
同步與非同步 用來表達任務的提交方式 同步: 提交完任務之後原地等待任務的返回結果 期間不做任何事 非同步: 提交完任務之後不願地等待任務的返回結果 直接去做其他事 有結果自動通知 阻塞與非阻塞 用來表達任務的執行狀態 阻塞 程式處於阻塞態 非阻塞 程式處於就緒態、運行態 綜合使用 同步阻塞 提交任務之 ...
目錄
同步與非同步
用來表達任務的提交方式
同步:
提交完任務之後原地等待任務的返回結果 期間不做任何事
非同步:
提交完任務之後不願地等待任務的返回結果 直接去做其他事 有結果自動通知
阻塞與非阻塞
用來表達任務的執行狀態
阻塞
程式處於阻塞態
非阻塞
程式處於就緒態、運行態
綜合使用
- 同步阻塞
提交任務之後 cpu走了 進程不執行了 - 同步非阻塞
在原地做一些事情 - 非同步阻塞
cpu沒來做不了事情 - 非同步非阻塞(效率最高)
提交完任務之後 進程還繼續 cpu也還在
非同步非阻塞框架(寫游戲、響應速度、效率高)
創建進程的多種方式
前言
# 1.創建進程的步驟
如何創建進程?用滑鼠雙擊一個桌面圖標,就創建了一個應用程式的進程。
而我們可以用python代碼創建進程,這其中至少有這樣的過程:
1.硬碟中存放python代碼
2.讀取代碼到記憶體
3.cpu執行代碼
4.操作系統創建新進程
# 2.不同操作系統的差異(重要)
因為進程是由操作系統創建的,所以根據不同操作系統也會有差異:
"""
在不同的操作系統中創建進程底層原理不一樣
windows
以導入模塊的形式創建進程(需要使用if __name__ == 'main')
linux/mac
以拷貝代碼的形式創建進程 (複製的時候不包含創建進程的代碼)
"""
# 3.父進程和子進程
比如一個瀏覽器,可能會有很多分頁。那相對的來說瀏覽器就是主進程,一個頁面就是一個子進程。
一個py文件,裡面寫了創建進程的代碼。那這個py文件運行之後,首先他自己是一個進程(父進程),被他創建出來的進程是他的子進程。
父進程和子進程是相對的概念,比如剛剛所說的py文件,又是pycharm的子進程。
windows系統創建進程的問題(重要)
在windows系統下使用Python模塊multiprocessing模塊創建進程:
from multiprocessing import Process
import time
def task():
print('子進程開始執行')
time.sleep(3)
print('子進程執行結束')
p = Process(target=task) # 使用Process模塊創建一個子進程 在子進程運行task函數
p.start() # 運行子進程
print('主進程運行結束')
# 執行後會產生如下報錯信息:
'''
RuntimeError:
An attempt has been made to start a new process before the
current process has finished its bootstrapping phase.
This probably means that you are not using fork to start your
child processes and you have forgotten to use the proper idiom
in the main module:
if __name__ == '__main__':
freeze_support()
...
The "freeze_support()" line can be omitted if the program
is not going to be frozen to produce an executable.
Process finished with exit code 0
'''
為什麼會產生這樣的報錯呢?
windows以導入模塊的形式創建進程。
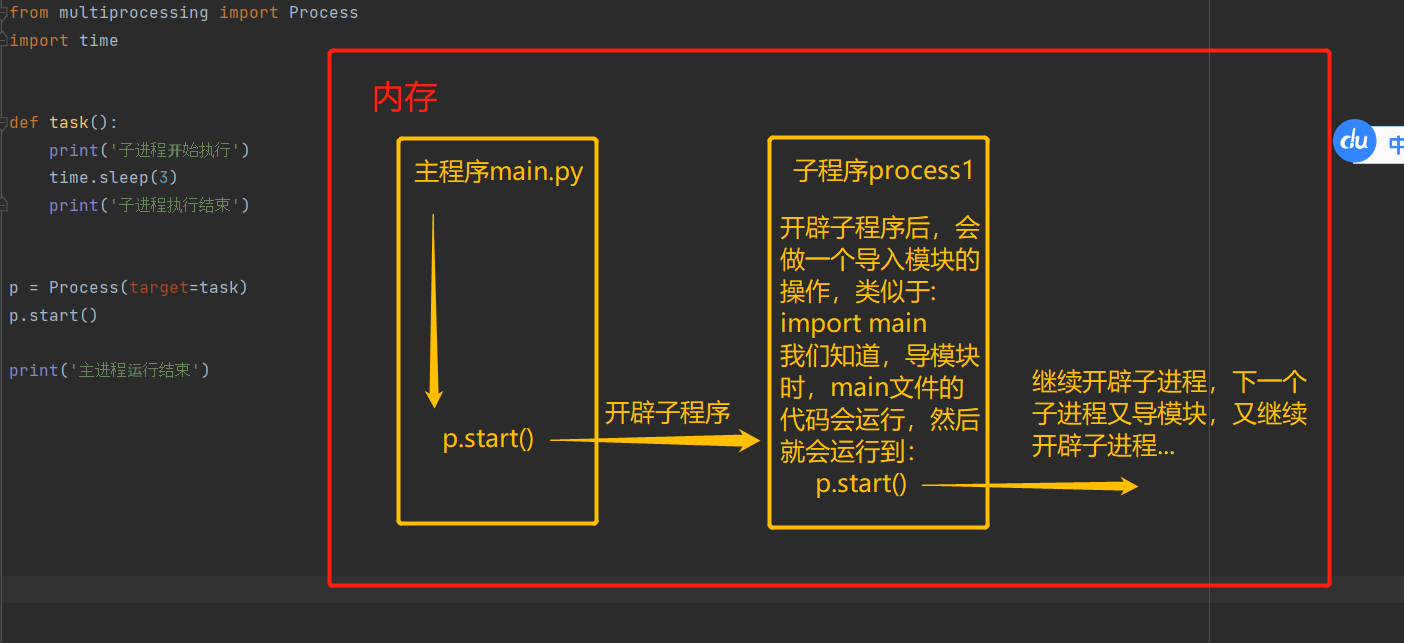
所以產生報錯的就是如下兩行代碼:
解決:
from multiprocessing import Process
import time
def task():
print('子進程開始執行')
time.sleep(3)
print('子進程執行結束')
if __name__ == '__main__':
p = Process(target=task)
p.start()
'''
將這兩行代碼放入if __name__ == 'main':
使主進程作為模塊導入的時候,不再執行這兩行代碼,就不會出現問題了。
'''
multiprocessing模塊之Process
展現非同步
展現非同步之前,先舉一個同步的例子:
import time
def task():
print('子進程開始執行')
time.sleep(3)
print('子進程執行結束')
if __name__ == '__main__':
task() # 程式會跳回去執行task函數,task沒執行完就不會執行下麵的print()
print('主進程運行結束')
'''輸出結果:
子進程開始執行
子進程執行結束
主進程運行結束
'''
展現非同步:
def task():
print('子進程開始執行')
time.sleep(3)
print('子進程執行結束')
if __name__ == '__main__':
p = Process(target=task)
p.start()
print('主進程運行結束') # 這行代碼執行最快 主進程真的結束了嗎? =。=
'''輸出結果:
主進程運行結束
子進程開始執行
子進程執行結束
'''
為什麼是這樣的輸出結果?
p.start()執行完後,相當於向操作系統發送了一個信息,要創建一個子進程。操作系統要處理信息是需要一定時間的。主進程只是發了一個信息就完了,代碼繼續往下走,自然會執行print。等操作系統反應過來了,子進程才會開始執行,而這個速度是慢於主進程代碼執行速度的。也就是說: 操作系統開闢記憶體空間的時候 主進程不停著,直接運行下一行。
請解釋輸出結果:
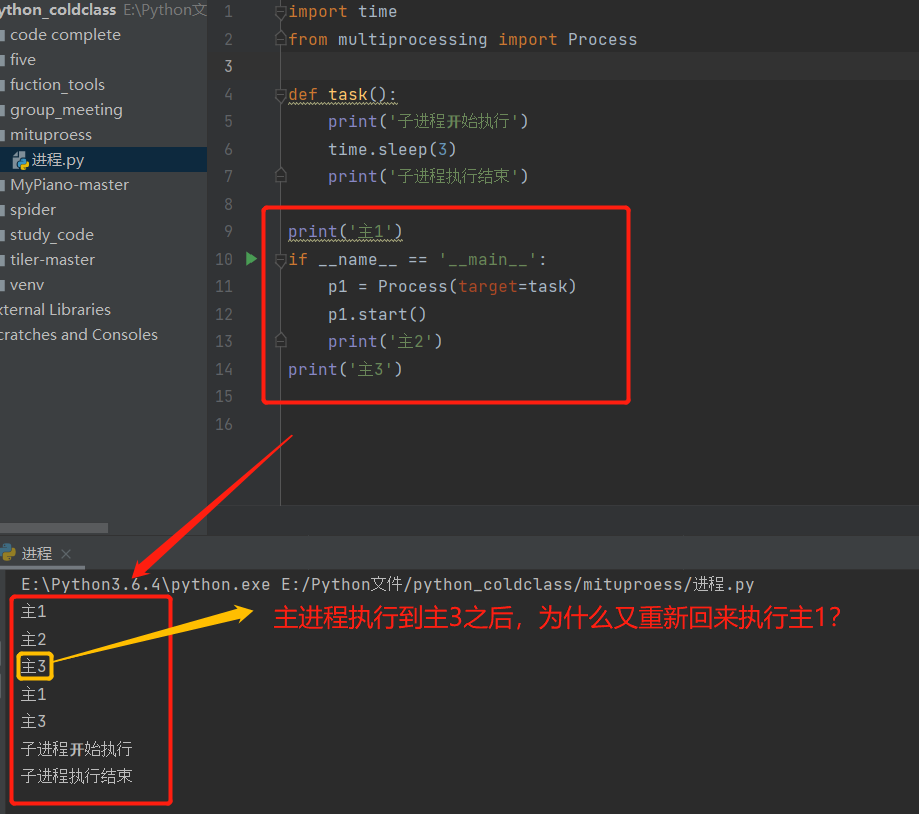
請解釋輸出結果:
創建進程的方式(一):使用Process()創建進程對象
基本使用
import time
from multiprocessing import Process
def task():
print('子進程開始執行')
time.sleep(3)
print('子進程執行結束')
if __name__ == '__main__':
p = Process(target=task)
print(p, type(p)) # <Process(Process-1, initial)> <class 'multiprocessing.context.Process'>
p.start()
# 用Process創建一個子進程對象 然後調用子進程對象的start()方法運行子進程。
查看Process源碼發現他繼承BaseProcess類:

BaseProcess類:看紅色框就好。

給子進程運行的函數傳參
import time
from multiprocessing import Process
def task1(a,b):
time.sleep(3)
print(a,b)
def task2(a,b):
time.sleep(3)
print(a,b)
if __name__ == '__main__':
p1 = Process(target=task1, args=('cloud','alice')) # 位置參數
p2 = Process(target=task2, kwargs={'a':'cloud','b':'alice'}) # 關鍵字參數
p1.start()
p2.start()
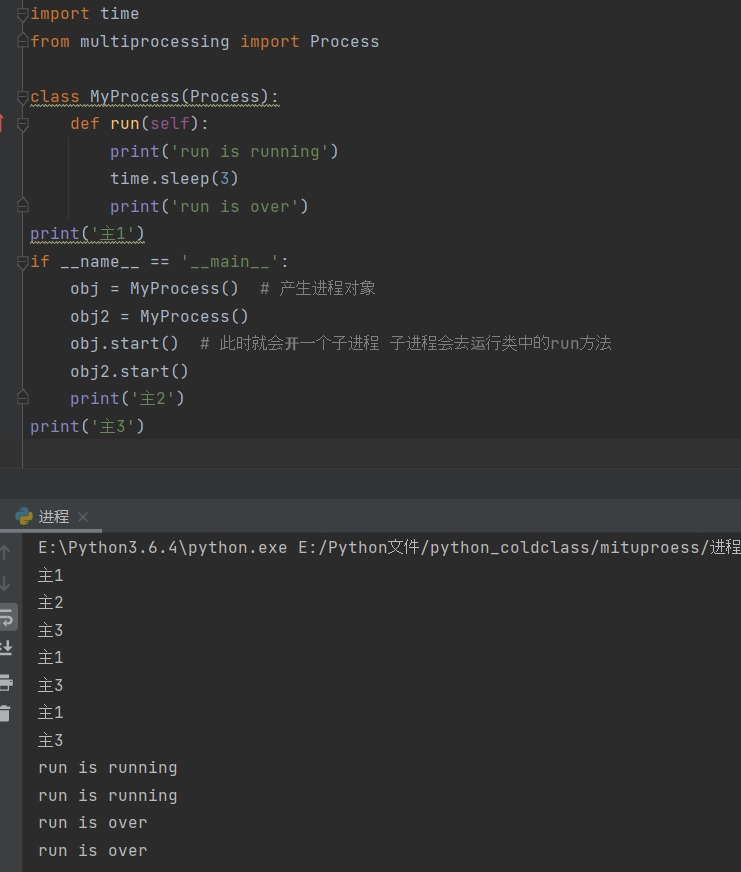
創建進程的方式(二):重寫Process類的run方法
import time
from multiprocessing import Process
class MyProcess(Process):
def run(self):
print('run is running')
time.sleep(3)
print('run is over')
if __name__ == '__main__':
obj = MyProcess() # 產生進程對象
obj.start() # 此時就會開一個子進程 子進程會去運行類中的run方法
print('主')
為什麼可以這麼做呢?我們知道Process繼承BaseProcess類。於是我們去看BaseProcess類的run方法:
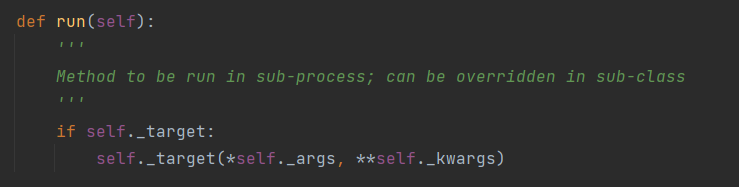
可以得知這個run方法就是留給我們重寫的。
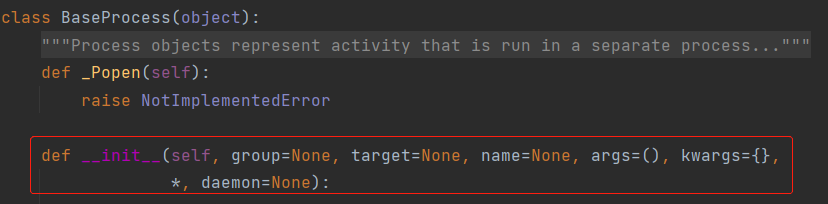
還是如何傳參
需要重寫BaseProcess類的雙下init:
from multiprocessing import Process
import time
class MyProcess(Process):
def __init__(self, name, age): # 重寫__init__方法
super().__init__() # 這裡init不傳參是因為 父類init裡面的形參全是預設參數
self.name = name # 這裡的self是進程對象
self.age = age # 給新產生的進程對象新增兩個對象獨有的屬性name、age
# 備忘:__new__產生新對象
def run(self):
print('run is running', self.name, self.age) # 使用對象中的屬性
time.sleep(3)
print('run is over', self.name, self.age)
if __name__ == '__main__':
obj = MyProcess('cloud', 18)
obj.start()
print('主')
join方法
join方法的作用是:讓主進程代碼等待子進程代碼結束之後,再執行。
主進程會卡在join方法處,主進程join方法下麵的代碼,不會執行。直到子進程運行結束。
# 1.基本使用
import time
from multiprocessing import Process
def task():
print('子進程開始執行')
time.sleep(3)
print('子進程執行結束')
if __name__ == '__main__':
p = Process(target=task)
p.start()
p.join()
print('主')
'''輸出結果:
子進程開始執行
子進程執行結束
主
'''
使用join方法會讓主程式等待子進程結束。不加join時,應該是'主'最先被輸出。
# 2.非阻塞例子
from multiprocessing import Process
import time
def task(name, n):
print('%s is running' % name)
time.sleep(n)
print('%s is over' % name)
if __name__ == '__main__':
p1 = Process(target=task, args=('jason1', 1)) # 子進程p1 執行時間為1s
p2 = Process(target=task, args=('jason2', 2)) # 子進程p2 執行時間為2s
p3 = Process(target=task, args=('jason3', 3)) # 子進程p3 執行時間為3s
start_time = time.time()
p1.start()
p2.start()
p3.start()
p1.join()
p2.join()
p3.join()
print(time.time() - start_time) # 請問運行時間是?
'''
jason1 is running
jason2 is running
jason3 is running
jason1 is over
jason2 is over
jason3 is over
3.2216908931732178
'''
# 3.阻塞例子
from multiprocessing import Process
import time
def task(name, n):
print('%s is running' % name)
time.sleep(n)
print('%s is over' % name)
if __name__ == '__main__':
p1 = Process(target=task, args=('jason1', 1)) # 子進程p1 執行時間為1s
p2 = Process(target=task, args=('jason2', 2)) # 子進程p2 執行時間為2s
p3 = Process(target=task, args=('jason3', 3)) # 子進程p3 執行時間為3s
start_time = time.time()
p1.start()
p1.join()
p2.start()
p2.join()
p3.start()
p3.join()
print(time.time() - start_time) # 請問運行時間是?
'''
jason1 is running
jason1 is over
jason2 is running
jason2 is over
jason3 is running
jason3 is over
6.449279308319092
'''
# 4.誰的速度快?
import time
from multiprocessing import Process
def task(name):
start_time = time.time()
print(f'{name}子進程開始執行')
time.sleep(3)
print(f'{name}子進程執行結束')
print(f'{name}進程耗時:{time.time()-start_time}')
if __name__ == '__main__':
p1 = Process(target=task,args = ('p1',))
p2 = Process(target=task,args = ('p2',))
p1.start()
p2.start()
p1.join()
print('主') # 這段print代碼有時可以跑的比第二個子進程還快!
# 5.無法阻擋子進程
import time
from multiprocessing import Process
def task(name):
start_time = time.time()
print(f'{name}子進程開始執行')
time.sleep(3)
print(f'{name}子進程執行結束')
print(f'{name}進程耗時:{time.time()-start_time}')
def task2(name):
start_time = time.time()
print(f'{name}子進程開始執行')
time.sleep(1)
print(f'{name}子進程執行結束')
print(f'{name}進程耗時:{time.time()-start_time}')
if __name__ == '__main__':
p1 = Process(target=task,args = ('p1',))
p2 = Process(target=task2,args = ('p2',))
p1.start()
p2.start()
p1.join() # join只能卡住主進程的代碼運行 不能阻擋子進程
print('主')
'''
p1子進程開始執行
p2子進程開始執行
p2子進程執行結束
p2進程耗時:1.0048680305480957
p1子進程執行結束
p1進程耗時:3.0130884647369385
主
'''
進程間的數據隔離
同一臺電腦上的多個進程數據是嚴格意義上的物理隔離(預設情況下)
from multiprocessing import Process
import time
money = 1000
def task():
global money
money = 666
print('子進程的task函數查看money', money)
if __name__ == '__main__':
p1 = Process(target=task)
p1.start() # 創建子進程
time.sleep(3) # 主進程代碼等待3秒
print(money) # 主進程代碼列印money
IPC機制 消息隊列
IPC的概念:實現進程間通信
消息隊列:消息隊列可以理解成一個公共存數據的地方 所有進程都可以存 也可以取。
multiprocessing模塊之Queue
from multiprocessing import Queue
# 1.產生消息隊列q
q = Queue(3) # 括弧內可以指定存儲數據的個數
不給Queue傳值的情況下,會自動使用最大值:(SEM_VALUE_MAX)
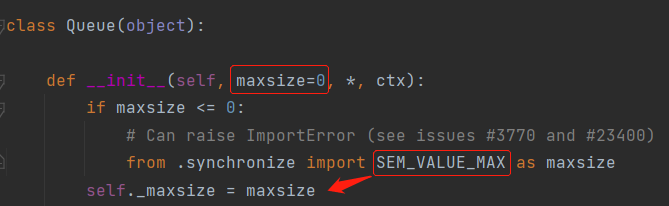
此時隊列可以容納值的數量為:
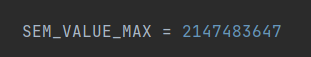
get() put()
使用get從隊列中獲取值 使用put往隊列添加值 符合先進先出
from multiprocessing import Queue
q = Queue(3)
q.put(111)
q.put(222)
q.put(333)
print(q.get()) # 111
print(q.get()) # 222
print(q.get()) # 333
當隊列已滿時,你使用put添加值
或者隊列已空,你使用get獲取值
都會導致當前進程阻塞,等待有別的進程往隊列里添加/獲取值
from multiprocessing import Queue
q = Queue(3)
q.put(111)
q.put(222)
q.put(333)
q.put(444)
print('阻塞') # 無法輸出這行代碼
full() empty()
full 用於判斷隊列是否為滿。
但有些需要註意:
1.判斷的是當前進程的隊列
2.判斷的是執行full()這行代碼這個瞬時時間下,隊列的狀態是否為滿
empty 與 full 相反 判斷的是隊列是否為空
from multiprocessing import Queue
q = Queue(3)
q.put(111)
print(q.full()) # 判斷隊列是否已滿 False
q.put(222)
q.put(333)
print(q.full()) # 判斷隊列是否已滿 True
print(q.get())
print(q.get())
print(q.empty()) # 判斷隊列是否為空 False
print(q.get())
print(q.empty()) # 判斷隊列是否為空 True
註意:
full() empty() 在多進程中都不能使用!!!
可能當前進程你執行完q.empty 之後 馬上又另外的進程塞一個數據進來 q.empty只能判斷當前進程一個瞬時時間管道是否空。
get_nowait()
這個方法如他的名字,如果獲取不到隊列的值,就馬上拋出異常。
from multiprocessing import Queue
q = Queue(3)
q.put(111)
print(q.get())
print(q.get_nowait()) # queue.Empty
消息隊列實現子進程消息傳遞
from multiprocessing import Process, Queue
def product(q):
q.put('子進程p添加的數據')
def consumer(q):
print('子進程獲取隊列中的數據', q.get())
if __name__ == '__main__':
q = Queue()
# 主進程往隊列中添加數據
# q.put('我是主進程添加的數據')
p1 = Process(target=consumer, args=(q,))
p2 = Process(target=product, args=(q,))
p1.start()
p2.start()
print('主')
'''
consumer進程在消息隊列沒有數據的時候 這個進程會等待product進程往Queue放東西
'''
消費者模型
"""回想爬蟲"""
生產者
負責產生數據的'人'
消費者
負責處理數據的'人'
該模型除了有生產者和消費者之外還必須有消息隊列
(只要是能夠提供數據保存服務和提取服務的理論上都可以)
生產者消費者模型可以實現程式結耦合。兩個程式(生產者、消費者)基於消息隊列都可以獨立運行。
用包子鋪舉例:
老闆提前做好包子放在蒸籠(消息隊列)。
沒有客人的時候可以一直做包子。客人也不需要等待,隨時可以來拿包子。(程式結耦合)
進程對象多種方法
如何查看進程號
# 1.current_process查看
from multiprocessing import Process, current_process
def task():
print('子進程')
print(current_process()) # 查看進程
print(current_process().pid) # 查看進程號
if __name__ == '__main__':
p = Process(target=task)
p.start()
print('主進程:')
print(current_process())
print(current_process().pid)
'''
主進程:
<_MainProcess(MainProcess, started)>
504
子進程
<Process(Process-1, started)>
23260
'''
# 2.os模塊
import os
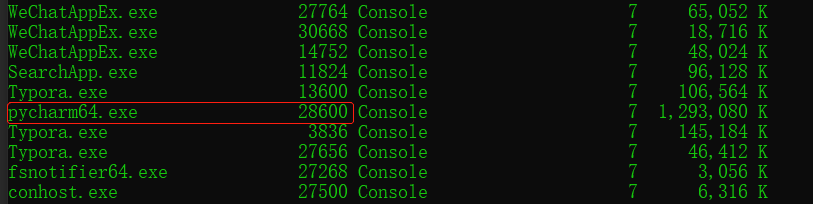
print(os.getpid()) # 獲取當前進程的進程號 # 17672
print(os.getppid()) # 獲取當前進程的父進程的進程號 # 28600 # 我用的是pycharm應該獲取的是pycharm的進程號
去cmd里輸入tasklist查看,果然如此:
multiprocessing模塊之Process其他方法
1.終止進程
p1.terminate()
ps:電腦操作系統都有對應的命令可以直接殺死進程
windows:taskkill /F /PID 進程號
2.判斷進程是否存活
p1.is_alive()
3.start()
4.join()
# 例子
import time
from multiprocessing import Process
def task():
print('子進程開始執行')
time.sleep(3)
print('子進程執行結束')
if __name__ == '__main__':
p = Process(target=task)
p.start()
p.terminate()
print(p.is_alive()) # True # 不是已經終止進程了嗎?為什麼還是True
# 1.前腳剛開 後腳就關了 這時候進程都起不來 如果加中間sleep可能就子進程運行完了
# 2.執行terminate相當於讓操作系統關掉剛剛創建的子進程,而這是需要時間的。可能執行is_alive的速度比操作系統關進程的速度快,所以結果是True
守護進程
守護進程會隨著守護的進程結束而立刻結束
使用場景:
一鍵關閉所有子進程
eg: 吳勇是張紅的守護進程 一旦張紅嗝屁了 吳勇立刻嗝屁
from multiprocessing import Process
import time
def task(name):
print('德邦總管:%s' % name)
time.sleep(3)
print('德邦總管:%s' % name)
if __name__ == '__main__':
p1 = Process(target=task, args=('大張紅',))
p1.daemon = True
p1.start()
time.sleep(1)
print('恕瑞瑪皇帝:小吳勇嗝屁了')
僵屍進程
僵屍進程
進程執行完畢後並不會立刻銷毀所有的數據 會有一些信息短暫保留下來
比如進程號、進程執行時間、進程消耗功率等給父進程查看
ps:所有的進程都會變成僵屍進程
孤兒進程
孤兒進程
子進程正常運行 父進程意外死亡 操作系統針對孤兒進程會派遣福利院管理
多進程數據錯亂問題
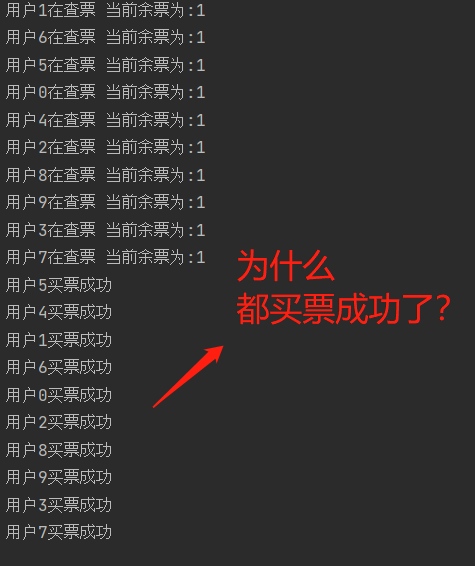
火車票搶票時經常出現這種問題:
本來有3張票 點進去之後一張票都沒有
是因為:你看到的這三張票基於 進入app的時間
你需要刷新 才能獲取當前時間的信息
模擬搶票軟體
from multiprocessing import Process
import time
import json
import random
# 查票
def search(name):
with open(r'data.json', 'r', encoding='utf8') as f:
data = json.load(f)
print('%s在查票 當前餘票為:%s' % (name, data.get('ticket_num')))
# 買票
def buy(name):
# 再次確認票
with open(r'data.json', 'r', encoding='utf8') as f:
data = json.load(f)
# 模擬網路延遲
time.sleep(random.randint(1, 3))
# 判斷是否有票 有就買
if data.get('ticket_num') > 0:
data['ticket_num'] -= 1
with open(r'data.json', 'w', encoding='utf8') as f:
json.dump(data, f)
print('%s買票成功' % name)
else:
print('%s很倒霉 沒有搶到票' % name)
def run(name):
search(name)
buy(name)
if __name__ == '__main__':
tick_dict = {'ticket_num': 1} # 創建車票字典 裡面就只有一張票
with open('data.json', 'w', encoding='utf8') as f:
json.dump(tick_dict, f)
for i in range(10):
p = Process(target=run, args=('用戶%s'%i, ))
p.start()
"""
多進程操作數據很可能會造成數據錯亂>>>:互斥鎖
互斥鎖
將併發變成串列 犧牲了效率但是保障了數據的安全
也就是讓進程排隊
"""
輸出結果:
練習
1.將TCP服務端使用多進程實現併發效果
聊天全部採用自動發送 不要用input手動輸
2.整理今日內容及博客
3.查詢IT行業可能出現的鎖名稱及概念
4.整理理論內容 嘗試編寫cs架構的軟體 實現數據的上傳與下載

