
下麵給出 Kafka 一些重要概念,讓大家對 Kafka 有個整體的認識和感知,後面還會詳細的解析每一個概念的作用以及更深入的原理 • Producer:消息生產者,向 Kafka Broker 發消息的客戶端。 • Consumer:消息消費者,從 Kafka Broker 取消息的客戶端。 • ...
下麵給出 Kafka 一些重要概念,讓大家對 Kafka 有個整體的認識和感知,後面還會詳細的解析每一個概念的作用以及更深入的原理
• Producer:消息生產者,向 Kafka Broker 發消息的客戶端。
• Consumer:消息消費者,從 Kafka Broker 取消息的客戶端。
• Consumer Group:消費者組(CG),消費者組內每個消費者負責消費不同分區的數據,提高消費能力。一個分區只能由組內一個消費者消費,消費者組之間互不影響。所有的消費者都屬於某個消費者組,即消費者組是邏輯上的一個訂閱者。
• Broker:一臺 Kafka 機器就是一個 Broker。一個集群由多個 Broker 組成。一個 Broker 可以容納多個 Topic。
• Topic:可以理解為一個隊列,Topic 將消息分類,生產者和消費者面向的是同一個 Topic。
• Partition:為了實現擴展性,提高併發能力,一個非常大的 Topic 可以分佈到多個 Broker (即伺服器)上,一個 Topic 可以分為多個 Partition,每個 Partition 是一個 有序的隊列。
• Replica:副本,為實現備份的功能,保證集群中的某個節點發生故障時,該節點上的 Partition 數據不丟失,且 Kafka 仍然能夠繼續工作,Kafka 提供了副本機制,一個 Topic 的每個分區都有若幹個副本,一個 Leader 和若幹個 Follower。
• Leader:每個分區多個副本的“主”副本,生產者發送數據的對象,以及消費者消費數據的對象,都是 Leader。
• Follower:每個分區多個副本的“從”副本,實時從 Leader 中同步數據,保持和 Leader 數據的同步。Leader 發生故障時,某個 Follower 還會成為新的 Leader。
• Offset:消費者消費的位置信息,監控數據消費到什麼位置,當消費者掛掉再重新恢復的時候,可以從消費位置繼續消費。
• ZooKeeper:Kafka 集群能夠正常工作,需要依賴於 ZooKeeper,ZooKeeper 幫助 Kafka 存儲和管理集群信息。
1. 消息和批次
Kafka中的數據單元稱為消息(message)。如果你對資料庫非常瞭解,那麼您可以將其視為與資料庫中行或記錄類似。就Kafka而言,消息只是一個位元組數組,因此其中包含的數據對Kafka沒有特定的格式或含義。消息可以具有可選的元數據位,其被稱為key。key也是一個位元組數組,與消息一樣,對Kafka沒有特定含義。當消息以更受控制的方式寫入分區時,使用key。最簡單的方案是生成key的一致哈希,然後通過獲取哈希模的結果(主題中的分區總數)來選擇該消息的分區號。這可確保具有相同key的消息始終寫入同一分區。
為了提高效率,將消息分批寫入Kafka。批處理只是一組消息,所有消息都生成到同一主題和分區。每條消息通過網路進行單獨的往返會導致過度的開銷,而將消息一起收集到一個批處理中則會減少這種情況。當然,這是延遲和吞吐量之間的權衡:批次越大,每單位時間可以處理的消息越多,但單個消息傳播所需的時間就越長。批次通常也是壓縮的,以一些處理能力為代價提供更有效的數據傳輸和存儲。
1.1 消息
是Kafka中的最小數據單元,類比“資料庫”中的一條記錄;消息由位元組數組組成,Kafka沒有具體的格式和定義,但是客戶端提供的消息定義中有一組可選的數據單元:
public final class ProducerRecord<K, V> {
private final String topic; //消息主題
private final Integer partition; //消息分區
private final K key; //消息的鍵
private final V value; // 消息值
}
在以上的欄位中,只有消息主題是必須的,標識這個消息的分類。
2.2 批次
同我們常說的分批處理思想中的批次概念是一致的;從根本上來講都是為了減少消耗,提升效率。
如果每一個生產者產生一條消息,我們就寫到網路中,會帶來大量的開銷,所以將消息分批次來傳遞;當然分批會帶來延遲,這樣就需要在延遲和吞吐量之間做一個權衡,Kafka提供參數來給開發者優化這種平衡。
單個批次消息越多,延遲越大,同時消息會被壓縮,來提升數據的傳輸和存儲能力,當然壓縮更消耗CPU。
批次裡面的消息都是屬於同一個主題中的同一個分區,這樣可以保證一次發送一批消息時的網路開銷最小。
2. 模式(Schemas)
雖然消息是Kafka本身的不透明位元組數組,但建議在消息內容上加上額外的結構或模式,以便易於理解。消息架構有許多選項,具體取決於您的應用程式的個性化需求。簡單系統,例如Javascript Object Notation(JSON)和可擴展標記語言(XML),易於使用且易於閱讀。但是,它們缺乏強大的類型處理和模式版本之間的相容性等功能。許多Kafka開發人員都贊成使用Apache Avro,這是一個最初為Hadoop開發的序列化框架。 Avro提供緊湊的序列化格式;與消息有效負載分離的模式,不需要在更改時生成代碼;強大的數據類型和模式演變,兼具向後和向前相容性。
一致的數據格式在Kafka中很重要,因為它允許寫入和讀取消息分離。當這些任務緊密耦合時,必須更新訂閱消息的應用程式以處理新數據格式,與舊格式並行。只有這樣才能更新發佈消息的應用程式以使用新格式。通過使用定義良好的模式並將它們存儲在一個通用的存儲庫中,可以無需協調地理解Kafka中的消息。
3. 主題和分區
Kafka 里的消息用主題進行分類(主題好比資料庫中的表) , 主題下有可以被分為若幹個分區(分表技術) 。 分區本質上是個提交日誌文件, 有新消息, 這個消息就會以追加的方式寫入分區(寫文件的形式) , 然後用先入先出的順序讀取。
3.1 主題
是消息的分類標識,類似於文件系統中的文件夾
3.2 分區
是一個主題的隊列,同一個主題會包含若幹分區,每一個分區都是一個提交記錄,消息會被追加到分區中,在一個分區中保證順序,以先入先出的順序被消費。
Kafka為每個分區中維護著一個偏移量,偏移量記錄著當前分區的消費記錄,偏移量保存在分散式協同伺服器ZooKeeper上。
分區在Kafka中有著重要的意義,Kafka通過分區來實現數據冗餘和主題的橫向擴展;多個分區可以分佈在不同的kafka服務端機器上,這使主題也可以橫跨多個伺服器存在,保證了分散式的能力;
在消息中講到了消息的鍵,在消息沒有配置鍵的時候,生產者會把消息均衡的寫入到各個分區。當我們需要把特定的消息寫入到固定的分區時,可以通過消息的鍵和分區器來實現,分區器會將鍵生成成散列值,並映射到各個分區上。
為了大量的消息能負載分散,要求主題的分區數要大於當前Kafka的broker伺服器數量,這樣才能保證所有每個broker能分擔到消息的壓力。在實際生產中,我們可以增加分區來給主題擴容,但是不能減少分區。
選定分區數量是一個需要經驗的事情,需要考慮多個因素:
-
主題需要多大的吞吐 -
單個分區的最大吞吐量多少 -
每個broker上擁有的分區數量,這需要考量磁碟和網路帶寬 -
單個分區上擁有的分區也不能太多,畢竟分區越多記憶體也越大,重新選舉的時間也越長
需要註意的是,如果使用了消息的鍵來控制消息寫入分區,那麼增加主題時就需要慎重了,因為這會帶來rehash的問題。
4. 生產者和消費者
Kafka客戶端是系統用戶,有兩種基本類型:生產者和消費者。還有高級客戶端API - 用於數據集成的Kafka Connect API和用於流處理的Kafka Streams。高級客戶端使用生產者和消費者作為構建塊,併在頂部提供更高級別的功能。
4.1 生產者
生產者創造新的信息。在其他發佈/訂閱系統中,這些可以稱為發佈者或編寫者。通常,將為特定主題生成消息。預設情況下,生產者不關心特定消息寫入的分區,並將均衡地平衡主題的所有分區上的消息。在某些情況下,生產者會將消息定向到特定分區。這通常使用消息key和分區程式來完成,該分區程式將生成key的散列並將其映射到特定分區。這確保了使用給定key生成的所有消息都將寫入同一分區。生產者還可以使用遵循其他業務規則的自定義分區程式將消息映射到分區。
4.2 消費者
消費者閱讀消息。 在其他發佈/訂閱系統中,這些客戶端可以被稱為訂閱者或讀者。 消費者訂閱一個或多個主題,並按消息的生成順序讀取消息。 消費者通過跟蹤消息的偏移來跟蹤它已經消耗了哪些消息。 偏移量(Offset)是元數據 - 一個不斷增加的整數值 - Kafka在生成時添加到每個消息中。 給定分區中的每條消息都有唯一的偏移量。 通過在Zookeeper或Kafka本身中存儲每個分區的最後消耗消息的偏移量,消費者可以停止並重新啟動而不會丟失其位置。
消費者負責消費者群組的一部分工作,消費者群組是一起工作以消費主題的一個或多個分區。 該小組確保每個分區僅由一名成員消費。 在單個組中有三個消費者使用主題。 其中兩個消費者分別在一個分區工作,而第三個消費者在兩個分區工作。 消費者對分區的映射通常稱為消費者對分區的所有權。
不同的消費者群組可以讀取同一個主題,但對於同一個群組中不同消費者不能讀取相同分區
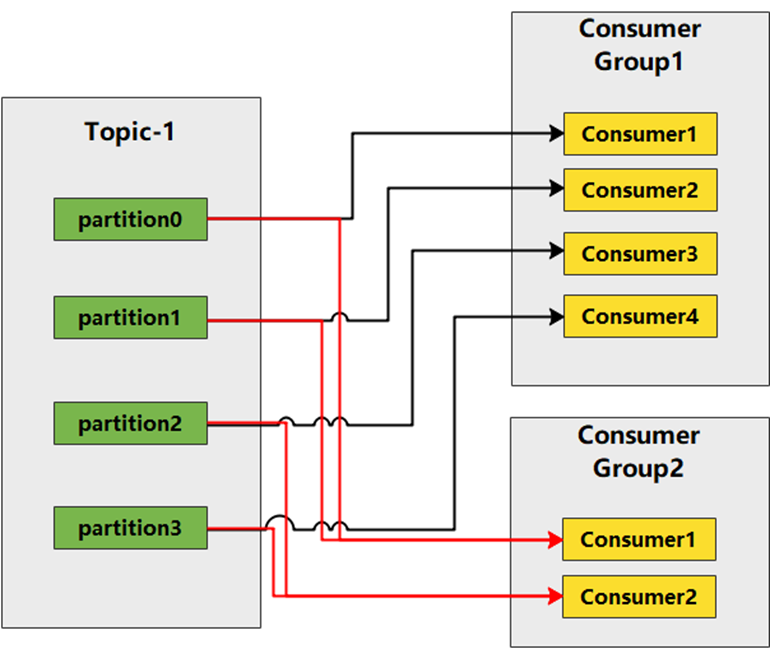
通過這種方式,消費者可以橫向擴展以消費具有大量消息的主題。 此外,如果單個使用者失敗,則該組的其餘成員將重新平衡正在使用的分區以接管缺少的成員。
5. 保留消息
保留消息是Kafka的一個重要特性。Kafka broker預設的消息保留策略有兩種。
-
保留一段固定的時間。比如7天 -
保留到消息達到一定大小的位元組數,如1GB 當達到上限後,舊的消息會過期從而被刪除。所以在任何時刻,可用消息的總量不會超過配置參數所指定的大小。
6. 多集群
隨著Kafka部署的增長,擁有多個集群通常是有利的。 有幾個原因可以解決這個問題:
• 分離數據類型
• 為安全要求隔離
• 多個數據中心(災難恢復)
特別是在處理多個數據中心時,通常需要在它們之間複製消息。 通過這種方式,線上應用程式可以訪問兩個站點的用戶活動。 例如,如果用戶更改其配置文件中的公共信息,則無論顯示搜索結果的數據中心如何,都需要顯示該更改。 或者,可以將監控數據從許多站點收集到分析和警報系統所在的單個中心位置。 Kafka集群中的複製機制僅設計用於單個集群,而不是多個集群之間。
Kafka項目包括一個名為MirrorMaker的工具,用於此目的。 MirrorMaker的核心是Kafka消費者和生產者,與隊列鏈接在一起。 消息從一個Kafka集群中消耗併為另一個集群生成。使用MirrorMaker架構,將來自兩個本地群集的消息聚合到聚合群集中,然後將該群集複製到其他數據中心。 應用程式的簡單特性掩蓋了它在創建複雜數據管道方面的能力。
本文由
傳智教育博學谷教研團隊發佈。如果本文對您有幫助,歡迎
關註和點贊;如果您有任何建議也可留言評論或私信,您的支持是我堅持創作的動力。轉載請註明出處!


