摘要:Bucket存儲是數據共用中重要的一環,當前階段,bucket存儲可以將列存中的CU數據和DN節點解綁。 本文分享自華為雲社區《存算分離之bucket表——【玩轉PB級數倉GaussDB(DWS)】》,作者:yd_278301229 。 在雲原生環境,用戶可以自由配置cup型號、記憶體、磁碟、帶 ...
摘要:Bucket存儲是數據共用中重要的一環,當前階段,bucket存儲可以將列存中的CU數據和DN節點解綁。
本文分享自華為雲社區《存算分離之bucket表——【玩轉PB級數倉GaussDB(DWS)】》,作者:yd_278301229 。
在雲原生環境,用戶可以自由配置cup型號、記憶體、磁碟、帶寬等資源,需要在計算和IO之間做平衡;如果計算和存儲耦合,擴縮容時數據要在節點之間移動,同時還要對外提供計算,性能會大受影響。如果存算分離,計算出和存儲層可以獨立增加節點互不幹擾,這其中一個關鍵點是做到數據共用。Bucket存儲是數據共用中重要的一環,當前階段,bucket存儲可以將列存中的CU數據和DN節點解綁。
一、bucket表在存算分離中的作用
通過存算分離,把DWS完全的shared nothing架構改造成計算層shared nothing + 存儲層shared storage。使用OBS替換EVS,OBS對append only存儲友好,與列存CU存儲天然適配;由於存算分離數據共用,對寫的併發性能不高,在OLAP場景下讀多寫少更有優勢,這一點也是和列存相匹配的,目前主要實現的是列存的存算分。
在當前。bucket表在存儲層共用中,為了將CU數據和DN節點解綁,主要做了兩件關鍵的事,CUID和FILEID全局統一管理。我們來看看為什麼這兩件事能把CU和DN節點解綁以及帶來的好處。
為瞭解釋這個問題,先看看目前shared nothing架構中,建庫和存儲數據的過程。
二,當建立一張列存表並存儲數據時,我們在做什麼
建一張列存表時,主要要做以下兩步:
1,系統表中建立表的數據。
2,為列存建立CUDesc表、Delta表等輔助表
當存儲數據時,主要做以下幾步:
1,根據數據分佈方式,決定數據存儲到哪個DN。
2,把列存存儲時需要的輔助信息填入CUDesc表、Delta表等輔助表。
3,把存儲用戶數據的CU存儲本地DN。
在上面的過程中,由於DN之間互不幹擾,那就需要各自管理自己的存儲的表的信息。
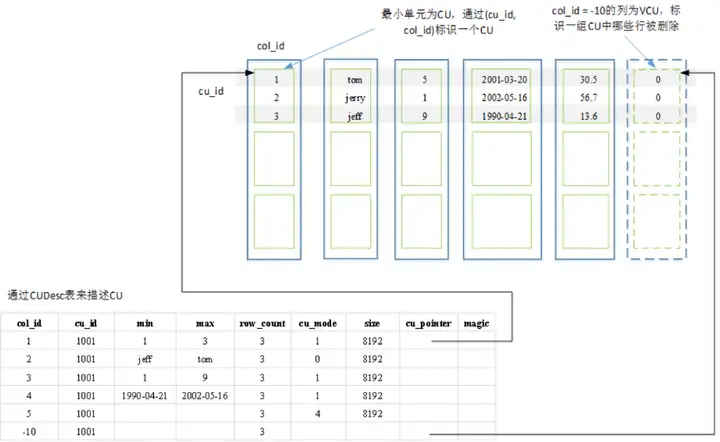
CUDesc表的一大功能是CU數據的“指路牌”,就像指針一樣,指出CU數據存儲的位置。靠的是CUID對應的CUPoint(偏移量),加上存儲在DN的文件位置就能標註出具體的CU數據,而文件名就是系統表中的relfilenode。
由於在MPPDB的存算一體中,數據都存儲在DN節點,DN節點之間互不幹擾,CUID和relfilenode各個DN節點自己管理,只要自己不出問題就行了,也就是“各人自掃門前雪莫管他人瓦上霜”,例如下圖,顯示一張列存表在集群中的存儲狀態。
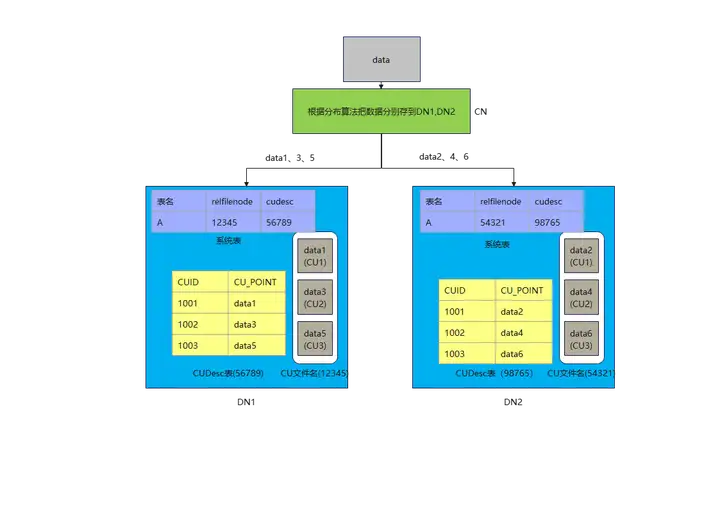
CN把要存儲的數據根據分佈演算法(例如對DN數量做除法取餘數)把1,3,5存到DN1,把2,4,6存到DN2。DN1此時生成存儲CU文件的relfilenode是12345,每插入一次CUID,就把該表的CUDesc表CUID自增,DN1只要把自己的數據管理好,與DN2無關。DN2同理。
三,數據共用和擴縮容時,遇到的困難
1,數據共用時遇到的困難
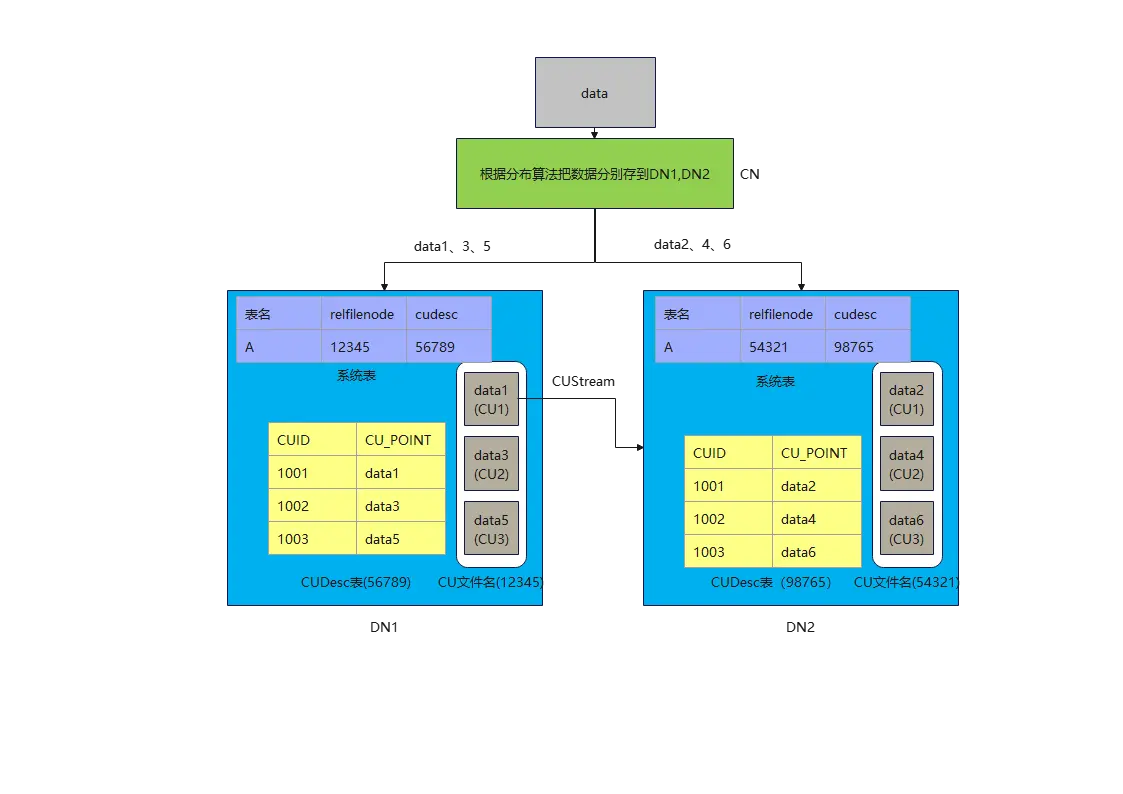
如上所述,當用戶想查詢數據1,2,4,6時,該怎麼辦。因為DN1和DN2都不可能單獨完成任務,就需要共用數據了。問題就來了,DN間肯定是想以最小代價來完成數據共用,系統表最小,CUDesc表也很小(就像指針一樣,同等規模下,只有CU數據的1/3000左右),CU數據最大。假如最後決定以DN2來匯聚所有結果,就算DN1把系統表和CUDesc表中的數據傳給DN2,DN2也看不懂,因為在DN2上,relfilenode為12345可能是另外一張表,cudesc表為中CUID為1001的CUPoint也不知道是指向哪兒了(data1,data2),沒辦法,只能是DN1自己計算,最後把data1的CU數據通過stream運算元發送給DN2。DN1迫不得已選了最難的那條路,CU的數據量太大,占用了網路帶寬,還需要DN1來參與計算,併發上不去。
2,擴縮容時遇到的困難
當用戶發現DN1,DN2節點不夠用時,想要一個DN3,該怎麼辦。根據分佈假設的演算法(對DN數量做除法取餘數),data3和data6應該要搬去DN3才對。系統表還比較好搬,無非是在DN3上新建一份數據,CUDesc表也好搬,因為數據量小,再把CUID和CUPoint按照DN3的邏輯寫上數據就好了,CU數據也要搬,但是因為CU數據量大,會占用過多的計算資源和帶寬,同時還要對外提供計算。真是打了幾份工,就賺一份工資。

總結起來,困難主要是
1)系統表元數據(計算元數據)
每個節點有自己的系統表元數據,新增dn必須創建“自己方言”的系統表,而實際上這些系統表內容是“相同的”,但是dn之間互相不理解;
2)CUDesc元數據(存儲元數據)
每個節點的CUID自己分配,同一個CUID在不同節點指向不同的數據,CU無法在dn之間遷移,因為遷移後會混亂,必須通過數據重分佈生成dn “自己方言的CUID”
CU的可見性信息(clog/csnlog)各自獨立管理,dn1讀取dn2的cudesc行記錄之後,不知道記錄是否可見
3)CU用戶數據
filepath(relfilenode) dn節點各自獨立管理,dn1不知道到哪裡讀取dn2的數據
四、揭秘CU與DN解綁的關鍵——bucket表
1,存儲映射
bucket表的存儲方式如圖,CU的管理粒度不再是DN,而是bucket,bucket是抽象出來的一個概念,DN存儲的,是系統元數據和bucket對應的CUDesc元數據,由於在bucket作為存儲粒度下,CUID和FILEID是全局統一管理的,DN只需要懂全局的規則,並且拿到別的bucket對應的CUDesc元數據,那就可以很方便的去OBS上拿到CU數據了。通過這種方式,把本該存儲在DN上的CU數據,映射到OBS上,可以保證DN間共用數據時相互獨立,換句話說,每個DN都讀的懂其他DN的CUDesc數據,不再需要把CU數據喂到嘴邊了。
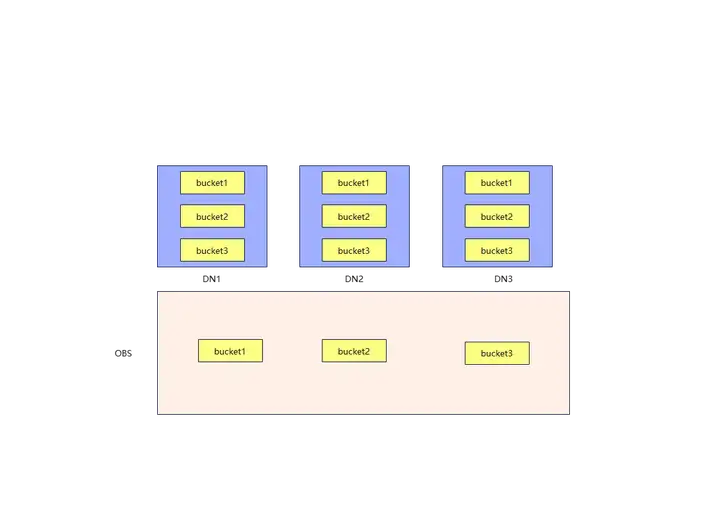
2,全局CUID和FILEID表生成
CUID不再是各節點自己管理生成,而是全局唯一的。其原因是CUID與bucket號綁定,特定的bucket號只能生成特定的globalCUID,與此同時,relfilenode不再作為存儲的文件名,而是作為存儲路徑。CU存放的文件名為relfilenode/C1_fileId.0,fileId的計算只與bukcet號和seqno有關。
這樣V3表就建立起了一套映射關係(以V2表示存算一體表,V3表示為bucket表):
step 1,數據插入哪一個bucket由分佈方式來確定,例如是RR分佈,那麼就是輪巡插入bucket。
step 2,CUID是多少,由bucket粒度級別的CUID來確定,比如+1自增作為下一個CUID。
step 3,在bucket上存儲bucket粒度級別的fileId。
step 4,生成全局唯一fileId,由bucketid和bucket粒度級別的fileId來生成,對應生成的CU插入該fileId文件名的文件。
setp 5,生成全局唯一globalCUID。由bucketid和bucket粒度級別的CUID計算得到全局唯一的globalCUID。
CUDesc表中,也為bucket表新建了一個屬性fileId,用來讓DN查找到OBS上的CU數據所在的文件。

3,共用數據和擴縮容的便利
如上所述,DN可以通過全局CUID和FILEID來找到CU數據,在數據共用時,不再需要其他DN參與大量的計算和搬遷CU,擴縮容時,也不需要搬遷CU了,只需要正確生成系統表中的信息和搬遷CUDesc即可。
最後,來看一看bucket表在OBS上存儲的CU數據: