
GreatSQL社區原創內容未經授權不得隨意使用,轉載請聯繫小編並註明來源。 GreatSQL是MySQL的國產分支版本,使用上與MySQL一致。 作者: 奧特曼愛小怪獸 文章來源:GreatSQL社區投稿 上一篇 MySQL8.0 優化器介紹(一)介紹了成本優化模型的三要素:表關聯順序,與每張表返 ...
- GreatSQL社區原創內容未經授權不得隨意使用,轉載請聯繫小編並註明來源。
- GreatSQL是MySQL的國產分支版本,使用上與MySQL一致。
- 作者: 奧特曼愛小怪獸
- 文章來源:GreatSQL社區投稿
上一篇 MySQL8.0 優化器介紹(一)介紹了成本優化模型的三要素:表關聯順序,與每張表返回的行數(過濾效率),查詢成本。而join演算法又是影響表關聯效率的首要因素。
join演算法(Join Algorithms)
join在MySQL 是一個如此重要的章節,毫不誇張的說,everything is a join。
截止到本文寫作時,MySQL8.0.32 GA已經發行,這裡主要介紹三大join:NL(Nested Loop),BNL(Block Nested Loop),HASH JOIN
嵌套迴圈(Nested Loop)
MySQL5.7之前,都只有NL,它實現簡單,適合索引查找。
幾乎每個人都可以手動實現一個NL。
SELECT CountryCode,
country.Name AS Country,
city.Name AS City,
city.District
FROM world.country
INNER JOIN world.city
ON city.CountryCode = country.Code
WHERE Continent = 'Asia';
##執行計劃類似如下:
-> Nested loop inner join
-> Filter: (country.Continent = 'Asia')
-> Table scan on country
-> Index lookup on city using CountryCode
(CountryCode=country.`Code`)
##python 代碼實現一個NL
result = []
for country_row in country:
if country_row.Continent == 'Asia':
for city_row in city.CountryCode['country_row.Code']:
result.append(join_rows(country_row, city_row))
圖示化一個NL
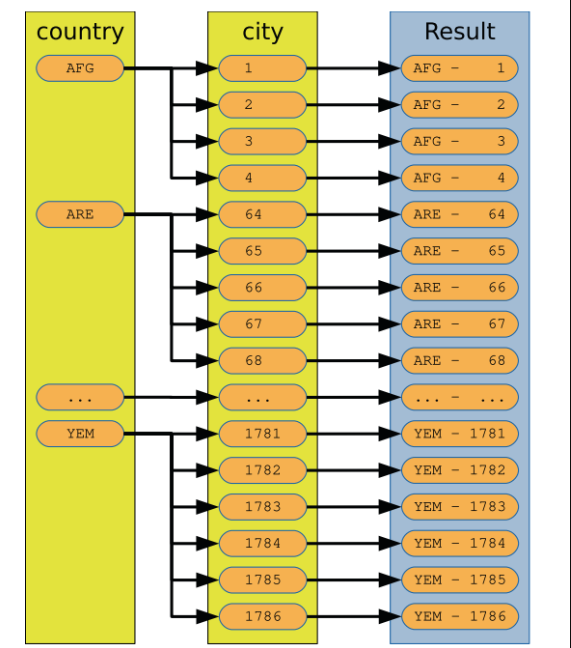
NL的限制:通常多個表join,小表在前做驅動表,被驅動表有索引檢索,效率會高一些。(官方手冊上沒有full outer join ,full join 語法,實際支持full join)
舉個例子 多表join 且關聯表不走索引:
#人為干預計劃,走性能最差的執行路徑。
SELECT /*+ NO_BNL(city) */
CountryCode,
country.Name AS Country,
city.Name AS City,
city.District
FROM world.country IGNORE INDEX (Primary)
INNER JOIN world.city IGNORE INDEX (CountryCode)
ON city.CountryCode = country.Code
WHERE Continent = 'Asia';
SELECT rows_examined, rows_sent,
last_statement_latency AS latency
FROM sys.session
WHERE thd_id = PS_CURRENT_THREAD_ID()\G
**************************** 1. row ****************************
rows_examined: 208268
rows_sent: 1766
latency: 44.83 ms
##對比一下優化器 自動優化後的
SELECT CountryCode,
country.Name AS Country,
city.Name AS City,
city.District
FROM world.country
INNER JOIN world.city
ON city.CountryCode = country.Code
WHERE Continent = 'Asia';
SELECT rows_examined, rows_sent,
last_statement_latency AS latency
FROM sys.session
WHERE thd_id = PS_CURRENT_THREAD_ID()\G
*************************** 1. row ***************************
rows_examined: 2005
rows_sent: 1766
latency: 4.36 ms
1 row in set (0.0539 sec)
塊嵌套迴圈(Block Nested Loop)
塊嵌套迴圈演算法是嵌套迴圈演算法的擴展。它也被稱為BNL演算法。連接緩衝區用於收集儘可能多的行,併在第二個表的一次掃描中比較所有行,而不是逐個提交第一個表中的行。這可以大大提高NL在某些查詢上的性能。
hash join是在MySQL8.0.18引進的,下麵的sql,使用了NO_HASH_JOIN(country,city) 的提示,並且兩表的join 欄位上的索引被忽略,目的是為了介紹BNL特性。
SELECT /*+ NO_HASH_JOIN(country,city) */
CountryCode,
country.Name AS Country,
city.Name AS City,
city.District
FROM world.country IGNORE INDEX (Primary)
INNER JOIN world.city IGNORE INDEX (CountryCode)
ON city.CountryCode = country.Code
WHERE Continent = 'Asia';
##使用python偽代碼來解釋一下 BNL
result = []
join_buffer = []
for country_row in country:
if country_row.Continent == 'Asia':
join_buffer.append(country_row.Code)
if is_full(join_buffer):
for city_row in city:
CountryCode = city_row.CountryCode
if CountryCode in join_buffer:
country_row = get_row(CountryCode)
result.append(
join_rows(country_row, city_row))
join_buffer = []
if len(join_buffer) > 0:
for city_row in city:
CountryCode = city_row.CountryCode
if CountryCode in join_buffer:
country_row = get_row(CountryCode)
result.append(join_rows(country_row, city_row))
join_buffer = []
圖示化一個BNL
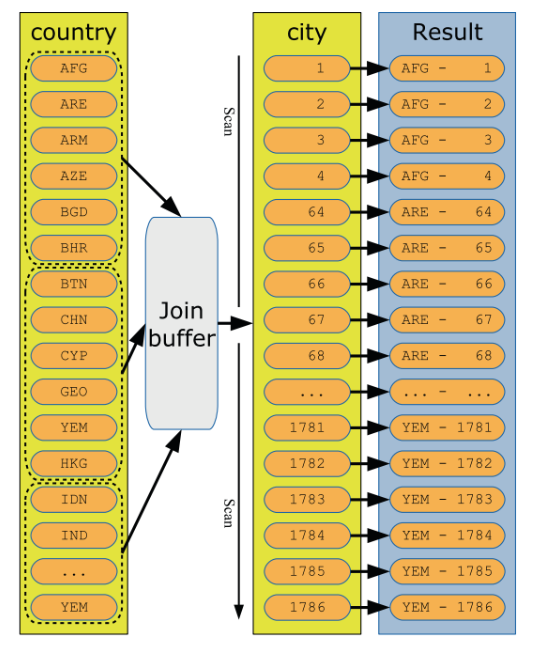
註意圖裡的join_buffer,在MySQL5.7上使用sysbench壓測讀寫場景,壓力上不去,主要就是因為BNL 演算法下,join_buffer_size的設置為預設值。適當調整幾個buffer後,tps得到顯著提高。join buffer對查詢影響,也可以用下麵的例子做一個量化說明。
SELECT /*+ NO_HASH_JOIN(country,city) */
CountryCode,
country.Name AS Country,
city.Name AS City,
city.District
FROM world.country IGNORE INDEX (Primary)
INNER JOIN world.city IGNORE INDEX (CountryCode)
ON city.CountryCode = country.Code
WHERE Continent = 'Asia';
SELECT rows_examined, rows_sent,
last_statement_latency AS latency
FROM sys.session
WHERE thd_id = PS_CURRENT_THREAD_ID()\G
*************************** 1. row ***************************
rows_examined: 4318
rows_sent: 1766
latency: 16.87 ms
1 row in set (0.0490 sec)
#人為干預計劃,走性能最差的執行路徑。
SELECT /*+ NO_BNL(city) */
CountryCode,
country.Name AS Country,
city.Name AS City,
city.District
FROM world.country IGNORE INDEX (Primary)
INNER JOIN world.city IGNORE INDEX (CountryCode)
ON city.CountryCode = country.Code
WHERE Continent = 'Asia';
SELECT rows_examined, rows_sent,
last_statement_latency AS latency
FROM sys.session
WHERE thd_id = PS_CURRENT_THREAD_ID()\G
**************************** 1. row ****************************
rows_examined: 208268
rows_sent: 1766
latency: 44.83 ms
在兩表join,且join欄位不使用索引的前提下,BNL +join_buffer 性能遠大於 NL
使用BNL 有幾個點需要註意。(我實在懶得全文翻譯官方文檔了)
- Only the columns required for the join are stored in the join buffer. This means that you will need less memory for the join buffer than you may at first expect. (不需要配置太高buffer)
- The size of the join buffer is configured with the join_buffer_size variable. The value of join_buffer_size is the minimum size of the buffer! Even if less than 1 KiB of country code values will be stored in the join buffer in the discussed example, if join_buffer_size is set to 1 GiB, then 1 GiB will be allocated. For this reason, keep the value of join_buffer_size low and only increase it as needed.
- One join buffer is allocated per join using the block nested loop algorithm.
- Each join buffer is allocated for the entire duration of the query.
- The block nested loop algorithm can be used for full table scans, full index scans, and range scans.(適用table access 方式)
- The block nested loop algorithm will never be used for constant tables as well as the first nonconstant table. This means that it requires a join between two tables with more than one row after filtering by unique indexes to use the block nested loop algorithm
可以通過 optimizer switch 配置BNL() 、 NO_BNL()
BNL 特別擅長在non-indexed joins 的場景,很多時候性能優於hash join。As of version 8.0.20, block nested-loop joins are no longer used; instead, a hash join has replaced it.
哈希join (Hash Join)

Hash Join 作為大殺器在 MySQL8.0.18引入,期間有過引起記憶體和文件句柄大量消耗的線上問題,但是不妨礙它作為一個join演算法的重大突破,特別適合大表與大表的無索引join。某些場景甚至比NL+index join 更快。(當然比起oracle 上的hash join 依然弱爆了,40w * 40w 的大表查詢,MySQL優化到極致在10s左右,oracle在1s 水平,相差一個數量級。
思考:MySQL、Oracle都是hash join,為何差距如此大?MySQL hash join 可以哪些方面進行性能提高?
業界主要有兩大方向
- 單線程hash優化演算法和數據結構
- NUMA架構下,多線程Hash Join的優化主要是能夠讓讀寫數據儘量發生在當前NUMA node
參考文檔(https://zhuanlan.zhihu.com/p/589601705)
大家不妨看看 MySQL工程師的worklog, 內容很精彩(https://dev.mysql.com/worklog/task/?id=2241)
可以看出國外大廠強大的標準化的it生產能力,一個功能從需求到實現經歷了哪些關鍵步驟。
MySQL 的Hash join是一個記憶體hash+磁碟hash的混合擴展。為了不讓hash join 溢出join buffer,需要加大記憶體設置,使用磁碟hash時,需要配置更多的文件句柄數。儘管有disk hash ,但實際幹活的還是in-memory hash。
記憶體hash 有兩個階段:
- build phase. One of the tables in the join is chosen as the build table. The hash is calculated for the columns required for the join and loaded into memory.
- probe phase. The other table in the join is the probe input. For this table, rows are read one at a time, and the hash is calculated. Then a hash key lookup is performed on the hashes calculated from the build table, and the result of the join is generated from the matching rows.
當hashes of build table 不足以全部放進記憶體時,MySQL會自動切換到on-disk的擴展實現(基於 GRACE hash join algorithm)。在build phase階段,join buffer滿,就會發生 in-mem hash 向on-disk hash 轉換。
on-disk algorithm 包含3個步驟:
- Calculate the hashes of all rows in both the build and probe tables and store them on disk in several small files partitioned by the hash. The number of partitions is chosen to make each partition of the probe table fit into the join buffer but with a limit of at most 128 partitions.
- Load the first partition of the build table into memory and iterate over the hashes from the probe table in the same way as for the probe phase for the in-memory algorithm. Since the partitioning in step 1 uses the same hash function for both the build and probe tables, it is only necessary to iterate over the first partition of the probe table.
- Clear the in-memory buffer and continue with the rest of the partitions one by one
無論是記憶體hash還是磁碟hash,都使用xxHash64 hash function。xxHash64有足夠快,hash質量好(reducing the number of hash collisions)的特點
BNL不會被選中的時候,MySQL就會選用hash join。
在整理這篇資料時,對要使用的哈希連接演算法存在以下要求:
- The join must be an inner join.
- The join cannot be performed using an index, either because there is no available index or because the indexes have been disabled for the query.
- All joins in the query must have at least one equi-join condition between the two tables in the join, and only columns from the two tables as well as constants are referenced in the condition. (查詢中的所有聯接必須在聯接中的兩個表之間至少有一個等聯接條件,並且在該條件中僅引用兩個表中的列以及常量)
- As of 8.0.20, anti, semi, and outer joins are also supported. If you join the two tables t1 and t2, then examples of join conditions that are supported for hash join include
- t1.t1_val = t2.t2_val
- t1.t1_val = t2.t2_val + 2
- t1.t1_val1 = t2.t2_val AND t1.t1_val2 > 100
- MONTH(t1.t1_val) = MONTH(t2.t2_val)
用一個例子來說明一下hash join:
SELECT CountryCode,
country.Name AS Country,
city.Name AS City,
city.District
FROM world.country IGNORE INDEX (Primary)
INNER JOIN world.city IGNORE INDEX (CountryCode)
ON city.CountryCode = country.Code
WHERE Continent = 'Asia';
#用一段偽代碼翻譯一下
result = []
join_buffer = []
partitions = 0
on_disk = False
for country_row in country:
if country_row.Continent == 'Asia':
hash = xxHash64(country_row.Code)
if not on_disk:
join_buffer.append(hash)
if is_full(join_buffer):
# Create partitions on disk
on_disk = True
partitions = write_buffer_to_disk(join_buffer)
join_buffer = []
else
write_hash_to_disk(hash)
if not on_disk:
for city_row in city:
hash = xxHash64(city_row.CountryCode)
if hash in join_buffer:
country_row = get_row(hash)
city_row = get_row(hash)
result.append(join_rows(country_row, city_row))
else:
for city_row in city:
hash = xxHash64(city_row.CountryCode)
write_hash_to_disk(hash)
for partition in range(partitions):
join_buffer = load_build_from_disk(partition)
for hash in load_hash_from_disk(partition):
if hash in join_buffer:
country_row = get_row(hash)
city_row = get_row(hash)
result.append(join_rows(country_row, city_row))
join_buffer = []
與所使用的實際演算法相比,所描述的演算法稍微簡化了一些。
真正的演算法必須考慮哈希衝突,
而對於磁碟上的演算法,某些分區可能會變得太大而無法放入連接緩衝區,
在這種情況下,它們會被分塊處理,以避免使用比配置的記憶體更多的記憶體
圖示化一下 in-mem hash 演算法:
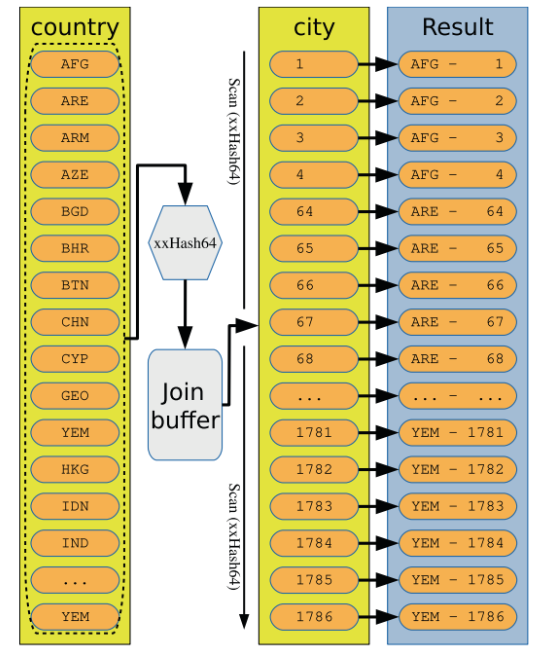
量化一下hash join 的成本
SELECT CountryCode,
country.Name AS Country,
city.Name AS City,
city.District
FROM world.country IGNORE INDEX (Primary)
INNER JOIN world.city IGNORE INDEX (CountryCode)
ON city.CountryCode = country.Code
WHERE Continent = 'Asia';
SELECT rows_examined, rows_sent,
last_statement_latency AS latency
FROM sys.session
WHERE thd_id = PS_CURRENT_THREAD_ID()\G
**************************** 1. row ****************************
rows_examined: 4318
rows_sent: 1766
latency: 3.53 ms
從本文的例子中,rows_examined 的角度來看 index_join 下的NL(2005) 優於 無索引join條件下的BNL (4318)= 無索引join條件下的 hash join。但是當數據量發生變化,可能結果就不一樣了,現實中也沒有絕對的性能好壞規則(如果有,基於規則的成本計算就能很好處理的查詢問題,實際上更值得信賴的是成本估算),hash join與NL,BNL 的優越比較,列出幾點,當作紙上談兵 :
-
For a join without using an index, the hash join will usually be much faster than a block nested join unless a LIMIT clause has been added. Improvements of more than a factor of 1000 have been observed.
參考:
(https://mysqlserverteam.com/hash-join-in-mysql-8/)
(https://dev.mysql.com/blog-archive/hash-join-in-mysql-8/)
(http://www.slideshare.net/NorvaldRyeng/mysql-8018-latest-updates-hash-join-and-explain-analyze) -
For a join without an index where there is a LIMIT clause, a block nested loop can exit when enough rows have been found, whereas a hash join will complete the entire join (but can skip fetching the rows). If the number of rows included due to the LIMIT clause is small compared to the total number of rows found by the join, a block nested loop may be faster.
-
For joins supporting an index, the hash join algorithm can be faster if the index has a low selectivity.
Hash Join 最大的好處在於提升多表無索引關聯時的查詢性能。具體NL,BNL,HASH JOIN誰更適合用於查詢計劃,實踐才是最好的證明。
同樣可以使用HASH_JOIN() 和 NO_HASH_JOIN() 的hint 來影響查詢計劃。
MySQL8.0 關於支持的三種high-level 連接策略的討論暫時到此結束。下來可以自己去查一下 anti, semi, and outer joins。
更多細節 參考
(https://dev.mysql.com/doc/refman/8.0/en/select-optimization.html)(https://dev.mysql.com/doc/refman/8.0/en/semijoins.html)
還有一些 關於join的lower-level優化值得考慮,下篇文章分解。
Enjoy GreatSQL


