
1.簡介 1.1 gRPC的起源 RPC是Remote Procedure Call的簡稱,中文叫遠程過程調用。用於解決分散式系統中服務之間的調用問題。通俗地講,就是開發者能夠像調用本地方法一樣調用遠程的服務。所以,RPC的作用主要體現在這兩個方面: 屏蔽遠程調用跟本地調用的區別,讓我們感覺就是調用 ...
1.簡介
1.1 gRPC的起源
RPC是Remote Procedure Call的簡稱,中文叫遠程過程調用。用於解決分散式系統中服務之間的調用問題。通俗地講,就是開發者能夠像調用本地方法一樣調用遠程的服務。所以,RPC的作用主要體現在這兩個方面:
-
屏蔽遠程調用跟本地調用的區別,讓我們感覺就是調用項目內的方法;
-
隱藏底層網路通信的複雜性,讓我們更專註於業務邏輯的開發。
長期以來,谷歌有一個名為 Stubby 的通用 RPC 框架,用來連接成千上萬的微服務,這些微服務跨多個數據中心並且使用完全不同的技術來構建。
Stubby 的核心 RPC 層每秒能處理數百億次的互聯網請求。Stubby有許多很棒的特性,但無法標準化為業界通用的框架,這是因為它與谷歌內部的基礎設施耦合得過於緊密。
2015 年,谷歌發佈了開源 RPC 框架 gRPC,這個 RPC 基礎設施具有標準化、可通用和跨平臺的特點,旨在提供類似 Stubby 的可擴展性、性能和功能,但它主要面向社區。
在此之後,gRPC 的受歡迎程度陡增,很多大型公司大規模採用了gRPC,如 Netflix、Square、Lyft、Docker、CoreOS 和思科。接著,gRPC 加入了雲原生計算基金會(Cloud Native Computing Foundation,CNCF),這是最受歡迎的開源軟體基金會之一,它致力於讓雲原生計算具備通用性和可持續性。gRPC 從 CNCF 生態系統項目中獲得了巨大的發展動力。
1.2 gRPC的定義
gRPC官網地址:https://grpc.io
gRPC 是由Google開發的一個語言中立、高性能、通用的開源RPC框架,基於ProtoBuf(Protocol Buffers) 序列化協議開發,且支持眾多開發語言。面向服務端和移動端,基於 HTTP/2 設計。
在每個 gRPC 發佈版本中,字母 g 的含義都不同。比如 1.1 版本的 g 代表 good(優秀),1.2版本的 g 代表 green(綠色)。具體可以參考https://github.com/grpc/grpc/blob/master/doc/g_stands_for.md

gRPC框架是圍繞定義服務的思想,顯式定義了可以被遠程調用的方法,包括入參和出參的信息等。gRPC服務端負責這些方法的具體實現,而客戶端擁有這些方法的一個存根(stub),這樣就可以遠程調用到服務端的方法。
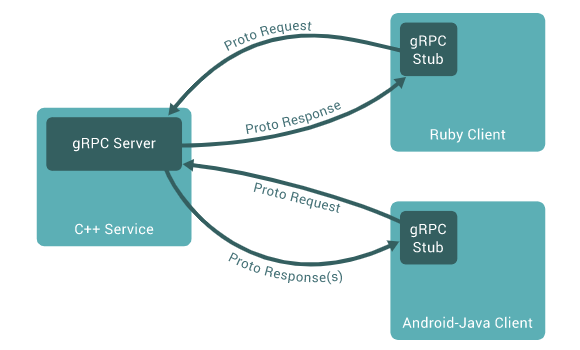
2.Quick Start
接下來,我們通過一個小例子,來感受一下gRPC的開發過程。
2.1 開發步驟
在開發 gRPC 應用程式時,先要定義服務介面,其中應包含如下信息:消費者消費服務的方式、消費者能夠遠程調用的方法以及調用這些方法所使用的參數和消息格式等。在服務定義中所使用的語言叫作介面定義語言(interface definition language,IDL)。gRPC 使用 Protocol Buffer 作為 IDL 來定義服務介面。
藉助服務定義,可以生成伺服器端代碼,也就是伺服器端骨架(skeleton) ,它通過提供低層級的通信抽象簡化了伺服器端的邏輯。同時,還可以生成客戶端代碼,也就是客戶端存根(stub),它使用抽象簡化了客戶端的通信,為不同的編程語言隱藏了低層級的通信。就像調用本地函數那樣,客戶端能夠遠程調用我們在服務介面定義中所指定的方法。底層的 gRPC 框架處理所有的複雜工作,通常包括確保嚴格的服務契約、數據序列化、網路通信、認證、訪問控制、可觀察性等。
2.2 定義Protocol Buffer
Protocol Buffer(簡稱Protobuf) 是語言中立、平臺無關、實現結構化數據序列化的可擴展機制。它就像JSON, 但比JSON體積更小,傳輸更快,具體可查閱其官網:https://developers.google.cn/protocol-buffers/docs/overview
Protobuf在 gRPC 的框架中主要有三個作用:定義數據結構、定義服務介面,通過序列化和反序列化方式提升傳輸效率。
Protobuf文件的尾碼是.proto,定義以下服務:
syntax = "proto3"; // 表示使用的protobuf版本是proto3。還有一個版本是proto2,建議使用最新版本。
import "google/protobuf/wrappers.proto";// 引入包裝類型,沒有預設值。下麵會講
option java_multiple_files = true; // 如果是false,則只生成一個java文件。反之生成多個。
option java_package = "com.khlin.grpc.proto"; // 類的包名
option java_outer_classname = "UserProto"; // 想要生成的類的名字
option objc_class_prefix = "khlin"; // 設置Objective-C類首碼,該首碼位於此.proto中所有Objective-C生成的類和枚舉之前。似乎Java沒用上。
package user; // protobuf消息類型的包類,同樣是為了防止命名衝突。
// 定義一個服務
service UserService{
// 簡單模式
rpc getUserInfo(UserRequest) returns (UserResponse);
// 客戶端流
rpc batchGetUserInfo(stream UserRequest) returns (google.protobuf.StringValue);
// 服務端流
rpc getUserInfoStream(UserRequest) returns (stream UserResponse);
// 雙向流
rpc biGetUserInfo(stream UserRequest) returns (stream UserResponse);
}
// 定義一個入參類型
message UserRequest{
string id = 1;
}
// 定義一個出參類型
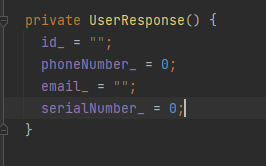
message UserResponse{
string id = 1;
int32 phoneNumber = 2; // 電話號碼
string email = 3; // 郵箱地址
int32 serialNumber = 4; // 序列號
}
下麵簡單介紹一下數據類型相關知識。
1.序號
每一個欄位被賦予了一個唯一的序號,從1開始。Protobuf是通過二進位數據的方式傳輸,所以需要知道每個位置存儲的是什麼欄位,並且建議一旦定義好就不要修改,防止引起相容性問題。
2.欄位約束
每一個欄位可以是以下一種約束:
singular proto3中的預設約束,最廣泛的約束
repeated 類比集合類型
map 類比Map類型
已經捨棄的約束:
optional proto3中捨棄,在proto2當中表示該欄位可為空
required proto3中捨棄,在proto2當中表示該欄位不能為空
3.數據類型
| .proto Type | Notes | Java/Kotlin Type |
|---|---|---|
| double | double | |
| float | float | |
| int32 | 使用變長編碼方式,不適用於負數。負數使用sint32。 | int |
| int64 | 使用變長編碼方式,不適用於負數。負數使用sint64。 | long |
| uint32 | 使用變長編碼方式 | int |
| uint64 | 使用變長編碼方式 | long |
| sint32 | 使用變長編碼。有符號的整型值。它們比普通的int32能更有效地編碼負數。 | int |
| sint64 | 使用變長編碼。有符號的整型值。它們比普通的int64能更有效地編碼負數。 | long |
| fixed32 | 固定4位元組 | int[2] |
| fixed64 | Always eight bytes. More efficient than uint64 if values are often greater than 256. | long[2] |
| sfixed32 | Always four bytes. | int |
| sfixed64 | 固定8位元組 | long |
| bool | boolean | |
| string | 字元串必須始終包含UTF-8編碼或7位ASCII文本,且長度不能超過232。 | String |
| bytes | 可以包含不超過232的任意位元組序列。 | ByteString |
具體語法查閱其官網:https://developers.google.cn/protocol-buffers/docs/proto3?hl=zh-cn
4.預設值
對於singular約束的欄位,如果沒有賦值,會賦上預設值。大部分與Java語法相同,需要註意的是string類型,它會預設賦上空字元串。可以引入 wrappers.proto,使用包裝類型。
| 類型 | 預設值 |
|---|---|
| string | 空字元串 |
| bytes | 空byte數組 |
| bool | false |
| 數值類型 | 0 |
| enums | 定義的枚舉第一個元素(預設必須為0) |
| 定義的message類型 | 不賦值 |
| repeated * | 空列表 |
這是我們定義的響應模型,可見它最終生成的string類型欄位是有預設值的。
2.3 生成存根
可以通過官方提供的編譯器,將Protobuf文件轉成相應的Java代碼。
1.獲取工具
獲取protoc軟體。用於處理proto文件的工具軟體,對proto文件生成消息對象和序列化及反序列化的Java實體類。下載地址:https://repo1.maven.org/maven2/com/google/protobuf/protoc/3.12.0/
獲取protoc-gen-grpc-java插件。用於處理rpc定義的插件,生成針對rpc定義的Java介面。下載地址:https://repo1.maven.org/maven2/io/grpc/protoc-gen-grpc-java/1.32.1/
獲取wrapper.proto。因為項目中用到了包裝類型,所以需要下載這個文件,如果沒使用到,則不需要。下載地址:https://github.com/protocolbuffers/protobuf/blob/main/src/google/protobuf/wrappers.proto
2.執行命令
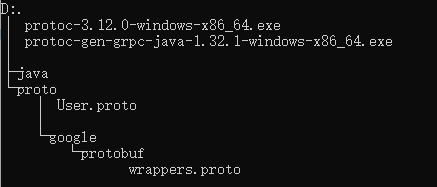
將上面獲取到的工具和User.proto文件放到同一個目錄裡面,新建一個java文件夾用於存放輸出,具體的結構如下:
CMD進入該目錄,執行以下命令
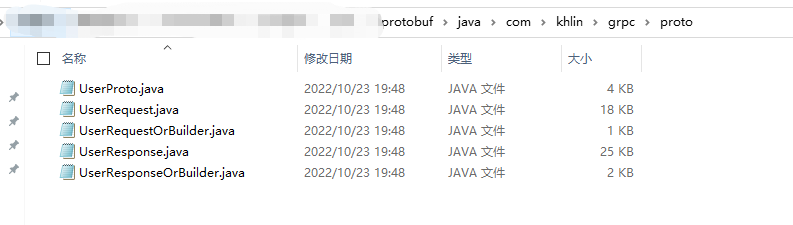
protoc-3.12.0-windows-x86_64.exe --java_out=java --proto_path=proto proto/User.proto
可以看到在這個目錄底下已經生成了相應的類。
再執行以下命令生成gRPC介面
protoc-3.12.0-windows-x86_64.exe --plugin=protoc-gen-grpc-java=protoc-gen-grpc-java-1.32.1-windows-x86_64.exe --grpc-java_out=java --proto_path=proto proto/User.proto
可以看到增加了一個類。

生成存根還可以通過Maven插件的方式,更為高效簡單。在後面介紹。
2.4 構建服務端
1. 創建Maven工程
命名為grpc-server,並引用依賴
<dependencies>
<dependency>
<groupId>io.grpc</groupId>
<artifactId>grpc-netty-shaded</artifactId>
<version>1.14.0</version>
</dependency>
<dependency>
<groupId>io.grpc</groupId>
<artifactId>grpc-protobuf</artifactId>
<version>1.14.0</version>
</dependency>
<dependency>
<groupId>io.grpc</groupId>
<artifactId>grpc-stub</artifactId>
<version>1.14.0</version>
</dependency>
</dependencies>
引入插件,就可以實現上面說的使用Maven插件生成Java類。
<build>
<extensions>
<extension>
<groupId>kr.motd.maven</groupId>
<artifactId>os-maven-plugin</artifactId>
<version>1.5.0.Final</version>
</extension>
</extensions>
<plugins>
<plugin>
<groupId>org.xolstice.maven.plugins</groupId>
<artifactId>protobuf-maven-plugin</artifactId>
<version>0.5.1</version>
<configuration>
<protocArtifact>com.google.protobuf:protoc:3.5.1-1:exe:${os.detected.classifier}</protocArtifact>
<pluginId>grpc-java</pluginId>
<pluginArtifact>io.grpc:protoc-gen-grpc-java:1.14.0:exe:${os.detected.classifier}</pluginArtifact>
</configuration>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>compile-custom</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>8</source>
<target>8</target>
</configuration>
</plugin>
</plugins>
</build>
2. Maven插件的方式生成存根
和java目錄平級的目錄下,創建一個proto文件夾,並把User.proto放進去,如下圖
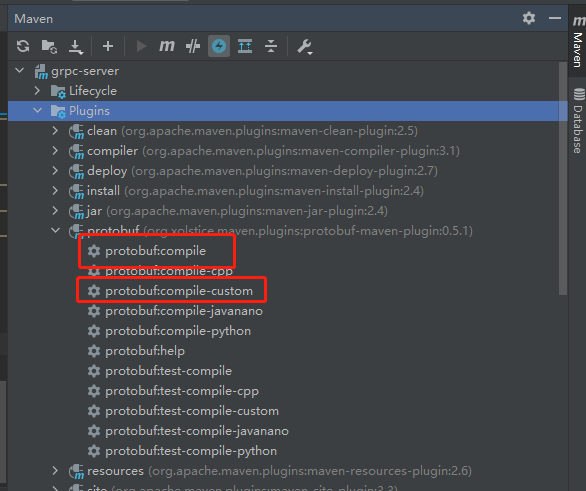
通過Maven插件的compile和compile-custom,分別生成消息對象和介面。
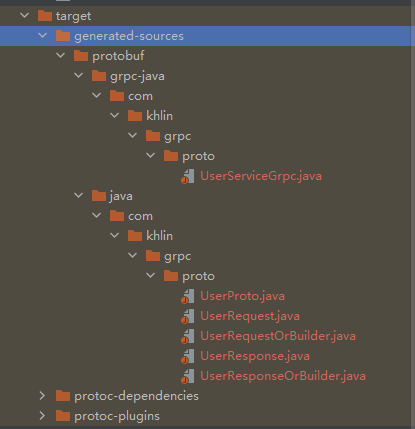
在target中就會自動生成了對應的文件,將它們移動到對應的源目錄底下即可。
3. 實現介面
具體可查閱附件工程。
public class UserService extends UserServiceGrpc.UserServiceImplBase {
/**
* 簡單模式(Unary RPCs)
*
* @param request
* @param responseObserver
*/
@Override
public void getUserInfo(UserRequest request, StreamObserver<UserResponse> responseObserver) {
System.out.println("Received message:" + request.getId());
UserResponse userResponse = createResponse(request, 1);
responseObserver.onNext(userResponse);
responseObserver.onCompleted();
}
}
4. 服務啟動
通過ServiceBuilder類,監聽一個埠,並把具體的介面加上。
package com.khlin.grpc.proto.service;
import io.grpc.Server;
import io.grpc.ServerBuilder;
import java.io.IOException;
import java.util.Objects;
public class UserServer {
private static final int PORT = 5001;
public static void main(String[] args) throws IOException, InterruptedException {
//
Server server = ServerBuilder.forPort(PORT).addService(new UserService()).build().start();
System.out.println("Server started, listening on " + PORT);
Runtime.getRuntime()
.addShutdownHook(
new Thread(
() -> {
System.err.println("Shutting down gRPC server since JVM is shutting down.");
if (Objects.nonNull(server)) {
server.shutdown();
}
System.err.println("Server shut down.");
}));
server.awaitTermination();
}
}
2.5 構建客戶端
1. 創建Maven工程
命名為grpc-client,引入同樣的依賴。
2. 引入存根
把上面生成的存根放到源代碼目錄下即可。

3. 服務啟動
創建一個ManagedChannel對象,連接服務端地址。
stub對象調用的getUserInfo方法,就是之前服務定義的同一個介面,這就實現了在遠程調用介面如同本地調用一樣的效果。
package org.example;
import com.khlin.grpc.proto.UserRequest;
import com.khlin.grpc.proto.UserResponse;
import com.khlin.grpc.proto.UserServiceGrpc;
import io.grpc.ManagedChannel;
import io.grpc.ManagedChannelBuilder;
import io.grpc.StatusRuntimeException;
import java.util.Scanner;
/**
* Hello world!
*/
public class App {
private static final String QUIT = "q";
public static void main(String[] args) {
ManagedChannel channel = ManagedChannelBuilder.forAddress("localhost", 5001).usePlaintext().build();
Scanner scanner = new Scanner(System.in);
try {
// 一元
getUserInfo(channel, scanner);
} finally {
scanner.close(); // 關閉資源
}
}
/**
* 一元模式
*
* @param channel
* @param scanner
*/
private static void getUserInfo(ManagedChannel channel, Scanner scanner) {
UserServiceGrpc.UserServiceBlockingStub stub = UserServiceGrpc.newBlockingStub(channel);
String userId = null;
do {
System.out.print("Please input user id: ");
userId = scanner.next(); // 等待輸入值
UserRequest request = UserRequest.newBuilder().setId(userId).build();
UserResponse response;
try {
response = stub.getUserInfo(request);
System.out.println("Message from gRPC-Server. Phone number: " + response.getPhoneNumber() + ", email: " + response.getEmail());
} catch (StatusRuntimeException e) {
e.printStackTrace();
}
} while (!QUIT.equals(userId)); // 如果輸入的值不版是#就繼續輸入
}
我們可以運行Demo感受一下。
3.底層原理
3.1 gRPC通信原理
要瞭解gRPC的通信原理,首先回顧一下RPC框架是怎麼工作的。在 RPC 的系統中,伺服器端會實現一組可以遠程調用的方法。客戶端會生成一個存根,該存根為伺服器端的方法提供抽象。這樣一來,客戶端應用程式可以直接調用存根方法,進而調用伺服器端應用程式的遠程方法。

gRPC 構建在兩個快速、高效的協議之上,也就是 protocol buffers 和HTTP/2。protocol buffers 是一個語言中立、平臺無關的數據序列化協議,並且提供了可擴展的機制來實現結構化數據的序列化。當序列化完成之後,該協議會生成二進位載荷,這種載荷會比常見的 JSON 載荷更小,並且是強類型的。序列化之後的二進位載荷會通過名為 HTTP/2 的二進位傳輸協議進行發送。
HTTP/2 是互聯網協議 HTTP 的第 2 個主版本。HTTP/2 是完全多路復用的,這意味著 HTTP/2 可以在 TCP 連接上並行發送多個數據請求。這樣一來,使用 HTTP/2 編寫的應用程式更快、更簡潔、更穩健。
以上諸多因素使 gRPC 成為高性能的 RPC 框架。
具體到Demo裡面的方法,一次調用的流程大體如下:

下麵,我們將介紹一下,這兩個協議是如何工作的。
3.2 HTTP/2簡介
HTTP/2 (原名HTTP/2.0)即超文本傳輸協議 2.0,是下一代HTTP協議。RFC 7540 定義了 HTTP/2 的協議規範和細節, RFC 7541定義了頭部壓縮。
1. HTTP/1的問題
TCP連接數限制
因為併發的原因一個TCP連接在同一時刻可能發送一個http請求。所以為了更快的響應前端請求,瀏覽器會建立多個tcp連接,但是第一tcp連接數量是有限制的。現在的瀏覽器針對同一功能變數名稱一般最多只能創建6~8個請求;第二創建tcp連接需要三次握手,增加耗時、cpu資源、增加網路擁堵的可能性。所以,缺點明顯。
線頭阻塞 (Head Of Line Blocking) 問題
每個 TCP 連接同時只能處理一個請求 - 響應,瀏覽器按 FIFO 原則處理請求,如果上一個響應沒返回,後續請求 - 響應都會受阻。為瞭解決此問題,出現了 管線化 - pipelining 技術,但是管線化存在諸多問題,比如第一個響應慢還是會阻塞後續響應、伺服器為了按序返回相應需要緩存多個響應占用更多資源、瀏覽器中途斷連重試伺服器可能得重新處理多個請求、還有必須客戶端 - 代理 - 伺服器都支持管線化。
Header 內容多
每次請求 Header不會變化太多,沒有相應的壓縮傳輸優化方案。特別是想cookie這種比較長的欄位
2. HTTP/2特性
首先需要瞭解幾個概念。
- 數據流: 已建立的連接內的雙向位元組流,可以承載一條或多條消息。
- 消息: 與邏輯請求或響應消息對應的完整的一系列幀。
- 幀: HTTP/2 通信的最小單位,每個幀都包含幀頭,至少也會標識出當前幀所屬的數據流。
這些概念的關係總結如下:
- 所有通信都在一個 TCP 連接上完成,此連接可以承載任意數量的雙向數據流。
- 每個數據流都有一個唯一的標識符和可選的優先順序信息,用於承載雙向消息。
- 每條消息都是一條邏輯 HTTP 消息(例如請求或響應),包含一個或多個幀。
- 幀是最小的通信單位,承載著特定類型的數據,例如 HTTP 標頭、消息負載等等。 來自不同數據流的幀可以交錯發送,然後再根據每個幀頭的數據流標識符重新組裝。

和HTTP/1的對比

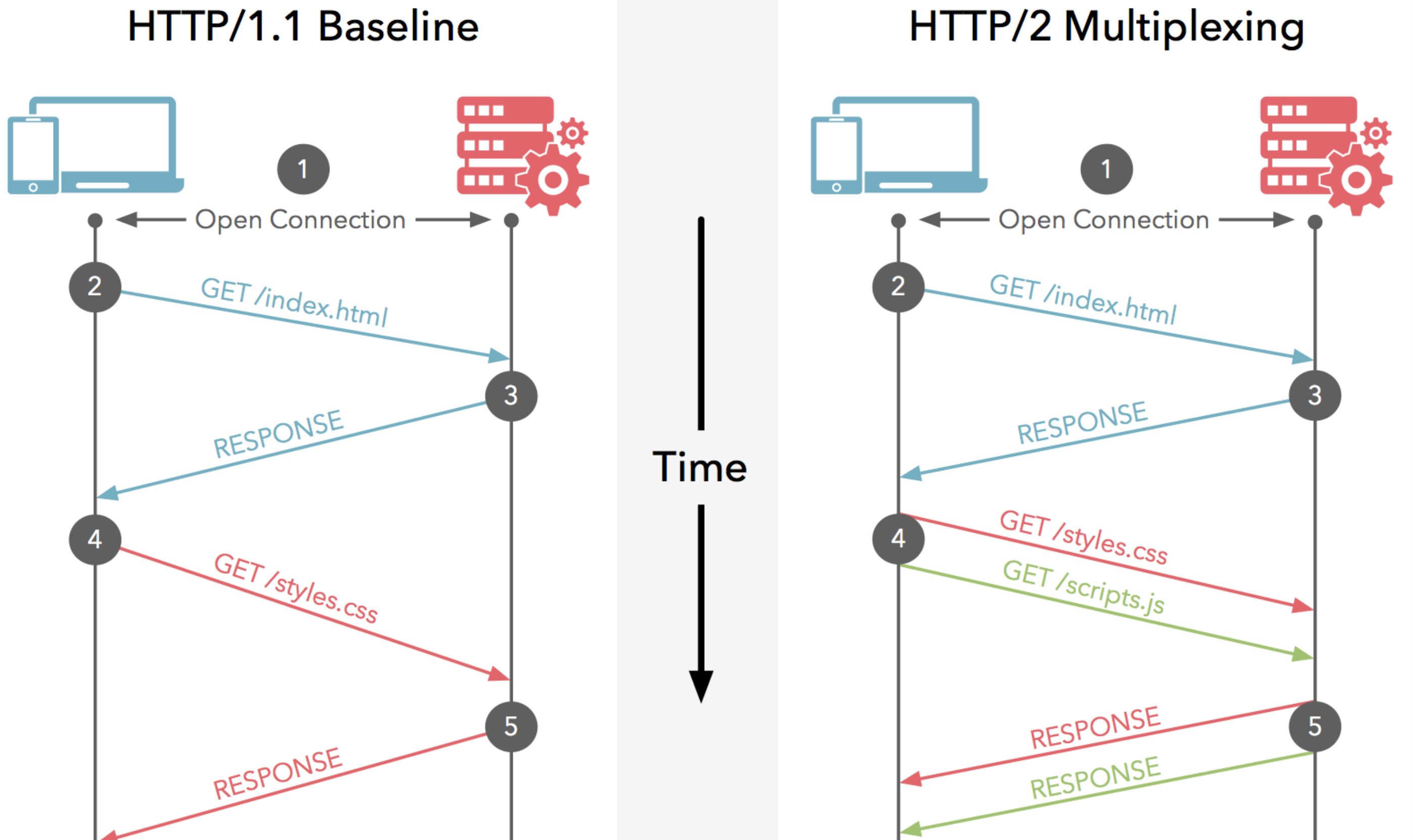
多路復用 Multiplexing
在一個 TCP 連接上,我們可以向對方不斷發送幀,每幀的 stream identifier 的標明這一幀屬於哪個流,然後在對方接收時,根據 stream identifier 拼接每個流的所有幀組成一整塊數據。
把 HTTP/1.1 每個請求都當作一個流,那麼多個請求變成多個流,請求響應數據分成多個幀,不同流中的幀交錯地發送給對方,這就是 HTTP/2 中的多路復用。
流的概念實現了單連接上多請求 - 響應並行,解決了線頭阻塞的問題,減少了 TCP 連接數量和 TCP 連接慢啟動造成的問題
所以 http2 對於同一功能變數名稱只需要創建一個連接,而不是像 http/1.1 那樣創建多個連接:
頭部壓縮
頭部壓縮採用HPACK演算法,需要在支持 HTTP/2 的瀏覽器和服務端之間:
- 維護一份相同的靜態字典(Static Table),包含常見的頭部名稱,以及特別常見的頭部名稱與值的組合;
- 維護一份相同的動態字典(Dynamic Table),可以動態地添加內容;
- 支持基於靜態哈夫曼碼表的哈夫曼編碼(Huffman Coding);
靜態字典的作用有兩個:1)對於完全匹配的頭部鍵值對,例如 :method: GET,可以直接使用一個字元表示;2)對於頭部名稱可以匹配的鍵值對,例如 cookie: xxxxxxx,可以將名稱使用一個字元表示。

具體的靜態表定義可以參考RFC7541規範 https://httpwg.org/specs/rfc7541.html#static.table.definition。

3.3 ProtoBuf編碼原理
proto消息類型文件一般以 .proto 結尾,可以在一個 .proto 文件中定義一個或多個消息類型。
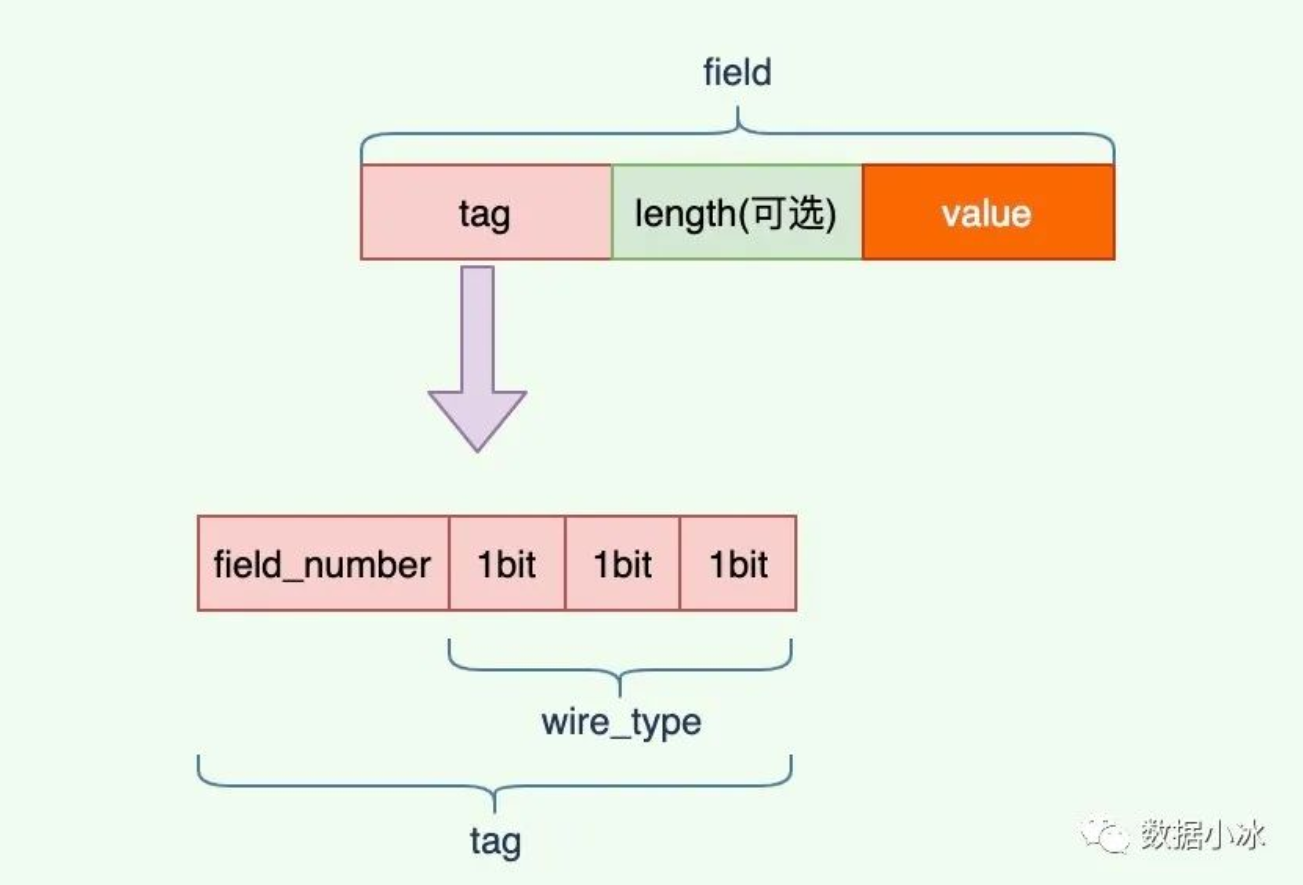
1. TLV
protobuf高效的秘密在於它的編碼格式,它採用了 TLV(tag-length-value) 編碼格式。每個欄位都有唯一的 tag 值,它是欄位的唯一標識。length 表示 value 數據的長度,length 不是必須的,對於固定長度的 value,是沒有 length 的。value 是數據本身的內容,通過解析t和l,就能明確欄位值的長度,如何解析等信息;

對於tag值,它有field_number和wire_type兩部分組成。
field_number就是在前面的message中我們給每個欄位的編號。以Demo為例,UserResponse模型中,id欄位的field_number就是1,phoneNumber就是2。
wire_type表示類型,是固定長度還是變長的。wire_type當前有0到5一共6個值,所以用3個bit就可以表示這6個值。tag結構如下圖。
它的格式是field_number<<3 | wire_type
wire_type值如下表, 其中3和4已經廢棄,我們只需要關心剩下的4種。對於Varint編碼數據,不需要存儲位元組長度length.這種情況下,TLV編碼格式退化成TV編碼。對於64-bit和32-bit也不需要length,因為type值已經表明瞭長度是8位元組還是4位元組。
我們重點關註0和2兩種編碼方式。

2. Varint
Varint顧名思義就可變的int,是一種變長的編碼方式。值越小的數字,使用越少的位元組表示,通過減少表示數字的位元組數從而進行數據壓縮。對於int32類型的數字,一般需要4個位元組表示,但是採用Varint編碼,對於小於128的int32類型的數字,用1個位元組來表示。對於很大的數字可能需要5個位元組來表示,但是在大多數情況下,消息中一般不會有很大的數字,所以採用Varint編碼可以用更少的位元組數來表示數字。
Varint是變長編碼,那它是怎麼區分出各個欄位的呢?也就是怎麼識別出這個數字是1個位元組還是2個位元組的呢?Varint通過每個位元組的最高位來標識當前位元組是否是當前整數的最後一個位元組,稱為最高有效位(most significant bit, msb)。msb 為 1 時,代表著後面還有數據;msb 為 0 時代表著當前位元組是當前整數的最後一個位元組。位元組剩餘的低7位都用來表示數字。雖然這樣每個位元組會浪費掉1bit空間,也就是1/8=12.5%的浪費,但是如果有很多數字不用固定的4位元組,還是能節省不少空間。
下麵通過一個例子來詳細學習編碼方法,我們在Demo裡面返回了一個電話號碼,固定為180,就以它為例講解。
需要說明的是,Protobuf採用的是小端模式(Little-endian),是指數據的高位元組位 保存在 記憶體的高地址中,而數據的低位元組位 保存在 記憶體的低地址中。這種存儲模式將地址的高低位和數據位有效地結合起來,高地址部分權值高,低地址部分權值低,和我們的邏輯方法一致。簡言之,低位位元組在前,高位位元組在後。
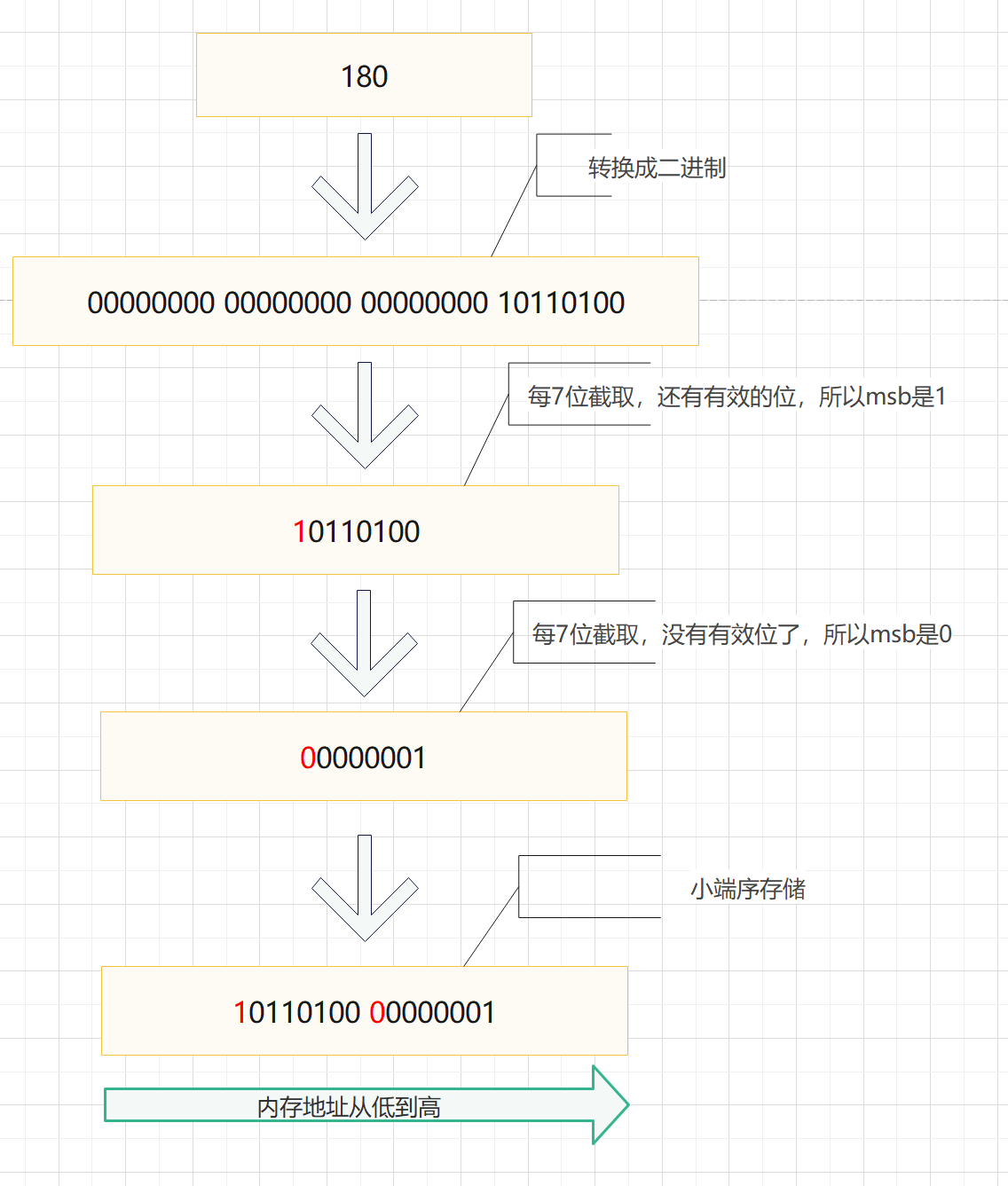
可以看到,僅需要2個位元組就可以表達180,比固定4位元組節省了2個位元組。當然,由於犧牲了1個位,如果數值大於2^28,那麼就需要5個位元組,反而多了一個位元組。因此需要評估是否會大概率出現這種情況。
在這個例子中,電話號碼field_number是2,wire_type是0,所以根據field_number<<3 | wire_type,該欄位最後變成00010000 10110100 00000001(後面會驗證)
負數的編碼需要通過ZigZag編碼,較為複雜,感興趣的同學可以查閱:https://www.cnblogs.com/en-heng/p/5570609.html
3. Length-delimited
這種類型是典型的TLV格式,T和上面的一樣,L採用varint的編碼方式,V是具體的值。
驗證一下L採用varint編碼方式,假設傳入的id大於128(保證有多個位元組),輸入130個a.
根據上面varint的分析,不難得出L編碼是:10000010 00000001。
V採用UTF-8編碼,a對應的值是97,轉換成二進位為01100001,所以一共是130個01100001。
T根據field_number<<3 | wire_type,其中field_number是1,wire_type是2,即00001010.
因此,該欄位最後變成00001010 10000010 00000001 130個01100001 (後面會驗證)
3.4 通信內容抓包
接下來,我們使用Wireshark對上面提到的例子進行網路抓包,直觀地感受和驗證一下我們的分析是否正確。
由於HTTP/2存儲的是二進位數據,並且Wireshark不知道我們的Protobuf格式,因此在操作前,需要對Wireshark做一些設置工作。可參考:wireshark支持gRPC協議 https://blog.csdn.net/luo15242208310/article/details/122909827
我們使用一元消息模式,輸入130個a,服務端將返回用戶的信息,包含電話號碼180.

我們點開發送的請求,可以看到對應的編碼如下,幀的ID是5,130個a的編碼和之前分析的一樣。頭信息里也有對應的方法信息。


我們再來看一下響應消息。可以看到,響應的幀ID也是5。對於int32類型的phoneNumber欄位,其編碼也和之前分析的一樣。



4.通信模式
在Demo里有這四種模式的演示。
4.1一元RPC模式
在一元 RPC 模式中,gRPC 伺服器端和 gRPC 客戶端的通信始終只涉及一個請求和一個響應。如下圖所示,請求消息包含頭信息,隨後是以長度作為首碼的消息,該消息可以跨一個或多個數據幀。消息最後會添加一個 EOS 標記,方便客戶端半關(half-close)連接,並標記請求消息的結束。在這裡,“半關”指的是客戶端在自己的一側關閉連接,這樣一來,客戶端無法再向伺服器端發送消息,但仍能夠監聽來自伺服器端的消息。只有在接收到完整的消息之後,伺服器端才生成響應。響應消息包含一個頭信息幀,隨後是以長度作為首碼的消息。當伺服器端發送帶有狀態詳情的 trailer 頭信息之後,通信就會關閉。

4.2服務端流模式
從客戶端的角度來說,一元 RPC 模式和伺服器端流 RPC 模式具有相同的請求信息流。這兩種情況都是發送一條請求消息,主要差異在於伺服器端。在伺服器端流 RPC 模式中,伺服器端不再向客戶端發送一條響應消息,而會發送多條響應消息。伺服器端會持續等待,直到接收到完整的請求消息,隨後它會發送響應頭消息和多條以長度作為首碼的消息,如下圖 所示。在伺服器端發送帶有狀態詳情的 trailer 頭信息之後,通信就會關閉。

4.3客戶端流模式
在客戶端流 RPC 模式中,客戶端向伺服器端發送多條消息,伺服器端在響應時發送一條消息。客戶端首先通過發送頭信息幀來與伺服器端建立連接,然後以數據幀的形式,向伺服器端發送多條以長度作為首碼的消息,如圖所示。最後,通過在末尾的數據幀中發送 EOS 標記,客戶端將連接設置為半關的狀態。與此同時,伺服器端讀取所接收到的來自客戶端的消息。在接收到所有的消息之後,客戶端發送一條響應消息和 trailer 頭信息,並關閉連接。
4.4雙向流模式
在雙向流 RPC 模式中,客戶端通過發送頭信息幀與伺服器端建立連接。然後,它們會互發以長度作為首碼的消息,無須等待對方結束。如圖 所示,客戶端和伺服器端會同時發送消息。兩者都可以在自己的一側關閉連接,這意味著它們不能再發送消息了。

重點看一下雙向流模式。在服務端, 我們可以模擬接收到請求後,進行了耗時的操作,如耗時2秒後,才進行響應。
在服務端處理請求期間,客戶端多次發送請求,可以發現不用等待服務端響應,就能發送新請求並被正確處理。


5.總結
gRPC 是一個高性能、開源和通用的 RPC 框架,面向移動和 HTTP/2 設計。
優點
1.性能好/效率高
· 基於 HTTP/2 標準設計,二進位編碼傳輸速度快
· Protobuf 壓縮性好,序列化和反序列化快,傳輸速度快
2.有代碼生成機制
3.支持向後相容和向前相容
當客戶端和伺服器同時使用一個協議時,客戶端在協議中增加一個位元組,並不會影響客戶端的使用。
4.支持多種編程語言
5.流式處理(基於http2.0):支持客戶端流式,服務端流式,雙向流式
缺點
1.二進位格式導致可讀性差
為了提高性能,protobuf 採用了二進位格式進行編碼。這直接導致了可讀性差,影響開發測試時候的效率。當然,在一般情況下,protobuf 非常可靠,並不會出現太大的問題。
2.缺乏自描述
一般來說,XML 是自描述的,而 protobuf 格式則不是。它是一段二進位格式的協議內容,並且不配合寫好的結構體是看不出來什麼作用的。
3.通用性差
protobuf 雖然支持了大量語言的序列化和反序列化,但仍然並不是一個跨平臺和語言的傳輸標準。在多平臺消息傳遞中,對其他項目的相容性並不是很好,需要做相應的適配改造工作。相比 json 和 XML,通用性還是沒那麼好。
引用鏈接:
《gRPC與雲原生應用開發:以Go和Java為例》
HTTP2詳解:https://juejin.cn/post/6844903667569541133
HTTP/2 頭部壓縮技術介紹:https://juejin.cn/post/6844903972642242574
Language Guide (proto3) | proto3 語言指南(十四)選項:https://www.cnblogs.com/itheo/p/14273574.html
Protobuf生成Java代碼(命令行):https://www.jianshu.com/p/420c18851aaa
說說我理解的grpc的編碼協議:https://juejin.cn/post/6993244854939549727


