
閱識風雲是華為雲信息大咖,擅長將複雜信息多元化呈現,其出品的一張圖(雲圖說)、深入淺出的博文(雲小課)或短視頻(雲視廳)總有一款能讓您快速上手華為雲。更多精彩內容請單擊此處。 摘要:Flink是一個批處理和流處理結合的統一計算框架,其核心是一個提供了數據分發以及並行化計算的流數據處理引擎。它的最大亮 ...
閱識風雲是華為雲信息大咖,擅長將複雜信息多元化呈現,其出品的一張圖(雲圖說)、深入淺出的博文(雲小課)或短視頻(雲視廳)總有一款能讓您快速上手華為雲。更多精彩內容請單擊此處。

摘要:Flink是一個批處理和流處理結合的統一計算框架,其核心是一個提供了數據分發以及並行化計算的流數據處理引擎。它的最大亮點是流處理,是業界最頂級的開源流處理引擎。
本文分享自華為雲社區《【雲小課】EI第44課 MRS基礎原理之Flink組件介紹》,作者:閱識風雲。
Flink是一個批處理和流處理結合的統一計算框架,其核心是一個提供了數據分發以及並行化計算的流數據處理引擎。它的最大亮點是流處理,是業界最頂級的開源流處理引擎。
Flink最適合的應用場景是低時延的數據處理(Data Processing)場景:高併發pipeline處理數據,時延毫秒級,且兼具可靠性。

本課程為您介紹華為雲MapReduce服務中Flink服務的基本原理介紹並展示如何通過MRS集群客戶端提交Flink作業。
圖1 Flink技術棧
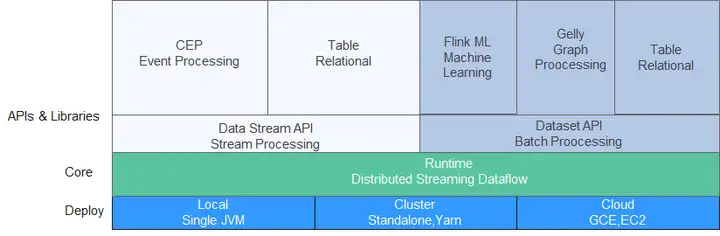
Flink重點構建如下特性:
- DataStream
- Checkpoint
- 視窗
- Job Pipeline
- 配置表
Flink結構
Flink結構如下圖所示。
圖2 Flink結構
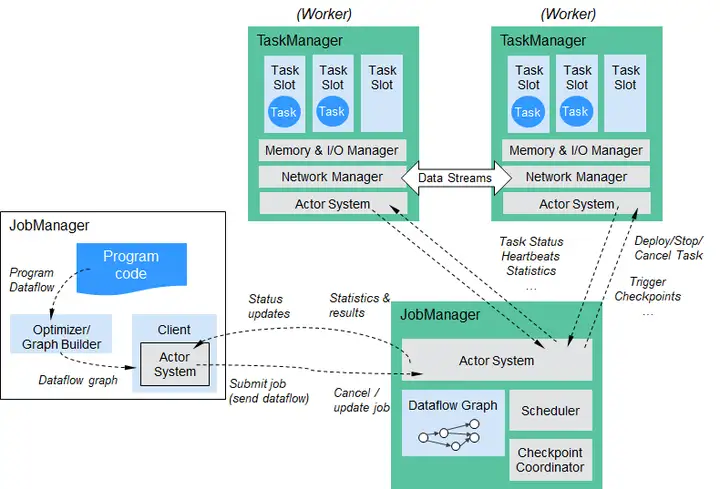
Flink整個系統包含三個部分:
- Client
Flink Client主要給用戶提供向Flink系統提交用戶任務(流式作業)的能力。
- TaskManager
Flink系統的業務執行節點,執行具體的用戶任務。TaskManager可以有多個,各個TaskManager都平等。
- JobManager
Flink系統的管理節點,管理所有的TaskManager,並決策用戶任務在哪些Taskmanager執行。JobManager在HA模式下可以有多個,但只有一個主JobManager。
MRS Flink關鍵特性
- 流式處理
高吞吐、高性能、低時延的實時流處理引擎,能夠提供ms級時延處理能力。 - 豐富的狀態管理
流處理應用需要在一定時間記憶體儲所接收到的事件或中間結果,以供後續某個時間點訪問併進行後續處理。Flink提供了豐富的狀態管理相關的特性支持,其中包括 - 多種基礎狀態類型:Flink提供了多種不同數據結構的狀態支持,如ValueState、ListState、MapState等。用戶可以基於業務模型選擇最高效、合適狀態類型。
- 豐富的State Backend:State Backend負責管理應用程式的狀態,並根據需要進行Checkpoint。Flink提供了不同State Backend,State可以存儲在記憶體上或RocksDB等上,並支持非同步以及增量的Checkpoint機制。
- 精確一次語義:Flink的Checkpoint和故障恢復能力保證了任務在故障發生前後的應用狀態一致性,為某些特定的存儲支持了事務型輸出的功能,即使在發生故障的情況下,也能夠保證精確一次的輸出。
- 豐富的時間語義支持
時間是流處理應用的重要組成部分,對於實時流處理應用來說,基於時間語義的視窗聚合、檢測、匹配等運算是非常常見的。Flink提供了豐富的時間語義支持。 - Event-time:使用事件本身自帶的時間戳進行計算,使亂序到達或延遲到達的事件處理變得更加簡單。
- Watermark支持:Flink引入Watermark概念,用以衡量事件時間的發展。Watermark也為平衡處理時延和數據完整性提供了靈活的保障。當處理帶有Watermark的事件流時,在計算完成之後仍然有相關數據到達時,Flink提供了多種處理選項,如將數據重定向(side output)或更新之前完成的計算結果。
- Processing-time和Ingestion-time支持。
- 高度靈活的流式視窗支持:Flink能夠支持時間視窗、計數視窗、會話視窗,以及數據驅動的自定義視窗,可以通過靈活的觸發條件定製,實現複雜的流式計算模式。
- 容錯機制
分散式系統,單個task或節點的崩潰或故障,往往會導致整個任務的失敗。Flink提供了任務級別的容錯機制,保證任務在異常發生時不會丟失用戶數據,並且能夠自動恢復。 - Checkpoint:Flink基於Checkpoint實現容錯,用戶可以自定義對整個任務的Checkpoint策略,當任務出現失敗時,可以將任務恢復到最近一次Checkpoint的狀態,從數據源重發快照之後的數據。
- Savepoint:一個Savepoint就是應用狀態的一致性快照,Savepoint與Checkpoint機制相似,但Savepoint需要手動觸發,Savepoint保證了任務在升級或遷移時,不丟失掉當前流應用的狀態信息,便於任何時間點的任務暫停和恢復。
- Flink SQL
Table API和SQL藉助了Apache Calcite來進行查詢的解析,校驗以及優化,可以與DataStream和DataSet API無縫集成,並支持用戶自定義的標量函數,聚合函數以及表值函數。簡化數據分析、ETL等應用的定義。下麵代碼實例展示瞭如何使用Flink SQL語句定義一個會話點擊量的計數應用。
SELECT userId, COUNT(*) FROM clicks GROUP BY SESSION(clicktime, INTERVAL '30' MINUTE), userId
- CEP in SQL
Flink允許用戶在SQL中表示CEP(Complex Event Processing)查詢結果以用於模式匹配,併在Flink上對事件流進行評估。
CEP SQL 通過MATCH_RECOGNIZE的SQL語法實現。MATCH_RECOGNIZE子句自Oracle Database 12c起由Oracle SQL支持,用於在SQL中表示事件模式匹配。CEP SQL使用舉例如下:
SELECT T.aid, T.bid, T.cid FROM MyTable MATCH_RECOGNIZE ( PARTITION BY userid ORDER BY proctime MEASURES A.id AS aid, B.id AS bid, C.id AS cid PATTERN (A B C) DEFINE A AS name = 'a', B AS name = 'b', C AS name = 'c' ) AS T
如何使用Flink客戶端
購買一個包含Flink組件的MRS集群,MRS集群的創建可參考MRS快速入門的“創建集群”章節,例如購買一個MRS 3.1.0集群,未開啟了Kerberos認證。
1.集群正常運行後,安裝集群客戶端,例如安裝目錄為“/opt/hadoopclient”。Flink客戶端的安裝可以參考MRS用戶指南的“安裝客戶端”章節。
2.以客戶端安裝用戶,登錄安裝客戶端的節點。
3.執行以下命令,切換到客戶端安裝目錄。
cd /opt/hadoopclient
source bigdata_env
4.運行wordcount作業。
方式1:執行如下命令啟動session,併在session中提交作業。
yarn-session.sh -nm "session-name" flink run /opt/hadoopclient/Flink/flink/examples/streaming/WordCount.jar
方式2:執行如下命令在Yarn上提交單個作業。
flink run -m yarn-cluster /opt/hadoopclient/Flink/flink/examples/streaming/WordCount.jar
5.作業提交成功後,客戶端界面顯示如下。
圖3 在Yarn上提交作業成功

圖4 啟動session成功

圖5 在session中提交作業成功

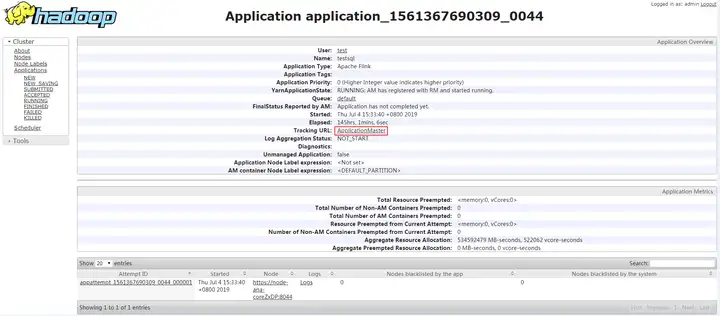
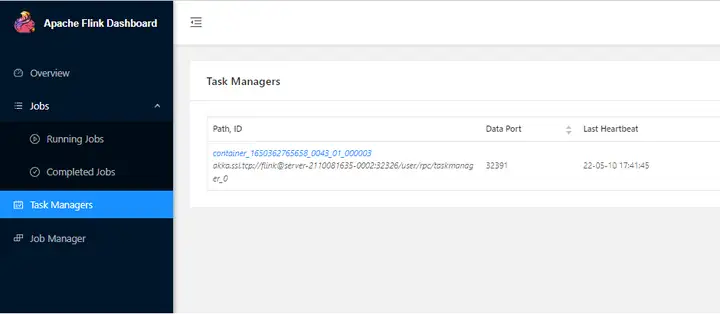
6.使用運行用戶登錄MRS集群的FusionInsight Manager界面,單擊“集群 > 服務 > Yarn”,單擊“ResourceManager WebUI”後的鏈接,進入Yarn服務的原生頁面,找到對應作業的application,單擊application名稱,進入到作業詳情頁面。
- 若作業尚未結束,可單擊“Tracking URL”鏈接進入到Flink的原生頁面,查看作業的運行信息。
- 若作業已運行結束,對於在session中提交的作業,可以單擊“Tracking URL”鏈接登錄Flink原生頁面查看作業信息。
圖6 application
好了,本期雲小課就介紹到這裡,快去體驗MapReduce(MRS)更多功能吧!猛戳這裡


