
摘要:本文結合圖解和問題,教你一次性搞定HashMap 本文分享自華為雲社區《java中HashMap的設計精妙在哪?用圖解和幾個問題教你一次性搞定HashMap》,作者:breakDawn。 HashMap核心原理 HashMap完整的put過程 以下是對上圖的詳細解釋: 首先,要獲取key的哈希 ...
摘要:本文結合圖解和問題,教你一次性搞定HashMap
本文分享自華為雲社區《java中HashMap的設計精妙在哪?用圖解和幾個問題教你一次性搞定HashMap》,作者:breakDawn。
HashMap核心原理
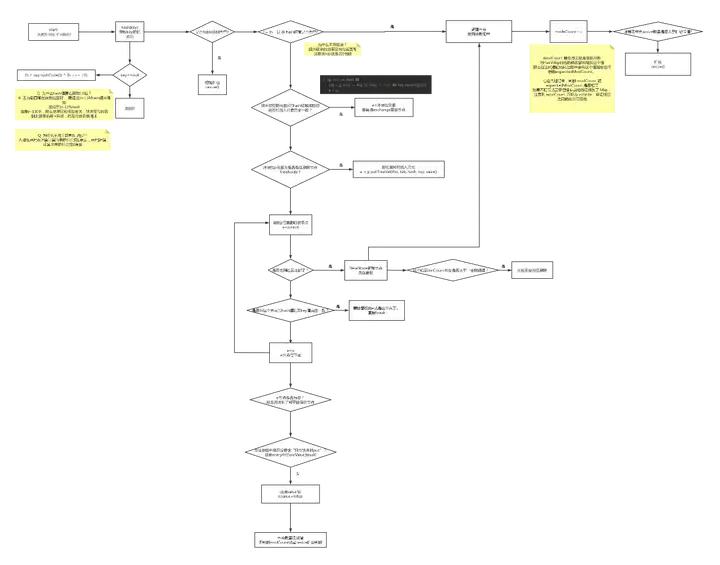
HashMap完整的put過程
以下是對上圖的詳細解釋:
- 首先,要獲取key的哈希值。
如果為空,就統一是0
否則,調用對象的.hashCode()方法,接著再與自己的右移16位進行異或,以便充分利用高位信息。 - 接著判斷內部node數組是否為空,如果是,先進行初始化擴容。預設為16。
- 根據(n-1)&hash值,獲取哈希表索引位置。
- 哈希表的node數組中,存放的是每組鏈表的頭節點。
先檢查頭節點是否和自己要存放的key完全匹配 (hash值相同,key值相同,先hash再key,是因為hash的判斷簡單,key的equals判斷可能會複雜)。如果匹配,得到需要替換的節點。 - 頭節點和自己要放的key不匹配,則判斷一下這個頭節點是否是紅黑樹節點,如果是,說明已經升級成紅黑樹了,調用putTree插入到紅黑樹中。
- 如果不是紅黑樹, 那就是遍歷鏈表,完全匹配就得到需要替換的節點。如果到尾部了,也沒匹配的,則插入新節點。
- 如果前面找到了要替換的節點,則判斷一下是否可以替換(是否沒要求putIfAbsent,或者value為null),是就替換,不是就結束
- 如果前面是插入了新節點,非替換, 則要modCount++(方便迭代器確認map是否更新), 同時++size, 然後和擴容閾值做判斷, 如果太大,就resize進行擴容
hashMap的擴容過程,java7和8擴容的區別
java7:
- 當resize時,新建一個數組newTable
- 遍歷原table中的每個鏈表和節點,重新hash,找到新的位置放入
- 放入的方式是頭插法,即始終插在鏈表的頭節點。
java8:
- 不再每個點rehash放置,而是最高位是0則坐標不變,最高位是1則坐標變為“10000+原坐標”,即“原長度+原坐標. 避免了頻繁的哈希計算和搬移過程。
- 使用尾插法在鏈表上插入節點
- 桶內元素超過8個,鏈表轉成紅黑樹
為什麼java8要改成尾插法?
A:多線程時,java7的map-put可能造成死迴圈。
A線程擴容到那一半, 還處在遍歷鏈表做頭插法搬移的過程時,存了2個局部變數,當前鏈點now指向a, next指向b,正準備搬移(a->b->c這樣的鏈表,a是頭節點)
B線程則同時完成線程擴容,但是map里都是引用,淺拷貝,** 因為是頭插法, 會導致順序變化**, 原本a->b->c 變成了c->b->a。
因此A恢復時, 鏈點還是a,next還是b, 於是往下走到了b, 取bbs的next時,已經變成了a, 於是發生了a->b->a的迴圈
導致後續操作的next都是錯誤操作,引發環形指針。
java8里改成尾插法,這樣做resize時,a->b->c 如果仍然哈希到同一個節點, 順序是不會發生變化的。
雖然解決了死迴圈問題, 但java8的hashMap仍然是線程不安全的,為什麼?
A:因為缺乏同步,導致同節點發生哈希碰撞時,if條件的判斷都可能是有問題的,導致本該插在鏈表頭節點後面的,結果直接作為鏈表頭覆蓋到數組上了。
具體到底滿足什麼情況,才會resize擴容呢?
A:HashMap負載因數 LoadFactor,預設值為0.75f。
衡量HashMap是否進行Resize的條件如下:
HashMap.Size >= Capacity * LoadFactor
另一種情況。JDK1.8源碼中,執行樹形化之前,會先檢查數組長度,如果長度小於64,則對數組進行擴容,而不是進行樹形化
擴容後,capacity擴容多少倍呢?為什麼
A:哈希表每次擴容是兩倍。
初始長度為2的冪次方,隨後以2倍擴容的方式擴容,元素在新表中的位置要麼不動,要麼有規律的出現在新表中(二的冪次方偏移量),這樣會使擴容的效率大大提高。
另外,hashmap採用二倍擴容還有另外一個好處:可以使元素均勻的散佈hashmap中,減少hash碰撞。

