
Calcite在大數據系統中有著廣泛的運用, 比如Apache Flink, Apache Drill等都大量使用了Calcite,理解Calcite的原理可以說已經成為理解大數據系統中SQL訪問層實現原理的必備條件之一。 但是不少人在學習Calcite的過程中都發現關於Calcite的實踐案例其實 ...
Calcite在大數據系統中有著廣泛的運用, 比如Apache Flink, Apache Drill等都大量使用了Calcite,理解Calcite的原理可以說已經成為理解大數據系統中SQL訪問層實現原理的必備條件之一。
但是不少人在學習Calcite的過程中都發現關於Calcite的實踐案例其實很少,本文就將為大家詳細介紹如何基於Calcite框架的SQL語法擴展探索使之更符合你的業務需求,以及擴展SQL在數棧產品的應用實踐。
Calcite介紹及用途
Calcite介紹
Apache Calcite是一個動態的數據管理框架,本身不涉及任何物理存儲信息,而是專註在SQL解析、基於關係代數的查詢優化,通過擴展方式來對接底層存儲。
目前Apache Calcite被應用在廣泛的數據開源系統中,比如Apache Hive、Apache Phoenix、Apache Flink等。
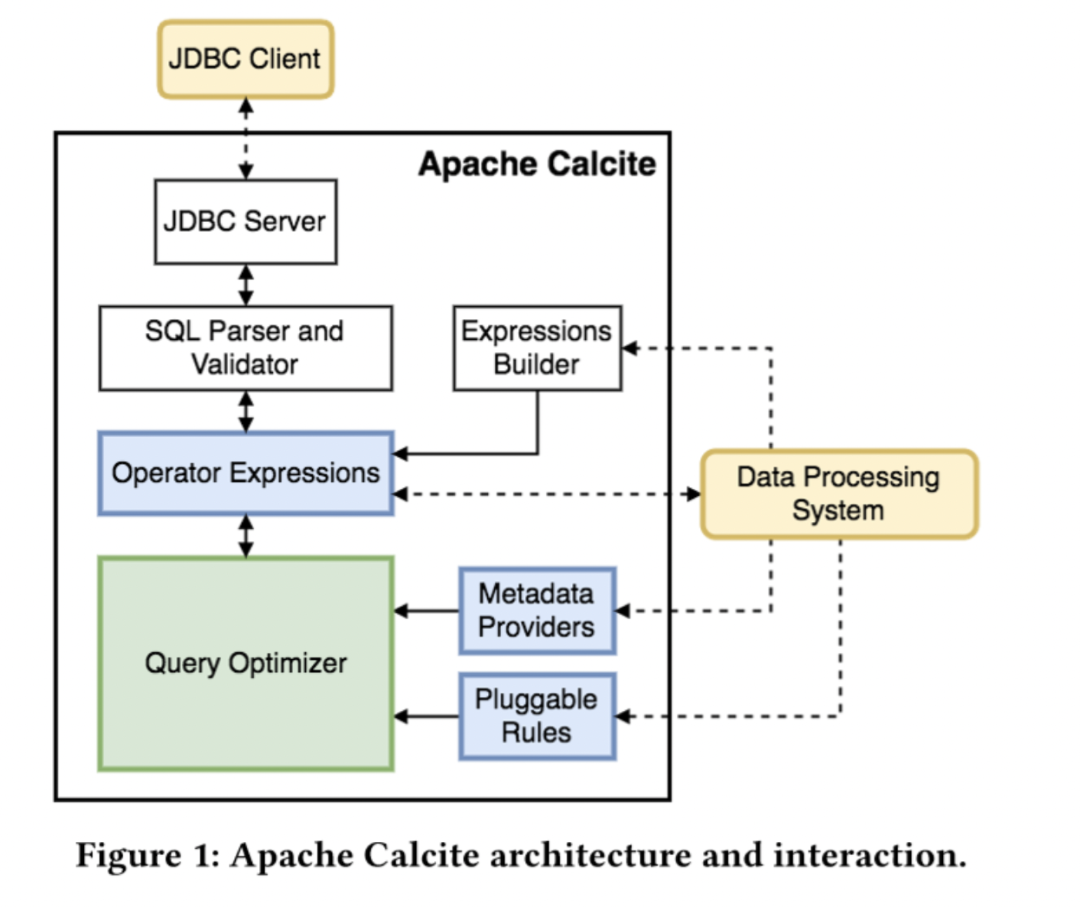
Calcite的用途
Calcite提供了ANSI標準SQL的解析,以及各種SQL 方言,針對來自於不同數據源的複雜SQL,在Calcite中會把SQL解析成SqlNode語法樹結構,然後根據得到的語法樹轉換成自定義Node,通過自定義Node解析獲取到表的欄位信息、以及表信息、血緣等相關信息。
下圖展示了一部分對外提供的介面信息:
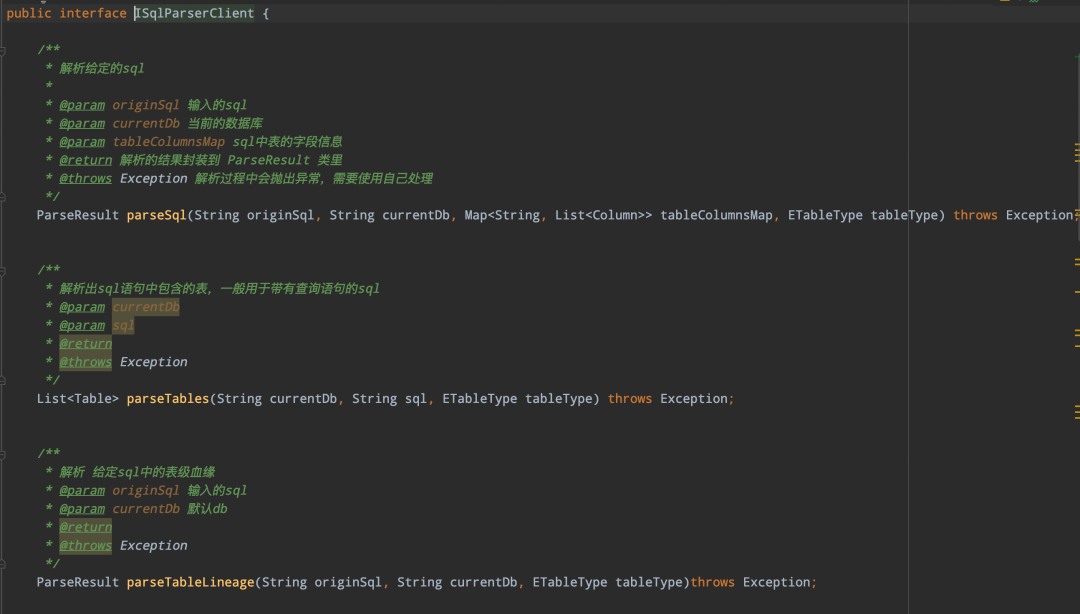
sqlparser 解析模塊主要提供了以下幾種功能 :
• 解析SQL包含的所有表、欄位信息
• 解析SQL的udf函數
• 解析SQL的血緣信息,包括表級血緣、欄位血緣
• 解析自定義SqlNode
• api服務變數解析替換
SQL語法擴展
瞭解完Calcite是什麼以及用途後,下麵為大家分享Calcite SQL語法擴展的相關內容。
SQL語法擴展背景
在 sqlparser 中進行sql解析的場景中,有兩種情況需要使用到自定義擴展,一是Calcite不支持的一些語法;二是在一些場景中存在sql中帶有${var}自定義變數語法。
那麼針對上面的這兩種情況,Calcite的自定義擴展是如何實現的呢?自定義擴展主要涉及到以下三個文件:
• Parser.jj:Parser.jj是一個Calcite核心的語法和詞法文件,基於Apache FreeMaker模版,該模版包含著變數,這些變數在編譯時可以被替換
• parserImpl.ftl:提供自定義SQL語句、literals、dataType的實現方法
• config.fmpp:該文件是FMPP的配置文件,提供了SQL語句、literals、dataType的介面擴展入口
Calcite使用javacc作為語法解析器,freemaker作為模版,把parserImpls.ftl、config.fmpp、Parser.jj模版合成最終的語法詞法文件,最終通過javacc編譯成自定義的解析器源碼,整體流程如下圖所示:
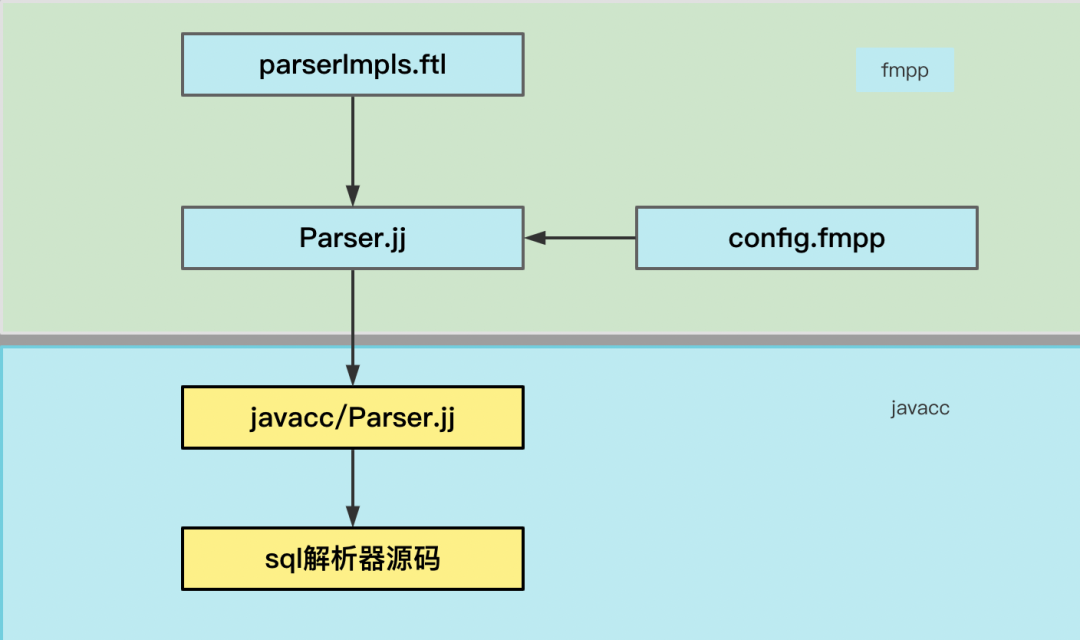
擴展SQL實現
● 工程目錄
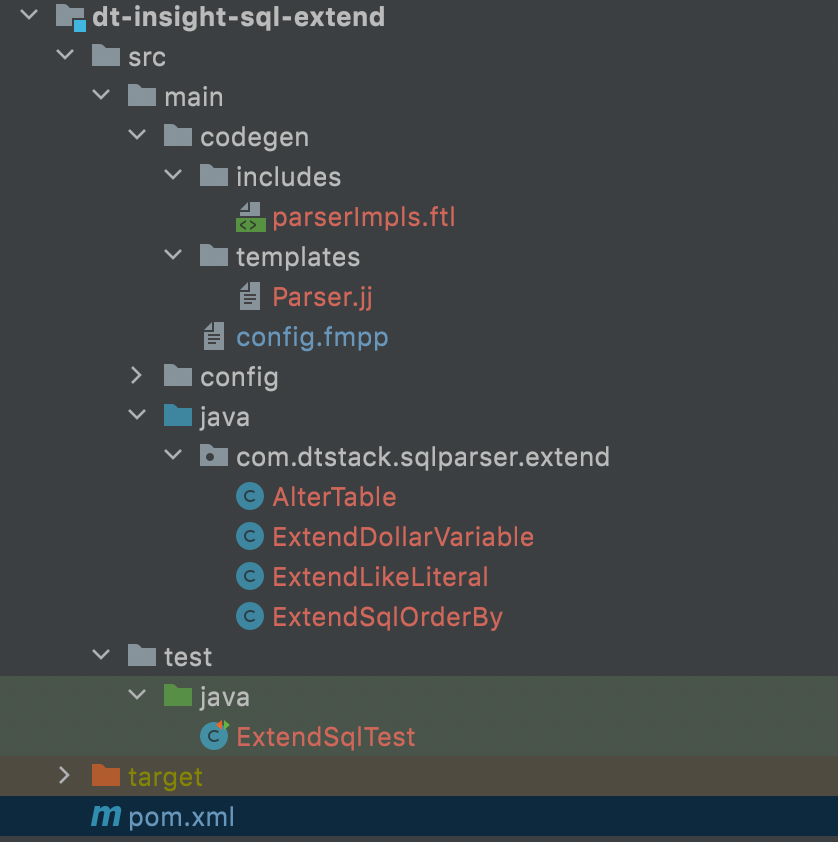
● 擴展sql實現案例
支持以下limit相關語法以及數字可以寫成${var}形式:
-> limit count, limit start count
-> limit count offset start
-> offset start limit count
在原生的Calcite解析是支持limit count語法的,但是由於返回SqlOrderBy對象內部類Operator的unparse方法在SQL輸出過程中對原始SQL進行了改寫,因此需要使用擴展SQL得到正確的SQL。
下麵介紹一個limit offset語法擴展樣例,擴展SQL如下:
select id, name from test where id > 3 order by id desc limit 1 offset ${offset_val}
整體流程如下:
01
Parser.jj 定義${var}變數的token詞法DOLLAR_VARIABLE:

02
Parser.jj 擴展的變數方法接入,下麵方法會在解析到limit、offset關鍵字後面的一個詞時進行調用:

03
Parser.jj limit offset在select語法的核心處理邏輯:
-> 定義變數
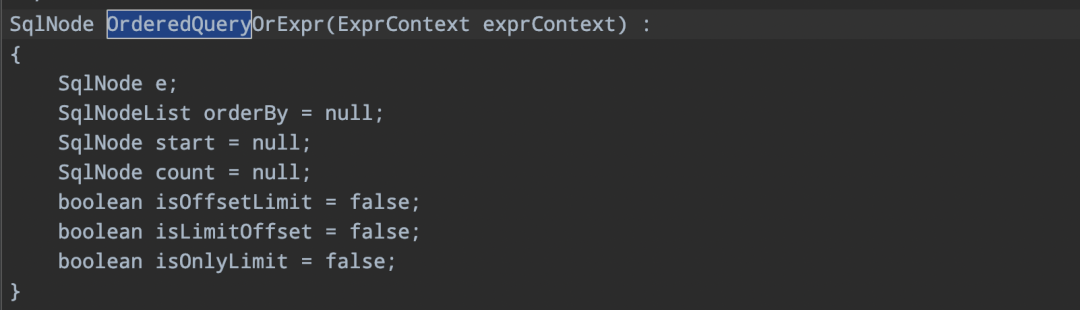
主要定義了三個boolean類型的變數,isOffsetLimit表示offset limit 語法,isLimitOffset表示limit offset語法,isOnlyLimit表示limit count、limit start count語法。
-> 定義處理邏輯
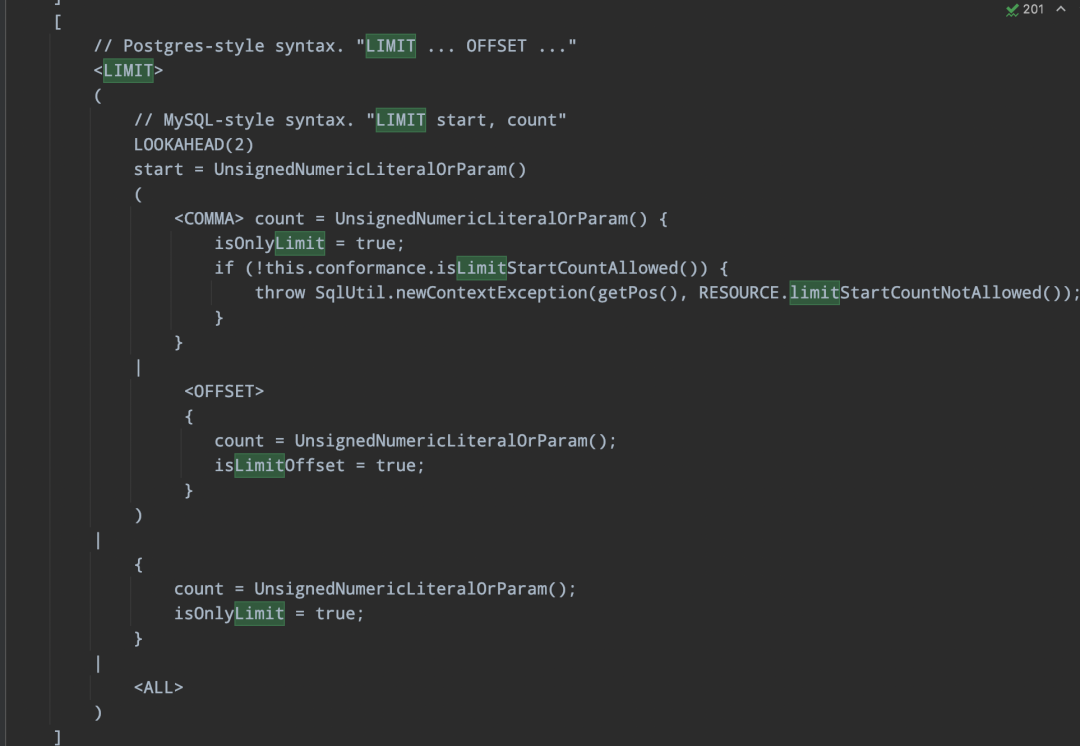
-> 返回自定義SqlNode
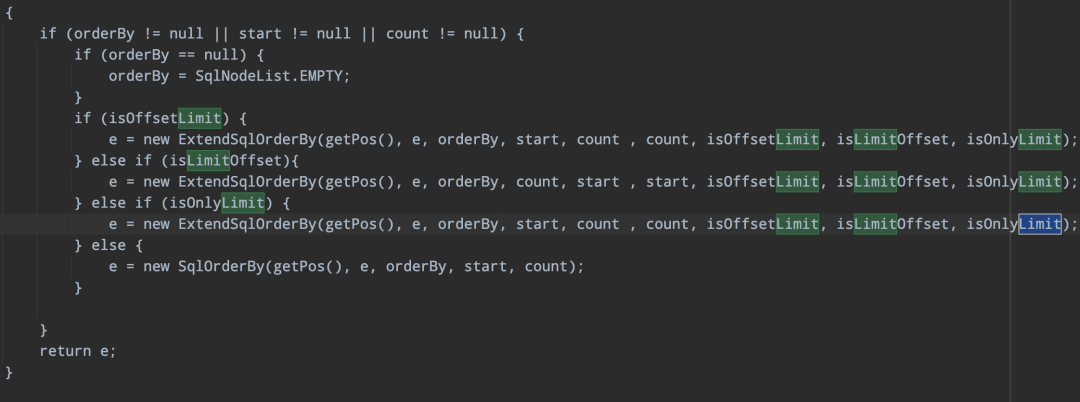
針對符合上面的三個boolean條件時,使用自定義ExtendSqlOrderBy的擴展類。
04
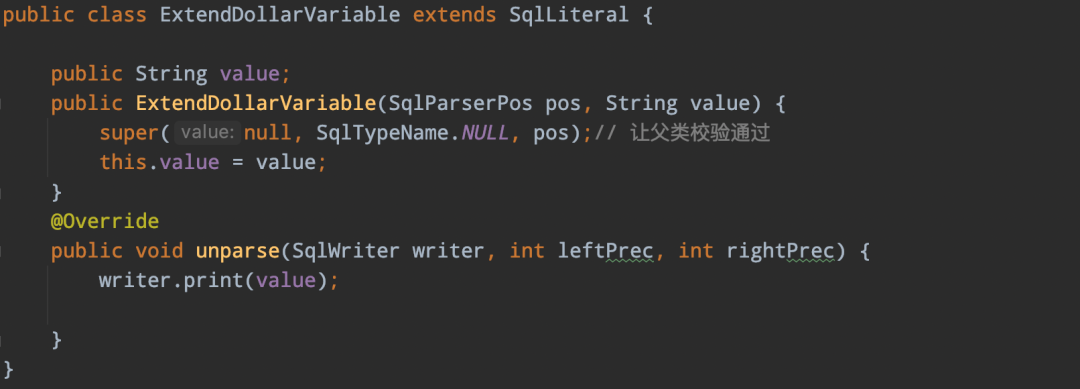
parserImpl.ftl 定義擴展的SqlNode ExtendDollarVariable:
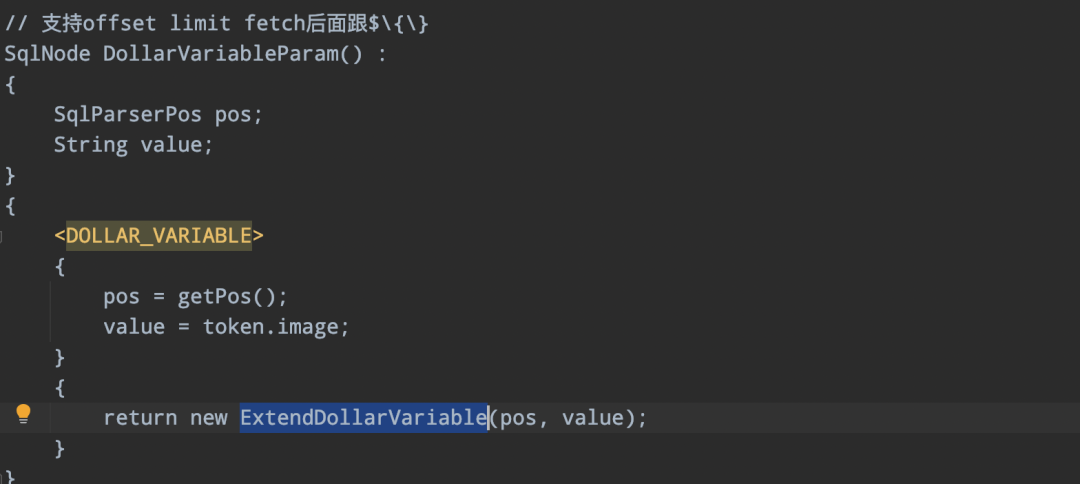
05
config.fmpp 定義包以及擴展實現類的import:
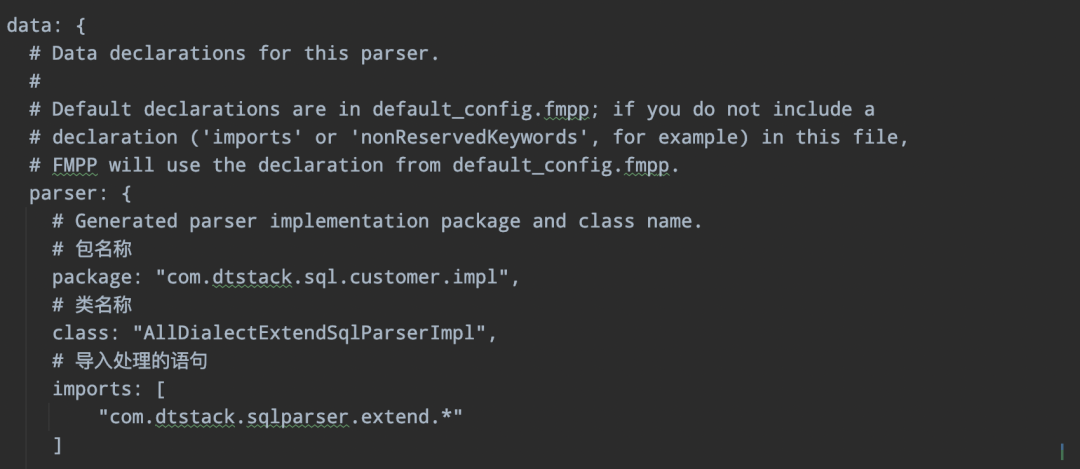
06
擴展SqlNode實現:
-> 變數實現sqlNode
-> 擴展limit實現類ExtendSqlOrderBy,該類實現了SqlOrderBy,併在此基礎擴展了limit的SqlNode,以及isOffsetLimit、isLimitOffset、isOnlyLimit三個boolean標識limit的不同語法
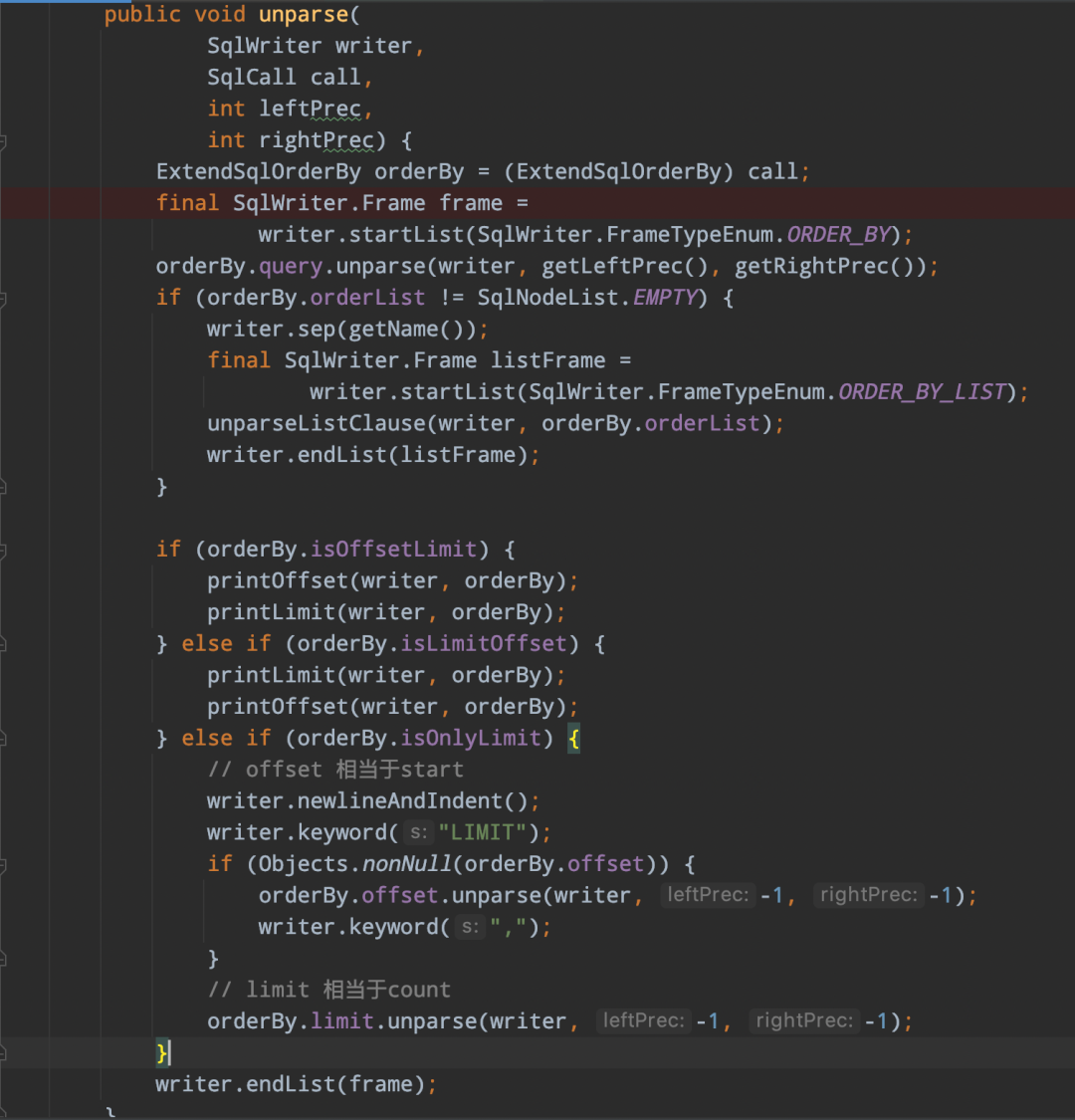
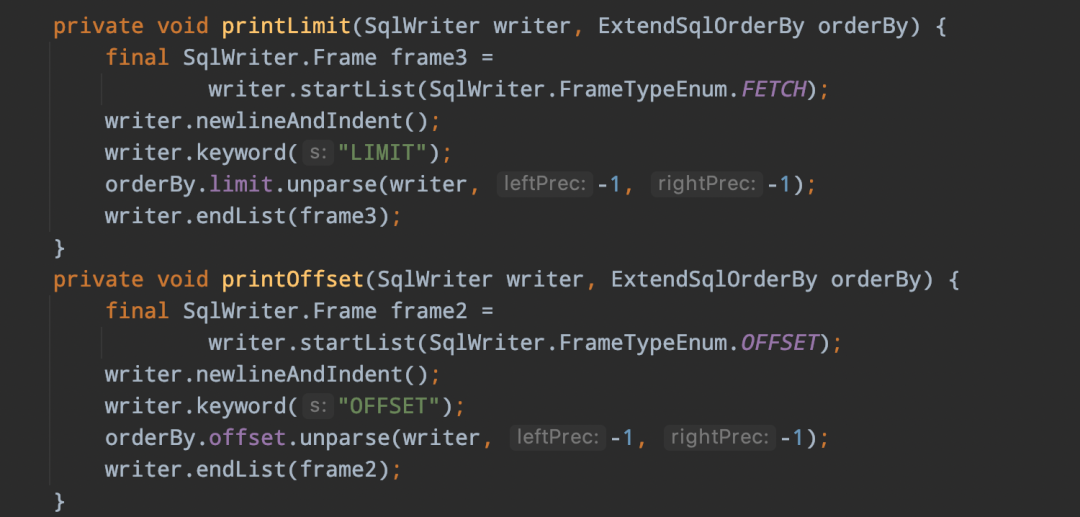
通過上面的這些步驟後,最後解析生成的SqlNode語法樹如下所示:

擴展SQL在數棧的應用
目前袋鼠雲的底層sqlparser sql解析涉及的子產品應用包括API數據服務、離線開發、客戶數據洞察(標簽)、實時開發等,雖然大部分針對Calcite的SQL語法擴展相對於上層的產品應用感知不是很明顯,但是擴展SQL還是解決了一些痛點,主要如下:
• 逐漸替換底層採用了多種解析工具解析的情況,使維護更簡單,減少bug的產生
• 解決一些不支持的語法,避免在上層業務層做處理或者在底層做一些特殊處理
以在API數據服務後續接入的like語法改造為例為大家進行分享,目前的API數據服務中支持like ${var}語法,在執行測試中通過傳遞like語法來確定執行的模糊匹配方式,例如%xx、xx%、%xx%。
收到客戶提出的優化like語法場景,袋鼠雲本著客戶第一的原則,這種合理的優化需求是採納的。SQL支持like%${var}、${var}%、%${var}%,這樣在執行測試中就不需要輸入%了,目前擴展SQL語法已經支持這種優化的like語法,預計在2023年上半年會接入進去,下麵通過API數據服務展示當前like SQL和擴展後的SQL差異:
● 當前like ${var}處理
-> 生成API
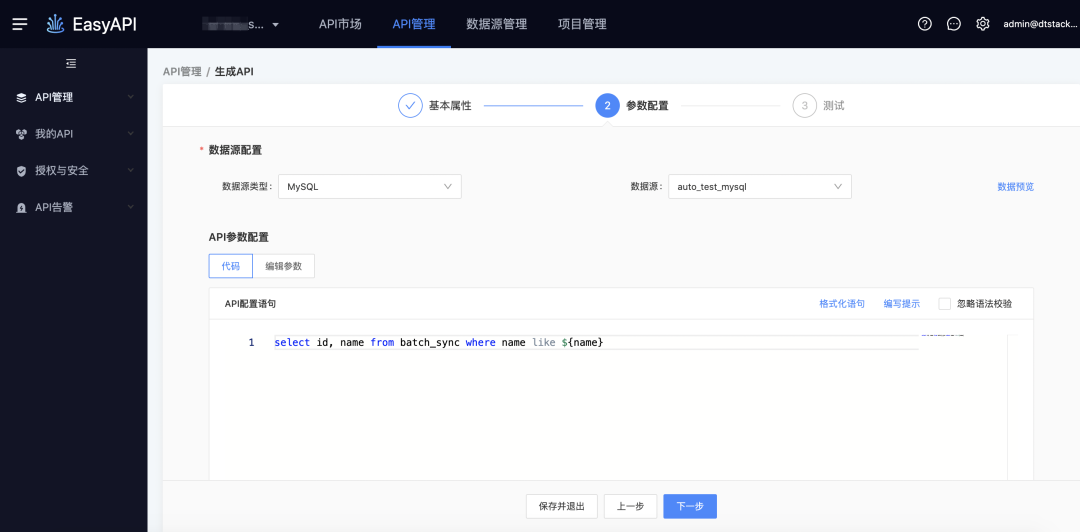
-> 測試執行,模糊匹配需要輸入%
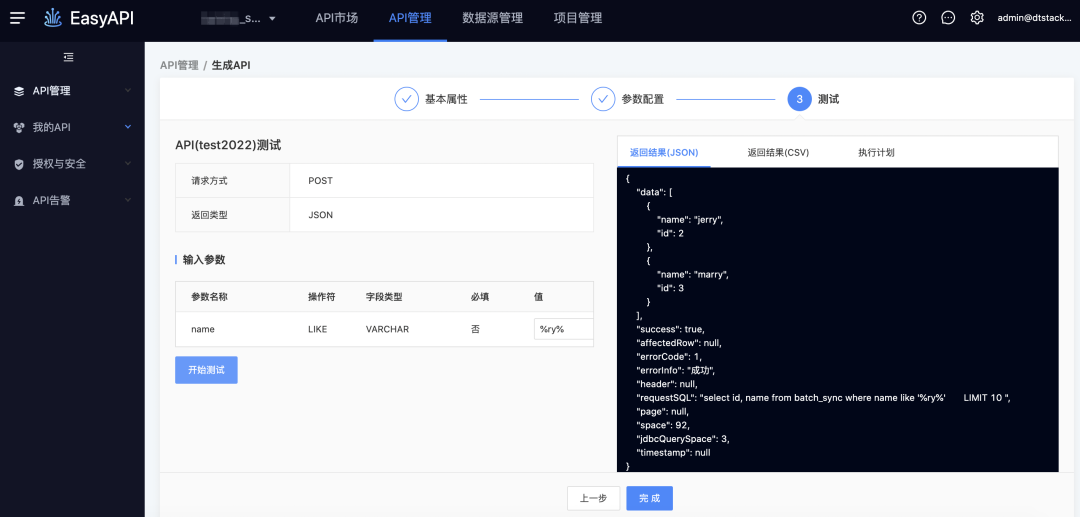
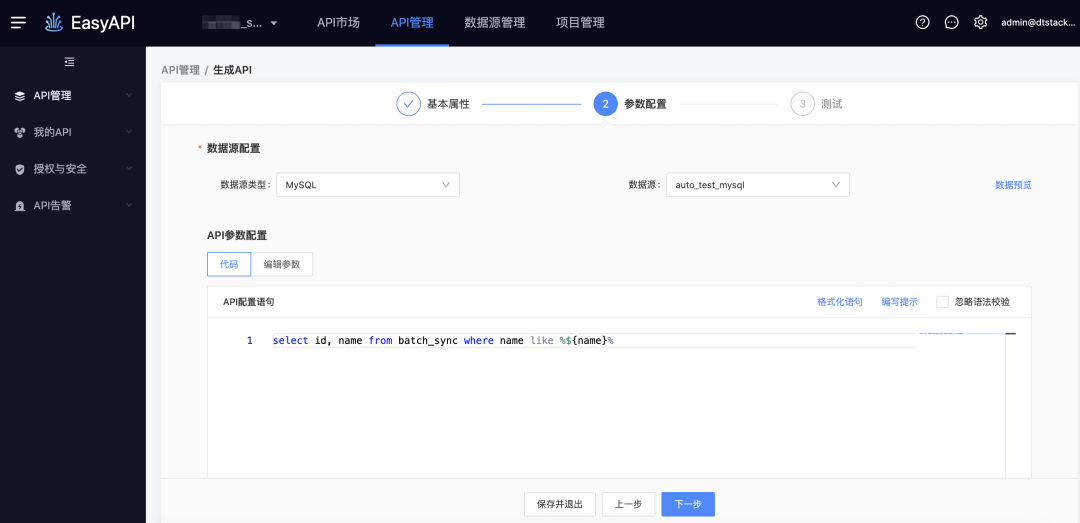
● 擴展like %${var}%
-> 生成API
-> 測試執行,由於在SQL階段已經寫了模糊匹配方式,因此可以直接輸入值
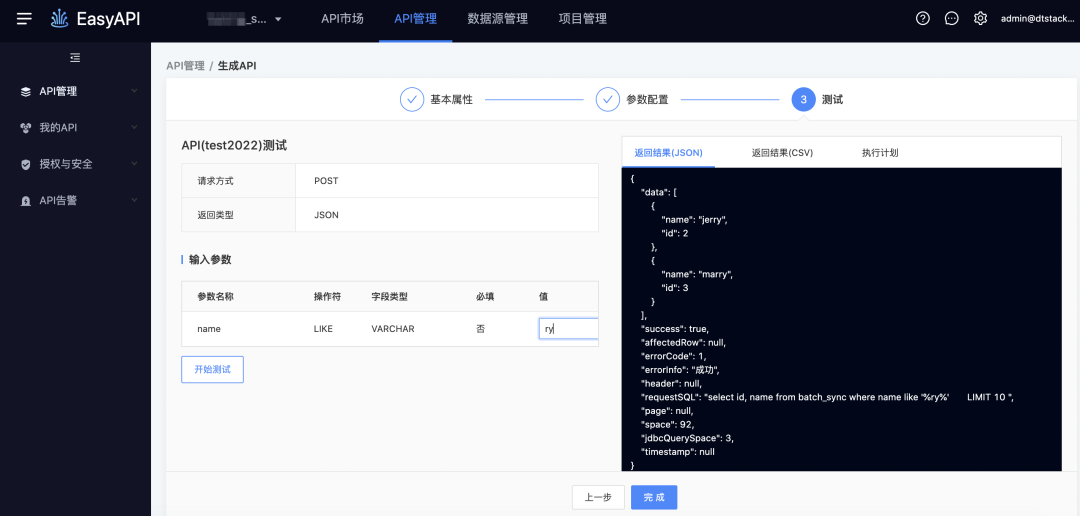
總結規劃
相信通過上面的案例後,大家對於Calcite擴展SQL語法的流程應該有了大致的瞭解,目前在袋鼠雲的業務場景中已經擴展了許多語法,在未來還有一些工作需要進行優化:
• 豐富SQL語法,實現不同數據源擴展SQL語法的隔離
• 逐漸通過SQL語法擴展替換掉底層Calcite和druid共同解析的場景,避免維護多套相同的解析,減少線上問題產生
最後如果是初步接觸Calcite SQL語法擴展的同學們,建議先熟悉javacc語法。
地址:https://javacc.github.io/javacc/
想瞭解或咨詢更多有關袋鼠雲大數據產品、行業解決方案、客戶案例的朋友,瀏覽袋鼠雲官網:https://www.dtstack.com/?src=szbky
同時,歡迎對大數據開源項目有興趣的同學加入「袋鼠雲開源框架釘釘技術qun」,交流最新開源技術信息,qun號碼:30537511,項目地址:https://github.com/DTStack


