
在我之前的一篇文章中,有引用一個討論用Hash還是Tree的問題,DB中關於查找類數據結構,除了樹,還有Hash(HashMap,HashSet)。 存儲數據結構之爭 B+樹主要是照顧磁碟IO這種特殊的性質應運而生的;然而在記憶體夠多夠大時,Hash某些時候比Tree結構有用得多。 但是Hash做索引 ...
在我之前的一篇文章中,有引用一個討論用Hash還是Tree的問題,DB中關於查找類數據結構,除了樹,還有Hash(HashMap,HashSet)。
存儲數據結構之爭
B+樹主要是照顧磁碟IO這種特殊的性質應運而生的;然而在記憶體夠多夠大時,Hash某些時候比Tree結構有用得多。
但是Hash做索引的缺點也非常明顯:
1,Hash衝突造成的散列不均勻,線性查找浪費時間;
2,不支持範圍查詢,避免不了全表掃描;
3,記憶體空間要求高。
MySQL中,InnoDB和MyISAM預設的索引是B+ Tree索引;Memory則同時支持Hash和Tree索引(可在創建時直接指定使用何種索引,具體移步)。
同時,Memory這種存儲引擎“斷電即毀”的特性也不再推薦使用。
B樹和B+樹之爭
前置知識:知道mysql中索引即數據,數據即索引(頁的存儲結構);知道為何採用B樹(多路平衡查找樹),知道為何實際採用了B+樹。
1,B+樹空間利用率更高。B+樹只在葉子節點存儲實際數據,非葉子節點,B+樹有了更多的空間存儲索引,這樣B+樹越靠近矮胖,IO減少,
磁碟讀寫代價低,檢索效率變高。
2,B+樹查詢效率更穩定。B+樹的檢索,任何檢索路徑都需要從根節點到葉子節點(只有葉子節點有數據),時間複雜度固定在O(LogN);
B樹則在O(1)和O(LogN)之間。即二分查找。
3,B+樹範圍查詢性能更優。 B+樹的葉子節點使用了雙向鏈表連接在一起,而且是嚴格的順序存儲,從左到右從小到大。
4,B+樹由於葉子節點使用了鏈表進行串聯,除了支持隨機檢索,還支持順序檢索。
一些常見概念
回表: 查詢計劃不是使用主鍵索引,即通過二級索引查找目標;而二級索引的B+樹只存儲了主鍵數據(索引列,主鍵),
如仍需要其它數據,需要再次根據主鍵去主鍵索引所在B+樹查找一次數據的過程,即回表。
回表引發的問題:某些情況,使用了索引,但仍然觸發了全表掃描(explain type='All')。因為此時查詢優化器對比了回表IO次數和全表掃描的IO次數,選擇了全表掃描。
MRR:MRR全稱:Multi-Range Read Optimization(多範圍讀取優化),動機是減少隨機磁碟訪問的次數,實現對基表數據的更順序掃描。
官網的解釋在這。即把隨機磁碟讀轉化為順序磁碟讀,提高查詢性能(磁頭運動&磁碟預讀)。本質在做一件以空間換時間的事情。
下麵這個圖很形象借用一下:(紅線表示查詢路線,藍線表示磁碟/磁頭運動路線)
未開啟MRR:
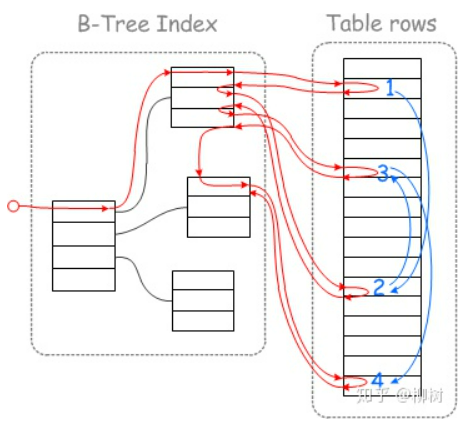
開啟MRR:
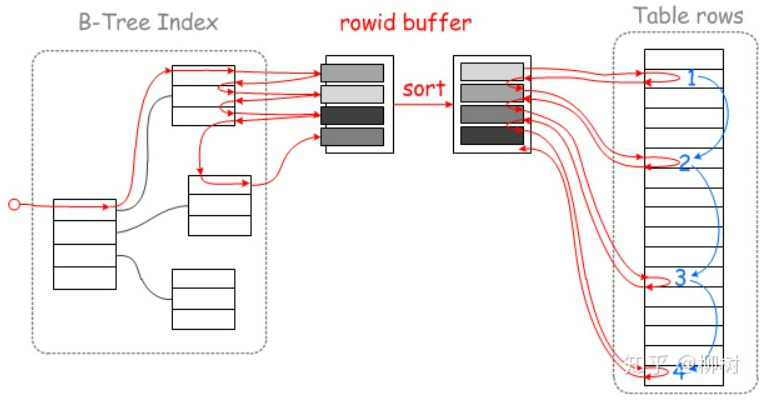
上面的圖來自文章MySQL的MRR到底是什麼?
以空間換時間,這個空間指的是記憶體,記憶體大小設置在系統變數read_rnd_buffer_size,設置請參考官網。
使用SQL命令:SELECT @@optimizer_switch
查看MRR是否已開啟(預設開啟)

索引覆蓋:查詢目標可直接從葉子節點獲取數據,不需要回表,即為索引覆蓋。
如下圖:country_id是二級索引,查找目標剛好只查詢主鍵索引和二級索引鍵值本身,直接使用二級索引的B+樹就能查到。不需要回表,稱為索引覆蓋。


最左匹配原則(多列索引): 官網的解釋在這裡。
舉例:
有組合索引信息如下:
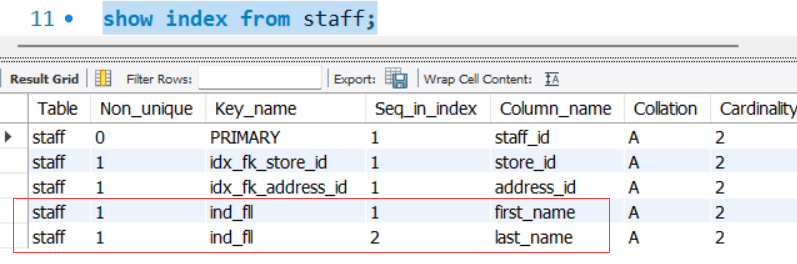
則驗證的關鍵原則是:
-- 最左匹配原則要點: -- 1,組合索引第一列(最左)作為第一個條件,只有接or不走索引,其它情況全部走索引; -- 2,不以最左作為第一個條件,一般都不會走索引,唯有把組合索引條件都加上才會走(內部優化)。 explain select * from staff where first_name='Mike'; -- yes explain select * from staff where last_name='Hillyer'; -- no explain select * from staff where first_name='Mike' and last_name='Hillyer'; -- yes explain select * from staff where last_name='Hillyer' and first_name='Mike'; -- yes(內部優化) explain select * from staff where first_name='Mike' or last_name='Hillyer'; -- no explain select * from staff where first_name='Mike' and(last_name='Hillyer' or last_name=''); -- yes
索引(條件)下推:即ICP,全稱是Index Condition Pushdown Optimization,官網的解釋在這裡。我們一般叫索引下推,其實正式應該稱為:索引條件下推。
怎麼理解?下推什麼呢? 顧名思義,Condition Pushdown,把查詢條件往下推。官網的這句:
With ICP enabled, ... , the MySQL server pushes this part of the WHERE condition down to the storage engine.
翻譯即是:ICP啟用後,把where條件的部分從server層下推到storage engine層。
需要先瞭解MySQL的大概架構:
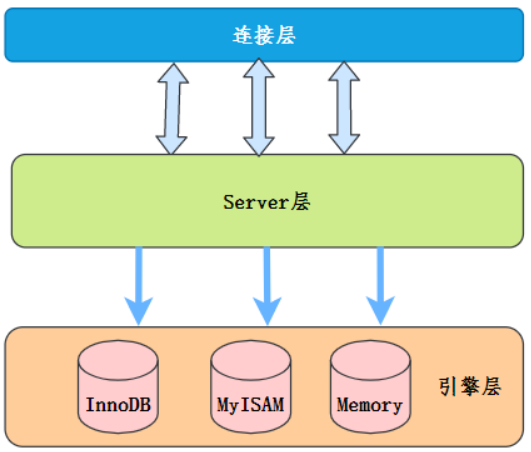
就是,原來where條件篩選在Server層這裡,現在下推到存儲引擎層去。
舉例:
下表中,id是主鍵,name,age是聯合索引。
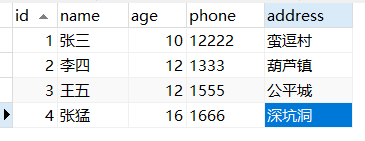
查找姓張且年齡是10歲的記錄:select * from tuser where name like '張%' and age=10;

沒有使用ICP:二級索引找到主鍵1和4,分別回表去查找對應的完整記錄,Server層再根據where條件的age=10進行篩選。這個過程要回表兩次。
使用ICP: 二級索引找到主鍵1和4,存儲引擎層(Server的下層)根據聯合索引where條件age=10進行篩選。根據篩選結果再回表查到完整記錄。這個過程回表1次。
上面的ICP舉例和圖片出自這裡。
使用執行計劃分析時,使用索引下推在Extra欄位會出現:Using index condition信息,具體參見。
MySQL預設啟用索引(條件)下推。系統設置變數為:index_condition_pushdown

避免全表掃描:官網的解釋在這裡。
使用查詢計劃分析時,對於大型表,應儘力避免type=All的情況。 表掃描非常昂貴。
本文閱讀MySQL文檔為5.7。
下一篇繼續探索索引優化部分。
作者:hangwei
出處:http://www.cnblogs.com/hangwei/
關於作者:專註於開源平臺,分散式系統的架構設計與開發、資料庫性能調優等工作。如有問題或建議,請多多賜教!
版權聲明:本文版權歸作者和博客園共有,歡迎轉載,但未經作者同意必須保留此段聲明,且在文章頁面明顯位置給出原文鏈接。
如果您覺得文章對您有幫助,可以點擊文章右下角“推薦”一下。您的鼓勵是作者堅持原創和持續寫作的最大動力!

