1.5 HDFS分散式文件系統 1.5.1 HDFS 簡介 HDFS(全稱:Hadoop Distribute File System,Hadoop 分散式文件系統)是 Hadoop 核心組成,是分散式存儲服務。 分散式文件系統橫跨多台電腦,在大數據時代有著廣泛的應用前景,它們為存儲和處理超大規模 ...
目錄
1.5 HDFS分散式文件系統
1.5.1 HDFS 簡介
HDFS(全稱:Hadoop Distribute File System,Hadoop 分散式文件系統)是 Hadoop 核心組成,是分散式存儲服務。
分散式文件系統橫跨多台電腦,在大數據時代有著廣泛的應用前景,它們為存儲和處理超大規模數據提供所需的擴展能力。
HDFS是分散式文件系統中的一種。
1.5.2 HDFS的重要概念
HDFS 通過統一的命名空間目錄樹來定位文件;另外,它是分散式的,由很多伺服器聯合起來實現其功能,集群中的伺服器有各自的角色(分散式本質是拆分,各司其職)
-
典型的 Master/Slave 架構
HDFS 的架構是典型的 Master/Slave 結構。
HDFS集群往往是一個NameNode(HA架構會有兩個NameNode,聯邦機制)+ 多個DataNode組成。
NameNode是集群的主節點,DataNode是集群的從節點。
-
分塊存儲(block機制)
HDFS中的文件在物理上是分塊存儲(block)的,塊的大小可以通過配置參數來規定。
Hadoop2.x版本中預設的block大小是128M。
-
命名空間(NameSpace)
HDFS支持傳統的層次型文件組織結構。用戶或者應用程式可以創建目錄,然後將文件保存在這些目錄里。文件系統名字空間的層次結構和大多數現有的文件系統類似:用戶可以創建、刪除、移動 或重命名文件。
Namenode 負責維護文件系統的名字空間,任何對文件系統名字空間或屬性的修改都將被 Namenode 記錄下來。
HDFS提供給客戶單一個抽象目錄樹,訪問形式:hdfs://namenode的hostname:port/test/input
hdfs://linux121:9000/test/input
-
NameNode元數據管理
我們把目錄結構及文件分塊位置信息叫做元數據。
NameNode的元數據記錄每一個文件所對應的block信息(block的id,以及所在的DataNode節點的信息)
-
DataNode數據存儲
文件的各個 block 的具體存儲管理由 DataNode 節點承擔。一個block會有多個DataNode來存儲,DataNode會定時向NameNode來彙報自己持有的block信息。
-
副本機制
為了容錯,文件的所有 block 都會有副本。每個文件的 block 大小和副本繫數都是可配置的。應用程式可以指定某個文件的副本數目。副本繫數可以在文件創建的時候指定,也可以在之後改變。 副本數量預設是3個。 -
一次寫入,多次讀出
HDFS是設計成適應一次寫入,多次讀出的場景,且不支持文件的隨機修改。(支持追加寫入, 不只支持隨機更新)
正因為如此,HDFS適合用來做大數據分析的底層存儲服務,並不適合用來做網盤等應用(修改不方便,延遲大,網路開銷大,成本太高)
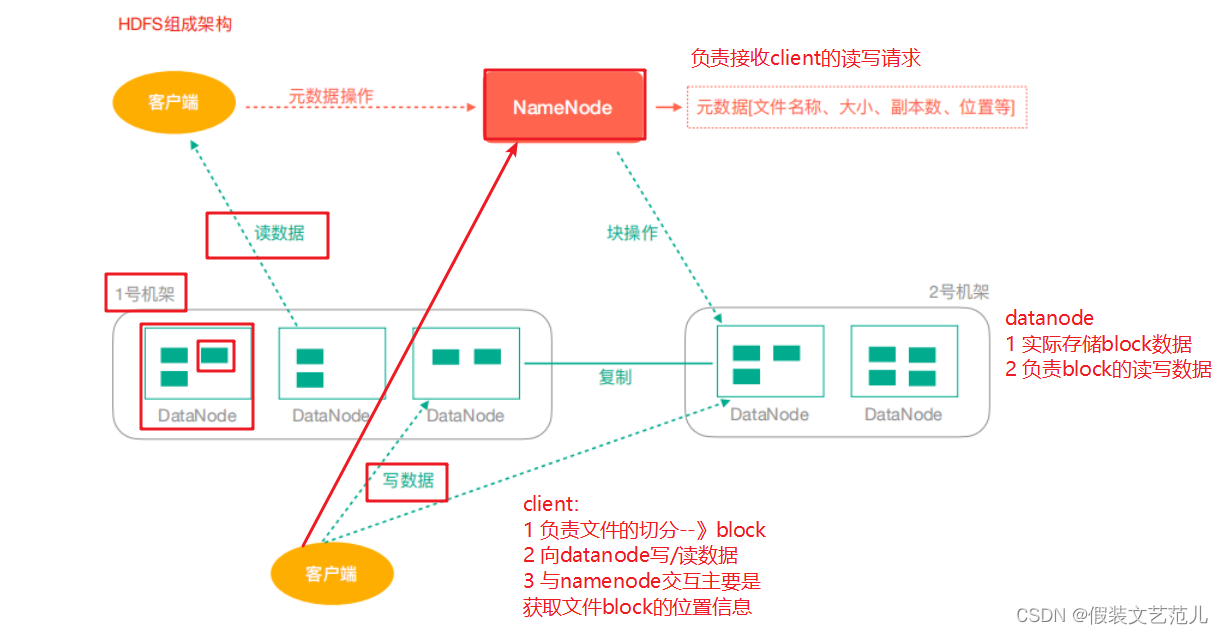
1.5.3 HDFS架構
-
NameNode(nn):hdfs集群的管理者,Master
-
維護管理hdfs的名稱空間(NameSpace)
-
維護副本策略
-
記錄文件塊(Block)的映射信息
-
負責處理客戶端讀寫請求
-
-
DataNode:NameNode下達命令,DataNode執行實際操作,Slave節點。
- 保存實際的數據塊
- 負責數據塊的讀寫
-
Client:客戶端
- 上傳文件到HDFS的時候,Client負責將文件切分成Block,然後進行上傳
- 請求NameNode交互,獲取文件的位置信息
- 讀取或寫入文件,與DataNode交互
- Client可以使用一些命令來管理HDFS或者訪問HDFS