
看《C++ Primer Plus》時整理的學習筆記,部分內容完全摘抄自《C++ Primer Plus》(第6版)中文版,Stephen Prata 著,張海龍 袁國忠譯,人民郵電出版社。只做學習記錄用途。 ...
看《C++ Primer Plus》時整理的學習筆記,部分內容完全摘抄自《C++ Primer Plus》(第6版)中文版,Stephen Prata 著,張海龍 袁國忠譯,人民郵電出版社。只做學習記錄用途。
目錄本章介紹 C++ 的記憶體模型和名稱空間,包括數據的存儲持續性、作用域和鏈接性,以及定位 new 運算符。
9.1 單獨編譯
C++ 鼓勵程式員將組件函數放在獨立的文件中,可以單獨編譯這些文件,然後將它們鏈接成可執行的程式。(通常,C++ 編譯器既編譯程式,也管理鏈接器。)如果只修改了一個文件,則可以只重新編譯該文件,然後將它與其他文件的編譯版本鏈接,大多數集成開發環境(如 Microsoft Visual C++ 和 Apple Xcode)都提供了這一功能,減少了人為管理的工作量。
9.1.1 程式組織策略
以下是一種非常有效且常用的程式組織策略,它將整個程式分為三個部分:
- 頭文件:包含結構聲明和使用這些結構的函數的原型。
- 源代碼文件:包含定義與結構有關的函數的代碼。
- 源代碼文件:包含調用與結構有關的函數的代碼。
在編譯時,C++ 預處理器會將源代碼文件中的 #include 指令替換成頭文件的內容。源代碼文件和它所包含的所有頭文件被編譯器看成一個包含以上所有信息的單獨文件,該文件被稱為翻譯單元(translation unit)。描述一個具有文件作用域的變數時,它的實際可見範圍是整個翻譯單元。如果程式由多個源代碼文件組成,那麼該程式也將由多個翻譯單元組成。每個翻譯單元均對應一個源代碼文件和它所包含的頭文件。下圖簡要地說明瞭在 UNIX 系統中,將含 1 個頭文件 coordin.h 與 2 個源代碼文件 file1.cpp、file2.cpp 的程式編譯成一個 out 可執行程式的過程。
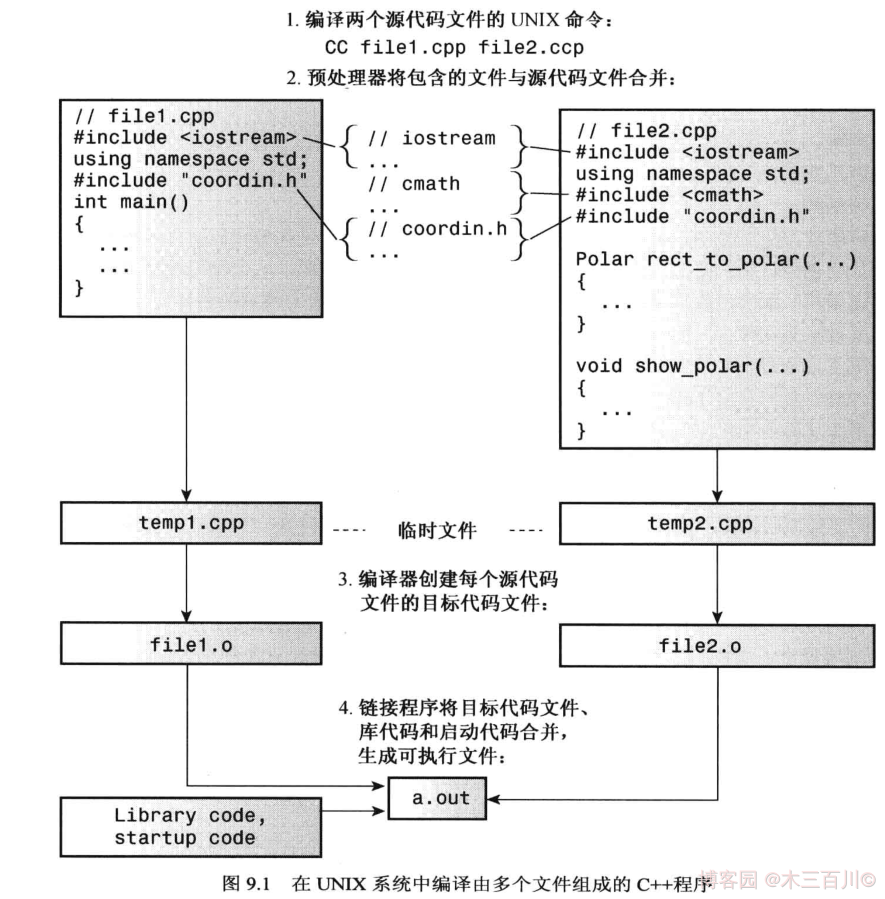
由於不同 C++ 編譯器對函數的名稱修飾方式不同,因此由不同編譯器創建的二進位模塊(對象代碼文件,如上圖中的 file1.o、file2.o)很可能無法正確地鏈接,因為兩個編譯器將為同一個函數生成不同的名稱修飾。這時,可使用同一個編譯器重新編譯所有源代碼文件,來消除鏈接錯誤。
9.1.2 頭文件
在同一個文件中只能將同一個頭文件包含一次,否則可能會出現重覆定義的問題。一般在頭文件中使用預處理器編譯指令 #ifndef(即 if not defined)來避免多次包含同一個頭文件。編譯器首次遇到該文件時,名稱 COORDIN_H_ 沒有定義(加上下劃線以獲得一個在其他地方不太可能被定義的名稱),這時編譯器將查看 #ifndef 和 #endif 之間的內容,並通過 #define 定義名稱 COORDIN_H_。如果在同一個文件中遇到其他包含 coordin.h 的代碼,編譯器將知道 COORDIN_H_ 已經被定義了,從而跳到 #endif 後面的一行。但這種方法並不能防止編譯器將文件包含兩次,而只是讓它忽略除第一次包含之外的所有內容。
#ifndef COORDIN_H_
#define COORDIN_H_
//頭文件內容
...
#endif
在頭文件中,可以包含以下內容:
- 使用
#define或const定義的符號常量。 - 結構聲明,它們並不創建變數,只是告訴編譯器當需要創建它們時應該如何創建。
- 類聲明,同結構聲明一樣,它們並不創建類,只是告訴編譯器當需要創建它們時應該如何創建。
- 模板定義,它們不是將被編譯的代碼,只是被用來指示編譯器如何生成與源代碼中的函數調用相匹配的函數定義。
- 常規函數原型。
- 內聯函數定義。
不要將常規函數定義(非函數模板、非內聯函數)或常規變數聲明(非 const 變數、非 static 變數)放到頭文件中,否則當同一個程式的兩個源文件都包含該頭文件時,可能會出現重覆定義的問題。
9.1.3 源代碼文件
在源代碼文件開頭處,通常會使用 #include 預編譯指令包含所需的頭文件,有以下兩種包含方式:
- 使用尖括弧
<>包含,例如#include <iostream>,如果文件名包含在尖括弧中,則 C++ 編譯器將在存儲標準頭文件的主機系統的文件系統中查找,一般用來包含系統自帶的頭文件或標準頭文件。 - 使用雙引號
""包含,例如#include "coordin.h",如果文件名包含在雙引號中,則編譯器將首先查找當前的工作目錄或源代碼目錄(或其它目錄,這取決於編譯器以及用戶設置),如果沒有在那裡找到頭文件,則將在標準位置查找,一般用來包含用戶自定義的頭文件。
不要在源代碼文件中包含其它源代碼文件,這可能出現重覆定義的問題。在源代碼文件中,一般包含頭文件中常規函數原型所對應的函數定義(聲明與定義相分離的策略,聲明位於頭文件中,定義位於源代碼文件中)、類聲明中成員函數的定義、全局變數聲明等。
9.2 存儲持續性、作用域和鏈接性
不同的 C++ 存儲方式是通過存儲持續性、作用域和鏈接性來描述的,下表總結了引入名稱空間之前使用的存儲特性。
| 存儲描述 | 持續性 | 作用域 | 鏈接性 | 聲明方式 |
|---|---|---|---|---|
| 常規自動變數 | 自動存儲持續性 | 代碼塊 | 無 | 在代碼塊中 |
| 寄存器自動變數 | 自動存儲持續性 | 代碼塊 | 無 | 在代碼塊中,使用關鍵字 register |
| 外部鏈接性的靜態變數 | 靜態存儲持續性 | 翻譯單元 | 外部 | 不在任何函數內,分為定義聲明和引用聲明 |
| 內部鏈接性的靜態變數 | 靜態存儲持續性 | 翻譯單元 | 內部 | 不在任何函數內,使用關鍵字 static |
| 無鏈接性的靜態變數 | 靜態存儲持續性 | 代碼塊 | 無 | 在代碼塊中,使用關鍵字 static |
下麵對這些存儲特性進行逐一介紹。
9.2.1 存儲持續性種類
C++ 使用三種(C++11 中是四種)不同的方案來存儲數據,這些方案的區別就在於數據保留在記憶體中的時間,即存儲持續性。
- 自動存儲持續性:在函數定義中聲明的變數(包括函數參數)的存儲持續性為自動的。它們在程式開始執行其所屬的函數或代碼塊時被創建,在執行完函數或代碼塊時,它們使用的記憶體被釋放。
- 靜態存儲持續性:在函數定義外部定義的變數和使用關鍵字
static定義的變數的存儲持續性都為靜態。它們在程式整個運行過程中都存在。 - 動態存儲持續性:用
new運算符分配的記憶體將一直存在,直到使用delete運算符將其釋放或程式結束為止。這種記憶體的存儲持續性為動態,有時被稱為自由存儲(free store)或堆(heap)。 - 線程存儲持續性(C++11):當前,多核處理器很常見,這些 CPU 可同時處理多個執行任務。這讓程式能夠將計算放在可並行處理的不同線程中。如果變數是使用關鍵字
thread_local聲明的,則其生命周期與所屬的線程一樣長。
9.2.2 作用域種類
作用域(scope)描述了名稱在文件(翻譯單元)的多大範圍內可見。C++ 變數的作用域有多種:
- 局部作用域:作用域為局部的變數只能在聲明它的代碼塊(由一對花括弧括起來的多條語句)中使用,不能在其它地方使用。所有自動變數的作用域都是局部的,靜態變數的作用域是全局還是局部取決於它是如何被聲明的。例如:函數體內聲明的常規變數、函數形參、無鏈接性的靜態變數。
- 全局作用域:作用域為全局的變數在其聲明位置到文件結尾之間都可以用,全局作用域也稱為文件作用域。例如在文件中函數定義之前定義的變數(外部鏈接性的靜態變數、內部鏈接性的靜態變數)。
- 函數原型作用域:在函數原型作用域中使用的名稱只在包含參數列表的括弧內可用。C++11 中可在原型括弧後面使用
decltype關鍵字推斷返回類型,但這實際上並沒有使用參數的值,只用它們來做了類型推斷。 - 類作用域:在類中聲明的成員的作用域為整個類,它們又有三種不同的屬性:公有、私有和繼承,這將在後續章節介紹。
- 名稱空間作用域:在名稱空間中聲明的變數的作用域為整個名稱空間,全局作用域是名稱空間作用域的特例。
C++ 函數的作用域可以是類作用域或名稱空間作用域(包括全局作用域),但不能是局部作用域。
9.2.3 鏈接性種類
鏈接性(linkage)描述了名稱如何在不同單元間共用。有以下三種鏈接性:
- 外部鏈接性:鏈接性為外部的名稱可在文件間共用。
- 內部鏈接性:鏈接性為內部的名稱只能由一個文件中的函數共用。
- 無鏈接性:自動變數的名稱沒有鏈接性,因為它們不能共用。
9.2.4 自動存儲持續性變數
自動變數的初始化:在預設情況下,在函數或代碼塊中聲明的函數參數和變數的存儲持續性為自動,作用域為局部,沒有鏈接性,只有在定義它們的函數中才能使用它們,當函數結束時,這些變數都將消失。可以使用任何在聲明時其值為已知的表達式來初始化自動變數,若在聲明時未進行初始化,則其值是未知的。
int w; //未被初始化,其值未知
int x = 5; //被數字字面常量初始化
int y = 2*x; //被可計算值的表達式初始化
int z = INT_MAX - 1; //被常量表達式初始化
自動變數的記憶體管理:自動變數的數目隨函數的開始和結束而增減,程式常用的方法是留出一段記憶體,並將其視為棧,以管理變數的增減。
- 棧的預設長度取決於實現,但編譯器通常提供改變棧長度的選項,Microsoft Visual Studio 預設大小為 1 MB。
- 棧的虛擬記憶體是連續的,但物理記憶體不一定連續,程式使用兩個指針來跟蹤棧,一個指針指向棧底(棧的開始位置),另一個指針指向棧頂(棧的下一個可用記憶體單元)。
- 當函數被調用時,其中的自動變數將被加入到棧中,棧頂指針指向變數後面的下一個可用的記憶體單元。當函數結束時,棧頂指針被重置為函數被調用前的值,從而釋放新變數使用的記憶體。
- 棧是 LIFO 的(後進先出),即最後加入到棧中的變數首先被彈出。這種設計簡化了參數傳遞,函數調用時將其參數的值放在棧頂,然後重新設置棧頂指針,被調用的函數根據其形參描述來確定每個參數的地址。
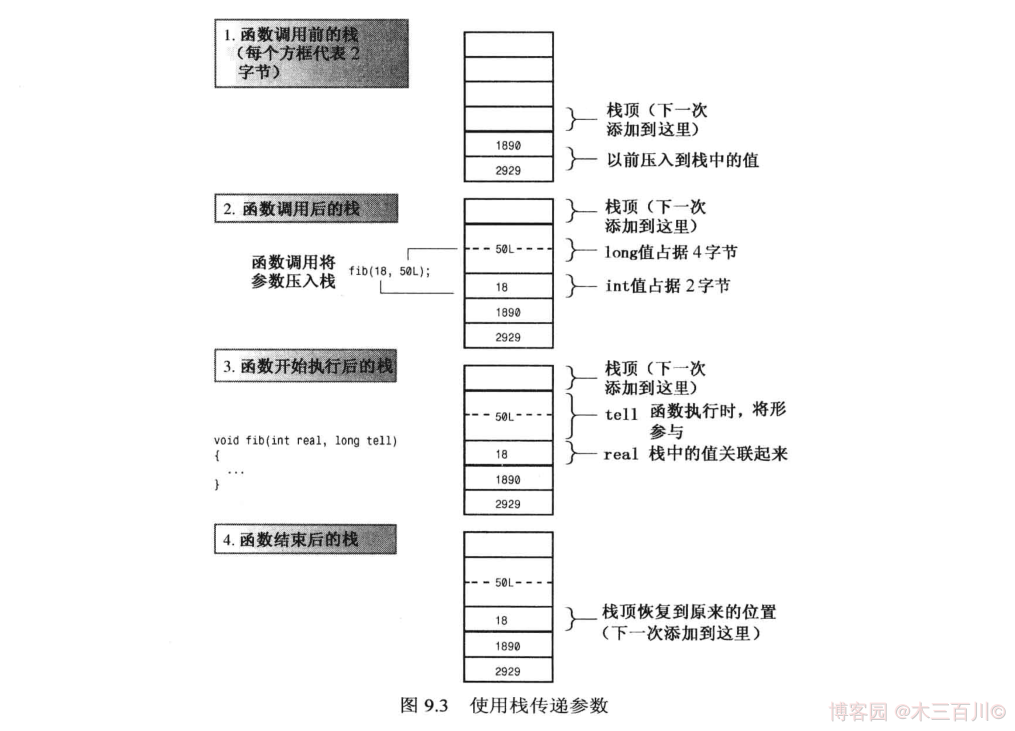
函數 fib() 被調用時,傳遞一個 2 位元組的 int 和一個 4 位元組的 long,這些值被加入到棧中。當 fib() 開始執行時,它將名稱 real 和 tell 同這兩個值關聯起來。當 fib() 結束時,棧頂指針重新指向以前的位置。新值沒有被刪除,但不再被標記,它們所占據的空間將被下一個將值加入到棧中的函數調用所使用。(上圖做了簡化,實際上函數調用可能傳遞其它信息,比如返回地址,深入學習可查看函數調用時的彙編代碼)
自動變數的隱藏:如下例子所示,在函數內的代碼塊中,新的同名自動變數 value 隱藏了代碼塊外部的 value變數,當程式離開該代碼塊時,原來的 value 變數又重新可見。
int main()
{
//自動變數1
int value = 1;
//輸出結果為0x0080FDC8
cout << &value << endl;
//用花括弧括起來的代碼塊
{
//自動變數2
int value = 2;
//輸出結果為0x0080FDBC
cout << &value << endl;
}
//輸出結果為0x0080FDC8
cout << &value << endl;
return 0;
}
auto 關鍵字:在 C++11 之前,關鍵字 auto 被用來顯式地指出變數為局部自動存儲,且只能被用於預設為自動存儲的變數;在 C++11 中,關鍵字 auto 被用來做自動類型推斷。
//C++11之前,顯式指明x為局部自動存儲
auto double x = 53.0;
//C++11中,用於自動類型推斷
auto x = 53.0;
register 關鍵字:在 C++11 之前,關鍵字 register 被用來建議編譯器使用 CPU 寄存器來存儲自動變數,提示編譯器這種變數用得很多,可對其做特殊處理(寄存器變數);在 C++11 中,關鍵字 register 被用來顯式地指出變數是局部自動存儲,且只能被用於原本就是自動存儲的變數,這與 auto 以前的用法完全相同,使用它的唯一原因是,指出一個自動變數,這個自動變數可能與外部變數同名。
//C++11之前,建議編譯器用寄存器存儲x
register int x = 53;
//C++11中,顯式指明x為局部自動存儲
register int x = 53;
9.2.5 靜態存儲持續性變數
靜態變數的種類:C++ 為靜態存儲持續性變數提供了 3 種鏈接性:外部鏈接性(可在其他文件中訪問)、內部鏈接性(只能在當前文件中訪問)和無鏈接性(只能在當前函數或代碼塊中訪問)。
- 要想創建外部鏈接性的靜態變數,必須在代碼塊的外面聲明它,如下代碼片段中的
global_all_file變數,可以在程式的其他文件中使用它; - 要想創建內部鏈接性的靜態變數,必須在代碼塊的外面聲明它並使用
static關鍵字,如下代碼片段中的global_one_file變數,只能在包含static int global_one_file = 50;語句的文件中使用它。 - 要想創建沒有鏈接性的靜態變數,必須在代碼塊的內部聲明它並使用
static關鍵字,如下代碼片段中的local_one_function變數,它的作用域為局部,只能在func()函數中使用它,與自動變數不同的是,即使在func()函數沒有被執行時,它也留在記憶體中。
int global_all_file = 1000; //外部鏈接性的靜態變數
static int global_one_file = 50; //內部鏈接性的靜態變數
int main()
{
...
}
void func()
{
static int local_one_function = 10; //無鏈接性的靜態變數
...
}
靜態變數的記憶體管理:靜態變數在整個程式執行期間一直存在,靜態變數的數目在程式運行期間是不變的。程式不需要使用特殊的裝置(如棧)來管理它們,編譯器將分配固定的記憶體塊來存儲所有的靜態變數,這些變數在整個程式執行期間一直存在。因此,與自動變數相比,它們的壽命更長。
靜態變數的初始化:所有靜態變數都有如下初始化特征:未被初始化的靜態變數的所有位都被設置為 0,這種變數被稱為零初始化的(zero-initialized),包括靜態數組和結構。對於標量類型,零將被強制轉換為合適的類型,例如空指針用 0 表示,但內部可能採用非零表示。除預設的零初始化外,還可對靜態標量進行常量表達式初始化和動態初始化。零初始化和常量表達式初始化被統稱為靜態初始化,這意味著在編譯器處理文件(翻譯單元)時初始化變數,動態初始化意味著變數將在編譯後初始化。
#include <cmath>
int x; //零初始化
int y = 5; //常量表達式初始化
int z = 13 * 13; //常量表達式初始化
int u = 2 *sizeof(long) + 1; //常量表達式初始化
double pi = 4.0 * atan(1.0); //動態初始化
首先,所有靜態變數都被零初始化,而不管程式員是否顯式地初始化了它。接下來,如果使用常量表達式初始化了變數,且編譯器僅根據當前翻譯單元就可計算表達式,編譯器將執行常量表達式初始化,必要時,編譯器將執行簡單計算,C++11 新增了關鍵字 constexpr,這增加了創建常量表達式的方式。最後,在程式執行時將進行動態初始化。上述程式中,x、y、z、u 和 pi 首先被零初始化,然後編譯器計算常量表達式的值對 y、z 和 u 進行常量表達式初始化,但要初始化pi,必須調用函數 atan(),這需要等到該函數鏈接且程式執行時。
9.2.6 外部鏈接性的靜態變數
外部變數的使用:鏈接性為外部的變數通常簡稱為外部變數,它們的存儲持續性為靜態,作用域為整個文件,但也可以在同一項目的其他文件中使用它。外部變數的使用條件有兩個:
- 一方面,在每個使用外部變數的文件中,都必須聲明它。
- 另一方面,C++ 有單定義規則 "One Definition Rule",簡稱 ODR,該規則指出,變數只能有一次定義。
C++ 提供了兩種變數聲明方式,來滿足這兩個條件:
- 定義聲明(defining declaration)或簡稱為定義(definition),它給變數分配存儲空間。定義聲明不使用關鍵字
extern,或者在使用關鍵字extern的同時對變數進行了人為初始化(可用此法來修改const全局常量預設的內部鏈接性為外部鏈接性,見後面的 cv 限定符小節)。 - 引用聲明(referencing declaration)或簡稱為聲明(declaration),它引用已有的變數,不給變數分配存儲空間。需要使用關鍵字
extern且不能進行初始化,否則該聲明將變為定義聲明。
int x; //定義聲明
extern int y = 0; //定義聲明
extern int z; //引用聲明,必須在其他文件中進行定義
在多個文件中使用外部變數時,必須且只能在一個文件中包含該變數的定義聲明(滿足第二個使用條件),在使用該變數的其他所有文件中,都必須使用關鍵字 extern 聲明它,即包含該變數的引用聲明(滿足第一個使用條件)。
//文件file01.cpp
int dogs = 22; //定義聲明
extern int cats = 40; //定義聲明
//文件file02.cpp
extern int dogs; //引用聲明
extern int cats; //引用聲明
外部變數的隱藏:局部變數可能隱藏同名的全局變數,這並不違反單定義規則,雖然程式中可包含多個同名的變數的定義,但每個變數的實際作用域不同,作用域相同的變數沒有違反單定義規則。定義與外部變數同名的局部變數後,局部變數將隱藏外部全局變數,但 C++ 提供了作用域解析運算符雙冒號(::),將它放在變數名前面,可使用該變數的全局版本。
//文件file01.cpp
int dogs = 22; //定義聲明
//文件file02.cpp
extern int dogs; //引用聲明
void local()
{
int dogs = 88;
cout << dogs << endl; //輸出88
cout << ::dogs << endl; //輸出22
}
int main()
{
...
}
9.2.7 內部鏈接性的靜態變數
將 static 關鍵字用於作用域為整個文件的變數時,該變數的鏈接性將為內部的。鏈接性為內部的變數只能在其所屬的文件中使用,無法在其他文件中使用,但外部變數都具有外部鏈接性,可以在其他文件中使用。
//文件file02.cpp
static int errors = 2; //內部鏈接性的靜態變數,只能在其所屬文件中使用
可使用外部變數在多文件程式的不同部分之間共用數據;可使用鏈接性為內部的靜態變數在同一個文件中的多個函數之間共用數據(名稱空間提供了另一種共用數據的方法)。另外,如果將作用域為整個文件的變數變為內部鏈接性的,就不必擔心其名稱與其他文件中的作用域為整個文件的變數發生衝突。因為此時若存在同名的外部變數,具有內部鏈接性的變數將完全隱藏同名外部變數,且無法通過 extern 關鍵字以及 :: 作用域解析運算符訪問到同名外部變數。
//文件file01.cpp
int errors = 1; //外部鏈接性靜態變數
//文件file02.cpp
static int errors = 2; //內部鏈接性靜態變數
void func()
{
int errors = 3;
cout << errors << endl; //結果為3
cout << ::errors << endl; //結果為2
}
void fund()
{
extern int errors;
cout << errors << endl; //結果為2
cout << ::errors << endl; //結果為2
}
int main()
{
...
}
9.2.8 無鏈接性的靜態變數
將 static 關鍵字用於在代碼塊中定義的局部變數時,該變數沒有鏈接性,且將導致局部變數的存儲持續性為靜態的。這意味著雖然該變數只在該代碼塊中可用,但它在該代碼塊不處於活動狀態時仍然存在。因此在兩次函數調用之間,靜態局部變數的值將保持不變。另外,如果初始化了靜態局部變數,則程式只在啟動時進行一次初始化,以後再次調用函數時,將不會像自動變數那樣再次被初始化。
void func()
{
//初始化只進行一次
static int count = 0;
//每次調用時改變其值
count++;
//輸出
cout << count << endl;
}
int main()
{
func(); //輸出1
func(); //輸出2
func(); //輸出3
func(); //輸出4
return 0;
}
9.2.9 存儲說明符和 cv 限定符
C++ 關鍵字中包含以下六個存儲說明符(storage class specifer),它們提供了有關存儲的信息,除了 thread_local 可與 static 或 extern 結合使用,其他五個說明符不能同時用於同一個聲明。
auto關鍵字:在 C++11之前,可以在聲明中使用關鍵字auto指出變數為自動變數;在 C++11 中,auto用於自動類型推斷,已不再是存儲說明符。register關鍵字:在 C++11 之前,關鍵字register用於在聲明中指示寄存器變數;在 C++11中,它只是顯式地指出變數是局部自動存儲。static關鍵字:關鍵字static被用在作用域為整個文件的聲明中時,表示內部鏈接性;被用於局部聲明中時,表示局部變數的存儲持續性是靜態的,有人稱之為關鍵字重載。extern關鍵字:關鍵字extern表明是引用聲明,即聲明引用在其他地方定義的變數。thread_local關鍵字:關鍵字thread_local指出變數的持續性與其所屬線程的持續性相同,thread_local變數之於線程,猶如常規靜態變數之於整個程式。mutable關鍵字:關鍵字mutable被用來指出,即使結構(或類)變數為const,其某個成員也可以被修改。
//mutable變數不受const限制
struct mdata
{
int x;
mutable int y;
};
const mdata veep = {0, 0};
veep.x = 5; //不被允許
veep.y = 5; //可以正常運行
C++ 中常說的 cv 限定符是指 const 關鍵字和 volatile 關鍵字。關鍵字 volatile 表明,即使程式代碼沒有對記憶體單元進行修改,其值也可能發生變化,例如:可以將一個指針指向某個硬體位置,其中包含了來自串列埠的時間或信息,在這種情況下,硬體(而不是程式)可能修改其中的內容,或者兩個程式可能互相影響,共用數據,該關鍵字的作用是為了防止編譯器進行相關的優化(若編譯器發現程式在相鄰的幾條語句中兩次使用了某個變數的值,則編譯器可能不是讓程式查找這個值兩次,而是將這個值緩存到寄存器中,這種優化假設變數的值在這兩次使用之間不會變化)。
關鍵字 const 表明,記憶體被初始化後,程式便不能再對它進行修改,除此之外,在 C++ 中,const 限定符對預設存儲類型也稍有影響。在預設情況下全局變數的鏈接性為外部的,但 const 全局變數的鏈接性為內部的。因此,在 C++ 看來,全局定義 const 常量就像使用了 static 說明符一樣:
//內部鏈接性的靜態const常量,以下兩種方式等效
const int x = 10;
static const int x = 10;
const 全局變數的這種特性意味著,可以將 const 常量的定義聲明放在頭文件中,只要在源代碼文件中包含這個頭文件,它們就可以獲得同一組常量,此時每個定義聲明都是其文件(翻譯單元)所私有的,而不是所有文件共用同一組常量。若程式員希望某個 const 全局變數的鏈接性為外部的,可以在定義聲明中增加 extern 關鍵字,來覆蓋預設的內部鏈接性,此時就只能有一個文件包含定義聲明,其他使用到該 const 常量的文件必須包含相應的 extern 引用聲明,這個 const 常量將在多個文件之間共用。
//外部鏈接性的靜態const常量
extern const int y = 10;
9.2.10 函數鏈接性
C++ 不允許在一個函數中定義另外一個函數,因此所有函數的存儲持續性都是靜態的,即在整個程式執行期間都一直存在。在預設情況下,函數的鏈接性為外部的,即可以在文件間共用。還可以使用關鍵字 static 將函數的鏈接性設置為內部的,使之只能在一個文件(翻譯單元)中使用,必須同時在原型和定義中使用 static 關鍵字:
//鏈接性為內部的函數,只能在所在文件中使用
static int privateFunction(); //函數原型
//函數定義
static int privateFunction()
{
...
}
和變數一樣,在定義內部鏈接性的函數的文件中,內部鏈接性函數定義將完全覆蓋外部同名函數定義。單定義規則也適用於非內聯函數,對於鏈接性為外部的函數來說,這意味著在多文件程式中,只能有一個文件(該文件可能是庫文件)包含該函數的定義,但使用該函數的每個文件都應包含其函數原型(和外部變數不同的是,函數原型前可省略使用關鍵字 extern)。內聯函數則不受單定義規則的約束,可將內聯函數定義寫在頭文件中,但 C++ 要求同一個函數的所有內聯定義都必須相同。內部鏈接性的 static 函數定義也可寫在頭文件中,這樣每個包含該頭文件的翻譯單元都將有各自的 static 函數,而不是共用同一個函數。
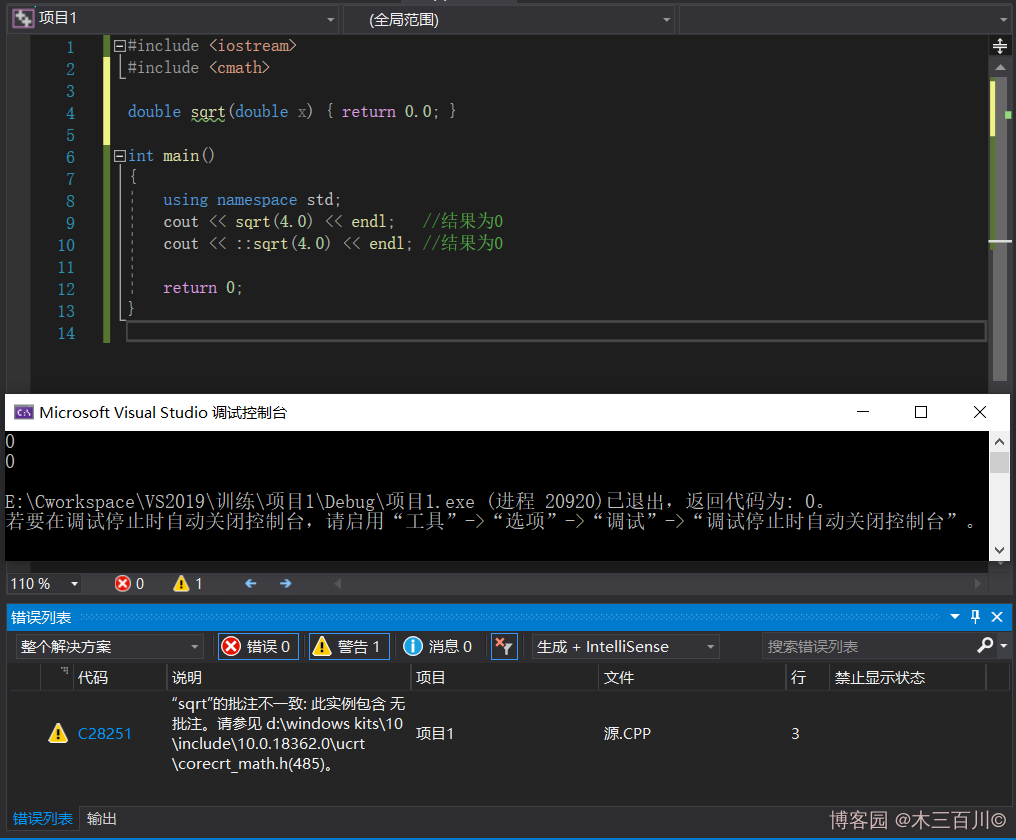
//文件file.cpp
#include <iostream>
#include <cmath>
double sqrt(double x) { return 0.0; }
int main()
{
using namespace std;
cout << sqrt(4.0) << endl; //結果為0
cout << ::sqrt(4.0) << endl; //結果為0
return 0;
}
在程式的某個文件中調用一個函數時,如果該文件中的函數原型指出該函數是靜態的,則編譯器將只在該文件中查找函數定義;否則,編譯器(包括鏈接程式)將在所有的程式文件中查找,如果找到兩個定義,編譯器將發出錯誤消息,如果在程式文件中未找到,編譯器將在庫中搜索。這意味著如果定義了一個與庫函數同名的函數,編譯器將使用程式員定義的版本,而不是庫函數。為養成良好的編程習慣,應儘量避免使用與標準庫函數相同的函數名,上述程式在 Microsoft Visual Studio 2019 中的輸出結果都為 0,但編譯器會輸出 C28251 的警告信息,如下圖所示。
9.2.11 語言鏈接性
另一種形式的鏈接性——稱為語言鏈接性(language linking)也對函數有影響,鏈接程式要求每個不同的函數都有不同的符號名。在 C 語言中,一個名稱只對應一個函數,編譯器可能將 spiff 這樣的函數名翻譯為 _spiff,這種方法被稱為 C 語言鏈接性(C language linking)。但在 C++ 中,由於函數重載,一個名稱可能對應多個函數,編譯器將執行名稱修飾,可能將 spiff(int) 轉換為 _spiff_i,將 spiff(double, double) 轉換為 _spiff_d_d,這種方法被稱為 C++ 語言鏈接性(C++ language linking)。因此,鏈接程式尋找與 C++ 函數調用匹配的函數時,使用的查詢約定與 C 語言不同,若要在 C++ 程式中使用 C 庫(靜態庫、動態庫)中預編譯的函數 spiff(int),應該使用如下函數原型來指出要使用的函數符號查詢約定:
//使用C庫中的預編譯好的函數
extern "C" void spiff(int); //方式一
extern "C" //方式二
{
void spiff(int);
}
上面的兩種方式都指出了使用 C 語言鏈接性來查找相應的函數,若要使用 C++ 語言鏈接性,可按如下方式指出:
//使用C++庫中的預編譯好的函數
void spiff(int); //方式一
extern void spiff(int); //方式二
extern "C++" void spiff(int); //方式三
extern "C++" //方式四
{
void spiff(int);
}
C 和 C++ 鏈接性是 C++ 標準指定的說明符,但實現可提供其他語言鏈接性說明符。
9.3 定位 new 運算符
9.3.1 動態存儲持續性
使用 C++ 運算符 new(或 C 函數 malloc())分配的記憶體,被稱為動態記憶體。動態記憶體由運算符 new 和 delete 控制,而不是由作用域和鏈接性規則控制。動態記憶體的分配和釋放順序取決於 new 和 delete 在何時以何種方式被使用,因此,可以在一個函數中分配動態記憶體,而在另一個函數中將其釋放。通常,編譯器使用三塊獨立的記憶體:一塊用於靜態變數(可能再細分),一塊用於自動變數,另外一塊用於動態存儲。
//文件file01.cpp
float * p_fees = new float[20];
//文件file02.cpp
extern float * p_fees;
雖然存儲方案概念不適用於動態記憶體,但適用於用來跟蹤動態記憶體的自動和靜態指針變數。例如上述程式中由 new 分配的 80 個位元組(假設 float 為 4 個位元組)的記憶體將一直保留在記憶體中,直到使用 delete 運算符將其釋放。但指針 p_fees 的存儲持續性與其聲明方式有關,若 p_fees 是自動變數,則當包含該申明的語句塊執行完畢時,指針 p_fees 將消失,如果希望另一個函數能夠使用這 80 個位元組中的內容,則必須將其地址傳遞出去。若將 p_fees 聲明為外部變數,則文件中位於該聲明後面的所有函數都可以使用它,通過在另一個文件中使用它的引用聲明,便可在其中使用該指針。
在程式結束時,由 new 分配的記憶體通常都將被系統釋放,但在不那麼健壯的操作系統中,在某些情況下,請求大型記憶體塊將導致該代碼塊在程式結束不會被自動釋放,最佳習慣是:使用 delete 來釋放 new 分配的記憶體。
9.3.2 常規 new 運算符的使用
使用常規 new 運算符初始化動態分配的記憶體時,有以下幾種方式:
//C++98風格,小括弧初始化
int *pint = new int(6);
//C++11風格,大括弧初始化
int *pint = new int{6};
//C++11大括弧初始化可用於結構和數組
struct points {
double x;
double y;
double z;
};
points * ptrP = new points{1.1, 2.2, 3.3};
int * arr = new int[4]{2, 4, 6, 7};
常規 new 負責在堆(heap)中找到一個足以能夠滿足要求的記憶體塊,當 new 找不到請求的記憶體量時,最初 C++ 會讓 new 返回一個空指針,但現在將會拋出一個異常 std::bad_alloc,這將在後續章節介紹。當使用 new 運算符時,通常會調用位於全局名稱空間中的分配函數(alloction function),當使用 delete 運算符時,會調用對應的釋放函數(deallocation function)。
//分配函數原型
void * operator new(std::size_t);
void * operator new[](std::size_t);
//釋放函數原型
void operator delete(void *);
void operator delete[](void *);
其中 std::size_t 是一個typedef,對應於合適的整型,這裡只做簡單的過程說明,實際上使用運算符 new 的語句也可包含給記憶體設定的初始值,會複雜一些。C++ 將這些函數稱為可替換的(replaceable),可根據需要對其進行定製。例如,可定義作用域為類的替換函數,對其進行定製,以滿足該類的記憶體分配需求。
int *pint = new int; //被轉換為 int *pint = new(sizeof(int));
int * arr = new int[4];//被轉換為 int * arr = new(4 * sizeof(int));
delete pint; //被轉換為 delete(pint);
9.3.3 定位 new 運算符的使用
new 運算符還有另一種變體,被稱為定位(placement)new 運算符,它能夠讓程式員指定要使用的位置,可使用這種特性來設置其記憶體管理規程、處理需要通過特定地址進行訪問的硬體或在特定位置創建對象。如下程式是一個使用定位 new 運算符的例子,有以下幾點需註意:
- 使用定位
new特性必須包含頭文件new,且在使用時需人為提供可用的記憶體地址。 - 定位
new既可以用來創建數組,也可以用來創建結構等變數。 - 定位
new運算符使用傳遞給它的地址,它不跟蹤哪些記憶體單元已被使用,也不查找未使用的記憶體塊,這將一些記憶體管理的負擔交給了程式員,當在同一塊大型記憶體區域內創建不同變數時,可能需要人為計算記憶體的偏移量大小,防止出現變數記憶體區域重疊的情況。 delete只能用來釋放常規new分配出來的堆記憶體,下麵例子中的buffer1與buffer2都屬於靜態記憶體,不能用delete釋放,若buffer1或buffer2是通過常規new運算符分配出來的,則可以且必須用delete進行釋放。
#include <iostream>
#include <new>
struct person
{
char name[20];
int age;
};
char buffer1[50];
char buffer2[500];
int main()
{
using namespace std;
//常規new運算符,數據存儲在堆上
person *p1 = new person;
int *p2 = new int[20];
//定位new運算符,數據存儲在指定位置,這裡為靜態區
person *pp1 = new (buffer1) person;
int *pp2 = new (buffer2) int[20];
//顯示地址(32位系統)
cout << (void *) buffer1 << endl; //結果為0x00AEC2D0
cout << (void *) buffer2 << endl; //結果為0x00AEC308
cout << p1 << endl; //結果為0x00EFF640
cout << p2 << endl; //結果為0x00EF6470
cout << pp1 << endl; //結果為0x00AEC2D0
cout << pp2 << endl; //結果為0x00AEC308
//釋放動態堆記憶體
delete p1;
delete[] p2;
}
上面程式中使用 (void *) 對 char * 進行強制轉換,以使得 buffer1 與 buffer2 的地址能夠正常輸出,否者它們將輸出字元串。定位 new 運算符的原理也與此類似,它只是返回傳遞給它的地址,並將其強制轉換為 void *,以便能夠賦給任何指針類型,將定位 new 運算符用於類對象時,情況將更複雜,這將在第 12 章介紹。C++ 允許程式員重載定位 new 函數,它至少需要接收兩個參數,且其中第一個總是 std::size_t,指定了請求的位元組數。
int * p1 = new(buffer) int; //被轉換為 int * p1 = new(sizeof(int),buffer);
int *arr = new(buffer) int[4];//被轉換為 int *arr = new(4*sizeof(int),buffer)
9.4 名稱空間
9.4.1 傳統的 C++ 名稱空間
且聽下回分解
9.4.2 新增的 C++ 名稱空間
且聽下回分解
9.4.3 using 聲明和 using 編譯指令
且聽下回分解
9.4.4 嵌套的名稱空間
且聽下回分解
9.4.5 未命名的名稱空間
且聽下回分解
9.4.6 名稱空間的使用方法
且聽下回分解
本文作者:木三百川
本文鏈接:https://www.cnblogs.com/young520/p/16864440.html
版權聲明:本文系博主原創文章,著作權歸作者所有。商業轉載請聯繫作者獲得授權,非商業轉載請附上出處鏈接。遵循 署名-非商業性使用-相同方式共用 4.0 國際版 (CC BY-NC-SA 4.0) 版權協議。


