
介面優化過程記錄 問題背景 某個介面耗時長(247ms),但裡面邏輯不算複雜,只進行了簡單的對象引用以及操作了多次Redis 步驟1:鏈路追蹤,確定業務耗時點 介面里通過鏈路追蹤以及日誌查詢發現主要是操作Redis的這條鏈路耗時變長 步驟2:從Redis找問題,列出可能點 原因可能是: Redis本 ...
介面優化過程記錄
問題背景
某個介面耗時長(247ms),但裡面邏輯不算複雜,只進行了簡單的對象引用以及操作了多次Redis
步驟1:鏈路追蹤,確定業務耗時點
介面里通過鏈路追蹤以及日誌查詢發現主要是操作Redis的這條鏈路耗時變長
步驟2:從Redis找問題,列出可能點
原因可能是:
- Redis本身存在問題,可能是命令複雜度、IO、連接數不夠、過載等
- 網路原因,獲取連接或者是數據傳輸耗時
經測試發現以下這些問題
-
使用本機ping伺服器,網路延遲大概在42ms(ping內網<1ms,ping公司線上環境7ms),屬於 高延遲
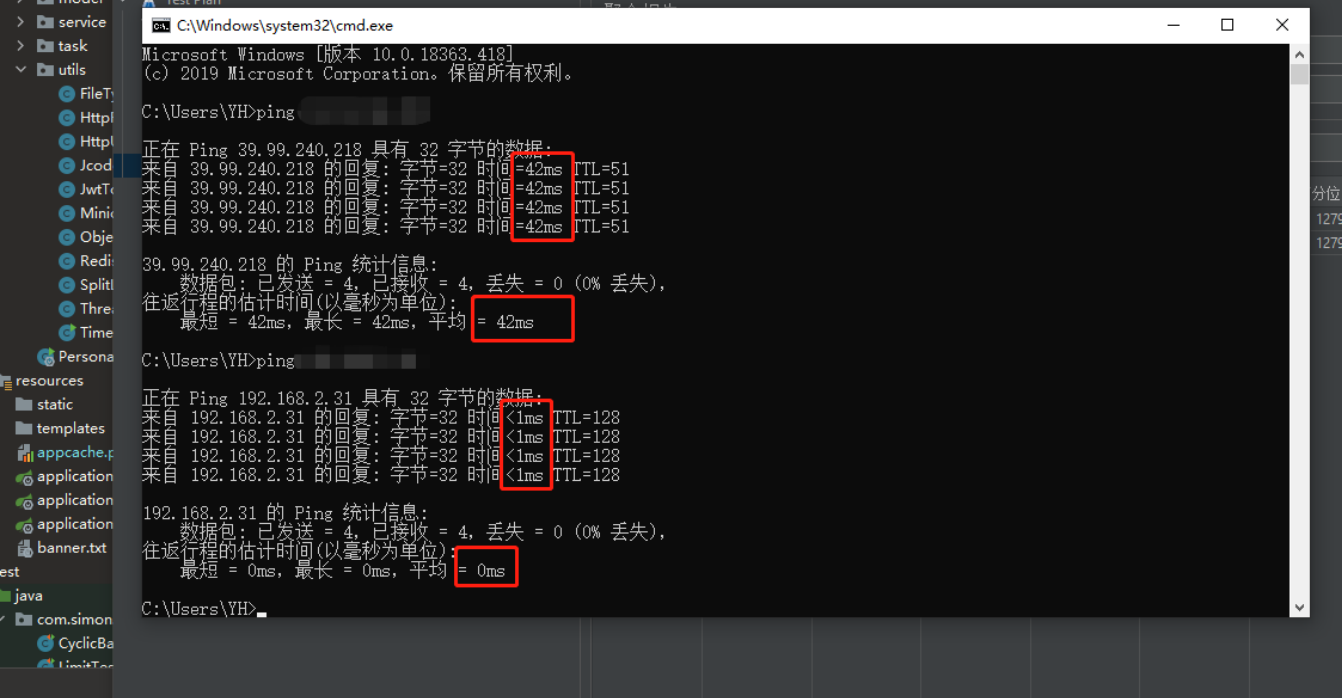
-
內部邏輯對獲取Redis連接進行耗時記錄,發現除首次獲取連接需30ms,後續獲取連接耗時 <1ms,
-
內部對Redis的一個get操作需要47ms(高耗時)
步驟二總結:
- 調用方與客戶端的網路高延遲
- 普通的get操作需要47ms不排除Redis本身存在問題,需要繼續排查
步驟3:從Redis內部排查
3.1從伺服器內部查看延遲峰值
由於Redis是使用Docker搭建,在虛擬化環境可能會差一些,不過還是先查看延遲峰值以及平均響應時 間
100秒內測試結果

60秒內測試結果
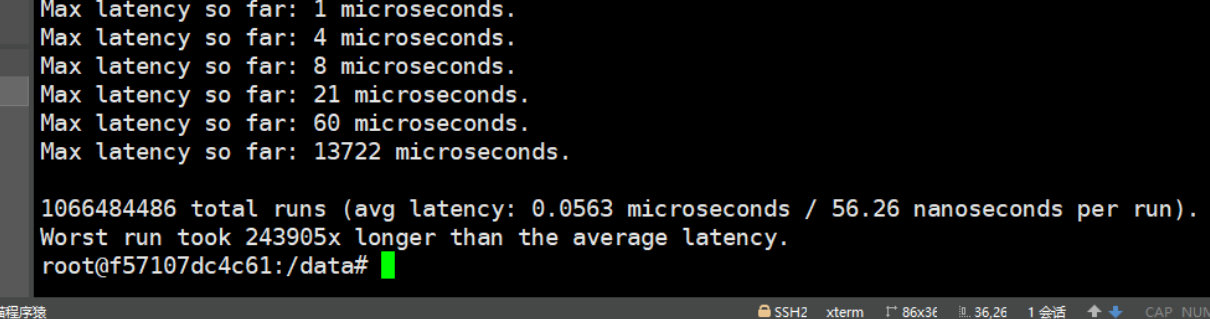
從測試數據可以看出
- 在100秒時,最大延遲為16ms,處理了1,762,165,232次命令平均響應時間為0.053ms
- 在60秒時,最大延遲為14ms,處理了1,066,484,486次命令平均響應時間為0.056ms
總結:從這一測試數據看單一get命令是不會到40+ms
3.2設置慢命令時間
通過給Redis設置slowlog時間為5ms,從業務代碼里操作set和get命令各200條,均無發現slowlog。
3.3命令複雜度過高(略)
介面里使用的命令只是簡單的get,set操作,並不是SORT、SUNION等聚合類容易導致操作延遲變大的 命令。
且O(N)里的N值並不大,也不需要花費很多時間在數據協議的組裝和網路傳輸過程中。
所以該指標不做測試。⚠ Ps:若是想測試該指標也可用slowlog進行排查。
3.4bigkey(略)
介面里操作的都不是bigkey,該指標不做測試。有需要可先使用redis命令掃描bigkey。註意:掃描時與 上述提到的延遲峰值都會使Redis的OPS突增。
3.5集中過期(略)
該Redis里並沒有過多數據,該指標不做測試。
3.6實例記憶體達到上限
從數據上來看,記憶體並沒有使用很多。
3.7fork耗時嚴重(略)
如3.5中所說,該指標不做測試
3.8連接數問題
從springboot里使用了nio開發的lettuce Redis線程池,當設置連接數為500時,在代碼層面開啟多個線 程一直跑,Redis客戶端連接數可以達到峰值,所以這塊暫時沒有問題。
暫時總結
根據上述數據總結出99%是網路問題造成的獲取數據延遲。當然還有很多指標都沒有列舉,例如:是否 開啟記憶體大頁、是否開啟AOF造成Redis、或者是是否使用Swap等。由於伺服器的Redis也算比較簡 單,這些也就預設是正常了
後續執行
後續可以再繼續監控
- 觀察連接數,是否有頻繁的短連接消耗
- 以及對Redis的各個指標進行監控

