
GreatSQL社區原創內容未經授權不得隨意使用,轉載請聯繫小編並註明來源。 GreatSQL是MySQL的國產分支版本,使用上與MySQL一致。 作者: 如常 Debezium Incremental snapshotting Introduction CDC(Change-Data-Captur ...
- GreatSQL社區原創內容未經授權不得隨意使用,轉載請聯繫小編並註明來源。
- GreatSQL是MySQL的國產分支版本,使用上與MySQL一致。
- 作者: 如常
Debezium Incremental snapshotting
Introduction
CDC(Change-Data-Capture)正被廣泛應用於數據緩存、更新查詢索引、創建派生視圖、異構數據同步等場景,Debezium 作為 CDC 的代表項目之一,它收集資料庫中的事務日誌(變化事件)並以統一的事件流格式輸出(支持「Kafka Connect」及「內嵌到程式中」兩種應用形式)。
資料庫的事務日誌往往會進行定期清理,這就導致了僅使用事務日誌無法涵蓋所有的歷史數據信息,因此 Debezium 在進行事件流捕獲前通常會執行 consistent snapshot(一致性快照) 以獲取當前資料庫中的完整數據。預設情況下,事件流的捕獲會在 consistent snapshot 完成之後 開啟,不同數據量情況下,這個過程可能會耗費數小時乃至數天,並且一旦這個過程由於某些異常因素停止,那重新開啟後,它將從頭開始執行。
為瞭解決一致性快照的這些痛點問題,Debezium 提出了一個新的設計方案,併在 DDD-3 中詳細介紹了該方案的核心理論,借鑒了 DBLog 中的思想,使用一種基於 Watermark 的框架,實現了 Incremental snapshotting。
Incremental snapshotting 的優勢
- 在任何時間都可以觸發快照的動作,除了在捕獲事件流前進行一次完整的快照外,在下游數據備份、丟失、恢復的場景中,往往也需要進行快照操作;
- 快照可在執行過程中「掛起」和「恢復」,並且恢復執行後可定位到掛起前的位置,無需再從頭開始;
- 在執行快照時,不需要暫停事件流的捕獲,也就是說快照可以和事件捕獲同時執行,互不影響,保證了事件流的低延遲性;
- 無鎖,保證了在快照的同時資料庫依然能夠寫入。
下麵詳細介紹 DBLog 論文中的方案。
DBLog
- DBLog 使用基於 Watermark 的方法,它能在直接使用
select from對資料庫進行快照的同時捕獲資料庫的變化事件流,並使用相同的格式對select快照和事務日誌捕捉進行輸出。這意味著 DBLog 可選擇在任意時刻開始執行快照,而不僅限於事件日誌捕獲開始前。 - DBLog 同時支持快照的掛起和恢復,歸功於它將數據按 chunk 進行劃分,並且在外部系統(如 Zookeeper)中存儲最近一次執行完成的 chunk。
- DBLog 的輸出通常為 Kafka,支持將輸出結果落庫和使用 API 獲取。
- DBLog 支持高可用,使用主備的方式保證同一時間會有一個活躍的實例處於正常工作狀態,多個備用實例處於等待狀態,一但工作中的實例發生異常,備用實例將會激活,替代原實例工作。
DBLog 的架構如下圖所示:

下麵將詳細介紹 DBLog 的事務日誌捕獲和快照機制。
事務日誌捕獲( Transaction log capture)
事務日誌捕獲依賴於資料庫的支持,如 MySQL 和 PostgreSQL 都提供了 replication 協議,DBLog 將作為資料庫主節點的一個從節點,資料庫主節點在事務執行完成後會向 replication 從節點發送事務日誌(經由 TCP)。通常的事務日誌中包含 create、update 和 delete 類型的事件,DBLog 對這些事件進行處理,最終包裝為一種統一的格式輸出,輸出的結果將包含各 column 在事務發生時的狀態(事務發生前後的值),每個事件的包裝都會以一個 8-byte 且嚴格單調遞增的 LSN(Log Sequence Number)標識,該 LSN 表示該事件在事務日誌中的偏移量。上述處理後的輸出結果將會存儲在 DBLog 進程的記憶體中,由另外的輔助線程將這些結果搬運到最終的目的地(如 Kafka、DB 等)。
事務日誌中還包含了 schema 變化相關的事件,需要妥善處理,但不是本文討論的重點,這裡暫且忽略不提。
完整狀態捕獲(Full state capture)
事務日誌由於定期清理等原因,通常無法保存當前資料庫的所有歷史狀態,而在許多應用場景(如同步)中,都需要保證能完整重現源庫的所有數據,這就需要提供一種擴展的 Full state capture 機制。一種較為直觀的手段是對每個表建立相應的 copy 表,並將原表中的數據按批(Chunk)寫入到 copy 表中,這些寫入操作就會按照正確的順序產生一系列的事務日誌事件,在後續處理中就可以正確消費到這些事件(此時正常的事務事件可以同時生成)。這種方式的缺點在於需要消耗 IO 和磁碟空間,雖然可以使用諸如 MySQL bloackhole engine 規避,但實現方式依賴於資料庫提供商的特性,沒有泛用性。
DBLog 提供了一種更為通用且對源庫影響較小策略,它無需將所有的源表中的數據寫入到事務日誌中,而是採用分批處理的方式,以 Chunk 為單位將源表中的數據查詢出來(嚴格要求每次查詢都以主鍵排序),將這些數據處理成為 DBLog 中的事件結果,並添加到該過程中產生的正常事務事件結果之後。執行過程中需要在外部存儲(如 Zookerper)中存儲上一個已完成的 Chunk 的最後一行的主鍵值,這樣當這個過程被掛起後,就可以根據這個主鍵值恢復定位到最近一次執行成功的位置。
下圖為 Chunk 的示例,該表中的主鍵為 c1,且查詢時按 c1 進行排序,Chunk size 為 3。當執行 Chunk2 的查詢時,會從存儲中取出一個表示 Chunk1 最後一行數據的主鍵 4,而後執行的 Chunk2 查詢就會增加條件 c1 > 4。

由於在查詢 Chunk 過程中,正常的事務事件仍然同時在產生和執行,為了保證這個過程中不會發生「新數據」被「舊數據」覆蓋的情況,每個 Chunk 在與正常事件合併前需要進行特殊處理。核心演算法就是在正常的事務事件流中人為插入 Watermark 事件以標記 Chunk 的起止位置,Watermark 就是我們在源端庫中創建的一張特殊的表,它由唯一的名稱標識,保證不與現有的任何表名衝突,這個表中僅存儲 一行一列 的數據,該記錄中的數據為一個永不重覆的 UUID,這樣每當對這個記錄進行 update 時,就會在事務日誌中產生一條有 UUID 標識的事件,這個事件就稱為 watermark event。
下麵演算法就是整個 Full state capture 的核心步驟:
Algorithm: Watermark-based Chunk Selection
Input: table
(1) pause log event processing
lw := uuid(), hw := uuid()
(2) update watermark table set value = lw
(3) chunk := select next chunk from table
(4) update watermark table set value = hw
(5) resume log event processing
inwindow := false
// other steps of event processing loop
while true do
e := next event from changelog
if not inwindow then
if e is not watermark then
append e to outputbuffer
else if e is watermark with value lw then
inwindow := true
else
if e is not watermark then
(6) if chunk contains e.key then
remove e.key from chunk
append e to outputbuffer
else if e is watermark with value hw then
(7) for each row in chunk do
append row to outputbuffer
// other steps of event processing loop
...
該演算法流程會一直迴圈,直至表中的所有數據都被處理完成。
- 步驟 1 暫停當前的正常事件日誌捕獲並生成兩個 UUID:
lw、hw。註意這裡是暫停 DBLog 對事件的捕獲,而不是暫停源端資料庫的日誌寫入,這個暫停過程中仍然可以有很多的寫入事件發生,這個暫停的過程較為短暫,在步驟 5 中會恢復; - 步驟 2 和步驟 4 分別使用步驟 1 中生成
lw和hw去修改 Watermark 表中的記錄,這將會在事務日誌中記錄兩個 update 事件; - 步驟 3 查詢某一個 Chunk 中的所有記錄,並將查詢的結果 chunk 保存在記憶體中,這個操作被夾在兩個 watermark 的更新操作之間,後續的處理流程就可以以這兩個位置為依據標識出哪些事件是在這次 Chunk 查詢過程中發生的;
- 步驟 5 開始,恢復正常的事件日誌捕獲,並迴圈遍歷每個按順序捕獲到的事件,如果事件發生在
lw前,則直接添加到輸出結果的記憶體中; - 如果事件
e進入到了lw和hw的區間中,則會在步驟 3 中的結果 chunk 中剔除與e具有相同主鍵的記錄,lw和hw視窗內到達的事件表示在查詢 Chunk 過程中有更「新」的數據達到,因此剔除掉 chunk 結果中的「舊數據」,保證「新數據」能夠被最終結果應用; - 如果事件
e已經超過了hw,則直接將 chunk 結果中剩餘的所有記錄附加到輸出結果末尾。
下麵以一個具體的例子來演示一下演算法的過程:
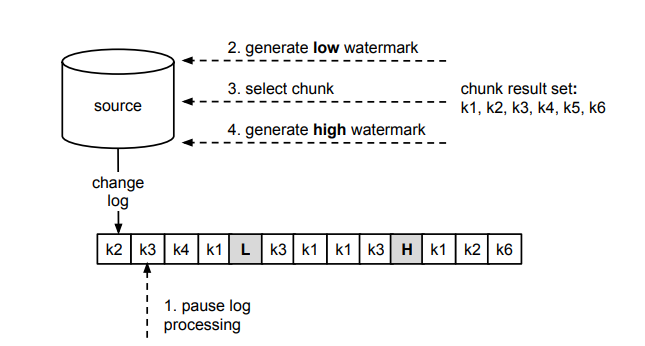
上圖中以 k1-k6 表示一張表中的主鍵值,change log 中的每個事務日誌事件也以主鍵標識為對該行數據的修改,步驟 1-4 與演算法中的步驟編號相對應。圖中表示了某次 Chunk 的查詢過程,暫停事件日誌捕獲後,先後執行了步驟 2-4,在記憶體中產生了一個 chunk 結果,併在源資料庫的事務日誌中記錄了兩條 watermark。
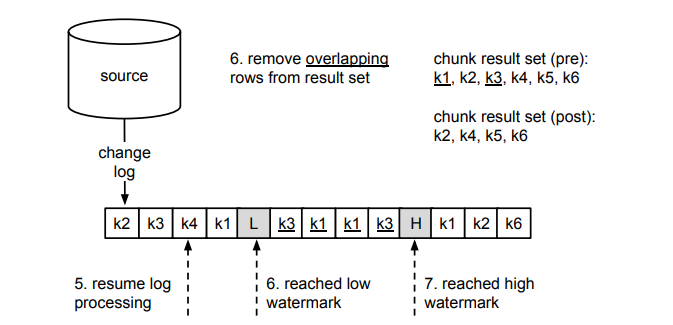
上圖中是步驟 5-7 的過程,我們以主鍵作為依據,從 chunk 結果中剔除了 L 和 H 視窗中修改數據事件對應的相關記錄。

最終,將剩餘的 chunk 結果附加到 H 之後,就完成了一個 Chunk 的選擇過程。
總結
本文詳細介紹了 Debezium 的 Incremental snapshot 的實現基礎——DBLog,它在原有的 CDC 基礎上使用一種基於 Watermark 的框架,擴展了 Full state capture 的功能,能夠在事務日誌事件捕獲開啟的同時執行快照,支持掛起和恢復操作,且用戶能在任何時間點開啟該快照操作。
Enjoy GreatSQL

