
索引 索引(index)是幫助MySQL高效獲取數據的==數據結構(有序)==。在數據之外,資料庫系統還維護著滿足特定查找演算法的數據結構,這些數據結構以某種方式引用(指向)數據,這樣就可以在這些數據結構上實現高級查找演算法,這種數據結構就是索引。 無索引的查找:全表掃描(將整張表遍歷一遍),性能極低。 ...
索引
索引(index)是幫助MySQL高效獲取數據的數據結構(有序)。在數據之外,資料庫系統還維護著滿足特定查找演算法的數據結構,這些數據結構以某種方式引用(指向)數據,這樣就可以在這些數據結構上實現高級查找演算法,這種數據結構就是索引。
-
無索引的查找:全表掃描(將整張表遍歷一遍),性能極低。
-
有索引的查找:資料庫系統在存儲數據的同時會維護一種數據結構(如二叉樹),當需要查找時,利用該數據結構進行查找,性能較高。
-
索引的優缺點

一. 索引結構
MySQL的索引是在存儲引擎層實現的,不同的存儲引擎有不同的結構。

- 索引在存儲引擎中的支持情況
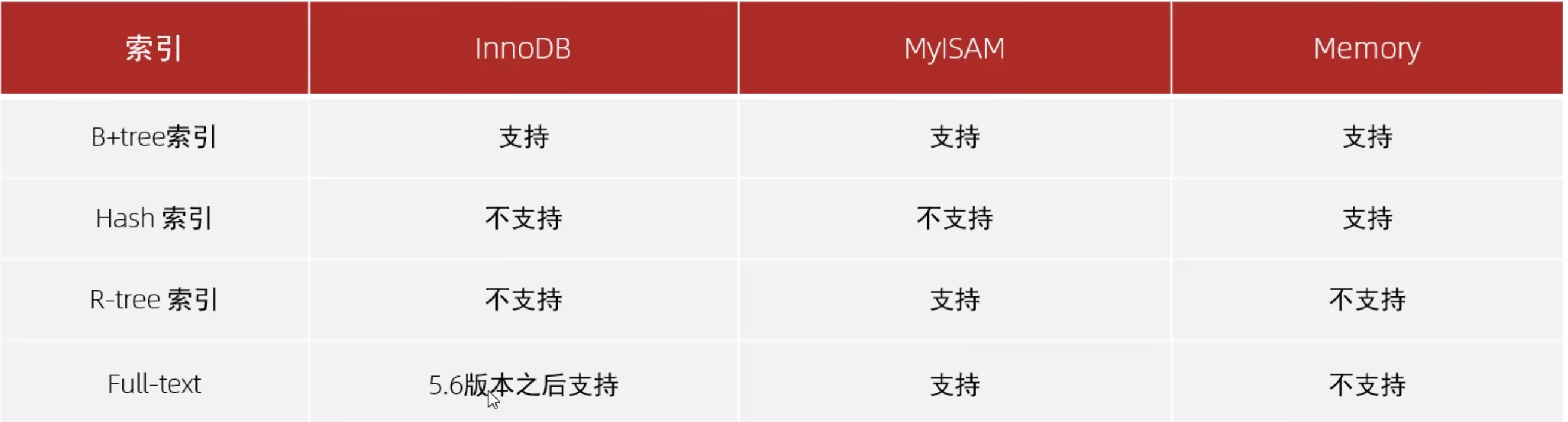
- 平常所說的索引,如果沒有特別指明,一般都是說B+樹結構組織的索引。
1. B+樹
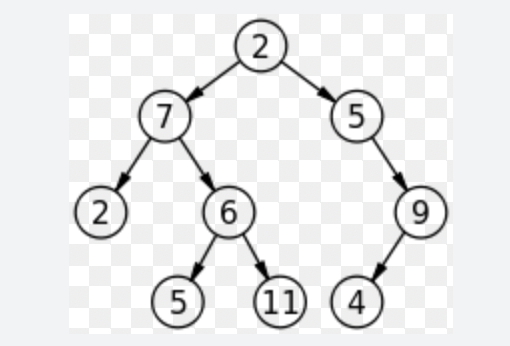
1.1 二叉樹
-
一種經典的數據結構。
-
二叉樹的兩個缺點:
- 順序存儲二叉樹時,會形成一條鏈表,二叉樹的深度很大,效率很低。
- 二叉樹的度不大於2,在資料庫中存有大量數據的時候深度很大,效率很低。
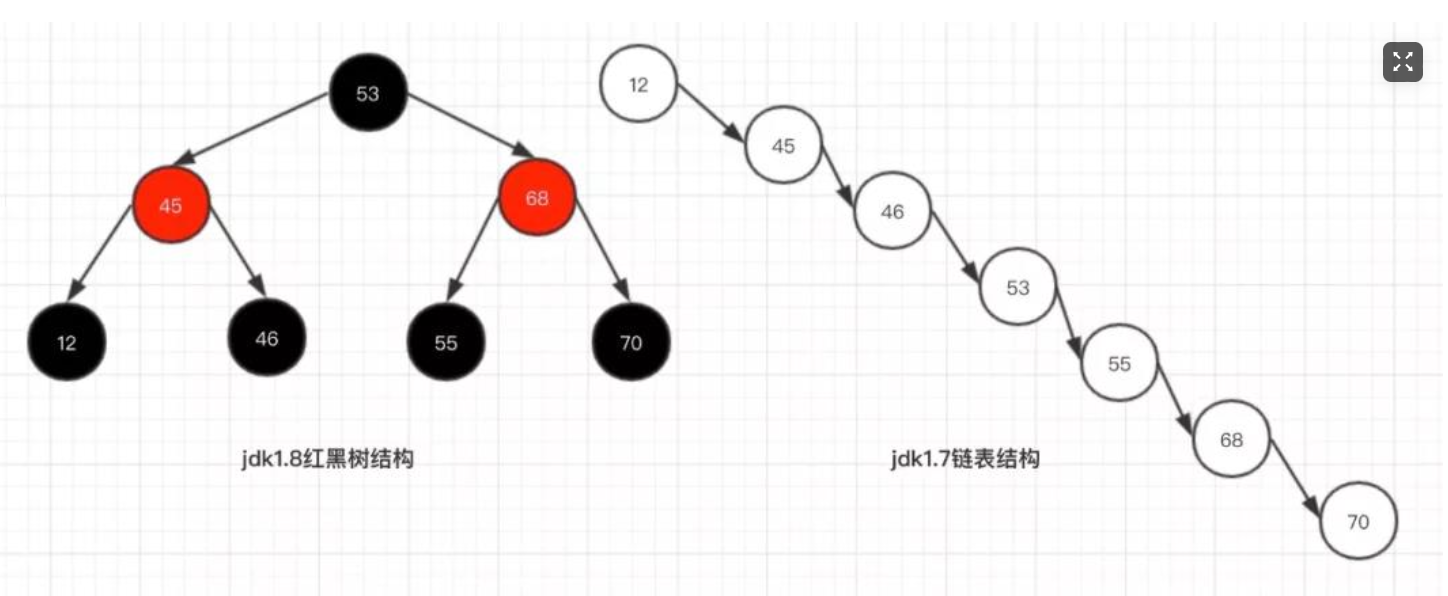
1.2 紅黑樹
-
一種自平衡的特殊二叉樹。
-
可以解決二叉樹可能形成鏈表的缺點,但是依舊存在數據量大時深度很大的問題。
1.3 B樹(平衡多路查找樹)
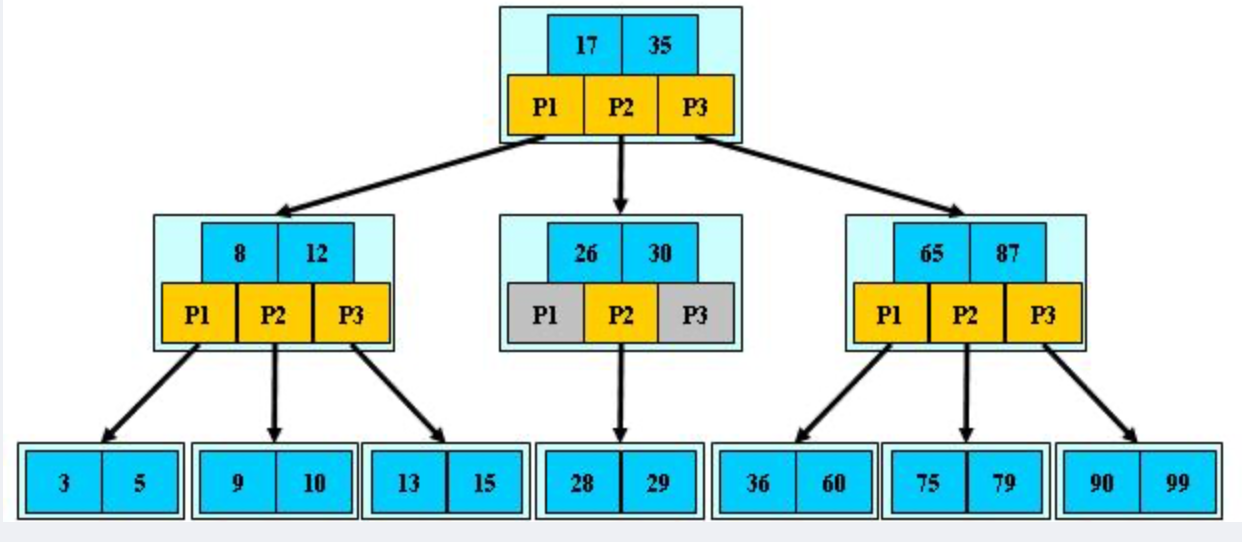
- 一種自平衡的樹。可以解決二叉樹的兩個缺點。
- 一個節點可以擁有兩個以上的子節點。
1.4 B+樹
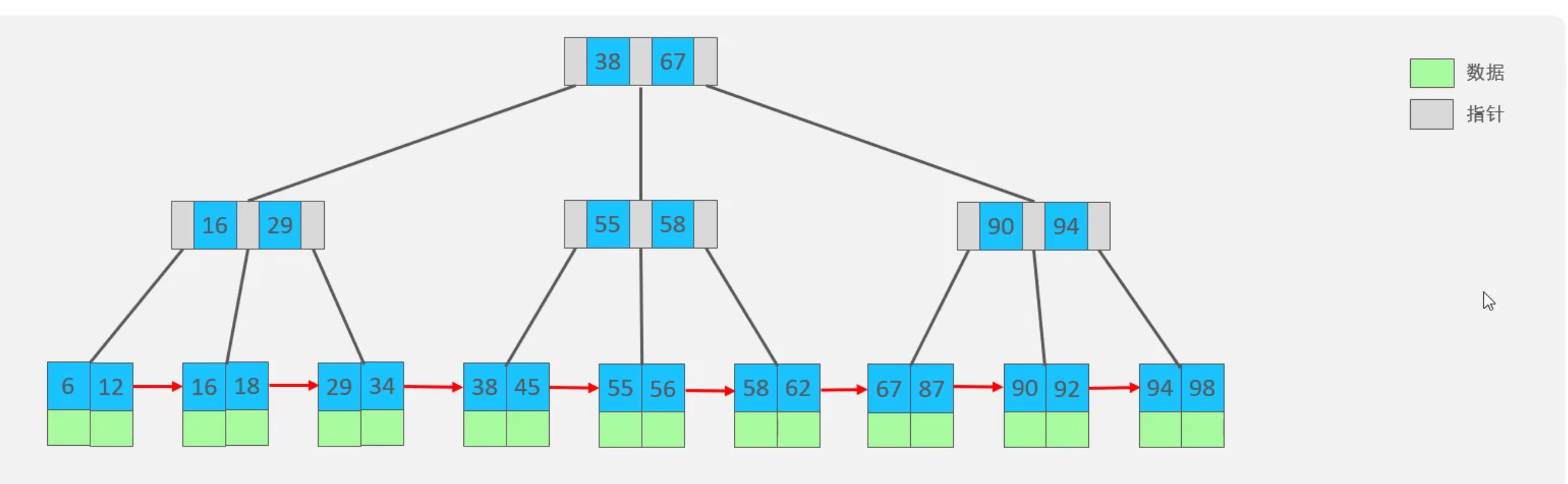
- B樹的變種。
- B+樹與B樹的區別:
- 所有的元素都會出現在葉子節點。
- 葉子節點形成了一條單向鏈表。
1.5 MySQL中的B+樹
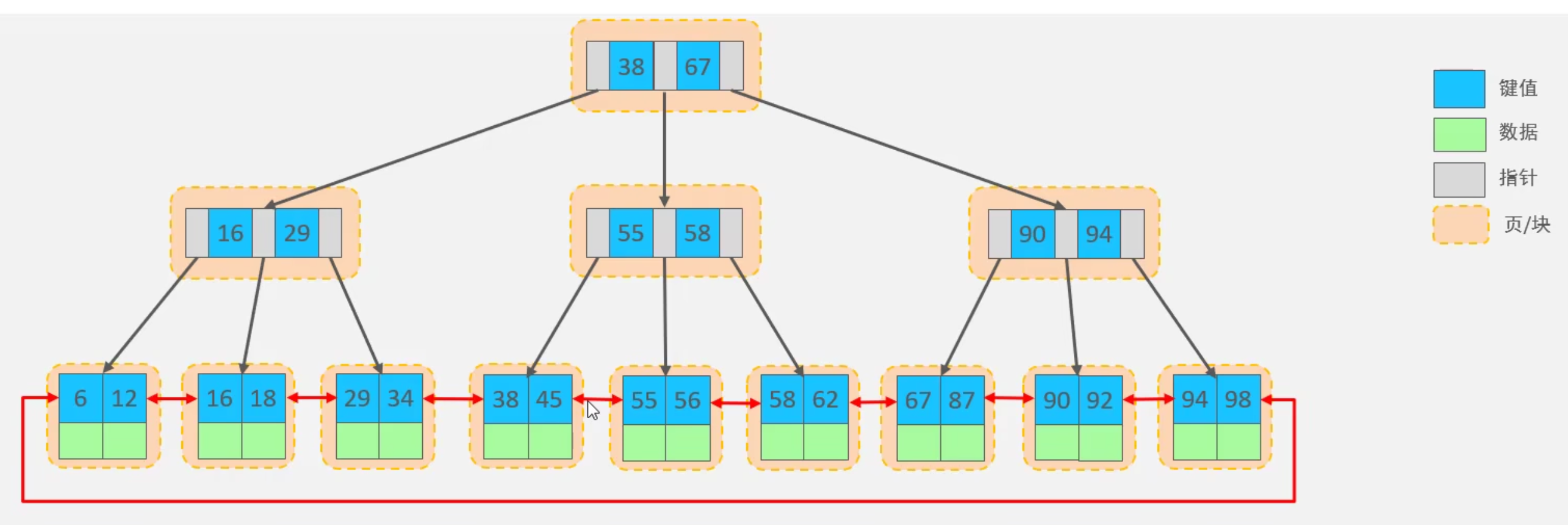
- 在MySQL中,對B+樹進行了優化。在原有基礎上,葉子節點改為了雙向迴圈鏈表,提高區間訪問的性能。
2. Hash
哈希索引就是採用一定的Hash演算法,將鍵值換算成新的Hash值,映射到對應的槽位上,然後存儲在Hash表中。
如果兩個(或多個)鍵值映射到同一個槽位上,產生了Hash衝突,可以通過鏈表解決。
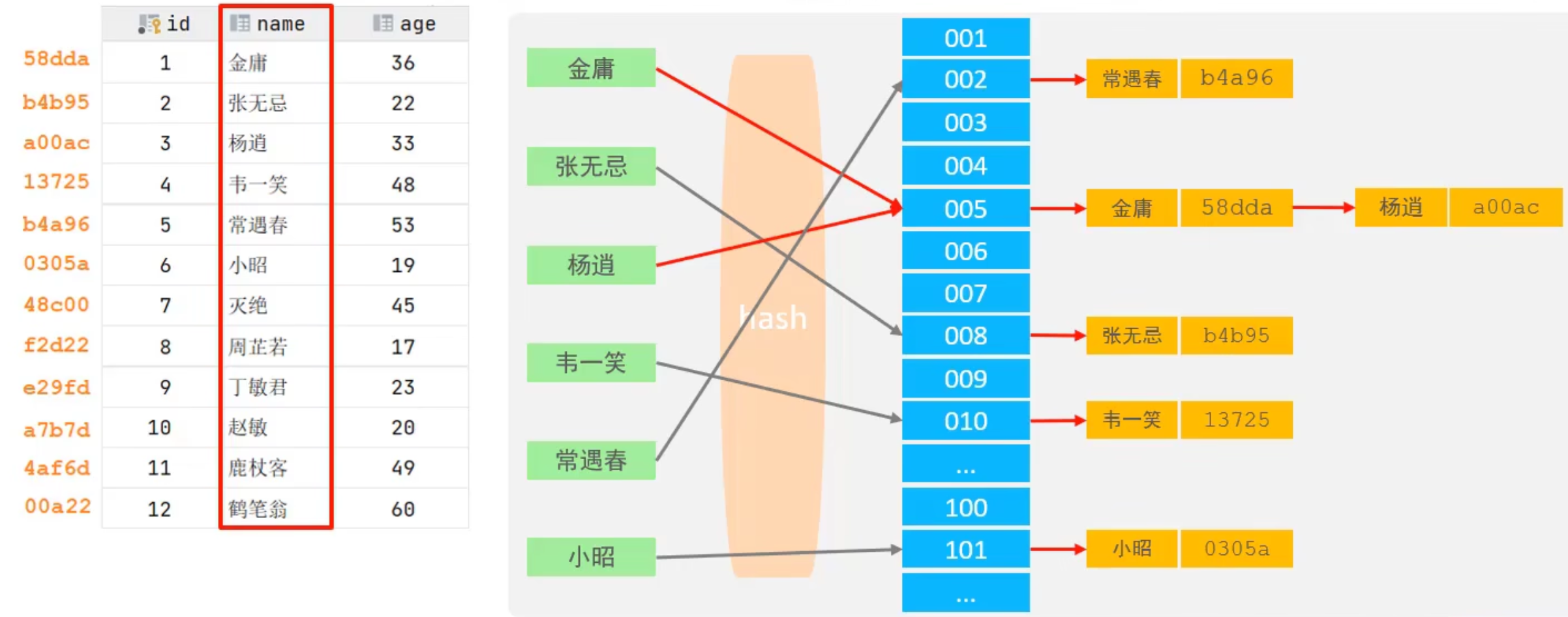
2.1 Hash索引的特點
- 只能用於對等比較(=,in),不支持範圍查詢(between,>,<,...)。
- 無法利用索引完成排序操作。
- 查詢效率高,通常只需要一次檢索(不出現hash衝突),效率高於B+樹。
2.2 存儲引擎支持
在MySQL中,支持hash索引的是Memory引擎,而InnoDB中具有自適應hash功能,hash索引是存儲引擎根據B+樹索引在指定條件下自動構建的。
二. 索引分類

- 在InnoDB存儲引擎中,根據索引的存儲形式,又可以分為以下兩種:

- 聚集索引的選取規則:
- 如果存在主鍵,主鍵索引就是聚集索引。
- 如果不存在主鍵,將適用第一個唯一(UNIQUE)索引作為聚集索引。
- 如果不存在主鍵,或沒有合適的唯一索引,則InnoDB會自動生成一個rowid作為隱藏的聚集索引。
- 聚集索引和二級索引的示意圖:
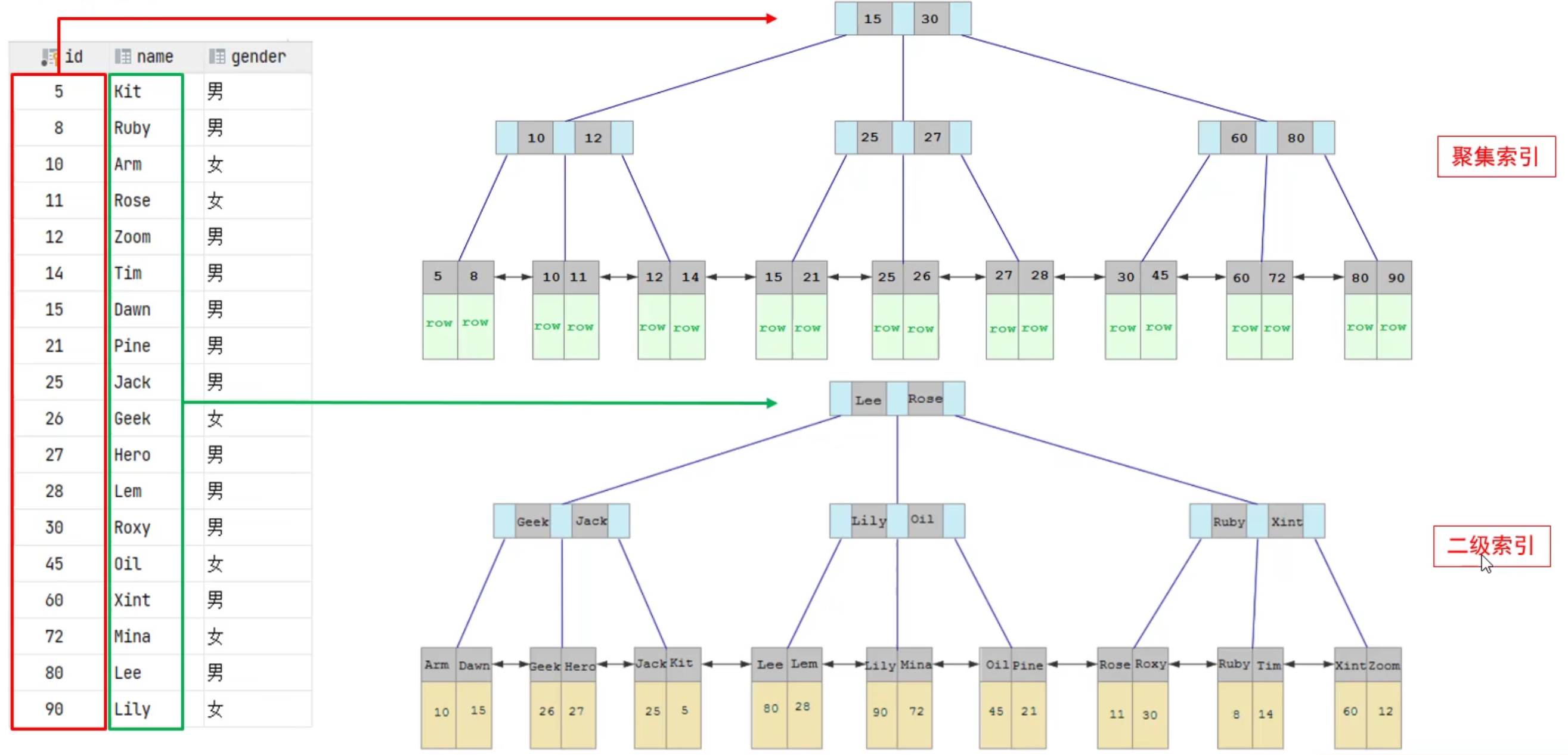
- 在查找時,先走二級索引,找到對應的主鍵後,再走聚集索引,找到對應的整個行。(回表查詢)
三. 索引語法
1. 創建索引
create [unique|fulltext] index {索引名} on {表名} ({欄位名},...);
- unique 唯一索引 |fulltext 全文索引 |不加這兩個則說明是常規索引。
- 一個索引可以關聯多個欄位,如果一個索引只關聯一個欄位,叫單列索引,如果關聯多個欄位,叫聯合索引(組合索引)。
- 聯合索引的欄位順序是有講究的。
- 索引名一般的命名規則:idx _ 表名 _ 欄位名
2. 查看索引
show index form {表名};
3. 刪除索引
drop index {索引名} on {表名};
四. SQL性能分析
做性能分析是為了做SQL優化,SQL主要是做查詢優化,因為查詢操作比增刪改多,查詢優化的關鍵在於索引。
1. SQL執行頻率
# 查看當前資料庫的增刪改查的訪問頻次
show global status like 'Com_______';
# 模糊匹配'Com'後面是7個下劃線
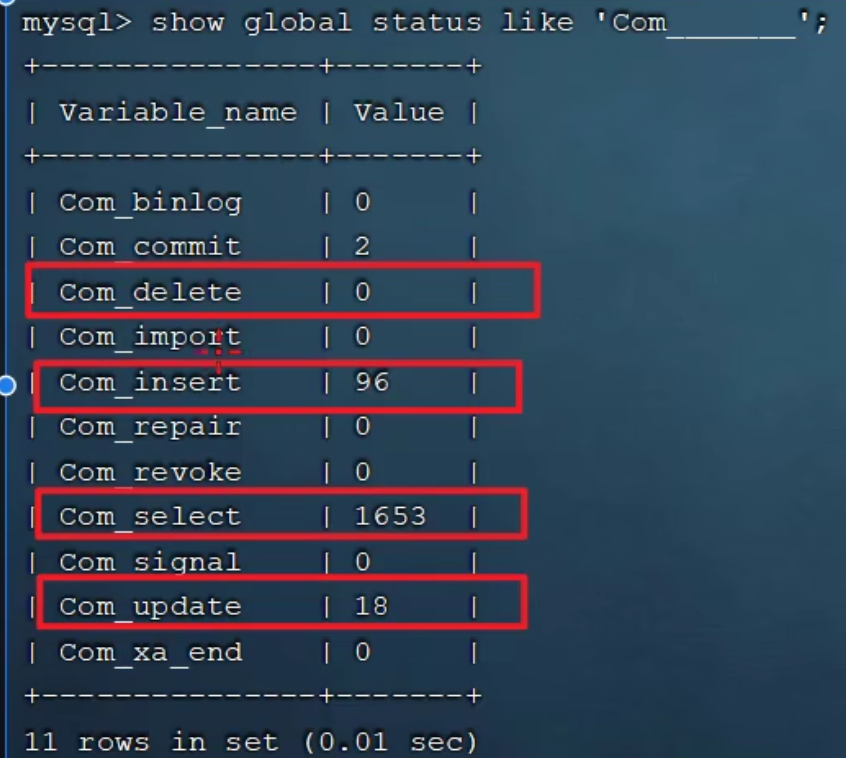
- 根據執行頻率來判斷SQL優化需要在哪方面進行,也就是說這個資料庫哪個操作頻率高就優化哪個操作。
2. 慢查詢日誌
慢查詢日誌記錄了所有執行時間超過制定參數 (long_query_time,單位:秒,預設10秒) 的所有sql語句的日誌
慢查詢日誌用於找到執行慢的sql語句,進行針對性優化。
2.1 開啟慢查詢日誌
MySQL的慢查詢日誌預設沒有開啟,需要在MySQL的配置文件(/etc/my.cnf) 中配置。
- 查詢是否開啟
show variables like 'slow_query_log';
- 開啟慢查詢日誌
在MySQL的配置文件(/etc/my.cnf) 中配置如下信息:
# 開啟MySQL慢查詢日誌開關
show_query_log = 1
# 設置慢查詢日誌的時間為2秒,SQL語句執行時間超過2秒就會被記錄
long_query_time = 2
配置完畢後,需要重啟伺服器。
# 重啟伺服器
systemctl restart mysqld
2.2 查看慢查詢日誌
# 慢查詢日誌存放地址 Linux下
/var/lib/mysql/localhost-slow.log
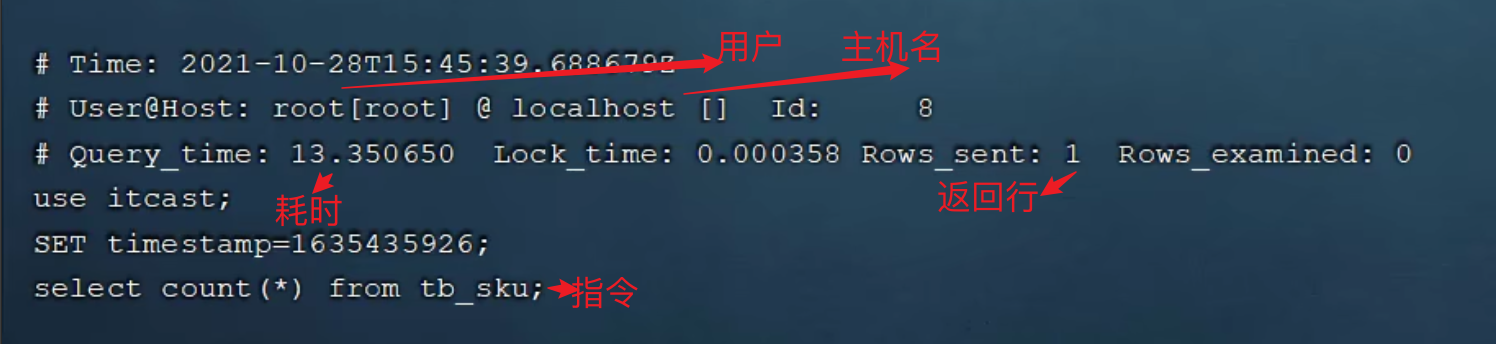
3. profile詳情
Show profiles 能夠在做SQL優化時幫助我們瞭解時間都耗費到哪裡去了。
3.1 查看MySQL是否支持profile操作
select @@have_profiling;
3.2 打開profile開關
# 查看是否打開
select @@profiling;
# 打開profile開關
set [session|global] profiling = 1;
-
profile預設是關閉的。
-
[session|global] 可以指定是會話級別的還是全局的。
3.3 查看profile詳情
# 查看每一條SQL的耗時基本情況
show profiles;
# 查看指定query_id的SQL語句各個階段的耗時情況
show profile for query query_id;
# 查看指定query_id的SQL語句CPU的使用情況
show profile cup for query query_id;
- query_id指的是在profiles中的某一條指令的id,可以在show profiles中看到。
4. explain執行計劃
explain 或者 desc命令獲取MySQL如何執行select語句的信息,包括在select語句執行過程中表如何連接和連接的順序。
# 直接在select語句之前加上關鍵字explain/desc
explain select {欄位列表} from {表名} where {條件};
- explain執行計劃各欄位含義


五. 索引使用
1. 最左首碼法則
-
如果索引了多列(聯合索引),要遵循最左首碼法則。最左首碼法則是指查詢從索引的最左列開始,並且不跳過索引中的列。
-
如果跳躍某一列,索引將部分失效(後面的欄位索引失效)。
-
查詢時左邊欄位存在即符合最左首碼法則,不管它在代碼中的位置。
2. 範圍查詢
- 聯合索引中,出現範圍查詢(> , <),範圍查詢右側的列索引失效。
- 用(>= , <=)不會出現失效情況。
3. 索引列運算
- 不要在索引列上進行運算操作,否則索引將失效。
4. 字元串不加引號
- 字元串類型欄位使用時,不加引號,索引將失效。
5. 模糊查詢
- 如果是尾部進行模糊查詢,索引不會失效;如果是頭部進行模糊查詢,索引會失效。
6. or連接的條件
- 用or分割開的條件,如果or前的條件中的列有索引,二後面的列沒有索引,那麼涉及的索引都不會被用到。
- 只要把沒有索引的建立一個索引就可以解決失效問題。
7. 數據分佈影響
- 如果MySQL評估使用索引比全表更慢,則不使用索引。
8. SQL提示
SQL提示是優化資料庫的一個重要手段。在SQL語句中加入一些人為的提示來達到優化操作的目的。
8.1 use index
- 使用指定索引(建議)
select * from {表名} use index({索引名}) where...;
8.2 ignore index
- 不使用某個索引
select * from {表名} ignore index({索引名}) where...;
8.3 force index
- 使用指定索引(必須)
select * from {表名} force index({索引名}) where...;
9. 覆蓋索引
-
儘量使用覆蓋索引(查詢使用了索引,並且需要返回的列,在該索引中已經全部能夠找到),減少使用select *。
-
使用覆蓋索引和沒有使用覆蓋索引,在explain中的Extra列有不一樣的提示:
- (沒使用)using index condition : 查找使用了索引,但是需要回表查詢數據。
- (使用了)using where; using index : 查找使用了索引,但是需要的數據都在索引列中能夠找到,所以不需要回表查詢數據。
-
覆蓋索引直接在二級索引中獲取了返回所需的所有數據,所以不需要回表查詢,查詢速度快。
-
如果不是覆蓋查詢,在二級索引中查詢到數據後,還需要拿到對應數據的主鍵,到聚焦索引中查詢行數據,這就叫回表查詢,所以速度慢。
10. 首碼索引
當欄位類型為字元串時,有時候需要存儲很長的字元串,如果建立索引,索引會變得很大,浪費大量磁碟IO,影響查詢效率。
此時可以只用字元串的一部分首碼來建立索引(首碼索引),可以大大節約索引空間,從而提高效率。
10.1 創建首碼索引
create index {索引名} on {表名}({欄位名}({首碼的字元數}));
10.2 首碼長度的選擇
-
可以根據索引的選擇性來決定。
-
選擇性:不重覆的索引值和數據表的記錄總數的比值。索引選擇性越高,效率越高。唯一索引的選擇性是1,是性能最好的。
-
求選擇性:
select count(distinct substring({欄位名},1,{截取長度}))/count(*) from {表名};
11. 單列索引和聯合索引
-
單列索引:一個索引只包含單個列
-
聯合索引:一個索引包含了多個列
-
在業務場景中,如果存在多個查詢條件,考慮針對查詢欄位建立索引時,建議使用聯合索引。
-
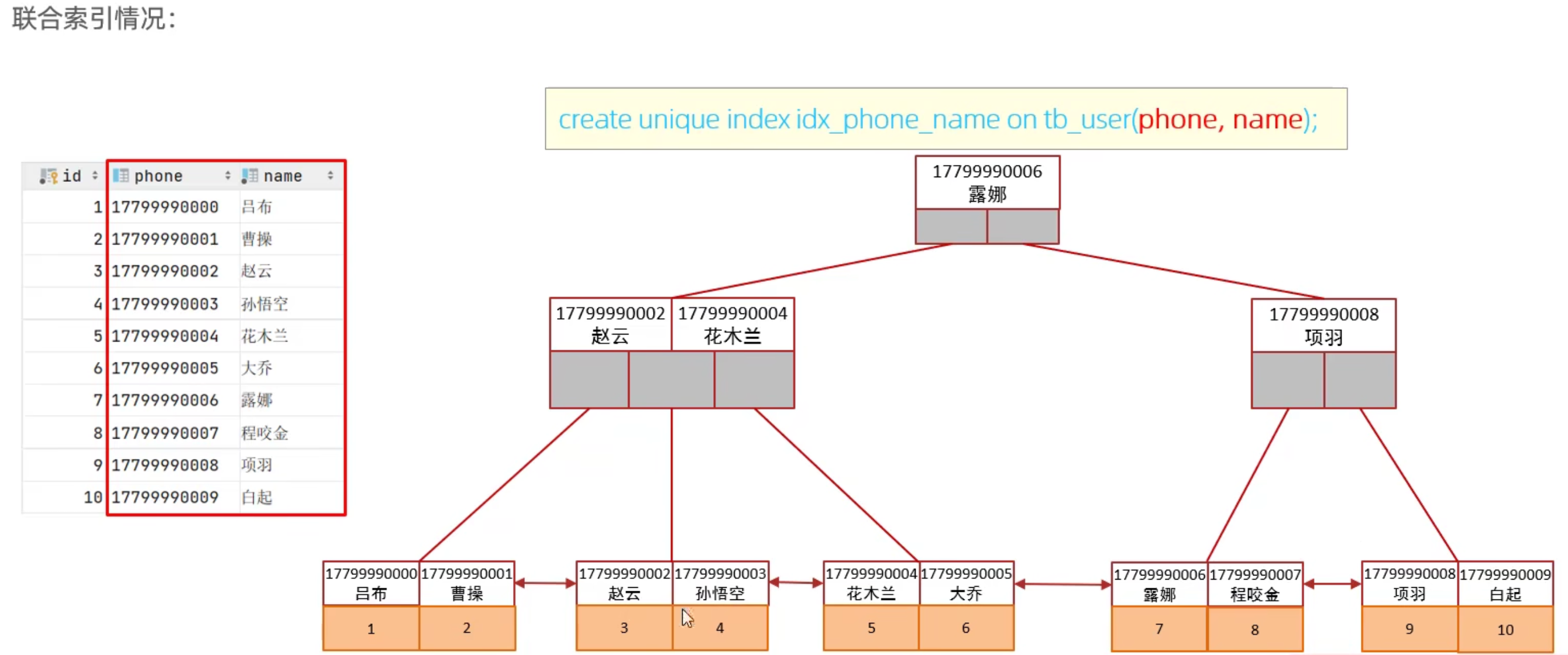
聯合索引的存儲結構:
六. 索引設計原則



