
前言 用過Lucene.net的都知道,我們自己搭建索引伺服器時和解決搜索匹配度的問題都用到過盤古分詞。其中包含一個詞典。 那麼既然用到了這種國際化的框架,那麼就避免不了中文分詞。尤其是國內特殊行業比較多。比如油田系統從勘探、打井、投產等若幹環節都涉及一些專業辭彙。 再像電商,手機、手機配件、筆記本 ...
前言
用過Lucene.net的都知道,我們自己搭建索引伺服器時和解決搜索匹配度的問題都用到過盤古分詞。其中包含一個詞典。 那麼既然用到了這種國際化的框架,那麼就避免不了中文分詞。尤其是國內特殊行業比較多。比如油田系統從勘探、打井、投產等若幹環節都涉及一些專業辭彙。 再像電商,手機、手機配件、筆記本、筆記本配件之類。汽車,品牌、車系、車型等等,這一系列數據背後都涉及各自領域的專業名次,所以中文分詞就最終的目的還是為瞭解決搜索結果的精確度和匹配度的問題。
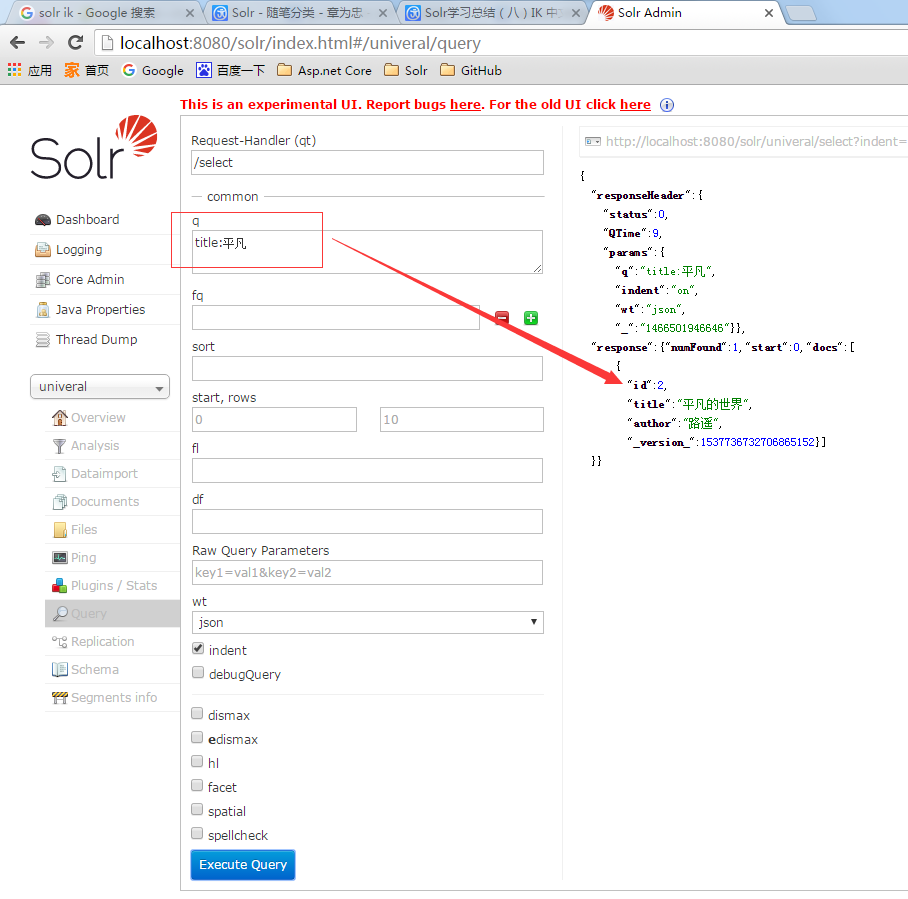
IK搜索預覽
我的univeral Core里包含兩條數據,第二條數據的title和author都是中文的。 然後我用關鍵字q=title:平凡來搜索,搜索出來第二條數據。 如果你在你的索引庫里沒搜索出來也不要奇怪,配置下IK中文分詞就可以了。
中文語義分析
在索引庫Core左側菜單Analysis中,你可以輸入複雜的查詢【關鍵字】,選擇對應欄位,點擊【Analysis Values】會幫你分析出當前這個複雜的片語都會分解出那幾個搜索關鍵字或關鍵詞來。如果這裡滿足不了你的專業辭彙,那就該從詞典下手了。我這裡輸入了:平凡的世界。分析後得出兩個詞:平凡、世界。 也就是我在上一張圖中用平凡搜索的結果。

中文分詞的配置和使用
1、下載對應IK版本。我本地部署的Solr5.5.1。 所以就下載最新版本。
2、把ik目錄下的文件複製到tomcat/webapps/solr/WEB-INF/lib目錄下。 ik目錄里有一個ext.dic、stopword.dic。 可以打開看一看裡面內容。
3、修改schema.xml。我本地是univeral/conf/managed-schema。 增加中文分詞配置節點,內容如下
<fieldType name="text_ik" class="solr.TextField"> <analyzer type="index" isMaxWordLength="false" class="org.wltea.analyzer.lucene.IKAnalyzer"/> <analyzer type="query" isMaxWordLength="true" class="org.wltea.analyzer.lucene.IKAnalyzer"/> </fieldType>
4、修改對應field的類型。我修改了兩個欄位
<field name="title" type="text_ik" indexed="true" stored="true" required="true" multiValued="false" /> <field name="author" type="text_ik" indexed="true" stored="true" required="true" multiValued="false" />
參考教程:http://www.cnblogs.com/zhangweizhong/p/5593909.html
備註
如果之前你已經創建了索引,那麼配置IK中文分詞後先修改schema.xml中的field對應類型。 清空索引後重新創建索引。 OK。大功搞成。


