
JVM調優,其實就是調整SWT和FGC的過程 JVM記憶體模型 通過一張基礎的圖瞭解最簡單的JVM模型: 其實在jvm模型中,主要包含了我們常見的堆棧方法區等待--每個版本不同可能解釋有所不同,這裡預設以8版本為例: 首先給出官方文檔的解釋: https://docs.oracle.com/javas ...
JVM調優,其實就是調整SWT和FGC的過程
-
JVM記憶體模型
通過一張基礎的圖瞭解最簡單的JVM模型:
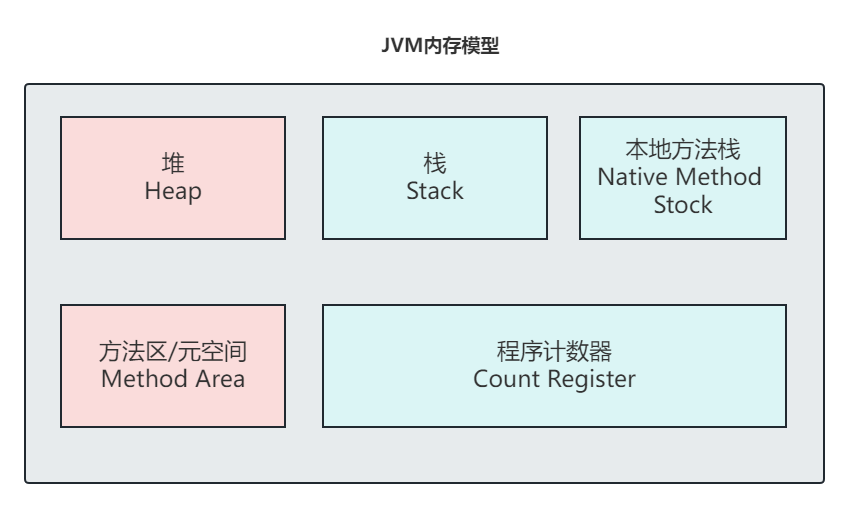
其實在jvm模型中,主要包含了我們常見的堆棧方法區等待--每個版本不同可能解釋有所不同,這裡預設以8版本為例:
首先給出官方文檔的解釋:
https://docs.oracle.com/javase/specs/jvms/se8/html/jvms-2.html#jvms-2.5.4
2.5. Run-Time Data Areas
The Java Virtual Machine defines various run-time data areas that are used during execution of a program. Some of these data areas are created on Java Virtual Machine start-up and are destroyed only when the Java Virtual Machine exits. Other data areas are per thread. Per-thread data areas are created when a thread is created and destroyed when the thread exits.
2.5.1. The
pcRegisterThe Java Virtual Machine can support many threads of execution at once (JLS §17). Each Java Virtual Machine thread has its own
pc(program counter) register. At any point, each Java Virtual Machine thread is executing the code of a single method, namely the current method (§2.6) for that thread. If that method is notnative, thepcregister contains the address of the Java Virtual Machine instruction currently being executed. If the method currently being executed by the thread isnative, the value of the Java Virtual Machine'spcregister is undefined. The Java Virtual Machine'spcregister is wide enough to hold areturnAddressor a native pointer on the specific platform.2.5.2. Java Virtual Machine Stacks
Each Java Virtual Machine thread has a private Java Virtual Machine stack, created at the same time as the thread. A Java Virtual Machine stack stores frames (§2.6). A Java Virtual Machine stack is analogous to the stack of a conventional language such as C: it holds local variables and partial results, and plays a part in method invocation and return. Because the Java Virtual Machine stack is never manipulated directly except to push and pop frames, frames may be heap allocated. The memory for a Java Virtual Machine stack does not need to be contiguous.
In the First Edition of The Java® Virtual Machine Specification, the Java Virtual Machine stack was known as the Java stack.
This specification permits Java Virtual Machine stacks either to be of a fixed size or to dynamically expand and contract as required by the computation. If the Java Virtual Machine stacks are of a fixed size, the size of each Java Virtual Machine stack may be chosen independently when that stack is created.
A Java Virtual Machine implementation may provide the programmer or the user control over the initial size of Java Virtual Machine stacks, as well as, in the case of dynamically expanding or contracting Java Virtual Machine stacks, control over the maximum and minimum sizes.
The following exceptional conditions are associated with Java Virtual Machine stacks:
If the computation in a thread requires a larger Java Virtual Machine stack than is permitted, the Java Virtual Machine throws a
StackOverflowError.If Java Virtual Machine stacks can be dynamically expanded, and expansion is attempted but insufficient memory can be made available to effect the expansion, or if insufficient memory can be made available to create the initial Java Virtual Machine stack for a new thread, the Java Virtual Machine throws an
OutOfMemoryError.2.5.3. Heap
The Java Virtual Machine has a heap that is shared among all Java Virtual Machine threads. The heap is the run-time data area from which memory for all class instances and arrays is allocated.
The heap is created on virtual machine start-up. Heap storage for objects is reclaimed by an automatic storage management system (known as a garbage collector); objects are never explicitly deallocated. The Java Virtual Machine assumes no particular type of automatic storage management system, and the storage management technique may be chosen according to the implementor's system requirements. The heap may be of a fixed size or may be expanded as required by the computation and may be contracted if a larger heap becomes unnecessary. The memory for the heap does not need to be contiguous.
A Java Virtual Machine implementation may provide the programmer or the user control over the initial size of the heap, as well as, if the heap can be dynamically expanded or contracted, control over the maximum and minimum heap size.
The following exceptional condition is associated with the heap:
If a computation requires more heap than can be made available by the automatic storage management system, the Java Virtual Machine throws an
OutOfMemoryError.2.5.4. Method Area
The Java Virtual Machine has a method area that is shared among all Java Virtual Machine threads. The method area is analogous to the storage area for compiled code of a conventional language or analogous to the "text" segment in an operating system process. It stores per-class structures such as the run-time constant pool, field and method data, and the code for methods and constructors, including the special methods (§2.9) used in class and instance initialization and interface initialization.
The method area is created on virtual machine start-up. Although the method area is logically part of the heap, simple implementations may choose not to either garbage collect or compact it. This specification does not mandate the location of the method area or the policies used to manage compiled code. The method area may be of a fixed size or may be expanded as required by the computation and may be contracted if a larger method area becomes unnecessary. The memory for the method area does not need to be contiguous.
A Java Virtual Machine implementation may provide the programmer or the user control over the initial size of the method area, as well as, in the case of a varying-size method area, control over the maximum and minimum method area size.
The following exceptional condition is associated with the method area:
If memory in the method area cannot be made available to satisfy an allocation request, the Java Virtual Machine throws an
OutOfMemoryError.2.5.5. Run-Time Constant Pool
A run-time constant pool is a per-class or per-interface run-time representation of the
constant_pooltable in aclassfile (§4.4). It contains several kinds of constants, ranging from numeric literals known at compile-time to method and field references that must be resolved at run-time. The run-time constant pool serves a function similar to that of a symbol table for a conventional programming language, although it contains a wider range of data than a typical symbol table.Each run-time constant pool is allocated from the Java Virtual Machine's method area (§2.5.4). The run-time constant pool for a class or interface is constructed when the class or interface is created (§5.3) by the Java Virtual Machine.
The following exceptional condition is associated with the construction of the run-time constant pool for a class or interface:
When creating a class or interface, if the construction of the run-time constant pool requires more memory than can be made available in the method area of the Java Virtual Machine, the Java Virtual Machine throws an
OutOfMemoryError.See §5 (Loading, Linking, and Initializing) for information about the construction of the run-time constant pool.
2.5.6. Native Method Stacks
An implementation of the Java Virtual Machine may use conventional stacks, colloquially called "C stacks," to support
nativemethods (methods written in a language other than the Java programming language). Native method stacks may also be used by the implementation of an interpreter for the Java Virtual Machine's instruction set in a language such as C. Java Virtual Machine implementations that cannot loadnativemethods and that do not themselves rely on conventional stacks need not supply native method stacks. If supplied, native method stacks are typically allocated per thread when each thread is created.This specification permits native method stacks either to be of a fixed size or to dynamically expand and contract as required by the computation. If the native method stacks are of a fixed size, the size of each native method stack may be chosen independently when that stack is created.
A Java Virtual Machine implementation may provide the programmer or the user control over the initial size of the native method stacks, as well as, in the case of varying-size native method stacks, control over the maximum and minimum method stack sizes.
The following exceptional conditions are associated with native method stacks:
- If the computation in a thread requires a larger native method stack than is permitted, the Java Virtual Machine throws a
StackOverflowError.
- If native method stacks can be dynamically expanded and native method stack expansion is attempted but insufficient memory can be made available, or if insufficient memory can be made available to create the initial native method stack for a new thread, the Java Virtual Machine throws an
OutOfMemoryError.
針對oracle的官方文檔,給我們描述了jvm虛擬機的幾個主要模塊。那麼從普通開發者的角度,其實這幾大塊分別幹了這些事:
-
- Heap堆:
Java虛擬機具有在所有Java虛擬機線程之間共用的堆。堆是運行時數據區,從中為所有類實例和數組分配記憶體。堆可以是固定大小的,或者可以根據計算的需要進行擴展,並且如果不需要更大的堆,則可以收縮。堆的記憶體不需要是連續的。 Java虛擬機實現可以為程式員或用戶提供對堆的初始大小的控制,以及如果堆可以動態擴展或收縮,則可以提供對最大和最小堆大小的控制。如果計算所需的堆數超過了自動存儲管理系統所能提供的堆數,Java虛擬機將拋出OutOfMemoryError。
那麼可以看出,堆的主要作用就是分配空間,屬於運行時數據區,會將我們運行時的記憶體分配。
同時,堆記憶體又分為新生代和老年代,以Young和Old區分,其中新生代主要存放回收年齡較短或者一些新new的對象,而老年代則是存放一些無法被gc的對象(考慮一下哪些對象會被放入老年代?)
堆記憶體,其實又被分為了三個區域:
Young:新生代;Old:老年代;Mate:元空間(永久代)
其中,新生代又分為這幾段:
Eden:伊甸區;
s0、s1:survivor,用於YGC中複製移動;
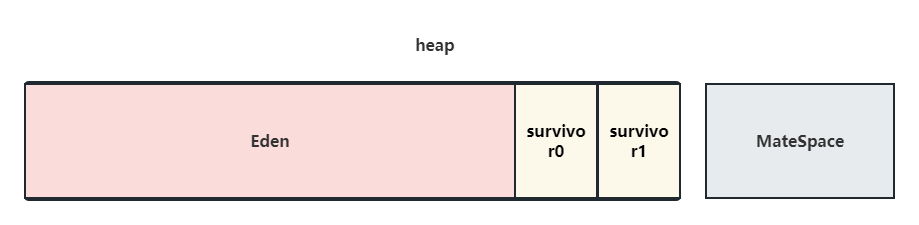
預設,Eden:s0:s1是8:1:1的關係,而老年代和年輕代的比例預設是2:1
那麼,什麼時候會放入新生代什麼時候會放入老年代呢?
預設,新創建的對象第一次會存放在新生代Eden中,我們認為新生代的對象百分之80都可能被回收掉,那麼第一次YGC就會把Eden的對象先複製到s0,這是記憶體的複製,速度很快;
下一次YGC,又會把Eden和不為空的s0做YGC,因為我們認為大多數對象都要被回收,再把Eden和s0全部清空,那麼沒有回收的對象就位於s1;
再下一次.... 就是s0和s1來回倒。
但是,如果對象很大無法被放入新生代,或者它已經超過動態survivo的大小50%以上,我們就認為它不適合在新生代了,就會直接放去老年代。
同時,jvm的Object有對象頭,對象頭包含了比如說對象線程,鎖,和一些gc年齡的屬性,那麼我們認為預設它的年齡到達15,它就是一個不可被回收的對象,那麼就放入老年代;大對象也會放入老年代;還有如果Eden滿了出發YGC,那麼存活對象大小s0沒辦法承受也會將部分多餘的對象放入老年代,我們認為老年代的對象很難被回收,那麼什麼對象可以出現在老年代呢?例如:spring生命周期的bean,常量(這裡string常量池其實有些許變化),定義線程池、連接池這些都應該屬於不可被回收。
-
- Stock棧(也叫虛擬機棧,線程棧)
每個Java虛擬機線程都有一個與線程同時創建的專用Java虛擬機堆棧。該規範允許Java虛擬機堆棧具有固定的大小,或者根據計算的需要動態擴展和收縮。如果Java虛擬機堆棧具有固定大小,則在創建每個Java虛擬機棧時,可以獨立地選擇該棧的大小。如果線程中的計算需要比允許的更大的Java虛擬機堆棧,則Java虛擬機會拋出StackOverflowError。如果Java虛擬機堆棧可以動態擴展,並且嘗試進行擴展,但沒有足夠的記憶體可用於實現擴展,或者如果沒有足夠的存儲器可用於創建新線程的初始Java虛擬機棧,則Java虛擬機將拋出OutOfMemoryError。
棧,顧名思義,是一種FILO的結構,那麼在我們方法調用時,就會在棧記憶體中存儲,包括一些對象的引用,棧中又有一個概念叫棧楨,什麼是棧幀呢?
簡單舉例子就是說,比如我們有一個A方法調用B方法,B再調用C方法,那麼這個棧幀可以這麼表示:
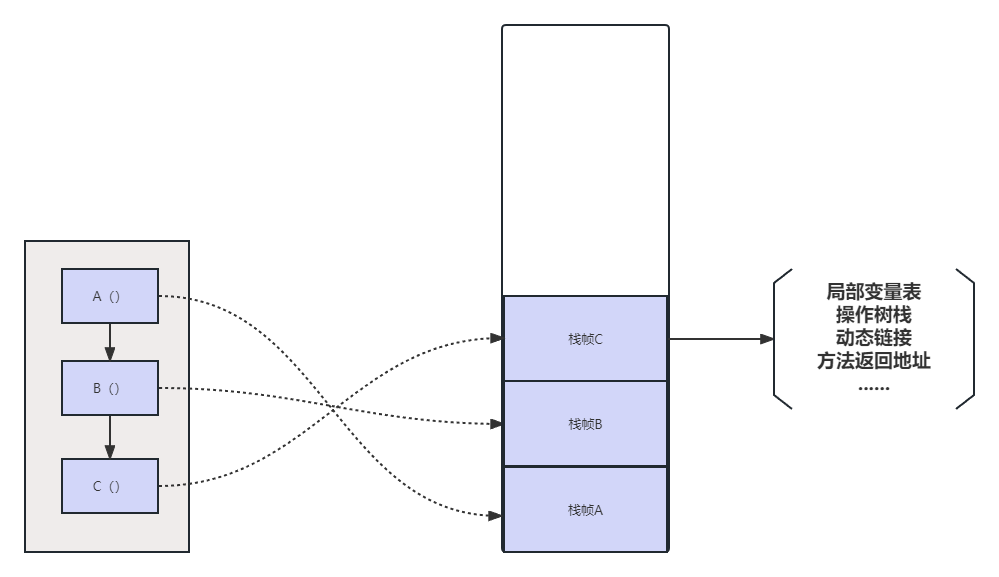
並且,棧存儲會隨著線程的創建而創建,會隨著線程的銷毀而釋放,不存在gc。這裡其實有一個概念,比如說棧記憶體的OOM,會是什麼樣子?
如果一個遞歸,無法跳出遞歸或者遞歸數量太大,棧記憶體設置太小,是可能會拋出OOM的。
局部變數表:對應的就是方法參數和一些局部變數,因為這些都是線程私有的,所以不需要額外gc,隨著線程結束被釋放。
操作數棧:棧內的一些計算操作。
動態鏈接:一些引用?
方法返回地址:調用當前方法寄存器的值。
-
- Native Method Stock本地方法棧
與stock類似,只不過這裡存儲的是基於一些native之類的本地方法。
-
- Method Area 方法區/元空間
首先,明確一個概念,方法區/元空間,又可以叫做no-heap,它是用於與堆記憶體進行分開的概念!這個概念在jdk7叫做方法區,在jdk8叫做元空間,而且元空間不需要指定預設的大小了,而是會根據物理記憶體進行計算,當然如果物理記憶體不夠了也會拋出OOM。並且,元空間是代替了7的老年代,其本質也是屬於堆的一部分。
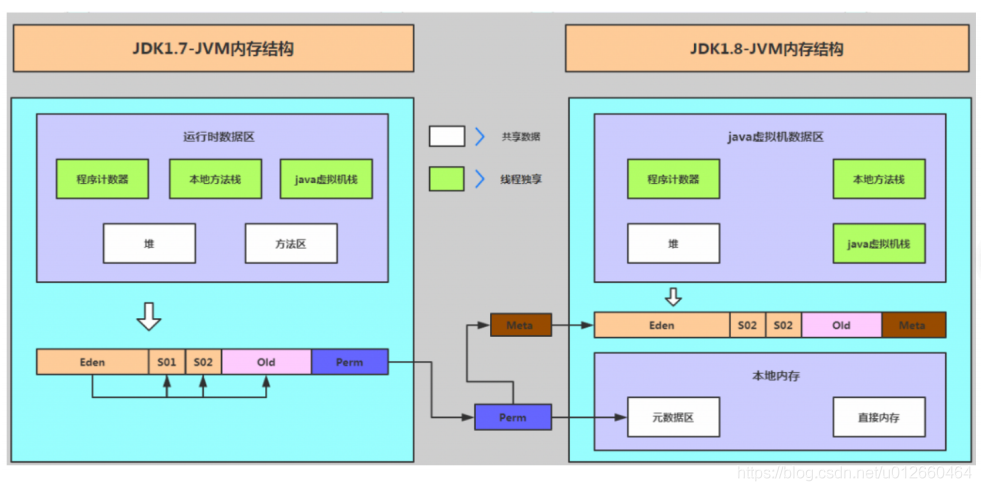
那麼,為什麼從7->8會有這樣的變化呢?
1.永久代是有固定空間的,如果永久代的空間太小,-XX:MaxPermSize太小就會導致永久代OOM。
2.元空間使用的情況根據物理存儲,最大沒有限制,當物理記憶體達不到要求後同樣會出發OOM。windows下,-XX:MetaspaceSize是21M,-XX:MaxMetaspaceSize的值是-1。
3.MetaspaceSize是初始化指定的大小,當達到了這個大小後,會觸發FGC,同時會根據FGC的回收情況適當調整。所以線上如果頻繁FGC,可能跟這個值有關,可以適當增大。
-
- STW
STW全名叫stop the world,它代表的意思是說在jvm觸發GC時,會停止當前所有的用戶線程,然後在gc完成後釋放,那麼在gc的時間段內就會發生所有的動作暫停無響應的情況。當然後面會有針對G1,ZGC以及一些回收演算法可以並行的模式。
其中,Class對象 -- 永久代/元數據;
字元串常量 -- 1.7永久代;1.8在堆heap里;
在1.8之後,元數據不存在於堆,而是根據操作系統的記憶體進行管理的;
-
什麼是垃圾
垃圾,顧名思義就是要被回收的對象,或者說要被回收的一組對象。
首先我們需要有個概念,java本身針對記憶體指針甚至記憶體空間的方式,都是基於unsafe或者其他的方式,我們在寫java代碼中不需要手動釋放記憶體,這與c有很大的不同。
那麼為什麼java幫助我們去這麼做呢?無非這麼幾點
1.忘記回收記憶體,那麼這一塊記憶體空間就會被占用無法釋放。
2.多次回收,那麼會不會將新的可用的數據回收掉?
3.更加簡化開發。
那既然GC就是回收不可用的垃圾,是有jvm幫我們去完成的,那麼jvm到底是如何確定什麼是垃圾的呢?
主要有兩種辦法:
1.計數器,jvm會在對象頭記錄計數器,計數器代表引用計數器,那麼如果這個計數器為0了,它沒有被任何對象引用那麼它就是一個可以回收的垃圾了。
2.GCROOT,根可達演算法:試想一下如果有三個對象ABC,A持有B,B持有C,C持有A,但是它們再沒有其他的對象引用了,那麼它們的引用計數器不為0,但是它們其實算一堆垃圾,這樣的話我們的根可達就派上用場了。比如我們根據Object,一直向下去找,那麼找得到的對象就是可用的對象,那麼其他的對象都可以稱為不可用對象。什麼概念呢?比如我們的局部變數 和我們的連接池 線程池 包括常量池 JNI指針持有的對象那這些一定是可用變數甚至載入的Clazz,一定不會被回收。
什麼是對象頭?
| object header | Mark word(64bit) | klass pointer(64bit) |
| normal object 普通對象,無鎖。 | unused:25|identity_hashcode:31|unused:1|age:4|biased_lock:1|lock:2 | oop to metadata object 指向對象的元定義,可能會被指針指針壓縮 |
| biased object 帶有偏向鎖的對象 | thread:54 |epoch:2 |unused:1|age:4|biased_lock:1|lock:2 | oop to metadata object 指向對象的元定義,可能會被指針指針壓縮 |
| 帶有輕量鎖的對象 | prt_to_lock_record:62 |lock:2 | oop to metadata object 指向對象的元定義,可能會被指針指針壓縮 |
| 帶有重量鎖的對象 | prt_to_heavyweigth_monitor:62 |lock:2 | oop to metadata object 指向對象的元定義,可能會被指針指針壓縮 |
| GC | |lock:2 | oop to metadata object 指向對象的元定義,可能會被指針指針壓縮 |
-
常見的垃圾回收演算法
- 標記清除
首先對垃圾進行標記,然後進行回收,但是這種方式會導致記憶體間斷,產生大量的記憶體碎片;這時當我們要分配一個大的對象時,可能會經歷頻繁的GC(目前大對象也可以直接扔在老年代中)
-
- copy複製
複製演算法,相當於把可用的對象複製在另一個記憶體塊中,然後直接將當前的記憶體清除;這樣不會有記憶體碎片,但是缺點是記憶體占用會很大,最少需要將記憶體劃分成兩塊進行複製移動,而且存活對象過多會導致效率低下
-
- 標記壓縮
這時複製的升級版,其實它會將不可用對象清除後將可用對象向一端移動,這樣的好處是不會有記憶體碎片並且不需要劃分記憶體空間、但是效率會比較低
-
- 分代收集
這是最常用的演算法,會根據記憶體空間進行劃分,並且針對不同的記憶體選擇不同的演算法:例如新生代可以選用複製演算法,預設新生代的對象很多都需要被回收;而老年代採用標記壓縮或複製,騰出大片記憶體。
-
常見的垃圾回收器
- Serial Young:串列回收,會觸發STW。
- Paraller Scavenge: ps,並行回收。
- ParNew配合CMS: 並行回收年輕代。
- Serial Old:串列回收,老年代。
- ParOld:並行回收,老年代。
- CMS:ConcurrentMarkSweep:併發回收,老年代。GC和用戶進程同時進行,降低STW。
- G1:10ms 不區分老年代新生代
- ZGC:1ms 不區分老年代新生代
-
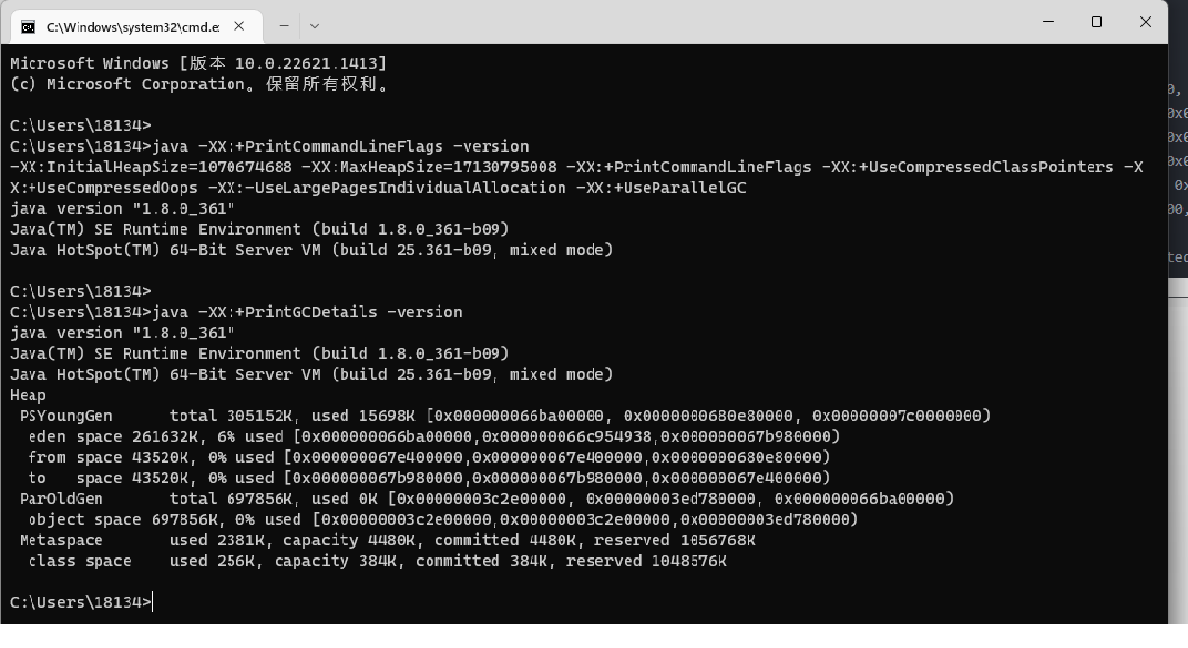
如何判斷當前參數
https://docs.oracle.com/javase/8/docs/technotes/tools/unix/java.html
-XX:+PrintCommandLineFlags:當前jvm參數
-XX:+PrintFlgsFinal :最終參數值
-XX:+PrintFlagsInitial:預設參數值
1.8版本預設使用的應該是Paraller GC 並行回收 : 預設使用 Parallel Scavenge(新生代)+ Serial Old(老年代)。
這裡整理一個簡單的表格,對這幾種GC做簡單的對比:
| GC | 特性 | 描述 |
| Paraller | 吞吐量 | 多線程STW |
| G1(Garbage first) | 均衡 | 多線程SWT 併發 分代回收 |
| ZGC(Z Garbage) | 延遲 | 所有併發 |
| Shenandoah(jdk 12後) | 延遲 | 所有併發 |
| Serial | 記憶體大小 啟動時間 | 單線程STW |
Parallel GC是JDK 8以及更早版本的預設回收期。它專註於吞吐量,儘快完成工作,而很少考慮延遲(暫停)。
Parallel GC會在STW(全局暫停)期間,以更緊湊的方式,將正在使用中的記憶體移動(複製)到堆中的其他位置,從而製造出大片的空閑記憶體區域。當記憶體分配請求無法滿足時就會發生STW暫停,然後JVM完全停止應用程式運行,投入儘可能多的處理器線程,讓垃圾回收演算法執行記憶體壓縮工作,然後分配請求的記憶體,最後恢復應用程式執行。
G1 GC是JDK 9以後的預設回收期。G1試圖平衡吞吐量和延遲。一方面,在STW暫停期間,依然會利用分代繼續執行記憶體回收工作,從而最大化效率,這一點和Parallel GC相同;但是,它還會儘可能避免在暫停期間執行需要較長時間的操作。G1的長時間操作會與應用程式並行進行,即通過多線程方式,在應用程式運行時執行。這樣可以大幅度減少暫停,代價是整體的吞吐量會降低一點。
所以,GC在8-9版本其實是一個分水嶺,從9版本後預設使用G1,並且優化了G1處理的時間,包括G1處理大對象及老年代的時間。
那麼,哪些場景下適用哪些垃圾回收器呢?
Serial:適用於單線程場景,簡單的client客戶端,記憶體小,沒有過多的對象,單線程回收不需要線程切換的開銷。
ParNew/Paraller :多CPU的伺服器,可以採用多線程的方式回收,但是Paraller 追求的是短時間內儘量完成任務,那麼就會有SWT時間,不適合交互型場景;ParNew降低了SWT時間,更適合交互場景。
Parallel Scavenge提供的參數
-XX:GCTimeRadio
直接設置吞吐量大小,GC時間占總時間比率.相當於是吞吐量的倒數.
-XX:MaxGCPauseMillis
設置最大GC停頓時間.
Parallel Scavenge會根據這個值的大小確定新生代的大小.如果這個值越小,新生代就會越小,從而收集器就能以較短的時間進行一次回收;但新生代變小後,回收的頻率就會提高,吞吐量也降下來了,因此要合理控制這個值.
-XX:+UseAdaptiveSizePolicy
通過命令就能開啟GC 自適應的調節策略(區別於ParNew).我們只要設置最大堆(-Xmx)和MaxGCPauseMillis或GCTimeRadio,收集器會自動調整新生代的大小、Eden和Survior的比例、對象進入老年代的年齡,以最大程度上接近我們設置的MaxGCPauseMillis 或GCTimeRadio.
-
聊聊G1
首先一點,不論是新生代還是老年代,G1 ZGC等垃圾回收器是不區分記憶體類型的。
通過 -XX:+UseG1GC 可以指定使用G1垃圾回收器。
G1首先具備壓縮功能、避免碎片化記憶體問題、而且G1的SWT暫停時間可控、多線程GC、面向服務端應用比較友好、而且可以預測停頓的時間。
首先,G1會將所有堆記憶體劃分成很多塊大小相等的Region。每次要觸發GC時,首先估算每個Region中可回收垃圾的數量、每次先從可回收最大的量開始回收,因此它的效率性能是很高的。
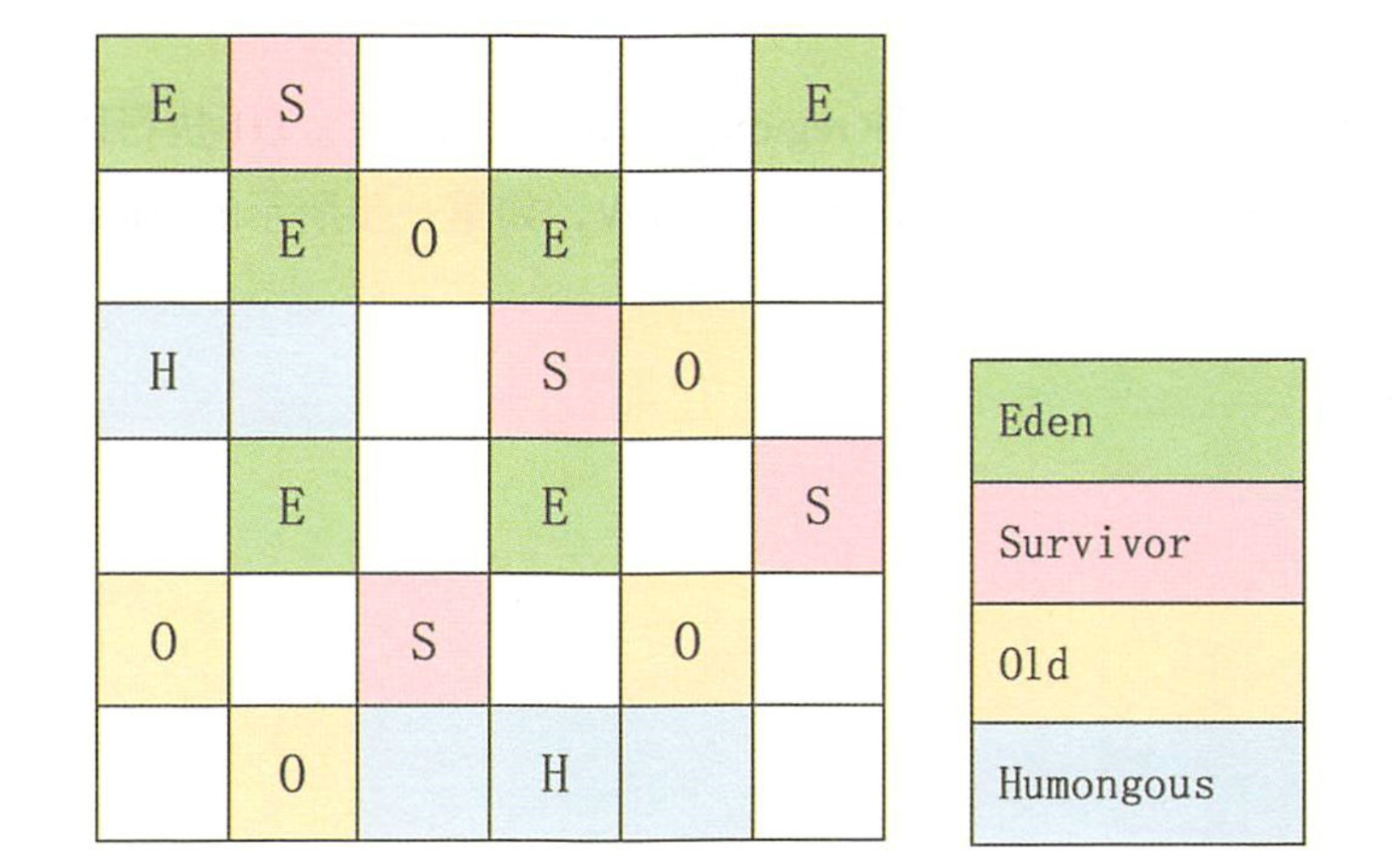
這樣,其實在G1里,不再區分老年代新生代了,整個堆記憶體都是Region。但是衍生出了一個Humongous,它是特殊的Old,專門存放大型的對象。
這樣的劃分方式意味著不需要一個連續的記憶體空間管理對象.G1將空間分為多個區域,優先回收垃圾最多的區域.
G1採用的是Mark-Copy ,有非常好的空間整合能力,不會產生大量的空間碎片
G1的一大優勢在於可預測的停頓時間,能夠儘可能快地在指定時間內完成垃圾回收任務,通過jstat命令可以查看垃圾回收情況,在YGC時S0/S1並不會交換.
那麼,如果一個對象,它自身和它持有引用的對象沒有分配在一個Region中,我們是否需要遍歷所有的Region才能進行一次GCRoot?每個Region上都有一個RememberSet,用於記錄當前區域引用對象所在的區域。
G1的GC模式
1.YoungGC年輕代收集
在分配一般對象(非巨型對象)時,當所有eden region使用達到最大閥值並且無法申請足夠記憶體時,會觸發一次YoungGC。每次younggc會回收所有Eden以及Survivor區,並且將存活對象複製到Old區以及另一部分的Survivor區。
YoungGC的回收過程如下:
根掃描,跟CMS類似,Stop the world,掃描GC Roots對象。
處理Dirty card,更新RSet.
掃描RSet,掃描RSet中所有old區對掃描到的young區或者survivor去的引用。
拷貝掃描出的存活的對象到survivor2/old區
處理引用隊列,軟引用,弱引用,虛引用
2. mixed gc
當越來越多的對象晉升到老年代old region時,為了避免堆記憶體被耗盡,虛擬機會觸發一個混合的垃圾收集器,即mixed gc,該演算法並不是一個old gc,除了回收整個young region,還會回收一部分的old region,這裡需要註意:是一部分老年代,而不是全部老年代,可以選擇哪些old region進行收集,從而可以對垃圾回收的耗時時間進行控制。
G1沒有fullGC概念,需要fullGC時,調用serialOldGC進行全堆掃描(包括eden、survivor、o、perm)。
何時使用G1
G1的第一個重要特點是為用戶的應用程式的提供一個低GC延時和大記憶體GC的解決方案。這意味著堆大小6GB或更大,穩定和可預測的暫停時間將低於0.5秒。
如果應用程式使用CMS或ParallelOld垃圾回收器具有一個或多個以下特征,將有利於切換到G1:
Full GC持續時間太長或太頻繁
對象分配率或年輕代升級老年代很頻繁
不期望的很長的垃圾收集時間或壓縮暫停(超過0.5至1秒)
註意:如果你正在使用CMS或ParallelOld收集器,並且你的應用程式沒有遇到長時間的垃圾收集暫停,則保持與您的當前收集器是很好的,升級JDK並不必要更新收集器為G1。
-
關於jvm調優
關於jvm調優,我相信很多人甚至不會接觸,因為畢竟有多少開發能直接操作線上伺服器環境呢?可能也就是公司大牛級別的人了。
jvm本身東西很多,但是更多的說到jvm調優,我們主要是針對full GC 就是FGC的優化,至於YGC 是正常的,但是我們希望在應用服務中,更多的對象應該在YGC被回收,而不是無法回收全部放入FGC,因為FGC里的對象都是長期存活的,對應的FGC的時間也會更長!!同時還有一些基於jvm的參數,例如新生代中eden、s0、s1的大小,這些都會直接影響到對象是否會被直接扔在老年代中。當然,如果線上程式很穩定,jvm監控FGC的頻率 時間都很正常,不建議修改jvm的參數!而且升級jdk版本也無需修改GC回收器!!
首先,我們要知道哪些會導致FGC
1.System.gc()方法的調用
此方法的調用是建議JVM進行Full GC,雖然只是建議而非一定,但很多情況下它會觸發 Full GC,從而增加Full GC的頻率,也即增加了間歇性停頓的次數。強烈影響系建議能不使用此方法就別使用,讓虛擬機自己去管理它的記憶體,可通過通過-XX:+ DisableExplicitGC來禁止RMI(Java遠程方法調用)調用System.gc。
2.老年代空間不足
在Survivor區域的對象滿足晉升到老年代的條件時,晉升進入老年代的對象大小大於老年代的可用記憶體,這個時候會觸發Full GC。,當執行Full GC後空間仍然不足,則拋出錯誤:java.lang.OutOfMemoryError: Java heap space 。為避免以上兩種狀況引起的FullGC,調優時應儘量做到讓對象在Minor GC階段被回收、讓對象在新生代多存活一段時間及不要創建過大的對象及數組。
3.Metaspace區記憶體達到閾值
4.統計得到的Minor GC晉升到舊生代的平均大小大於老年代的剩餘空間 Survivor區域對象晉升到老年代有兩種情況:
(1)一種是給每個對象定義一個對象計數器,如果對象在Eden區域出生,並且經過了第一次GC,那麼就將他的年齡設置為1,在Survivor區域的對象每熬過一次GC,年齡計數器加一,等到到達預設值15時,就會被移動到老年代中,預設值可以通過-XX:MaxTenuringThreshold來設置。
(2)另外一種情況是如果JVM發現Survivor區域中的相同年齡的對象占到所有對象的一半以上時,就會將大於這個年齡的對象移動到老年代,在這批對象在統計後發現可以晉升到老年代,但是發現老年代沒有足夠的空間來放置這些對象,這就會引起Full GC。 5.堆中產生大對象超過閾值這個參數可以通過-XX:PretenureSizeThreshold進行設定,大對象或者長期存活的對象進入老年代,典型的大對象就是很長的字元串或者數組,它們在被創建後會直接進入老年代,雖然可能新生代中的Eden區域可以放置這個對象,在要放置的時候JVM如果發現老年代的空間不足時,會觸發GC。
6.老年代連續空間不足
JVM如果判斷老年代沒有做足夠的連續空間來放置大對象,那麼就會引起Full GC,例如老年代可用空間大小為200K,但不是連續的,連續記憶體只要100K,而晉升到老年代的對象大小為120K,由於120>100的連續空間,所以就會觸發Full GC。
那如何排查服務gc頻率呢?
直接上arthas:
- Github:https://github.com/alibaba/arthas
- 文檔:https://arthas.aliyun.com/doc/
https://arthas.aliyun.com/doc/vmoption.html
通過dashboard 以及命令可以排查gc的問題:
- 使用vmoption命令動態打開GC日誌
$ vmoption PrintGC true
$ vmoption PrintGC true Successfully updated the vm option. NAME BEFORE-VALUE AFTER-VALUE ------------------------------------ PrintGC false true
$ vmoption PrintGCDetails true
$ vmoption PrintGCDetails true Successfully updated the vm option. NAME BEFORE-VALUE AFTER-VALUE ------------------------------------------- PrintGCDetails false true
-
使用vmtool強制GC
$ vmtool --action forceGc
[GC (JvmtiEnv ForceGarbageCollection) [PSYoungGen: 2184K->352K(76288K)] 19298K->17474K(166912K), 0.0011562 secs] [Times: user=0.01 sys=0.00, real=0.00 secs]
[Full GC (JvmtiEnv ForceGarbageCollection) [PSYoungGen: 352K->0K(76288K)] [ParOldGen: 17122K->16100K(90112K)] 17474K->16100K(166400K), [Metaspace: 20688K->20688K(1069056K)], 0.0232947 secs] [Times: user=0.14 sys=0.01, real=0.03 secs]
- 其他gc參數
$ vmoption PrintGCID true 列印GC ID
$ vmoption PrintGCID true Successfully updated the vm option. NAME BEFORE-VALUE AFTER-VALUE -------------------------------------- PrintGCID false true
$ vmoption PrintGCDateStamps true 列印GC時間戳
$ vmoption PrintGCDateStamps true Successfully updated the vm option. NAME BEFORE-VALUE AFTER-VALUE ---------------------------------------------- PrintGCDateStamps false true
$ vmoption PrintGCTimeStamps true 列印GC啟動時間
$ vmoption PrintGCTimeStamps true Successfully updated the vm option. NAME BEFORE-VALUE AFTER-VALUE ---------------------------------------------- PrintGCTimeStamps false true
- heapdump
打開HeapDumpBeforeFullGC開關,可以在GC前生成heapdump文件;打開HeapDumpAfterFullGC開關,可以在GC結束後生成heapdump文件
$ vmoption HeapDumpBeforeFullGC true Successfully updated the vm option. NAME BEFORE-VALUE AFTER-VALUE ------------------------------------------------- HeapDumpBeforeFullGC false true $ vmtool --action forceGc
再使用vmtool --action forceGc強制GC,則可以在GC日誌中發現heapdump信息,並且在應用目錄下會生成heapdump hprof
打開PrintClassHistogramBeforeFullGC開關,可以在GC前列印類直方圖;打開PrintClassHistogramAfterFullGC開關,可以在GC結束後列印類直方圖
$ vmoption PrintClassHistogramBeforeFullGC true Successfully updated the vm option. NAME BEFORE-VALUE AFTER-VALUE ------------------------------------------------------------ PrintClassHistogramBeforeFullGC false true $ vmtool --action forceGc
再使用vmtool --action forceGc強制GC,在GC日誌中會列印類直方圖,可以直觀知道每個類的instances數量,占用記憶體大小:
#13: [Class Histogram (before full gc): num #instances #bytes class name ---------------------------------------------- 1: 24519 5783400 [C 2: 5648 5102712 [B 3: 3685 888128 [Ljava.lang.Object; 4: 3255 619560 [I 5: 24263 582312 java.lang.String 6: 4227 475320 java.lang.Class 7: 1288 402112 [Ljava.util.HashMap$Node; 8: 75 296160 [Ljava.nio.channels.SelectionKey; 9: 6759 216288 java.util.HashMap$Node 10: 2069 182072 java.lang.reflect.Method 11: 3326 133040 java.util.LinkedHashMap$Entry
具體使用,參考arthas的使用文檔。
-
常用JVM參數
堆設置: -Xmx3500m 設置JVM最大可用記憶體為3550M -Xms3500m 設置JVM堆記憶體為3550m。此值可以設置與-Xmx相同,以避免每次垃圾回收完成後JVM重新分配記憶體 -Xmn2g 設置年輕代大小為2G -Xss128k 設置每個線程的堆棧大小 ‐XX:MetaspaceSize=256M 設置元空間大小 ‐XX:MaxMetaspaceSize=256M 設置元空間最大值 -XX:NewRatio=4 設置年輕代(包括Eden和兩個Survivor區)與年老代的比值(除去持久代) -XX:SurvivorRatio=4 設置年輕代中Eden區與Survivor區的大小比值。設置為4,則兩個Survivor區與一個Eden區的比值為2:4 -XX:MaxPermSize=16m 設置持久代大小為16m -XX:MaxTenuringThreshold=0 設置垃圾最大年齡,如果設置為0的話,則年輕代對象不經過Survivor區,直接進入年老代 垃圾收集器: -XX:+UseParallelGC 選擇垃圾收集器為並行收集器 -XX:ParallelGCThreads=20 配置並行收集器的線程數 -XX:+UseParallelOldGC 配置年老代垃圾收集方式為並行收集 -XX:MaxGCPauseMillis=100 設置每次年輕代垃圾回收的最長時間,如果無法滿足此時間,JVM會自動調整年輕代大小,以滿足此值 -XX:+UseConcMarkSweepGC設置年老代為CMS併發收集 -XX:+UseParNewGC 設置年輕代為並行收集。可與CMS收集同時使用 日誌列印: -XX:+PrintGC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCApplicationStoppedTime 列印垃圾回收期間程式暫停的時間 -XX:PrintHeapAtGC 列印GC前後的詳細堆棧信息
例如:
1.將堆的最大、最小設置為相同的值,目的是防止垃圾收集器在最小、最大之間收縮堆而產生額外的時間。
-Xmx3550m: 最大堆大小為3550m。
-Xms3550m: 設置初始堆大小為3550m。
2.在配置較好的機器上(比如多核、大記憶體),可以為老年代選擇並行收集演算法: -XX:+UseParallelOldGC 。
3.年輕代和老年代將根據預設的比例(1:2)分配堆記憶體, 可以通過調整二者之間的比率來調整二者之間的大小,也可以針對回收代。
比如年輕代,通過 -XX:newSize -XX:MaxNewSize來設置其絕對大小。同樣,為了防止年輕代的堆收縮,我們通常會把-XX:newSize -XX:MaxNewSize設置為同樣大小。
4.年輕代和老年代設置多大才算合理
1)更大的年輕代必然導致更小的老年代,大的年輕代會延長普通GC的周期,但會增加每次GC的時間;小的老年代會導致更頻繁的Full GC
2)更小的年輕代必然導致更大老年代,小的年輕代會導致普通GC很頻繁,但每次的GC時間會更短;大的老年代會減少Full GC的頻率
如何選擇應該依賴應用程式對象生命周期的分佈情況: 如果應用存在大量的臨時對象,應該選擇更大的年輕代;如果存在相對較多的持久對象,老年代應該適當增大。但很多應用都沒有這樣明顯的特性。
在抉擇時應該根 據以下兩點:
(1)本著Full GC儘量少的原則,讓老年代儘量緩存常用對象,JVM的預設比例1:2也是這個道理 。
(2)通過觀察應用一段時間,看其他在峰值時老年代會占多少記憶體,在不影響Full GC的前提下,根據實際情況加大年輕代,比如可以把比例控制在1:1。但應該給老年代至少預留1/3的增長空間。
在實際過程中,我們並不頻繁調整JVM參數,保證能夠使用就好,當然在日常的監控中我們可以觀察一下jvm中gc的頻率,FGC的大小,根據具體的場景進行選擇!正常情況下非必要不要去嘗試調整,否則線上問題會很頭疼。
本文來自博客園,作者:青檸_fisher,轉載請註明原文鏈接:https://www.cnblogs.com/oldEleven/p/17289884.html


