
INSERT INTO orders (order_id, user_id, product_id, quantity)
VALUES ('ORD123', 1, 101, 2),
('ORD124', 2, 102, 1),
('ORD125', 3, 103, 3),
('ORD126', 1, 104, 1),
('ORD127', 2, 105, 5);
● 使用 Binlog 插件採集數據到 Kafka
為了表示數據的變化類型和更好地處理數據變化,實時採集插件一般會用 RowData(Flink 內部數據結構)中的 RowKind 記錄⽇志中的數據事件(insert、delete 等)類型,binlog 插件也⼀樣。而當數據被打到 Kafka 中時,RowKind 信息應該怎麼處理呢?
這⾥我們就需要⽤到 upsert-kafka-x,upsert-kafka-x 會識別 RowKind。對各類時間的處理邏輯如下:
• insert 數據:序列化後直接打⼊
• delete 數據:只寫 key,value 置為 null
• update 數據:分為⼀條 delete 數據和 insert 數據處理,即先根據主鍵刪除原本的數據,再寫⼊ update 後的數據
在下⼀步中我們再解釋如何將 Kafka 中的數據還原到 HBase 或者其他⽀持 upsert 語義的資料庫中,接下來我們來編寫 SQL 腳本,實現 MySQL 數據實時採集到 Kafka 中的功能,示例如下:
CREATE TABLE binlog_source (
id int,
order_id STRING,
user_id INT,
product_id int,
quantity int,
order_date TIMESTAMP(3)
) WITH (
'connector' = 'binlog-x',
'username' = 'root',
'password' = 'root',
'cat' = 'insert,delete,update',
'url' = 'jdbc:mysql://localhost:3306/ecommerce_db?useSSL=false',
'host' = 'localhost',
'port' = '3306',
'table' = 'ecommerce_db.orders',
'timestamp-format.standard' = 'SQL',
'scan.parallelism' = '1'
);
CREATE TABLE kafka_sink (
id int,
order_id STRING,
user_id INT,
product_id int,
quantity int,
order_date TIMESTAMP(3),PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'upsert-kafka-x',
'topic' = 'orders',
'properties.bootstrap.servers' = 'localhost:9092',
'key.format' = 'json',
'value.format' = 'json',
'value.fields-include' = 'ALL',
'sink.parallelism' = '1'
);
insert into
kafka_sink
select
*
from
binlog_source u;
還原 Kafka 中的數據到 HBase
上述步驟中,我們通過 binlog-x 和 upsert-kafka-x,將 MySQL 中的數據實時採集到了 Kafka 中。解鈴還須系鈴⼈,我們可以通過 upsert-kafka-x 再去將 Kafka 中的數據解析成帶有 upsert 語義的數據。
upsert-kafka-x 作為 source 插件時,會判斷 Kafka 中數據的 value 是否為 null,如果 value 為 null 則標記這條數據的 RowKind 為 DELETE,否則將數據的 ROWKIND 標記為 INSERT。
ChunJun的 hbase-x 插件⽬前已經具備了 upsert 語句的能⼒,使⽤ hbase-x 即可將 Kafka 中的數據還原到 hbase中。接下來是 SQL 腳本示例,為了⽅便在 HBase 中查看數據結果,我們將 int 數據 cast 為 string 類型:
CREATE TABLE kafka_source (
id int,
order_id STRING,
user_id INT,
product_id INT,
quantity INT,
order_date TIMESTAMP(3),
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'upsert-kafka-x',
'topic' = 'orders',
'properties.bootstrap.servers' = 'localhost:9092',
'properties.group.id' = 'test_group',
'key.format' = 'json',
'value.format' = 'json',
'scan.parallelism' = '1'
);
CREATE TABLE hbase_sink(
rowkey STRING, order_info ROW < order_id STRING,
user_id STRING,
product_id STRING,
quantity STRING,
order_date STRING >,
PRIMARY KEY (rowkey) NOT ENFORCED
) WITH(
-- 這⾥以hbase14為例,如果hbase版本是2.x,我們可以使⽤hbase2-x插件代替
'connector' = 'hbase14-x',
'zookeeper.quorum' = 'localhost:2181',
'zookeeper.znode.parent' = '/hbase',
'table-name' = 'ecommerce_db:orders',
'sink.parallelism' = '1'
);
INSERT INTO
hbase_sink
SELECT
cast(id as STRING),
ROW(
cast(order_id as STRING),
cast(user_id as STRING),
cast(product_id as STRING),
cast(quantity as STRING),
cast(order_date as STRING)
)
FROM
kafka_source
Tips:如果我們不需要 Kafka 中間件,也可以使⽤ binlog-x 插件直接對接 hbase-x 插件。
ChunJun 支持的 RDB 實時採集插件
本節主要介紹 ChunJun 的 RDB 實時採集插件的特性、採集邏輯及其原理。
ChunJun 的 RDB 實時採集可以實時監視資料庫中的更改,併在發⽣更改時讀取數據變化,例如插⼊、更新和刪除操作。使⽤ ChunJun 實時採集,我們可以實時獲取有關資料庫中更改的信息,從⽽能夠及時響應這些更改,如此便可以幫助我們更好地管理和利⽤ RDB 資料庫中的數據。
並且 ChunJun 提供了故障恢復和斷點續傳功能來確保數據的完整性。ChunJun 實時採集類插件的⼤致實現步驟如下:
· 連接資料庫,確認讀取點位,讀取點位可以理解為⼀個 offset,如 Binlog 中,指⽇志的⽂件名和⽂件的 position 信息
· 根據讀取點位開始讀取 redolog,獲取其中關於數據變更相關的操作記錄
· 根據 tableName、操作事件(如insert、delete、update)等過濾信息過濾出需要的 log ⽇志
· 解析 log ⽇志,解析後的事件信息包括表名、資料庫名、操作類型(插⼊、更新或刪除)和變更的數據⾏等
· 將解析出來的數據會加⼯為 ChunJun 內部統⼀的 DdlRowData 供下游使⽤
ChunJun ⽬前已⽀持的實時採集 Connector 有:binlog(mysql)、oceanbasecdc、oraclelogminer、sqlservercdc。
Binlog 簡介
ChunJun binlog 插件的主要功能是讀取 MySQL 的⼆進位⽇志(binlog)⽂件。這些⽂件記錄了所有對數據的更改操作,如插⼊、更新和刪除等。⽬前,該插件依賴 Canal 組件來讀取 MySQL 的 binlog ⽂件。
核⼼操作步驟如下:
• 確認讀取點位:在 binlog 插件中,我們可以在腳本的 start 欄位中直接指定 journal-name(binlog ⽂件名)和 position(⽂件的特定位置)
• 讀取binlog:binlog 插件將⾃身偽裝成 MySQL 的 Slave 節點,向 MySQL Master 發送請求,要求將 binlog ⽂件的數據流發送給它
• 故障恢復和斷點續傳:故障時,插件會記錄當前的 binlog 位置信息,從 checkpoint/savepoint 恢復後,我們可以從上次記錄的位置繼續讀取 binlog ⽂件,確保數據變化的完整性
使⽤ binlog 所需的許可權在「binlog插件使⽤⽂檔」中有詳細說明,鏈接如下:
OracleLogminer 簡介
Logminer 插件藉助 Oracle 提供的 Logminer ⼯具通過讀取視圖的⽅式獲取 Oracle redolog 中的信息。
核⼼操作步驟如下:
01 定位需讀取起始點位(start_scn)
⽬前 logminer ⽀持四種策略指定 StartScn:
· all:從 Oracle 資料庫中最早的歸檔⽇志組開始採集(不建議使⽤)
· current:任務運⾏時的 SCN 號
· time:指定時間點對應的 SCN 號
· scn:直接指定 SCN 號
02 定位需要讀取的結束點位(end_scn)
插件根據 start_scn 和 maxLogFileSize(預設5G)獲取可載入的 redolog ⽂件列表,end_scn 取這個⽂件列表中最⼤的 scn 值。
03 載入 redo ⽇志到 Logminer
通過⼀個存儲過程,將 scn 區間範圍內的 redolog 載入到 Logminer ⾥。
04 從視圖中讀取數據
以 scn > ? 作為 where 條件直接查詢 v$logmnr_contents 視圖內的信息即可獲取 redolog 中的數據。
05 重覆1-4步驟,實現不斷的讀取
如標題。
06 故障恢復和斷點續傳
在發⽣故障時,插件會保存當前消費的 scn 號,重啟時從上次的 scn 號開始讀取,確保數據完整性。
• 關於該插件原理的詳細介紹請參⻅「Oracle Logminer 實現原理說明⽂檔」:
• 使⽤lominer插件的前提條件詳⻅「Oracle配置LogMiner」:
SqlServerCDC 簡介
SqlServerCDC 插件依賴 SQL Server 的 CDC Agent 服務提供的視圖獲取 redolog 中的信息。
核⼼操作步驟如下:
01 定位需讀取起始點位(from_lsn)
⽬前 SqlserverCDC 僅⽀持直接配置 lsn 號,如果 lsn 號未配置,則取資料庫中當前最⼤的 lsn 號為 from_lsn。
02 定位需要讀取的結束點位(to_lsn)
SqlserverCDC 插件定期地(可通過 pollInterval 參數指定)獲取資料庫中的最⼤ lsn 為 end_lsn。
03 從視圖中讀取數據
查詢 Agent 服務提供的視圖中 lsn 區間範圍內的數據,過濾出需要監聽的表及事件類型。
04 重覆1-3步驟,實現不斷的讀取
如標題。
05 故障恢復和斷點續傳
在發⽣故障時,插件會保存當前消費的 lsn 號。重啟時從上次的 lsn 號開始讀取,確保數據完整性。
• 關於該插件原理的詳細介紹請參⻅「Sqlserver CDC 實現原理說明⽂檔」:
• 配置 SqlServer CDC Agent 服務詳⻅「Sqlserver 配置 CDC ⽂檔」:
OceanBaseCDC 簡介
OceanBase 是螞蟻集團開源的⼀款分散式關係型資料庫,它使⽤⼆進位⽇志(binlog)記錄數據變更。OceanBaseCDC 的實現依賴於 OceanBase 提供的 LogProxy 服務,LogProxy 提供了基於發佈-訂閱模型的服務,允許使⽤ OceanBase 的 logclient 訂閱特定的 binlog 數據流。
OceanBaseCDC 啟動⼀個 Listener 線程。當 logclient 連接到 LogProxy 後,Listener 會訂閱經過數據過濾的 binlog,然後將其添加到內部維護的列表中。當收到 COMMIT 信息後,Listener 會將⽇志變更信息傳遞給⼀個阻塞隊列,由主線程消費並將其轉換為 ChunJun 內部的 DdlRowData,最終發送到下游。
JDBC-Polling 模式讀
JDBC 插件的 polling 讀取模式是基於 SQL 語句做數據讀取的,相對於基於重做⽇志的實時採集成本更低,但 jdbc 插件做實時同步對業務場景有更⾼的要求:
· 有⼀個數值類型或者時間類型的遞增主鍵
· 不更新曆史數據或者不關⼼歷史數據是否更新,僅關⼼新數據的獲取
實現原理簡介
• 設置遞增的業務主鍵作為 polling 模式依賴的增量鍵
• 在增量讀取的過程中,實時記錄 increColumn 對應的值(state),作為下⼀次數據讀取的起始點位
• 當⼀批數據讀取完後,間隔⼀段時間之後依據 state 讀取下⼀批數據
polling 依賴部分增量同步的邏輯,關於增量同步的更多介紹可以點擊:
如何配置⼀個 jdbc-polling 作業
先介紹⼀下開啟 polling 模式需要關註的配置項:
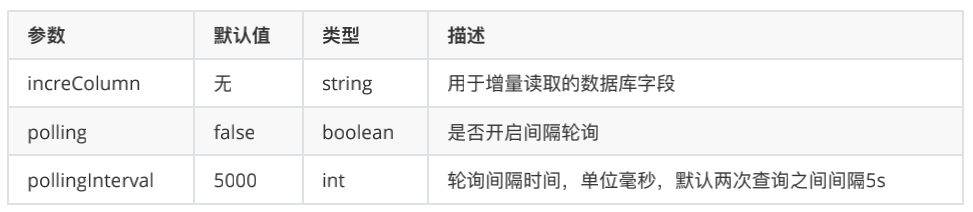
以 MySQL 為例,假設我們有⼀個存儲訂單信息的歷史表,且訂單的 order_id 是遞增的,我們希望定期地獲取這張表的新增數據。
CREATE TABLE order.realtime_order_archive (
order_id INT PRIMARY KEY COMMENT '訂單唯⼀標識',
customer_id INT COMMENT '客戶唯⼀標識',
product_id INT COMMENT '產品唯⼀標識',
order_date TIMESTAMP COMMENT '訂單⽇期和時間',
payment_method VARCHAR(255) COMMENT '⽀付⽅式(信⽤卡、⽀付寶、微信⽀付等)',
shipping_method VARCHAR(255) COMMENT '配送⽅式(順豐速運、圓通速遞等)',
shipping_address VARCHAR(255) COMMENT '配送地址',
order_total DECIMAL(10,2) COMMENT '訂單總⾦額',
discount DECIMAL(10,2) COMMENT '折扣⾦額',
order_status VARCHAR(255) COMMENT '訂單狀態(已完成、已取消等)'
);
我們可以這樣配置 json 腳本的 reader 信息。
"name": "mysqlreader",
"parameter": {
"column" : [
"*" //這⾥假設我們讀取所有欄位,可以填寫‘*’
],
"increColumn": "id",
"polling": true,
"pollingInterval": 3000,
"username": "username",
"password": "password",
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://ip:3306/liuliu?useSSL=false"
],
"schema":"order",
"table": [
"realtime_order_archive" ]
}
]
}
}
《數棧產品白皮書》:https://fs80.cn/cw0iw1
《數據治理行業實踐白皮書》下載地址:https://fs80.cn/380a4b
想瞭解或咨詢更多有關袋鼠雲大數據產品、行業解決方案、客戶案例的朋友,瀏覽袋鼠雲官網:https://www.dtstack.com/?src=szbky
同時,歡迎對大數據開源項目有興趣的同學加入「袋鼠雲開源框架釘釘技術qun」,交流最新開源技術信息,qun號碼:30537511,項目地址:https://github.com/DTStack


