
轉義字元 一些特殊字元。 | 轉義字元 | 含義 | | : : | : : | | \n | 換行 | | \r | 回車 | | \0 | 結束字元 | | \s | 空格 | | \’ | 單引號 | | \" | 雙引號 | | \\ | 反斜杠 | 字元編碼 ASCII American ...
轉義字元
一些特殊字元。
| 轉義字元 | 含義 |
|---|---|
| \n | 換行 |
| \r | 回車 |
| \0 | 結束字元 |
| \s | 空格 |
| \’ | 單引號 |
| \" | 雙引號 |
| \\ | 反斜杠 |
字元編碼
ASCII
American Standard Code for Information Interchange,美國信息交換標準代碼。
電腦發明之初,基本只考慮了美國的需求,美國大概只需要 128 個字元。
數字 32~126 表示的字元都是可列印字元。
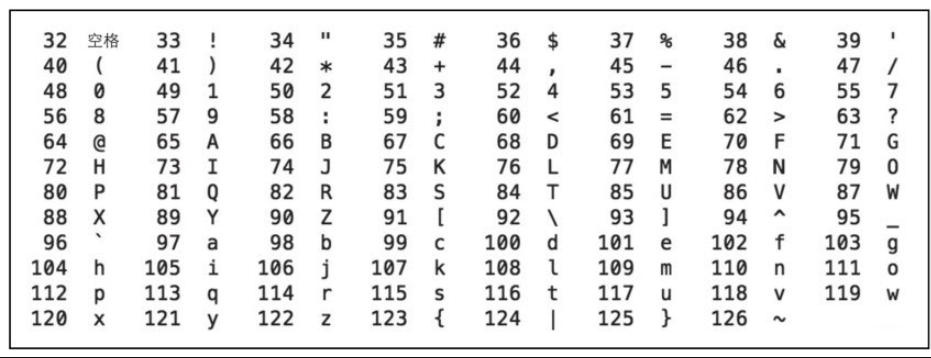
0~31 和 127 表示一些不可列印的字元。
| 數字 | 縮寫/字元 | 解釋 | 轉義字元 |
|---|---|---|---|
| 0 | NUL(null) | 空字元 | \0 |
| 8 | BS(backspace) | 退格 | \b |
| 9 | HT(horizontal tab) | 水平製表符 | \t |
| 10 | LF(NL line feed,new line) | 換行鍵 | \n |
| 13 | CR(carriage return) | 回車鍵 | \r |
| 27 | ESC | 換碼 | |
| 127 | DEL(delete) | 刪除 |
ASCII 碼對美國夠用,但對其他國家是不夠的。
各國的電腦廠商發明瞭各自的編碼方式以表示自己國家的字元,為了保持與 ASCII 碼的相容性,一般都是將最高位設置為 1。
就是說,當最高位為 0 時,表示 ASCII 碼,當為 1 時就是各個國家自己的字元。
ISO 8859-1
ISO 8859-1 又稱 Latin-1,同樣使用一個位元組表示一個字元。
其中 0~127 與 ASCII 一樣,128~255 規定了不同的含義。
Windows-1252
基本上可以認為,ISO8859-1 已被 Windows-1252 取代,在很多應用程式中,即使文件聲明它採用的是 ISO 8859-1 編碼,解析的時候依然被當作 Windows-1252 編碼。
GBK
GBK 使用固定的兩個位元組表示字元,高位位元組範圍是 0x81~0xFE ,低位位元組範圍是 0x40~0x7E 和 0x80~0xFE。
需要註意的是,低位位元組是從 0x40(即64)開始的,因此低位位元組的最高位可能為 0。
Unicode
Unicode 給世界上所有字元都分配了一個唯一的數字編號,編號範圍從 0x000000~0x10FFFF。
每個字元都有一個 Unicode 編號,這個編號一般寫成十六進位,在前面加 U+。
但它並沒有規定這個編號怎麼對應到二進位表示。
編號怎麼對應到二進位表示?主要有 UTF-32、UTF-16 和 UTF-8 。
UTF-32
字元 Unicode 編號的整數二進位形式,4個位元組。
UTF-16
UTF-16 使用變長位元組表示。對於編號在 U+0000 ~ U+FFFF的字元(常用字元),直接用 2 個位元組表示。編號在 U+10000 ~ U+10FFFF的字元(增補字元集),需要使用 4 個位元組表示。
在 Java 內部進行字元處理時,採用的是 Unicode 編碼,具體的編碼格式是 UTF-16。
UTF-8
UTF-8 使用變長位元組表示,字元使用的位元組個數與其 Unicode 編號的大小有關,編號小的使用的位元組就少,位元組個數為 1~4 不等。
| 編號範圍 | 二進位格式 |
|---|---|
| 0x00 ~ 0x7F(0 ~ 127) | 0xxx xxxx |
| 0x80 ~ 0x7FF(128 ~ 2047) | 110x xxxx 10xx xxxx |
| 0x800 ~ 0xFFFF(2048 ~ 65535) | 1110 xxxx 10xx xxxx 10xx xxxx |
| 0x10000 ~ 0x10FFFF(65536以上) | 1111 0xxx 10xx xxxx 10xx xxxx 10xx xxxx |
UTF-8 將字元看作整數,轉化為二進位形式(去掉高位的 0),然後將二進位位從右向左依次填入對應的二進位格式 x 中,填充完後,如果對應的二進位格式還有沒填的 x,則設為 0。
/*
如 '馬' 的 Unicode 編號是 0x9A6C,整數編號是 39532,二進位 1001 101001 101100
對應的 UTF-8 二進位格式是:1110 xxxx 10xx xxxx 10xx xxxx
將二進位 1001 101001 101100 從右到左依次填入二進位格式中
結果就是其 UTF-8 編碼:1110 1001 1010 1001 1010 1100
*/
UTF-8 是相容 ASCII 的,對大部分中文字元而言,需要使用三個位元組表示。
編碼轉換
不同編碼格式之間可以藉助 Unicode 編號進行編碼轉換。可以認為,每種編碼都有一個映射表,存儲 Unicode 編號和其特有的字元編碼之間的對應關係。
編碼轉換的具體過程可以是:一個字元從 A 編碼轉到 B 編碼,先找到字元的 A 編碼格式,通過 A 編碼的映射表找到其 Unicode 編號,然後通過 Unicode 編號再查找 B 編碼的映射表,找到字元的 B 編碼格式。
亂碼問題
解析錯誤:使用錯誤的編碼進行解析,如小明採用 Windows-1252 寫了個文件,發送給了小紅,小紅 使用 GBK 來解析這個字元,看到的可能就是亂碼。
編碼轉換錯誤:在錯誤解析的基礎上還進行了編碼轉換。如上述,小紅用 GBK 解析打開後看到亂碼,又轉換成了 UTF-8 編碼。


