
一、前言 近幾年大數據是異常的火爆,今天小編以java開發的身份來會會大數據,提高一下自己的層面! 大數據技術也是有很多: Hadoop Spark Flink 小編也只知道這些了,由於Hadoop,存在一定的缺陷(迴圈迭代式數據流處理:多 並行運行的數據可復用場景效率不行)。所以Spark出來了, ...
一、前言
近幾年大數據是異常的火爆,今天小編以java開發的身份來會會大數據,提高一下自己的層面!
大數據技術也是有很多:
- Hadoop
- Spark
- Flink
小編也只知道這些了,由於Hadoop,存在一定的缺陷(迴圈迭代式數據流處理:多
並行運行的數據可復用場景效率不行)。所以Spark出來了,一匹黑馬,8個月的時間從加入 Apache,直接成為頂級項目!!
選擇Spark的主要原因是:
Spark和Hadoop的根本差異是多個作業之間的數據通信問題 : Spark多個作業之間數據
通信是基於記憶體,而 Hadoop 是基於磁碟。
二、Spark介紹
Spark 是用於大規模數據處理的統一分析引擎。它提供了 Scala、Java、Python 和 R 中的高級 API,以及支持用於數據分析的通用計算圖的優化引擎。它還支持一組豐富的高級工具,包括用於 SQL 和 DataFrames 的 Spark SQL、用於 Pandas 工作負載的 Spark 上的 Pandas API、用於機器學習的 MLlib、用於圖形處理的 GraphX 和用於流處理的結構化流。
spark是使用Scala語言開發的,所以使用Scala更好!!
三、下載安裝
1. Scala下載
點擊安裝

下載自己需要的版本

點擊自己需要的版本:小編這裡下載的是2.12.11
點擊下載Windows二進位:

慢的話可以使用迅雷下載!
2. 安裝
安裝就是下一步下一步,記住安裝目錄不要有空格,不然會報錯的!!!
3. 測試安裝
win+R輸入cmd:
輸入:
scala
必須要有JDK環境哈,這個學大數據基本都有哈!!

4. Hadoop下載
一個小技巧:
Hadoop和Spark版本需要一致,我們先去看看spark,他上面名字就帶著和他配套的Hadoop版本!!
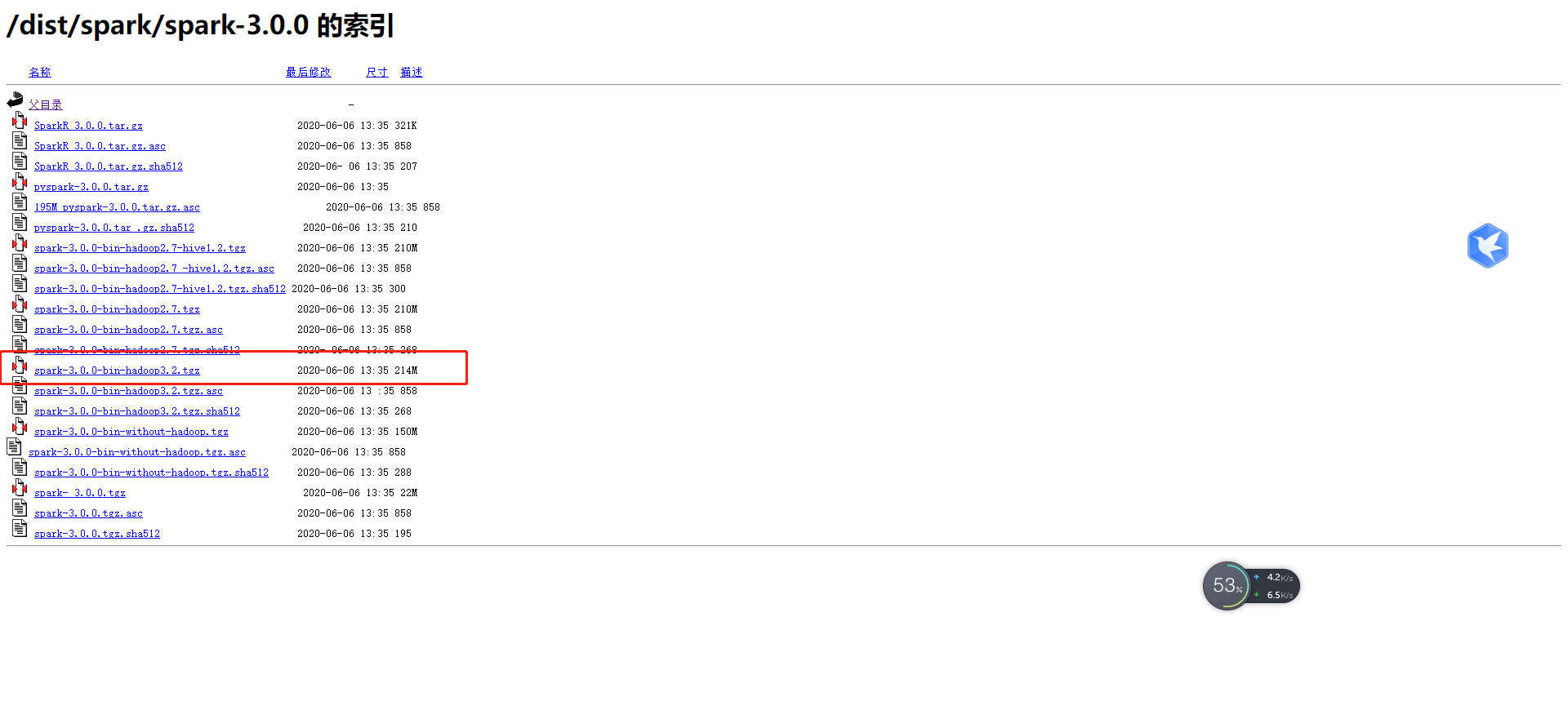
得出我們下載Hadoop的版本為:3.2

5. 解壓配置環境
解壓到即可使用,為了使用方便,要想jdk一樣配置一下環境變數!
新建HADOOP_HOME
值為安裝目錄:D:\software\hadoop-3.2.1
在Path里添加:%HADOOP_HOME%\bin
cmd輸入:hadoop:提示
系統找不到指定的路徑。
Error: JAVA_HOME is incorrectly set.
這裡先不用管,咱們只需要Hadoop的環境即可!
6. 下載Spark
點擊找到歷史版本:

點擊下載:

7. 解壓環境配置
新建:SPARK_HOME:D:\spark\spark-3.3.1-bin-hadoop3
Path添加:%SPARK_HOME%\bin
8. 測試安裝
win+R輸入cmd:
輸入:
spark-shell

四、集成Idea
1. 下載插件
scala
2. 給項目添加Global Libraries
打開配置:

新增SDK

下載你需要的版本:小編這裡是:2.12.11

右擊項目,添加上scala:

3. 導入依賴
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.0.0</version>
</dependency>
4. 第一個程式


object Test {
def main(args: Array[String]): Unit = {
println("hello")
var sparkConf = new SparkConf().setMaster("local").setAppName("WordCount");
var sc = new SparkContext(sparkConf);
sc.stop();
}
}
5. 測試bug1
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
22/10/31 16:20:35 INFO SparkContext: Running Spark version 3.0.0
22/10/31 16:20:35 ERROR Shell: Failed to locate the winutils binary in the hadoop binary path
java.io.IOException: Could not locate executable D:\software\hadoop-3.2.1\bin\winutils.exe in the Hadoop binaries.

原因就是缺少:winutils

把它發放Hadoop的bin目錄下:

6. 測試bug2
這個沒辦法復現,拔的網上的記錄:
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
22/10/08 21:02:10 INFO SparkContext: Running Spark version 3.0.0
22/10/08 21:02:10 ERROR SparkContext: Error initializing SparkContext.
org.apache.spark.SparkException: A master URL must be set in your configuration
at org.apache.spark.SparkContext.<init>(SparkContext.scala:380)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:120)
at test.wyh.wordcount.TestWordCount$.main(TestWordCount.scala:10)
at test.wyh.wordcount.TestWordCount.main(TestWordCount.scala)
就是這句:A master URL must be set in your configuration
解決方案:
就是沒有用到本地的地址
右擊項目:

沒有環境就添加上:

添加上:
-Dspark.master=local

7. 測試完成
沒有error,完美!!

五、總結
這樣就完成了,歷盡千辛萬苦,終於成功。第一次結束差點勸退,發現自己對這個東西還是不懂,後面再慢慢補Scala。先上手感受,然後再深度學習!!
如果對你有用,還請點贊關註下,支持一下一直是小編寫作的動力!!
可以看下一小編的微信公眾號,和網站文章首發看,歡迎關註,一起交流哈!!微信搜索:小王博客基地



