1.4 Apache Hadoop 完全分散式集群搭建 軟體和操作系統版本 Hadoop框架是採用Java語言編寫,需要java環境(jvm) JDK版本:JDK8版本 集群: 知識點學習:統一使用vmware虛擬機虛擬三台linux節點,linux操作系統:Centos7 生產階段:建議最少5台服 ...
目錄
1.4 Apache Hadoop 完全分散式集群搭建
- 軟體和操作系統版本
Hadoop框架是採用Java語言編寫,需要java環境(jvm)
JDK版本:JDK8版本
集群:
知識點學習:統一使用vmware虛擬機虛擬三台linux節點,linux操作系統:Centos7
生產階段:建議最少5台伺服器節點 - Hadoop搭建方式
單機模式:單節點模式,非集群,生產不會使用這種方式
單機偽分散式模式:單節點,多線程模擬集群的效果,生產不會使用這種方式
完全分散式模式:多台節點,真正的分散式Hadoop集群的搭建(生產環境建議使用這種方式)
1.4.1 虛擬機環境準備
- 三台虛擬機(靜態IP,關閉防火牆,修改主機名,配置免密登錄,集群時間同步)
- 在/opt目錄下創建文件夾
#軟體安裝包存放目錄
mkdir -p /opt/lagou/software
#軟體安裝目錄
mkdir -p /opt/lagou/servers
- Hadoop下載地址:
https://archive.apache.org/dist/hadoop/common/hadoop-2.9.2/
Hadoop官網地址:
- 上傳hadoop安裝文件到/opt/lagou/software
1.4.2 集群規劃
| 框架 | linux121 | linux122 | linux123 |
|---|---|---|---|
| HDFS | NameNode、DataNode | DataNode | SecondaryNameNode、DataNode |
| YARN | NodeManager | NodeManager | NodeManager、ResourceManager |
1.4.3 安裝Hadoop
- 登錄linux121節點;進入/opt/lagou/software,解壓安裝文件到/opt/lagou/servers
tar -zxvf hadoop-2.9.2.tar.gz -C /opt/lagou/servers
- 查看是否解壓成功
ll /opt/lagou/servers/hadoop-2.9.2
- 添加Hadoop到環境變數 vim /etc/profile
#HADOOP_HOME
export HADOOP_HOME=/opt/lagou/servers/hadoop-2.9.2 export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
- 使環境變數生效
source /etc/profile
- 驗證hadoop
hadoop version
校驗結果:

- hadoop目錄
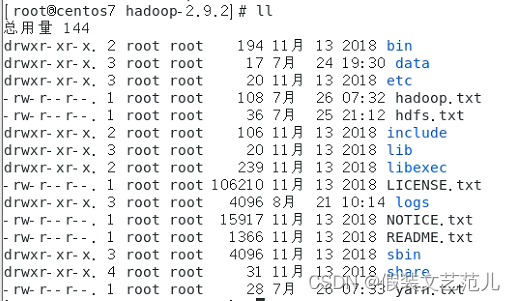
- bin目錄:對Hadoop進行操作的相關命令,如hadoop,hdfs等
- etc目錄:Hadoop的配置文件目錄,如hdfs-site.xml,core-site.xml等
- lib目錄:Hadoop本地庫(解壓縮的依賴)
- sbin目錄:存放的是Hadoop集群啟動停止相關腳本,命令
- share目錄:Hadoop的一些jar,官方案例jar,文檔等
1.4.3.1 集群配置
Hadoop集群配置 = HDFS集群配置 + MapReduce集群配置 + Yarn集群配置
- HDFS集群配置
- 將JDK路徑明確配置給HDFS(修改hadoop-env.sh)
- 指定NameNode節點以及數據存儲目錄(修改core-site.xml)
- 指定SecondaryNameNode節點(修改hdfs-site.xml)
- 指定DataNode從節點(修改etc/hadoop/slaves文件,每個節點配置信息占一行)
- MapReduce集群配置
- 將JDK路徑明確配置給MapReduce(修改mapred-env.sh)
- 指定MapReduce計算框架運行Yarn資源調度框架(修改mapred-site.xml)
- Yarn集群配置
- 將JDK路徑明確配置給Yarn(修改yarn-env.sh)
- 指定ResourceManager老大節點所在電腦節點(修改yarn-site.xml)
- 指定NodeManager節點(會通過slaves文件內容確定)
集群配置具體步驟:
1.4.3.1.1 HDFS集群配置
cd /opt/lagou/servers/hadoop-2.9.2/etc/hadoop
-
配置:hadoop-env.sh
將JDK路徑明確配置給HDFS
vim hadoop-env.sh
export JAVA_HOME=/opt/lagou/servers/jdk1.8.0_231
-
指定NameNode節點以及數據存儲目錄(修改core-site.xml)
vim core-site.xml
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://linux121:9000</value>
</property>
<!-- 指定Hadoop運行時產生文件的存儲目錄 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/lagou/servers/hadoop-2.9.2/data/tmp</value>
</property>
core-site.xml的預設配置:
https://hadoop.apache.org/docs/r2.9.2/hadoop-project-dist/hadoop-common/core-default.xml
-
指定secondarynamenode節點(修改hdfs-site.xml)
vim hdfs-site.xml
<!-- 指定Hadoop輔助名稱節點主機配置 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>linux123:50090</value>
</property>
<!-- 副本數量 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
官方預設配置
https://hadoop.apache.org/docs/r2.9.2/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
- 指定datanode從節點(修改slaves文件,每個節點配置信息占一行)
vim slaves
linux121
linux122
linux123
註意:該文件中添加的內容結尾不允許有空格,文件中不允許有空行。
1.4.3.1.2 MapReduce集群配置
-
指定MapReduce使用的jdk路徑(修改mapred-env.sh)
vim mapred-env.sh
export JAVA_HOME=/opt/lagou/servers/jdk1.8.0_231
- 指定MapReduce計算框架運行Yarn資源調度框架(修改mapred-site.xml)
mv mapred-site.xml.template mapred-site.xml
vim mapred-site.xml
<!-- 指定MR運行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
mapred-site.xml預設配置
1.4.3.1.3 Yarn集群配置
- 指定JDK路徑
vim yarn-env.sh
export JAVA_HOME=/opt/lagou/servers/jdk1.8.0_231
- 指定ResourceManager的master節點信息(修改yarn-site.xml)
vim yarn-site.xml
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>linux123</value>
</property>
<!-- Reducer獲取數據的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
yarn-site.xml的預設配置
https://hadoop.apache.org/docs/r2.9.2/hadoop-yarn/hadoop-yarn-common/yarn-default.xml
- 指定NodeManager節點(slaves文件已修改)
註意:
Hadoop安裝目錄所屬用戶和所屬用戶組信息,預設是501 dialout,而我們操作Hadoop集群的用戶使用的是虛擬機的root用戶,所以為了避免出現信息混亂,修改Hadoop安裝目錄所屬用戶和用戶組!!!
chown -R root:root /opt/lagou/servers/hadoop-2.9.2
1.4.3.2 分發配置
編寫集群分發腳本rsync-script
- rsync 遠程同步工具
rsync主要用於備份和鏡像。具有速度快、避免複製相同內容和支持符號鏈接的優點。
rsync和scp區別:用rsync做文件的複製要比scp的速度快,rsync只對差異文件做更新。scp是把所有文 件都複製過去。
- 基本語法
rsync -rvl $pdir/$fname $user@$host:$pdir/$fname
命令 選項參數 要拷貝的文件路徑/名稱 目的用戶@主機:目的路徑/名稱
- 選項參數說明
表2-2
| 選項 | 功能 |
|---|---|
| -r | 遞歸 |
| -v | 顯示覆制過程 |
| -l | 拷貝符號連接 |
-
rsync案例
- 三台虛擬機安裝rsync (執行安裝需要保證機器聯網)
[root@linux121 ~]# yum install -y rsync- 把linux121機器上的/opt/lagou/software目錄同步到linux122伺服器的root用戶下的/opt/目錄
[root@linux121 opt]$ rsync -rvl /opt/lagou/software/ root@linux122:/opt/lagou/software -
集群分發腳本編寫
-
需求:迴圈複製文件到集群所有節點的相同目錄下
rsync命令原始拷貝:
rsync -rvl /opt/module root@linux123:/opt/ -
期望腳本
腳本+要同步的文件名稱 -
說明:在/usr/local/bin這個目錄下存放的腳本,root用戶可以在系統任何地方直接執行。
-
腳本實現
(1)在/usr/local/bin目錄下創建文件rsync-script,文件內容如下:[root@linux121 bin]$ touch rsync-script [root@linux121 bin]$ vim rsync-script在文件中編寫shell代碼
#!/bin/bash #1 獲取命令輸入參數的個數,如果個數為0,直接退出命令 paramnum=$# if((paramnum==0)); then echo no params; exit; fi #2 根據傳入參數獲取文件名稱 p1=$1 file_name=`basename $p1` echo fname=$file_name #3 獲取輸入參數的絕對路徑 pdir=`cd -P $(dirname $p1); pwd` echo pdir=$pdir #4 獲取用戶名稱 user=`whoami` #5 迴圈執行rsync for((host=121; host<124; host++)); do echo ------------------- linux$host -------------- rsync -rvl $pdir/$file_name $user@linux$host:$pdir done(2)修改腳本 rsync-script 具有執行許可權
[root@linux121 bin]$ chmod 777 rsync-script(3)調用腳本形式:rsync-script 文件名稱
[root@linux121 bin]$ rsync-script /home/root/bin(4)調用腳本分發Hadoop安裝目錄到其它節點
[root@linux121 bin]$ rsync-script /opt/lagou/servers/hadoop-2.9.2
-
1.4.4 啟動集群
註意:如果集群是第一次啟動,需要在Namenode所在節點格式化NameNode,非第一次不用執行格式化Namenode操作!!!
1.4.4.1 單節點啟動
[root@linux121 hadoop-2.9.2]$ hadoop namenode -format
格式化命令執行效果:

格式化後創建的文件:/opt/lagou/servers/hadoop-2.9.2/data/tmp/dfs/name/current

-
在linux121上啟動NameNode
[root@linux121 hadoop-2.9.2]$ hadoop-daemon.sh start namenode [root@linux121 hadoop-2.9.2]$ jps -
在linux121、linux122以及linux123上分別啟動DataNode
[root@linux121 hadoop-2.9.2]$ hadoop-daemon.sh start datanode [root@linux121 hadoop-2.9.2]$ jps 3461 NameNode 3608 Jps 3561 DataNode [root@linux122 hadoop-2.9.2]$ hadoop-daemon.sh start datanode [root@linux122 hadoop-2.9.2]$ jps 3190 DataNode 3279 Jps [root@linux123 hadoop-2.9.2]$ hadoop-daemon.sh start datanode [root@linux123 hadoop-2.9.2]$ jps 3237 Jps 3163 DataNode -
web端查看hdfs界面
查看HDFS集群正常節點:
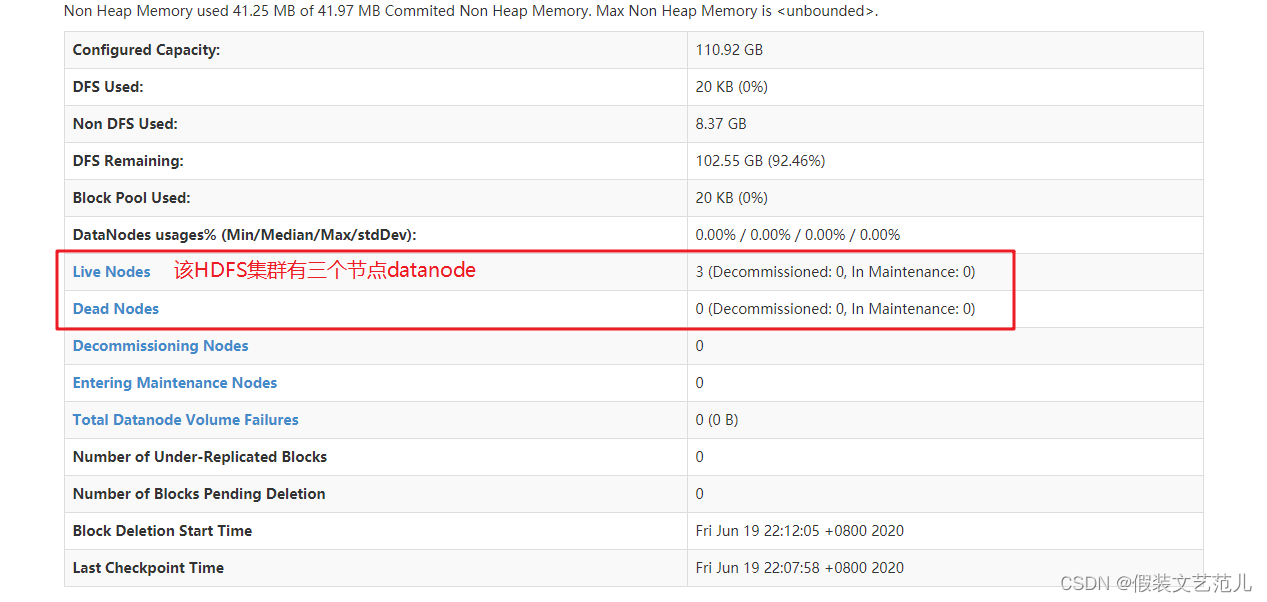
-
Yarn集群單節點啟動
[root@linux123 servers]# yarn-daemon.sh start resourcemanager [root@linux123 servers]# jps 7881 ResourceManager 8094 Jps [root@linux122 servers]# yarn-daemon.sh start nodemanager [root@linux122 servers]# jps 8166 NodeManager 8223 Jps [root@linux121 servers]# yarn-daemon.sh start nodemanager [root@linux121 servers]# jps 8166 NodeManager 8223 Jps -
思考:Hadoop集群每次需要一個一個節點的啟動,如果節點數增加到成千上萬個怎麼辦?
1.4.4.2 集群群起
-
如果已經單節點方式啟動了Hadoop,可以先停止之前的啟動的Namenode與Datanode進程,如果之前Namenode沒有執行格式化,這裡需要執行格式化!!!!
hadoop namenode -format -
啟動HDFS
[root@linux121 hadoop-2.9.2]$ sbin/start-dfs.sh [root@linux121 hadoop-2.9.2]$ jps 4166 NameNode 4482 Jps 4263 DataNode [root@linux122 hadoop-2.9.2]$ jps 3218 DataNode 3288 Jps [root@linux123 hadoop-2.9.2]$ jps 3221 DataNode 3283 SecondaryNameNode 3364 Jps -
啟動YARN
[root@linux123 hadoop-2.9.2]$ sbin/start-yarn.sh
註意:NameNode和ResourceManger不是在同一臺機器,不能在NameNode上啟動 YARN,應該 在ResouceManager所在的機器上啟動YARN。
1.4.4.3 Hadoop集群啟動停止命令彙總
-
各個服務組件逐一啟動/停止
-
分別啟動/停止HDFS組件
hadoop-daemon.sh start / stop namenode / datanode / secondarynamenode -
啟動/停止YARN
yarn-daemon.sh start / stop resourcemanager / nodemanager
-
-
各個模塊分開啟動/停止(配置ssh是前提)常用
-
整體啟動/停止HDFS
start-dfs.sh / stop-dfs.sh -
整體啟動/停止YARN
start-yarn.sh / stop-yarn.sh
-
1.4.5 集群測試
-
HDFS 分散式存儲初體驗
從linux本地文件系統上傳下載文件驗證HDFS集群工作正常
hdfs dfs -mkdir -p /test/input #本地hoome目錄創建一個文件 cd /root vim test.txt hello hdfs #上傳linxu文件到Hdfs hdfs dfs -put /root/test.txt /test/input #從Hdfs下載文件到linux本地 hdfs dfs -get /test/input/test.txt -
MapReduce 分散式計算初體驗
-
在HDFS文件系統根目錄下麵創建一個wcinput文件夾
[root@linux121 hadoop-2.9.2]$ hdfs dfs -mkdir /wcinput -
在/root/目錄下創建一個wc.txt文件(本地文件系統)
[root@linux121 hadoop-2.9.2]$ cd /root/ [root@linux121 wcinput]$ touch wc.txt -
編輯wc.txt文件
[root@linux121 wcinput]$ vi wc.txt -
在文件中輸入如下內容
hadoop mapreduce yarn hdfs hadoop mapreduce mapreduce yarn lagou lagou lagou -
保存退出
: wq! -
上傳wc.txt到Hdfs目錄/wcinput下
hdfs dfs -put wc.txt /wcinput -
回到Hadoop目錄/opt/lagou/servers/hadoop-2.9.2
-
執行程式
[root@linux121 hadoop-2.9.2]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.2.jar wordcount /wcinput /wcoutput -
查看結果
[root@linux121 hadoop-2.9.2]$ hdfs dfs -cat /wcoutput/part-r-00000 hadoop 2 hdfs 1 lagou 3 mapreduce 3 yarn 2
-
1.4.6 配置歷史伺服器
在Yarn中運行的任務產生的日誌數據不能查看,為了查看程式的歷史運行情況,需要配置一下歷史日誌伺服器。具體配置步驟如下:
-
配置mapred-site.xml
[root@linux121 hadoop]$ vi mapred-site.xml在該文件裡面增加如下配置。
<!-- 歷史伺服器端地址 --> <property> <name>mapreduce.jobhistory.address</name> <value>linux121:10020</value> </property> <!-- 歷史伺服器web端地址 --> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>linux121:19888</value> </property> -
分發mapred-site.xml到其它節點
rsync-script mapred-site.xml -
啟動歷史伺服器
[root@linux121 hadoop-2.9.2]$ sbin/mr-jobhistory-daemon.sh start historyserver -
查看歷史伺服器是否啟動
[root@linux121 hadoop-2.9.2]$ jps -
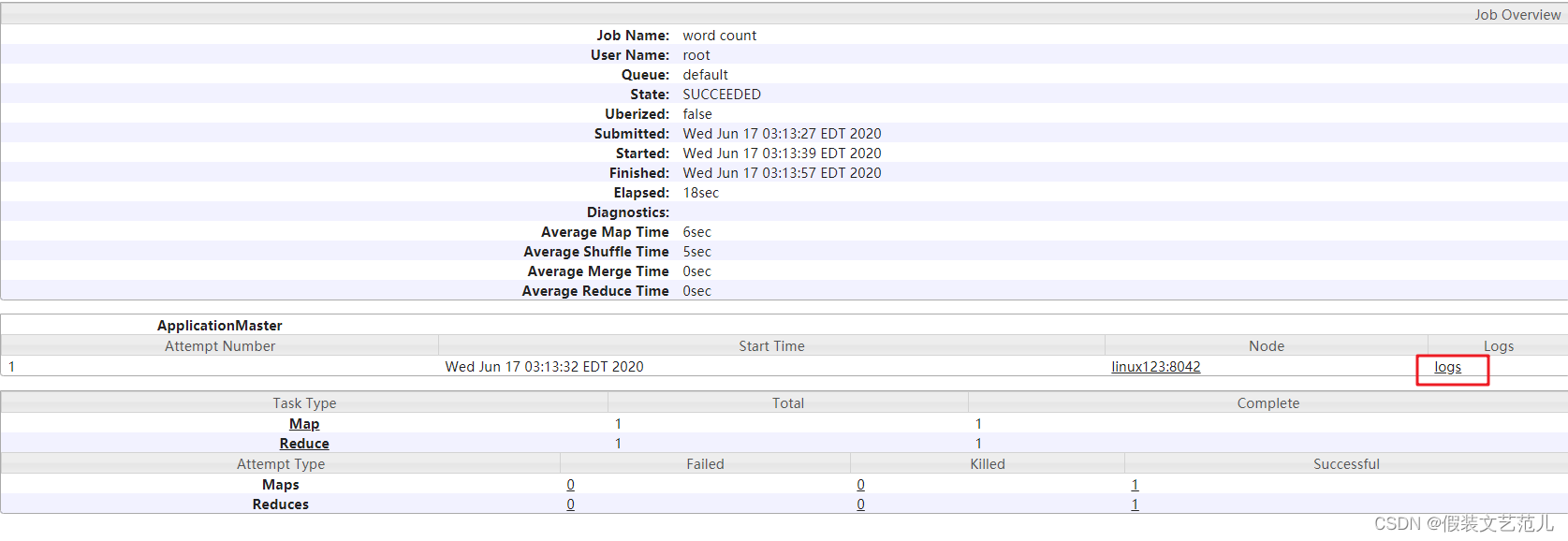
查看JobHistory
http://linux121:19888/jobhistory
1.4.6.1 配置日誌的聚集
日誌聚集:應用(Job)運行完成以後,將應用運行日誌信息從各個task彙總上傳到HDFS系統上。
日誌聚集功能好處:可以方便的查看到程式運行詳情,方便開發調試。
註意:開啟日誌聚集功能,需要重新啟動NodeManager 、ResourceManager和 HistoryManager。
開啟日誌聚集功能具體步驟如下:
-
配置yarn-site.xml
[root@linux121 hadoop]$ vi yarn-site.xml在該文件裡面增加如下配置。
<!-- 日誌聚集功能開啟 --> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <!-- 日誌保留時間設置7天 --> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property> <property> <name>yarn.log.server.url</name> <value>http://linux121:19888/jobhistory/logs</value> </property> -
分發yarn-site.xml到集群其它節點
rsync-script yarn-site.xml -
關閉NodeManager 、ResourceManager和HistoryManager
[root@linux121 hadoop-2.9.2]$ sbin/yarn-daemon.sh stop resourcemanager [root@linux121 hadoop-2.9.2]$ sbin/yarn-daemon.sh stop nodemanager [root@linux121 hadoop-2.9.2]$ sbin/mr-jobhistory-daemon.sh stop historyserver -
啟動NodeManager 、ResourceManager和HistoryManager
[root@linux121 hadoop-2.9.2]$ sbin/yarn-daemon.sh start resourcemanager [root@linux121 hadoop-2.9.2]$ sbin/yarn-daemon.sh start nodemanager [root@linux121 hadoop-2.9.2]$ sbin/mr-jobhistory-daemon.sh start historyserver -
刪除HDFS上已經存在的輸出文件
[root@linux121 hadoop-2.9.2]$ bin/hdfs dfs -rm -R /wcoutput -
執行WordCount程式
[root@linux121 hadoop-2.9.2]$ hadoop jar share/hadoop/mapreduce/hadoop- mapreduce-examples-2.9.2.jar wordcount /wcinput /wcoutput -
查看日誌,如圖所示