
XML 官方文檔:https://www.w3school.com.cn/xml/index.asp 1.為什麼需要xml? 需求1:兩個程式間進行數據通信? 需求2:給一臺伺服器,做一個配置文件,當伺服器程式啟動時,去讀取它應當監聽的埠號、還有連接資料庫的用戶名和密碼 spring中的IOC配置 ...
XML
官方文檔:https://www.w3school.com.cn/xml/index.asp
1.為什麼需要xml?
- 需求1:兩個程式間進行數據通信?
- 需求2:給一臺伺服器,做一個配置文件,當伺服器程式啟動時,去讀取它應當監聽的埠號、還有連接資料庫的用戶名和密碼
- spring中的IOC配置文件beans.xml,mybatis的xxxMapper.xml文件,tomcat的server.xml,web.xml文件
- xml能存儲複雜的數據關係
xml技術用於解決什麼問題?
-
解決程式間數據傳輸的問題:
比如qq之間的數據傳送,用xml格式來傳輸數據,具有良好的可讀性,可維護性
以前兩個程式間的通信用xml作為數據通信的格式,現在一般用json
-
xml可以做配置文件
xml做配置文件可以說是非常的普遍,比如我們的tomcat伺服器的server.xml web.xml
-
xml可以充當小型的資料庫
我們程式中可能用到的數據,如果放在資料庫中讀取不合適(因為你要增加維護資料庫工作),可以考慮直接用xml文件來做小型資料庫,而且直接讀取文件顯然要比讀取資料庫快
現在也不太使用xml作數據存儲了
2.xml語法
- 快速入門
需求:使用idea創建Students.xml存儲多個學生信息
<?xml version="1.0" encoding="UTF-8" ?>
<!-- 1.xml:表示該文件的類型為xml
2.version 表示版本
3.encoding="UTF-8" 文件編碼為UTF-8
4.students:root元素/根元素,名字自己定義
5.<student> </student>表示一個students的子元素,可以有多個
6.id就是屬性,name,age,gender是student元素的子元素
-->
<students>
<student id="100">
<name>jack</name>
<age>10</age>
<gender>男</gender>
</student>
<student id="200">
<name>Mary</name>
<age>18</age>
<gender>女</gender>
</student>
</students>
- 一個xml文檔分為如下幾部分內容
- 文檔聲明
- 元素
- 屬性
- 註釋
- CDATA區、特殊字元
2.1文檔聲明
<?xml version="1.0" encoding="UTF-8" ?>
- xml聲明放在xml文檔的第一行
- xml聲明由以下幾個部分組成:
- version:文檔符合xml1.0規範,我們學習1.0
- encoding:文檔字元編碼,比如:utf-8
2.2元素
- 元素語法要求:
- 每個xml文檔必須有且只有一個根元素
- 根元素是一個完全包括文檔中其他所有元素的元素
- 根元素的起始標記要放在所有其他元素的起始標記之前
- 根元素的結束標記要放在所有其他元素的結束標記之後
- xml元素指xml文件中出現的標簽,一個標簽分為開始標簽和結束標簽,一個標簽有如下幾種書寫形式
-
包含標簽體:
<a>www.baidu.com</a> -
不含標簽體:
<a></a>,簡寫為<a/> -
一個標簽中也可以嵌套若幹子標簽。但所有的標簽必須合理地嵌套,絕對不允許交叉嵌套
- 在很多時候,元素,節點,標簽是相同的意思
- xml元素命名規則:
- 區分大小寫,例如:
<P>和<p>是兩個不同的標記 - 不能以數字開頭
- 不能包含空格
- 名稱中間不能包含冒號
: - 如果標簽單詞需要間隔,建議使用下劃線
- 區分大小寫,例如:
2.3屬性
屬性介紹:
-
屬性值用雙引號
""或單引號''分隔(如果屬性值中有單引號'',就用雙引號""分隔,如過屬性值中有雙引號"",就用單引號''分隔) -
一個元素可以用多個屬性,它的基本格式為:
<元素名 屬性名="屬性值"> -
特定的屬性名稱在同一個元素標記中只能出現一次
即屬性名稱在同一個元素中不能重覆
-
屬性值不能包括&字元
2.4註釋
<!--這是一個註釋-->- 註釋內容中不要出現
-- - 不要把註釋放在標記中間。錯誤寫法:
<Name <!--the name-->>TOM</Name> - 註釋不能嵌套
- 可以在除標記以外的任何地方放註釋
2.5CDATA節
有些內容不想讓解析引擎執行,而是當做原始內容(普通文本)處理,可以使用CDATA括起來,CDATA節中的所有字元都會被當做簡單文本,而不是xml標記
-
語法:
<![CDATA[這裡可以把你輸入的字元原樣顯示,不會解析xml]]> -
可以輸入任意字元(除
]]>外) -
不能嵌套
例子
<?xml version="1.0" encoding="UTF-8" ?>
<students>
<student>
<code>
<!--如果希望把某些字元串當做普通文本使用,就用CDATA括起來-->
<![CDATA[
<script data-compress=strip>
function h(obj){
alert("一段js代碼");
}
</script>
]]>
</code>
</student>
</students>
3.轉義字元
對於一些單個字元,若想顯示其原始樣式,也可以使用轉義的形式予以處理
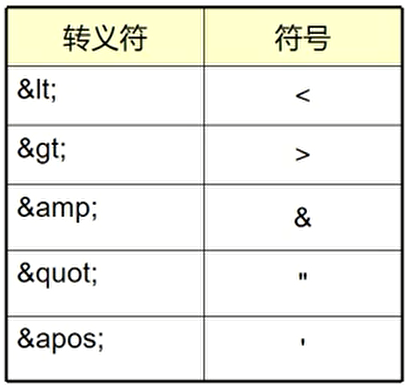
例子
<?xml version="1.0" encoding="UTF-8" ?>
<students>
<student>
<name>jack</name>
<age>10</age>
<gender>男</gender>
<!--轉義字元表示一些特殊的字元-->
<resume>年齡<>&</resume>
</student>
</students>
-
小結:
遵循如下規則的xml文檔稱為格式正規的xml文檔:
- xml聲明語句
<?xml version="1.0" encoding="UTF-8" ?> - 必須有且僅有一個根元素
- 標記區分大小寫
- 屬性值用引號
- 標記成對
- 空標記關閉
- 元素正確嵌套
4.DOM4j
4.1xml解析技術原理和介紹
-
xml技術原理
DOM (Document Object Model,文檔對象模型)定義了訪問和操作文檔的標準方法。
- 不管是html文件還是xml文件,都是標記型文檔,都可以使用w3c組織制定的dom技術來解析
- document對象表示的是整個文檔(可以是html文檔,也可以是xml文檔)
- DOM 把 XML 文檔作為樹結構來查看。能夠通過 DOM 樹來訪問所有元素。可以修改或刪除它們的內容,並創建新的元素。元素,它們的文本,以及它們的屬性,都被認為是節點
-
xml解析技術介紹
早期 JDK 為我們提供了兩種xml的解析技術:DOM和Sax
- dom解析技術是W3C組織制定的,而所有的編程語言都對這個解析技術使用了自己語言的特點進行實現。Java對dom技術解析也做了實現
- sun公司在JDK5版本對dom解析技術進行升級:SAX(Simple API for XML)解析,它是以類似事件機制通過回調告訴用戶當前正在解析的內容。是一行一行地讀取xml文件進行解析的,不會創建大量的dom對象。所以它在解析xml的時候,在性能上由於Dom解析
這兩種技術已經過時,簡單瞭解即可
- 第三方的XML解析技術
- jdom在dom基礎上進行了封裝
- dom4j 又對 jdom進行了封裝
- pull主要用在Android手機開發,跟sax非常類似,都是事件機制解析xml文件
4.2dom4j介紹
-
dom4j是一個簡單、靈活的開放源代碼的庫(用於解析/處理xml文件)。dom4j是由早期開發JDOM的人分離出來後獨立開發的。
-
與JDOM不同的是,dom4j使用介面和抽象基類,雖然dom4j的API相對要複雜一些,但他提供了比JDOM更好的靈活性
-
Dom4j是一個非常優秀的Java XML API,具有性能優異、功能強大和極易使用的特點。現在很多軟體採用的dom4j
-
使用dom4j開發,需要下載dom4j對象的jar文件
dom4j的jar包下載地址(內有使用案例):dom4j
官方api文檔:Overview (dom4j 1.6.1 API)
4.3dom4j獲得document對象的方式
開發dom4j要導入dom4j的jar包
DOM4j中,獲得document對象的方式有三種:
-
讀取XML文件,獲得document對象
SAXReader reader = new SAXReader();//創建一個解析器 Document document = reader.read(new File("src/input.xml"));//XML Document -
解析XML形式的文本,得到document對象
String text = "<members></members>";//直接對一個字元串的xml文本進行解析 Document document = DocumentHelper.parseText(text); -
主動創建document對象
Document document = DocumentHelper.createDocument();//創建根節點 Element root = document.addElement("members");
下麵只演示方式一的使用:讀取XML文件,獲得document對象
dom4j應用實例-讀取XML文件,獲得document對象
-
使用dom4j對students.xml文件進行增刪改查
- 重點講解查詢(遍歷和指定查詢)
- xml增刪改使用少,作為拓展,給出案例
-
引入dom4j的依賴的jar包
-
在src文件下創建Dom4j_類以及students.xml文件
students.xml:
<?xml version="1.0" encoding="UTF-8" ?>
<students>
<student id="01">
<name>小龍女</name>
<gender>女</gender>
<age>16</age>
<resume>古墓派掌門人</resume>
</student>
<student id="02">
<name>歐陽鋒</name>
<gender>男</gender>
<age>18</age>
<resume>白駝山弟子</resume>
</student>
</students>
Dom4j_.java:
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.io.SAXReader;
import org.testng.annotations.Test;
import java.io.File;
public class Dom4j_ {
/**
* 演示如何載入xml文件
*/
@Test
public void loadXML() throws DocumentException {
//得到一個解析器
SAXReader reader = new SAXReader();
//debug-->看看document對象的屬性
Document document = reader.read(new File("src/students.xml"));
System.out.println(document);
}
}
-
如下:在
Document document=reader.read(new File("src/students.xml"));處打上斷點:
-
點擊debug,點擊step over,可以看到document對象,它代表整個文檔。
展開document對象,rootElement代表的就是students根元素
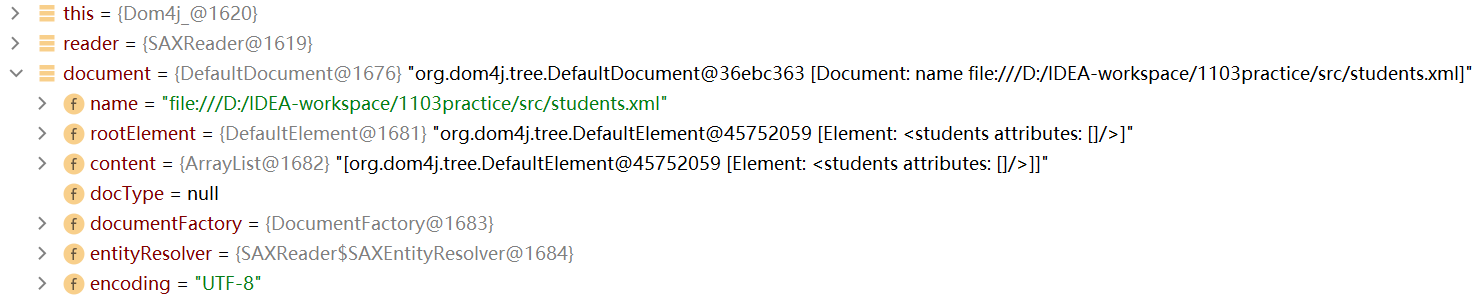
-
rootElement下麵有一個content屬性,content屬性存儲著所有的elementData
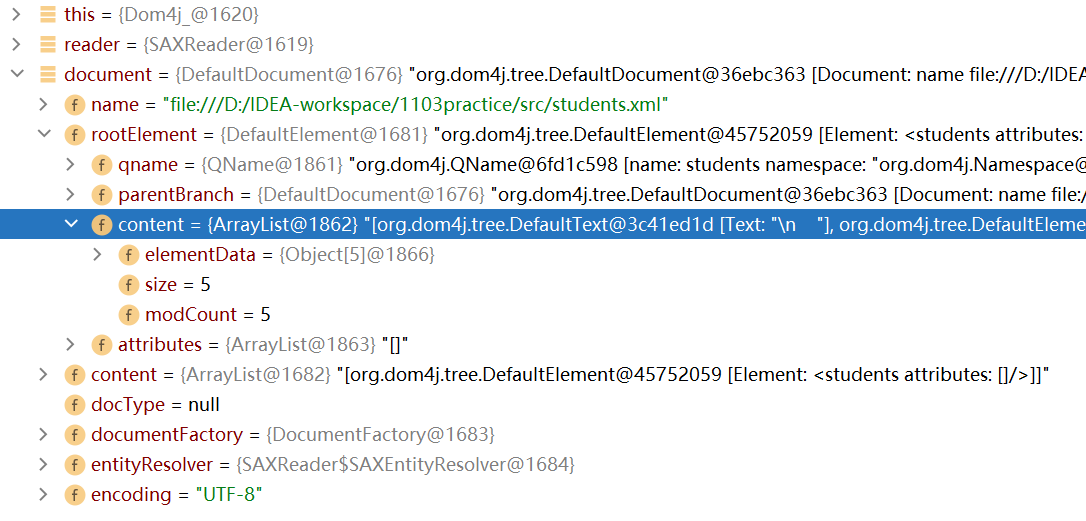
-
點擊elementData屬性,可以看到該屬性有5個對象:
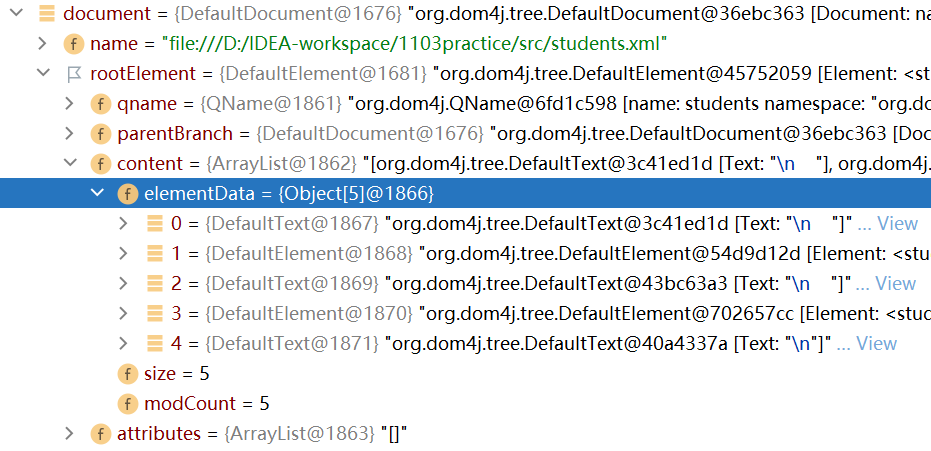
和html-dom解析一樣,這五個對象中有三個是換行符號\n,其餘的兩個才是根元素下麵的子元素student
-
點擊展開索引為1的元素對象(即student元素),可以看到該元素對象中又包含了9個對象,除了換行符之外,其餘的對象就是student元素的子元素,name節點,gender節點,age節點和resume節點

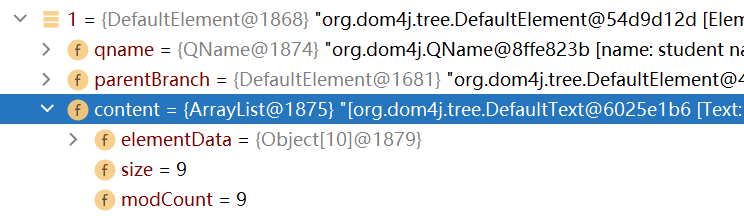
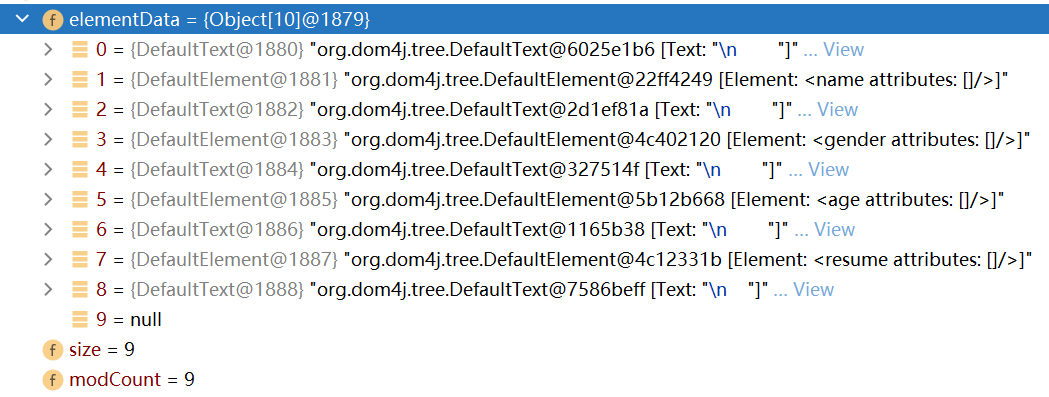
-
點擊name節點,展開,即可看到name節點的值

document對象的整體結構為:
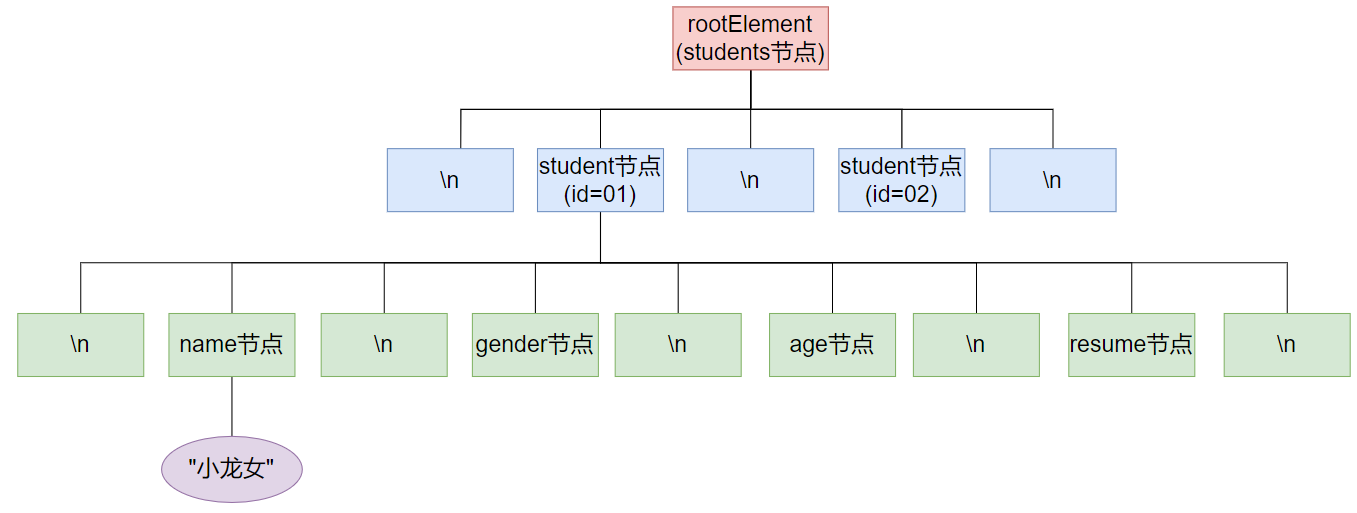
1.方式一遍歷
演示案例1:遍歷xml指定元素
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import org.testng.annotations.Test;
import java.io.File;
import java.util.List;
public class Dom4j_ {
/**
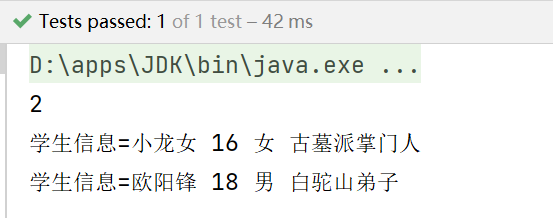
* 遍歷所有的student信息
*/
@Test
public void listStus() throws DocumentException {
//得到一個解析器
SAXReader reader = new SAXReader();
Document document = reader.read(new File("src/students.xml"));
//1.得到rootElement
Element rootElement = document.getRootElement();
//2.得到rootElement的student節點
List<Element> students = rootElement.elements("student");
System.out.println(students.size());//2
for (Element student : students) {//student就是student節點/元素
//獲取student節點的name節點
Element name = student.element("name");//因為name只有一個,這裡用element方法
Element age = student.element("age");
Element gender = student.element("gender");
Element resume = student.element("resume");
System.out.println("學生信息=" + name.getText() + " " +
age.getText() + " " + gender.getText() + " " + resume.getText());
}
}
}
2.方式一查詢
案例2:讀取指定xml元素
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import org.testng.annotations.Test;
import java.io.File;
public class Dom4j_ {
/**
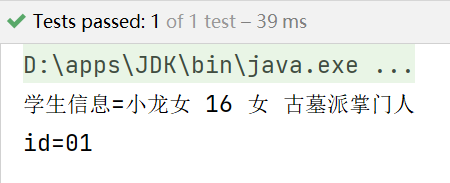
* 指定讀取第一個學生的信息
*/
@Test
public void readOne() throws DocumentException {
//得到一個解析器
SAXReader reader = new SAXReader();
Document document = reader.read(new File("src/students.xml"));
//1.得到rootElement
Element rootElement = document.getRootElement();
//2.獲取第一個學生
Element student = (Element) rootElement.elements("student").get(0);
//3.輸出該學生的信息
System.out.println("學生信息=" +
student.element("name").getText() + " " +
student.element("age").getText() + " " +
student.element("gender").getText() + " " +
student.element("resume").getText());
//4.獲取student元素的屬性
System.out.println("id="+student.attributeValue("id"));
}
}
- 如果想要省略層層取元素的步驟,直接在根節點取出指定的元素,可以使用xpath(https://dom4j.github.io/#xpath)


