
正則表達式01 5.1正則表達式的作用 正則表達式的便利 在一篇文章中,想要提取相應的字元,比如提取文章中的所有英文單詞,提取文章中的所有數字等。 傳統方法是:使用遍歷的方式,對文本中的每一個字元進行ASCII碼的對比,如果ASCII碼處於英文字元的範圍,就將其截取下來,再看後面是否有連續的字元,將 ...
正則表達式01
5.1正則表達式的作用
正則表達式的便利
在一篇文章中,想要提取相應的字元,比如提取文章中的所有英文單詞,提取文章中的所有數字等。
- 傳統方法是:使用遍歷的方式,對文本中的每一個字元進行ASCII碼的對比,如果ASCII碼處於英文字元的範圍,就將其截取下來,再看後面是否有連續的字元,將連續的字元拼接成一個單詞。這種方式代碼量大,且效率不高。
- 使用正則表達式
package li.regexp;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
//體驗正則表達式的便利
public class Regexp_ {
public static void main(String[] args) {
//假設有如下文本
String content = "1995年,互聯網的蓬勃發展給了Oak機會。業界為了使死板、單調的靜態網頁能夠“靈活”起來," +
"急需一種軟體技術來開發一種程式,這種程式可以通過網路傳播並且能夠跨平臺運行。於是,世界各大IT企" +
"業為此紛紛投入了大量的人力、物力和財力。這個時候,Sun公司想起了那個被擱置起來很久的Oak,並且" +
"重新審視了那個用軟體編寫的試驗平臺,由於它是按照嵌入式系統硬體平臺體繫結構進行編寫的,所以非常" +
"小,特別適用於網路上的傳輸系統,而Oak也是一種精簡的語言,程式非常小,適合在網路上傳輸。Sun公" +
"司首先推出了可以嵌入網頁並且可以隨同網頁在網路上傳輸的Applet(Applet是一種將小程式嵌入到網" +
"頁中進行執行的技術),並將Oak更名為Java。5月23日,Sun公司在Sun world會議上正式發佈Java和" +
"HotJava瀏覽器。IBM、Apple、DEC、Adobe、HP、Oracle、Netscape和微軟等各大公司都紛紛停止" +
"了自己的相關開發項目,競相購買了Java使用許可證,併為自己的產品開發了相應的Java平臺。";
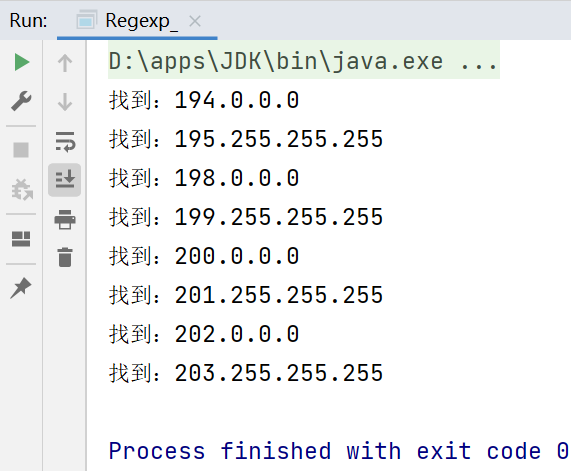
String content2 = "無類域間路由(CIDR,Classless Inter-Domain Routing)地址根據網路拓撲來分配,可以" +
"將連續的一組網路地址分配給一家公司,並使整組地址作為一個網路地址(比如使用超網技術),在外部路由表上" +
"只有一個路由表項。這樣既解決了地址匱乏問題,又解決了路由表膨脹的問題。另外,CIDR還將整個世界分為四" +
"個地區,給每個地區分配了一段連續的C類地址,分別是:歐洲(194.0.0.0~195.255.255.255)、北美(19" +
"8.0.0.0~199.255.255.255)、中南美(200.0.0.0~201.255.255.255)和亞太(202.0.0.0~203.2" +
"55.255.255)。這樣,當一個亞太地區以外的路由器收到前8位為202或203的數據報時,它只需要將其放到通向亞" +
"太地區的路由即可,而對後24位的路由則可以在數據報到達亞太地區後再進行處理,這樣就大大緩解了路由表膨脹的問題";
//正則表達式來完成
// (1)先創建一個Pattern對象,模式對象,可以理解成就是一個正則表達式對象
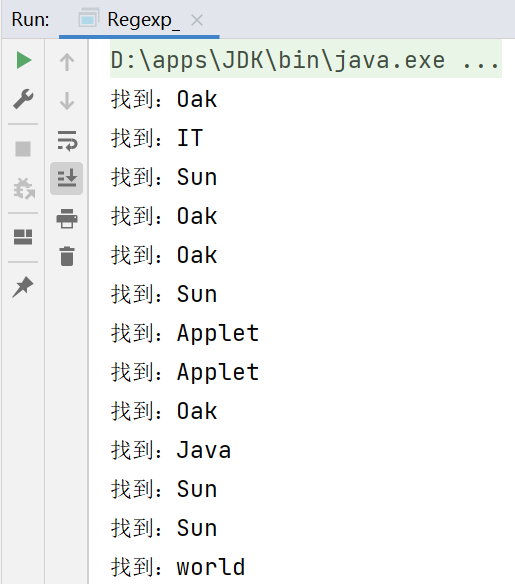
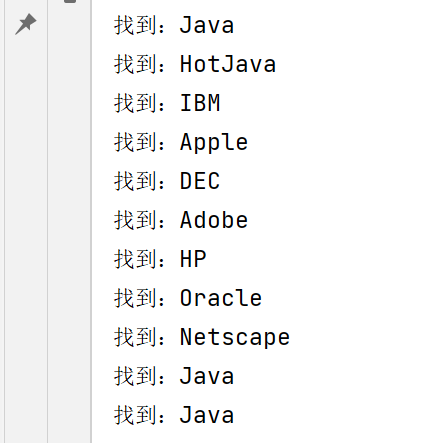
//Pattern pattern = Pattern.compile("[a-zA-Z]+");//提取文章中的所有英文單詞
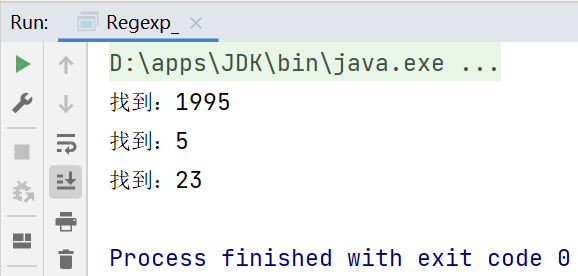
//Pattern pattern = Pattern.compile("[0-9]+");//提取文章中的所有數字
//Pattern pattern = Pattern.compile("([0-9]+)|([a-zA-Z]+)");//提取文章中的所有的英文單詞和數字
Pattern pattern = Pattern.compile("\\d+\\.\\d+\\.\\d+\\.\\d+");//提取文章中的ip地址
// (2)創建一個匹配器對象
// 理解:就是 matcher 匹配器按照pattern(模式/樣式),到content文本中去匹配
// 找到就返回true,否則就返回false(如果返回false就不再匹配了)
Matcher matcher = pattern.matcher(content2);
// (3)可以開始迴圈匹配
while (matcher.find()) {
//匹配到的內容和文本,放到 m.group(0)
System.out.println("找到:" + matcher.group(0));
}
}
}
提取所有英文單詞:
提取所有數字:
提取ip地址:
正則表達式是處理文本的利器
- 再提出幾個問題
- 在程式中如何驗證用戶輸入的郵件信息是否符合電子郵件的格式?
- 如何驗證輸入的電話號碼是符合手機號格式?
為瞭解決上述問題,java提供了正則表達式技術(regular expression / regexp),專門用於處理類似的文本問題。簡單地說,正則表達式是對字元串執行 模式匹配 的技術。
5.2基本介紹
- 介紹
-
一個正則表達式,就是用某種模式去匹配字元串的一個公式。
它們看上去奇怪而複雜,但經過練習後,你就會發現這些複雜的表達式寫起來還是相當簡單的。而且,一旦弄懂它們,就能將數小時辛苦而且容易出錯的文本處理工作縮短在幾分鐘甚至幾秒內完成。
-
正則表達式不是java獨有的,實際上很多編程語言都支持正則表達式進行字元串操作,且它們的匹配規則大同小異。
5.3底層實現
實例分析:
給出一段字元串文本,請找出所有四個數字連在一起的子串===>分析底層實現
package li.regexp;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
//分析java的正則表達式的底層實現**
public class RegTheory {
public static void main(String[] args) {
String content="1998年12月8日,第二代Java平臺的企業版J2EE發佈。1999年6月,Sun公司發佈了" +
"第二代Java平臺(簡稱為Java2)的3個版本:J2ME(Java2 Micro Edition,Java2平臺的微型" +
"版),應用於移動、無線9889+及有限資源的環境;J2SE(Java 2 Standard Edition,Java 2平臺的" +
"標準版),應用於桌面環境;J2EE(Java 2Enterprise Edition,Java 2平臺的企業版),應" +
"用於基於Java的應用伺服器。Java 2平臺的發佈,是Java發展過程中最重要的一個裡程碑,標志著J" +
"ava的應用開始普及。3443";
//請找出所有四個數字連在一起的子串
//說明:
// 1.\\d表示一個任意的數字
String regStr="\\d\\d\\d\\d";
//2.創建一個模式對象
Pattern pattern = Pattern.compile(regStr);
//3.創建匹配器
//說明:創建匹配器matcher,按照前面寫的 正則表達式的規則 去匹配 content字元串
Matcher matcher = pattern.matcher(content);
//4.開始匹配
while (matcher.find()){
System.out.println("匹配:"+matcher.group(0));
}
}
}
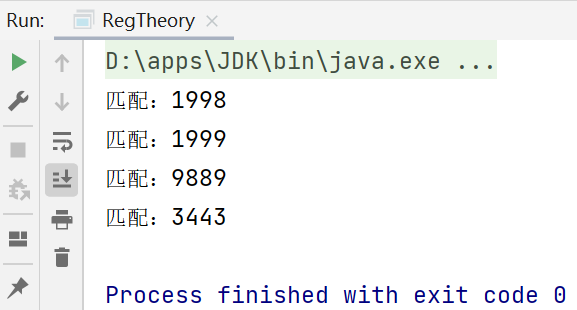
5.3.1match.find()
- match.find()完成的任務:
-
根據指定的規則,定位滿足規則的子字元串(比如1998)
-
找到後,將"1998"子字元串開始的索引記錄到 matcher對象的屬性 int[] groups數組中的groups[0];把該子串的結束索引再+1的值記錄到 groups[1]
此時groups[0]=0,groups[1]=4
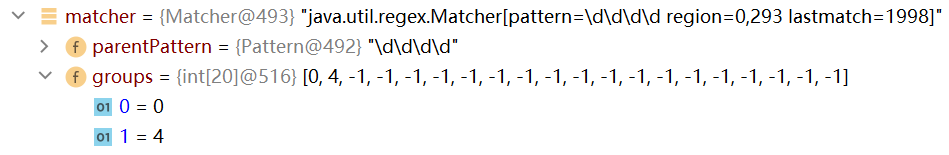
-
同時記錄oldLast的值為 子串的結束索引+1 即4,這樣做的原因是:下次執行find方法時,就從該下標4開始匹配

5.3.2matcher.group(0)
//源碼:
public String group(int group) {
if (first < 0)
throw new IllegalStateException("No match found");
if (group < 0 || group > groupCount())
throw new IndexOutOfBoundsException("No group " + group);
if ((groups[group*2] == -1) || (groups[group*2+1] == -1))
return null;
return getSubSequence(groups[group * 2], groups[group * 2 + 1]).toString();
}
根據傳入的參數group=0,計算groups[0 * 2] 和 groups[0 * 2 + 1] 的記錄的位置,從content截取子字元串返回
此時groups[0]=0,groups[1]=4,註意:截取的位置為[0,4) ,包含 0 但是不包含索引為 4 的位置
-
如果再次指向find方法,仍然按照上面的分析去執行:
比如下一個匹配的子字元串是“1999”,首先,將該字元串的開始索引的值,以及結束索引加1的值記錄到matcher屬性的groups數組中(會先將上次存儲在groups數組中的數值清空)
然後記錄oldLast的值為 子串的結束索引+1,下次執行find方法時,就從該下標35開始匹配
groups[0]=31,groups[1]=35,oldLsat=35
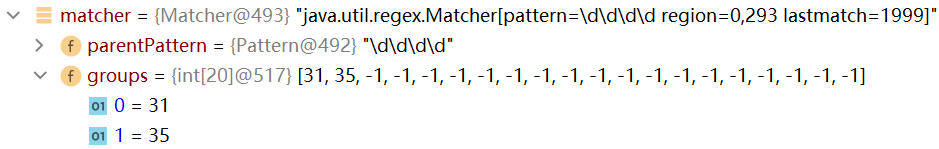
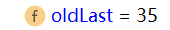
然後執行matcher.group(0)方法,根據傳入的參數group=0,計算groups[0 * 2] 和 groups[0 * 2 + 1] 的記錄的位置,即[31,35),從content截取子字元串返回
5.3.3分組
什麼是分組?
在正則表達式中有括弧(),表示分組,第一個括弧()表示第一組,第二個括弧()表示第二組....
實例代碼:
package li.regexp;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
//分析java的正則表達式的底層實現**
public class RegTheory {
public static void main(String[] args) {
String content="1998年12月8日,第二代Java平臺的企業版J2EE發佈。1999年6月,Sun公司發佈了" +
"第二代Java平臺(簡稱為Java2)的3個版本:J2ME(Java2 Micro Edition,Java2平臺的微型" +
"版),應用於移動、無線及9889有限資源的環境;J2SE(Java 2 Standard Edition,Java 2平臺的" +
"標準版),應用於桌面環境;J2EE(Java 2Enterprise Edition,Java 2平臺的企業版),應" +
"用於基於Java的應用伺服器。Java 2平臺的發佈,是Java發展過程中最重要的一個裡程碑,標志著J" +
"ava的應用開始普及。3443";
//請找出所有四個數字連在一起的子串
//說明:
// 1.\\d表示一個任意的數字
String regStr="(\\d\\d)(\\d\\d)";
//2.創建一個模式對象
Pattern pattern = Pattern.compile(regStr);
//3.創建匹配器
//說明:創建匹配器matcher,按照前面寫的 正則表達式的規則 去匹配 content字元串
Matcher matcher = pattern.matcher(content);
//4.開始匹配
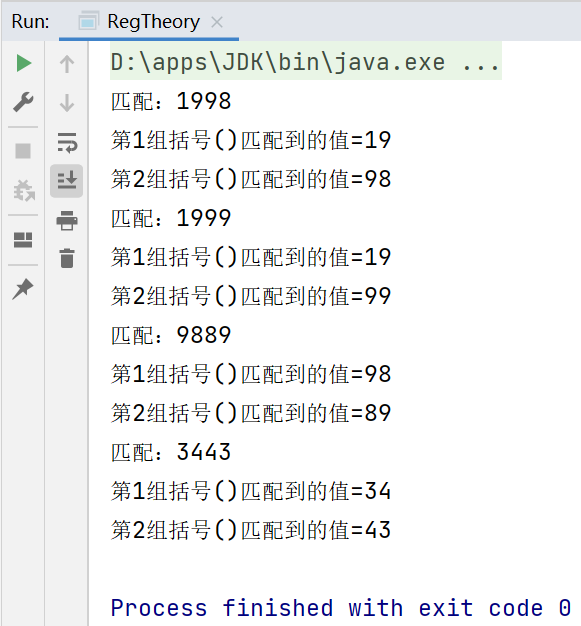
while (matcher.find()){
System.out.println("匹配:"+matcher.group(0));
System.out.println("第1組括弧()匹配到的值="+matcher.group(1));
System.out.println("第2組括弧()匹配到的值="+matcher.group(2));
}
}
}
以上面的代碼為例:
- match.find():
1.根據指定的規則,定位滿足規則的子字元串(比如"1998")
2.1找到後,將"1998"子字元串開始的索引位置記錄到 matcher對象的屬性 int[] groups數組中,把該子串的結束索引+1的值記錄到 groups[1] 中
此時 groups[0]=0 ;groups[1] = 4
2.2 記錄第一組括弧()匹配到的字元串("19")的位置 : groups[2]=0 , groups[3]=2
2.3 記錄第二組括弧()匹配到的字元串("98")的位置 : groups[4]=2 , groups[5]=4
如果有更多的分組就以此類推
索引下標是指:匹配的字元串在整文本或字元串中的位置,索引下標從0開始
驗證:
在程式中打上斷點,點擊debug調試:

可以看到剛開始時,groups數組的所有值都是-1
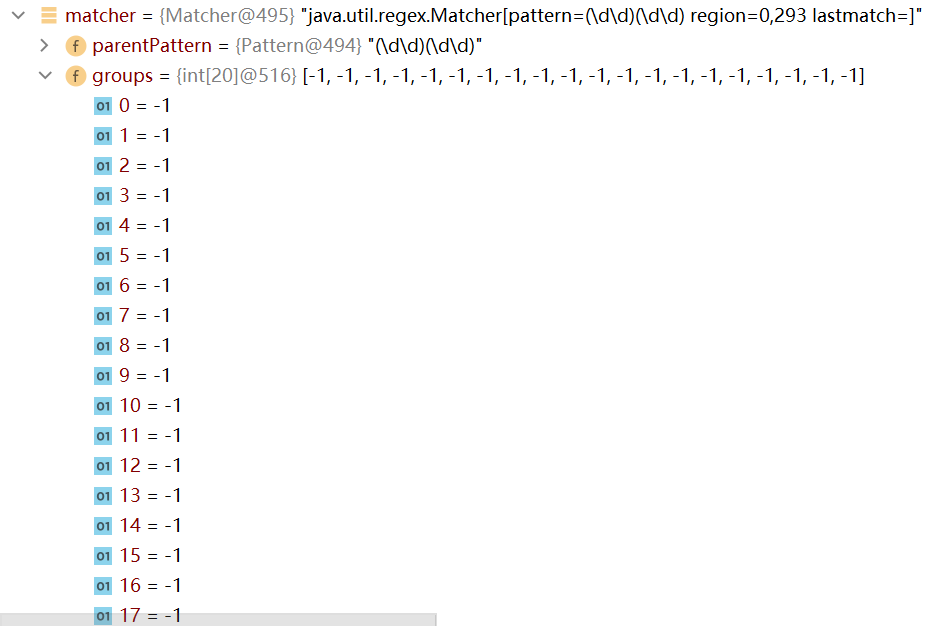
點擊step over,可以看到groups數組的變化如下:

//源碼:
public String group(int group) {
if (first < 0)
throw new IllegalStateException("No match found");
if (group < 0 || group > groupCount())
throw new IndexOutOfBoundsException("No group " + group);
if ((groups[group*2] == -1) || (groups[group*2+1] == -1))
return null;
return getSubSequence(groups[group * 2], groups[group * 2 + 1]).toString();
}
在源碼中,返回語句 return getSubSequence(groups[group * 2], groups[group * 2 + 1]).toString();
中,[group * 2] 和 [group * 2 + 1]計算的就是groups數組的下標位置
如果我們想要取出第一組括弧匹配的子字元串,即groups下標為[2]和[3],只需要將傳入的參數改為1即可
groups[1 * 2]=groups[2] , groups[1 * 2 + 1]=groups[3]
取出第二組括弧匹配的字元串同理,將傳入的參數改為2即可
groups[2 * 2]=groups[4] , groups[2 * 2 + 1]=groups[5]
小結:
- 如果正則表達式有括弧(),即分組
- 取出匹配的字元串規則如下:
matcher.group(0)表示匹配到的子字元串matcher.group(1)表示匹配到的子字元串的第1組字串matcher.group(2)表示匹配到的子字元串的第2組字串- 以此類推,註意分組的數不能越界
5.4正則表達式語法
-
基本介紹
如果想要靈活地運用正則表達式,必須瞭解其中各種元字元(Metacharacter)的功能,元字元從功能上大致分為:
- 限定符
- 選擇匹配符
- 分組組合和反向引用符
- 特殊字元
- 字元匹配符
- 定位符
5.4.1元字元-轉義符 \\\
\\符號的說明:在我們使用正則表達式去檢索某些特殊字元時,需要用到轉義符號\\,否則檢索不到結果,甚至會報錯。
註意:在Java的正則表達式中,兩個\\表示其他語言中的一個\
需要用到轉義符號的字元有如下:
. * + () $ / \ ? [] ^ {}
例子:
package li.regexp;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
//演示轉義字元的使用
public class RegExp02 {
public static void main(String[] args) {
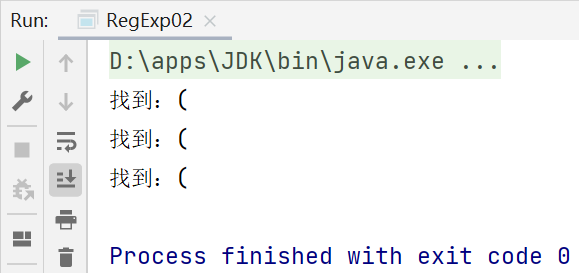
String content = "abc$(a.bc(123(";
//匹配 ( ==> \\(
//匹配 ( ==> \\.
//String regStr = "\\(";
String regStr = "\\.";
Pattern pattern = Pattern.compile(regStr);
Matcher matcher = pattern.matcher(content);
while (matcher.find()) {
System.out.println("找到:" + matcher.group(0));
}
}
}
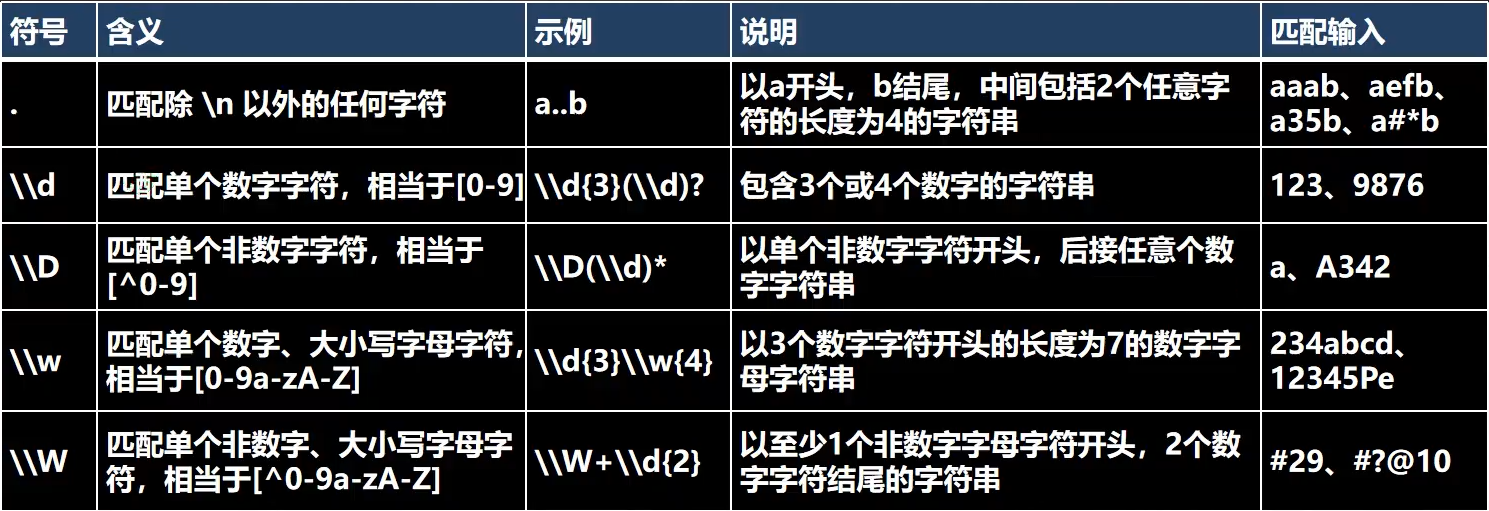
5.4.2元字元-字元匹配符

- 應用實例
-
[a-z]說明:[a-z]表示可以匹配 a-z 之間任意的一個字元[A-Z]表示可以匹配 A-Z 之間任意的一個字元[0-9]表示可以匹配 0-9 之間任意的一個字元比如[a-z]、[A-Z]去匹配“a11c8”會得到什麼結果?結果是:a、c
-
java正則表達式預設是區分大小寫的,如何實現不區分大小寫?
(?i)abc表示abc都不區分大小寫a(?i)bc表示bc不區分大小寫a((?i)b)c表示只有b不區分大小寫Pattern pattern = Pattern.compile(regStr,Pattern.CASE_INSENSITIVE);
-
[^a-z]說明:[^a-z]表示可以匹配不是a-z中的任意一個字元[^A-Z]表示可以匹配不是A-Z中的任意一個字元[^0-9]表示可以匹配不是0-1中的任意一個字元如果用 [^a-z]去匹配“a11c8”會得到什麼結果?結果:1、1、8
用 [^a-z]{2}又會得到什麼結果?結果是:11
-
[abcd]表示可以匹配abcd中的任意一個字元 -
[^abcd]表示可以匹配不是abcd中的任意一個字元 -
\\d表示可以匹配0-9的任意一個數字,相當於[0-9] -
\\D表示可以匹配不是0-9的任意一個數字,相當於[^0-9],即匹配非數字字元 -
\\w表示可以匹配任意英文字元、數字和下劃線,相當於[a-zA-Z0-9_] -
\\W相當於[^a-zA-Z0-9_],與\\w相反 -
\\s匹配任何空白字元(空格,製表符等) -
\\S匹配任何非空白字元,與\\s相反 -
.匹配除\n和\r之外的所有字元,如果要匹配.本身則需要使用\\
package li.regexp;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
//演示字元匹配符的使用
public class RegExp03 {
public static void main(String[] args) {
String content = "a1 1\r@c^8ab_c\nA BC\r\n";
//String regStr = "[a-z]";//匹配 a-z 之間任意的一個字元
//String regStr = "[A-Z]";//匹配 A-Z 之間任意的一個字元
//String regStr = "[0-9]";//匹配 0-9 之間任意的一個字元
//String regStr = "abc";//匹配 abc 字元串[預設區分大小寫]
//String regStr = "(?i)abc";//匹配 abc 字元串[不區分大小寫]
//String regStr = "[^a-z]";//匹配不在 a-z 之間任意的一個字元
//String regStr = "[^0-9]";//匹配不在 0-9 之間任意的一個字元
//String regStr = "[abcd]";//匹配在 abcd 中任意的一個字元
//String regStr = "\\D";//匹配不在 0-9 中的任意的一個字元[匹配非數字字元]
//String regStr = "\\w";//匹配任意英文字元、數字和下劃線
//String regStr = "\\W";//\[^a-zA-Z0-9_]
//String regStr = "\\s";//匹配任何空白字元(空格,製表符等)
//String regStr = "\\S";//匹配任何非空白字元
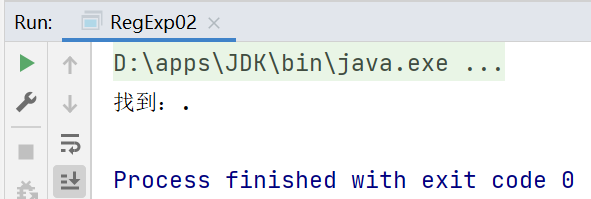
String regStr = ".";//.匹配除\n之外的所有字元,如果要匹配.本身則需要使用\\
//說明:當創建Pattern對象時,指定Pattern.CASE_INSENSITIVE,表示匹配是不區分字母大小寫的
//Pattern pattern = Pattern.compile(regStr,Pattern.CASE_INSENSITIVE);
Pattern pattern = Pattern.compile(regStr);
Matcher matcher = pattern.matcher(content);
while (matcher.find()) {
System.out.println("找到:" + matcher.group(0));
}
}
}
5.4.3元字元-選擇匹配符
在匹配某個字元串的時候是選擇性的,即:既可以匹配這個,又可以匹配那個,這時需要用到選擇匹配符號|

例子:
package li.regexp;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
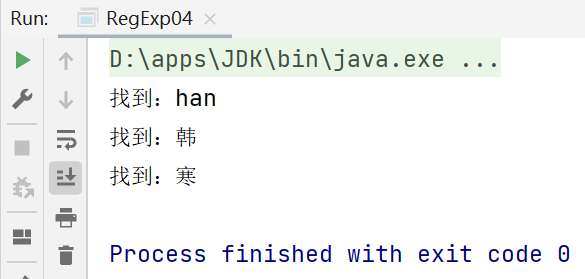
public class RegExp04 {
public static void main(String[] args) {
String content ="hangshunping 韓 寒冷";
String regStr="han|韓|寒";
Pattern pattern = Pattern.compile(regStr);
Matcher matcher = pattern.matcher(content);
while (matcher.find()) {
System.out.println("找到:" + matcher.group(0));
}
}
}
5.4.4元字元-限定符
用於指定其前面的字元和組合項連續出現多少次



