
1. 前文回顧 在之前的幾篇記憶體管理系列文章中,筆者帶大家從巨集觀角度完整地梳理了一遍 Linux 記憶體分配的整個鏈路,本文的主題依然是記憶體分配,這一次我們會從微觀的角度來探秘一下 Linux 內核中用於零散小記憶體塊分配的記憶體池 —— slab 分配器。 在本小節中,筆者還是按照以往的風格先帶大家簡單 ...
1. 前文回顧
在之前的幾篇記憶體管理系列文章中,筆者帶大家從巨集觀角度完整地梳理了一遍 Linux 記憶體分配的整個鏈路,本文的主題依然是記憶體分配,這一次我們會從微觀的角度來探秘一下 Linux 內核中用於零散小記憶體塊分配的記憶體池 —— slab 分配器。
在本小節中,筆者還是按照以往的風格先帶大家簡單回顧下之前巨集觀視角下 Linux 記憶體分配最為核心的內容,目的是讓大家從巨集觀視角平滑地過度到微觀視角,內容上有個銜接,不至於讓大家感到突兀。
下麵的內容我們只做簡單回顧,大家不必糾纏細節,把握整體巨集觀流程
在 《深入理解 Linux 物理記憶體分配與釋放全鏈路實現》一文中,筆者以內核物理記憶體分配與釋放的 API 為起點,詳細為大家介紹了物理記憶體分配與釋放的整個完整流程,以及相關內核源碼的實現。
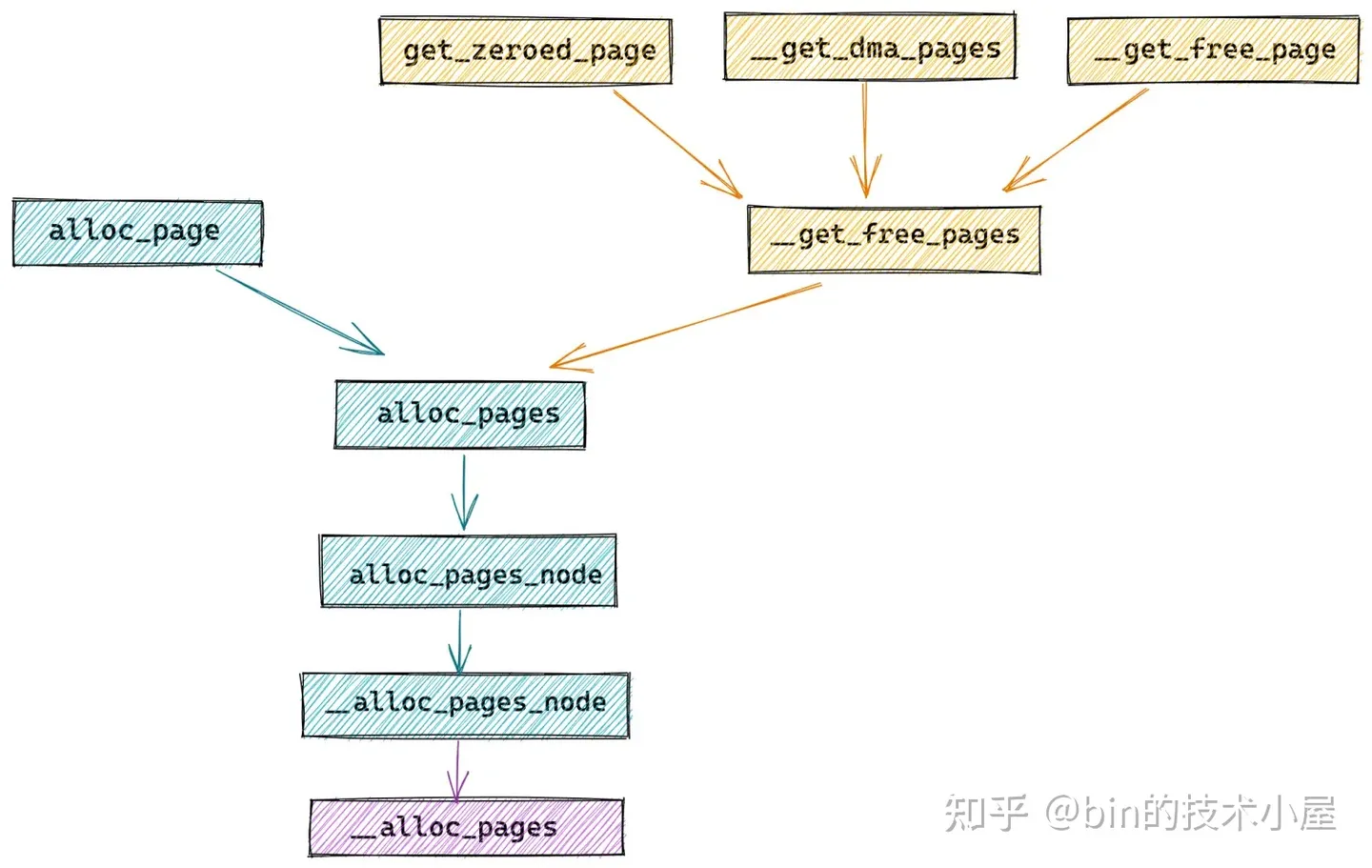
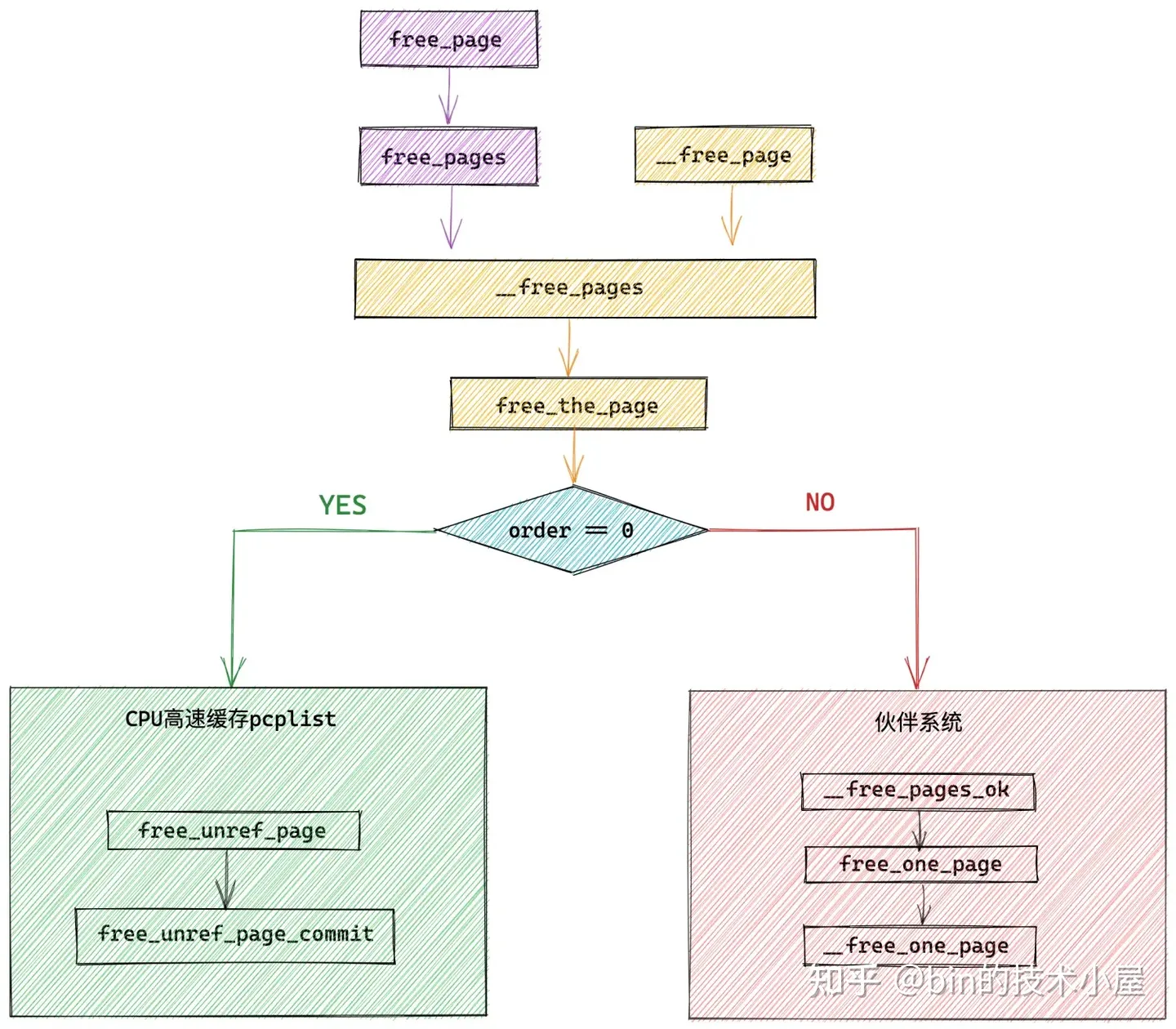
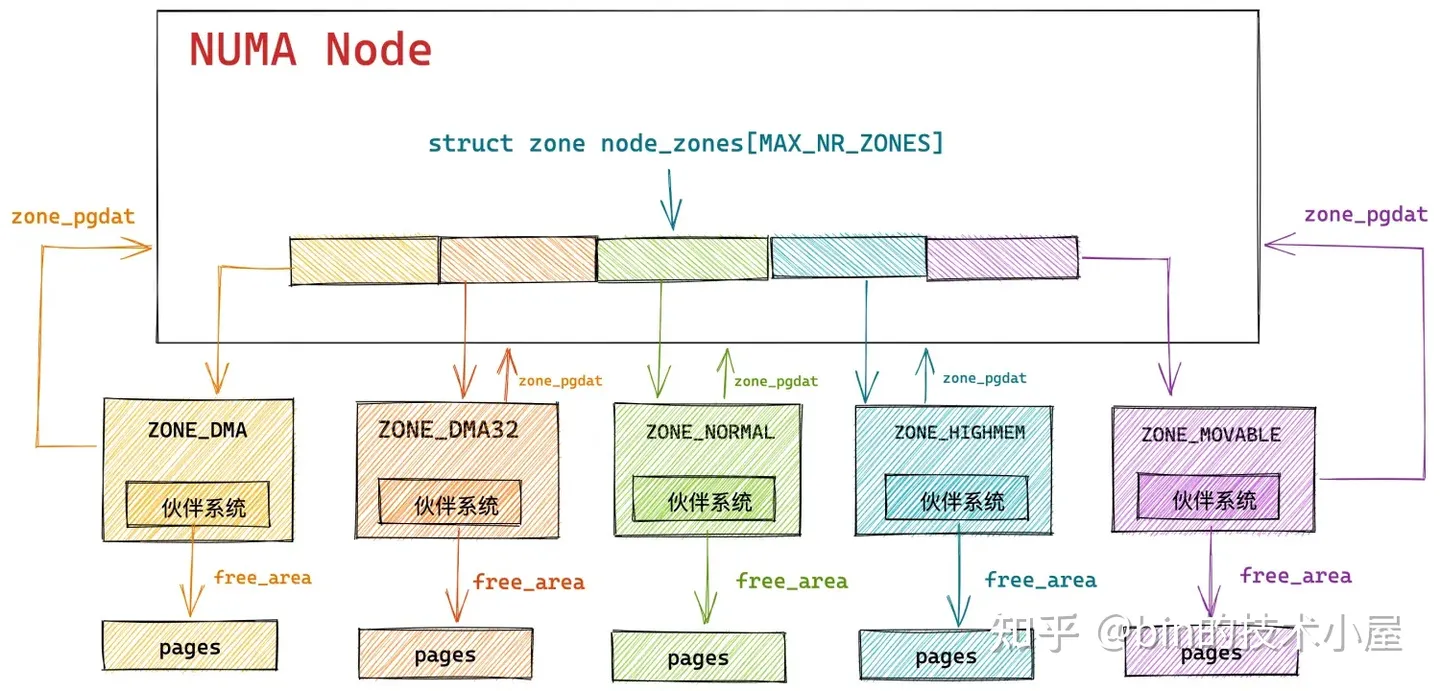
其中物理記憶體分配在內核中的全鏈路流程如下圖所示:
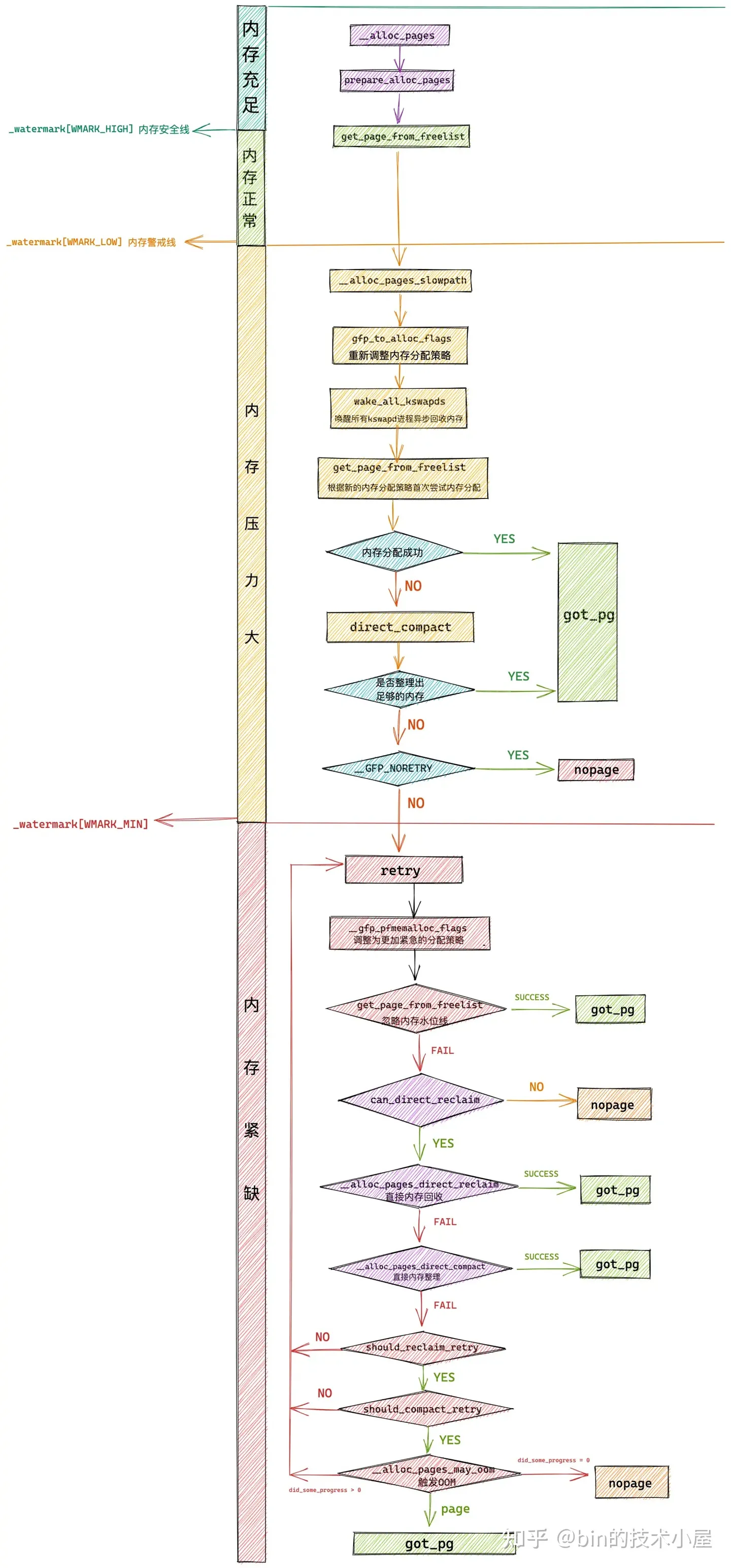
在 Linux 內核中,真正負責物理記憶體分配的核心是伙伴系統,在我們從總體上熟悉了物理記憶體分配的全鏈路流程之後,隨後我們繼續來到了伙伴系統的入口 get_page_from_freelist 函數,它的完整流程如下:
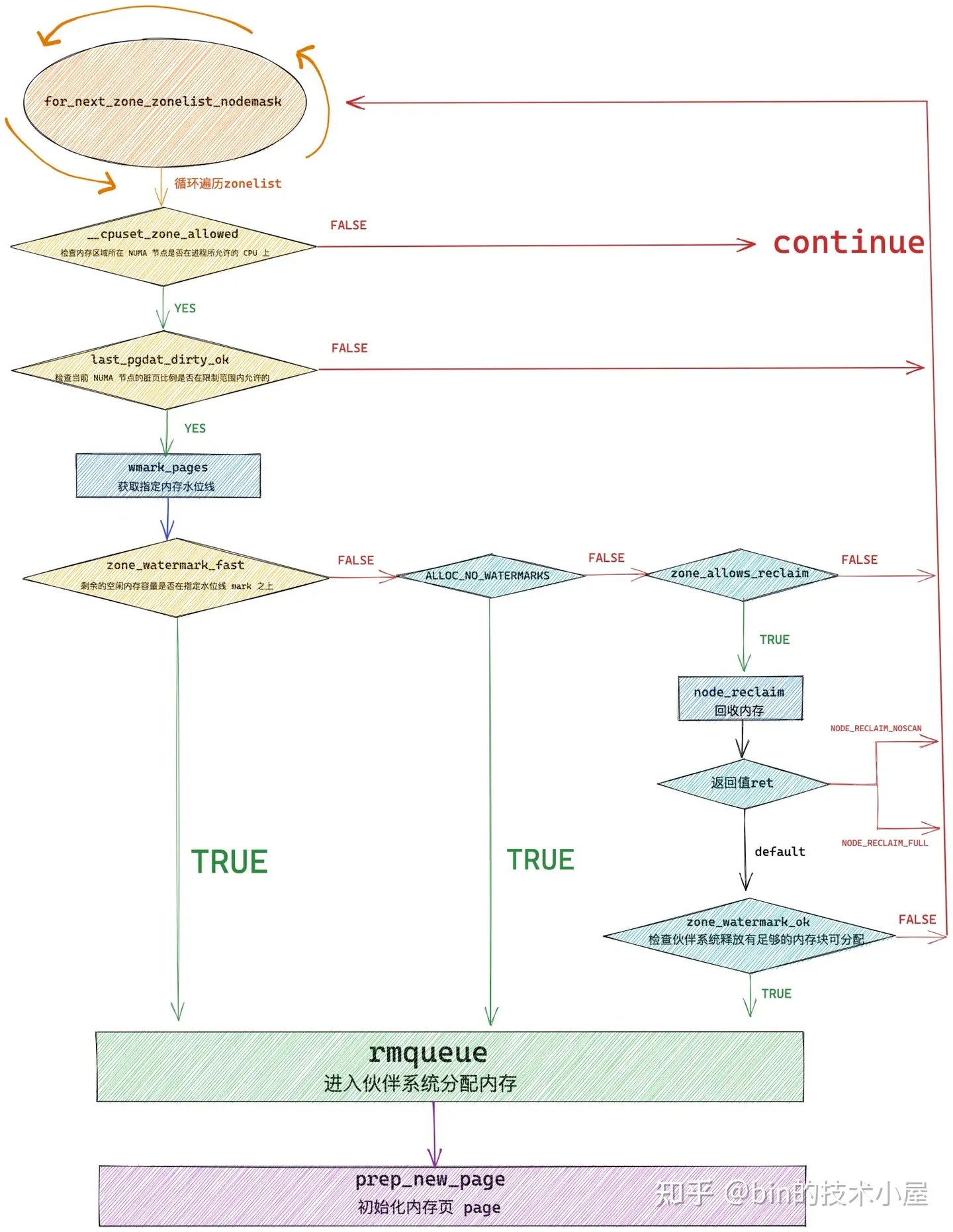
內核通過 get_page_from_freelist 函數,挨個遍歷檢查各個 NUMA 節點中的物理記憶體區域是否有足夠的空閑記憶體可以滿足本次的記憶體分配要求,當找到符合記憶體分配標準的物理記憶體區域 zone 之後,接下來就會通過 rmqueue 函數進入到該物理記憶體區域 zone 對應的伙伴系統中分配物理記憶體。
那麼內核既然已經有了伙伴系統,那麼為什麼還需要一個 slab 記憶體池呢 ?下麵就讓我們從這個疑問開始,正式拉開本文的帷幕~~~
2. 既然有了伙伴系統,為什麼還需要 Slab ?
從上篇文章 《深度剖析 Linux 伙伴系統的設計與實現》第一小節 “1. 伙伴系統的核心數據結構” 的介紹中我們知道,內核中的伙伴系統管理記憶體的最小單位是物理記憶體頁 page。
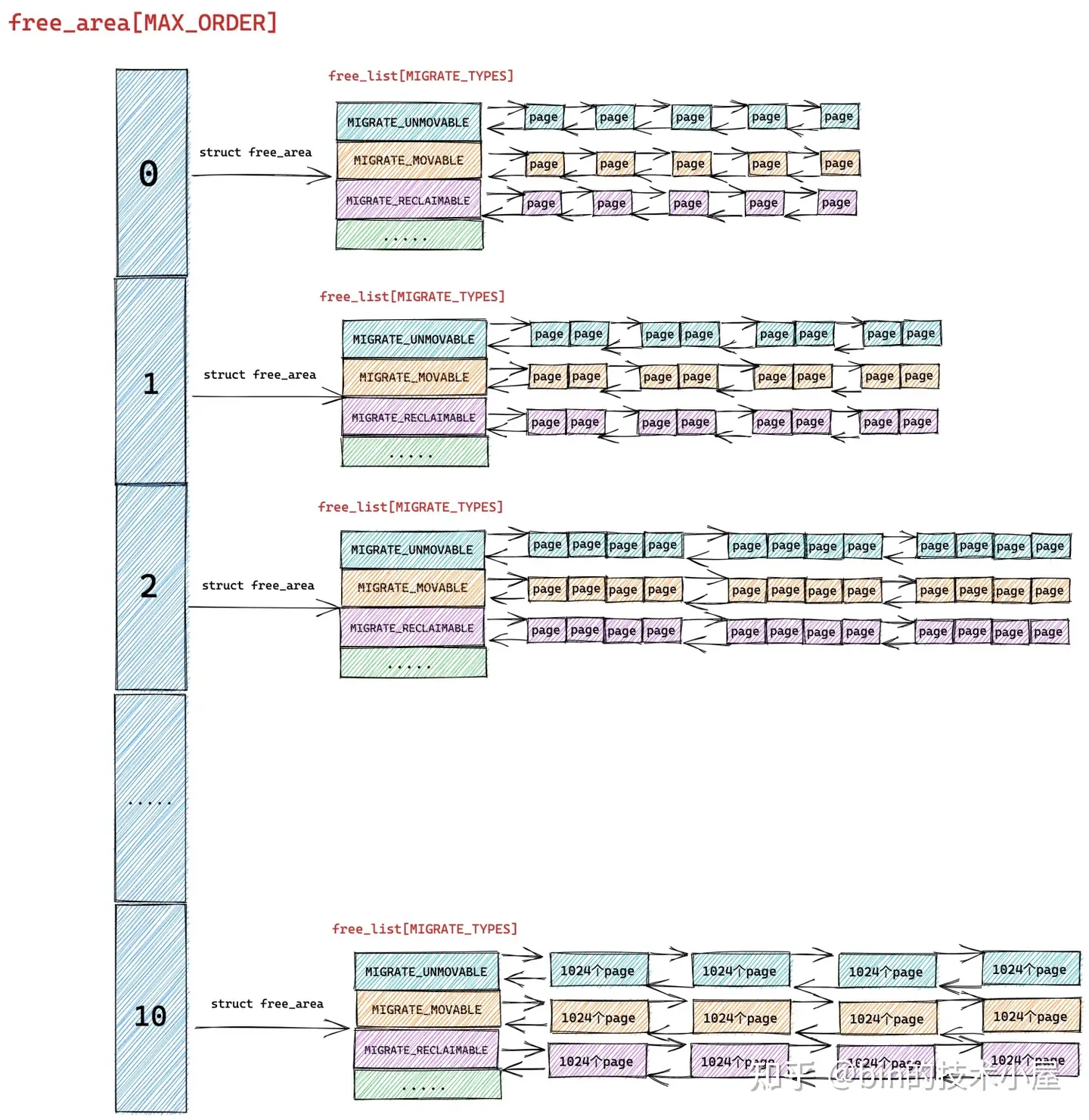
伙伴系統會將它所屬物理記憶體區 zone 里的空閑記憶體劃分成不同尺寸的物理記憶體塊,這裡的尺寸必須是 2 的次冪,物理記憶體塊可以是由 1 個 page 組成,也可以是 2 個 page,4 個 page ........ 1024 個 page 組成。
內核將這些相同尺寸的記憶體塊用一個內核數據結構 struct free_area 中的雙向鏈表 free_list 串聯組織起來。
struct free_area {
struct list_head free_list[MIGRATE_TYPES];
unsigned long nr_free;
};
而這些由 free_list 串聯起來的相同尺寸的記憶體塊又會近一步根據物理記憶體頁 page 的遷移類型 MIGRATE_TYPES 進行歸類,比如:MIGRATE_UNMOVABLE (不可移動的頁面類型),MIGRATE_MOVABLE (可以移動的記憶體頁類型),MIGRATE_RECLAIMABLE (不能移動,但是可以直接回收的頁面類型)等等。
這樣一來,具有相同遷移類型,相同尺寸的記憶體塊就被組織在了同一個 free_list 中,最終伙伴系統完整的數據結構如下圖所示:
free_area 中組織的全部是相同尺寸的記憶體塊,不同尺寸的記憶體塊被不同的 free_area 管理。在 free_area 的內部又會近一步按照物理記憶體頁面的遷移類型 MIGRATE_TYPES,將相同遷移類型的物理記憶體頁組織在同一個 free_list 中。
伙伴系統所分配的物理記憶體頁全部都是物理上連續的,並且只能分配 2 的整數冪個頁
隨後在物理記憶體分配的過程中,內核會基於這個完整的伙伴系統數據結構,進行不同尺寸的物理記憶體塊的分配與釋放,而分配與釋放的單位依然是 2 的整數冪個物理記憶體頁 page。
詳細的記憶體分配過程感興趣的讀者朋友可以回看下 《深度剖析 Linux 伙伴系統的設計與實現》一文中的第 3 小節 “ 3. 伙伴系統的記憶體分配原理 ” 以及第 6 小節 “ 6. 伙伴系統的實現 ”。
這裡我們只對伙伴系統的記憶體分配原理做一個簡單的整體回顧:
當內核向伙伴系統申請連續的物理記憶體頁時,會根據指定的物理記憶體頁遷移類型 MIGRATE_TYPES,以及申請的物理記憶體塊尺寸,找到對應的 free_list 鏈表,然後依次遍歷該鏈表尋找物理記憶體塊。
比如我們向內核申請 ( 2 ^ (order - 1),2 ^ order ] 之間大小的記憶體,並且這塊記憶體我們指定的遷移類型為 MIGRATE_MOVABLE 時,內核會按照 2 ^ order 個記憶體頁進行申請。
隨後內核會根據 order 找到伙伴系統中的 free_area[order] 對應的 free_area 結構,併進一步根據頁面遷移類型定位到對應的 free_list[MIGRATE_MOVABLE],如果該遷移類型的 free_list 中沒有空閑的記憶體塊時,內核會進一步到上一級鏈表也就是 free_area[order + 1] 中尋找。
如果 free_area[order + 1] 中對應的 free_list[MIGRATE_MOVABLE] 鏈表中還是沒有,則繼續迴圈到更高一級 free_area[order + 2] 尋找,直到在 free_area[order + n] 中的 free_list[MIGRATE_MOVABLE] 鏈表中找到空閑的記憶體塊。
但是此時我們在 free_area[order + n] 鏈表中找到的空閑記憶體塊的尺寸是 2 ^ (order + n) 大小,而我們需要的是 2 ^ order 尺寸的記憶體塊,於是內核會將這 2 ^ (order + n) 大小的記憶體塊逐級減半分裂,將每一次分裂後的記憶體塊插入到相應的 free_area 數組裡對應的 free_list[MIGRATE_MOVABLE] 鏈表中,並將最後分裂出的 2 ^ order 尺寸的記憶體塊分配給進程使用。
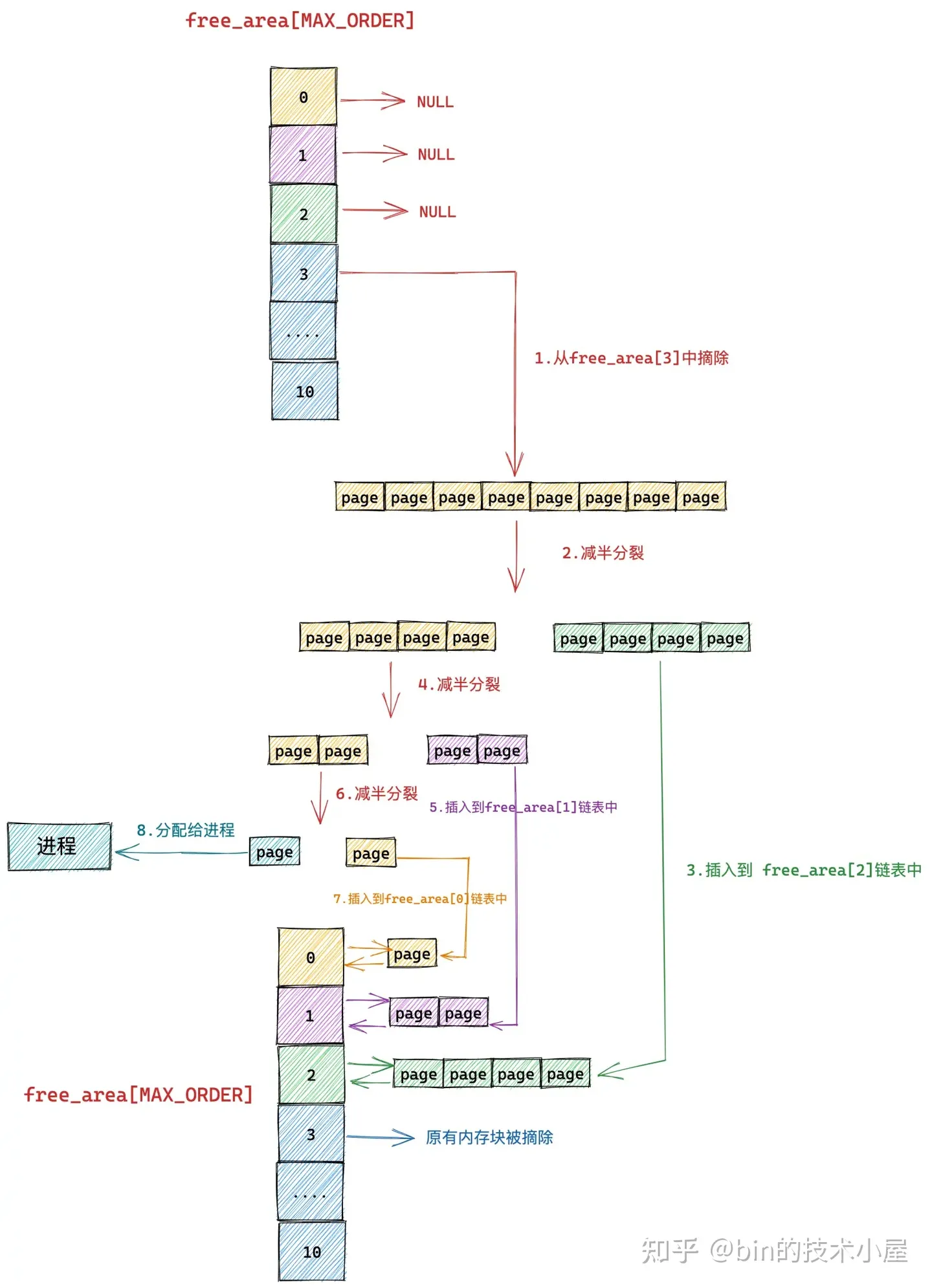
我們假設當前伙伴系統中只有 order = 3 的空閑鏈表 free_area[3],其餘剩下的分配階 order 對應的空閑鏈表中均是空的。 free_area[3] 中僅有一個空閑的記憶體塊,其中包含了連續的 8 個 page,我們暫時忽略 MIGRATE_TYPES 相關的組織結構。
現在我們向伙伴系統申請一個 page 大小的記憶體(對應的分配階 order = 0),如上圖所示,內核會在伙伴系統中首先查看 order = 0 對應的空閑鏈表 free_area[0] 中是否有空閑記憶體塊可供分配。如果有,則將該空閑記憶體塊從 free_area[0] 摘下返回,記憶體分配成功。
如果沒有,隨後內核會根據前邊介紹的記憶體分配邏輯,繼續升級到 free_area[1] , free_area[2] 鏈表中尋找空閑記憶體塊,直到查找到 free_area[3] 發現有一個可供分配的記憶體塊。這個記憶體塊中包含了 8 個 連續的空閑 page,但是我們只要一個 page 就夠了,那該怎麼辦呢?
於是內核先將 free_area[3] 中的這個空閑記憶體塊從鏈表中摘下,然後減半分裂成兩個記憶體塊,分裂出來的這兩個記憶體塊分別包含 4 個 page(分配階 order = 2)。
隨後內核會將分裂出的後半部分(上圖中綠色部分,order = 2),插入到 free_area[2] 鏈表中。
前半部分(上圖中黃色部分,order = 2)繼續減半分裂,分裂出來的這兩個記憶體塊分別包含 2 個 page(分配階 order = 1)。如上圖中第 4 步所示,前半部分為黃色,後半部分為紫色。同理按照前邊的分裂邏輯,內核會將後半部分記憶體塊(紫色部分,分配階 order = 1)插入到 free_area[1] 鏈表中。
前半部分(圖中黃色部分,order = 1)在上圖中的第 6 步繼續減半分裂,分裂出來的這兩個記憶體塊分別包含 1 個 page(分配階 order = 0),前半部分為青色,後半部分為黃色。
黃色後半部分插入到 frea_area[0] 鏈表中,青色前半部分返回給進程,這時伙伴系統分配記憶體流程結束。
我們從以上介紹的伙伴系統核心數據結構,以及伙伴系統記憶體分配原理的相關內容來看,伙伴系統管理物理記憶體的最小單位是物理記憶體頁 page。也就是說,當我們向伙伴系統申請記憶體時,至少要申請一個物理記憶體頁。
而從內核實際運行過程中來看,無論是從內核態還是從用戶態的角度來說,對於記憶體的需求量往往是以位元組為單位,通常是幾十位元組到幾百位元組不等,遠遠小於一個頁面的大小。如果我們僅僅為了這幾十位元組的記憶體需求,而專門為其分配一整個記憶體頁面,這無疑是對寶貴記憶體資源的一種巨大浪費。
於是在內核中,這種專門針對小記憶體的分配需求就應運而生了,而本文的主題—— slab 記憶體池就是專門應對小記憶體頻繁的分配和釋放的場景的。
slab 首先會向伙伴系統一次性申請一個或者多個物理記憶體頁面,正是這些物理記憶體頁組成了 slab 記憶體池。
隨後 slab 記憶體池會將這些連續的物理記憶體頁面劃分成多個大小相同的小記憶體塊出來,同一種 slab 記憶體池下,劃分出來的小記憶體塊尺寸是一樣的。內核會針對不同尺寸的小記憶體分配需求,預先創建出多個 slab 記憶體池出來。
這種小記憶體在內核中的使用場景非常之多,比如,內核中那些經常使用,需要頻繁申請釋放的一些核心數據結構對象:task_struct 對象,mm_struct 對象,struct page 對象,struct file 對象,socket 對象等。
而創建這些內核核心數據結構對象以及為這些核心對象分配記憶體,銷毀這些內核對象以及釋放相關的記憶體是需要性能開銷的。
這一點我們從 《深入理解 Linux 物理記憶體分配與釋放全鏈路實現》一文中詳細介紹的記憶體分配與釋放全鏈路過程中已經非常清楚的看到了,整個記憶體分配鏈路還是比較長的,如果遇到記憶體不足,還會涉及到記憶體的 swap 和 compact ,從而進一步產生更大的性能開銷。
既然 slab 專門是用於小記憶體塊分配與回收的,那麼內核很自然的就會想到,分別為每一個需要被內核頻繁創建和釋放的核心對象創建一個專屬的 slab 對象池,這些內核對象專屬的 slab 對象池會根據其所管理的具體內核對象所占用記憶體的大小 size,將一個或者多個完整的物理記憶體頁按照這個 size 劃分出多個大小相同的小記憶體塊出來,每個小記憶體塊用於存儲預先創建好的內核對象。
這樣一來,當內核需要頻繁分配和釋放內核對象時,就可以直接從相應的 slab 對象池中申請和釋放內核對象,避免了鏈路比較長的記憶體分配與釋放過程,極大地提升了性能。這是一種池化思想的應用。
關於更多池化思想的介紹,以及對象池的應用與實現,筆者之前寫過一篇對象池在用戶態應用程式中的設計與實現的文章 《詳解 Netty Recycler 對象池的精妙設計與實現》,感興趣的讀者朋友可以看一下。
將內核中的核心數據結構對象,池化在 slab 對象池中,除了可以避免內核對象頻繁反覆初始化和相關記憶體分配,頻繁反覆銷毀對象和相關記憶體釋放的性能開銷之外,其實還有很多好處,比如:
-
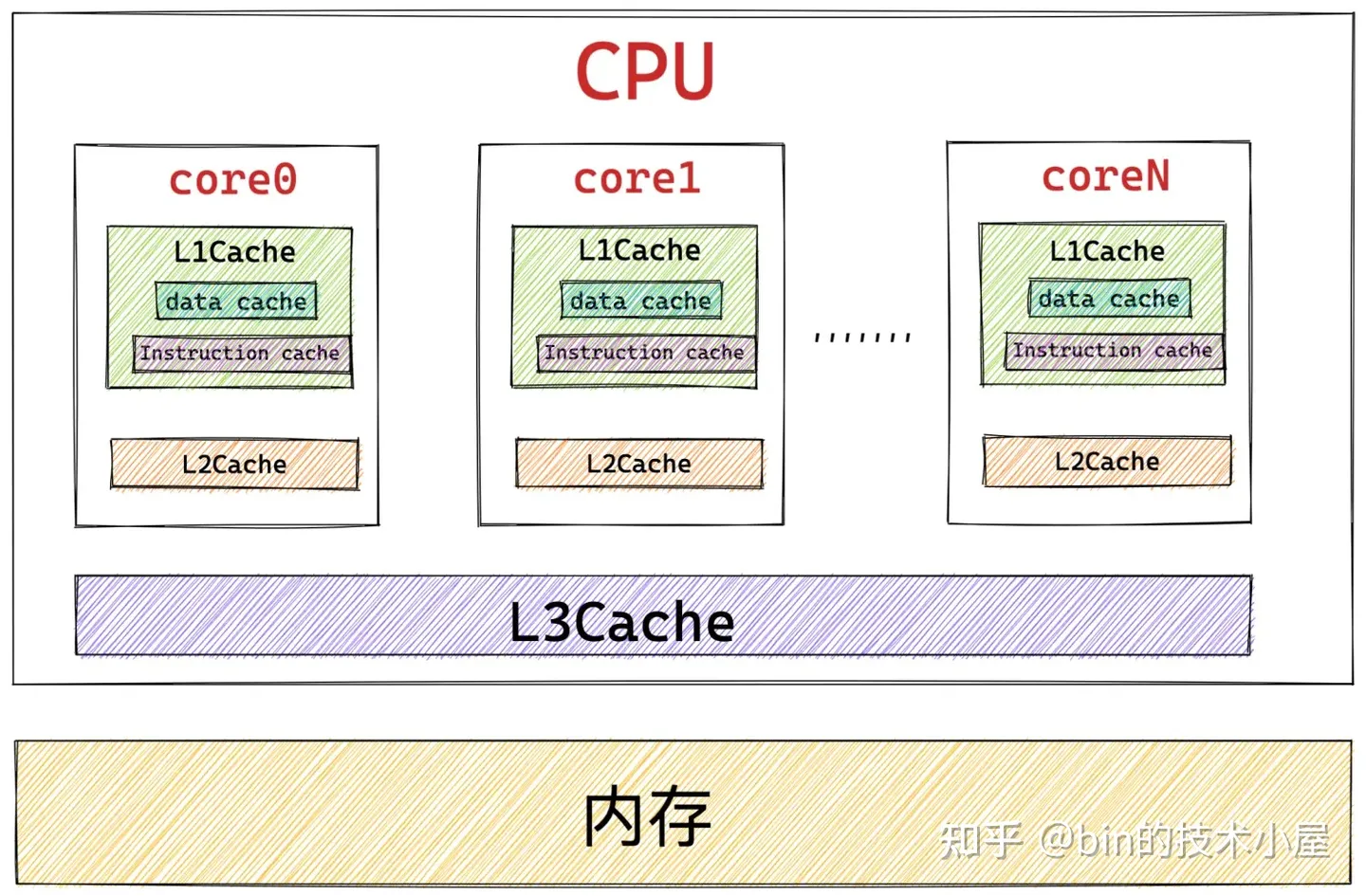
利用 CPU 高速緩存提高訪問速度。當一個對象被直接釋放回 slab 對象池中的時候,這個內核對象還是“熱的”,仍然會駐留在 CPU 高速緩存中。如果這時,內核繼續向 slab 對象池申請對象,slab 對象池會優先把這個剛剛釋放 “熱的” 對象分配給內核使用,因為對象很大概率仍然駐留在 CPU 高速緩存中,所以內核訪問起來速度會更快。
-
伙伴系統只能分配 2 的次冪個完整的物理記憶體頁,這會引起占用高速緩存以及 TLB 的空間較大,導致一些不重要的數據駐留在 CPU 高速緩存中占用寶貴的緩存空間,而重要的數據卻被置換到記憶體中。 slab 對象池針對小記憶體分配場景,可以有效的避免這一點。
-
調用伙伴系統的操作會對 CPU 高速緩存 L1Cache 中的 Instruction Cache(指令高速緩存)和 Data Cache (數據高速緩存)有污染,因為對伙伴系統的長鏈路調用,相關的一些指令和數據必然會填充到 Instruction Cache 和 Data Cache 中,從而將頻繁使用的一些指令和數據擠壓出去,造成緩存污染。而在內核空間中越浪費這些緩存資源,那麼在用戶空間中的進程就會越少的得到這些緩存資源,造成性能的下降。 slab 對象池極大的減少了對伙伴系統的調用,防止了不必要的 L1Cache 污染。
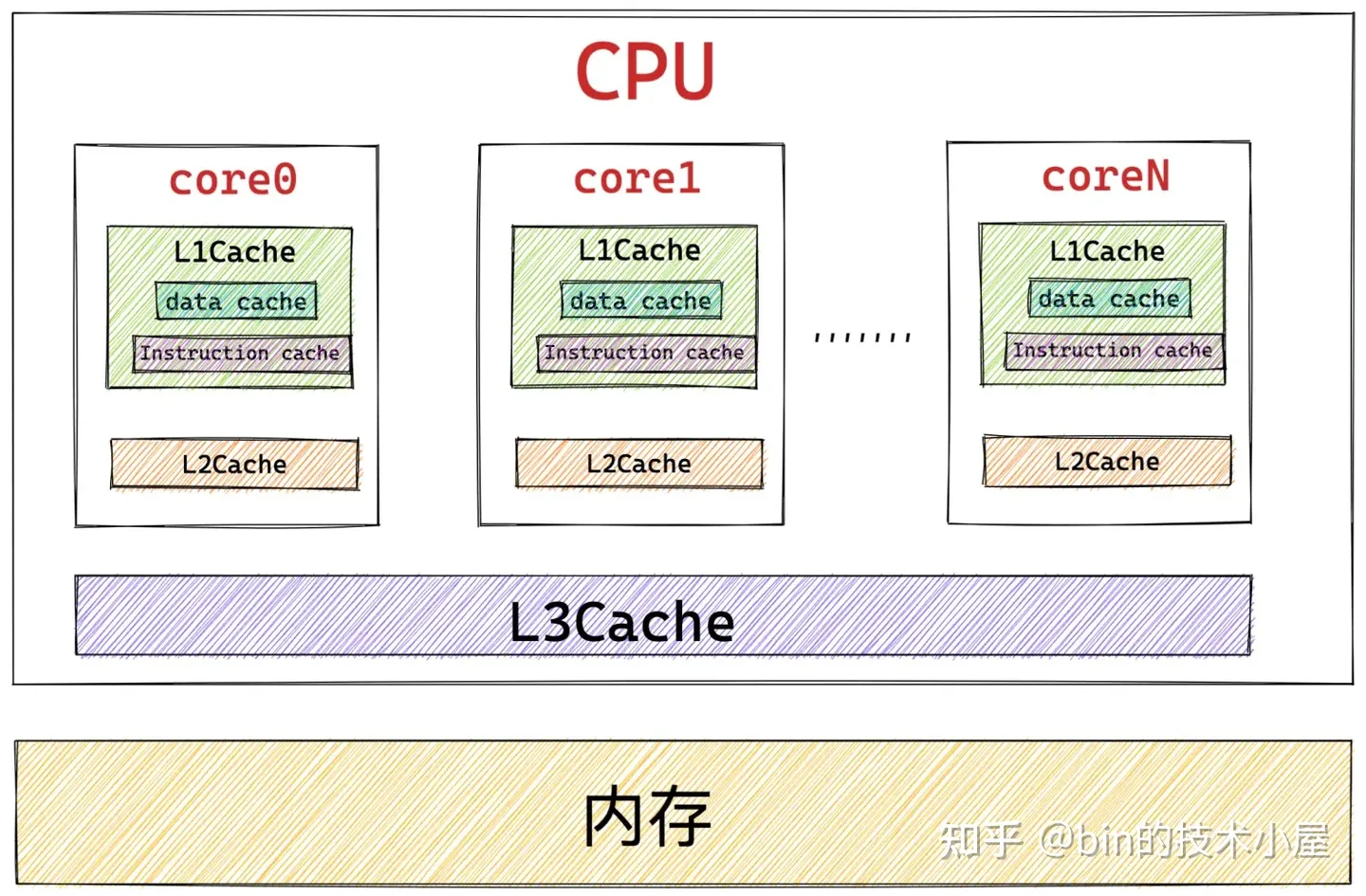
- 使用 slab 對象池可以充分利用 CPU 高速緩存,避免多個對象對同一 cache line 的爭用。如果對象直接存儲排列在伙伴系統提供的記憶體頁中的話(不受 slab 管理),那麼位於不同記憶體頁中具有相同偏移的對象很可能會被放入同一個 cache line 中,即使其他 cache line 還是空的。具體為什麼會造成具有相同記憶體偏移地址的對象會對同一 cache line 進行爭搶,筆者會在文章後面相關章節中為大家解答,這裡我們只是簡單列出 slab 針對小記憶體分配的一些優勢,目的是讓大家先從總體上把握。
3. slab 對象池在內核中的應用場景
現在我們最起碼從概念上清楚了 slab 對象池的產生背景,以及它要解決的問題場景。下麵筆者列舉了幾個 slab 對象池在內核中的使用場景,方便大家進一步從總體上理解。
本小節我們依然還是從總體上把握 slab 對象池,大家不必過度地陷入到細節當中。
- 當我們使用 fork() 系統調用創建進程的時候,內核需要使用 task_struct 專屬的 slab 對象池分配 task_struct 對象。
static struct task_struct *dup_task_struct(struct task_struct *orig, int node)
{
...........
struct task_struct *tsk;
// 從 task_struct 對象專屬的 slab 對象池中申請 task_struct 對象
tsk = alloc_task_struct_node(node);
...........
}
- 為進程創建虛擬記憶體空間的時候,內核需要使用 mm_struct 專屬的 slab 對象池分配 mm_struct 對象。
static struct mm_struct *dup_mm(struct task_struct *tsk,
struct mm_struct *oldmm)
{
..........
struct mm_struct *mm;
// 從 mm_struct 對象專屬的 slab 對象池中申請 mm_struct 對象
mm = allocate_mm();
..........
}
- 當我們向頁高速緩存 page cache 查找對應的文件緩存頁時,內核需要使用 struct page 專屬的 slab 對象池分配 struct page 對象。
struct page *pagecache_get_page(struct address_space *mapping, pgoff_t offset,
int fgp_flags, gfp_t gfp_mask)
{
struct page *page;
repeat:
// 在 radix_tree(page cache)中根據緩存頁 offset 查找緩存頁
page = find_get_entry(mapping, offset);
// 緩存頁不存在的話,跳轉到 no_page 處理邏輯
if (!page)
goto no_page;
.......省略.......
no_page:
// 從 page 對象專屬的 slab 對象池中申請 page 對象
page = __page_cache_alloc(gfp_mask);
// 將新分配的記憶體頁加入到頁高速緩存 page cache 中
err = add_to_page_cache_lru(page, mapping, offset, gfp_mask);
.......省略.......
}
return page;
}
- 當我們使用 open 系統調用打開一個文件時,內核需要使用 struct file專屬的 slab 對象池分配 struct file 對象。
struct file *do_filp_open(int dfd, struct filename *pathname,
const struct open_flags *op)
{
struct file *filp;
// 分配 struct file 內核對象
filp = path_openat(&nd, op, flags | LOOKUP_RCU);
..........
return filp;
}
static struct file *path_openat(struct nameidata *nd,
const struct open_flags *op, unsigned flags)
{
struct file *file;
// 從 struct file 對象專屬的 slab 對象池中申請 struct file 對象
file = alloc_empty_file(op->open_flag, current_cred());
..........
}
- 當服務端網路應用程式使用 accpet 系統調用接收客戶端的連接時,內核需要使用 struct socket 專屬的 slab 對象池為新進來的客戶端連接分配 socket 對象。
SYSCALL_DEFINE4(accept4, int, fd, struct sockaddr __user *, upeer_sockaddr,
int __user *, upeer_addrlen, int, flags)
{
struct socket *sock, *newsock;
// 查找正在 listen 狀態的監聽 socket
sock = sockfd_lookup_light(fd, &err, &fput_needed);
// 為新進來的客戶端連接申請 socket 對象以及與其關聯的 inode 對象
// 從 struct socket 對象專屬的 slab 對象池中申請 struct socket 對象
newsock = sock_alloc();
............. 利用監聽 socket 初始化 newsocket ..........
}
當然了被 slab 對象池所管理的內核核心對象不只是筆者上面為大家列舉的這五個,事實上,凡是需要被內核頻繁使用的內核對象都需要被 slab 對象池所管理。
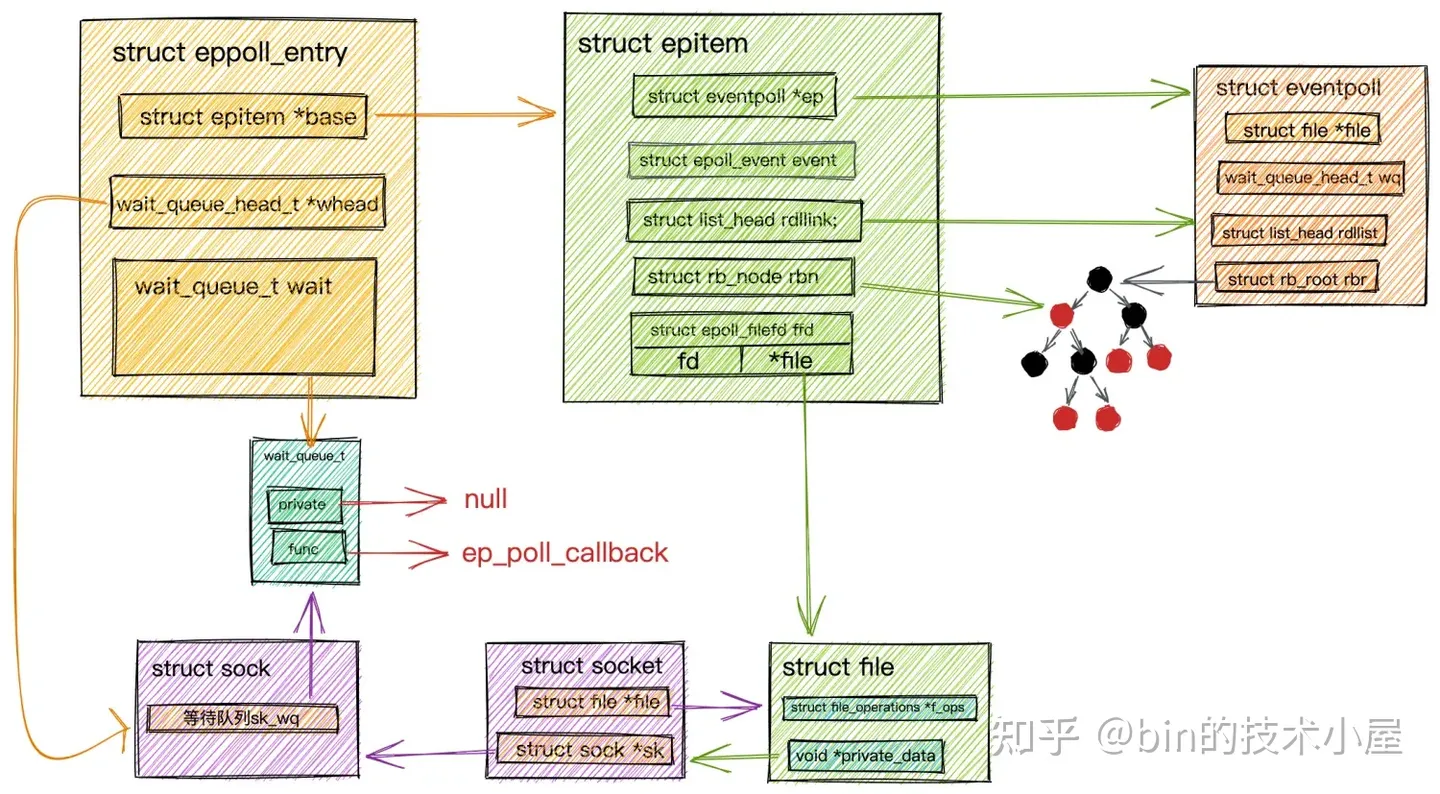
比如:我們在 《從 Linux 內核角度探秘 IO 模型的演變》 一文中為大家介紹的 epoll 相關的對象:
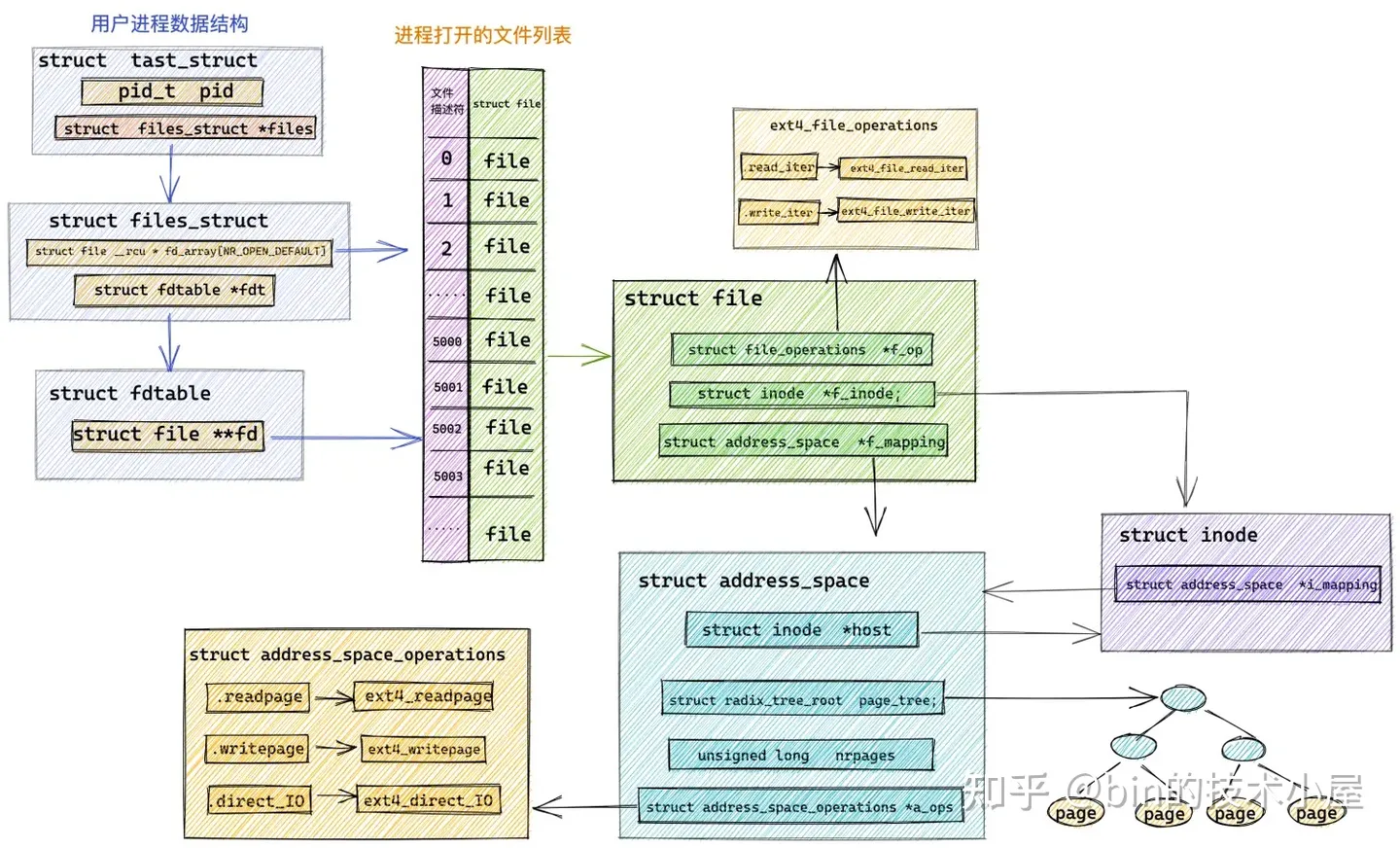
在《從 Linux 內核角度探秘 JDK NIO 文件讀寫本質》 一文中介紹的頁高速緩存 page cache 相關的對象:
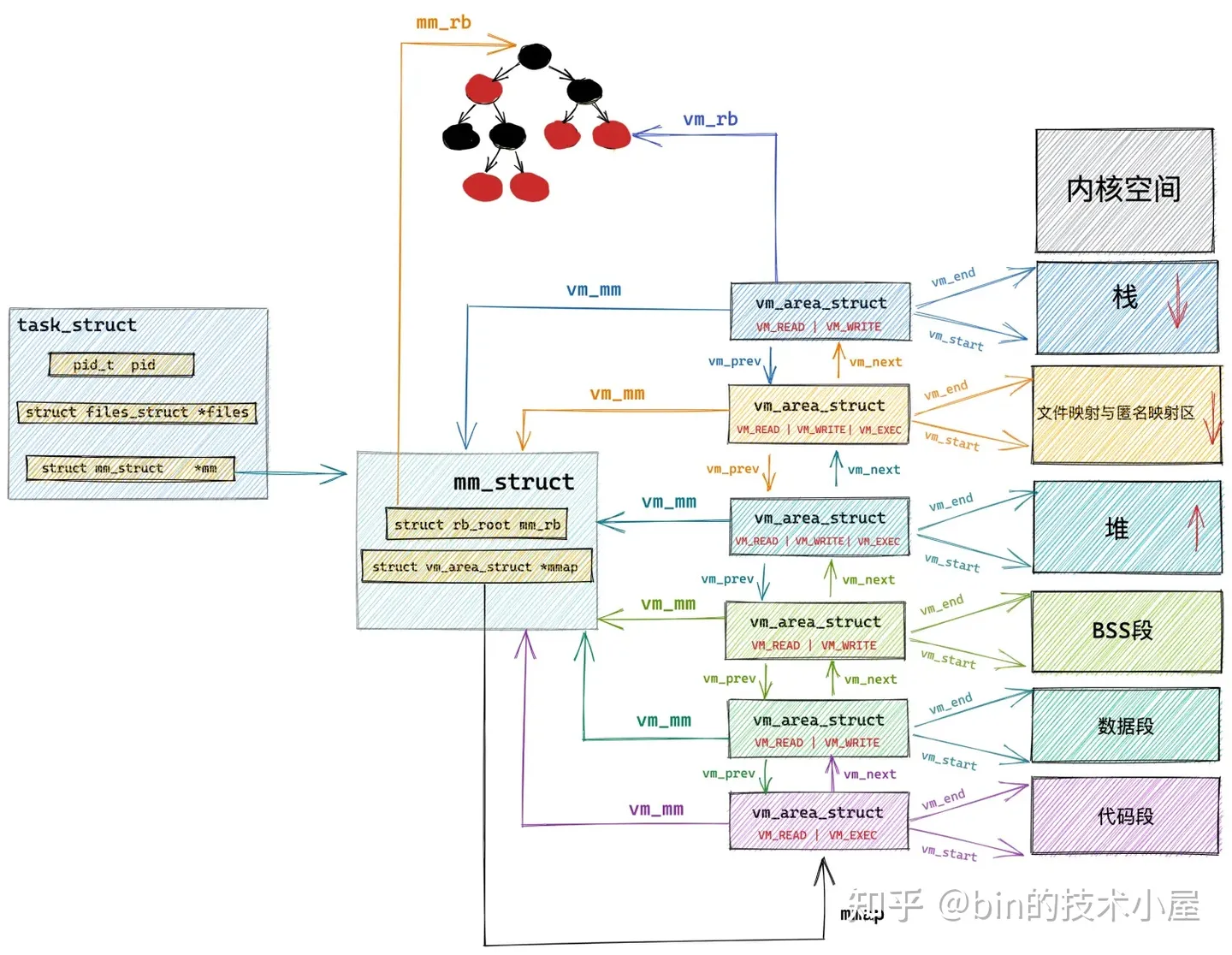
在 《深入理解 Linux 虛擬記憶體管理》 一文中介紹的虛擬記憶體地址空間相關的對象:
現在我們只是對 slab 對象池有了一個最錶面的認識,那麼接下來的內容,筆者會帶大家深入到 slab 對象池的實現細節中一探究竟。
在開始介紹內核源碼實現之前,筆者想和大家交代一下本文的行文思路,之前的系列文章中筆者都是採用 “總——分——總” 的思路為大家講述源碼,但是本文要介紹的 slab 對象池實現比較複雜,一上來就把總體架構給大家展示出來,大家看的也是一臉懵。
所以這裡我們換一種思路,筆者會帶大家從一個最簡單的物理記憶體頁 page 開始,一步一步地演進,直到一個完整的 slab 對象池架構清晰地展現在大家的面前。
4. slab, slub, slob 傻傻分不清楚
在開始正式介紹 slab 對象池之前,筆者覺得有必要先向大家簡單交代一下 Linux 系統中關於 slab 對象池的三種實現:slab,slub,slob。
其中 slab 的實現,最早是由 Sun 公司的 Jeff Bonwick 大神在 Solaris 2.4 系統中設計並實現的,由於 Jeff Bonwick 大神公開了 slab 的實現方法,因此被 Linux 所借鑒並於 1996 年在 Linux 2.0 版本中引入了 slab,用於 Linux 內核早期的小記憶體分配場景。
由於 slab 的實現非常複雜,slab 中擁有多種存儲對象的隊列,隊列管理開銷比較大,slab 元數據比較臃腫,對 NUMA 架構的支持臃腫繁雜(slab 引入時內核還沒支持 NUMA),這樣導致 slab 內部為了維護這些自身元數據管理結構就得花費大量的記憶體空間,這在配置有超大容量記憶體的伺服器上,記憶體的浪費是非常可觀的。
針對以上 slab 的不足,內核大神 Christoph Lameter 在 2.6.22 版本(2007 年發佈)中引入了新的 slub 實現。slub 簡化了 slab 一些複雜的設計,同時保留了 slab 的基本思想,摒棄了 slab 眾多管理隊列的概念,並針對多處理器,NUMA 架構進行優化,放棄了效果不太明顯的 slab 著色機制。slub 與 slab 相比,提高了性能,吞吐量,並降低了記憶體的浪費。成為現在內核中常用的 slab 實現。
而 slob 的實現是在內核 2.6.16 版本(2006 年發佈)引入的,它是專門為嵌入式小型機器小記憶體的場景設計的,所以實現上很精簡,能在小型機器上提供很不錯的性能。
而內核中關於記憶體池(小記憶體分配器)的相關 API 介面函數均是以 slab 命名的,但是我們可以通過配置的方式來平滑切換以上三種 slab 的實現。本文我們主要討論被大規模運用在伺服器 Linux 操作系統中的 slub 對象池的實現,所以本文下麵的內容,如無特殊說明,筆者提到的 slab 均是指 slub 實現。
5. 從一個簡單的記憶體頁開始聊 slab
從前邊小節的內容中,我們知道內核會把那些頻繁使用的核心對象統一放在 slab 對象池中管理,每一個核心對象對應一個專屬的 slab 對象池,以便提升核心對象的分配,訪問,釋放相關操作的性能。

如上圖所示,slab 對象池在記憶體管理系統中的架構層次是基於伙伴系統之上構建的,slab 對象池會一次性向伙伴系統申請一個或者多個完整的物理記憶體頁,在這些完整的記憶體頁內在逐步劃分出一小塊一小塊的記憶體塊出來,而這些小記憶體塊的尺寸就是 slab 對象池所管理的內核核心對象占用的記憶體大小。
下麵筆者就帶大家從一個最簡單的物理記憶體頁 page 開始,我們一步一步的推演 slab 的整個架構設計與實現。
如果讓我們自己設計一個對象池,首先最直觀最簡單的辦法就是先向伙伴系統申請一個記憶體頁,然後按照需要被池化對象的尺寸 object size,把記憶體頁劃分為一個一個的記憶體塊,每個記憶體塊尺寸就是 object size。
事實上,slab 對象池可以根據情況向伙伴系統一次性申請多個記憶體頁,這裡只是為了方便大家理解,我們先以一個記憶體頁為例,為大家說明 slab 中對象的記憶體佈局。
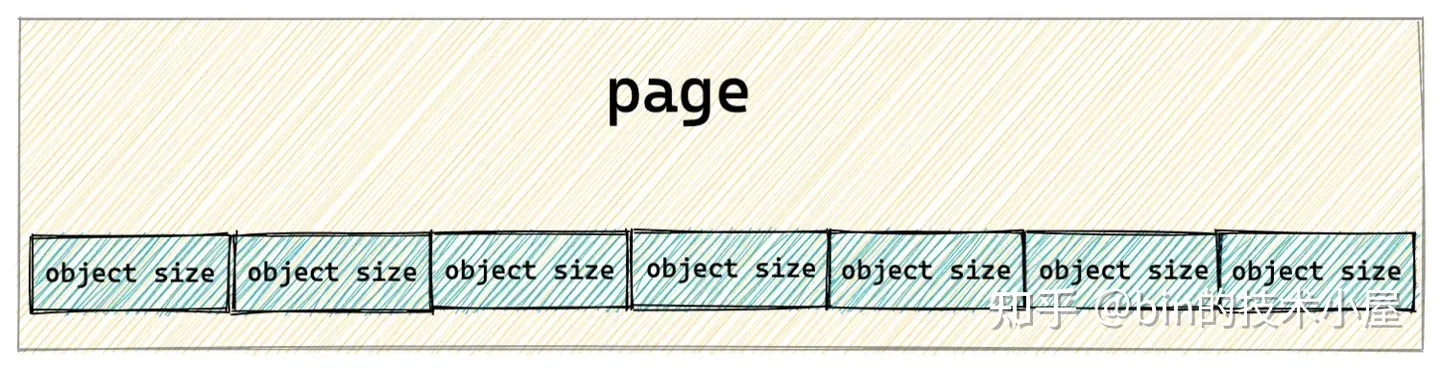
但是在一個工業級的對象池設計中,我們不能這麼簡單粗暴的搞,因為對象的 object size 可以是任意的,並不是記憶體對齊的,CPU 訪問一塊沒有進行對齊的記憶體比訪問對齊的記憶體速度要慢一倍。
因為 CPU 向記憶體讀取數據的單位是根據 word size 來的,在 64 位處理器中 word size = 8 位元組,所以 CPU 向記憶體讀寫數據的單位為 8 位元組。CPU 只能一次性向記憶體訪問按照 word size ( 8 位元組) 對齊的記憶體地址,如果 CPU 訪問一個未進行 word size 對齊的記憶體地址,就會經歷兩次訪存操作。
比如,我們現在需要訪問 0x0007 - 0x0014 這樣一段沒有對 word size 進行對齊的記憶體,CPU只能先從 0x0000 - 0x0007 讀取 8 個位元組出來先放入結果寄存器中並左移 7 個位元組(目的是只獲取 0x0007 ),然後 CPU 在從 0x0008 - 0x0015 讀取 8 個位元組出來放入臨時寄存器中並右移1個位元組(目的是獲取 0x0008 - 0x0014 )最後與結果寄存器或運算。最終得到 0x0007 - 0x0014 地址段上的 8 個位元組。
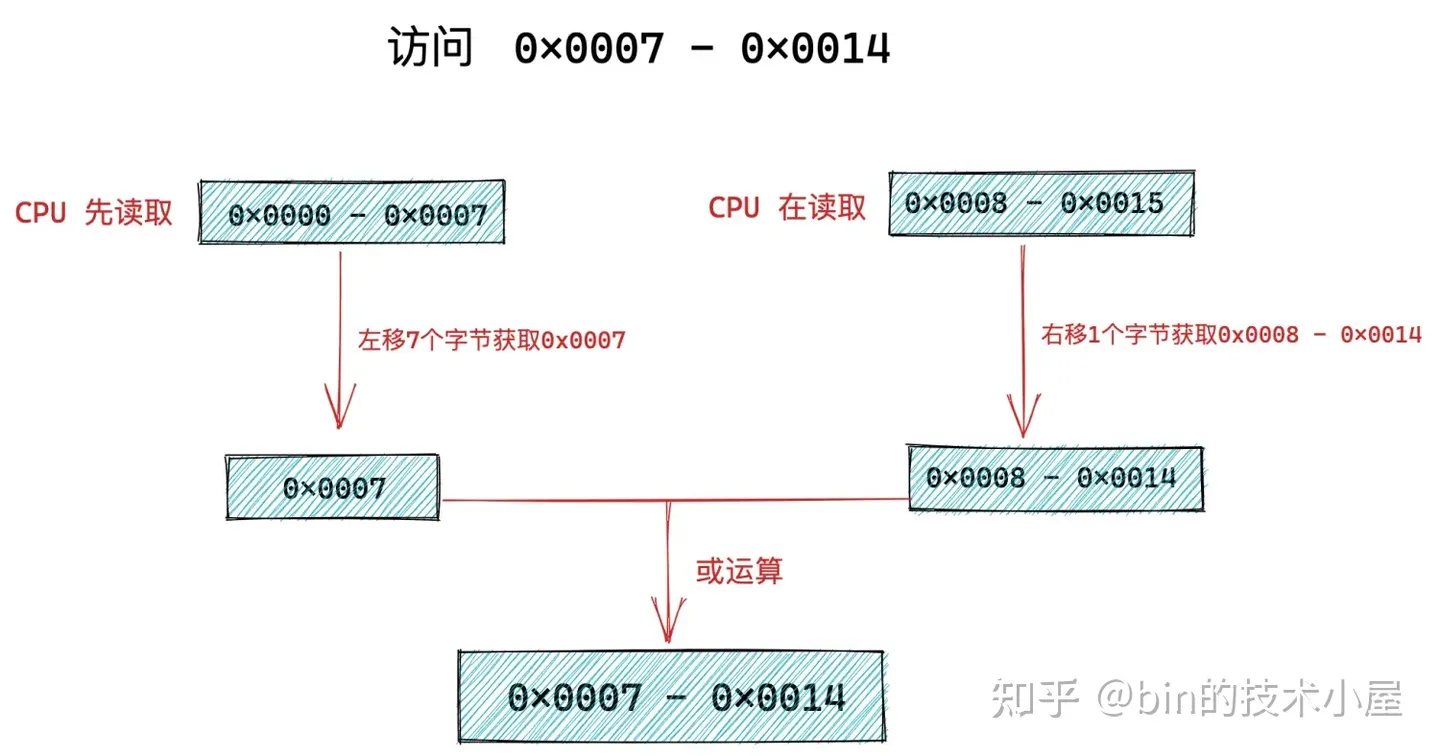
從上面過程我們可以看出,CPU 訪問一段未進行 word size 對齊的記憶體,需要兩次訪存操作。
記憶體對齊的好處還有很多,比如,CPU 訪問對齊的記憶體都是原子性的,對齊記憶體中的數據會獨占 cache line ,不會與其他數據共用 cache line,避免 false sharing。
這裡大家只需要簡單瞭解為什麼要進行記憶體對齊即可,關於記憶體對齊的詳細內容,感興趣的讀者可以回看下 《記憶體對齊的原理及其應用》 一文中的 “ 5. 記憶體對齊 ” 小節。
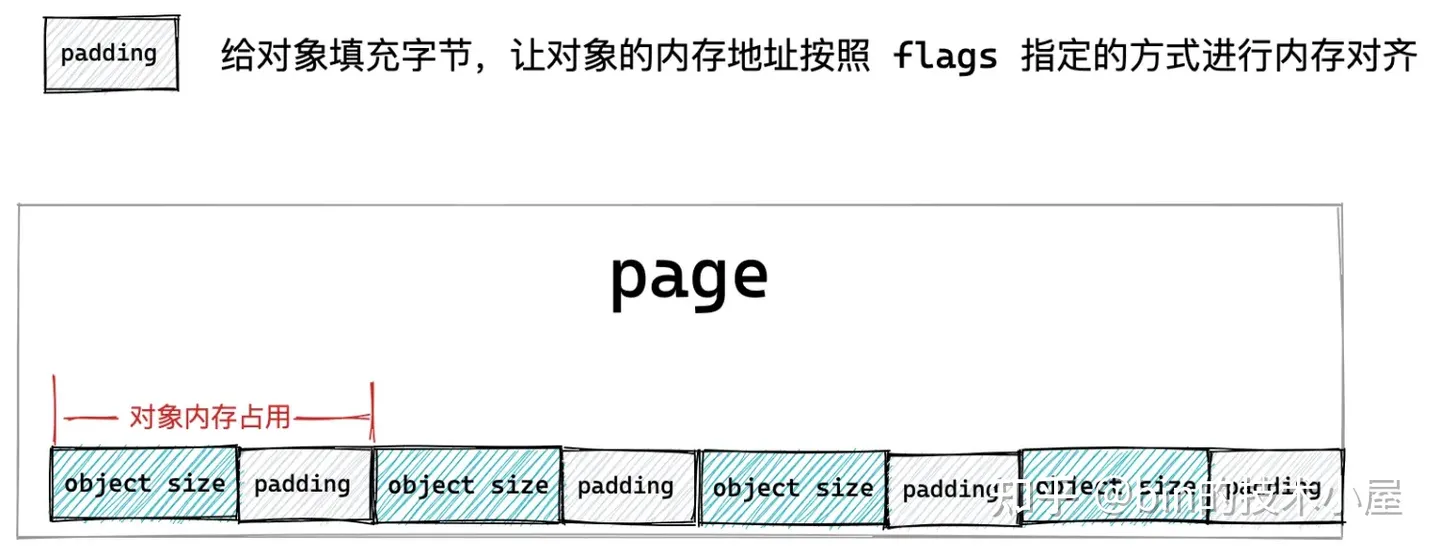
基於以上原因,我們不能簡單的按照對象尺寸 object size 來劃分記憶體塊,而是需要考慮到對象記憶體地址要按照 word size 進行對齊。於是上面的 slab 對象池的記憶體佈局又有了新的變化。
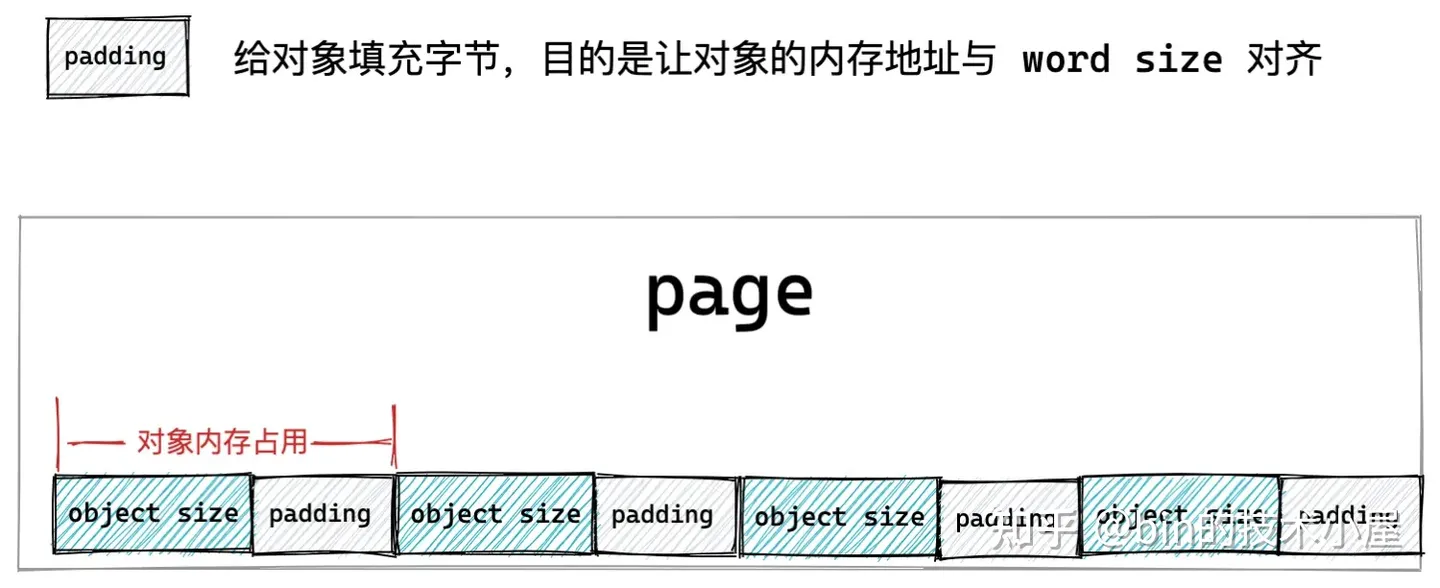
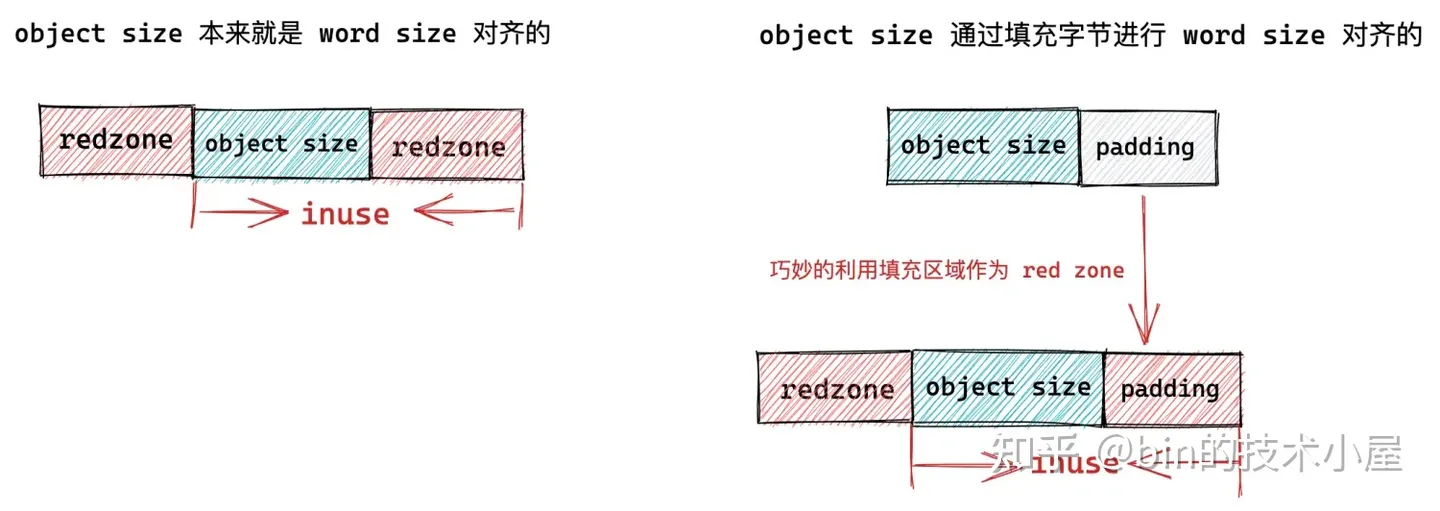
如果被池化對象的尺寸 object size 本來就是和 word size 對齊的,那麼我們不需要做任何事情,但是如果 object size 沒有和 word size 對齊,我們就需要填充一些位元組,目的是要讓對象的 object size 按照 word size 進行對齊,提高 CPU 訪問對象的速度。
但是上面的這些工作對於一個工業級的對象池來說還遠遠不夠,工業級的對象池需要應對很多複雜的詭異場景,比如,我們偶爾在複雜生產環境中會遇到的記憶體讀寫訪問越界的情況,這會導致很多莫名其妙的異常。
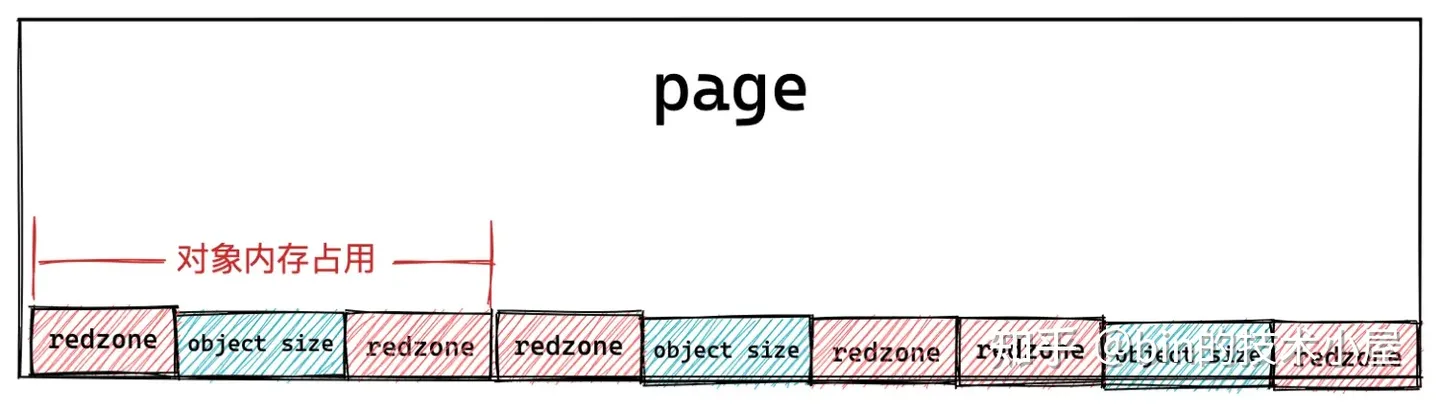
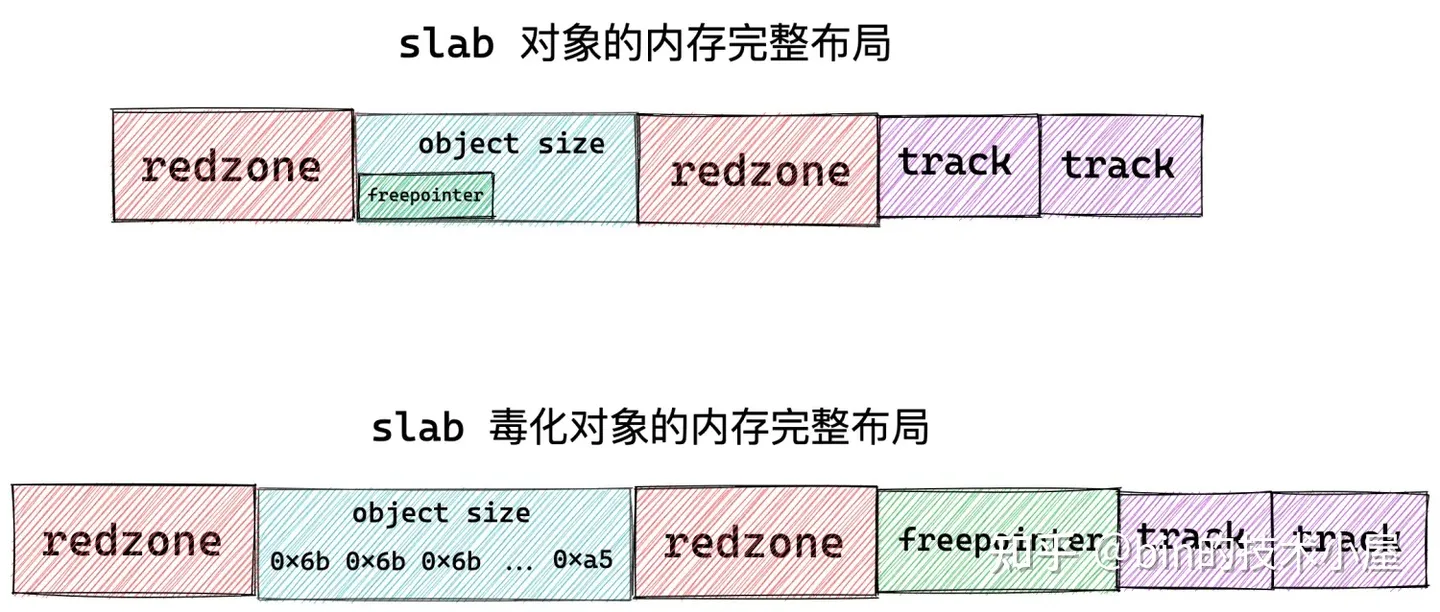
內核為了應對記憶體讀寫越界的場景,於是在對象記憶體的周圍插入了一段不可訪問的記憶體區域,這些記憶體區域用特定的位元組 0xbb 填充,當進程訪問的到記憶體是 0xbb 時,表示已經越界訪問了。這段記憶體區域在 slab 中的術語為 red zone,大家可以理解為紅色警戒區域。
插入 red zone 之後,slab 對象池的記憶體佈局近一步演進為下圖所示的佈局:
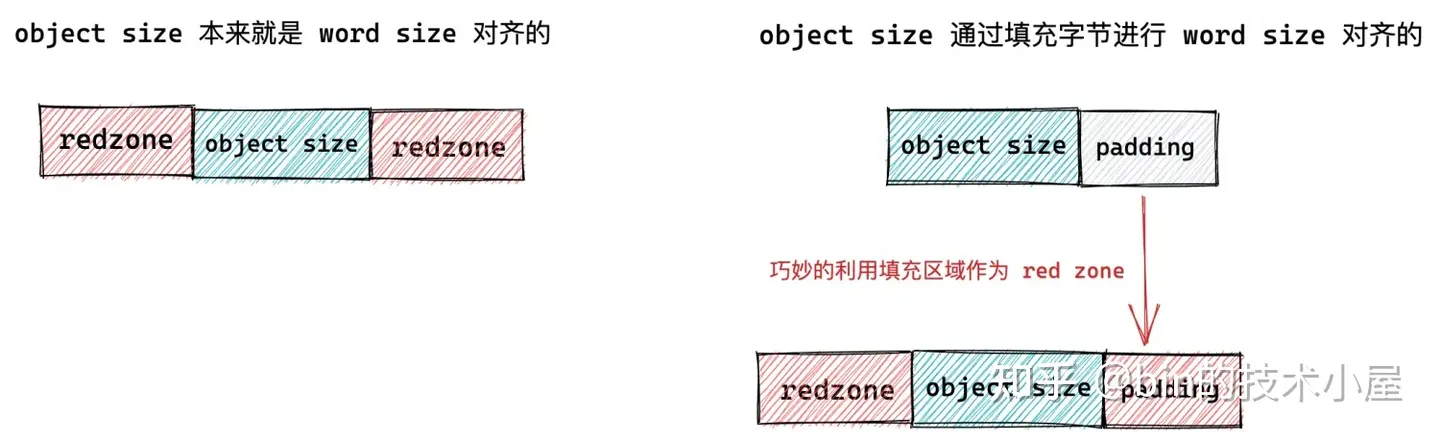
-
如果對象尺寸 object size 本身就是 word size 對齊的,那麼就需要在對象左右兩側填充兩段 red zone 區域,red zone 區域的長度一般就是 word size 大小。
-
如果對象尺寸 object size 是通過填充 padding 之後,才與 word size 對齊。內核會巧妙的利用對象右邊的這段 padding 填充區域作為 red zone。只需要額外的在對象記憶體區域的左側填充一段 red zone 即可。
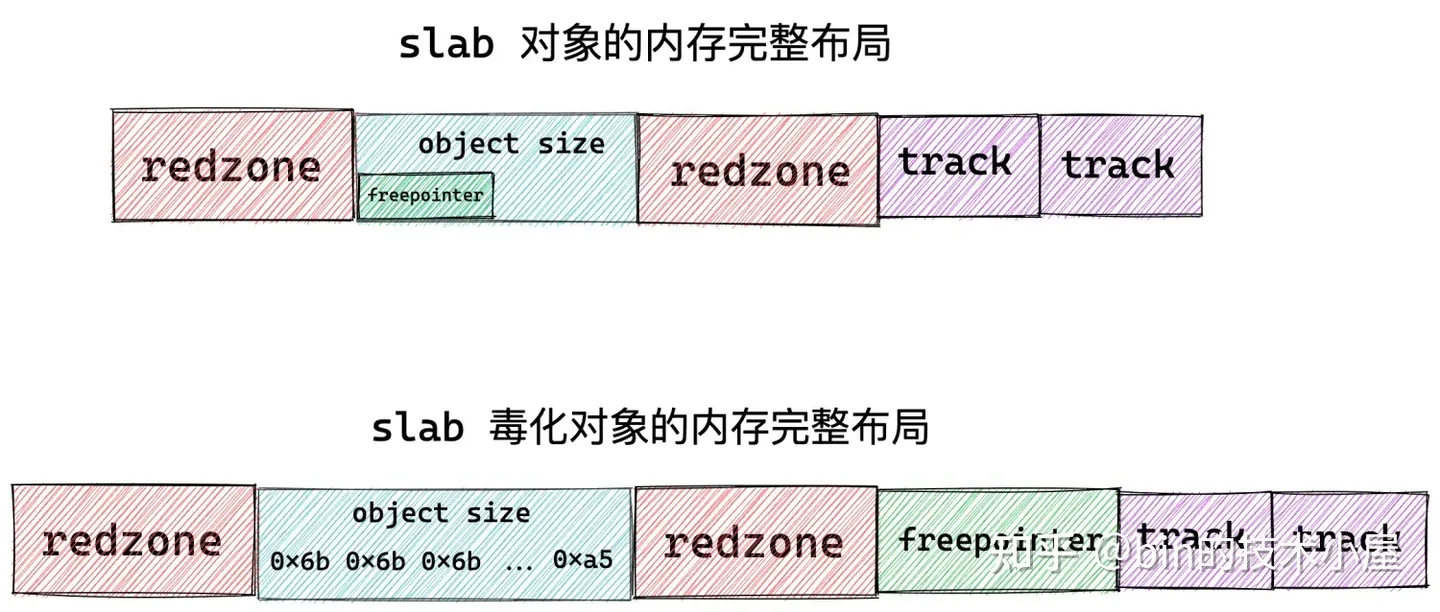
在有了新的記憶體佈局之後,我們接下來就要考慮一個問題,當我們向 slab 對象池獲取到一個空閑對象之後,我們需要知道它的下一個空閑對象在哪裡,這樣方便我們下次獲取對象。那麼我們該如何將記憶體頁 page 中的這些空閑對象串聯起來呢?
有讀者朋友可能會說了,這很簡單啊,用一個鏈表把這些空閑對象串聯起來不就行了嘛,其實內核也是這樣想的,哈哈。不過內核巧妙的地方在於不需要為串聯對象所用到的 next 指針額外的分配記憶體空間。
因為對象在 slab 中沒有被分配出去使用的時候,其實對象所占的記憶體中存放什麼,用戶根本不會關心的。既然這樣,內核乾脆就把指向下一個空閑對象的 freepointer 指針直接存放在對象所占記憶體(object size)中,這樣避免了為 freepointer 指針單獨再分配記憶體空間。巧妙的利用了對象所在的記憶體空間(object size)。

我們接著對 slab 記憶體佈局進行演化,有時候我們期望知道 slab 對象池中各個對象的狀態,比如是否處於空閑狀態。那麼對象的狀態我們在哪裡存儲呢?
答案還是和 freepointer 的處理方式一樣,巧妙的利用對象所在的記憶體空間(object size)。內核會在對象所占的記憶體空間中填充一些特殊的字元用來表示對象的不同狀態。因為反正對象沒有被分配出去使用,記憶體里存的是什麼都無所謂。
當 slab 剛剛從伙伴系統中申請出來,並初始化劃分物理記憶體頁中的對象記憶體空間時,內核會將對象的 object size 記憶體區域用特殊位元組 0x6b 填充,並用 0xa5 填充對象 object size 記憶體區域的最後一個位元組表示填充完畢。
或者當對象被釋放回 slab 對象池中的時候,也會用這些位元組填充對象的記憶體區域。

這種通過在對象記憶體區域填充特定位元組表示對象的特殊狀態的行為,在 slab 中有一個專門的術語叫做 SLAB_POISON (SLAB 中毒)。POISON 這個術語起的真的是只可意會不可言傳,其實就是表示 slab 對象的一種狀態。
是否毒化 slab 對象是可以設置的,當 slab 對象被 POISON 之後,那麼會有一個問題,就是我們前邊介紹的存放在對象記憶體區域 object size 里的 freepointer 就被會特殊位元組 0x6b 覆蓋掉。這種情況下,內核就只能為 freepointer 在額外分配一個 word size 大小的記憶體空間了。

slab 對象的記憶體佈局信息除了以上內容之外,有時候我們還需要去跟蹤一下對象的分配和釋放相關信息,而這些信息也需要在 slab 對象中存儲,內核中使用一個 struct track 結構體來存儲跟蹤信息。
這樣一來,slab 對象的記憶體區域中就需要在開闢出兩個 sizeof(struct track) 大小的區域出來,用來分別存儲 slab 對象的分配和釋放信息。
上圖展示的就是 slab 對象在記憶體中的完整佈局,其中 object size 為對象真正所需要的記憶體區域大小,而對象在 slab 中真實的記憶體占用大小 size 除了 object size 之外,還包括填充的 red zone 區域,以及用於跟蹤對象分配和釋放信息的 track 結構,另外,如果 slab 設置了 red zone,內核會在對象末尾增加一段 word size 大小的填充 padding 區域。
當 slab 向伙伴系統申請若幹記憶體頁之後,內核會按照這個 size 將記憶體頁劃分成一個一個的記憶體塊,記憶體塊大小為 size 。
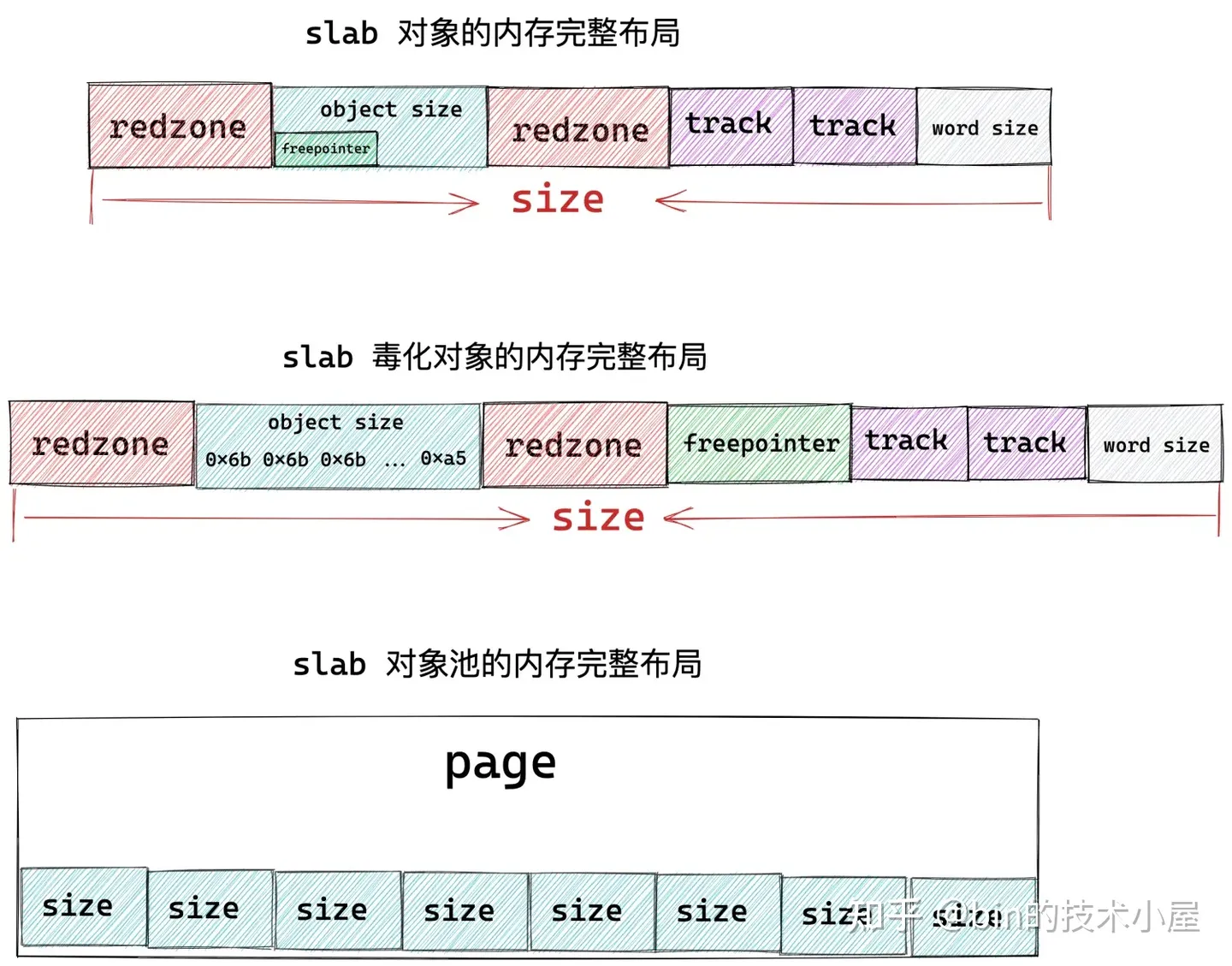
其實 slab 的本質就是一個或者多個物理記憶體頁 page,內核會根據上圖展示的 slab 對象的記憶體佈局,計算出對象的真實記憶體占用 size。最後根據這個 size 在 slab 背後依賴的這一個或者多個物理記憶體頁 page 中劃分出多個大小相同的記憶體塊出來。
所以在內核中,都是用 struct page 結構來表示 slab,如果 slab 背後依賴的是多個物理記憶體頁,那就使用在 《深度剖析 Linux 伙伴系統的設計與實現》 一文中 " 5.3.2 設置複合頁 compound_page " 小節提到的複合頁 compound_page 來表示。
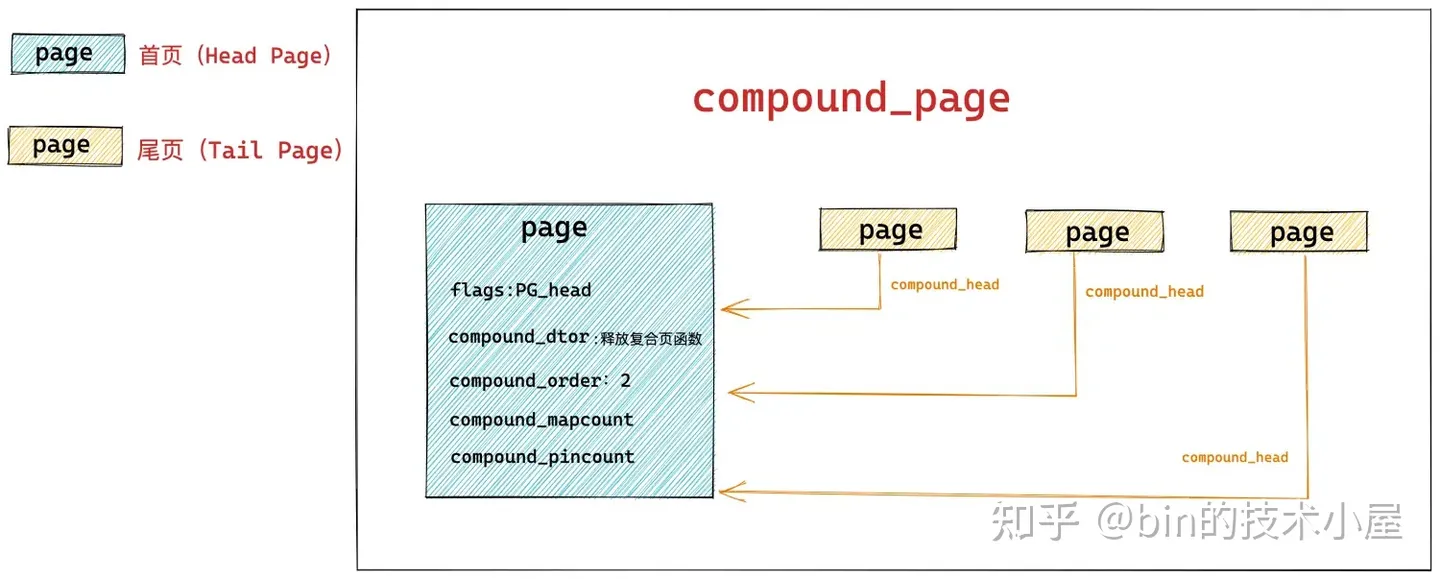
struct page {
// 首頁 page 中的 flags 會被設置為 PG_head 表示覆合頁的第一頁
unsigned long flags;
// 其餘尾頁會通過該欄位指向首頁
unsigned long compound_head;
// 用於釋放複合頁的析構函數,保存在首頁中
unsigned char compound_dtor;
// 該複合頁有多少個 page 組成,order 還是分配階的概念,在首頁中保存
// 本例中的 order = 2 表示由 4 個普通頁組成
unsigned char compound_order;
// 該複合頁被多少個進程使用,記憶體頁反向映射的概念,首頁中保存
atomic_t compound_mapcount;
// 複合頁使用計數,首頁中保存
atomic_t compound_pincount;
}
slab 的具體信息也是在 struct page 中存儲,下麵筆者提取了 struct page 結構中和 slab 相關的欄位:
struct page {
struct { /* slub 相關欄位 */
union {
// slab 所在的管理鏈表
struct list_head slab_list;
struct { /* Partial pages */
// 用 next 指針在相應管理鏈表中串聯起 slab
struct page *next;
#ifdef CONFIG_64BIT
// slab 所在管理鏈表中的包含的 slab 總數
int pages;
// slab 所在管理鏈表中包含的對象總數
int pobjects;
#else
short int pages;
short int pobjects;
#endif
};
};
// 指向 slab cache,slab cache 就是真正的對象池結構,裡邊管理了多個 slab
// 這多個 slab 被 slab cache 管理在了不同的鏈表上
struct kmem_cache *slab_cache;
// 指向 slab 中第一個空閑對象
void *freelist; /* first free object */
union {
struct { /* SLUB */
// slab 中已經分配出去的獨享
unsigned inuse:16;
// slab 中包含的對象總數
unsigned objects:15;
// 該 slab 是否在對應 slab cache 的本地 CPU 緩存中
// frozen = 1 表示緩存再本地 cpu 緩存中
unsigned frozen:1;
};
};
};
}
在筆者當前所在的內核版本 5.4 中,內核是使用 struct page 來表示 slab 的,但是考慮到 struct page 結構已經非常龐大且複雜,為了減少 struct page 的記憶體占用以及提高可讀性,內核在 5.17 版本中專門為 slab 引入了一個管理結構 struct slab,將原有 struct page 中 slab 相關的欄位全部刪除,轉移到了 struct slab 結構中。這一點,大家只做瞭解即可。
6. slab 的總體架構設計
在上一小節的內容中,筆者帶大家從 slab 的微觀層面詳細的介紹了 slab 對象的記憶體佈局,首先 slab 會從伙伴系統中申請一個或多個物理記憶體頁 page,然後根據 slab 對象的記憶體佈局計算出對象在記憶體中的真實尺寸 size,並根據這個 size,在物理記憶體頁中劃分出多個記憶體塊出來,供內核申請使用。
有了這個基礎之後,在本小節中,筆者將繼續帶大家從 slab 的巨集觀層面上繼續深入 slab 的架構設計。
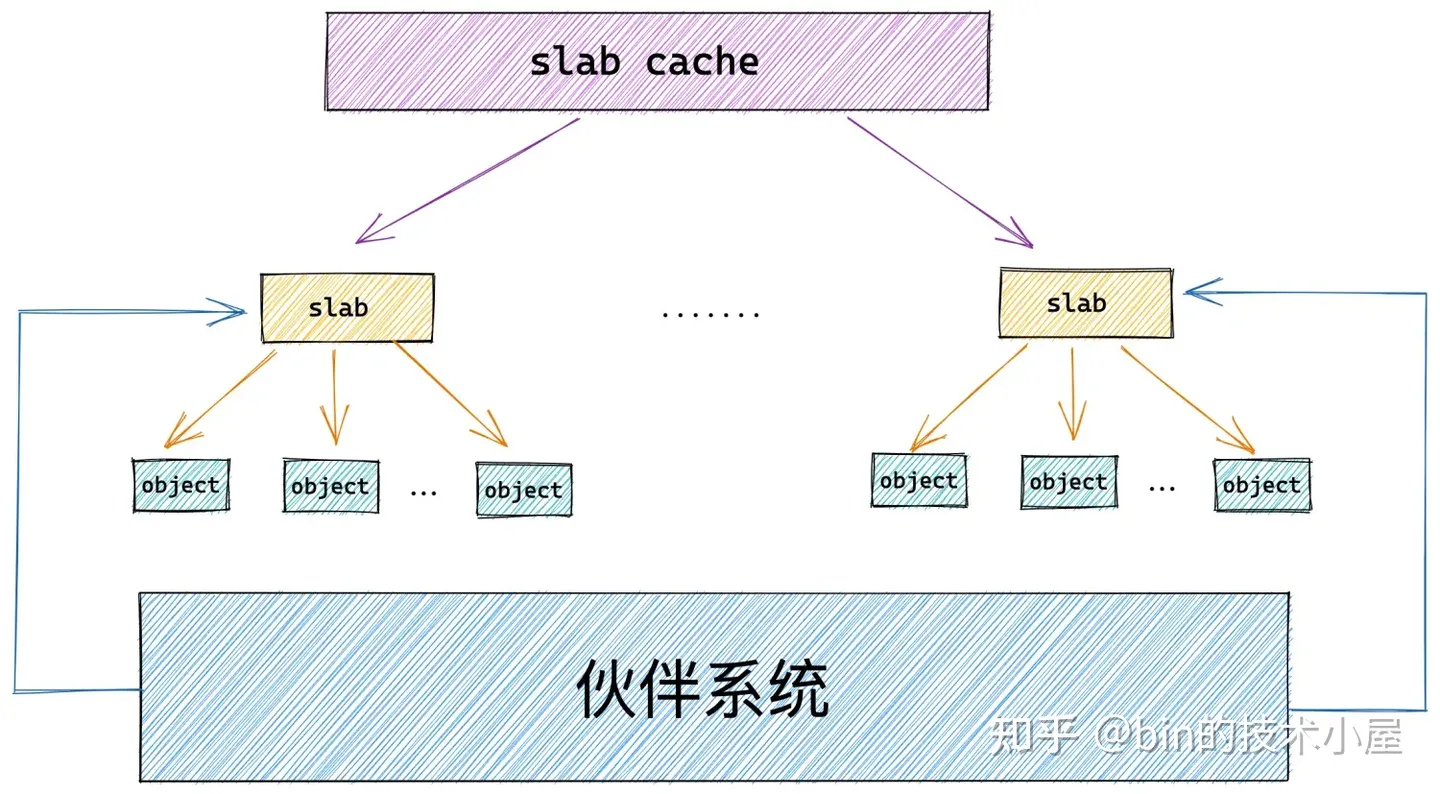
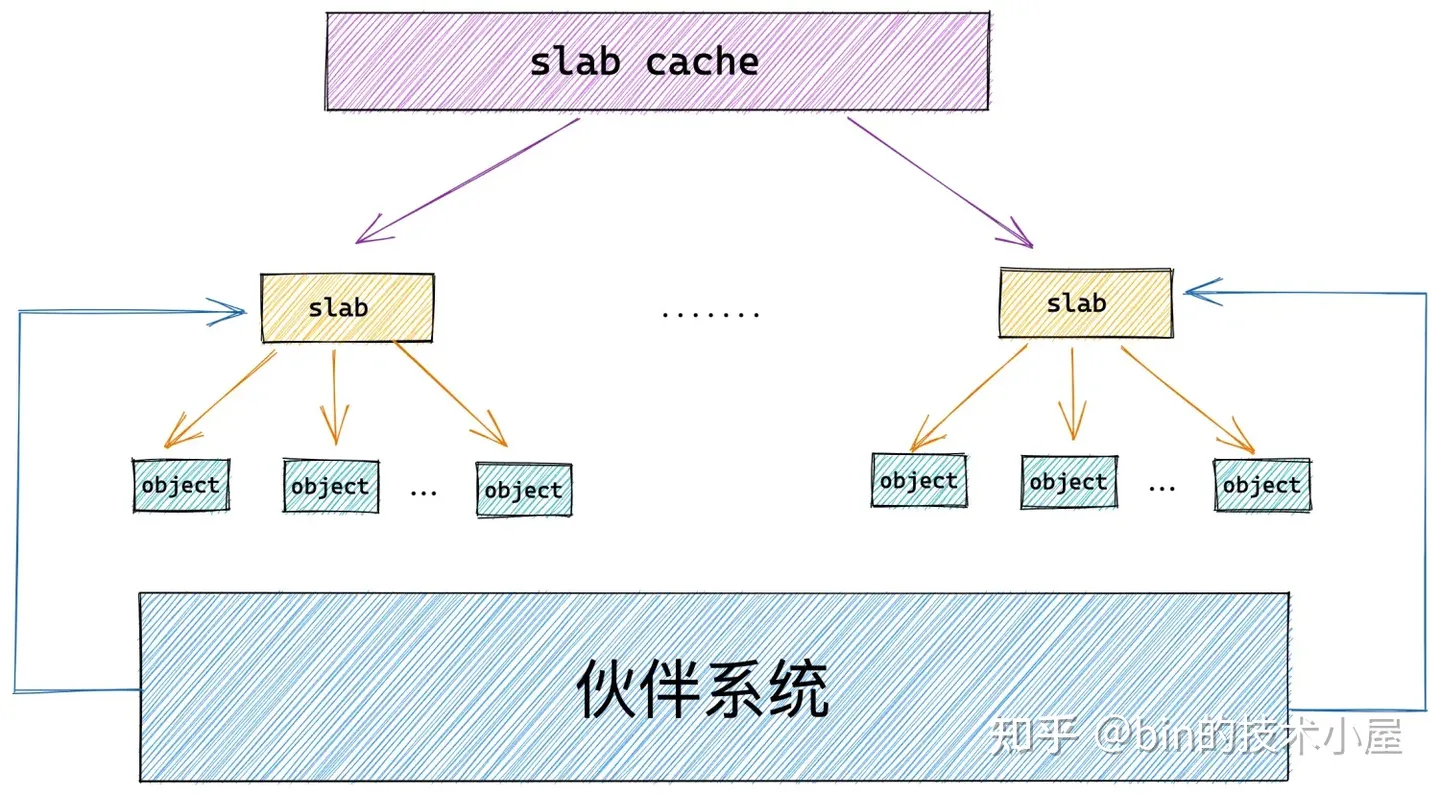
筆者在前邊的內容中多次提及的 slab 對象池其實就是上圖中的 slab cache,而上小節中介紹的 slab 只是 slab cache 架構體系中的基本單位,對象的分配和釋放最終會落在 slab 這個基本單位上。
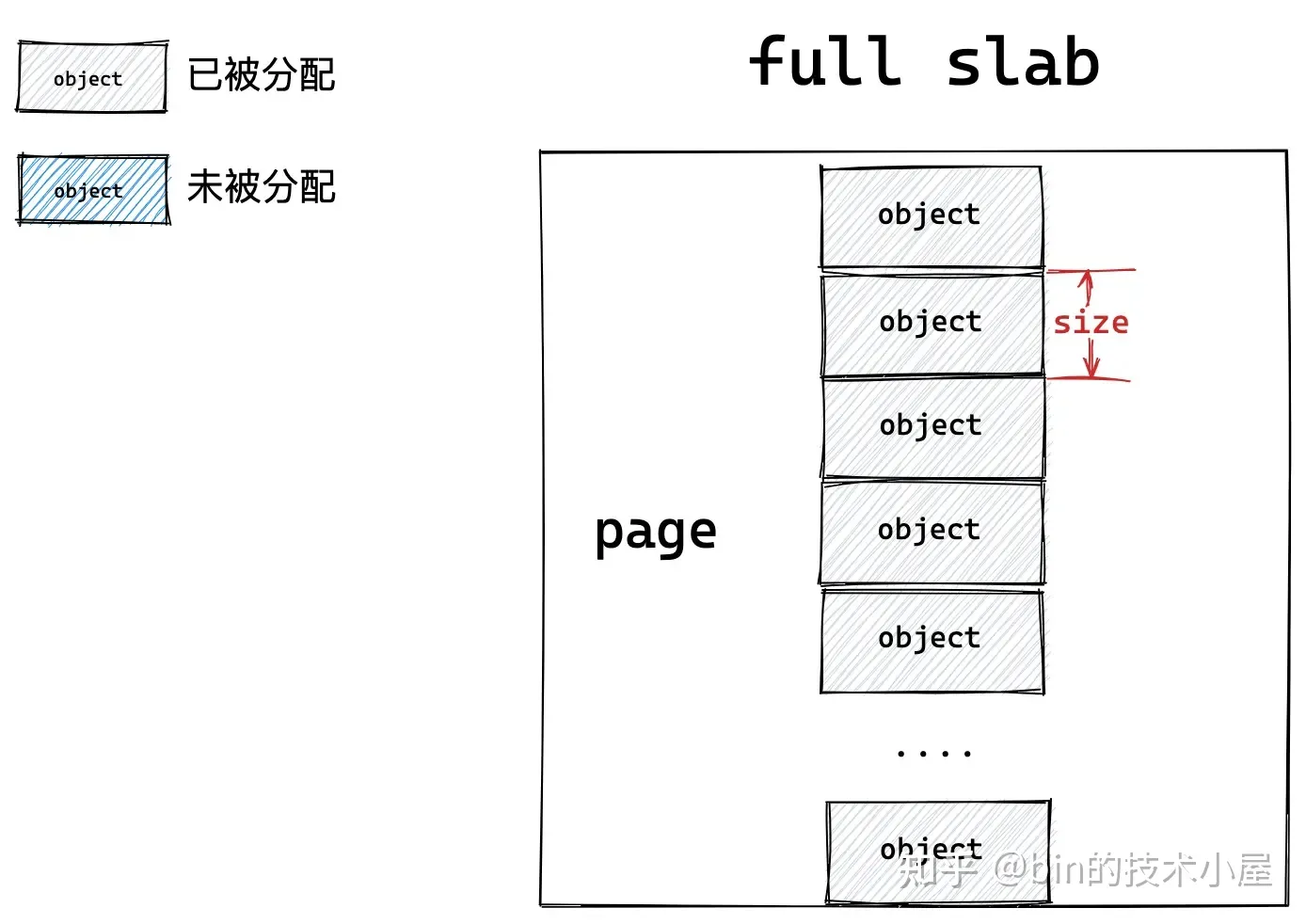
如果一個 slab 中的對象全部分配出去了,slab cache 就會將其視為一個 full slab,表示這個 slab 此刻已經滿了,無法在分配對象了。slab cache 就會到伙伴系統中重新申請一個 slab 出來,供後續的記憶體分配使用。
當內核將對象釋放回其所屬的 slab 之後,如果 slab 中的對象全部歸位,slab cache 就會將其視為一個 empty slab,表示 slab 此刻變為了一個完全空閑的 slab。如果超過了 slab cache 中規定的 empty slab 的閾值,slab cache 就會將這些空閑的 empty slab 重新釋放回伙伴系統中。

如果一個 slab 中的對象部分被分配出去使用,部分卻未被分配仍然在 slab 中緩存,那麼內核就會將該 slab 視為一個 partial slab。
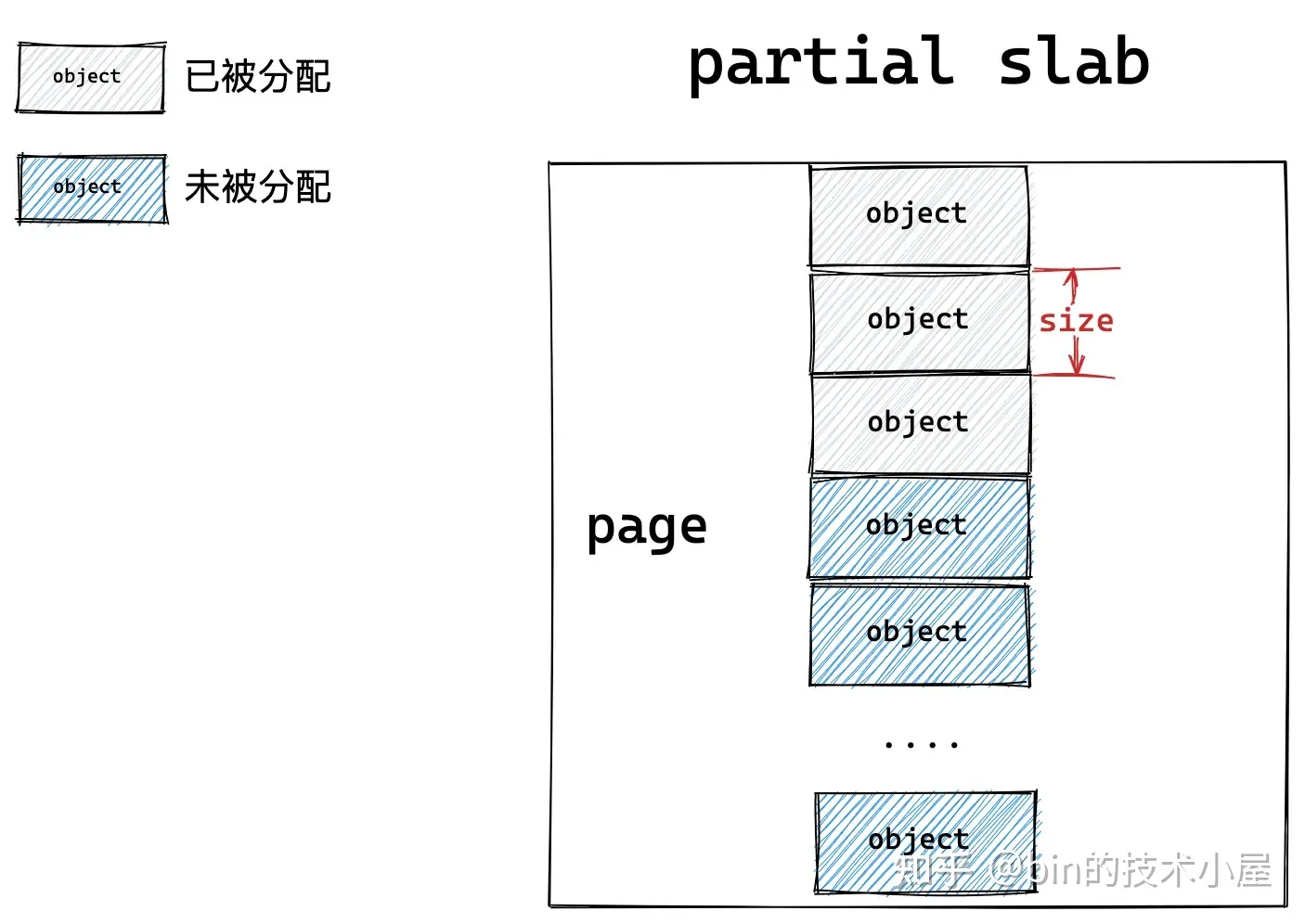
這些不同狀態的 slab,會在 slab cache 中被不同的鏈表所管理,同時 slab cache 會控制管理鏈表中 slab 的個數以及鏈表中所緩存的空閑對象個數,防止它們無限制的增長。
slab cache 中除了需要管理眾多的 slab 之外,還包括了很多 slab 的基礎信息。比如:
-
上小節中提到的 slab 對象記憶體佈局相關的信息
-
slab 中的對象需要按照什麼方式進行記憶體對齊,比如,按照 CPU 硬體高速緩存行 cache line (64 位元組) 進行對齊,slab 對象是否需要進行毒化 POISON,是否需要在 slab 對象記憶體周圍插入 red zone,是否需要追蹤 slab 對象的分配與回收信息,等等。
-
一個 slab 具體到底需要多少個物理記憶體頁 page,一個 slab 中具體能夠容納多少個 object (記憶體塊)。
6.1 slab 的基礎信息管理
slab cache 在內核中的數據結構為 struct kmem_cache,以上介紹的這些 slab 的基本信息以及 slab 的管理結構全部定義在該結構體中:
/*
* Slab cache management.
*/
struct kmem_cache {
// slab cache 的管理標誌位,用於設置 slab 的一些特性
// 比如:slab 中的對象按照什麼方式對齊,對象是否需要 POISON 毒化,是否插入 red zone 在對象記憶體周圍,是否追蹤對象的分配和釋放信息 等等
slab_flags_t flags;
// slab 對象在記憶體中的真實占用,包括為了記憶體對齊填充的位元組數,red zone 等等
unsigned int size; /* The size of an object including metadata */
// slab 中對象的實際大小,不包含填充的位元組數
unsigned int object_size;/* The size of an object without metadata */
// slab 對象池中的對象在沒有被分配之前,我們是不關心對象裡邊存儲的內容的。
// 內核巧妙的利用對象占用的記憶體空間存儲下一個空閑對象的地址。
// offset 表示用於存儲下一個空閑對象指針的位置距離對象首地址的偏移
unsigned int offset; /* Free pointer offset */
// 表示 cache 中的 slab 大小,包括 slab 所需要申請的頁面個數,以及所包含的對象個數
// 其中低 16 位表示一個 slab 中所包含的對象總數,高 16 位表示一個 slab 所占有的記憶體頁個數。
struct kmem_cache_order_objects oo;
// slab 中所能包含對象以及記憶體頁個數的最大值
struct kmem_cache_order_objects max;
// 當按照 oo 的尺寸為 slab 申請記憶體時,如果記憶體緊張,會採用 min 的尺寸為 slab 申請記憶體,可以容納一個對象即可。
struct kmem_cache_order_objects min;
// 向伙伴系統申請記憶體時使用的記憶體分配標識
gfp_t allocflags;
// slab cache 的引用計數,為 0 時就可以銷毀並釋放記憶體回伙伴系統重
int refcount;
// 池化對象的構造函數,用於創建 slab 對象池中的對象
void (*ctor)(void *);
// 對象的 object_size 按照 word 字長對齊之後的大小
unsigned int inuse;
// 對象按照指定的 align 進行對齊
unsigned int align;
// slab cache 的名稱, 也就是在 slabinfo 命令中 name 那一列
const char *name;
};
slab_flags_t flags 是 slab cache 的管理標誌位,用於設置 slab 的一些特性,比如:
- 當 flags 設置了 SLAB_HWCACHE_ALIGN 時,表示 slab 中的對象需要按照 CPU 硬體高速緩存行 cache line (64 位元組) 進行對齊。
- 當 flags 設置了 SLAB_POISON 時,表示需要在 slab 對象記憶體中填充特殊位元組 0x6b 和 0xa5,表示對象的特定狀態。

-
當 flags 設置了 SLAB_RED_ZONE 時,表示需要在 slab 對象記憶體周圍插入 red zone,防止記憶體的讀寫越界。
-
當 flags 設置了 SLAB_CACHE_DMA 或者 SLAB_CACHE_DMA32 時,表示指定 slab 中的記憶體來自於哪個記憶體區域,DMA or DMA32 區域 ?如果沒有特殊指定,slab 中的記憶體一般來自於 NORMAL 直接映射區域。
- 當 flags 設置了 SLAB_STORE_USER 時,表示需要追蹤對象的分配和釋放相關信息,這樣會在 slab 對象記憶體區域中額外增加兩個
sizeof(struct track)大小的區域出來,用於存儲 slab 對象的分配和釋放信息。
相關 slab cache 的標誌位 flag,定義在內核文件 /include/linux/slab.h 中:
/* DEBUG: Red zone objs in a cache */
#define SLAB_RED_ZONE ((slab_flags_t __force)0x00000400U)
/* DEBUG: Poison objects */
#define SLAB_POISON ((slab_flags_t __force)0x00000800U)
/* Align objs on cache lines */
#define SLAB_HWCACHE_ALIGN ((slab_flags_t __force)0x00002000U)
/* Use GFP_DMA memory */
#define SLAB_CACHE_DMA ((slab_flags_t __force)0x00004000U)
/* Use GFP_DMA32 memory */
#define SLAB_CACHE_DMA32 ((slab_flags_t __force)0x00008000U)
/* DEBUG: Store the last owner for bug hunting */
#define SLAB_STORE_USER
struct kmem_cache 結構中的 size 欄位表示 slab 對象在記憶體中的真實占用大小,該大小包括對象所占記憶體中各種填充的記憶體區域大小,比如下圖中的 red zone,track 區域,等等。

unsigned int object_size 表示單純的存儲 slab 對象所需要的實際記憶體大小,如上圖中的 object size 藍色區域所示。
在上小節我們介紹 freepointer 指針的時候提到過,當對象在 slab 中緩存並沒有被分配出去之前,其實對象所占記憶體中存儲的是什麼,用戶根本不會去關心。內核會巧妙的利用對象的記憶體空間來存儲 freepointer 指針,用於指向 slab 中的下一個空閑對象。
但是當 kmem_cache 結構中的 flags 設置了 SLAB_POISON 標誌位之後,slab 中的對象會 POISON 毒化,被特殊位元組 0x6b 和 0xa5 所填充,這樣一來就會覆蓋原有的 freepointer,在這種情況下,內核就需要把 freepointer 存儲在對象所在記憶體區域的外面。
所以內核就需要用一個欄位來標識 freepointer 的位置,struct kmem_cache 結構中的 unsigned int offset 欄位乾的就是這個事情,它表示對象的 freepointer 指針距離對象的起始記憶體地址的偏移 offset。
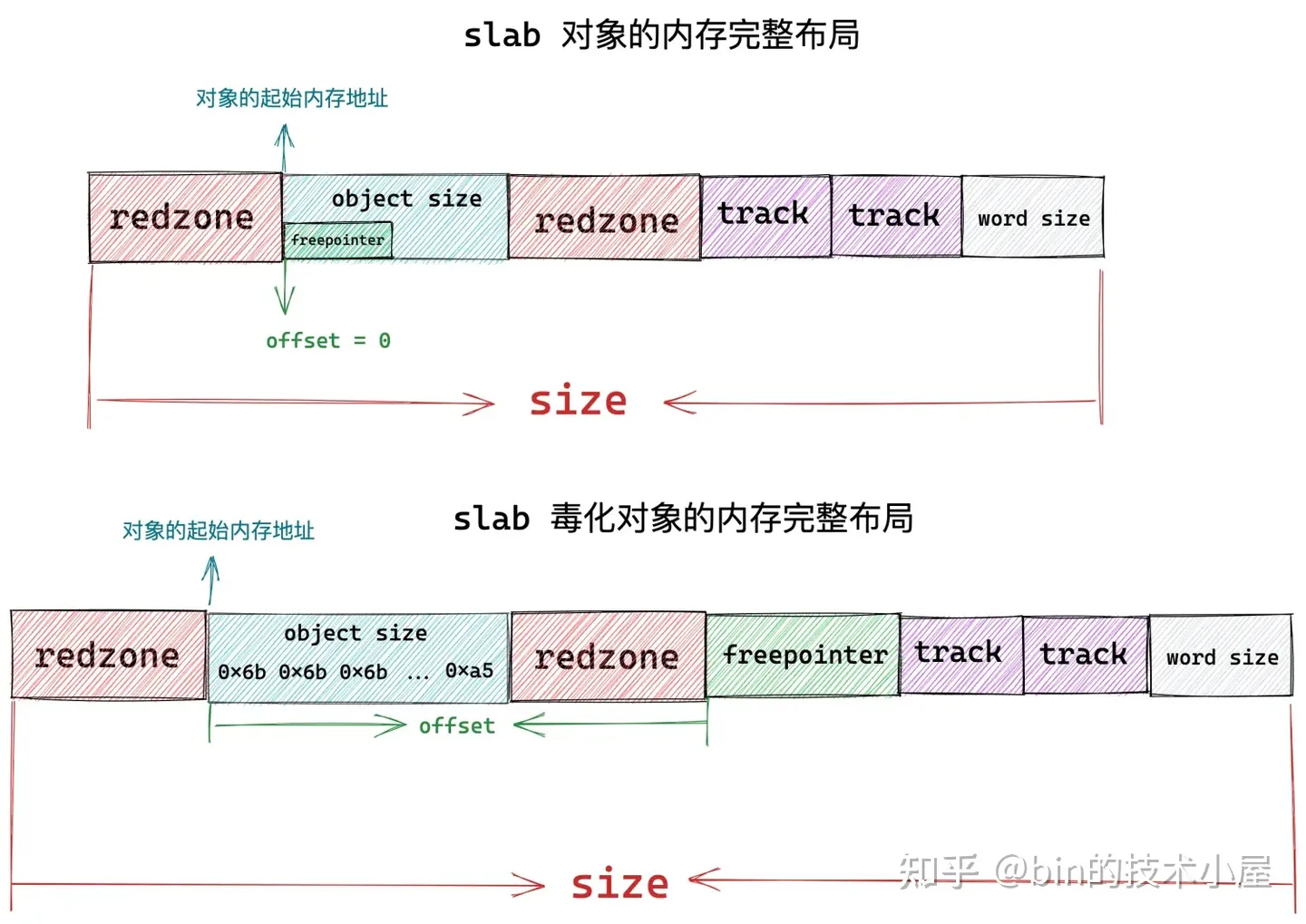
上小節中,我們也提到過,slab 的本質其實就是一個或者多個物理記憶體頁,slab 在內核中的結構也是用 struct page 來表示的,那麼一個 slab 中到底包含多少個記憶體頁 ? 這些記憶體頁中到底能容納多少個記憶體塊(object)呢?
struct kmem_cache_order_objects oo 欄位就是保存這些信息的,struct kmem_cache_order_objects 結構體其實就是一個無符號的整形欄位,它的高 16 位用來存儲 slab 所需的物理記憶體頁個數,低 16 位用來存儲 slab 所能容納的對象總數。
struct kmem_cache_order_objects {
// 高 16 為存儲 slab 所需的記憶體頁個數,低 16 為存儲 slab 所能包含的對象總數
unsigned int x;
};
struct kmem_cache_order_objects max 欄位表示 oo 的最大值,內核在初始化 slab 的時候,會將 max 的值設置為 oo。
struct kmem_cache_order_objects min 欄位表示 slab 中至少需要容納的對象個數以及容納最少的對象所需要的記憶體頁個數。內核在初始化 slab 的時候會 將 min 的值設置為至少需要容納一個對象。
內核在創建 slab 的時候,最開始會按照 oo 指定的尺寸來向伙伴系統申請記憶體頁,如果記憶體緊張,申請記憶體失敗。那麼內核會降級採用 min 的尺寸再次向伙伴系統申請記憶體。也就是說 slab 中至少會包含一個對象。
gfp_t allocflags 是內核在向伙伴系統為 slab 申請記憶體頁的時候,所用到的記憶體分配標誌位,感興趣的朋友可以回看下 《深入理解 Linux 物理記憶體分配全鏈路實現》 一文中的 “ 2.規範物理記憶體分配行為的掩碼 gfp_mask ” 小節中的內容,那裡有非常詳細的介紹。
unsigned int inuse 表示對象的 object size 按照 word size 對齊之後的大小,如果我們設置了SLAB_RED_ZONE,inuse 也會包括對象右側 red zone 區域的大小。
unsigned int align 在創建 slab cache 的時候,我們可以向內核指定 slab 中的對象按照 align 的值進行對齊,內核會綜合 word size , cache line ,align 計算出一個合理的對齊尺寸。
const char *name 表示該 slab cache 的名稱,這裡指定的 name 將會在 cat /proc/slabinfo 命令中顯示,該命令用於查看系統中所有 slab cache 的信息。
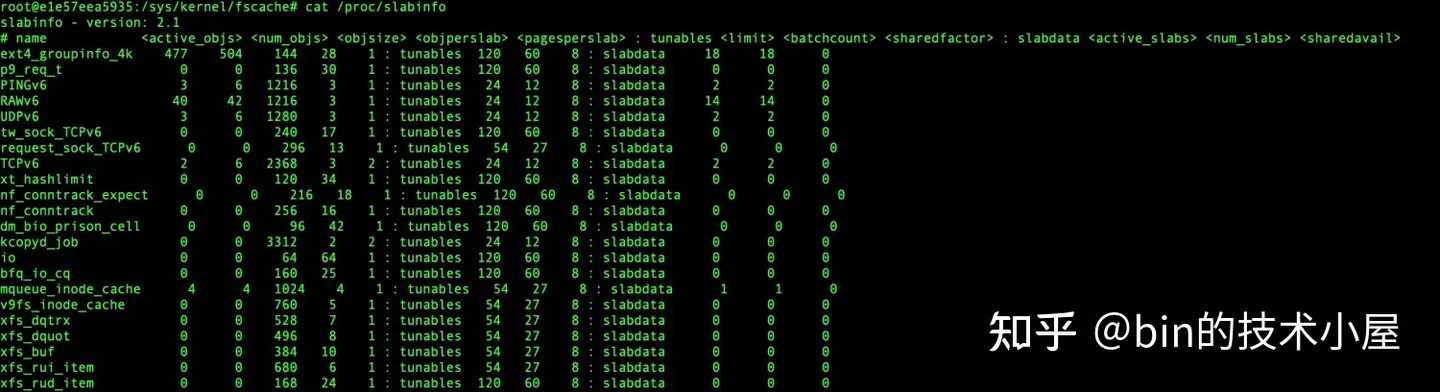
cat /proc/slabinfo 命令的顯示結構主要由三部分組成:
-
statistics 部分顯示的是 slab cache 的基本統計信息,這部分是我們最常用的,下麵是每一列的含義:
- active_objs 表示 slab cache 中已經被分配出去的對象個數
- num_objs 表示 slab cache 中容納的對象總數
- objsize 表示 slab 中對象的 object size ,單位為位元組
- objperslab 表示 slab 中可以容納的對象個數
- pagesperslab 表示 slab 所需要的物理記憶體頁個數
-
tunables 部分顯示的 slab cache 的動態可調節參數,如果我們採用的 slub 實現,那麼 tunables 部分全是 0 ,
/proc/slabinfo文件不可寫,無法動態修改相關參數。如果我們使用的 slab 實現的話,可以通過# echo 'name limit batchcount sharedfactor' > /proc/slabinfo命令動態修改相關參數。命令中指定的 name 就是 kmem_cache 結構中的 name 屬性。tunables 這部分顯示的信息均是 slab 實現中的相關欄位,大家只做簡單瞭解即可,與我們本文主題 slub 的實現沒有關係。- limit 表示在 slab 的實現中,slab cache 的 cpu 本地緩存 array_cache 最大可以容納的對象個數
- batchcount 表示當 array_cache 中緩存的對象不夠時,需要一次性填充的空閑對象個數。
-
slabdata 部分顯示的 slab cache 的總體信息,其中 active_slabs 一列展示的 slab cache 中活躍的 slab 個數。nums_slabs 一列展示的是 slab cache 中管理的 slab 總數
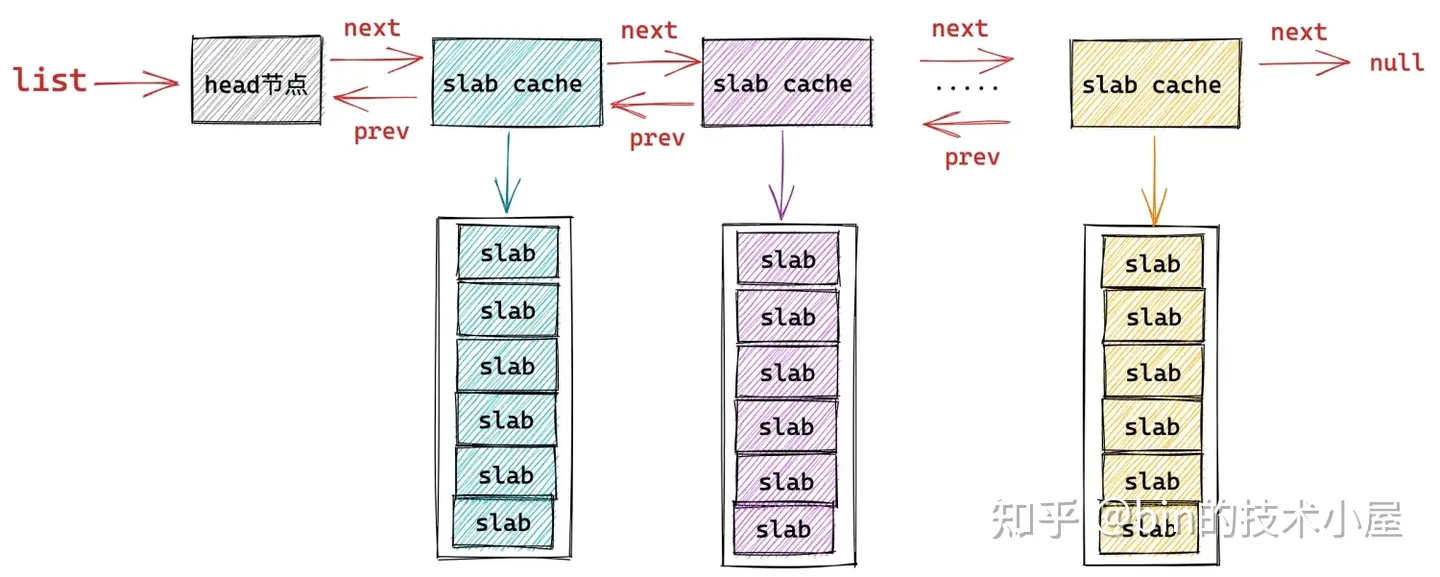
在 cat /proc/slabinfo 命令顯示的這些系統中所有的 slab cache,內核會將這些 slab cache 用一個雙向鏈表統一串聯起來。鏈表的頭結點指針保存在 struct kmem_cache 結構的 list 中。
struct kmem_cache {
// 用於組織串聯繫統中所有類型的 slab cache
struct list_head list; /* List of slab caches */
}
系統中所有的這些 slab cache 占用的記憶體總量,我們可以通過 cat /proc/meminfo 命令查看:
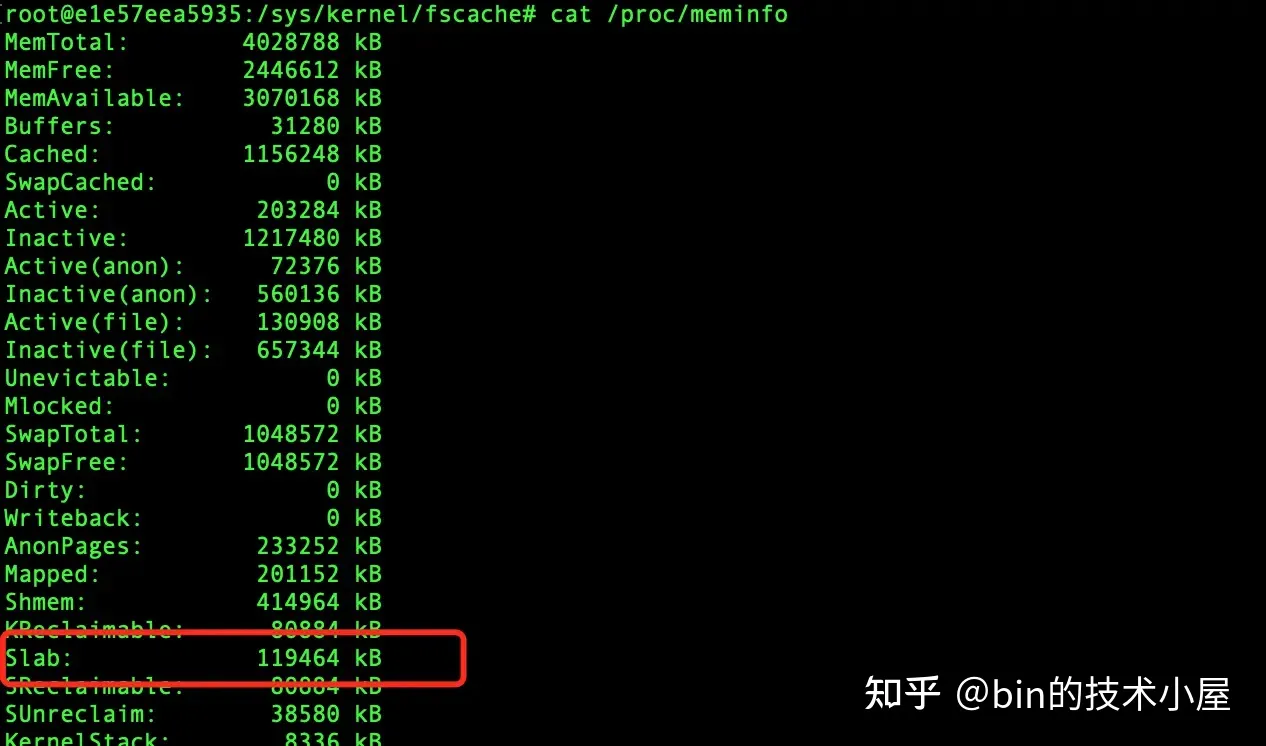
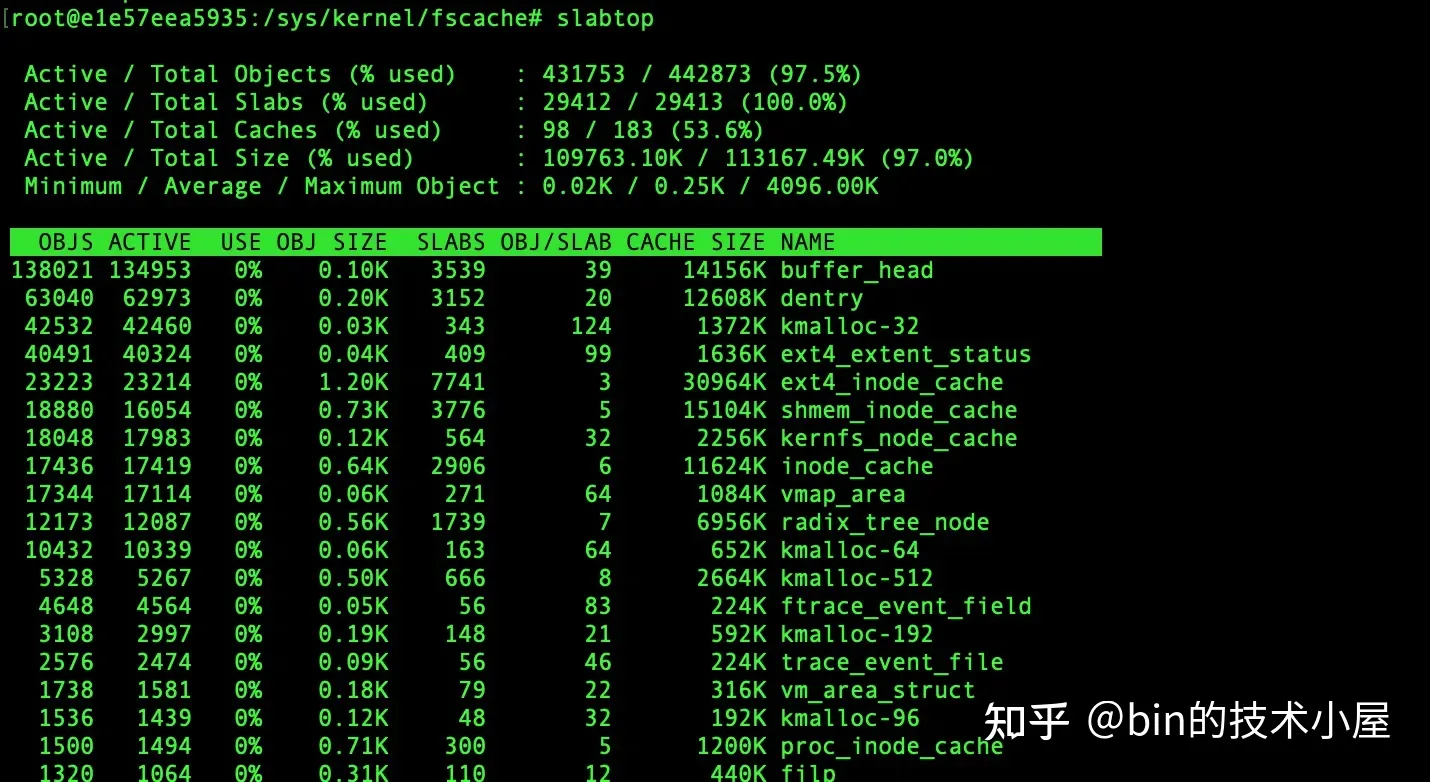
除此之外,我們還可以通過 slabtop 命令來動態查看系統中占用記憶體最高的 slab cache,當記憶體緊張的時候,如果我們通過 cat /proc/meminfo 命令發現 slab 的記憶體占用較高的話,那麼可以快速通過 slabtop 迅速定位到究竟是哪一類的 object 分配過多導致記憶體占用飆升。
6.2 slab 的組織架構
在上小節的內容中,筆者主要為大家介紹了 struct kmem_cache 結構中關於 slab 的一些基礎信息,其中主要包括 slab cache 中所管理的 slabs 相關的容量控制,以及 slab 中對象的記憶體佈局信息。
那麼 slab cache 中的這些 slabs 是如何被組織管理的呢 ?在本小節中,筆者將為大家揭開這個謎底。
slab cache 其實就是內核中的一個對象池,而關於對象池的設計,筆者在之前的文章 《詳解 Recycler 對象池的精妙設計與實現》 中詳細的介紹過 Netty 關於對象池這塊的設計,其中用了大量的篇幅重點著墨了多線程無鎖化設計。
內核在對 slab cache 的設計也是一樣,也充分考慮了多進程併發訪問 slab cache 所帶來的同步性能開銷,內核在 slab cache 的設計中為每個 cpu 引入了 struct kmem_cache_cpu 結構的 percpu 變數,作為 slab cache 在每個 cpu 中的本地緩存。
/*
* Slab cache management.
*/
struct kmem_cache {
// 每個 cpu 擁有一個本地緩存,用於無鎖化快速分配釋放對象
struct kmem_cache_cpu __percpu *cpu_slab;
}
這樣一來,當進程需要向 slab cache 申請對應的記憶體塊(object)時,首先會直接來到 kmem_cache_cpu 中查看 cpu 本地緩存的 slab,如果本地緩存的 slab 中有空閑對象,那麼就直接返回了,整個過程完全沒有加鎖。而且訪問路徑特別短,防止了對 CPU 硬體高速緩存 L1Cache 中的 Instruction Cache(指令高速緩存)污染。
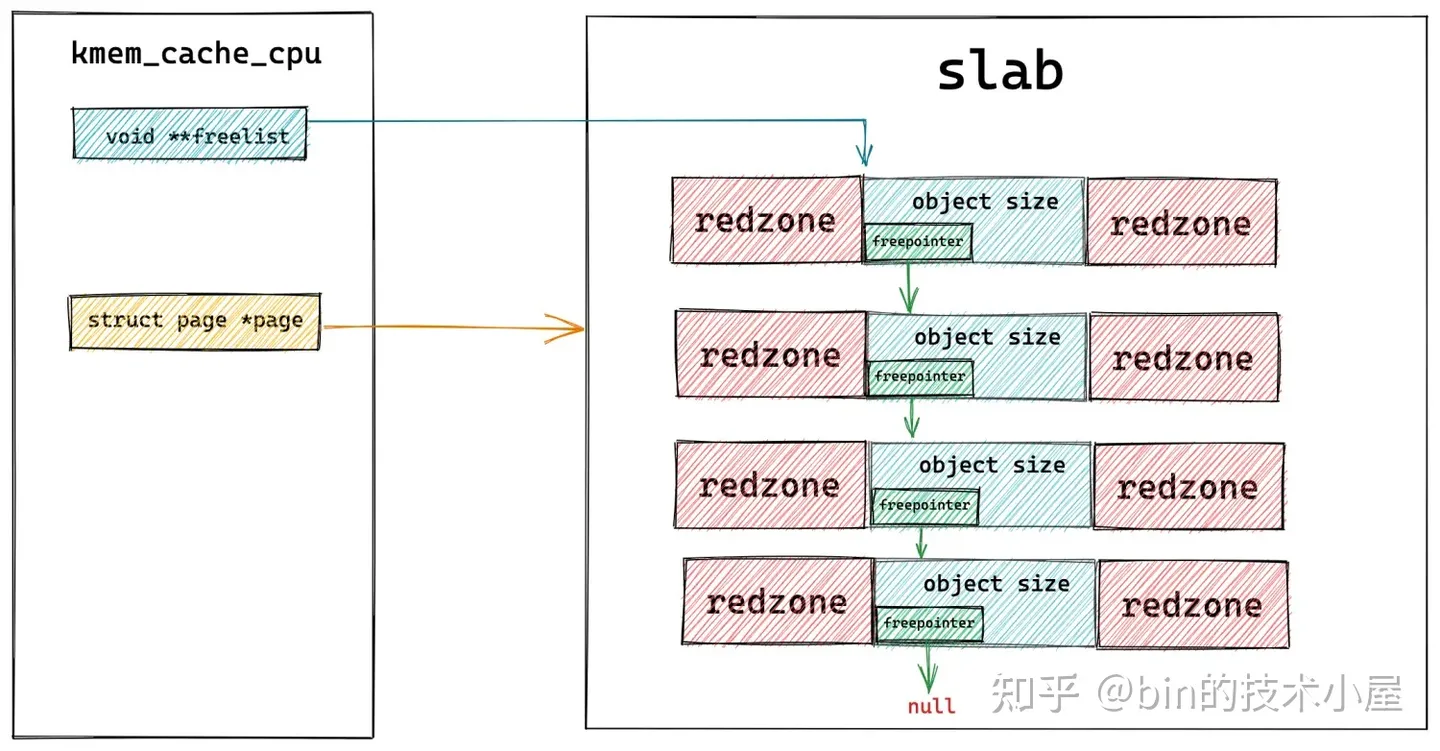
下麵我們來看一下 slab cache 它的 cpu 本地緩存 kmem_cache_cpu 結構的詳細設計細節:
struct kmem_cache_cpu {
// 指向被 CPU 本地緩存的 slab 中第一個空閑的對象
void **freelist; /* Pointer to next available object */
// 保證進程在 slab cache 中獲取到的 cpu 本地緩存 kmem_cache_cpu 與當前執行進程的 cpu 是一致的。
unsigned long tid; /* Globally unique transaction id */
// slab cache 中 CPU 本地所緩存的 slab,由於 slab 底層的存儲結構是記憶體頁 page
// 所以這裡直接用記憶體頁 page 表示 slab
struct page *page; /* The slab from which we are allocating */
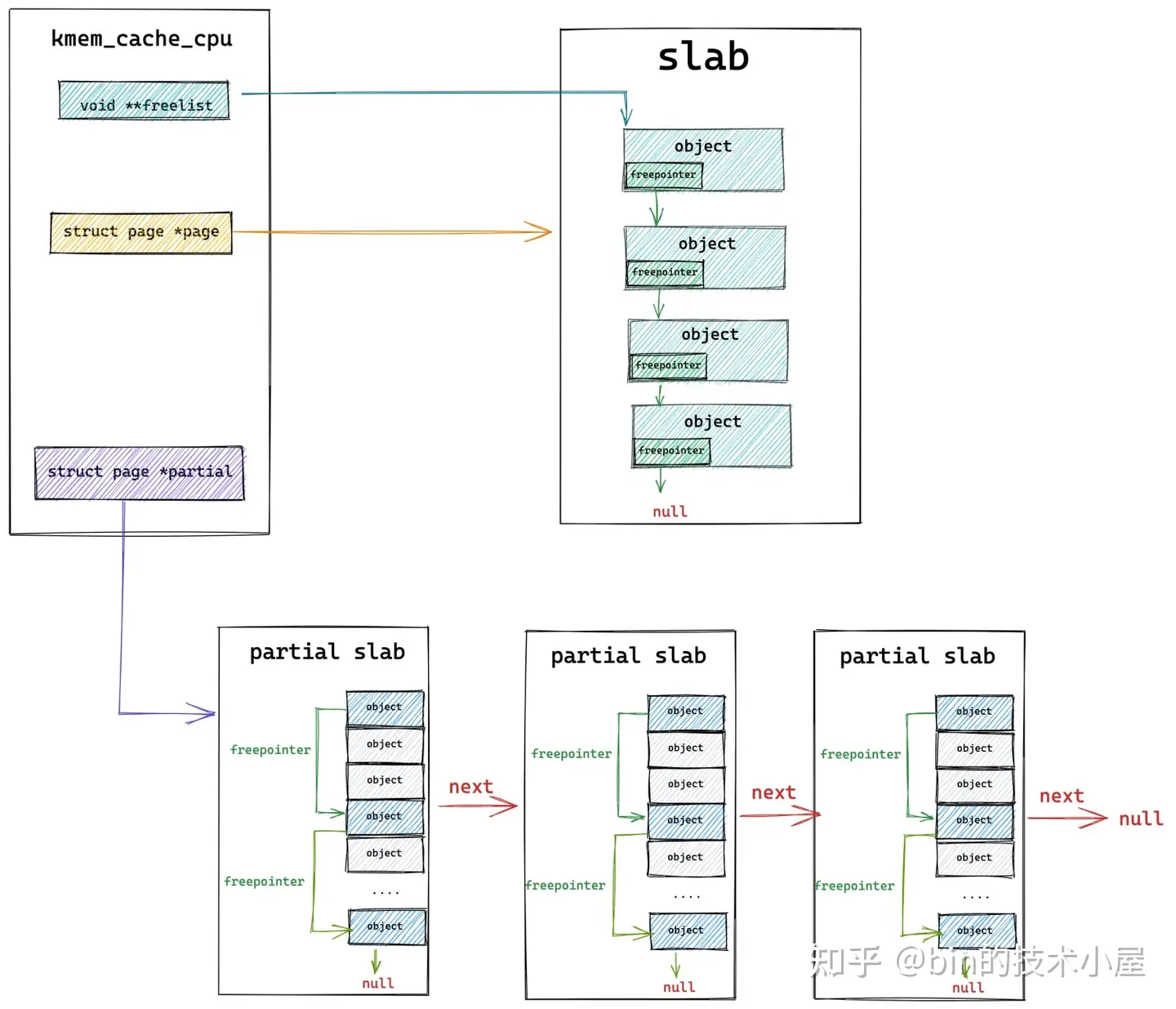
#ifdef CONFIG_SLUB_CPU_PARTIAL
// cpu cache 緩存的備用 slab 列表,同樣也是用 page 表示
// 當被本地 cpu 緩存的 slab 中沒有空閑對象時,內核會從 partial 列表中的 slab 中查找空閑對象
struct page *partial; /* Partially allocated frozen slabs */
#endif
#ifdef CONFIG_SLUB_STATS
// 記錄 slab 分配對象的一些狀態信息
unsigned stat[NR_SLUB_STAT_ITEMS];
#endif
};
在本文 《5. 從一個簡單的記憶體頁開始聊 Slab》小節後面的內容介紹中,我們知道,slab 在內核中是用 struct page 結構來描述的,這裡 struct kmem_cache_cpu 結構中的 page 指針指向的就是被 cpu 本地緩存的 slab。
freelist 指針指向的是該 slab 中第一個空閑的對象,在本文第五小節介紹 slab 對象記憶體佈局的內容中,筆者提到過,為了充分利用 slab 對象所占用的記憶體,內核會在對象占用記憶體區域內開闢一塊區域來存放 freepointer 指針,而 freepointer 可以用來指向下一個空閑對象。
這樣一來,通過這裡的 freelist 和 freepointer 就將 slab 中所有的空閑對象串聯了起來。
事實上,在 struct page 結構中也有一個 freelist 指針,用於指向該記憶體頁中第一個空閑對象。當 slab 被緩存進 kmem_cache_cpu 中之後,page 結構中的 freelist 會賦值給 kmem_cache_cpu->freelist,然後 page->freelist 會置空。page 的 frozen 狀態設置為1,表示 slab 在本地 cpu 中緩存。
struct page {
// 指向記憶體頁中第一個空閑對象
void *freelist; /* first free object */
// 該 slab 是否在對應 slab cache 的本地 CPU 緩存中
// frozen = 1 表示緩存再本地 cpu 緩存中
unsigned frozen:1;
}
kmem_cache_cpu 結構中的 tid 是內核為 slab cache 的 cpu 本地緩存結構設置的一個全局唯一的 transaction id ,這個 tid 在 slab cache 分配記憶體塊的時候主要有兩個作用:
-
內核會將 slab cache 每一次分配記憶體塊或者釋放記憶體塊的過程視為一個事物,所以在每次向 slab cache 申請記憶體塊或者將記憶體塊釋放回 slab cache 之後,內核都會改變這裡的 tid。
-
tid 也可以簡單看做是 cpu 的一個編號,每個 cpu 的 tid 都不相同,可以用來標識區分不同 cpu 的本地緩存 kmem_cache_cpu 結構。
其中 tid 的第二個作用是最主要的,因為進程可能在執行的過程中被更高優先順序的進程搶占 cpu (開啟 CONFIG_PREEMPT 允許內核搶占)或者被中斷,隨後進程可能會被內核重新調度到其他 cpu 上執行,這樣一來,進程在被搶占之前獲取到的 kmem_cache_cpu 就與當前執行進程 cpu 的 kmem_cache_cpu 不一致了。
所以在內核中,我們經常會看到如下的代碼片段,目的就是為了保證進程在 slab cache 中獲取到的 cpu 本地緩存 kmem_cache_cpu 與當前執行進程的 cpu 是一致的。
do {
// 獲取執行當前進程的 cpu 中的 tid 欄位
tid = this_cpu_read(s->cpu_slab->tid);
// 獲取 cpu 本地緩存 cpu_slab
c = raw_cpu_ptr(s->cpu_slab);
// 如果兩者的 tid 欄位不一致,說明進程已經被調度到其他 cpu 上了
// 需要再次獲取正確的 cpu 本地緩存
} while (IS_ENABLED(CONFIG_PREEMPT) &&
unlikely(tid != READ_ONCE(c->tid)));
如果開啟了 CONFIG_SLUB_CPU_PARTIAL 配置項,那麼在 slab cache 的 cpu 本地緩存 kmem_cache_cpu 結構中就會多出一個 partial 列表,partial 列表中存放的都是 partial slub,相當於是 cpu 緩存的備用選擇.
當 kmem_cache_cpu->page (被本地 cpu 所緩存的 slab)中的對象已經全部分配出去之後,內核會到 partial 列表中查找一個 partial slab 出來,並從這個 partial slab 中分配一個對象出來,最後將 kmem_cache_cpu->page 指向這個 partial slab,作為新的 cpu 本地緩存 slab。這樣一來,下次分配對象的時候,就可以直接從 cpu 本地緩存中獲取了。
如果開啟了 CONFIG_SLUB_STATS 配置項,內核就會記錄一些關於 slab cache 的相關狀態信息,這些信息同樣也會在 cat /proc/slabinfo 命令中顯示。
slab cache 的架構演變到現在,筆者已經為大家介紹了三種內核數據結構了,它們分別是:
- slab cache 在內核中的數據結構 struct kmem_cache
- slab cache 的本地 cpu 緩存結構 struct kmem_cache_cpu
- slab 在內核中的數據結構 struct page
現在我們把這種三種數據結構結合起來,得到下麵這副 slab cache 的架構圖:

但這還不是 slab cache 的最終架構,到目前為止我們的 slab cache 架構只演進到了一半,下麵請大家繼續跟隨筆者的思路我們接著進行 slab cache 架構的演進。
我們先把 slab cache 比作一個大型超市,超市裡擺放了一排一排的商品貨架,毫無疑問,顧客進入超市直接從貨架上選取自己想要的商品速度是最快的。
上圖中的 kmem_cache 結構就好比是超市,slab cache 的本地 cpu 緩存結構 kmem_cache_cpu 就好比超市的營業廳,營業廳內擺滿了一排一排的貨架,這些貨架就是上圖中的 slab,貨架上的商品就是 slab 中劃分出來的一個一個的記憶體塊。

毫無疑問,

