
說說複合索引 寫索引的博客太多了,一直不想動手寫,有一下兩個原因: 一是覺得有炒剩飯的嫌疑,有兄弟曾說:索引嗎,只要在查詢條件上建索引就行了,真的可以這麼暴力嗎? 二來覺得,索引是個非常大的話題,很難概括出所有的情況,你不整齣點新意來,倒是有抄襲照搬的嫌疑 既然寫了,就寫一點稍微不一樣的東西出來, ...
說說複合索引
寫索引的博客太多了,一直不想動手寫,有一下兩個原因:
一是覺得有炒剩飯的嫌疑,有兄弟曾說:索引嗎,只要在查詢條件上建索引就行了,真的可以這麼暴力嗎?
二來覺得,索引是個非常大的話題,很難概括出所有的情況,你不整齣點新意來,倒是有抄襲照搬的嫌疑
既然寫了,就寫一點稍微不一樣的東西出來,
好了,廢話打住,開搞
搭建測試環境:
創建一張表,模擬實際業務中的一個表,往裡面填入數據,
時間欄位上,相對按照時間均勻地填充,其他欄位以GUID填充
Create table BusinessInfoTable ( BuniessCode1 varchar(50), BuniessCode2 varchar(50), BuniessCode3 varchar(50), BuniessCode4 varchar(50), BuniessStatus1 tinyint, BuniessStatus2 tinyint, BuniessDateTime1 Datetime, BuniessDateTime2 Datetime, OtherColumn1 varchar(50), OtherColumn2 varchar(50), OtherColumn3 varchar(50) ) declare @i int=0 while @i<1000000 begin insert into BusinessInfoTable values ( NEWID(),NEWID(),NEWID(),NEWID(),RAND()*100,RAND()*100, DATEADD(MI,@i,GETDATE()),DATEADD(MI,@i,GETDATE()),NEWID(),NEWID(),NEWID() ) set @i=@i+1 end
現在有這麼一個查詢(實際上查詢遠比這個複雜,我簡化一點,不要說我刻意造環境)
select OtherColumn2, BuniessStatus1, BuniessStatus2, BuniessDateTime1, BuniessDateTime2 from BusinessInfoTable where BuniessDateTime1 between '2016-6-21' and '2016-6-28' and BuniessDateTime2 between '2016-6-21' and '2016-6-28' and BuniessStatus1 = 55 and BuniessStatus2 = 66
鄭重的說明一點:
暫時不考慮聚集索引,畢竟一個表上只能有一個聚集索引,
別人也不是傻子,不會輕易去建聚集索引,聚集索引早被占用了
既然被占用了,我的原則是一般不去動別人現有的東西的,比如別人建了聚集索引,你給人家刪了,根據自己的情況建聚集索引
這不是找罵麽
有經驗的你一定考慮符合索引了,同時考慮到為避免Key Lookup導致的書簽查找,我們把查詢索要的OtherColumn2列include進來
比如這樣
CREATE NONCLUSTERED INDEX IDX_1 ON BusinessInfoTable (BuniessStatus1,BuniessStatus2,BuniessDateTime1,BuniessDateTime2) INCLUDE(OtherColumn2)
或者這樣,只是索引列順序不一樣
CREATE NONCLUSTERED INDEX IDX_1 ON BusinessInfoTable (BuniessDateTime1,BuniessDateTime2,BuniessStatus1,BuniessStatus2) INCLUDE(OtherColumn2)
當然可以隨意調整四個列的順序,我就不過多地做演示了,有興趣的自己試
這裡的前導列的順序並不會影響到索引的使用,查詢的時候都是非聚集索引Seek,絕對的
那麼問題來了,完全一樣的查詢條件,結果一樣,使用不同的索引,索引的區別僅僅是列順序不一樣,其代價一樣嗎,先猜測一下,有區別嗎?
同樣查詢,使用不同索引的結果(分別是上面的IDX_1和IDX_2):
下麵看圖說話
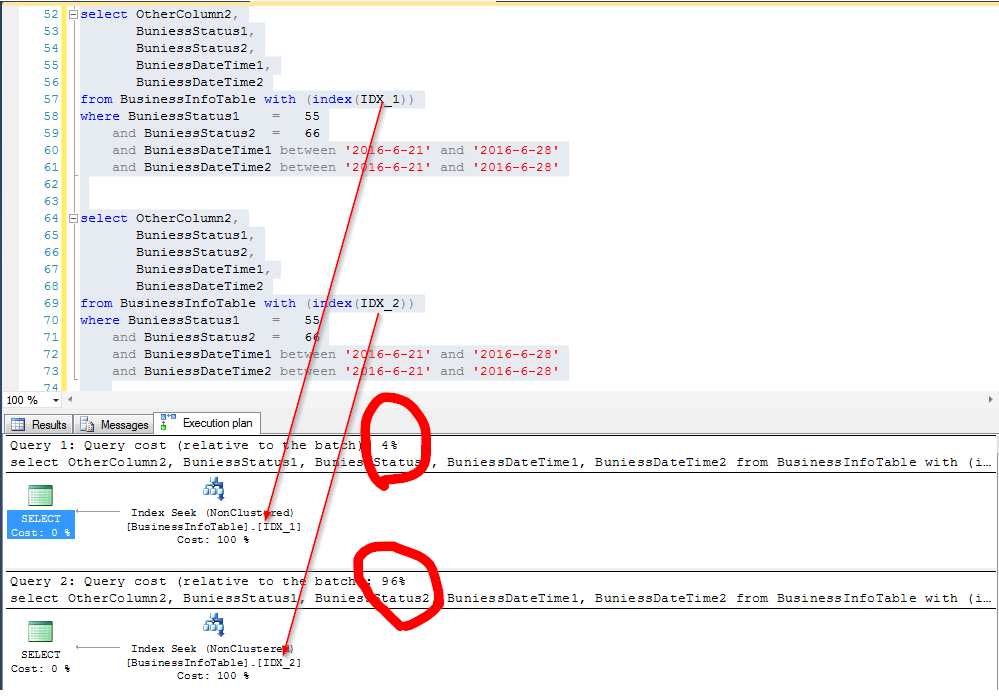
看看IO情況
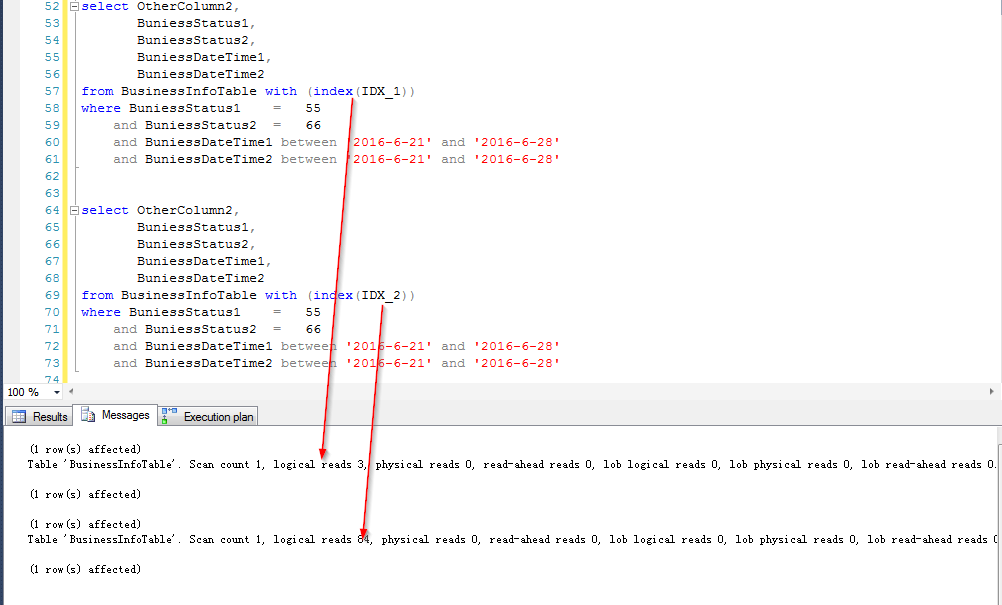
原因分析
看來是有點差別吧,好似乎這個差別還真不小(以往寫文章,我測試環境弄不好,對比出來的效果不明顯,感覺沒啥說服力,這次對比還是比較明顯的)
究竟原因在何?
索引是以平衡樹(B樹)的方式存在的,複合索引的列的順序決定了B樹的信息的存儲的順序
如果是以BuniessStatus1列為前導列,因為BuniessStatus1分佈的範圍(相對)較小,
這樣在查詢的時候通過BuniessStatus1=55就可以過濾出來一個比較小的結果集,後面依次用其他條件過濾就相對較快了
比如BuniessStatus1=55過濾出來符合條件的數據有5條,
加上BuniessStatus2 BuniessDateTime1 BuniessDateTime2 這三個條件再過濾,出來一條數據。
如果BuniessDateTime1 是索引的前導列,用BuniessDateTime1 between '2016-6-21' and '2016-6-28'過濾
可能會有10000條數據,然後依次再用 BuniessDateTime2,BuniessStatus1, BuniessStatus2過濾
最後也只有一條符合條件的數據。
差別就在於:一開始的過濾條件,決定了查詢多少page初步確定滿足條件的數據,再進一步的進行過濾
如果最開始就相對精確地確定了滿足查詢條件的數據範圍,後面可以通過相對較小的代價來最終確認出滿足條件的數據
如果最開始相對模糊地卻確定了滿足查詢條件的數據範圍,那麼這個過程的代價就相對比較大,雖然後面通過每一個條件的過,結果是一樣的
當然這種索引的建立跟數據分佈有關,
但是,我沒有下結論說,複合索引一定要按照什麼什麼順序來是最好的
還是那句話:具體問題具體分析,避免經驗主義,沒有一刀切的手段可以解決所有的問題。
總結:
本文通過一個簡單的例子,分析了創建符合索引時,列的順序對查詢的影響,說明在創建索引的時候,不僅僅要考慮在哪些列上創建索引,同時也要註意到,索引列的順序,是否會對查詢產生影響。避免一說到索引,就是“在查詢條件上建索引”的暴力做法。


