
一、使用VMware安裝Ubuntu虛擬機 在Linux系統各個發行版中,Ubuntu系統在服務端和桌面端使用占比最高,網路上資料最是齊全,所以這裡使用Ubuntu LTS。 整體的系統安裝文件較大(>1G),這裡採用了迅雷加速下載。迅雷下載地址:下載迅雷工具 下載地址:Download Ubunt ...
一、使用VMware安裝Ubuntu虛擬機
在Linux系統各個發行版中,Ubuntu系統在服務端和桌面端使用占比最高,網路上資料最是齊全,所以這裡使用Ubuntu LTS。
整體的系統安裝文件較大(>1G),這裡採用了迅雷加速下載。迅雷下載地址:下載迅雷工具
下載地址:Download Ubuntu Desktop。
對於虛擬機,這裡採用VMware,因為在諸多免費軟體裡面VMware是最好用的。
VMware 官網鏈接 https://www.vmware.com/
使用版本:VMware Workstation 16 Pro
百度一個秘鑰就好了,有很多可以查得到的。
推薦可以再下個Xshell用於操作終端。
Xshell免費版官網下載地址:https://www.xshell.com/zh/free-for-home-school/
這裡採用的是來自CSDN博客的流程,圖文相當詳細所以就不再繼續贅述。
唯一需要強調一下的是在“13. 設置磁碟容量,並選擇 "將虛擬磁碟拆分成多個文件" 。(這裡的磁碟大小看個人需求,大於等於推薦的大小)”時,可以將磁碟大小調大一點,像我這裡選擇的是80GB,這並不是意味著會馬上占用你電腦80GB,而是一個類似上限的意思,這東西初始設置好改,後面不夠用了就很麻煩,所以初始給多一點。
二、偽分散式平臺搭建
Part1: 準備工作
首先按 ctrl+alt+t 打開終端視窗,輸入如下命令創建新用戶 。這條命令創建了可以登陸的 hadoop 用戶,並使用 /bin/bash 作為 shell。
sudo useradd -m hadoop -s /bin/bash
- sudo命令: 本文中會大量使用到sudo命令。sudo是ubuntu中一種許可權管理機制,管理員可以授權給一些普通用戶去執行一些需要root許可權執行的操作。當使用sudo命令時,就需要輸入您當前用戶的密碼。
接著使用如下命令設置密碼,如果提示密碼過於簡單可以無視,只要兩次相同即可:
sudo passwd hadoop
可為 hadoop 用戶增加管理員許可權,方便部署:
sudo adduser hadoop sudo
然後切換到新建的hadoop用戶下:
su hadoop
更新 apt,在 Ubuntu 中使用 apt 來下載安裝軟體,如果沒更新可能有一些軟體安裝不了。
sudo apt-get update
按照下圖依次點擊 ① ②:

選擇“其他”然後選擇阿裡雲鏡像伺服器。這等效於我們平時在 Windows 系統下安裝 python 包時使用清華鏡像站。
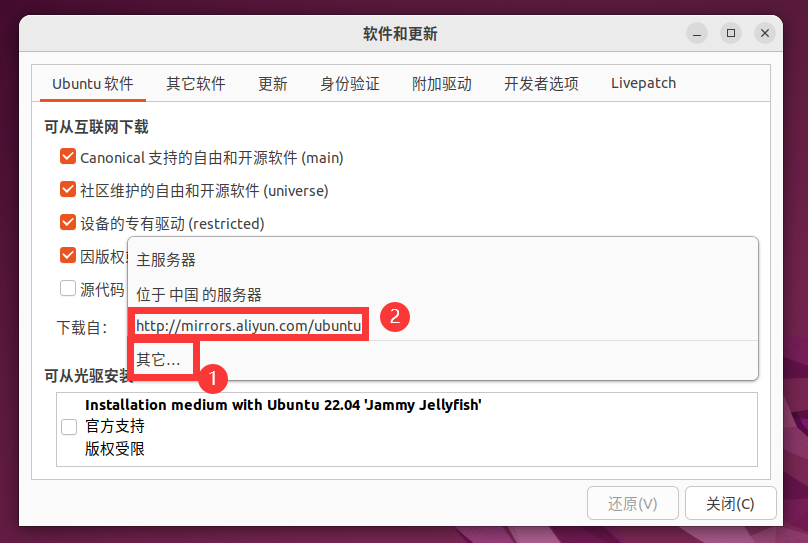
選擇關閉後會提醒你信息過時
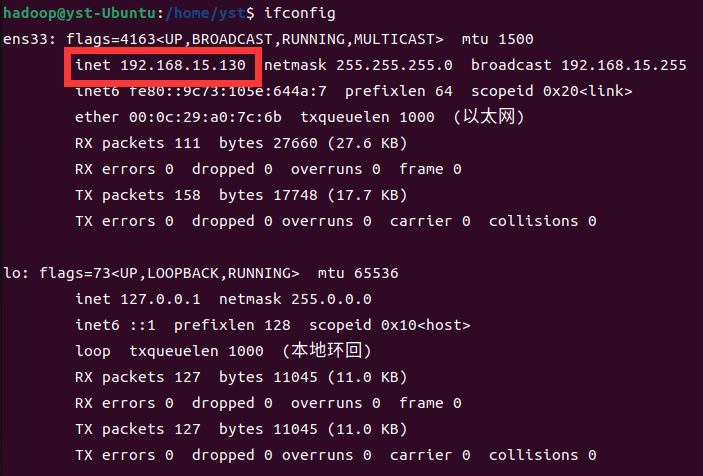
後續操作將不再需要圖形化界面,故建議使用 xshell 軟體,下麵演示一下,如不需要可以直接跳轉至Part2。
- step1:查詢本機的ip地址:
- step2:建立Windows與虛擬機的連接。
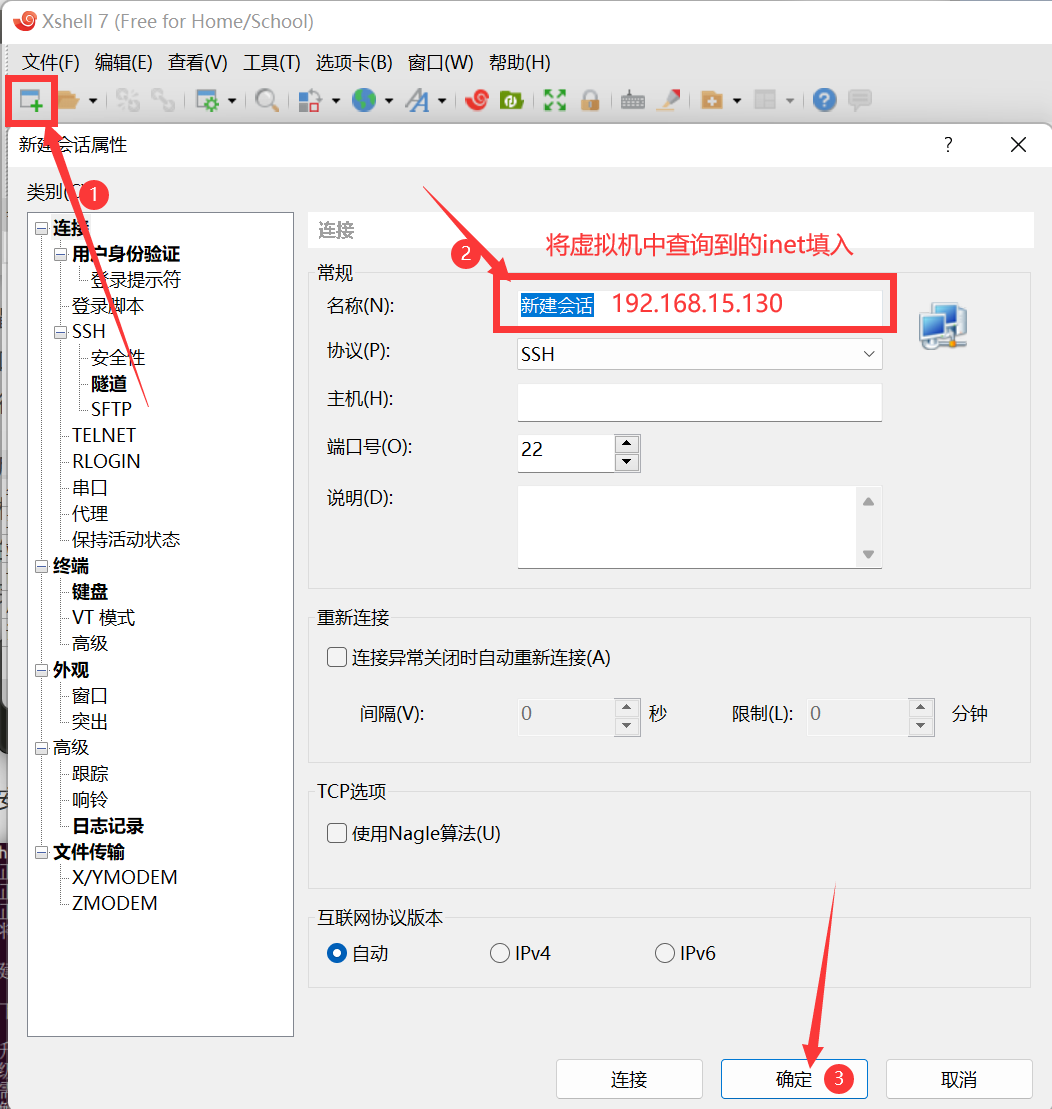
- step3:連接建議勾選“記住用戶名”“記住密碼”

Part2: SSH無密碼登錄配置
安裝vim,提示時按y即可:
sudo apt-get install vim
安裝SSH,配置無密碼登錄:
sudo apt-get install openssh-server
SSH首次登陸提示),輸入 yes 。然後按提示輸入密碼,利用 ssh-keygen 生成密鑰,並將密鑰加入到授權中:
ssh localhost exit cd ~/.ssh/ # 若沒有該目錄,再執行一次ssh localhost ssh-keygen -t rsa # 會有提示,都按回車就可以 cat ./id_rsa.pub >> ./authorized_keys # 加入授權
此時再用 ssh localhost 命令,無需輸入密碼就可以直接登錄了。
Part3: JDK的安裝與配置
我們需要先將 JDK1.8 (目前企業中主流的 java 版本仍然是 jdk1.8)下載到電腦。
然後將文件上傳到 Ubuntu 中,這裡我採用的是 rz 的上傳方式,需要借用 xshell 工具。
cd ~ sudo mkdir Downloads # 創建 ~/Downloads 目錄用來存放下載的文件 cd Downloads # 進入目標目錄 rz # 上傳文件到 Ubuntu 系統中
解壓 JDK 文件:
cd /usr/lib sudo mkdir jvm # 創建/usr/lib/jvm目錄用來存放JDK文件 cd ~ # 進入hadoop用戶的主目錄 cd Downloads sudo tar -zxvf ./jdk-8u162-linux-x64.tar.gz -C /usr/lib/jvm # 把JDK文件解壓到 /usr/lib/jvm 目錄下
配置環境變數:
cd ~
vim ~/.bashrc
在文件中輸入以下內容後,按 Esc 鍵,輸入“:wq”保存並退出
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_162 export JRE_HOME=${JAVA_HOME}/jre export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib export PATH=${JAVA_HOME}/bin:$PATH
執行如下命令讓.bashrc文件的配置立即生效:
source ~/.bashrc
驗證環境變數是否生效:
java -version
如果能夠在屏幕上返回如下信息,則說明安裝成功:

Part4: Hadoop的安裝與配置
首先,你需要下載一個 hadoop-3.3.4.tar.gz(這是一個官網鏈接),當然你也可以下載 3.1.3 的版本,這並沒有很大的改變。
然後使用同樣的方法將文件上傳到 Ubuntu 中。
cd ~/Downloads # 進入目標目錄 rz # 上傳文件到 Ubuntu 系統中
將 Hadoop 安裝至 /usr/local/ 中:
sudo tar -zxvf ~/Downloads/hadoop-3.3.4.tar.gz -C /usr/local # 解壓到/usr/local中 cd /usr/local/ sudo mv ./hadoop-3.3.4/ ./hadoop # 將文件夾名改為hadoop sudo chown -R hadoop ./hadoop # 修改文件許可權
驗證 hadoop 是否安裝成功:
cd /usr/local/hadoop
bin/hadoop version
如果能夠在屏幕上返回如下信息,則說明安裝成功:

Part5: Hadoop偽分散式的搭建
Hadoop 的配置文件位於 /usr/local/hadoop/etc/hadoop/ 中,偽分散式需要修改2個配置文件 core-site.xml 和 hdfs-site.xml 。Hadoop的配置文件是 xml 格式,每個配置以聲明 property 的 name 和 value 的方式來實現。
修改配置文件 core-site.xml
vim etc/hadoop/core-site.xml
將原先的<configuration></configuration>改為下麵的內容:
<configuration> <property> <name>hadoop.tmp.dir</name> <value>file:/usr/local/hadoop/tmp</value> <description>Abase for other temporary directories.</description> </property> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> </configuration>
修改配置文件 hdfs-site.xml:
vim etc/hadoop/hdfs-site.xml
將原先的<configuration></configuration>改為下麵的內容:
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/usr/local/hadoop/tmp/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/usr/local/hadoop/tmp/dfs/data</value> </property> </configuration>
配置完成後,執行 NameNode 的格式化:
cd /usr/local/hadoop
bin/hdfs namenode -format
成功格式化返回樣例(部分):
STARTUP_MSG: Starting NameNode STARTUP_MSG: host = hadoop/127.0.1.1 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 3.3.4
如果在這一步時提示 Error: JAVA_HOME is not set and could not be found. 的錯誤,首先你要確定前面關於JDK的環境變數配置文件中沒有出現問題。然後,到hadoop的安裝目錄修改配置文件“/usr/local/hadoop/etc/hadoop/hadoop-env.sh”,在裡面找到“export JAVA_HOME=${JAVA_HOME}”這行,然後,把它修改成JAVA安裝路徑的具體地址,比如,“export JAVA_HOME=/usr/lib/jvm/default-java”,再次啟動Hadoop。
接著開啟 NameNode 和 DataNode 守護進程:
cd /usr/local/hadoop sbin/start-all.sh #start-all.sh是個可執行文件,中間沒有空格
對於偽分散式可以用 start-dfs.sh 啟動hadoop,等效於前面的 start-all.sh。
如果啟動 Hadoop 時遇到輸出非常多“ssh: Could not resolve hostname xxx”的異常情況,可通過設置 Hadoop 環境變數來解決。首先按鍵盤的 ctrl + c 中斷啟動,然後在 ~/.bashrc 中,增加如下兩行內容(設置過程與 JAVA_HOME 變數一樣,其中 HADOOP_HOME 為 Hadoop 的安裝目錄):
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
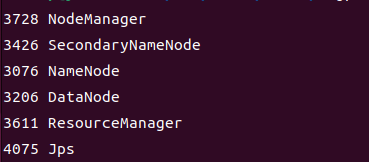
啟動完成後,可以通過命令 jps 來判斷是否成功啟動,若成功啟動則會列出如下進程: "NameNode"、"DataNode" 和 "SecondaryNameNode"(如果 SecondaryNameNode 沒有啟動,請運行 sbin/stop-all.sh 關閉進程,然後再次嘗試啟動嘗試)。如果沒有 NameNode 或 DataNode ,那就是配置不成功,請仔細檢查之前步驟。由於我前面執行的命令為 start-all.sh,所以是下麵這個樣子。
成功啟動後,可以訪問 Web 界面 http://localhost:9870 (由於hadoop版本不同,可能你需要訪問的埠號是50070)以及 http://localhost:8088 查看 NameNode 和 Datanode 信息,還可以線上查看 HDFS 中的文件。
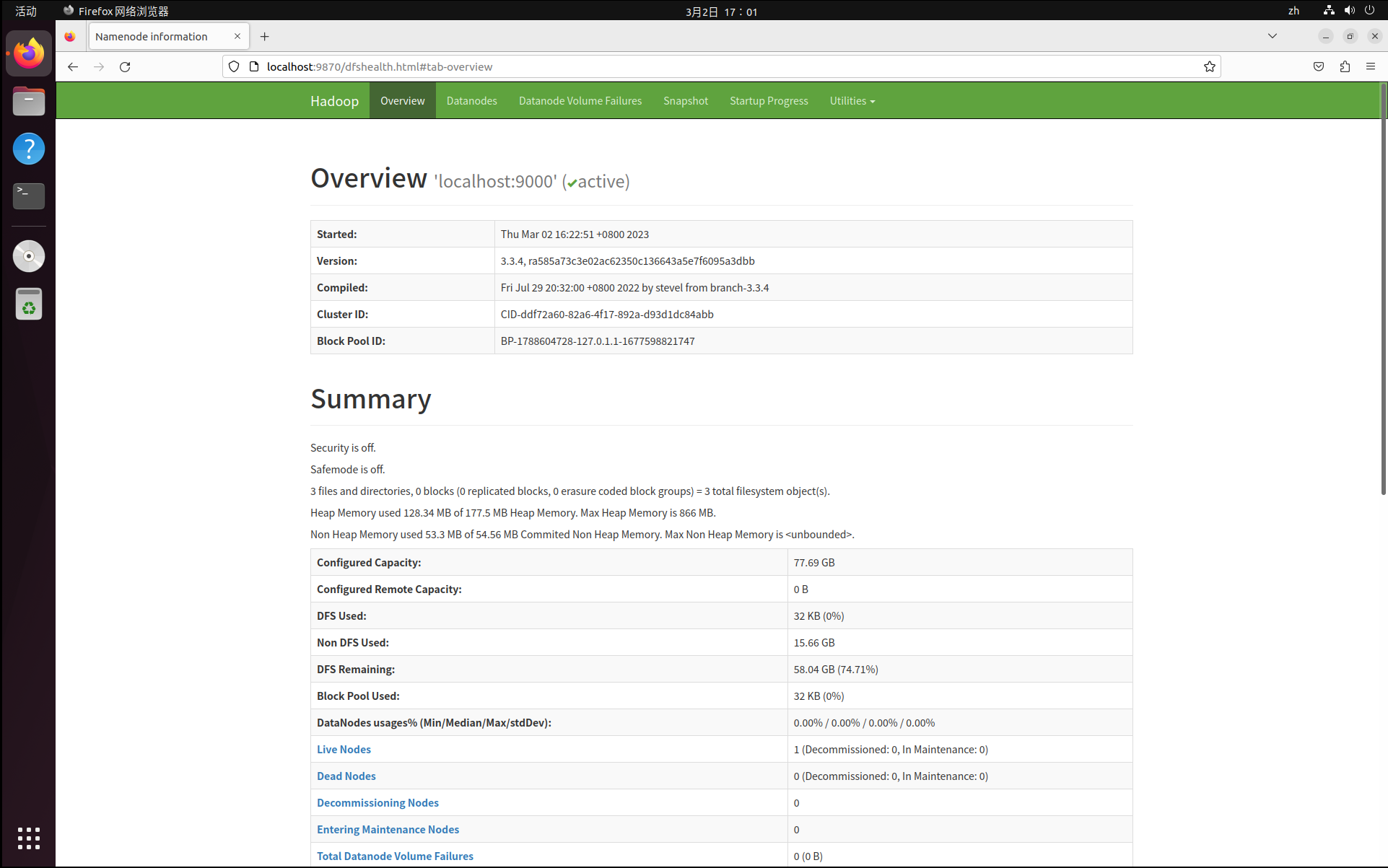
偽分散式到此就搭建完成啦!
下麵會再補充一些報錯以及解決方案
(1)若是 DataNode 沒有啟動,可嘗試如下的方法(註意這會刪除 HDFS 中原有的所有數據,如果原有的數據很重要請不要這樣做)
cd /usr/local/hadoop
sbin/stop-all.sh # 關閉
rm -r ./tmp # 刪除 tmp 文件,註意這會刪除 HDFS 中原有的所有數據
./bin/hdfs namenode -format # 重新格式化 NameNode
sbin/start-all.sh # 啟動
(2)解決 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable警告問題
vim ~/.bashrc
# 添加以下內容
export JAVA_LIBRARY_PATH=/usr/local/hadoop/lib/native
然後重新應用環境變數
source ~/.bashrc
(3)當遇到9870埠被占用的問題時,可以通過更改啟動時的埠號來實現啟動,記得先通過 sbin/stop-dfs.sh 關閉服務,然後更改前面的 core-site.xml 文件,往裡面添加以下內容到<configuration></configuration>中間
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>localhost:50090</value>
</property>
(4)無法訪問網站,這可能是Linux中的防火牆未關閉的問題:
sudo ufw status # 查看防火牆狀態
sudo ufw disable # 關閉防火牆
啊,好累,這篇寫了巨久
整理:BDT20040


