
1、需求描述 最近碰到了一個需求,是要統計各個團隊的員工的銷售金額,然後一級一級向上彙總。 編輯 架構團隊樹是類似於這種樣子的,需要先算出每個員工的銷售金額,然後彙總成上一級的團隊金額,然後各個團隊的銷售總金額再往上彙總成一個區域的銷售金額,然後各個區域的金額再往上彙總成總公司的金額。當然我工 ...
1、需求描述
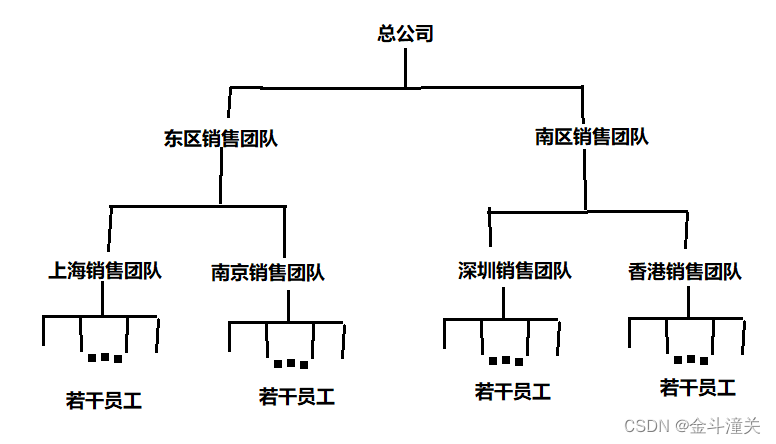
最近碰到了一個需求,是要統計各個團隊的員工的銷售金額,然後一級一級向上彙總。
![]()
架構團隊樹是類似於這種樣子的,需要先算出每個員工的銷售金額,然後彙總成上一級的團隊金額,然後各個團隊的銷售總金額再往上彙總成一個區域的銷售金額,然後各個區域的金額再往上彙總成總公司的金額。當然我工作碰到的團隊樹要遠比這個複雜許多,但反正差不多是這麼個意思。
2、解決方法
2.1、方法一(不推薦)
持久層通過一些sql把團隊樹結構,以及各個員工的銷售金額彙總拿到,然後在業務層通過代碼去一層層拼起來。這是我一開始拿到這個需求時的思路,後來發現可以但是很複雜,代碼可讀性及可維護性很差。
2.2、方法二(推薦)
在sql裡面計算彙總出來。
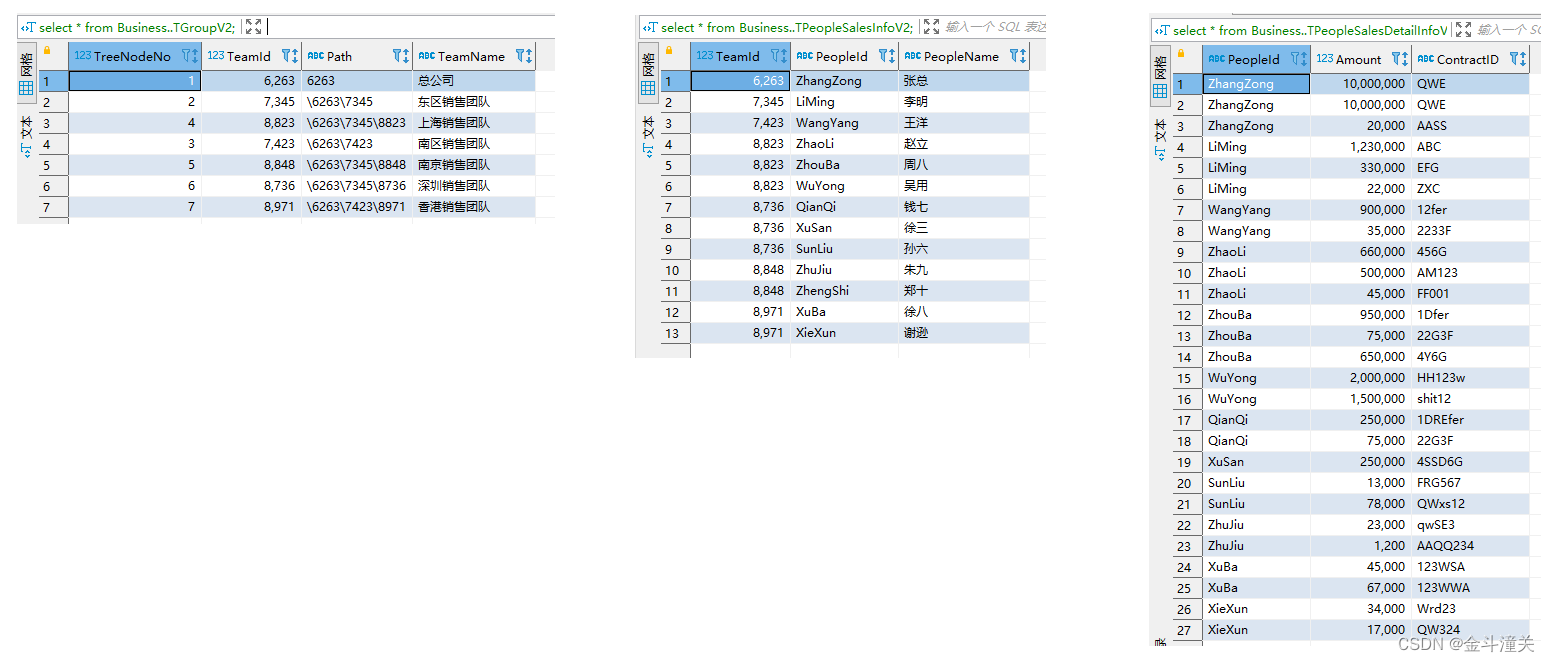
我這裡是在測試環境建了幾張Demo表來加以說明sql的邏輯。
1、建表、
CREATE TABLE Business..TGroupV2(TreeNodeNo int,TeamId int,TeamName varchar(100),[Path] varchar(100));
CREATE TABLE Business..TPeopleSalesInfoV2(TeamId int,PeopleId varchar(100),PeopleName varchar(100));
CREATE TABLE Business..TPeopleSalesDetailInfoV2(PeopleId varchar(100),Amount Decimal(18,2),ContractID varchar(100));2、添加一些測試數據
![]()
3、SQL代碼
--以團隊為單位,彙總各個團隊,子團隊,父團隊的銷售金額
SELECT TB.TreeNodeNo,TB.TeamID,TB.TeamName,AA.Amount,'' as PeopleId ,'' as PeopleName FROM
(
SELECT A.ParentTeamID,SUM(A.Amount) as Amount FROM
(
SELECT
TT.*,TG2.TeamID as ParentTeamID,BB.Amount from
(
select T1.*,TG.[Path]
from Business..TPeopleSalesInfoV2 T1
left join Business..TGroupV2 TG on T1.TeamId=TG.TeamId
) AS TT
left join Business..TGroupV2 TG1 on TT.TeamId=TG1.TeamId
left join Business..TGroupV2 TG2 on
TG1.[Path] LIKE ('%\' + convert(varchar(50),TG2.TeamID))
or TG1.[Path] like ('%\' + convert(varchar(100),TG2.TeamID) + '\%')
or TG1.[Path] like (convert(varchar(50),TG2.TeamID) + '\%')
or TG1.[Path] = convert(varchar(50),TG2.TeamID)
LEFT JOIN
(select PeopleId,SUM(Amount) as Amount from Business..TPeopleSalesDetailInfoV2 group by PeopleId)
as BB on TT.PeopleId=BB.PeopleId
) A GROUP by ParentTeamID
) as AA LEFT JOIN Business..TGroupV2 TB on TB.TeamID=AA.ParentTeamID
UNION
--以員工為單位獲取各個銷售人員的銷售金額
select TB.TreeNodeNo,TB.TeamID,TB.TeamName,SUM(TP.Amount) as Amount,TP.PeopleId,TPS.PeopleName from Business..TPeopleSalesDetailInfoV2 TP
LEFT JOIN Business..TPeopleSalesInfoV2 TPS on TPS.PeopleId=TP.PeopleId
LEFT JOIN Business..TGroupV2 TB on TB.TeamID=TPS.TeamID
group by TB.TreeNodeNo,TB.TeamID,TB.TeamName,TP.PeopleId,TPS.PeopleName
ORDER BY TreeNodeNo,PeopleId ASC 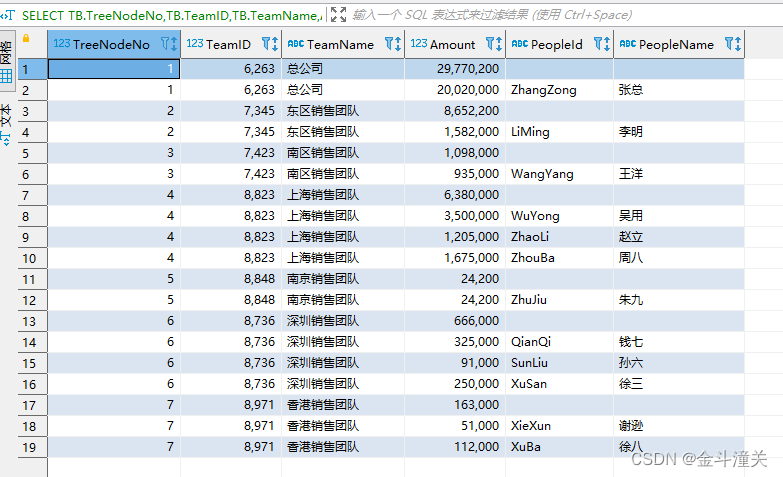
![]()
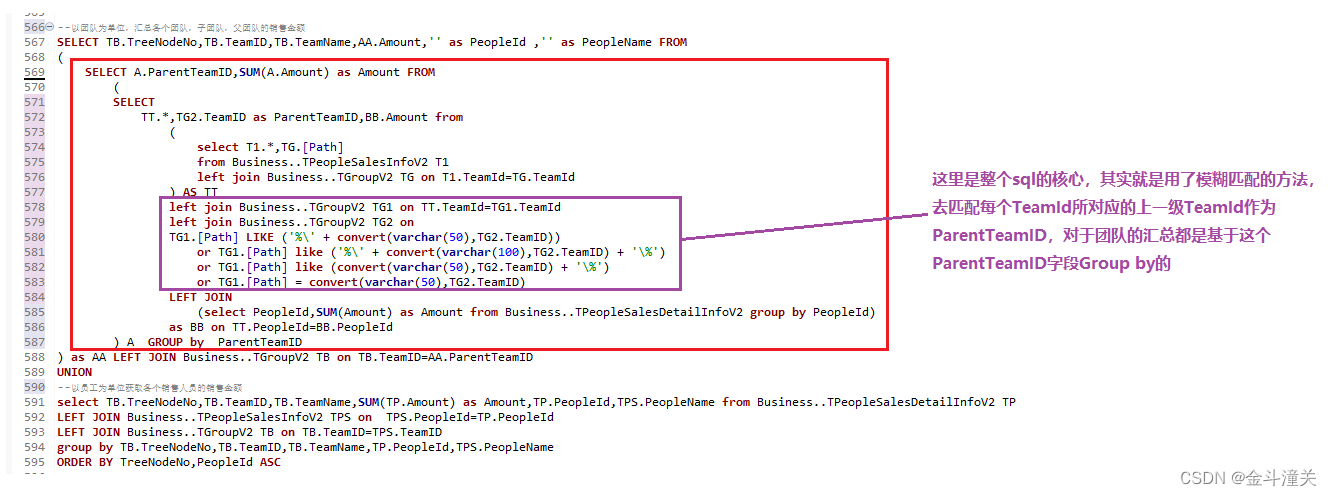
2.3、思路說明
![]()
3、總結
隨著數據量增加一些老的sql查詢性能太慢了,經常出現這種查詢超時問題。

![]()
造成這種問題的原因有很多,一種是sql寫的太爛了,業務層有迴圈查詢。就像我方法一中的那種思想,不可避免你要迴圈查詢出每個團隊的金額再一級一級向上彙總。還有就是不合理的許可權控制。比如你要查詢團隊的銷售金額。因為團隊的關係是一個樹狀結構嘛。假如你是東區的領導,你只能查詢東區及其下所有子團隊的數據,但在許可權判斷這塊,其實是會東區下每個子團隊,以及子團隊的子團隊.....都要判斷一遍你有沒有查詢的許可權。這樣就增加了不必要的負擔。不過這個是歷史遺留問題,是因為之前的許可權結構設計就不完善,也不太好改。
解決方法嘛,目前我就是通過存儲過程取代select查詢,因為存儲過程是預編譯的,所以執行起來開銷比較小所以速度比較快。可以看下這篇詳細瞭解下:
因為原先的select查詢關聯了好多表以及視圖,各種join的,可讀性很差。我所要做的就是理清這些join之間的關係, 存儲過程中用幾個臨時表把大的join拆成合併成小的join。再加一些註釋什麼的,雖然業務沒有變,只是代碼更容易理解了。速度確實快了一些,不在出現查詢的超時的問題了。
4、參考資料


