
一、什麼是數據湖? 在探討數據湖技術或如何構建數據湖之前,我們需要先明確,什麼是數據湖? 數據湖的起源,應該追溯到2010年10月。基於對半結構化、非結構化存儲的需求,同時為了推廣自家的Pentaho產品以及Hadoop,2010年Pentaho的創始人兼CTO James Dixon首次提出了數據 ...

l 採集網站
【場景描述】採集貓眼電影熱門資訊數據。
【源網站介紹】貓眼電影為用戶提供熱點影視資訊,新聞資訊,讓用戶能夠提前瞭解當下即將上映的電影信息。
【使用工具】前嗅ForeSpider數據採集系統,免費下載:
【入口網址】
https://www.maoyan.com/news?showTab=2&offset=0
【採集內容】
採集貓眼電影上的熱門新聞資訊數據,採集欄位:標題、資訊內容。
【採集效果】如下圖所示:

l 思路分析
配置思路概覽:

l 配置步驟
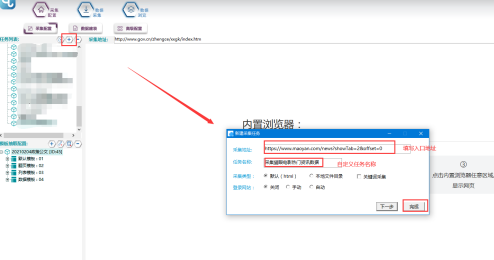
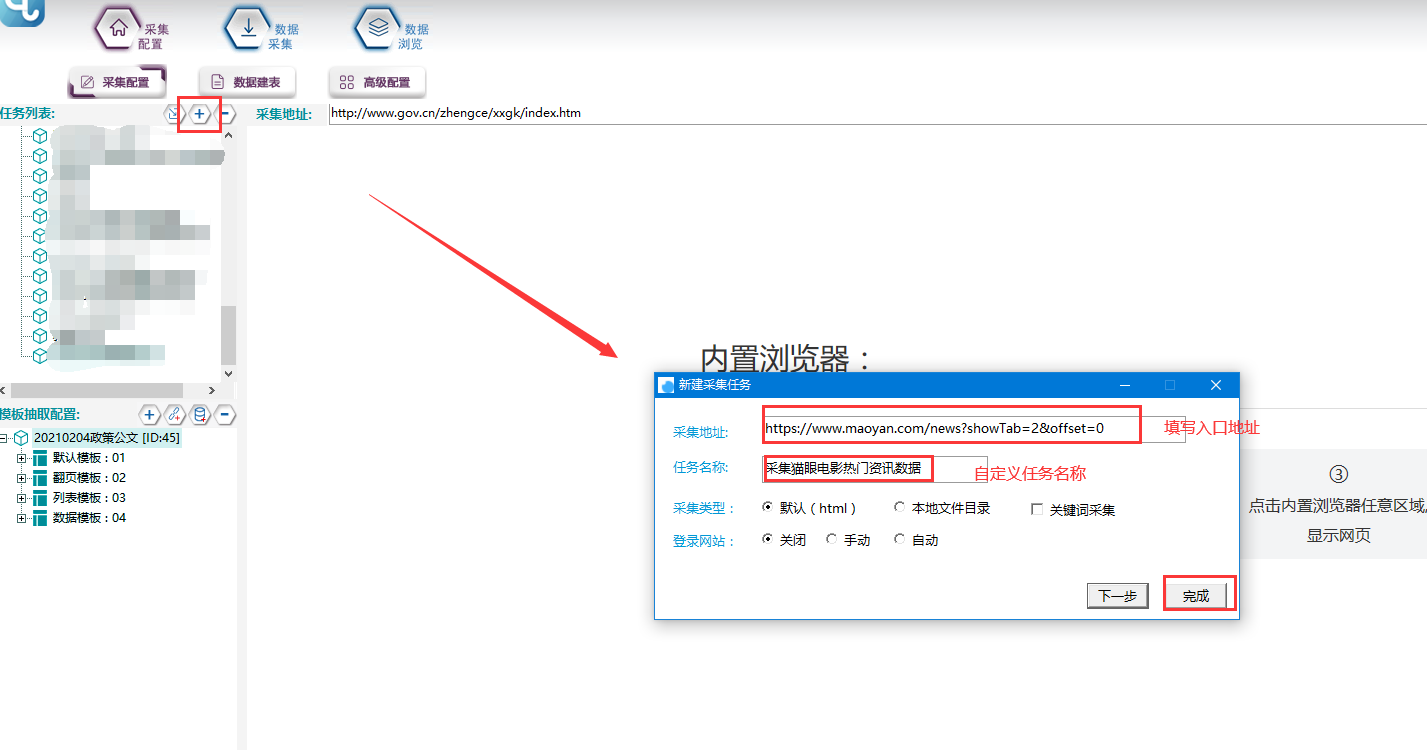
1.新建採集任務
選擇【採集配置】,點擊任務列表右上方【+】號可新建採集任務,將採集入口地址填寫在【採集地址】框中,【任務名稱】自定義即可,點擊下一步。
2.獲取翻頁鏈接
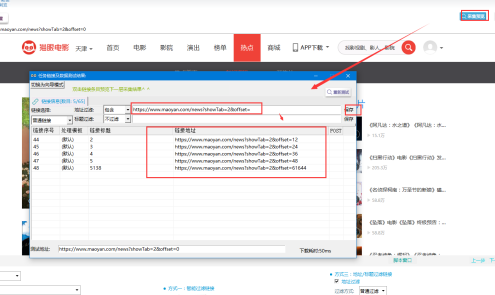
採用鏈接過濾的方法來抽取翻頁鏈接,具體如下所示:
①在瀏覽器上先觀察翻頁鏈接規律,找到規律,很明顯翻頁鏈接中都包含:https://www.maoyan.com/news?showTab=2&offset=
②設置地址過濾,過濾包含“https://www.maoyan.com/news?showTab=2&offset=”的鏈接,這樣就把翻頁鏈接過濾出來了。
③關聯模板,將翻頁鏈接抽取,關聯模板01。
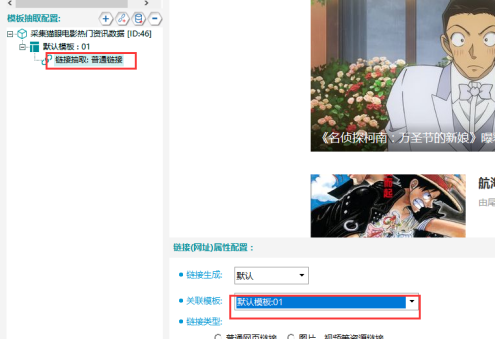
3.抽取列錶鏈接
①新建一個鏈接抽取,改名為【列錶鏈接】,將翻頁鏈接抽取改名為【翻頁鏈接】。
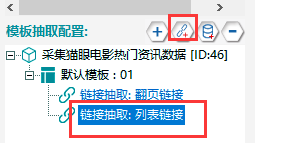
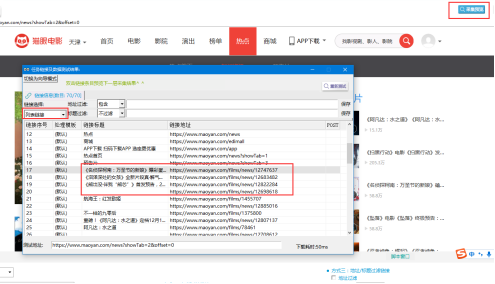
②使用鏈接過濾的方法來獲取列錶鏈接,先採集預覽,打開列錶鏈接預覽結果,找到資訊鏈接並觀察規律,發現其中都包括:“https://www.maoyan.com/films/news/+一串數字”
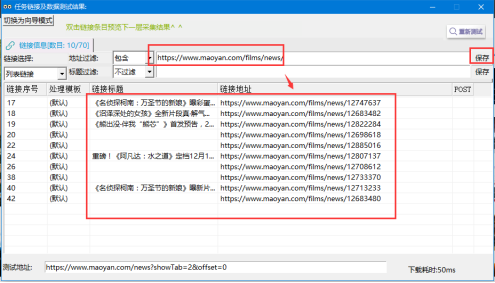
③設置地址過濾,過濾包含“https://www.maoyan.com/films/news/”的鏈接,這樣就把翻頁鏈接過濾出來了。其中\d表示數字串。
4.抽取數據
①新建一個抽取模板,在其下新建一個數據抽取,具體操作如下所示:
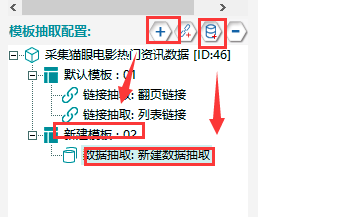
②數據建表,按照下圖所示建數據表。(註意欄位屬性等應嚴格按照下圖進行設置)

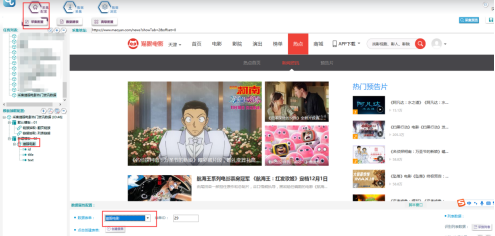
③將新建好的數據表,關聯到模板中去,如下圖所示:
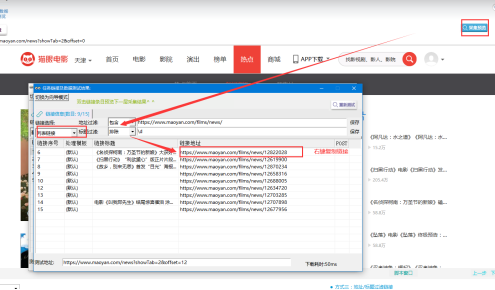
④填寫示例數據,採集預覽,複製任意一條影評鏈接。
⑤將鏈接粘貼到本模板示例地址中,並雙擊內置瀏覽器空白部分,載入本鏈接。
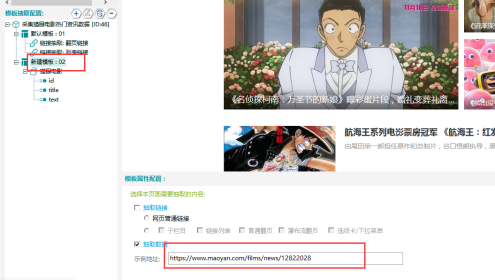
⑥關聯模板
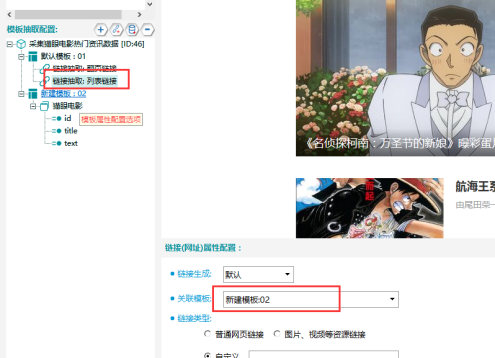
⑦數據取值
使用定位取值的方法,title欄位如下所示:
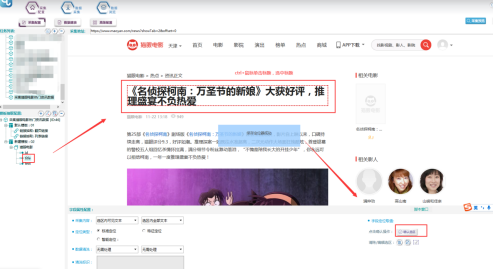
Text欄位如下所示:
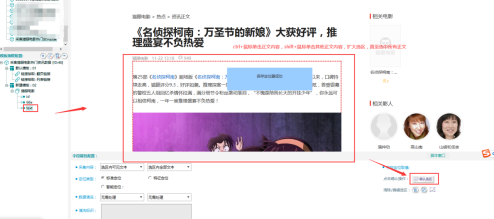
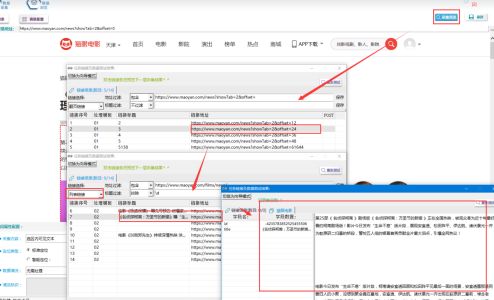
⑧採集預覽
採集預覽如下圖所示,說明配置成功,可以開始採集。如果有哪個欄位或者數據沒有出來,再次檢查之前配置,正確配置模板。
l 採集步驟
模板配置完成,採集預覽沒有問題後,可以進行數據採集。
①建立數據表單:
選擇【數據建表】,點擊【表單列表】中該模板的表單,在【關聯數據表】中選擇【創建】,表名稱自定義,這裡命名為【maoyan】(註意命名不能用數字和特殊符號),點擊【確定】。創建完成,勾選數據表,並點擊右上角保存按鈕。
②開始採集
選擇【數據採集】,勾選任務名稱,點擊【開始採集】,則正式開始採集。
③導出數據
採集結束後,可以在【數據瀏覽】中,選擇數據表查看採集數據,並可以導出數據。

④導出的文件打開如下圖所示:

本教程僅供教學使用,嚴禁用於商業用途!


