
3.1 SQL概述: SQL:結構化查詢語言,是關係資料庫的標準語言,SQL是一個通用的、功能極強的關係資料庫語言 結構化查詢:理解:就是只要告訴資料庫我要乾什麼,怎麼乾就可以了 3.1.2 SQL的特點: 綜合統一: 集數據定義語言 DDL,數據操縱語言 DML,數據控制語言 DCL功能於一體, ...
3.1 SQL概述:
- SQL:結構化查詢語言,是關係資料庫的標準語言,SQL是一個通用的、功能極強的關係資料庫語言
- 結構化查詢:理解:就是只要告訴資料庫我要乾什麼,怎麼乾就可以了
-
3.1.2 SQL的特點:
- 綜合統一:
- 集數據定義語言 DDL,數據操縱語言 DML,數據控制語言 DCL功能於一體, 可以獨立完成資料庫生命周期中的全部活動,如下:
- 定義關係模式,插入數據,建立資料庫,
- 對資料庫中的數據進行查詢和更新
-
資料庫重構和維護
-
資料庫安全性、完整性控制等
- 嵌入式SQL和動態SQL定義
- 用戶資料庫投入運行後,可根據需要隨時逐步修改模式,不影響數據的運行
- 數據操作符統一(如:查詢就用select,刪除就用:delete)
- 高度非過程化:
- 非關係數據模型的數據操縱語言“面向過程”,必須制定存取路徑
- SQL只要提出“做什麼”,無須瞭解存取路徑
- 存取路徑的選擇以及SQL的操作過程由系統自動完成
- 面向集合的操作方式:
- 非關係數據模型採用面向記錄的操作方式,操作對象是一條記錄
- SQL採用集合操作方式:
- 操作對象、查找結果可以是元組的集合
- 一次插入、刪除、更新操作的對象可以是元組的集合
- 以同一種語法結構提供多種使用方式:
- SQL是獨立的語言
- 能夠獨立地用於聯機交互的使用方式
- SQL又是嵌入式語言
- SQL能夠嵌入到高級語言(例如C,C++,Java)程式中,供程式員設計程式時使用
- 簡單容學:
- SQL功能極強,完成核心功能只用了9個動詞
-
SQL功能 動詞 數據查詢 SELECT 數據定義 CREATE、DROP、ALTER 數據操縱 INSERT、UPDATE、DELETE 數據控制 GRANT、REVOKE
- 綜合統一:
-
3.1.3SQL基本概念:
-
- SQL支持關係資料庫三級模式結構:
- 基本表:
- 本身獨立存在的表
- SQL中一個關係就對應一個基本表
- 一個(或多個)基本表對應一個存儲文件
- 一個表可以帶若幹索引(索引:目的:快速查找數據,理解:相當於書中的目錄,如給學號做一個目錄,就可以快速查找)
- 存儲文件
- 邏輯結構組成了關係資料庫的內模式
- 物理結構是任意的,對用戶透明
- 視圖
- 從一個或幾個基本表導出的表
- 資料庫中只存放視圖的定義而不存放視圖對應的數據
- 視圖是一個虛表
- 用戶可以在視圖上再定義視圖
- 基本表:
- SQL支持關係資料庫三級模式結構:
3.2 學生-課程資料庫:
- 本章節內容以書上學習為主,書上包括示例圖表等
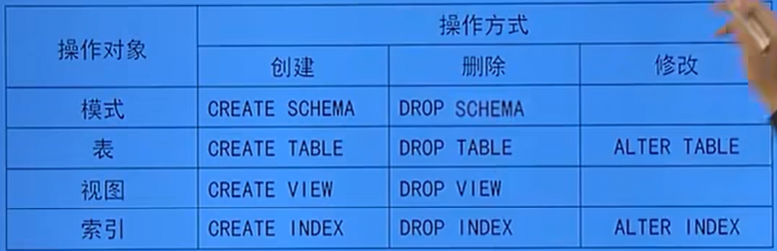
3.3 數據的定義:
- SQL的數據定義功能:模式定義、表定義、視圖和索引的定義
-
3.3.1 模式的定義於刪除:
- 定義模式:
- 模式在SQL理解:相當於一個倉庫有不同的房間存放不同的工具,不同的房間就是不同的模式,不同的房間也只能放不同的工具,可以給房間授權只允許誰去訪問,資料庫就相當於倉庫
- 語句格式如下:
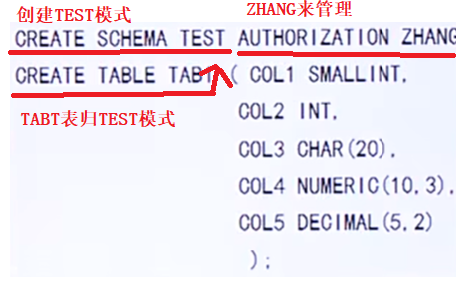
- CREATE SCHEMA <模式名> AUTHORIZATION <用戶名>
- AUTHORIZATION :該關鍵字的意思是把誰設置成該模式的管理員
- CREATE SCHEMA <模式名> AUTHORIZATION <用戶名>
- 例子:為用戶WANG定義一個學生-課程模式S-T
- CREATE SCHEMA "S-T" AUTHORIZATON WANG;
- 細節:
- 若沒有指定模式名,那麼就以用戶名來表示
- CREATE SCHEMA <用戶名錶示> AUTHORIZATON WANG;
- 在創建模式時同時還可以建立表
- 語法:CREATE SCHEMA <模式名> AUTHORIZATON <用戶名>[<表定義子句>|<視圖定義子句>];

- 執行創建模式語句必須擁有DBA許可權,或者DBA授權在CREATESCHEMA的許可權
- 如:張三管理太多模式了,他就可以在創建模式的時候把許可權給到歷史,註意的是資料庫要有李四這個人
- 若沒有指定模式名,那麼就以用戶名來表示
- 刪除模式:
- 語法:DROP SCHEMA <模式名> <CASCADE | RESTRICT>;
- <CASCADE | RESTRICT> 中的兩選項必須二選一:
- CASCADE(級聯)
-
刪除模式的同時把該模式中所有的資料庫對象全部刪除
-
-
RESTRICT(限制)
-
如果該模式中定義了下屬的資料庫對象(如表、視圖等),則拒絕該刪除語句的執行
-
- CASCADE(級聯)
-
例子:DROP SCHEMA ZHANG CASCADE;
-
刪除模式ZHANG,同時該模式中定義的表也被刪除
-
- 定義模式:
-
3.3.2 基本表的定義、刪除與修改:
- 定義基本表:
-
語句格式:
-
- 定義基本表:
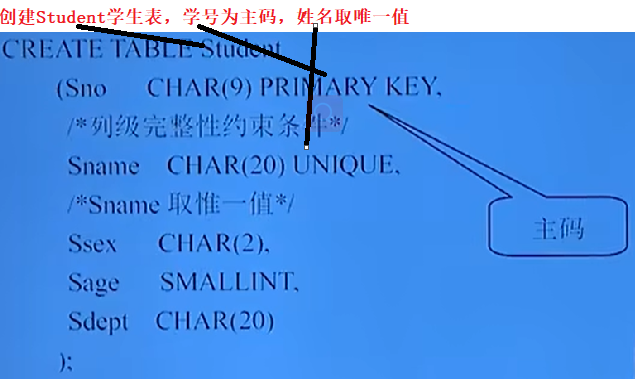
CREATE TABLE <表名>
( <列名> <數據類型> [<列級完整性約束條件>],
<列名> <數據類型> [<列級完整性約束條件>],
[<表級完整性約束條件>]);
-
-
- 細節:
- 如果完整性約束條件涉及到該表的多個屬性列 - [<表級完整性約束條件>],否則定義在列 - [<列級完整性約束條件>]
- 逗號代表一條語句的結束
- [ ] 大括弧里的內部代表可有可無
- 例子:
- 細節:
-
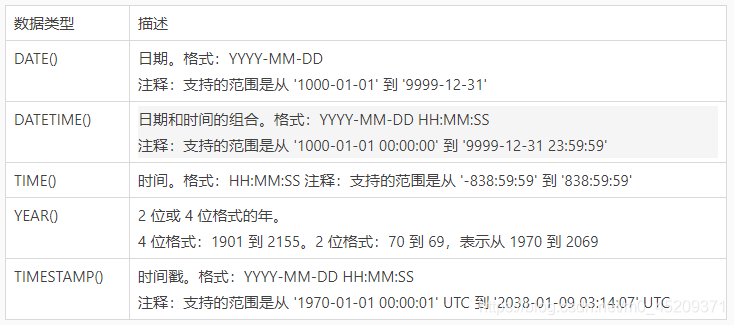
數據類型:
-
-


字元串類型:

枚舉類型:
枚舉類型英文為ENUM,對1~255個成員的枚舉需要1個位元組存儲;對於255 ~ 65535個成員,需要2個位元組存儲。最多允許65535個成員。創建方式:enum(“M”,“F”);日期類型:
-
-
-
模式與表:
-
每一個基本表都屬於某一個模式,一個模式包含多個基本表
- 理解:模式代表倉庫房間,基本表代表工具,工具可以是錘子、鐵鍬等等,所以基本表都屬於某一個模式,一個模式包含多個基本表
-
創建基本表(其他資料庫對象也一樣)時,若沒有指定模式,系統根據搜索路徑來確定該對象所屬的模式
- 理解:創建表,沒有指定模式,根據搜索路徑來確定:買了工具,都我沒有說放到能夠房間,那就誰買的誰去管理
-
顯示當前搜索路徑:
- SHOW search path;
-
搜索路徑的當前某預設值:
- $user(用戶名,登錄時的用戶名), PUBLIC;
-
DBA用戶可以設置搜索路徑:
-
SET search_path To "S-T",PUBLIC;
- “S-T”就是修改的搜索路徑,PUBLIC是沒有S-T就創建一個PUBLIC的模式
-
理解:買工具回來放到S-T房間,如果沒有S-T房間就放到PUBLIC房間中去
-
SET search_path To "S-T",PUBLIC;
-
若搜索路徑的模式名都不存在,系統將給出錯誤
-
若搜索路徑中的存在模式,ROMBS還使用模式列表中第一個存在的模式作為資料庫對象的模式名
-
理解:我設置了多個模式名,使用的時候用第一個,如果不存在在找第二個
-
-
每一個基本表都屬於某一個模式,一個模式包含多個基本表
- 創建基本表:
- 在模式的狀態下創建表 - 就是創表的時候指定模式:
- 1.創建表給出模式名:
- CREATE TABLE "ST-T".Studnet(...); // Student所屬的模式是S-T
- CREATE TABLE "ST-T".Course(...); // Course所屬的模式是S-T - 後需還可以往模式中添加表,一個模式可以有若幹個基本表(前面有說)
- CREATE TABLE "ST-T".SC(...); // SC所屬的模式是S-T
- 2.在創建模式語句中同時創建表:
-
3.設置所屬模式,在創建表中不必給出模式名(就是設置它的搜索路徑)
-
修改基本表:
-
語法:
- CASCADE - 級聯刪除,使用該操作自動刪除引用了該列的其它對象
- RESTRICT -限制刪除,使用該操作如果該列被其它對象引用,就會拒絕刪除該列
- ALTER COLUMN - 用於修改原有的列定義,包括修改列名和數據類型
-

-
例子:
-

-
-
刪除基本表:
-
語法:DROP TABLE <表名>[RESTRICT| CASCADE];
- 基本表定義被刪除,數據被刪除,表上建立的索引、視圖、觸發器等一般也將被刪除
-
RESTRICT:刪除表是有限制的,欲刪除的基本表不能被其他表的約束所引用
如果存在依賴該表的對象,則此表不能被刪除 -
CASCADE:刪除該表沒有限制。
在刪除基本表的同時,相關的依賴對象一起刪除 -
例子:
-

-
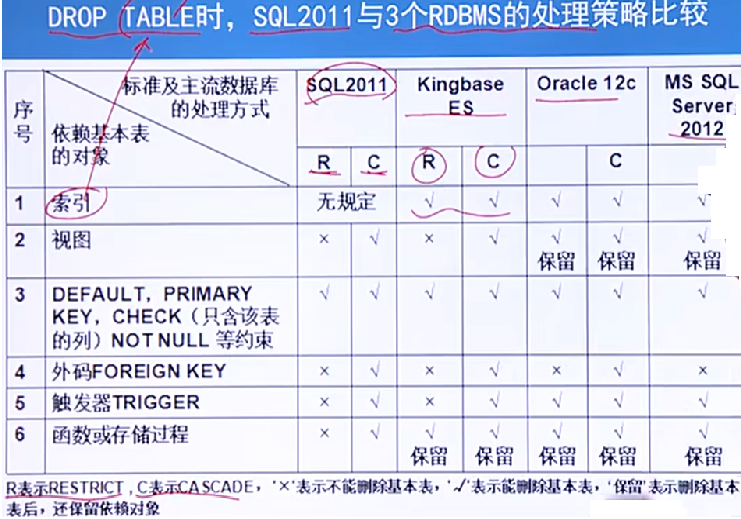
不同資料庫處理的策略:
-
-
-
-
3.3.3 索引的創建和刪除:
-
建立索引的目的:加速查詢速度
-
誰可以建立索引:DBA或表的屬主(建表人)
-
DMBS一般會自動建立以下列上的索引(相當於有下麵關鍵字的自動加到目錄):
-
PRIMARY KEY;
-
UNIQUE;
-
-
誰維護索引:DMBS自動完成
-
使用索引:DMBS自動執行是否使用索引及使用哪些索引
-
R(R表示關係資料庫)DBMS中索引一般採用B+樹、HASH索引來實現
-
B+樹索引具有動態平衡的優點
HASH索引具有查找速度快的特點
採用B+樹,還是HASH索引 則由具體的RDBMS來決定 -
索引是關係資料庫的內部實現技術,屬於內模式的範疇
-
CREATE INDEX 語句定義索引時,可以定義索引是唯一索引、非唯一索引(如:年齡,年齡可能就是會重覆)或聚簇索引
-
建立索引:
-
語句:CREATE [UNIQUE(唯一索引)] [CLUSTER(聚簇索引)] INDEX <索引名>
ON <表名>(<列名>[<次序>][,<列名>[<次序>] ]…); - 不寫大括弧裡面的索引,就是非唯一索引
-
- 建立唯一索引例子:
-

-
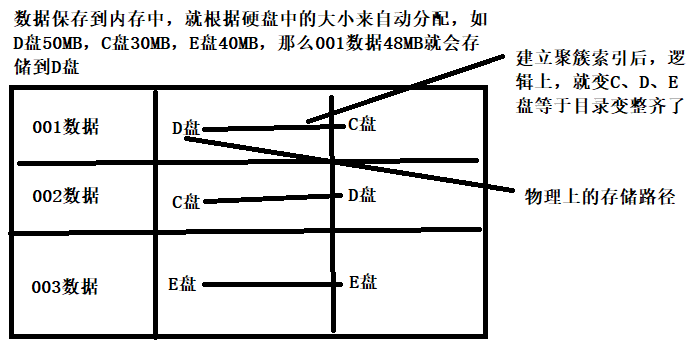
建立聚簇索引例子:
- 什麼是聚簇索引:數據搜索到電腦中
-




-
- 刪除索引:
- 語句:DROP INDEX<索引名>;
- 刪除索引時,系統會從數據字典中刪去有關該索引的描述
- 例:刪除Student表的Stusname索引
- DROP INDEX Stusname;
- 數據字典: - 和新華字典一樣記錄了所有數據
- 數據字典是關係資料庫管理系統內部的一組系統表,它記錄了資料庫中所有的定義信息,包括關係模式定義、視圖定義、索引定義、完整性約束定義、各類用戶對資料庫的操作許可權、統計信息等。
- 關係資料庫管理系統在執行SQL的數據定義語句時,實際上就是在更新數據字典表中的相應信息。
- 在進行查詢優化和查詢處理時,數據字典中的信息是其重要依據
- 刪除索引:
3.4 數據查詢:
- 語句:
-
/* SELECT - 查詢 all - 顯示所有 distinct - 顯示不同的(去重) from - 去哪個表查 where - 條件 group by - 分組 order by - 排序 */ SELECT [ALL | DISTINCT ]<目標列表達式>[,<目標列表達式>]... FROM<表名或視圖名>[,<表名或視圖名>...] | (<SELECT語句>)[AS]<別名> [WHERE<條件表達式>] [GROUP BY<列名1>[HAVING<條件表達式>]] [ORDER BY<列名2>[ASC | DESC]]
-
- 細節:
- 語句中的字母不分大小寫
- 語句中的符號都為業務狀態下的
- [ ]中的內容,不是語句必須內容,需要該功能在添加
-
3.4.1 單表查詢:
- 什麼是單表查詢?只對一個表的內容進行查詢
- 查詢表中的若幹列:
- 查詢指定列:
-
/* 查詢全體學生的學號和姓名 */ SELECT son,sname FROM Student;
-
查詢表中全部列:
-
/* 查詢全體學生的詳細記錄 */ SELECT * FROM Student;
-
選擇經過計算的值:
-
作用:選出表中指定的屬性列,經過計算後輸出
-
格式:SELECT字語句的<目標列表達式>可以為:算數表達式、字元串常量、函數、列別名
-
例: 註意表格的名字
-
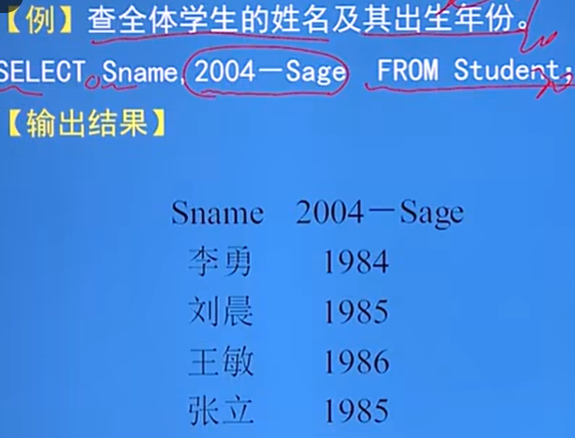
- 例:函數的使用,不存在列,輸出到表格
-

-
例:別名的使用
-
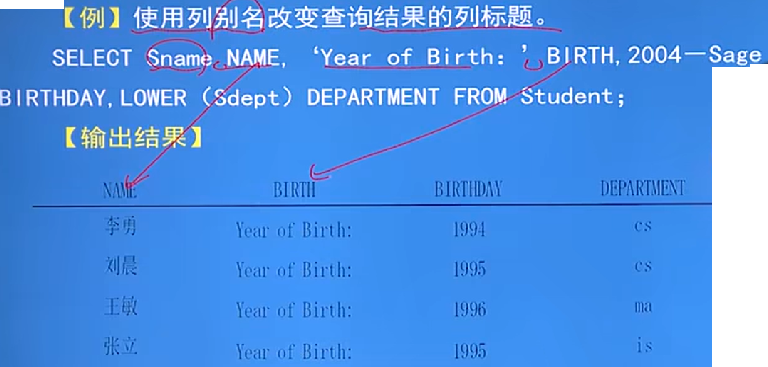
-
-
選擇表中的若幹元組:
-
消除取值重覆的行(去重):
-
兩個關鍵字:DISTINCT(顯示去重後的)和ALL(顯示所有),不寫關鍵字預設是ALL
-
例:
-

-
-
查詢滿足條件的元組:
-
通過關鍵字where子句實現
-
操作符 說 明 = 等於 <> 不等於 != 不等於 < 小於 <= 小於等於 !< 不小於 > 大於 >= 大於等於 !> 不大於 BETWEEN , NOT BETWEEN 在指定的兩個值之間 ,不在指定訪問的值 IS NULL, IS NOT NILL 為NULL的值, 不為NULL的值
AND,OR,NOT 並且 ,或者,反;不是
-
例子:比較大小
-

-
例子:確定範圍
-
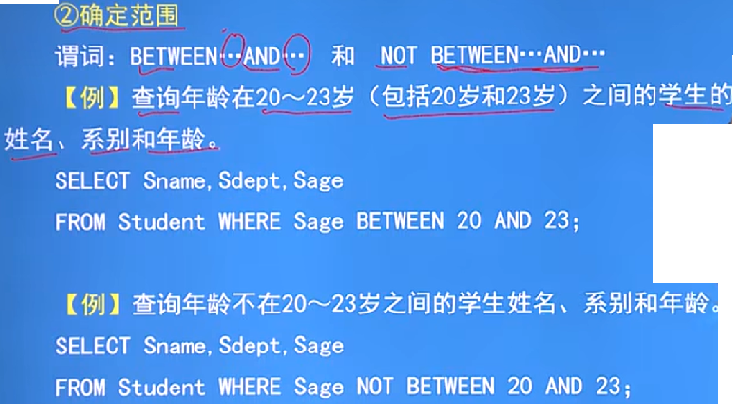
-
例子:確定集合
-

- 例子:字元匹配

-
-
例子:匹配串為含通配符的字元串
-
%表示任意長度的字元串
-
_ ,下斜線表示任意單個字元
-
-

-
例子:使用換碼字元串將通配符轉義為普通字元
-
ESCAPE '<換碼字元>' - 如:查詢的字元串中有& _ 這些特殊字元時,可以通過轉碼讓它轉為字元
-
-

-
例子:涉及空值的查詢
-
IS NULL或IS NOT NULL, "IS" 不能用“=”代替
-

-
-
例子:多重條件查詢
-
AND和OR來聯結多個查詢條件,AND的優先順序高於OR,可以用括弧來改變優先順序
-
有時候可以用:[NOT] IN 或 [NOT] BETWEEN ... AND ...
-
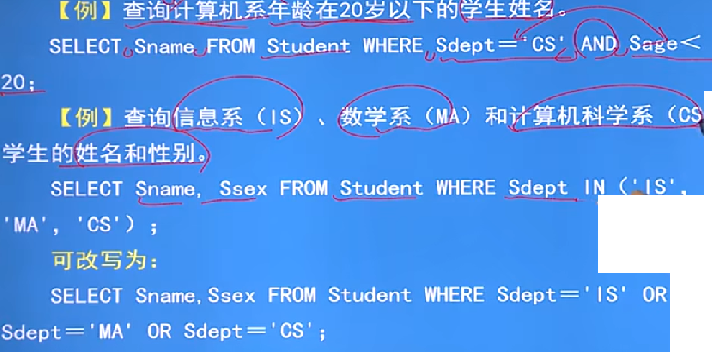
-
-
例子:ORDER BY子句(排序)
-
ORDER BY 子句可以按一個或多個屬性列排序
-
升序:ASC; 降序:DESC; - 預設是升序
-
空值預設是最大值
-
ASC:排序列為空值的元組最後顯示
-
DESC:排序列為空值的元組最先顯示
-

-
-
聚集函數
- COUNT ( * ) 統計元組(行)個數
- COUNT ( [ DISTINCT | ALL ] <列名> ) 統計一列中的值的個數
- SUM( [ DISTINCT | ALL ] <列名> ) 計算一列值的總和(該列必須是數組型)
- AVG( [ DISTINCT | ALL ] <列名> ) 計算一列值的平均值(該列必須是數組型)
- MAX( [ DISTINCT | ALL ] <列名> ) 求一列中的最大值
- MIN( [ DISTINCT | ALL ] <列名> ) 求一列中的最效值
- 細節:WHERE子句中不能使用聚集函數作為條件表達式,只能在SELECT和GROUPBY的HAVING子句中

-
GRIOUP BY子句(分組)
-
GRIOUP BY子句作用:按指定的一列或多列值分組,值相等的為一組,來細化聚集函數的作用對象
-
細節:
-
未對查詢結果分組,聚集函數將作用於整個查詢結果
-
對查詢結果分組,聚集函數將分別作用於每個組
-
語
-
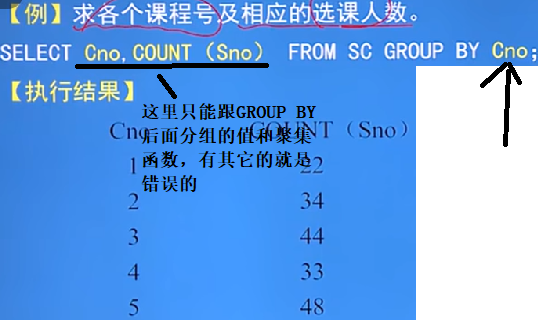
-
-
HAVING語句
-
GROUP BY子句分組後,可以使用HAVING語句指定篩選條件
-
細節:
-
HAVING是和GROUP BY語句連在一起的,作用在分組對象中
-
-

-
-
HAVING短句與WHERE子句的區別
-
HAVING是和GROUP BY語句連在一起的,作用在分組對象中
-
WHERE是作用在整個查詢對象中
-
作用對象不同:WHERE子句作用於基表或視圖,從中選擇滿足條件的元組。HAVING短語作用於組,從中選擇滿足條件的元組
-
WHERE子句中是不能用聚集函數作為條件表達式的
-

-
-
-
3.4.2 連接查詢:
- 等值連接與非等值連接查詢:
- 連接查詢的WHERE子句中用來連接兩個表的條件稱為連接條件或連接謂詞
-
等值連接:當連接運算符為=時,稱為等值連接
-
非等值連接:所以非=符號時,稱為非等值連接
-
細節:
-
連接謂詞中的列名稱為連接欄位,並且各連接欄位必須是可比的,但名字不必相同
- 運算符有:= > < >= <= != <>等
-
-
例:
-
- 等值連接與非等值連接查詢:
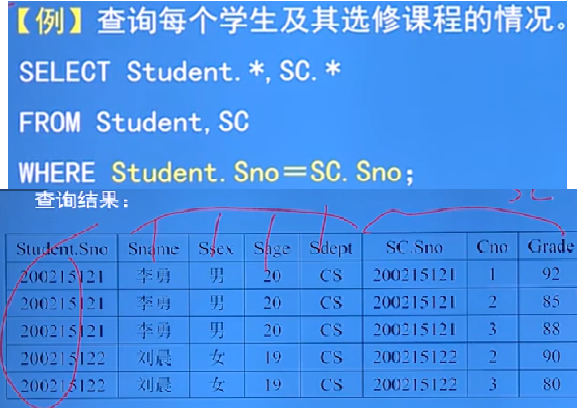
-
- 例的執行過程:首先在Student表中拿出第一個Sno學號和Sc表中的所有Sno學號做比較,只要是和Student的Sno相同的就和成一個新的元組,
以此類推,拼接得到的表不是真實存在的,隨著查詢的結束而結束
-
-
自然連接:
- 若在等中連接中把目標列中重覆的屬性列去掉則稱自然連接(就是有重覆的屬性或列,就去重)

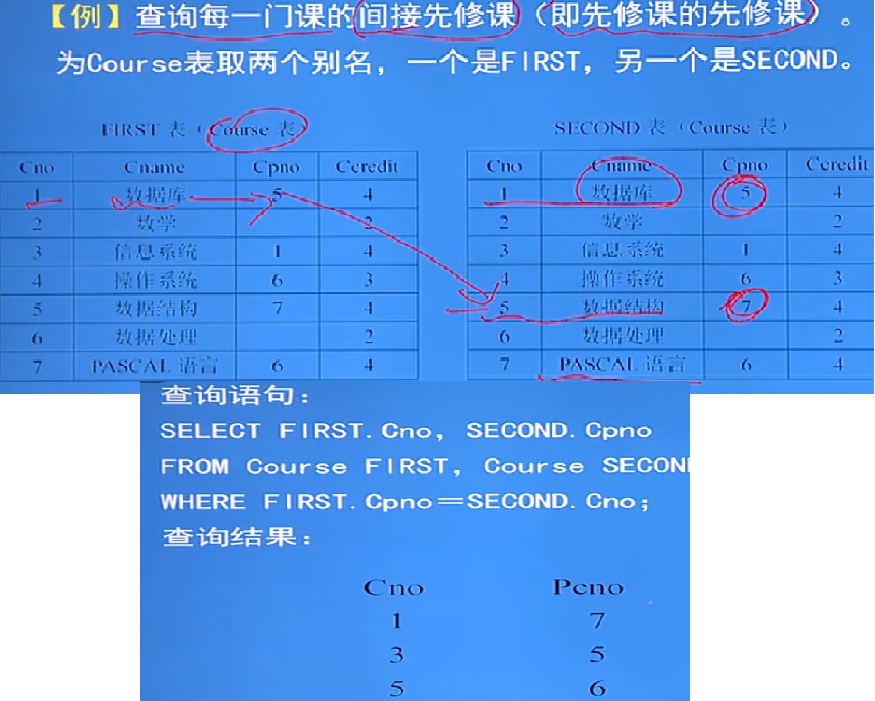
- 自身連接:
- 一個表與其自己進行連接
- 細節:
- 都是同一個表連接,怎麼讓這兩個表區分? 起別名
- 由於屬性名都是同名屬性,因此必須使用別名來區分
-
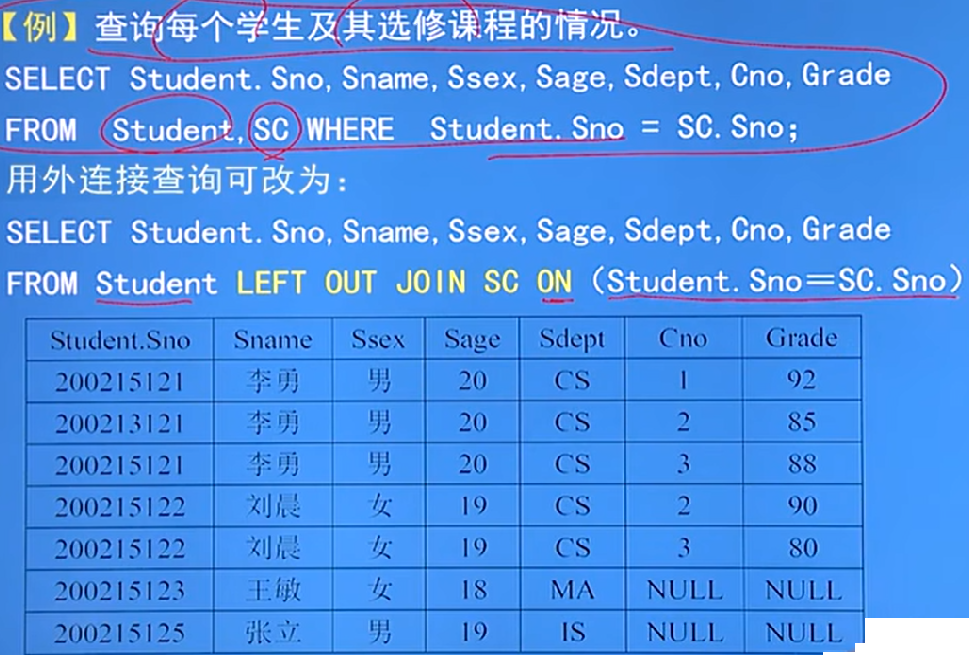
外連接:
- 就是把不要的懸浮元組也加到表裡面
- 普通連接和外連接的區別:
- 普通連接操作只輸出滿足連接條件的元組
- 外連接操 接主體,將主體表中的不符合條件的元組一併輸出
- 外連接分為:
- 左連接為:列出左邊關係中的所有元組
- LEFT OUT JOIN SC ON
- 右連接為:列出右邊關係中的所有元組
- RIGHT OUT JOIN SC ON
- 左連接為:列出左邊關係中的所有元組
- 例:
-
多表連接:
-
連接操作是流量以上的表進行連接
-
-
例: - 下麵用到了三個表
-
-
-
3.4.3 嵌套查詢:
-
一個SELECT-FROM-WHERE語句陳為一個查詢塊
-
嵌套查詢定義:是指將一個查詢塊嵌套在另一個查詢塊的WHERE子句或HAVING短語的條件中的查詢
-
理解:就是將新的查詢語句嵌套在已有的查詢語句中的WHERE或HAVLNG中,其它地方不能嵌套
-
-
細節;
-
子查詢中不能使用ORDER BY子句
-
層層嵌套方式反映來哦SQL語言的結構化
-
有些嵌套查詢可以用連接運算代替
-
外層查詢叫:父查詢,內層查詢叫:子查詢
-
父查詢裡面嵌套子查詢,子程式裡面還可以嵌套子查詢
-
不相關子查詢:子查詢的查詢條件不依賴父查詢(看案例)
-
相關子查詢:子查詢的查詢條件依賴於父查詢,整個語句稱為嵌套查詢(看案例)
-
-
例:
-
-
帶有IN謂詞的子程查詢:
-

-

-
例子2:
-

-
-
帶有比較運算符的子查詢:
-
當確切知道內層返回的是單個值時,可以用 >、<、=、>=、<=、!=或<>等運算符
-
例1:
-

-
例2:
-
例子執行流程:1.x表的第一個Son和y表的每一個Son進行比較,和x的Son一樣的就進行表拼接,依此類推
-
2.得到拼接的表,然後通過函數AVG去求X的Son和y的Son拼接表的平均成績,和X表的成績進行比較,大於就顯示學號
-
-

-
-
帶有ANY(SOME不同的系統可能使用這個)或ALL謂詞的子查詢:
-
ANY - - 任意一個值
-
ALL - - 所以值
-
ANY和ALL需要配合比較運算符使用
-

-
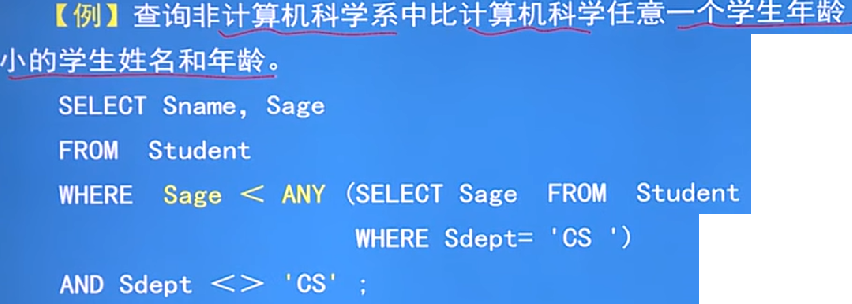
例子: - 執行過程 :先執行子查詢,找出電腦科學的的所有人年齡得到一個集合(xx,xx),然後執行父查詢不是電腦系的年齡,然後和子程查詢的集合比較
-
-

-

-
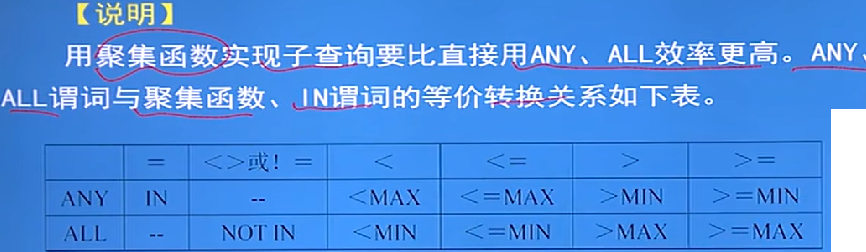
細節: - =ANY等價於IN謂詞,<ANY等價於<MAX,<>ALL等價於NOT IN謂詞,<ALL等價於<MIN,等等
-
-
帶有EXISTS謂詞的子查詢:
-
EXISTS謂詞:代表存在量詞∃,帶有EXUISTS謂詞的子查詢,不返回任何數據,只產生邏輯真值"true",或邏輯假值"false"
-
存在量詞:存在,有些,有一個,至少有一個,存在一個,對某一個,對有些,對某些,有的等
-
-
例:查詢所有選修了1號課程的學生姓名
-
思路:需要Student和SC表,通過Student中Son去確定SC中選了課的學生的Sno,並且通過條件AND判斷,課程號為1的
-
-
細節1:所有存在量詞EXISTS後,如若內層查詢結果非空,則外層的WHERE子句返回真值,否則返回假值
-
細節2:由EXISTS引出的子查詢,select後通過用*,因為EXISTS返回的只有真和假,用列名沒有意義
-

-
-
NOT EXISTS謂詞的子查詢:
-
若內查詢結果非空,外層WHERE子句返回假值
-
若內查詢結果為空,外層WHERE子句返回真值
-
例子:思路:內層查詢,查詢出所有選擇了1號課程的學生,通過NOT EXISTS返回沒選擇的學生就是真
-

-
-
不同形式的查詢間的替換:
-
一些帶EXISTS或NOT EXISTS謂詞的子程式不能本其他形式的子程式等價替換
-
所有帶IN謂詞、比較運算符、ANY和ALL謂詞的子查詢都能用帶EXISTS謂詞的子程式等價替換
-
理解:如IN和ALL的目的就是表達查詢結果集裡面所有的值,那EXISTS表示真假,就可以完美代替
-
-
例:思路:內查詢S2表想S1表進行自身連接查詢,當S2中的系和S1中的系對應上,並且S2表中的名字是劉晨,返回真(不理解畫圖)
-

-
-
用EXISTS/NOT EXISTS實現全稱量詞:
-
全稱量詞:一切、每一個、任意
-
SQL語言中是沒有全稱量詞語的,但可以通過存在量詞轉為全稱量詞
-
例:
-

-
-
用EXISTS/NOT EXISTS實現邏輯蘊涵:
-
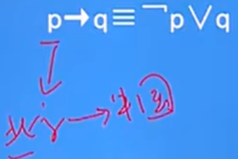
邏輯蘊涵:我來過北京代表我來過中國,我來過中國不代表去過北京
- SQL語言中沒有蘊涵邏輯運算,可以利用謂詞演算將邏輯蘊涵謂詞等價轉換
-
-

-
-
-
-
3.4.4 集合查詢:
- 什麼是集合查詢?SELECT語句的查詢結果是元組的集合,所以多個的SELECT語句的結果可以進行集合查詢
- 集合查詢種類:
- 並操作(操作關鍵字:UNLON):第一個查詢出來的集合是1234,第二個是456,並起來就是123456,是去重的
- UBLON - 是去重的, 如果是:UNLON ALL 是保留重覆結果
- 交操作(操作關鍵字:INTERSECT):第一個查詢出來的集合是489,第二個是456,交就是4
- 差操作(操作關鍵字:EXCEPT):第一個查詢出來的集合是1234,第二個是23,差就是在第一個集合里,不在第二個集合里,那麼就是14
- 細節:參加集合操作的各查詢結果的列數(一列的的數)必須相同,對應的數據類型也必須相同
- 並操作(操作關鍵字:UNLON):第一個查詢出來的集合是1234,第二個是456,並起來就是123456,是去重的
- 並操作例子:
-
交操作例子:
-
-
差操作例子:
-

-
3.4.5 基於派生表的查詢:
-
在from語句中,成為主存在的子查詢叫派生表
- 細節:派生表(子查詢)必須取一個別名,如果沒有使用聚集函數,使用預設的,如果使用了需要指定屬性列
-

-
-
3.4.6 SELECT語句的一般格式:
-







3.5數據更新:
- 什麼是數據更新?就是如何插入數據、修改數據、刪除數據
-
3.5.1 插入數據:
- 什麼是插入數據?在一個表中插入一個新的,元組、一個查詢結果、多個元組


