
Mysql資料庫 一、資料庫 mysql服務啟動,在cmd輸入net start mysql #創建資料庫 CREATE DATABASE hsp_db01; #創建一個使用 utf8 字元集的 hsp_db02 資料庫 CREATE DATABASE hsp_db02 CHARACTER SET ...
Mysql資料庫
mysql服務啟動,在cmd輸入net start mysql#創建資料庫
CREATE DATABASE hsp_db01;
#創建一個使用 utf8 字元集的 hsp_db02 資料庫
CREATE DATABASE hsp_db02 CHARACTER SET utf8
#創建一個使用 utf8 字元集,並帶校對規則的 hsp_db03 資料庫
CREATE DATABASE hsp_db03 CHARACTER SET utf8 COLLATE utf8_bin
#校對規則 utf8_bin 區分大小 預設 utf8_general_ci 不區分大小寫
#查看當前資料庫伺服器中的所有資料庫
SHOW DATABASES
#查看創建的 hsp_db01 資料庫的定義信息
SHOW CREATE DATABASE `hsp_db01` #為了規避關鍵字,可以使用反引號
#刪除前面創建的 hsp_db01 資料庫
DROP DATABASE hsp_db01資料庫的備份、恢復(導入)(必須在dos下運行)
備份恢複數據庫
mysqldump -u 用戶名 -p 密碼 -B 資料庫名 > 路徑(例:d:\\database.sql)
備份恢複數據庫的表
備份資料庫的多個表不能帶-B,否則會被認為是多個資料庫
mysqldump -u 用戶名 -p 密碼 資料庫名 表1 表2 > 路徑(例:d:\\database.sql)
使用mysqldump命令來恢復一個叫data01資料庫的一個叫table01的表(已有備份文件)。具體步驟如下:
-
打開cmd視窗,輸入mysql -u 用戶名 -p,然後輸入mysql密碼,進入mysql資料庫。
-
輸入use data01,選擇您要恢復的資料庫。
-
輸入source d:/table01.sql,執行您的備份文件,恢復您的表。
恢複數據庫(必須在mysql命令行下運行)
先進入mysql命令行:mysql -u 用戶名 -p 密碼
恢復:source 文件路徑.sql(例:d:\\database.sql)
左上角寫了mysql -u 用戶名 -p 的界面才叫mysql命令行
備份,恢複數據庫實踐
先用mysqldump -u 用戶名 -p 密碼 -B 資料庫名 > 路徑(例:d:\\database.sql)
從資料庫里備份一個到E盤裡,然後在資料庫中用drop指令將其刪除
然後通過mysql -u 用戶名 -p 密碼進入mysql命令行,輸入source d:\\database.sql將其備份
二、Mysql基本數據類型

基本數據類型的使用細節
數值型:
decimal(M,D)中的M預設為10(最大65),D預設為0(最大30),M是位數,D是小數點後有幾位
如果沒有指定 unsinged , 就是有符號
#創建一個無符號的tinyint類型數據,0~255
CREATE TABLE t4 (id TINYINT UNSIGNED)字元串型:

VARCHAR雖然可以有65535個位元組,但是首先去掉3個位元組用於記錄欄位大小,所以最大為65532個位元組,
如果用的編碼是UTF-8的話,一個字元消耗3個位元組,最多存放65532 / 3 = 21844個字元,
GBK是2個位元組,最多存放65532 / 2 = 32766個字元。
#我們來創建一個數據類型為varchar,編碼為GBK的表
CREATE TABLE t10 (`name` VARCHAR(32766)) CHARSET gbk;



日期類型:
DATE / DATETIME / TIMESTAMP
CREATE TABLE t14 (
birthday DATE , -- 年月日
job_time DATETIME, -- 年月日 時分秒
login_time TIMESTAMP -- 如果希望 login_time 列自動更新, 需要配置這兩句
NOT NULL DEFAULT CURRENT_TIMESTAMP -- 不允許為空,預設為當前時間
ON UPDATE CURRENT_TIMESTAMP -- 更新當前時間戳
);三、表
創建表
CREATE TABLE `emp` (
id INT,
`name` VARCHAR(32),
sex CHAR(1),
brithday DATE,
entry_date DATETIME,
job VARCHAR(32),
salary DOUBLE,
`resume` TEXT
)
CHARSET utf8 COLLATE utf8_bin ENGINE INNODB
#charset是character set的簡寫,即字元集
#字元集,校驗規則,存儲引擎不寫的話就是預設的(預設的話跟隨當前資料庫)要用cmd在一個叫database的資料庫下新建一個表,你需要先用mysql命令登錄到資料庫,然後用use命令選擇database資料庫,再用create table命令創建表。具體的步驟如下:
-
打開cmd,輸入mysql -u root -p,回車後輸入密碼,登錄到資料庫。
-
輸入use database;,選擇database資料庫。
-
輸入如上代碼完成創建。
刪除表
DROP TABLE `emp`修改表
舉例演示:
ALTER TABLE emp
-- 員工表 emp 的上增加一個 image 列,varchar 類型(要求在 birthday 後面)。
ADD image VARCHAR(32) NOT NULL DEFAULT '' AFTER birthday ;
-- DEFAULT ''預設為''這個字元
-- 修改 job 列,使其長度為 60。
ALTER TABLE emp
MODIFY job VARCHAR(60) NOT NULL DEFAULT '' ;
-- 刪除 sex 列。
ALTER TABLE emp
DROP sex;
-- 表名改為 employee。
RENAME TABLE emp TO employee;
-- 修改表的字元集為 utf8
ALTER TABLE emp CHARACTER SET utf8;
-- 列名 name 修改為 user_name
ALTER TABLE emp;
-- 顯示表結構,可以查看表的所有列
DESC emp ;四、CRUD增刪改查
1. Insert
用法:
INSERT INTO 表名 (列名1,列名2...)
values (對應列名的值);INSERT INTO `emp` (id, birthday)
VALUES(1, '2003-05-15'); -- 註意date等日期類型一定要按照規則寫否則報錯或者錯位寫入insert使用細節
-
插入的數據應與欄位的數據類型相同
-
數據的長度應在列的規定範圍內
-
在 values 中列出的數據位置必須與被加入的列的排列位置相對應
-
字元和日期型數據應包含在單引號中
-
列可以插入空值[前提是該欄位允許為空]
-
可以用 values ( ),( ) ,( ) ; 的形式添加多條記錄
INSERT INTO `goods` (id, goods_name, price) VALUES(50, '三星手機', 2300),(60, '海爾手機', 1800); -
如果是給表中的所有欄位添加數據,可以不寫前面的欄位名稱
-
預設值的使用,當不給某個欄位值時,如果有預設值就會添加預設值,否則報錯
-- 如果某個列 沒有指定 not null ,那麼當添加數據時,沒有給定值,則會預設給 null
-- 如果我們希望指定某個列的預設值,可以在創建表時通過 not null default xxx 指定
#表裡有3個數據,id,goodname,price有預設值10
INSERT INTO `goods` (id, goods_name)
VALUES(80, '格力手機');
#最後會插進去一個(80,格力手機,10)進去
2. Update
用法:
UPDATE 表名 SET 列名 = 值 WHERE 布爾表達式,篩選滿足條件的行#將所有員工薪水修改為 5000 元。如果不帶 where 條件,會修改該列所有的記錄,因此要小心
UPDATE employee SET salary = 5000;
將姓名為 小妖怪 的員工薪水修改為 3000 元
UPDATE employee
SET salary = 3000
WHERE user_name = '小妖怪';
也可以修改多個列的值
UPDATE employee
SET salary = salary + 1000 , job = '出主意的'
WHERE user_name;
3. Delete
用法:
DELETE FROM 表名
where 布爾等值式; -- 如果不帶 where 條件,會修改所有記錄,小心刪庫跑路#刪除表中名稱為’老妖怪’的記錄。
DELETE FROM employee
WHERE user_name = '老妖怪';delete使用細節
-
delete不能刪除某一列的值,只能使用update將列設為空
-
如果不帶 where 條件,會修改所有記錄,小心刪庫跑路!!!
4. 單表Select
用法1:基礎查詢
SELECT [DISTINCT] * 或 指定列 FROM 表名;
-- distinct功能是去重(寫在from前的每一個列的值都相同才去)
-- *代表所有列,也可以寫多個列(用逗號隔開)
比如:
-- 查詢表中所有學生的信息
SELECT * FROM student;
-- 查詢表中所有學生的姓名和對應的英語成績
SELECT name,english FROM student;
-- 過濾表中重覆數據
SELECT DISTINCT name,english FROM student;
用法2:列名使用表達式進行運算
比如:
-- 統計每個學生的總分
SELECT `name`, (chinese + english + math ) FROM student;
#但是使用這種方法系統會自動命名第二列為chinese + english + math,所以我們可以採用下麵的方式美化一下
-- 使用AS給列命名
SELECT name AS '名字', (chinese + english + math ) AS total
FROM student;
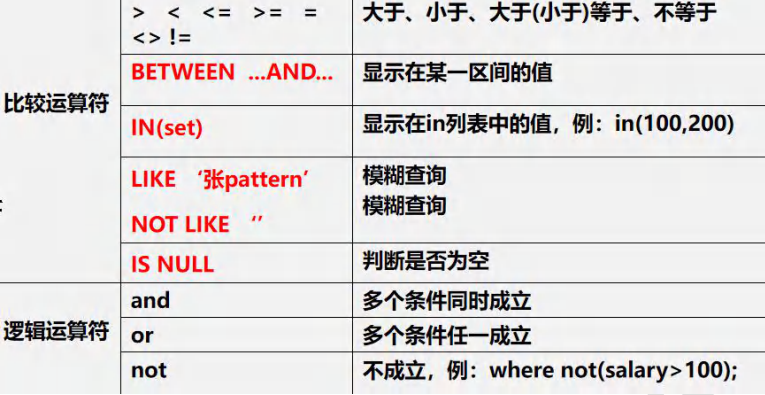
常用運算符表
用法3: 使用where子句運算符,進行過濾查詢
SELECT [DISTINCT] * 或 指定列 FROM 表名 WHERE 布爾表達式; -- select定最後顯示多少列,from定從哪個表查詢,where定最後顯示滿足條件的行
比如:
-- 查詢姓名為趙雲的學生成績
SELECT * FROM student
WHERE name = '趙雲';
-- 查詢 math 大於 60 並且(and) id 大於 4 的學生成績
SELECT * FROM student
WHERE math >60 AND id > 4;
-- 查詢英語成績大於語文成績的同學
SELECT * FROM student
WHERE english > chinese;
-- 查詢總分大於 200 分 並且 數學成績小於語文成績 並且 姓趙的學生, 趙% 表示名字以趙開頭
SELECT * FROM student
WHERE (chinese + english + math) > 200 AND
math < chinese AND name LIKE '趙%';
-- 查詢英語分數在 80-90 之間的同學。
SELECT * FROM student
WHERE english >= 80 AND english <= 90;
SELECT * FROM student
WHERE english BETWEEN 80 AND 90; -- between .. and .. 是 閉區間
-- 查詢數學分數為 89,90,91 的同學。
SELECT * FROM student
WHERE math = 89 OR math = 90 OR math = 91;
SELECT * FROM student
WHERE math IN (89,90,91);
用法4: 使用 order by子句排序查詢結果
SELECT * FROM 表名 ORDER BY 列名(排序的依據) [DESC]; -- 預設為升序,DESC改為降序
比如:
-- 對數學成績排序後輸出【升序】。
SELECT *
FROM student
ORDER BY math;
-- 對總分按從高到低的順序輸出 [降序] -- 使用別名排序
SELECT name , (chinese + english + math) AS '總分'
FROM student
ORDER BY total_score DESC;
-- 對姓韓的學生成績[總分]排序輸出(升序) where + order by
SELECT name, (chinese + english + math) AS '總分' FROM student
WHERE name LIKE '韓%'
ORDER BY total_score;
用法5:使用like模糊查詢
比如:
-- % 表示 0 到多個的任意字元
-- _ 表示單個任意字元 其中GBK中需要兩個_ _來表達一個字元
-- 顯示首字元為 S 的員工姓名和工資
SELECT name, salary FROM emp
WHERE name LIKE 'S%'
-- 顯示第三個字元為大寫 O 的所有員工的姓名和工資
SELECT name, salary FROM emp
WHERE name LIKE '__O%'
用法6:使用DESC查詢表結構
DESC 表名用法7:使用LIMIT分頁查詢
select * from table limit 參數1,參數2; -- 參數1 : 代表偏移量offset(從第offset + 1數據開始查),註意是從0開始,所以應該+1代表第一個數據
-- 參數2 : 取出的數據條數rows
/* 查詢第1-10條數據 */
SELECT * FROM Student LIMIT 0,10;
/* 查詢第11-20條數據 */
SELECT * FROM Student LIMIT 10 , 10; -- 講到這我們會想知道如何快速算出 參數1,接下來我們看一下計算公式公式
-
offset:(要查詢的頁數 - 1) * 每頁顯示的數據條數
-
rows:顯示的數據條數
在進行分頁之前,要註意一下是否超出了最大頁數,所以我們需要先根據數據總量來得出總頁數,這需要用到統計函數COUNT和向上取整函數CEIL,SQL操作如下:
#獲得數據總條數
SELECT COUNT(*) FROM Student;
#假設每頁顯示10條,則直接進行除法運算,然後向上取整,這樣我們就獲得了總頁數,在實際操作中,要註意一下是否超出了最大頁數
SELECT CEIL(COUNT(*) / 10) AS '總頁數' FROM Student;5. 多表查詢Select
多表查詢的條件不能少於 要查詢的表個數 - 1, 否則會出現笛卡爾集
自連接
自連接的特點
1. 把同一張表當做兩張表使用
2. 需要給表取別名 如果from同一張表兩次,會報錯,所以需要對錶重命名,無需使用 AS,直接表加別名就好
3. 列名有時不明確,可以通過 AS 指定列的別名
舉例:
顯示公司員工名字和他上級的名字,員工名字和上級的名字都在emp表
其中員工和上級是通過 emp 表的 manager列 關聯
SELECT worker.name AS '職員名' ,
boss.name AS '上級名'
FROM emp worker, emp boss
WHERE worker.manager = boss.empno
子查詢(嵌套查詢)
-
單行子查詢:只返回一行數據
-
多行子查詢:返回多行數據 ,因為子查詢的結果是不確定的,所以使用比較運算符 IN (用於確定IN前面的值是否與IN的括弧中的值或子查詢中的任何值匹配)
#多行子查詢中使用in運算符
#查詢和10號部門的工作相同的雇員的 名字、崗位、工資、部門號, 但是不含10號部門的員工
select ename, job, sal, deptno
from emp
where job in (
SELECT DISTINCT job
FROM emp
WHERE deptno = 10
) and deptno != 10
多行子查詢中使用 all 操作符
查詢工資比部門 30 的所有員工的工資高的員工的姓名、工資和部門號
SELECT ename, sal, deptno
FROM emp
WHERE sal > ALL(
SELECT sal
FROM emp
WHERE deptno = 30
)
多行子查詢中使用 any 操作符
查詢工資比部門 30 的任意/其中一個員工的工資高的員工的姓名、工資和部門號
SELECT ename, sal, deptno
FROM emp
WHERE sal > any(
SELECT sal
FROM emp
WHERE deptno = 30
)
-
把子查詢當做臨時表使用 : 避免mysql重覆計算表,提高查詢性能,並且可以解決很多複雜的查詢
#查找每個部門工資 高於 他們自己部門平均工資的人的資料 -- 1. 先得到每個部門的 部門號和 對應的平均工資 SELECT deptno, AVG(sal) AS avg_sal FROM emp GROUP BY deptno -- 當聚合列和非聚合列出現在一起時必須使用group by語句-- 2. 把上面的結果當做子查詢, 和 emp 進行多表查詢
SELECT ename, sal, temp.avg_sal, emp.deptno
FROM emp,(
SELECT deptno, AVG(sal) AS avg_sal
FROM emp
GROUP BY deptno
) temp -- 把子查詢當作一個臨時表使用,重命名為temp
WHERE emp.deptno = temp.deptno AND emp.sal > temp.avg_sal
合併查詢
-
union all 單純取並集不去重
-
union 去重
舉例: -- union all 就是將兩個查詢結果合併,不會去重 SELECT ename,sal,job FROM emp WHERE sal>2500 -- 5條 UNION ALL SELECT ename,sal,job FROM emp WHERE job='MANAGER' -- 3條 -- 最後有8條
6.連接
自然連接
通常用於將兩個關係表中具有相同屬性的行組合在一起,以便我們可以從兩個表中同時獲取信息。
自然連接是一種特殊的等值連接(區別在於等值連接需要指定值),他要求兩個表中進行連接的必須是相同的屬性列(名字相同),無須添加連接條件,並且在結果中消除重覆的屬性列。
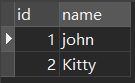
natural表1:
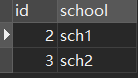
natural表2:
select 列名 from 左表 natural join 右表
-- 將2個表自然連接一下
SELECT * FROM `natural` NATURAL JOIN `natural2` 說人話,直接先把兩張表的列名去重後列出來

然後開始對比他們兩相同的列(id)的值,我們就找到id = 2時相同,直接把左表和右表連接起來,結果:
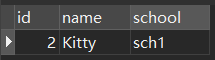
內連接
內連接基本與自然連接相同,不同之處在於自然連接的是同名屬性列的連接,而內連接則不要求兩屬性列同名,可以用using或on來指定某兩列欄位相同的連接條件。
select 列名 from 左表 inner join 右表 on 條件 -- inner可以省略外連接
通常用於查詢在一張表中存在但在另一張表中不存在的記錄
-
左外:只保留左表的所有元素,右表沒有則置null
-
右外:同理
-
全外連接 :mysql不支持
用法: select 列名 from 左表 left join 右表 on 條件 select 列名 from 左表 right join 右表 on 條件下麵是一個簡單的例子,演示如何使用外連接查詢兩張表中的數據。
假設我們有兩張表:員工表和部門表。員工表包含員工的姓名和所屬部門,部門表包含部門名稱和部門編號。
員工表:
姓名 部門編號
張三 1
李四 2
王五 3
趙六 NULL部門表:
部門編號 部門名稱
1 銷售部
2 人事部
如果我們想要查詢所有員工及其所屬部門,可以使用以下SQL語句:SELECT 員工姓名, 部門名稱 FROM 員工表 LEFT JOIN 部門表 ON 員工的部門編號 = 部門的編號;
執行上述語句後,將得到以下結果:
姓名 部門名稱
張三 銷售部
李四 人事部
王五 NULL
趙六 NULL
可以看到,上述查詢結果中包含了員工表中所有記錄,並且顯示了每個員工所屬的部門。對於那些在部門表中沒有匹配記錄的員工(即王五和趙六),其所屬部門顯示為NULL。
五、函數
1.聚簇函數(合計、統計)
count:
SELECT COUNT(*) 或 (列)FROM 表名 WHERE 表達式;
-- count(*) 和 count(列) 的區別
-- count(*) 返回滿足條件的行數
-- count(列): 統計滿足條件的某列個數,會排除為 null 的sum:
SELECT SUM(列) FROM 表名 WHERE 表達式;
比如:
-- 統計一個班級語文、英語、數學各科的總成績並使用別名
SELECT SUM(math) AS math_total_score,
SUM(english) AS english_total_score,
SUM(chinese) AS chinese_total_score
FROM student;
-- 統計一個班級語文成績平均分
SELECT SUM(chinese)/ COUNT(*) FROM student;
-- 註意有些數據類型不能統計比如字元串之類
SELECT SUM(name) FROM student; #不報錯但無意義
avg:
SELECT AVG(列) FROM 表名 WHERE 表達式;
比如:
-- 求一個班級數學平均分?
SELECT AVG(math) FROM student;
-- 求一個班級總分平均分
SELECT AVG(math + english + chinese) FROM student;
-- 求班級最高分和最低分
SELECT MAX(math + english + chinese), MIN(math + english + chinese)
FROM student;
-- 求出班級數學最高分和最低分並使用別名
SELECT MAX(math) AS math_high_socre,
MIN(math) AS math_low_socre
FROM student;
使用group by 對列進行分組 :
註意:當聚合列和非聚合列出現在一起時必須使用group by語句
SELECT 列名 FROM 表名 group by 列名(從select後面的幾個列名之中挑);
比如:
-- 顯示每個部門的每種崗位的平均工資和最低工資
SELECT AVG(salary), MIN(salary) , department, job
FROM emp GROUP BY department, job;
-- GROUP BY也可以對查詢結果進行去重
使用 having 對group by 分組後的結果進行過濾
SELECT 列名 FROM 表名 group by 列名 having 布爾表達式;
比如:
-- 顯示平均工資低於 2000 的部門編號和它的平均工資 並使用別名
SELECT AVG(salary) AS '平均工資',
deptno AS '部門編號'
FROM emp
GROUP BY deptno
HAVING AVG(salary) < 2000; # 註意HAVING 子句中不能使用別名,只能使用原始的表達式2.字元串函數
3.數學函數
4.日期函數
5.加密函數
MySQL有一些加密函數,可以用來對字元串進行加密和解密。常用的有以下幾種:
AES_ENCRYPT(str,key):返回用密鑰key對字元串str利用高級加密標準演算法加密後的結果,調用AES_ENCRYPT的結果是一個二進位字元串,以BLOB類型存儲。
AES_DECRYPT(crypt_str,key):返回用密鑰key對字元串crypt_str利用高級加密標準演算法解密後的結果1。
DECODE(str,key):使用key作為密鑰解密加密字元串str2。
ENCODE(str,key):使用key作為密鑰加密字元串str2。
MD5(str):返回str的MD5校驗和,是一個32位十六進位數2。
演示MD5使用
-- 插入
INSERT INTO users (username, password) VALUES ('admin', MD5('123456'));
-- 這樣就可以把用戶名和密碼加密後存儲在users表中。你也可以使用MD5函數來驗證用戶輸入的密碼是否正確,例如:
SELECT * FROM users WHERE username = 'admin' AND password = MD5('123456');
這樣就可以根據用戶名和密碼查詢users表中是否有匹配的記錄。你明白了嗎?
六、約束
MySQL約束語句是用來限製表中數據的條件。MySQL支持以下幾種約束:
-
主鍵(PRIMARY KEY):唯一標識表中的每一行。
-
外鍵(FOREIGN KEY):引用另一個表中的主鍵或唯一鍵。
-
唯一(UNIQUE):保證列中的值不重覆。
-
非空(NOT NULL):保證列中的值不為空。
-
檢查(CHECK):保證列中的值滿足指定的條件。
-
預設(DEFAULT):為列提供預設值。
可以在創建表或修改表時添加或刪除約束。
我來介紹一下這6種約束的用法。
主鍵(PRIMARY KEY)
不能重覆而且不能為 null
在創建表時,可以使用PRIMARY KEY關鍵字來指定一個或多個列作為主鍵,例如:
CREATE TABLE student (
id INT PRIMARY KEY,
name VARCHAR(20),
age INT
);
#複合主鍵
CREATE TABLE t(
id INT ,
`name` VARCHAR(32),
PRIMARY KEY (id, `name`) -- 這裡就是複合主鍵
);也可以在創建表後,使用ALTER TABLE語句來添加或刪除主鍵,例如:
ALTER TABLE student ADD PRIMARY KEY (id);
ALTER TABLE student DROP PRIMARY KEY;外鍵(FOREIGN KEY)
外鍵是用於建立和加強兩個表數據之間的鏈接的列。 外鍵的作用是保持數據的一致性、完整性,主要體現在下麵兩個方面
-
約束作用:外鍵可以防止在外鍵所在表中插入無效的數據,或者刪除外鍵指向表中引用的數據。
-
連接作用:外鍵可以通過連接操作實現兩個表之間的聯合查詢。
在創建表時,可以使用FOREIGN KEY關鍵字來指定一個或多個列作為外鍵,並引用主表中的主鍵(primary key)或唯一鍵(unique)
用法:FOREIGN KEY (外鍵所在表的外鍵列列名) REFERENCES 主表名(主表中的主鍵或唯一鍵)
比如:
-- 創建 主表 my_class (外鍵指向表)
CREATE TABLE my_class (
id INT PRIMARY KEY , -- 班級編號
name VARCHAR(32) NOT NULL DEFAULT ''
);
-- 創建 從表 my_stu (外鍵所在表)
CREATE TABLE my_stu (
id INT PRIMARY KEY , -- 學生編號
name VARCHAR(32) NOT NULL DEFAULT '',
class_id INT , -- 學生所在班級的編號
FOREIGN KEY (class_id) REFERENCES my_class(id) -- 外鍵
);

唯一(UNIQUE)
-
在創建表時,可以使用UNIQUE關鍵字來指定一個或多個列的值不重覆,例如:
CREATE TABLE user (
id INT PRIMARY KEY,
username VARCHAR(20) UNIQUE NOT NULL, -- unique + not null = primary key
password VARCHAR(20) NOT NULL
);非空(NOT NULL)
在創建表時,可以使用NOT NULL關鍵字來指定一個列的值不為空,例如:
CREATE TABLE book (
id INT PRIMARY KEY,
title VARCHAR(50) NOT NULL,
);檢查(CHECK)
-
在創建表時,可以使用CHECK關鍵字來強制指定一個列的值滿足指定的條件,(註意MySQL目前不支持檢查約束)
CREATE TABLE employee (
id INT PRIMARY KEY,
name VARCHAR(20) NOT NULL,
salary DECIMAL(10,2),
CHECK (salary >0)
);預設(DEFAULT)
-
在創建表時,可以使用DEFAULT關鍵字來為列提供預設值,在插入數據時如果沒有指定該列的值,則會自動填充預設值。預設值必須是常量。如果要設置當前日期時間作為預設值,則需要用CURRENT_TIMESTAMP函數。例如:
CREATE TABLE post (
id INT PRIMARY KEY,
title VARCHAR(50) NOT NULL,
content TEXT,
create_time DATETIME DEFAULT CURRENT_TIMESTAMP
);七、自增長
目的:當我們希望一列每插一個數據進去會自動增長時可以使用自增長,這樣可以避免手動輸入主鍵值,也可以保證主鍵值的唯一性
要實現MySQL自增長,需要滿足以下條件:
-
只能有一個欄位使用AUTO_INCREMENT約束
-
該欄位必須有唯一索引(主鍵或主鍵的一部分)
-
該欄位必須具備NOT NULL屬性(要麼直接primary key 要麼就加 not null )
-
該欄位只能是整型(TINYINT、SMALLINT、INT、BIGINT)
用法:
欄位名 整型 primary key auto_increment
-- 創建一個名為student的表,包含id、name和age三個欄位
CREATE TABLE student (
id INT NOT NULL AUTO_INCREMENT, -- id欄位為自增長欄位,必須為整數類型且非空
name VARCHAR(20) NOT NULL, -- name欄位為字元串類型,非空
age INT NOT NULL, -- age欄位為整數類型,非空
PRIMARY KEY (id) -- id欄位為主鍵,保證唯一性
);
-- 插入兩條記錄,不需要指定id值,資料庫會自動賦值
INSERT INTO student (name, age) VALUES ('Alice', 18);
INSERT INTO student (name, age) VALUES ('Bob', 19);
-- 查詢表中的數據,可以看到id值自動遞增了
SELECT * FROM student;
輸出結果如下:
id name age
1 Alice 18
2 Bob 19
-- 如果插入的時候插入一個不是自增長的值時,再插入數據則從上一個開始自增
INSERT INTO student (id ,name, age) VALUES (666,'Tom', 18);
INSERT INTO student (name, age) VALUES ('John', 18);
-- 查詢
SELECT * FROM student;
輸出結果如下:
id name age
1 Alice 18
2 Bob 19
666 TOM 18
667 John 18
八、索引
MySQL索引是一種幫助MySQL高效獲取數據的數據結構。它可以根據一列或多列的值進行排序,從而加快資料庫的查詢速度
MySQL中常用的索引結構有B-TREE,B+TREE,HASH等。不同的索引結構適用於不同的查詢場景,例如:
-
B-TREE索引適用於全鍵值、鍵值範圍和首碼查找
-
B+TREE索引是B-TREE索引的改進版,具有更高的查詢效率和空間利用率
-
HASH索引適用於等值查找,但不支持範圍查找和排序
用法:
CREATE INDEX 索引名 ON 表名 (列名);
ALTER TABLE 表名 ADD INDEX 索引名 (列名);
在創建表時,可以使用 PRIMARY KEY,UNIQUE或INDEX關鍵字來定義主鍵、唯一或普通索引12。例如:
-- 創建一個名為student的表,包含id、name和age三個欄位
CREATE TABLE student (
id INT NOT NULL AUTO_INCREMENT PRIMARY KEY, -- id欄位為主鍵索引
name VARCHAR(20) NOT NULL UNIQUE, -- name欄位為唯一索引
age INT NOT NULL INDEX -- age欄位為普通索引
);
在已有的表上,可以使用 ALTER TABLE 或 CREATE INDEX語句來創建索引
-- 在student表上創建一個名為idx_name_age的複合索引,包含name和age兩個欄位
ALTER TABLE student ADD INDEX idx_name_age (name, age);
-- 或者
CREATE INDEX idx_name_age ON student (name, age);
單獨創建主鍵索引,例如:
ALTER TABLE student ADD PRIMARY KEY (id);
刪除主鍵索引,例如:
ALTER TABLE student DROP PRIMARY KEY;
在已有的表上,可以使用 DROP INDEX 或 ALTER TABLE語句來刪除索引。
-- 刪除student表上的idx_name_age索引
DROP INDEX idx_name_age ON student;
-- 或者
ALTER TABLE student DROP INDEX idx_name_age;
資料庫索引的優點與缺點
-
優點:
-
索引可以提高數據檢索的效率,降低資料庫的I/O成本
-
索引可以通過索引列對數據進行排序,降低數據排序的成本,降低CPU的消耗
-
索引可以加快表與表之間的連接,提高關聯查詢的性能
-
索引可以保證行或列的唯一性,生成唯一的row
-
-
缺點:
-
索引需要占用額外的存儲空間,增加資料庫的負擔
-
索引會降低數據更新(插入、刪除、修改)的速度,因為每次更新都需要維護索引結構
-
不恰當地使用索引可能導致查詢性能下降或者無法使用索引
-
創建索引的條件

九、事務
事務是指一組操作量大,複雜度高的數據操作,它們要麼都執行成功,要麼都執行失敗,不會出現中間狀態。
-
原子性(Atomicity):事務中的所有操作要麼全部完成,要麼全部不完成,不會停滯在中間某個環節。
-
一致性(Consistency):事務在完成時,必須使所有數據恢復到一致性狀態。在一致性狀態下,所有相關的數據規則都得到滿足。
-
隔離性(Isolation):事務的隔離性是指多個用戶併發訪問資料庫時,一個用戶的事務不能被其他用戶的事務所干擾,多個併發事務之間要相互隔離。
-
持久性(Durability):持久性是指一個事務一旦被提交了,那麼對資料庫中的數據的改變就是永久性的。
MySQL預設每條DML(增刪改)操作都是一個事務。可以通過 SHOW VARIABLES LIKE 'autocommit’ 查看自動提交模式是否開啟。如果關閉自動提交模式,則需要手動使用COMMIT或ROLLBACK來提交或回滾事務
MySQL只有使用了InnoDB資料庫引擎的資料庫或表才支持事務。
START TRANSACTION; / SET autocommit = off; -- 開啟一個新的事務
SAVEPOINT 保存點名; -- 設置保存點
ROLLBACK TO 保存點名; -- 回滾到某事務,
-- (註意)假如有按順序的3個保存點A,B,C 如果回滾到A時,B和C保存點就被刪除
ROLLBACK; -- 回滾到最開始的狀態
COMMIT; -- 提交當前事務,一旦執行,就不能再回滾了,保存點也被刪除,也只有提交事務之後,其他客戶端才(可能)看見資料庫的更新,為什麼是可能,引用到後面的隔離級別知識點十、事務隔離級別
MySQL事務的隔離級別。事務的隔離級別是指多個併發事務之間如何相互影響的問題,不同的隔離級別會導致不同的併發問題。
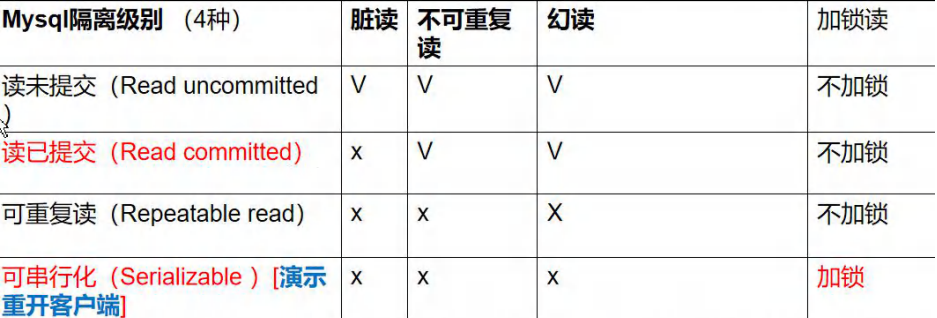
四個事務隔離級別
-
讀未提交(read uncommitted):最低的隔離級別,一個事務可以讀取另一個未提交事務的修改數據,可能會出現臟讀,不可重覆讀,幻讀
-
讀已提交(read committed):一個事務只能讀取另一個已提交事務的修改數據,可以避免臟讀,但可能會出現不可重覆讀、幻讀
-
可重覆讀(repeatable read):MySQL預設隔離級別,一個事務在執行期間看到的數據始終和這個事務在啟動時看到的數據是一致的,可以避免臟讀和不可重覆讀,但可能會出現幻讀,不過InnoDB實現的RR通過mvcc機制避免了這種幻讀現象。面試重點之一,核心就是採用了一個間隙鎖(Next-key lock),行鎖只能鎖一行,所以對於幻讀這種範圍查詢的數據不能避免數據的插入,
-
可串列化(serializable):最高的隔離級別,所有事務都必須按照順序執行,可以避免所有併發問題,但性能最差。
那麼臟讀、不可重覆讀、幻讀都是什麼意思呢?
-
臟讀(dirty read):一個事務讀取了另一個還未提交事務的修改數據,如果後者回滾了操作,則前者所讀取的數據就是不正確的
-
不可重覆讀(non-repeatable read):一個事務在執行期間多次讀取同一份數據(比如某行某列的一個值),但由於另一個事務對該數據進行了update並提交,導致前者兩次讀取的結果不一致
-
幻讀(phantom read):一個事務在執行期間多次查詢某段數據(比如一張表),但由於另一個事務對該段數據進行了delete,insert並提交,導致前者查詢的結果不一致
-
不可重覆讀的重點是修改:
同樣的條件, 你讀取過的數據, 再次讀取出來發現值不一樣了
幻讀的重點在於新增或者刪除
同樣的條件, 第1次和第2次讀出來的記錄數不一樣
當然, 從總的結果來看, 似乎兩者都表現為兩次讀取的結果不一致.
但如果你從控制的角度來看, 兩者的區別就比較大
-
對於前者, 只需要鎖住滿足條件的記錄
-
對於後者, 要鎖住滿足條件及其相近的記錄
-
設置事務隔離級別
在MySQL中,可以使用以下命令設置事務的隔離級別:
set session transaction isolation level 隔離級別; -- read committed /read uncommitted / repeatable read / serializable
例如,設置隔離級別為讀取未提交:
set session transaction isolation level read uncommitted;
設置隔離級別為讀取已提交:
set session transaction isolation level read committed;
你可以使用以下語句查看當前資料庫的隔離級別:
SELECT @@global.tx_isolation; -- 查看全局事務隔離級別
SELECT @@tx_isolation; -- 會話事務當前級別
十一、視圖
用法: CREATE VIEW 視圖名 AS
SELECT 列名... FROM 表名(基表);
-- 創建一個視圖 emp_view01,只能查詢 emp 表的(empno、ename, job 和 deptno ) 信息
CREATE VIEW emp_view01 AS
SELECT empno, ename, job, deptno FROM emp;
-- 1. 創建視圖後,到資料庫去看,對應視圖只有一個視圖結構文件(形式: 視圖名.frm)
-- 2. 視圖的數據變化會影響到基表,基表的數據變化也會影響到視圖[insert update delete]
十二、用戶管理
#創建用戶
CREATE USER '用戶名' @ '允許登錄的IP地址' IDENTIFIED BY '密碼'
-- 創建用戶 shunping 密碼 123 , 從本地登錄
CREATE USER 'shunping'@ 'localhost' IDENTIFIED BY '123'
刪除用戶
DROP USER '用戶名'@ '登錄地址'
DROP USER 'shunping'@ 'localhost'
修改密碼
-- 改自己的
set password = password('密碼');
-- 改別人的
set password for '用戶名'@ '登錄地址' = password('密碼');
-- '用戶名' @ '登錄地址'也叫用戶賬戶
給用戶授權
GRANT 許可權列表.. -- 比如增刪改查等許可權
ON 庫.對象名.. -- 比如賦予對象訪問student資料庫的(表,視圖等對象)的許可權
TO 用戶賬戶 [WITH GRANT OPTION]; -- 加上最後的[WITH.. ]代表允許該用戶將許可權授予給其他用戶
-- 給 shunping 分配查看 (SELECT) test庫下的 news表 的許可權 和 添加 (INSERT) 的許可權
GRANT SELECT , INSERT
ON test.news
TO 'shunping'@'localhost';
回收用戶許可權
REVOKE 許可權列表
ON 庫.對象
FROM 用戶賬戶
-- 回收 shunping 用戶在 testdb.news 表的增改查許可權
REVOKE SELECT , UPDATE, INSERT
ON testdb.news
FROM 'shunping'@'localhost'
-- 回收 shunping 用戶在 testdb.news 表的所有許可權
REVOKE ALL
ON testdb.news
FROM 'shunping'@'localhost
細節說明



