
一:在hadoop3.3中安裝配置sqoop1.4.7 前言: sqoop功能已經非常完善了,沒有什麼可以更新的了,官方停止更新維護了。因此官方集成的hadoop包停留在了2.6.0版本,在hadoop3.3.0版本會提示類版本過低錯誤,但純凈版sqoop有缺少必須的第三方庫,所以將這兩個包下載下來 ...
一:在hadoop3.3中安裝配置sqoop1.4.7
前言:
sqoop功能已經非常完善了,沒有什麼可以更新的了,官方停止更新維護了。因此官方集成的hadoop包停留在了2.6.0版本,在hadoop3.3.0版本會提示類版本過低錯誤,但純凈版sqoop有缺少必須的第三方庫,所以將這兩個包下載下來,提取部分sqoop_hadoop2.6.0版本的jar包放到純凈版sqoop的lib目錄下,在sqoop配置文件中加入獲取當前環境中的hive及hadoop的lib庫來使用.
配置sqoop1.4.7 支持hadoop3.3
1:下載sqoop1.4.7的兩個版本
http://archive.apache.org/dist/sqoop/1.4.7
sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz # 只用到裡面的jar包
sqoop-1.4.7.tar.gz # 上傳到伺服器
2:提取sqoop-1.4.7.bin__hadoop-2.6.0根目錄下的sqoop-1.4.7.jar放到sqoop-1.4.7根目錄,正常純凈版sqoop是沒有這個jar包的
3:提取lib目錄下的這三個必須的jar包放到sqoop-1.4.7/lib/目錄下,正常純凈版sqoop的lib目錄下是沒有文件的。
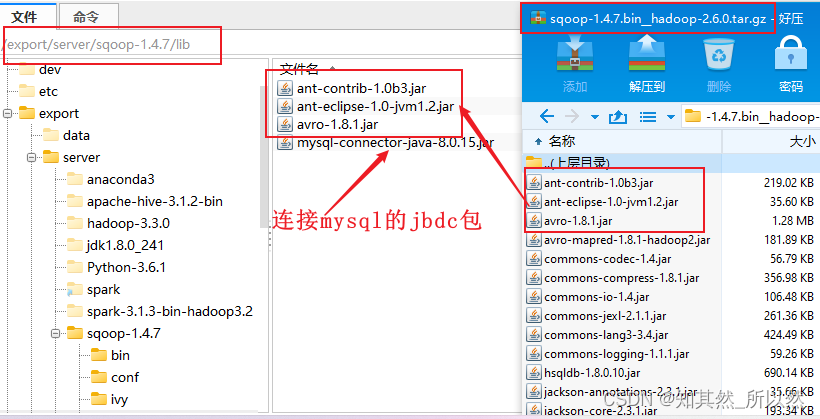
4:提取出sqoop-1.4.6.jar放在hadoop的lib下
添加sqoop配置信息,引用hadoop,hive的lib庫
sqoop-1.4.7/conf 目錄下的sqoop-env.sh文件追加如下信息
export HADOOP_COMMON_HOME=/export/server/hadoop-3.3.0 export HADOOP_MAPRED_HOME=/export/server/hadoop-3.3.0 export HIVE_HOME=/export/server/apache-hive-3.1.2-bin export HIVE_CONF_DIR=/export/server/apache-hive-3.1.2-bin/conf export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:$HIVE_HOME/lib/*
添加sqoop環境變數
在/etc/profile 中添加
export SQOOP_HOME=/export/server/sqoop/ export PATH=$PATH:$SQOOP_HOME/bin:$SQOOP_HOME/bin
二:sqoop 常見的使用方式
sqoop的數據導入操作
1:sqoop help 查看幫助文檔命令
2:查看資料庫中的所有表
sqoop list-tables \ --connect jdbc:mysql://192.168.52.150:3306/hue \ --username root \ --password 123456
3:如何將MySQL中的數據全量的導入到HDFS中(全量)


命令1: sqoop import \ --connect jdbc:mysql://192.168.50.150:3306/test \ --username root \ --password root \ --table emp 說明: 預設情況下, 會將數據導入到操作sqoop用戶的HDFS的家目錄下,在此目錄下會創建一個以導入表的表名為名稱文件夾, 在此文件夾下莫每一條數據會運行一個mapTask, 數據的預設分隔符號為 逗號 思考: 是否更改其預設的位置呢? sqoop import \ --connect jdbc:mysql://192.168.52.150:3306/test \ --username root \ --password 123456 \ --table emp \ --delete-target-dir \ --target-dir '/sqoop_works/emp_1' 思考: 是否調整map的數量呢? sqoop import \ --connect jdbc:mysql://192.168.52.150:3306/test \ --username root \ --password 123456 \ --table emp \ --delete-target-dir \ --target-dir '/sqoop_works/emp_2' \ --split-by id \ -m 2 思考: 是否調整預設分隔符號呢? 比如調整為 \001 sqoop import \ --connect jdbc:mysql://192.168.52.150:3306/test \ --username root \ --password 123456 \ --table emp \ --fields-terminated-by '\001' \ --delete-target-dir \ --target-dir '/sqoop_works/emp_3' \ -m 1View Code
4:將MySQL中的數據全量的導入到hive中
以emp_add 表為例 第一步: 在HIVE中創建一個目標表 create database hivesqoop; use hivesqoop; create table hivesqoop.emp_add_hive( id int, hno string, street string, city string ) row format delimited fields terminated by '\t' stored as orc ; 第二步: 通過sqoop完成數據導入操作 sqoop import \ --connect jdbc:mysql://192.168.52.150:3306/test \ --username root \ --password 123456 \ --table emp_add \ --hcatalog-database hivesqoop \ --hcatalog-table emp_add_hive \ -m 1View Code
5:如何將MySQL中的數據條件的導入到HDFS中
方式一: 通過 where的方式 sqoop import \ --connect jdbc:mysql://192.168.52.150:3306/test \ --username root \ --password 123456 \ --table emp \ --where 'id > 1205' \ --delete-target-dir \ --target-dir '/sqoop_works/emp_2' \ --split-by id \ -m 2 方式二: 通過SQL的方式 sqoop import \ --connect jdbc:mysql://192.168.52.150:3306/test \ --username root \ --password 123456 \ --query 'select deg from emp where 1=1 AND \$CONDITIONS' \ --delete-target-dir \ --target-dir '/sqoop_works/emp_4' \ --split-by id \ -m 1 註意: 如果SQL語句使用 雙引號包裹, $CONDITIONS前面需要將一個\進行轉義, 單引號是不需要的View Code
6:如何通過條件的方式導入到hive中 (後續模擬增量導入數據)
sqoop import \ --connect jdbc:mysql://192.168.52.150:3306/test \ --username root \ --password 123456 \ --table emp_add \ --where 'id > 1205' \ --hcatalog-database hivesqoop \ --hcatalog-table emp_add_hive \ -m 1 或者: sqoop import \ --connect jdbc:mysql://192.168.52.150:3306/test \ --username root \ --password 123456 \ --query 'select * from emp_add where id>1205 and $CONDITIONS' --hcatalog-database hivesqoop \ --hcatalog-table emp_add_hive \ -m 1View Code
sqoop的數據導出操作
需求: 將hive中 emp_add_hive 表數據導出到MySQL中
# 第一步: 在mysql中創建目標表 (必須創建) create table test.emp_add_mysql( id INT , hno VARCHAR(32) NULL, street VARCHAR(32) NULL, city VARCHAR(32) NULL ); # 第二步: 執行sqoop命令導出數據 sqoop export \ --connect jdbc:mysql://192.168.52.150:3306/test \ --username root \ --password 123456 \ --table emp_add_mysql \ --hcatalog-database hivesqoop \ --hcatalog-table emp_add_hive \ -m 1
| 說明 | |
|---|---|
| --connect | 連接關係型資料庫的URL |
| --username | 連接資料庫的用戶名 |
| --password | 連接資料庫的密碼 |
| --driver | JDBC的driver class |
| --query或--e <statement> | 將查詢結果的數據導入,使用時必須伴隨參--target-dir,--hcatalog-table,如果查詢中有where條件,則條件後必須加上關鍵字。如果使用雙引號包含,則CONDITIONS前要加上\以完成轉義:$CONDITIONS |
| --hcatalog-database | 指定HCatalog表的資料庫名稱。如果未指定,default則使用預設資料庫名稱。提供 --hcatalog-database不帶選項--hcatalog-table是錯誤的。 |
| --hcatalog-table | 此選項的參數值為HCatalog表名。該--hcatalog-table選項的存在表示導入或導出作業是使用HCatalog表完成的,並且是HCatalog作業的必需選項。 |
| --create-hcatalog-table | 此選項指定在導入數據時是否應自動創建HCatalog表。表名將與轉換為小寫的資料庫表名相同。 |
| --hcatalog-storage-stanza 'stored as orc tblproperties ("orc.compress"="SNAPPY")' \ | 建表時追加存儲格式到建表語句中,tblproperties修改表的屬性,這裡設置orc的壓縮格式為SNAPPY |
| -m | 指定並行處理的MapReduce任務數量。 -m不為1時,需要用split-by指定分片欄位進行並行導入,儘量指定int型。 |
| --split-by id | 如果指定-split by, 必須使用$CONDITIONS關鍵字, 雙引號的查詢語句還要加\ |
| --hcatalog-partition-keys --hcatalog-partition-values | keys和values必須同時存在,相當於指定靜態分區。允許將多個鍵和值提供為靜態分區鍵。多個選項值之間用,(逗號)分隔。比如: --hcatalog-partition-keys year,month,day --hcatalog-partition-values 1999,12,31 |
| --null-string '\N' --null-non-string '\N' | 指定mysql數據為空值時用什麼符號存儲,null-string針對string類型的NULL值處理,--null-non-string針對非string類型的NULL值處理 |
| --hive-drop-import-delims | 設置無視字元串中的分割符(hcatalog預設開啟) |
| --fields-terminated-by '\t' |


