
1. 用戶空間和內核態空間 1.1 為什麼要區分用戶和內核 伺服器大多都採用 Linux 系統,這裡我們以 Linux 為例來講解: ubuntu 和 Centos 都是 Linux 的發行版,發行版可以看成對 linux 包了一層殼,任何 Linux 發行版,其系統內核都是 Linux 。我們的應 ...
1. 用戶空間和內核態空間
1.1 為什麼要區分用戶和內核
伺服器大多都採用 Linux 系統,這裡我們以 Linux 為例來講解:
ubuntu 和 Centos 都是 Linux 的發行版,發行版可以看成對 linux 包了一層殼,任何 Linux 發行版,其系統內核都是 Linux 。我們的應用都需要通過 Linux 內核與硬體交互

用戶的應用,比如 redis ,mysql 等其實是沒有辦法去執行訪問我們操作系統的硬體的,所以我們可以通過發行版的這個殼子去訪問內核,再通過內核去訪問電腦硬體

電腦硬體包括,如 cpu,記憶體,網卡等等,內核(通過定址空間)可以操作硬體的,但是內核需要不同設備的驅動,有了這些驅動之後,內核就可以去對電腦硬體去進行 記憶體管理,文件系統的管理,進程的管理等等
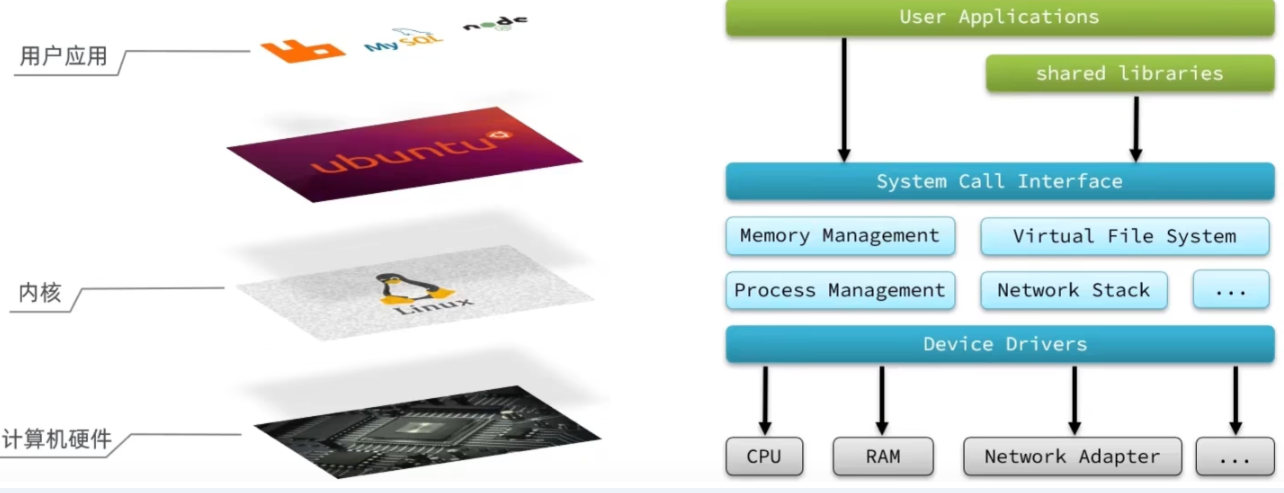
我們想要用戶的應用來訪問,電腦就必須要通過對外暴露的一些介面,才能訪問到,從而簡介的實現對內核的操控,但是內核本身上來說也是一個應用,所以他本身也需要一些記憶體,cpu 等設備資源,用戶應用本身也在消耗這些資源,如果不加任何限制,用戶去操作隨意的去操作我們的資源,就有可能導致一些衝突,甚至有可能導致我們的系統出現無法運行的問題,因此我們需要把用戶和內核隔離開
1.2 進程定址空間
進程的定址空間劃分成兩部分:內核空間、用戶空間
什麼是定址空間呢?我們的應用程式也好,還是內核空間也好,都是沒有辦法直接去物理記憶體的,而是通過分配一些虛擬記憶體映射到物理記憶體中,我們的內核和應用程式去訪問虛擬記憶體的時候,就需要一個虛擬地址,這個地址是一個無符號的整數。
比如一個 32 位的操作系統,他的帶寬就是 32,他的虛擬地址就是 2 的 32 次方,也就是說他定址的範圍就是 0~2 的 32 次方, 這片定址空間對應的就是 2 的 32 個位元組,就是 4GB,這個 4GB,會有 3 個 GB 分給用戶空間,會有 1GB 給內核系統

在 linux 中,他們許可權分成兩個等級,0 和 3,用戶空間只能執行受限的命令(Ring3),而且不能直接調用系統資源,必須通過內核提供的介面來訪問內核空間可以執行特權命令(Ring0),調用一切系統資源,所以一般情況下,用戶的操作是運行在用戶空間,而內核運行的數據是在內核空間的,而有的情況下,一個應用程式需要去調用一些特權資源,去調用一些內核空間的操作,所以此時他倆需要在用戶態和內核態之間進行切換。
比如:
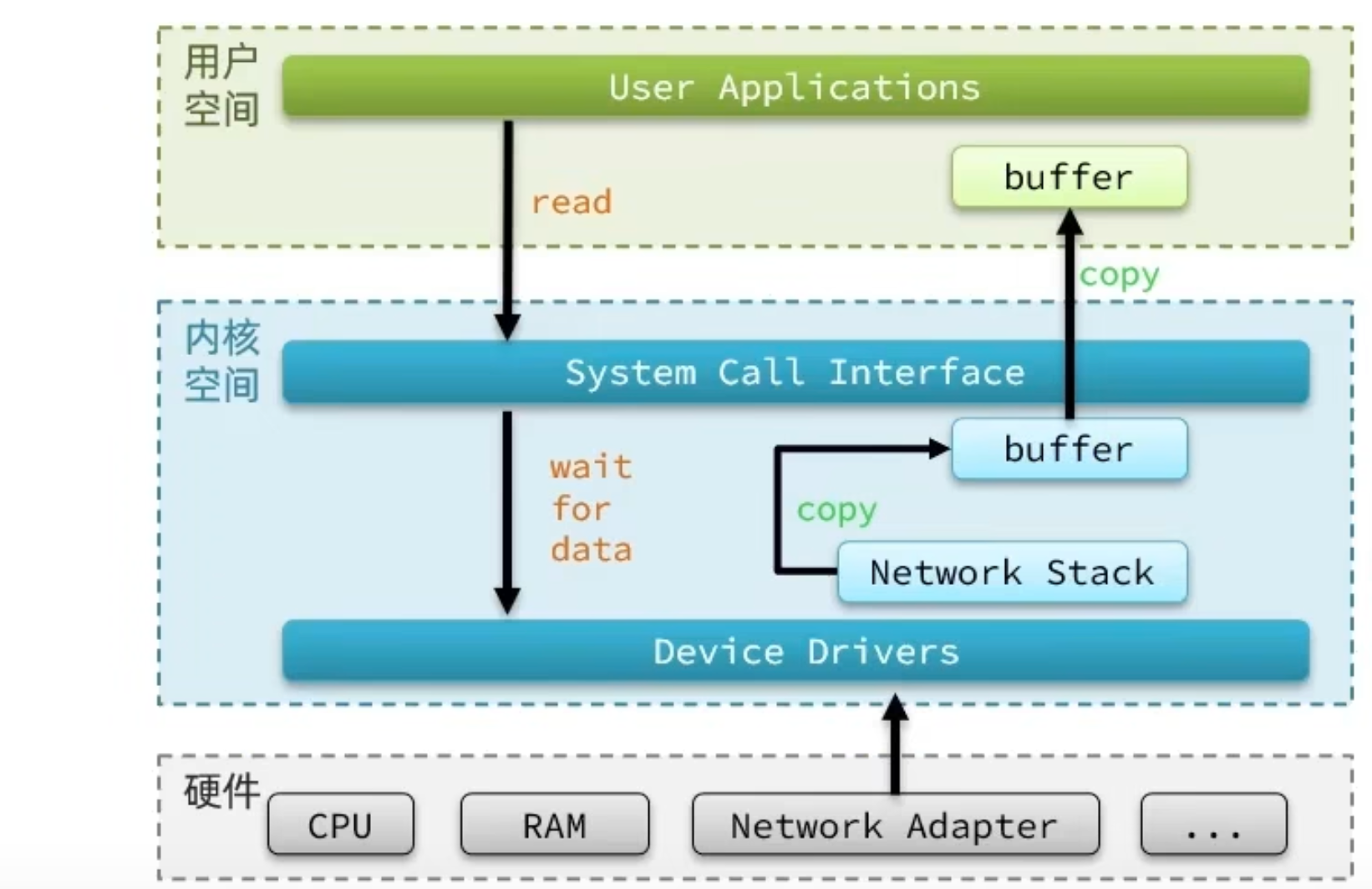
Linux 系統為了提高 IO 效率,會在用戶空間和內核空間都加入緩衝區:
- 寫數據時,要把用戶緩衝數據拷貝到內核緩衝區,然後寫入設備
- 讀數據時,要從設備讀取數據到內核緩衝區,然後拷貝到用戶緩衝區
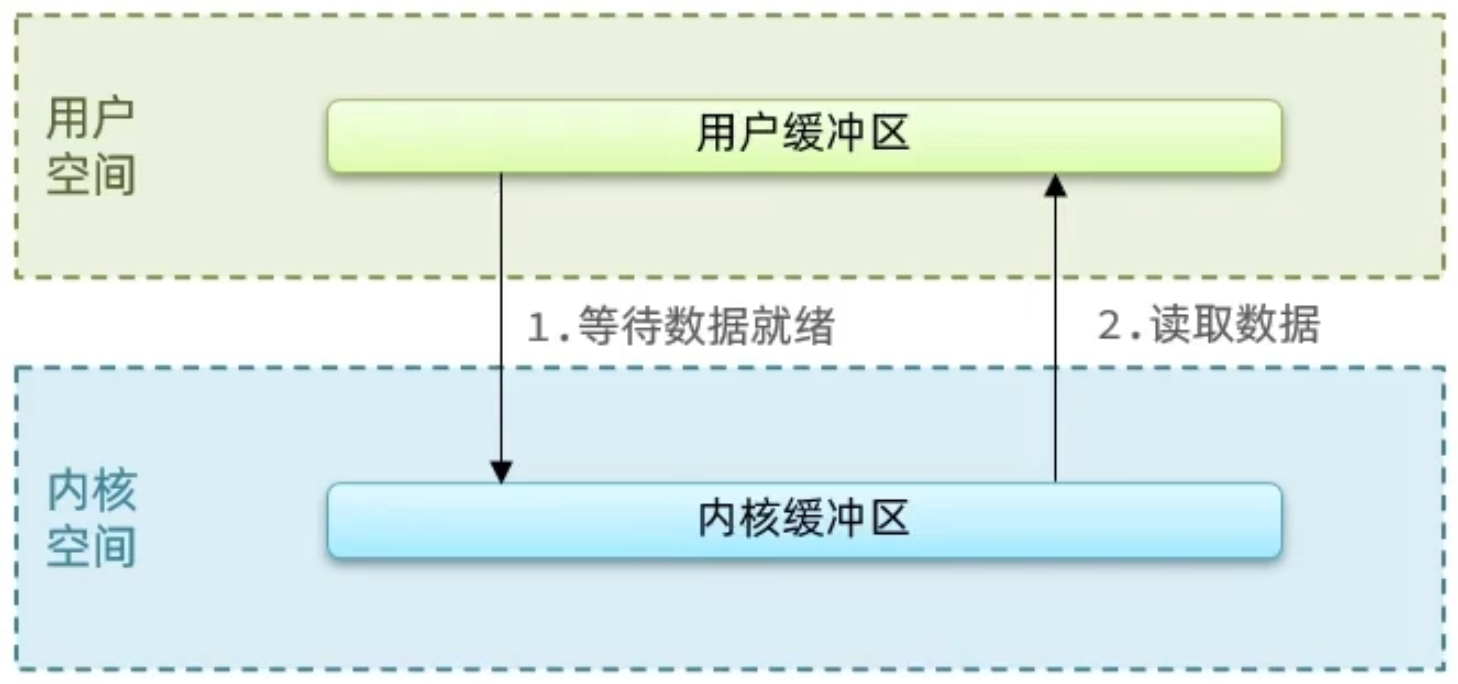
針對這個操作:我們的用戶在寫讀數據時,會去向內核態申請,想要讀取內核的數據,而內核數據要去等待驅動程式從硬體上讀取數據,當從磁碟上載入到數據之後,內核會將數據寫入到內核的緩衝區中,然後再將數據拷貝到用戶態的 buffer 中,然後再返回給應用程式,整體而言,速度慢,就是這個原因,為了加速,我們希望 read 也好,還是 wait for data 也最好都不要等待,或者時間儘量的短。
2. 網路模型
2.1 阻塞IO
- 過程 1:應用程式想要去讀取數據,他是無法直接去讀取磁碟數據的,他需要先到內核裡邊去等待內核操作硬體拿到數據,這個過程是需要等待的,等到內核從磁碟上把數據載入出來之後,再把這個數據寫給用戶的緩存區。
- 過程 2:如果是阻塞 IO,那麼整個過程中,用戶從發起讀請求開始,一直到讀取到數據,都是一個阻塞狀態。
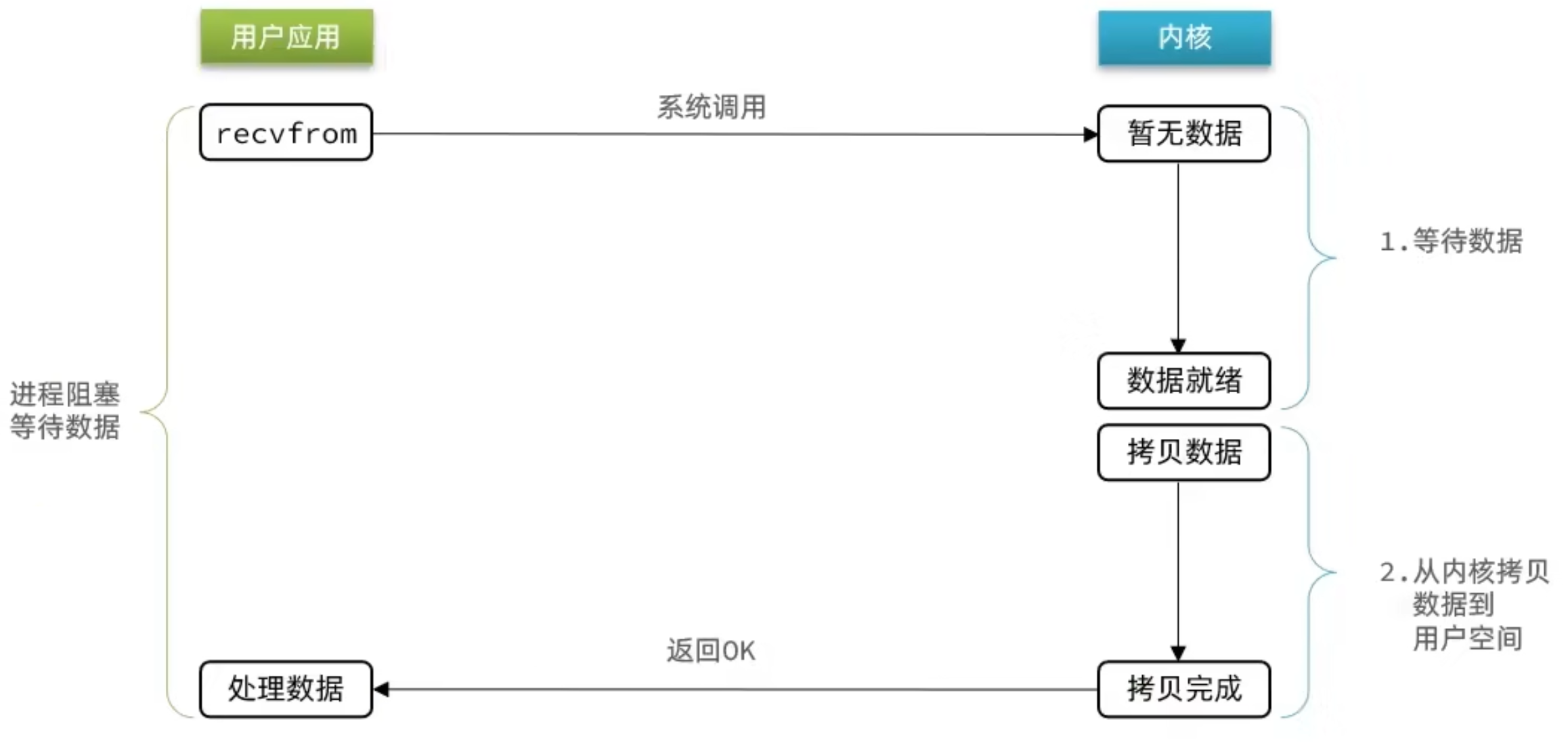
用戶去讀取數據時,會去先發起 recvform 一個命令,去嘗試從內核上載入數據,如果內核沒有數據,那麼用戶就會等待,此時內核會去從硬體上讀取數據,內核讀取數據之後,會把數據拷貝到用戶態,並且返回 ok,整個過程,都是阻塞等待的,這就是阻塞 IO
總結如下:
顧名思義,阻塞 IO 就是兩個階段都必須阻塞等待:
階段一:
- 用戶進程嘗試讀取數據(比如網卡數據)
- 此時數據尚未到達,內核需要等待數據
- 此時用戶進程也處於阻塞狀態
階段二:
- 數據到達並拷貝到內核緩衝區,代表已就緒
- 將內核數據拷貝到用戶緩衝區
- 拷貝過程中,用戶進程依然阻塞等待
- 拷貝完成,用戶進程解除阻塞,處理數據
可以看到,阻塞 IO 模型中,用戶進程在兩個階段都是阻塞狀態。
2.2 非阻塞 IO
顧名思義,非阻塞 IO 的 recvfrom 操作會立即返回結果而不是阻塞用戶進程
階段一:
- 用戶進程嘗試讀取數據(比如網卡數據)
- 此時數據尚未到達,內核需要等待數據
- 返回異常給用戶進程
- 用戶進程拿到 error 後,再次嘗試讀取
- 迴圈往複,直到數據就緒
階段二:
- 將內核數據拷貝到用戶緩衝區
- 拷貝過程中,用戶進程依然阻塞等待
- 拷貝完成,用戶進程解除阻塞,處理數據
- 可以看到,非阻塞 IO 模型中,用戶進程在第一個階段是非阻塞,第二個階段是阻塞狀態。雖然是非阻塞,但性能並沒有得到提高。而且忙等機制會導致 CPU 空轉,CPU 使用率暴增。
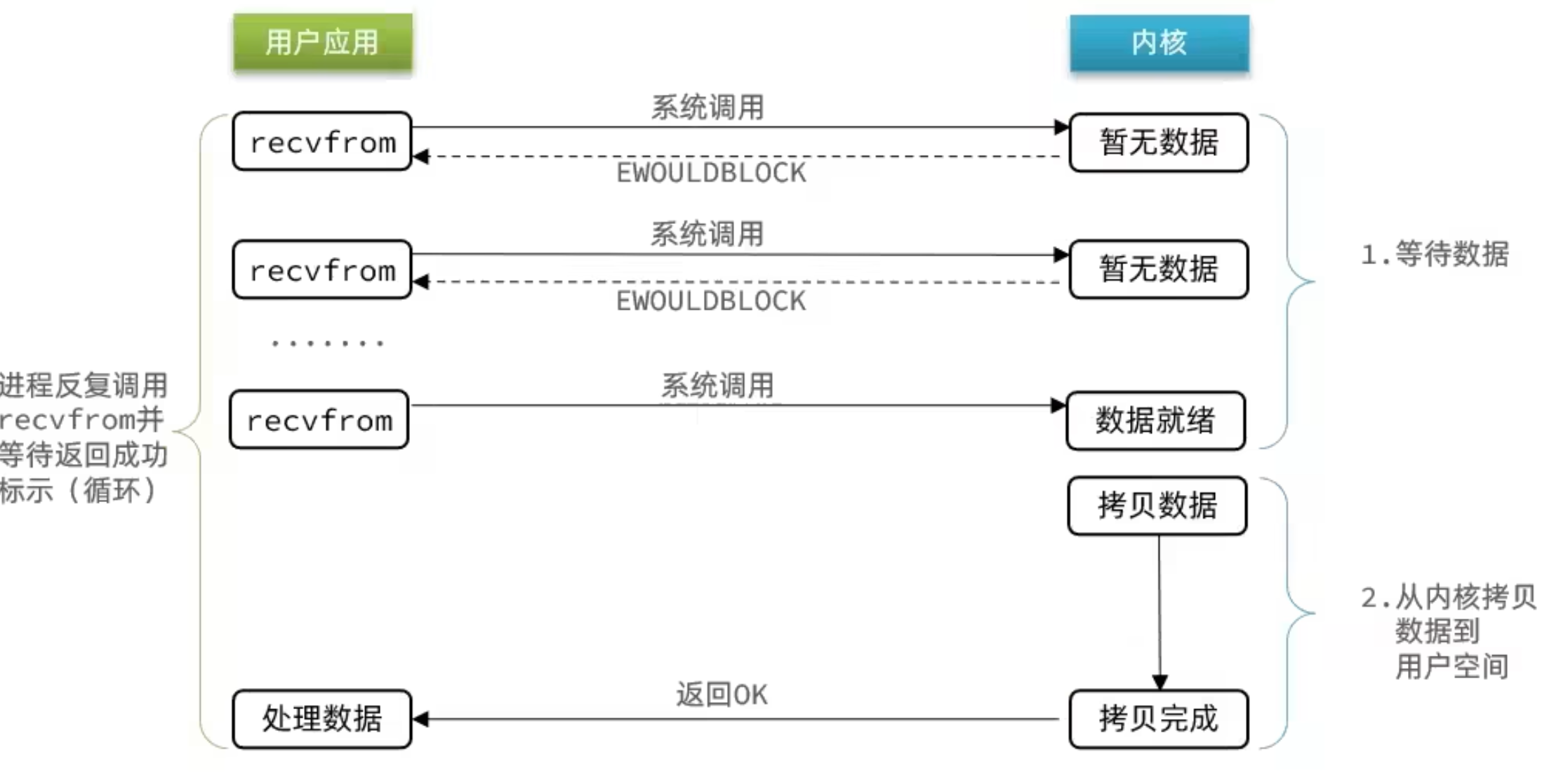
2.3 信號驅動
信號驅動 IO 是與內核建立 SIGIO 的信號關聯並設置回調,當內核有 FD 就緒時,會發出 SIGIO 信號通知用戶,期間用戶應用可以執行其它業務,無需阻塞等待。
階段一:
- 用戶進程調用 sigaction ,註冊信號處理函數
- 內核返回成功,開始監聽 FD
- 用戶進程不阻塞等待,可以執行其它業務
- 當內核數據就緒後,回調用戶進程的 SIGIO 處理函數
階段二:
- 收到 SIGIO 回調信號
- 調用 recvfrom ,讀取
- 內核將數據拷貝到用戶空間
- 用戶進程處理數據
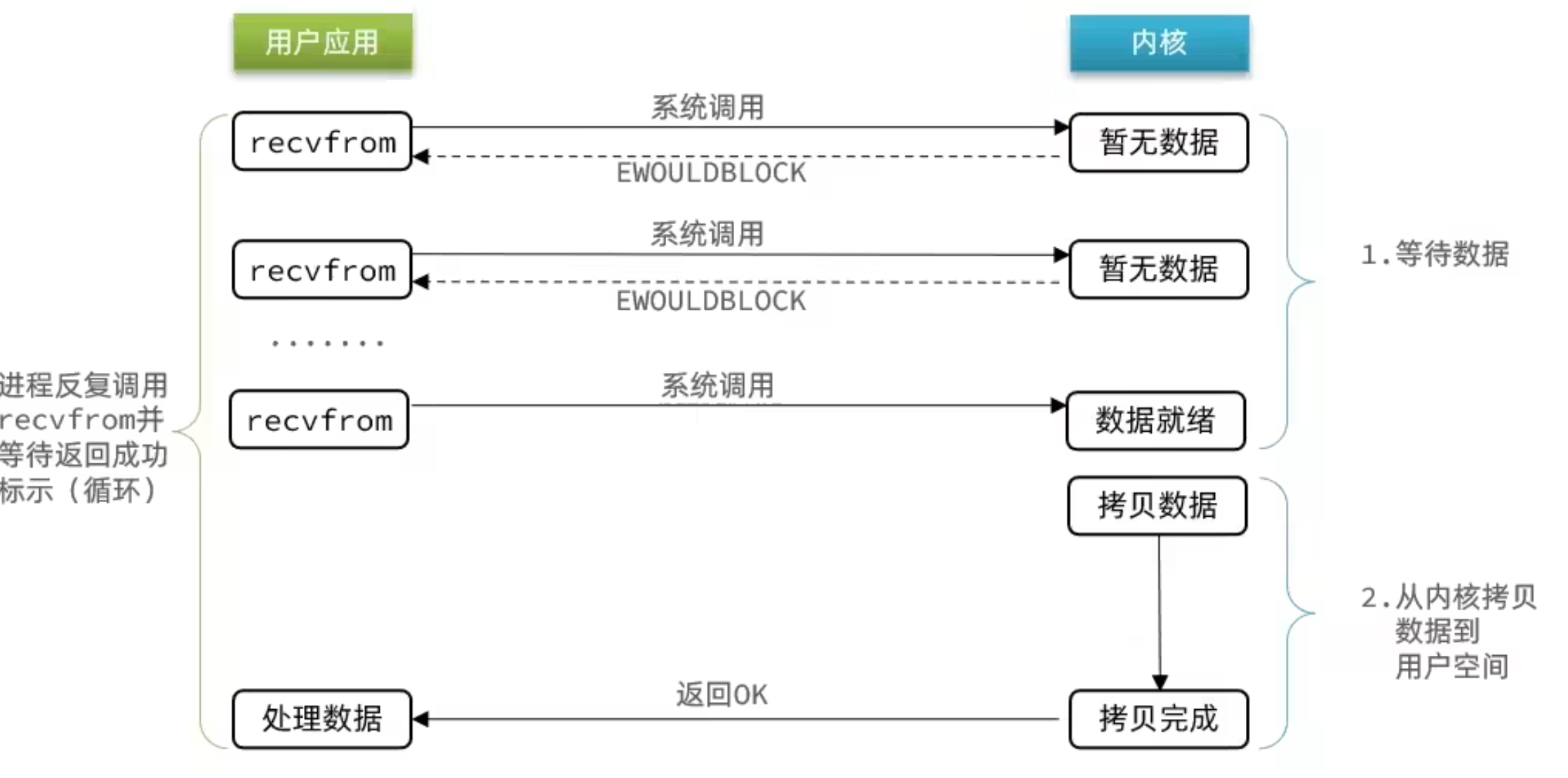
當有大量 IO 操作時,信號較多,SIGIO 處理函數不能及時處理可能導致信號隊列溢出,而且內核空間與用戶空間的頻繁信號交互性能也較低。
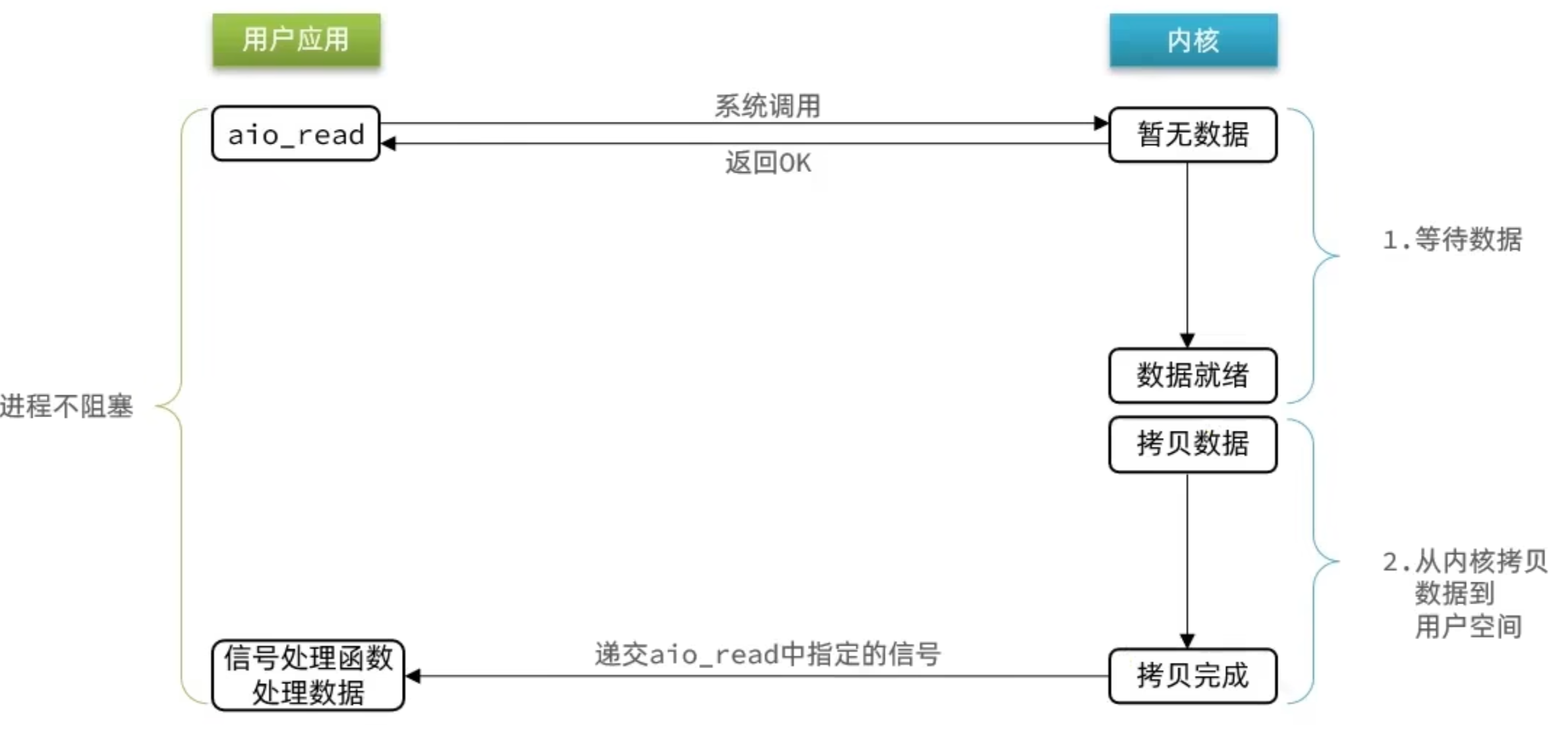
2.4 非同步 IO
這種方式,不僅僅是用戶態在試圖讀取數據後,不阻塞,而且當內核的數據準備完成後,也不會阻塞
他會由內核將所有數據處理完成後,由內核將數據寫入到用戶態中,然後才算完成,所以性能極高,不會有任何阻塞,全部都由內核完成,可以看到,非同步 IO 模型中,用戶進程在兩個階段都是非阻塞狀態。
2.5 IO 多路復用
場景引入
為了更好的理解 IO ,現在假設這樣一種場景:一家餐廳
- A 情況:這家餐廳中現在只有一位服務員,並且採用客戶排隊點餐的方式,就像這樣:

每排到一位客戶要吃到飯,都要經過兩個步驟:
思考要吃什麼
顧客開始點餐,廚師開始炒菜
由於餐廳只有一位服務員,因此一次只能服務一位客戶,並且還需要等待當前客戶思考出結果,這浪費了後續排隊的人非常多的時間,效率極低。這就是阻塞 IO。
當然,為了緩解這種情況,老闆完全可以多雇幾個人,但這也會增加成本,而在極大客流量的情況下,仍然不會有很高的效率提升
- B 情況: 這家餐廳中現在只有一位服務員,並且採用客戶排隊點餐的方式。
每排到一位客戶要吃到飯,都要經過兩個步驟:
- 思考要吃什麼
- 顧客開始點餐,廚師開始炒菜
與 A 情況不同的是,此時服務員會不斷詢問顧客:“你想吃番茄雞蛋蓋澆飯嗎?那滑蛋牛肉呢?那肉末茄子呢?……”
雖然服務員在不停的問,但是在網路中,這並不會增加數據的就緒速度,主要還是等顧客自己確定。所以,這並不會提高餐廳的效率,說不定還會招來更多差評。這就是非阻塞 IO。
- C 情況: 這家餐廳中現在只有一位服務員,但是不再採用客戶排隊的方式,而是顧客自己獲取菜單並點餐,點完後通知服務員,就像這樣:
每排到一位客戶要吃到飯,還是都要經過兩個步驟:
- 看著菜單,思考要吃什麼
- 通知服務員,我點好了
與 A B 不同的是,這種情況服務員不必再等待顧客思考吃什麼,只需要在收到顧客通知後,去接收菜單就好。這樣相當於餐廳在只有一個服務員的情況下,同時服務了多個人,而不像 A B,同一時刻只能服務一個人。此時餐廳的效率自然就提高了很多。
映射到我們的網路服務中,就是這樣:
- 客人:客戶端請求
- 點餐內容:客戶端發送的實際數據
- 老闆:操作系統
- 人力成本:系統資源
- 菜單:文件狀態描述符。操作系統對於一個進程能夠同時持有的文件狀態描述符的個數是有限制的,在 linux 系統中 $ulimit -n 查看這個限制值,當然也是可以 (並且應該) 進行內核參數調整的。
- 服務員:操作系統內核用於 IO 操作的線程 (內核線程)
- 廚師:應用程式線程 (當然廚房就是應用程式進程咯)
- 餐單傳遞方式:包括了阻塞式和非阻塞式兩種。
- 方法 A: 阻塞 IO
- 方法 B: 非阻塞 IO
- 方法 C: 多路復用 IO
2.6 多路復用 IO 的實現
目前流程的多路復用 IO 實現主要包括四種: select、poll、epoll、kqueue。下表是他們的一些重要特性的比較:
| IO 模型 | 相對性能 | 關鍵思路 | 操作系統 | JAVA 支持情況 |
|---|---|---|---|---|
| select | 較高 | Reactor | windows/Linux | 支持,Reactor 模式 (反應器設計模式)。Linux 操作系統的 kernels 2.4 內核版本之前,預設使用 select;而目前 windows 下對同步 IO 的支持,都是 select 模型 |
| poll | 較高 | Reactor | Linux | Linux 下的 JAVA NIO 框架,Linux kernels 2.6 內核版本之前使用 poll 進行支持。也是使用的 Reactor 模式 |
| epoll | 高 | Reactor/Proactor | Linux | Linux kernels 2.6 內核版本及以後使用 epoll 進行支持;Linux kernels 2.6 內核版本之前使用 poll 進行支持;另外一定註意,由於 Linux 下沒有 Windows 下的 IOCP 技術提供真正的 非同步 IO 支持,所以 Linux 下使用 epoll 模擬非同步 IO |
| kqueue | 高 | Proactor | Linux | 目前 JAVA 的版本不支持 |
多路復用 IO 技術最適用的是 “高併發” 場景,所謂高併發是指 1 毫秒內至少同時有上千個連接請求準備好。其他情況下多路復用 IO 技術發揮不出來它的優勢。另一方面,使用 JAVA NIO 進行功能實現,相對於傳統的 Socket 套接字實現要複雜一些,所以實際應用中,需要根據自己的業務需求進行技術選擇。
2.6.1 select
select 是 Linux 最早是由的 I/O 多路復用技術:
linux 中,一切皆文件,socket 也不例外,我們把需要處理的數據封裝成 FD,然後在用戶態時創建一個 fd_set 的集合(這個集合的大小是要監聽的那個 FD 的最大值 + 1,但是大小整體是有限制的 ),這個集合的長度大小是有限制的,同時在這個集合中,標明出來我們要控制哪些數據。
其內部流程:
用戶態下:
- 創建 fd_set 集合,包括要監聽的 讀事件、寫事件、異常事件 的集合
- 確定要監聽的 fd_set 集合
- 將要監聽的集合作為參數傳入 select () 函數中,select 中會將 集合複製到內核 buffer 中
內核態:
- 內核線程在得到 集合後,遍歷該集合
- 沒數據就緒,就休眠
- 當數據來時,線程被喚醒,然後再次遍歷集合,標記就緒的 fd 然後將整個集合,複製回用戶 buffer 中
- 用戶線程遍歷 集合,找到就緒的 fd ,再發起讀請求。

不足之處:
- 集合大小固定為 1024 ,也就是說最多維持 1024 個 socket,在海量數據下,不夠用
- 集合需要在 用戶 buffer 和內核 buffer 中反覆複製,涉及到 用戶態和內核態的切換,非常影響性能
2.6.2 poll
poll 模式對 select 模式做了簡單改進,但性能提升不明顯。
IO 流程:
- 創建 pollfd 數組,向其中添加關註的 fd 信息,數組大小自定義
- 調用 poll 函數,將 pollfd 數組拷貝到內核空間,轉鏈表存儲,無上限
- 內核遍歷 fd ,判斷是否就緒
- 數據就緒或超時後,拷貝 pollfd 數組到用戶空間,返回就緒 fd 數量 n
- 用戶進程判斷 n 是否大於 0, 大於 0 則遍歷 pollfd 數組,找到就緒的 fd
與 select 對比:
- select 模式中的 fd_set 大小固定為 1024,而 pollfd 在內核中採用鏈表,理論上無上限,但實際上不能這麼做,因為的監聽 FD 越多,每次遍歷消耗時間也越久,性能反而會下降

2.6.3 epoll
epoll 模式是對 select 和 poll 的改進,它提供了三個函數:eventpoll 、epoll_ctl 、epoll_wait
- eventpoll 函數內部包含了兩個東西 :
- 紅黑樹 :用來記錄所有的 fd
- 鏈表 : 記錄已就緒的 fd
- epoll_ctl 函數 ,將要監聽的 fd 添加到 紅黑樹 上去,並且給每個 fd 綁定一個監聽函數,當 fd 就緒時就會被觸發,這個監聽函數的操作就是 將這個 fd 添加到 鏈表中去。
- epoll_wait 函數,就緒等待。一開始,用戶態 buffer 中創建一個空的 events 數組,當就緒之後,我們的回調函數會把 fd 添加到鏈表中去,當函數被調用的時候,會去檢查鏈表(當然這個過程需要參考配置的等待時間,可以等一定時間,也可以一直等),如果鏈表中沒有有 fd 則 fd 會從紅黑樹被添加到鏈表中,此時再將鏈表中的的 fd 複製到 用戶態的空 events 中,並且返回對應的操作數量,用戶態此時收到響應後,會從 events 中拿到已經準備好的數據,在調用 讀方法 去拿數據。
2.6.4 總結:
select 模式存在的三個問題:
- 能監聽的 FD 最大不超過 1024
- 每次 select 都需要把所有要監聽的 FD 都拷貝到內核空間
- 每次都要遍歷所有 FD 來判斷就緒狀態
poll 模式的問題:
- poll 利用鏈表解決了 select 中監聽 FD 上限的問題,但依然要遍歷所有 FD,如果監聽較多,性能會下降
epoll 模式中如何解決這些問題的?
- 基於 epoll 實例中的紅黑樹保存要監聽的 FD,理論上無上限,而且增刪改查效率都非常高
- 每個 FD 只需要執行一次 epoll_ctl 添加到紅黑樹,以後每次 epol_wait 無需傳遞任何參數,無需重覆拷貝 FD 到內核空間
- 利用 ep_poll_callback 機制來監聽 FD 狀態,無需遍歷所有 FD,因此性能不會隨監聽的 FD 數量增多而下降
2.7 基於 epoll 的伺服器端流程
一張圖搞定:

我們來梳理一下這張圖
- 伺服器啟動以後,服務端會去調用 epoll_create,創建一個 epoll 實例,epoll 實例中包含兩個數據
-
紅黑樹(為空):rb_root 用來去記錄需要被監聽的 FD
-
鏈表(為空):list_head,用來存放已經就緒的 FD
-
創建好了之後,會去調用 epoll_ctl 函數,此函數會會將需要監聽的 fd 添加到 rb_root 中去,並且對當前這些存在於紅黑樹的節點設置回調函數。
-
當這些被監聽的 fd 一旦準備就緒,與之相關聯的回調函數就會被調用,而調用的結果就是將紅黑樹的 fd 添加到 list_head 中去 (但是此時並沒有完成)
-
fd 添加完成後,就會調用 epoll_wait 函數,這個函數會去校驗是否有 fd 準備就緒(因為 fd 一旦準備就緒,就會被回調函數添加到 list_head 中),在等待了一段時間 (可以進行配置)。
-
如果等夠了超時時間,則返回沒有數據,如果有,則進一步判斷當前是什麼事件,如果是建立連接事件,則調用 accept () 接受客戶端 socket ,拿到建立連接的 socket ,然後建立起來連接,如果是其他事件,則把數據進行寫出。
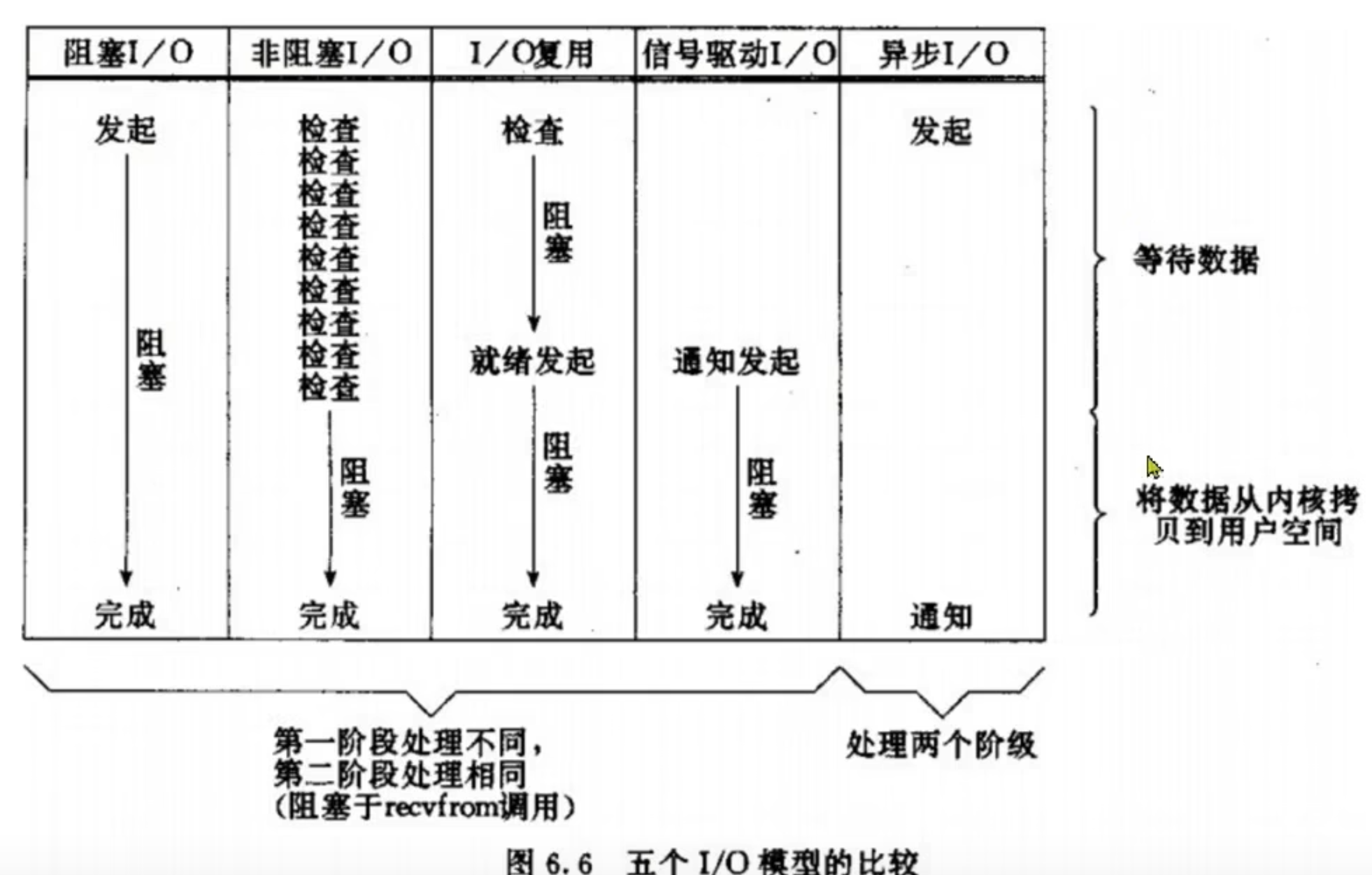
2.8 五種網路模型對比:
最後用一幅圖,來說明他們之間的區別
3. redis 通信協議
3.1 RESP 協議
Redis 是一個 CS 架構的軟體,通信一般分兩步(不包括 pipeline 和 PubSub):
- 客戶端(client)向服務端(server)發送一條命令,服務端解析並執行命令
- 返迴響應結果給客戶端,因此客戶端發送命令的格式、服務端響應結果的格式必須有一個規範,這個規範就是通信協議。
而在 Redis 中採用的是 RESP(Redis Serialization Protocol)協議:
- Redis 1.2 版本引入了 RESP 協議
- Redis 2.0 版本中成為與 Redis 服務端通信的標準,稱為 RESP2
- Redis 6.0 版本中,從 RESP2 升級到了 RESP3 協議,增加了更多數據類型並且支持 6.0 的新特性–客戶端緩存
但目前,預設使用的依然是 RESP2 協議。在 RESP 中,通過首位元組的字元來區分不同數據類型,常用的數據類型包括 5 種:
- 單行字元串:首位元組是 ‘+’ ,後面跟上單行字元串,以 CRLF( “\r\n” )結尾。例如返回”OK”: “+OK\r\n”
- 錯誤(Errors):首位元組是 ‘-’ ,與單行字元串格式一樣,只是字元串是異常信息,例如:”-Error message\r\n”
- 數值:首位元組是 ‘:’ ,後面跟上數字格式的字元串,以 CRLF 結尾。例如:”:10\r\n”
- 多行字元串:首位元組是 ‘$’ ,表示二進位安全的字元串,最大支持 512MB:
- 如果大小為 0,則代表空字元串:”$0\r\n\r\n”
- 如果大小為 - 1,則代表不存在:”$-1\r\n”
- 數組:首位元組是 ‘*’,後面跟上數組元素個數,再跟上元素,元素數據類型不限 :

本文由
傳智教育博學谷教研團隊發佈。如果本文對您有幫助,歡迎
關註和點贊;如果您有任何建議也可留言評論或私信,您的支持是我堅持創作的動力。轉載請註明出處!


