聲明 本文章中所有內容僅供學習交流使用,不用於其他任何目的,不提供完整代碼,抓包內容、敏感網址、數據介面等均已做脫敏處理,嚴禁用於商業用途和非法用途,否則由此產生的一切後果均與作者無關! 本文章未經許可禁止轉載,禁止任何修改後二次傳播,擅自使用本文講解的技術而導致的任何意外,作者均不負責,若有侵權, ...

聲明
本文章中所有內容僅供學習交流使用,不用於其他任何目的,不提供完整代碼,抓包內容、敏感網址、數據介面等均已做脫敏處理,嚴禁用於商業用途和非法用途,否則由此產生的一切後果均與作者無關!
本文章未經許可禁止轉載,禁止任何修改後二次傳播,擅自使用本文講解的技術而導致的任何意外,作者均不負責,若有侵權,請在公眾號【K哥爬蟲】聯繫作者立即刪除!
逆向目標
- 目標:某音網頁端用戶信息介面 X-Bogus 參數
- 介面:
aHR0cHM6Ly93d3cuZG91eWluLmNvbS9hd2VtZS92MS93ZWIvdXNlci9wcm9maWxlL290aGVyLw==
什麼是 JSVMP?
JSVMP 全稱 Virtual Machine based code Protection for JavaScript,即 JS 代碼虛擬化保護方案。
JSVMP 的概念最早應該是由西北大學2015級碩士研究生匡開圓,在其2018年的學位論文中提出的,論文標題為:《基於 WebAssembly 的 JavaScript 代碼虛擬化保護方法研究與實現》,同年還申請了國家專利,專利名稱:《一種基於前端位元組碼技術的 JavaScript 虛擬化保護方法》,網上可以直接搜到,也可在公眾號【K哥爬蟲】後臺回覆 JSVMP,免費獲取原版高清無水印的論文和專利。本文就簡單介紹一下 JSVMP,想要詳細瞭解,當然還是建議去讀一下這篇論文。

JSVMP 的核心是在 JavaScript 代碼保護過程中引入代碼虛擬化思想,實現源代碼的虛擬化過程,將目標代碼轉換成自定義的位元組碼,這些位元組碼只有特殊的解釋器才能識別,隱藏目標代碼的關鍵邏輯。在匡開圓的論文中,利用 WebAssembly 技術實現了特殊的虛擬解釋器,通過編譯隱藏解釋器的執行邏輯。JSVMP 的保護流程如下圖所示:
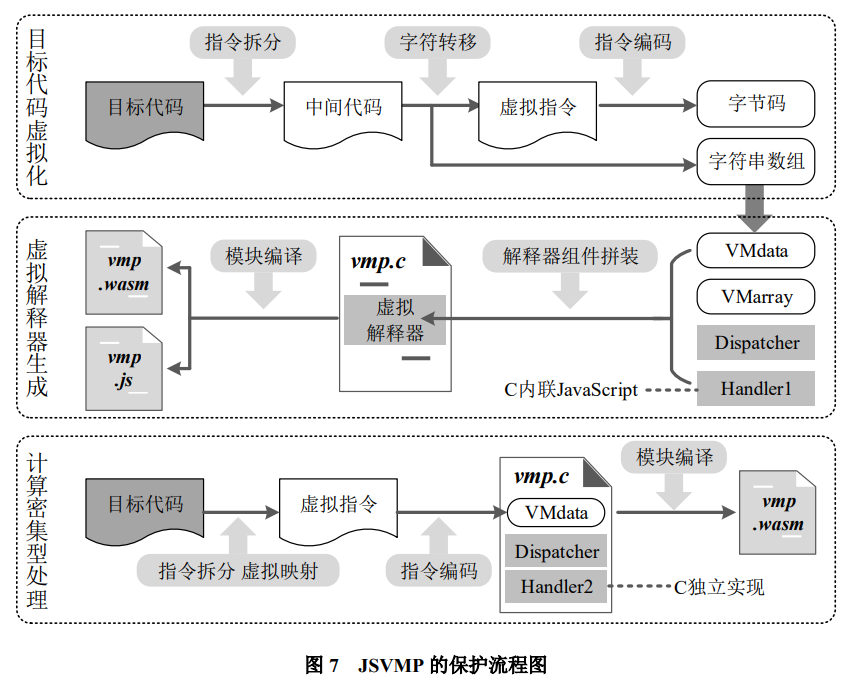
一個完整的 JSVMP 保護系統,大致的架構應該是這樣子的:伺服器端讀取 JavaScript 代碼 —> 詞法分析 —> 語法分析 —> 生成AST語法樹 —> 生成私有指令 —> 生成對應私有解釋器,將私有指令加密與私有解釋器發送給瀏覽器,然後一邊解釋,一邊執行。
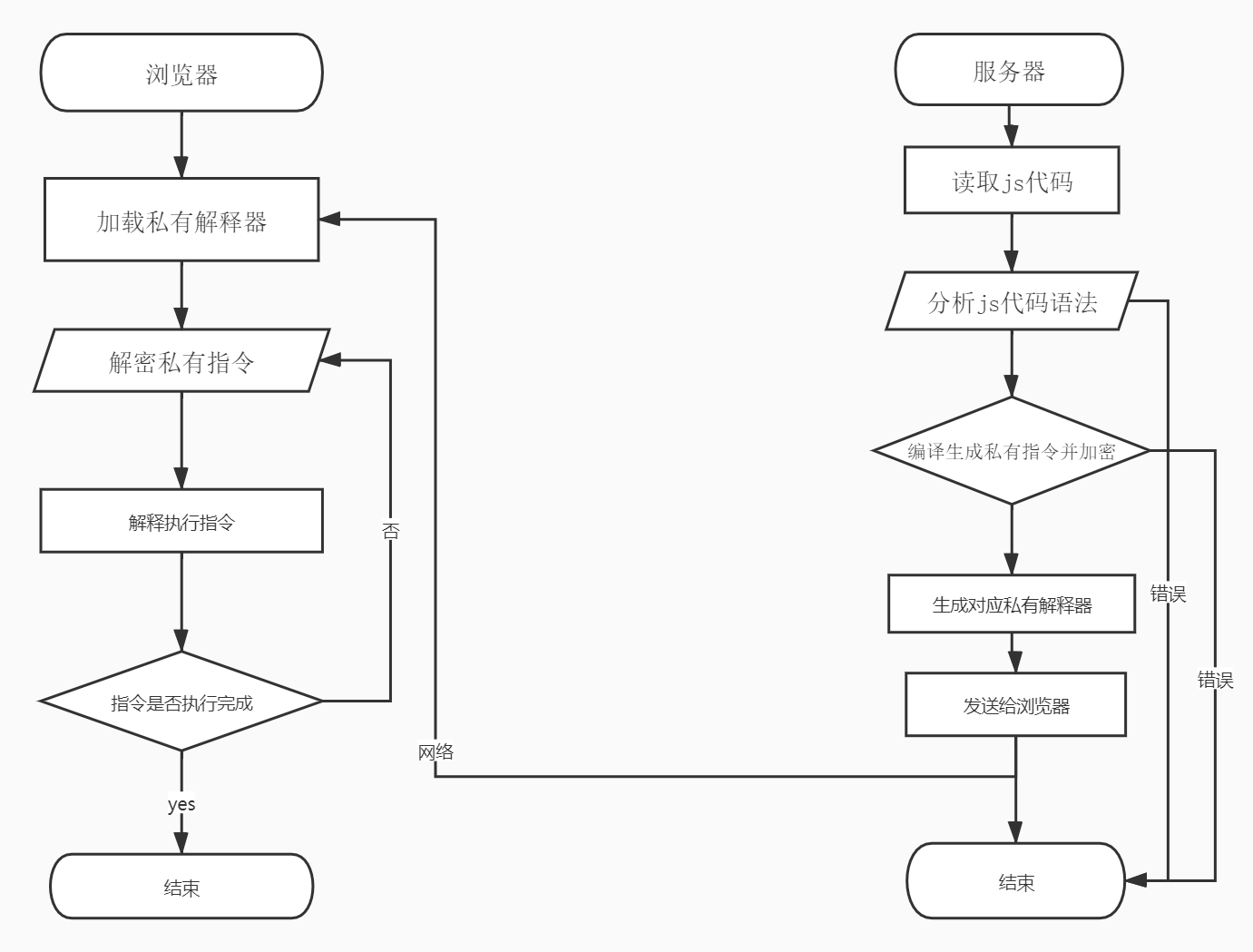
JSVMP 有哪些學習資料?
除了匡開圓的論文以外,還有以下文章也值得學習:
JSVMP 逆向方法有哪些?
就目前來講,JSVMP 的逆向方法有三種(自動化不算):RPC 遠程調用,補環境,日誌斷點還原演算法,其中日誌斷點也稱為插樁,找到關鍵位置,輸出關鍵參數的日誌信息,從結果往上倒推生成邏輯,以達到演算法還原的目的,RPC 技術K哥以前寫過文章,補環境的方式以後有時間再寫,本文主要介紹如何使用插樁來還原演算法。
抓包情況
隨便來到某個博主主頁,抓包後搜索可發現一個介面,返回的是 JSON 數據,裡面包含了博主某音號,認證信息、簽名,關註、粉絲、獲贊等,請求 Query String Parameters 里包含了一個 X-Bogus 參數,每次請求會改變,此外還有 sec_user_id 是博主主頁 URL 後面那一串,webid 直接請求主頁返回內容里就有,msToken 與 cookie 有關,清除 cookie 訪問,就沒這個參數了,實測該介面不驗證 webid 和 msToken,直接置空即可。
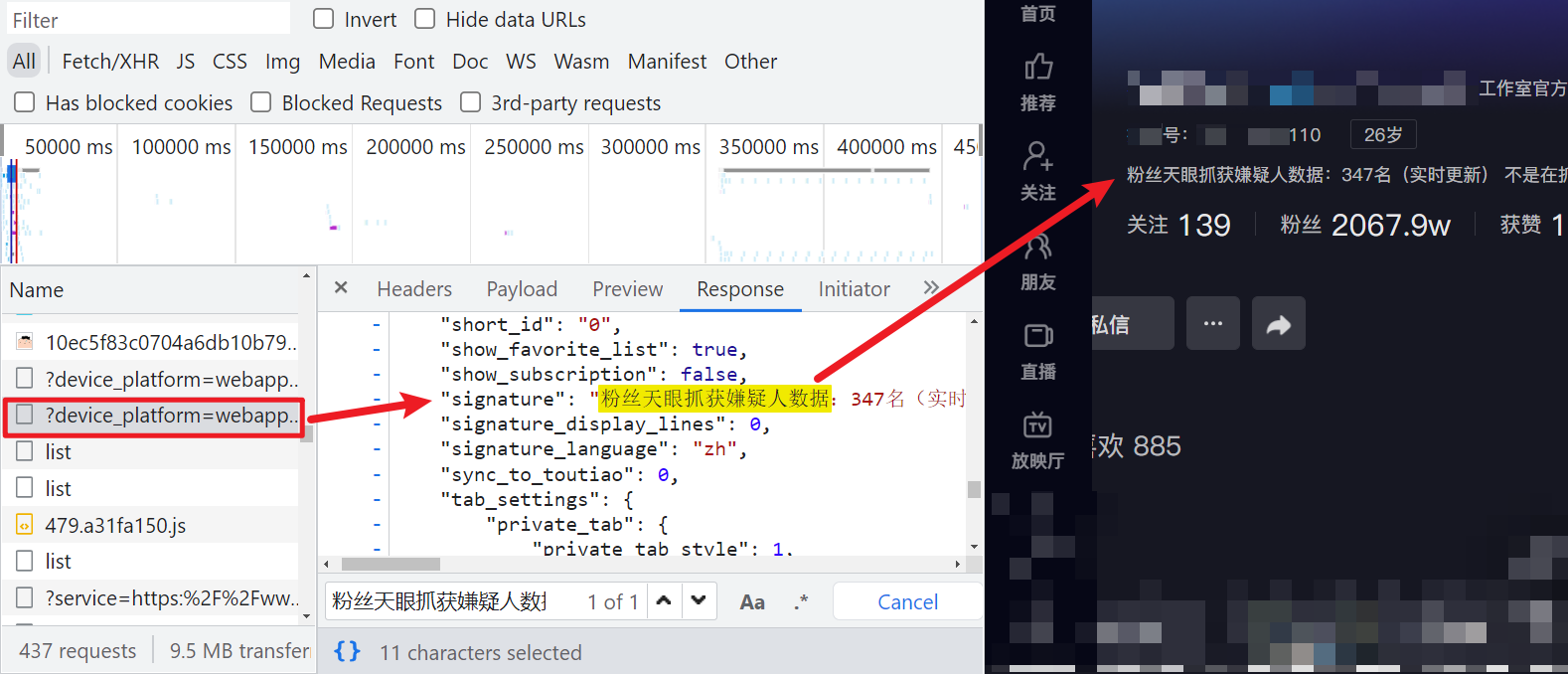
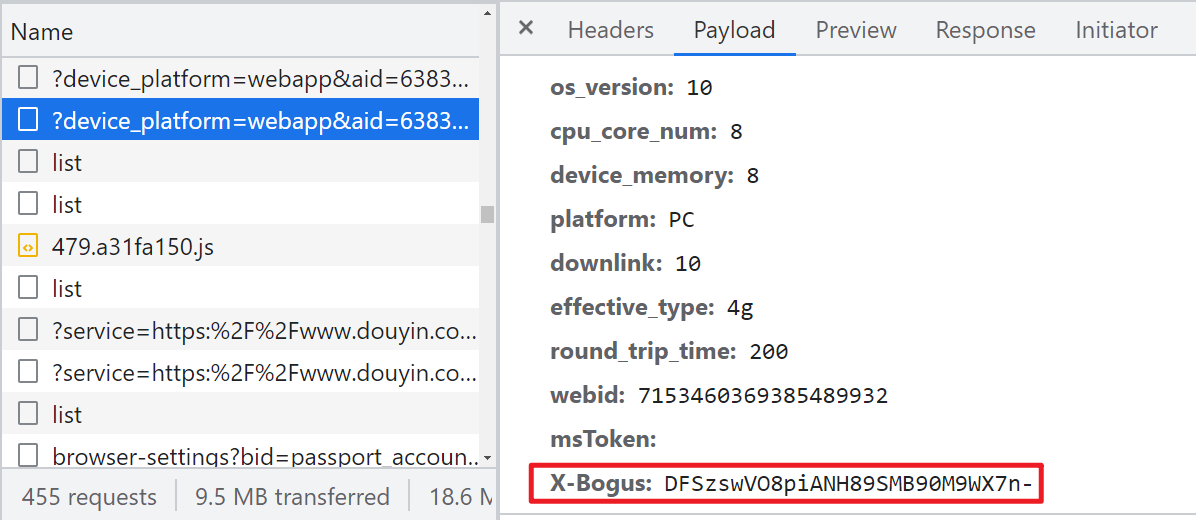
逆向分析
這條請求是 XHR 請求,所以直接下個 XHR 斷點,當 URL 中包含 X-Bogus 參數時就斷下:
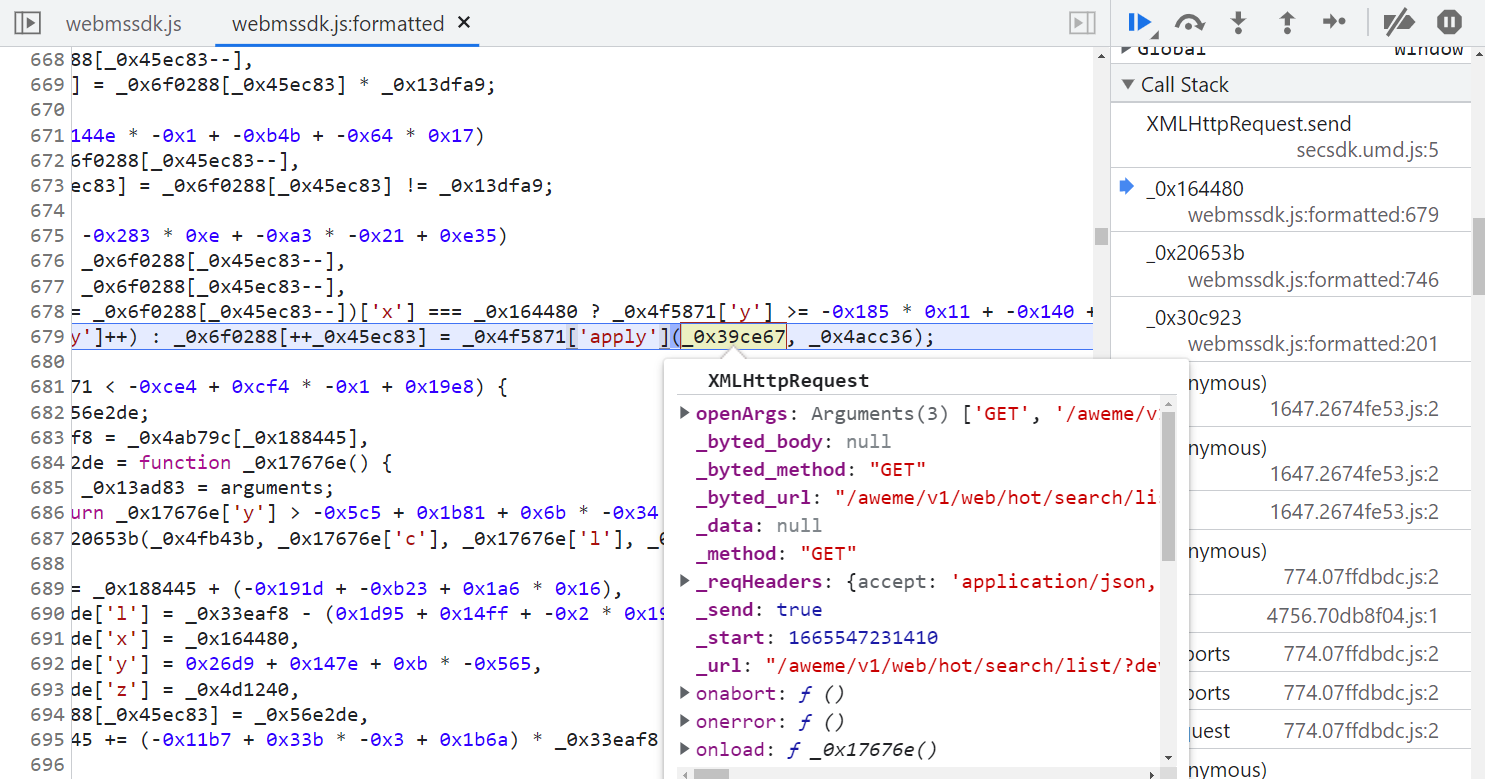
往前跟棧,來到一個叫 webmssdk.js 的 JS 文件,這裡就是生成參數的主要 JS 邏輯了,也就是 JSVMP,整體上做了一個混淆,這裡可以使用 AST 來解混淆,K哥以前同樣也寫過 AST 的文章,這裡還原混淆不是重點,咱們直接使用 V 佬的插件 v_jstools 來還原:
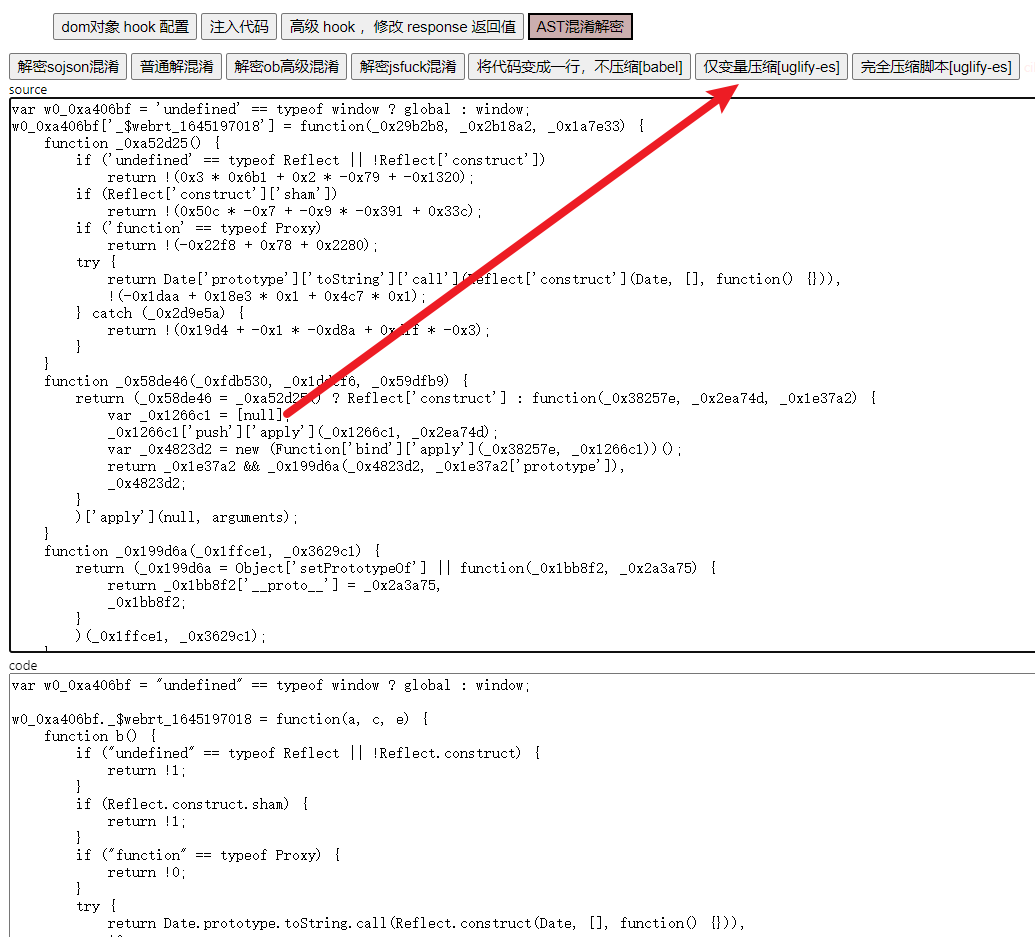
還原後使用瀏覽器的 Overrides 替換功能將 webmssdk.js 替換掉,往上跟棧,如下圖所示,到 W 這裡就已經生成了 X-Bogus 了,this.openArgs[1] 就是攜帶了 X-Bogus 的完整 URL,仔細觀察這段代碼,有很多三元表達式,當 M 的值為 15 時,就會走到這段邏輯,U 的值生成之後,有一個 S[C] = U 的操作。
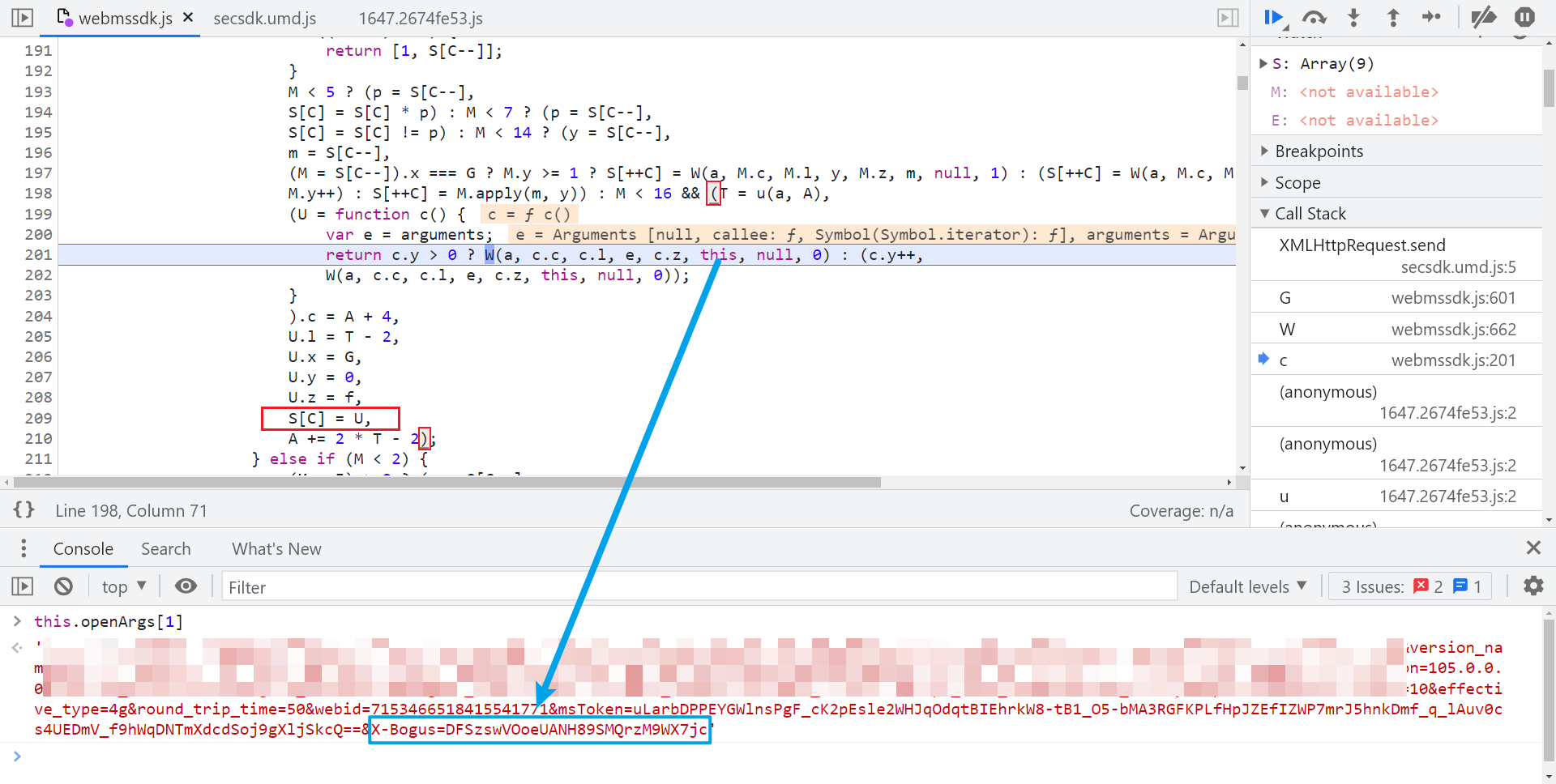
再往上看代碼,S 是一個數組,單步調試的話會發現代碼會一直走這個 if-else 的邏輯,幾乎每一步都有 S 數組的參與,不斷往裡面增刪改查值,for 迴圈裡面的 I 值,決定著後續 if 語句的走向,這裡也就是插樁的關鍵所在,如下圖所示:
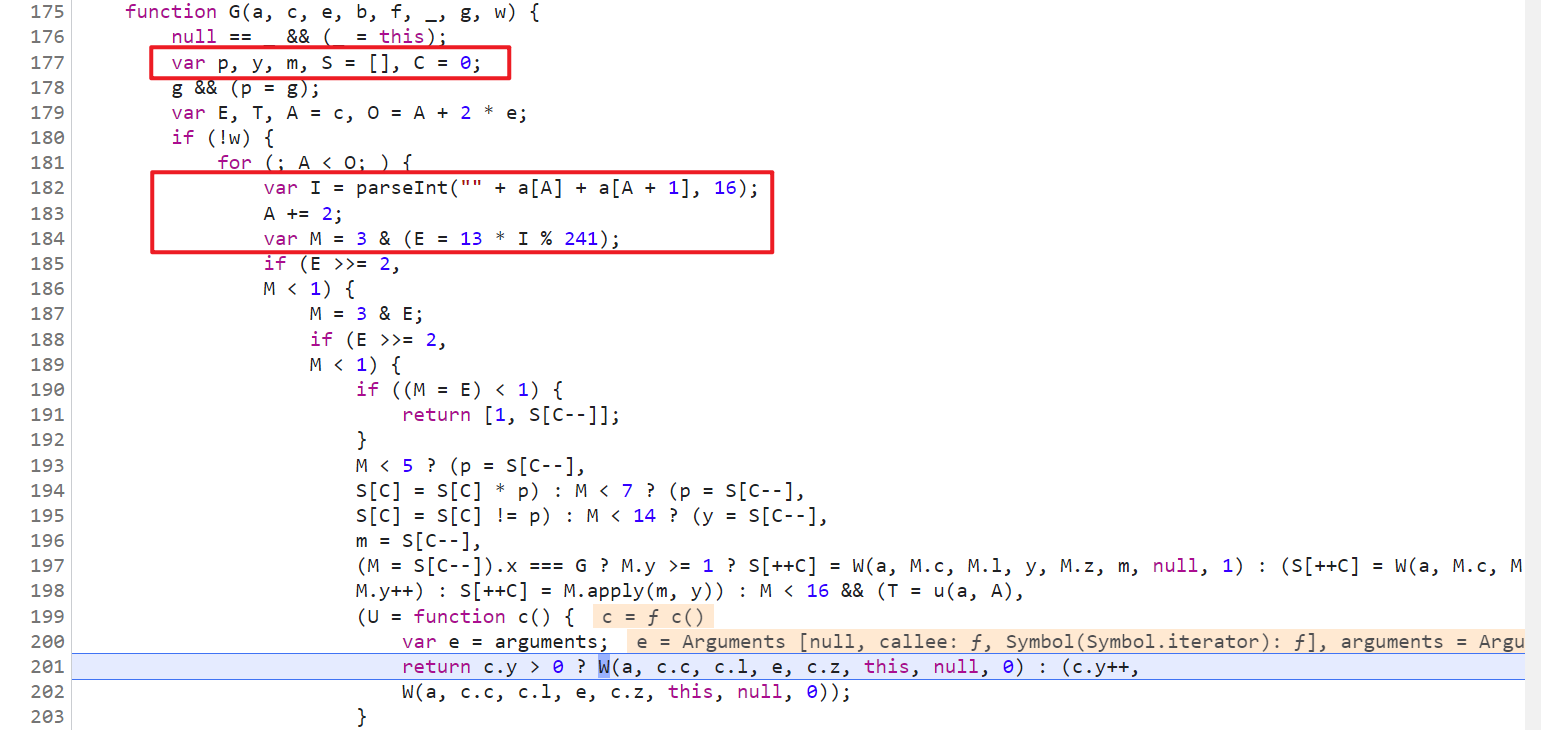
插樁分析
大的 for 迴圈和 if-else 邏輯有兩個地方,為了保證最後的日誌更加詳細完整,在這兩個地方都下個日誌斷點(右鍵 Add logpoint),斷點內容為:
"位置 1", "索引I", I, "索引A", A, "值S: ", JSON.stringify(S, function(key, value) {if (value == window) {return undefined} return value})
"位置 2", "索引I", I, "索引A", A, "值S: ", JSON.stringify(S, function(key, value) {if (value == window) {return undefined} return value})
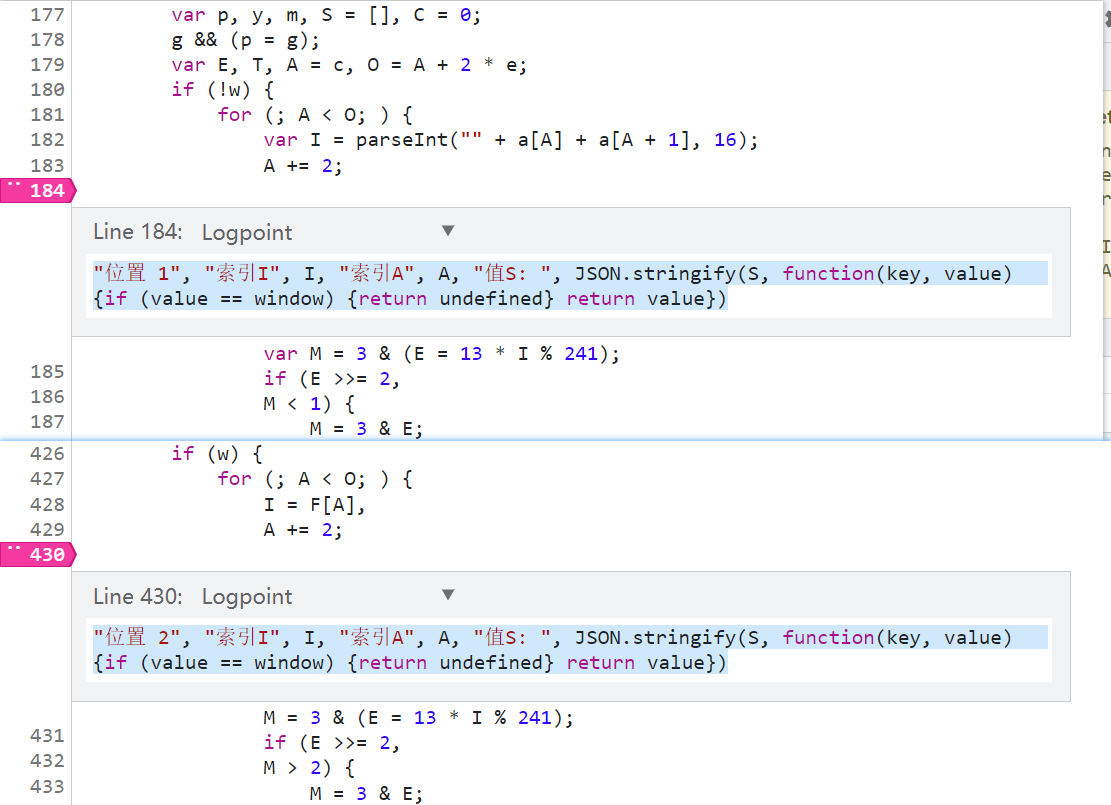
插樁輸出 S 的時候為什麼要寫這麼長一串呢?首先 JSON.stringify() 方法的作用是將 JavaScript 值轉換為 JSON 字元串,基礎語法是 JSON.stringify(value[, replacer [, space]]),如果不將其轉換成 JSON,那麼 S 的值,輸出可能是這樣的:[empty, Array(26), 1, Array(0)],你看不到 Array 數組裡面具體的值,該方法有個可選參數 replacer,如果 replacer 為函數,則 JSON.stringify 將調用該函數,並傳入每個成員的鍵和值,在函數中可以對成員進行處理,最後返回處理後的值,如果此函數返回 undefined,則排除該成員,舉個例子:
var obj1 = {key1: 'value1', key2: 'value2'}
function changeValue(key, value) {
if (value == 'value2') {
return '公眾號:K哥爬蟲'
} return value
}
var obj2 = JSON.stringify(obj1, changeValue)
console.log(obj2)
// 輸出:{"key1":"value1","key2":"公眾號:K哥爬蟲"}
上面的代碼中 JSON.stringify 傳入了一個函數,當 value 為 value2 的時候就將其替換成字元串 公眾號:K哥爬蟲,接下來我們演示一下當 value 為 window 時,會發生什麼:
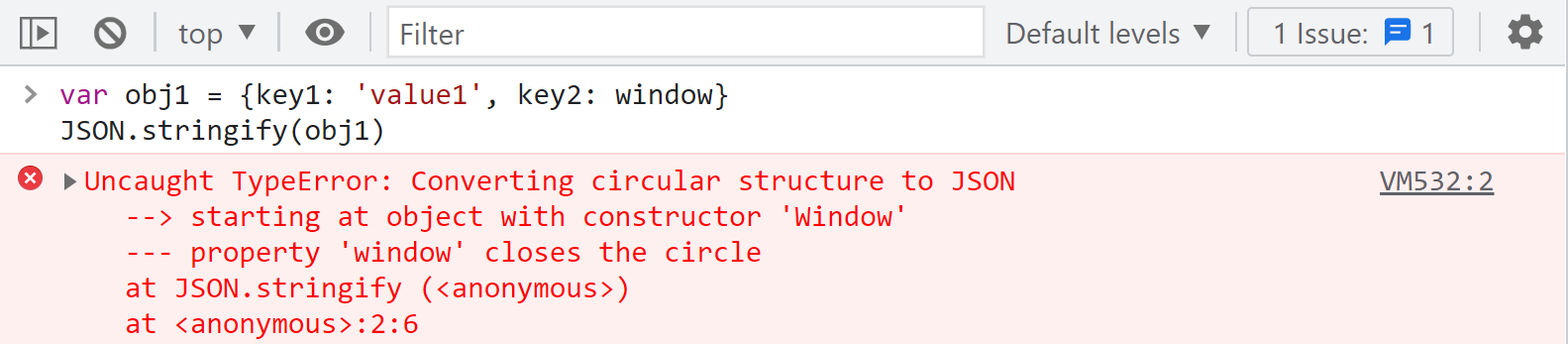
根據報錯我們可以看到這裡由於迴圈引用導致異常,要知道在插樁的時候,如果插樁內容有報錯,就會導致不能正常輸出日誌,這樣就會缺失一部分日誌,這種情況我們就可以加個函數處理一下,讓 value 為 window 的時候,JSON 處理的時候函數返回 undefined,排除該成員,其他成員正常輸出,如下圖所示:
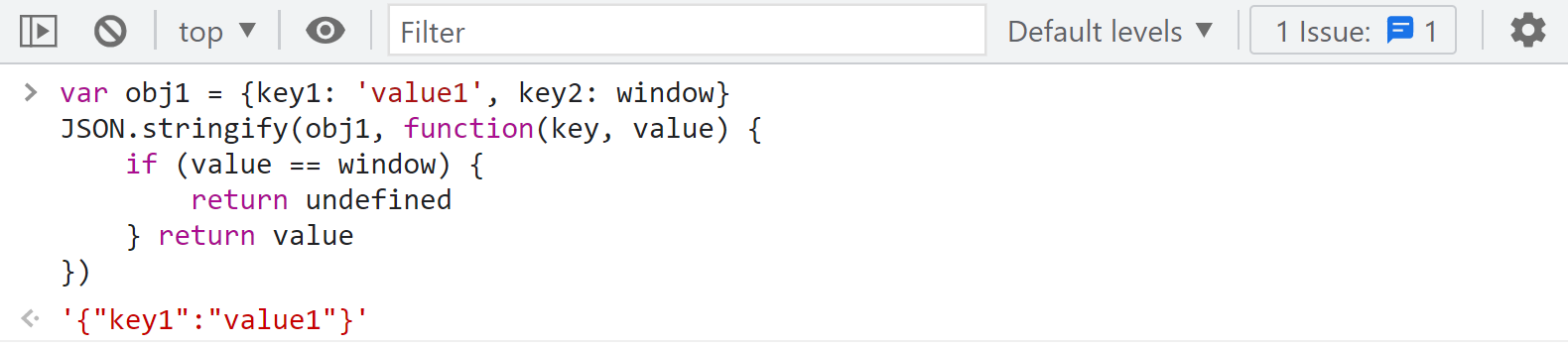
以上就是日誌斷點為什麼要這樣寫的原因,下好日誌斷點後,註意前面我們下的 XHR 斷點不要取消,然後刷新網頁,控制台就開始列印日誌了,因為有很多 XHR 請求都包含了 X-Bogus,如果你 XHR 斷點取消了,日誌就會一直列印直到卡死。日誌輸出完畢後,大約有8千多條,搜索就能看到最後一條日誌 X-Bogus 已經生成了:
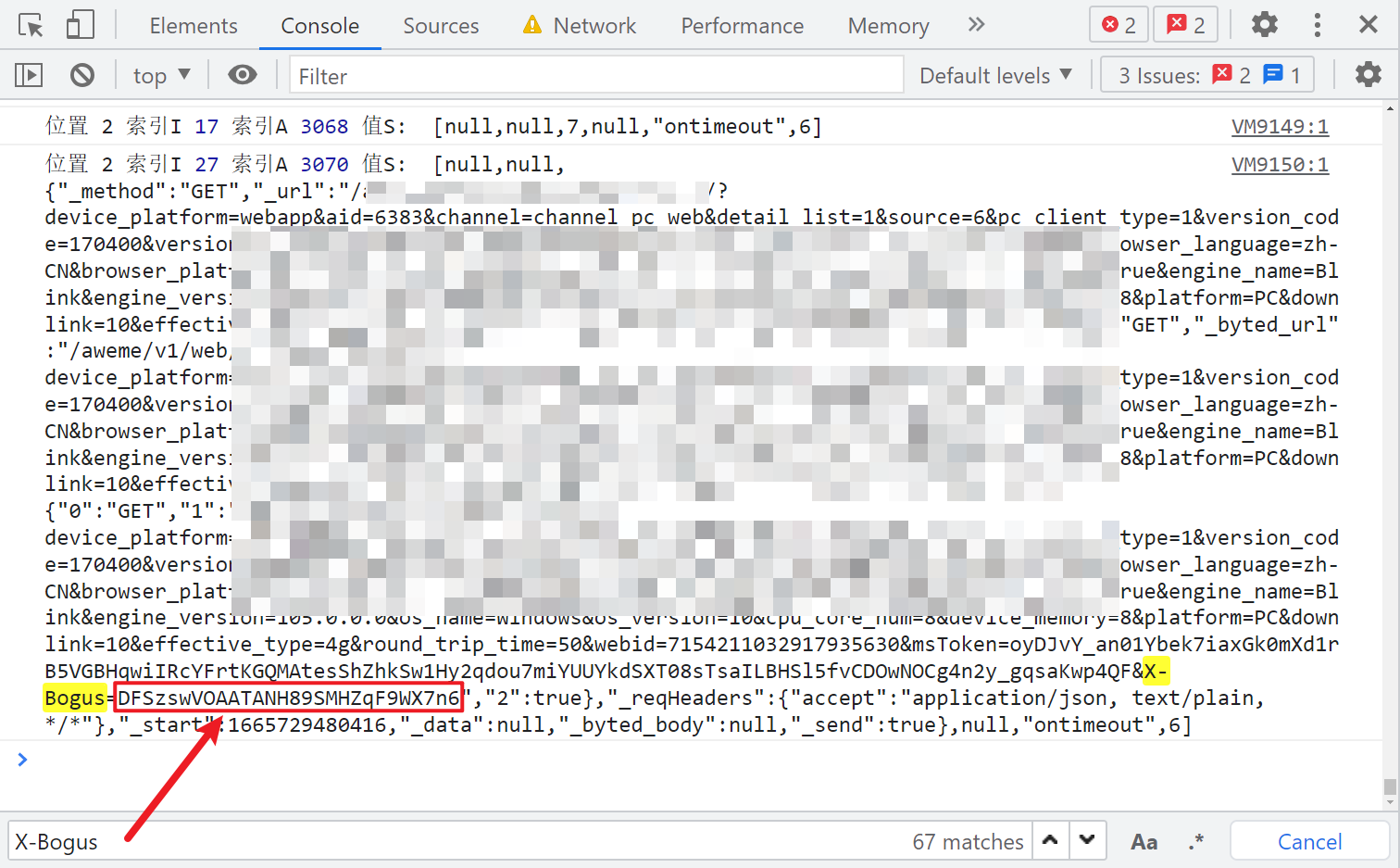
28個字元生成邏輯
直接在列印的日誌頁面右鍵 save as..,將日誌導出到本地進行分析。X-Bogus 由28個字元組成,現在要做的就是看 DFSzswVOAATANH89SMHZqF9WX7n6 這28個字元是怎麼來的,在日誌里搜索這個字元串,找到第一次出現的地方,觀察一下可以發現,他是逐個字元依次生成的,如下圖紅框所示:
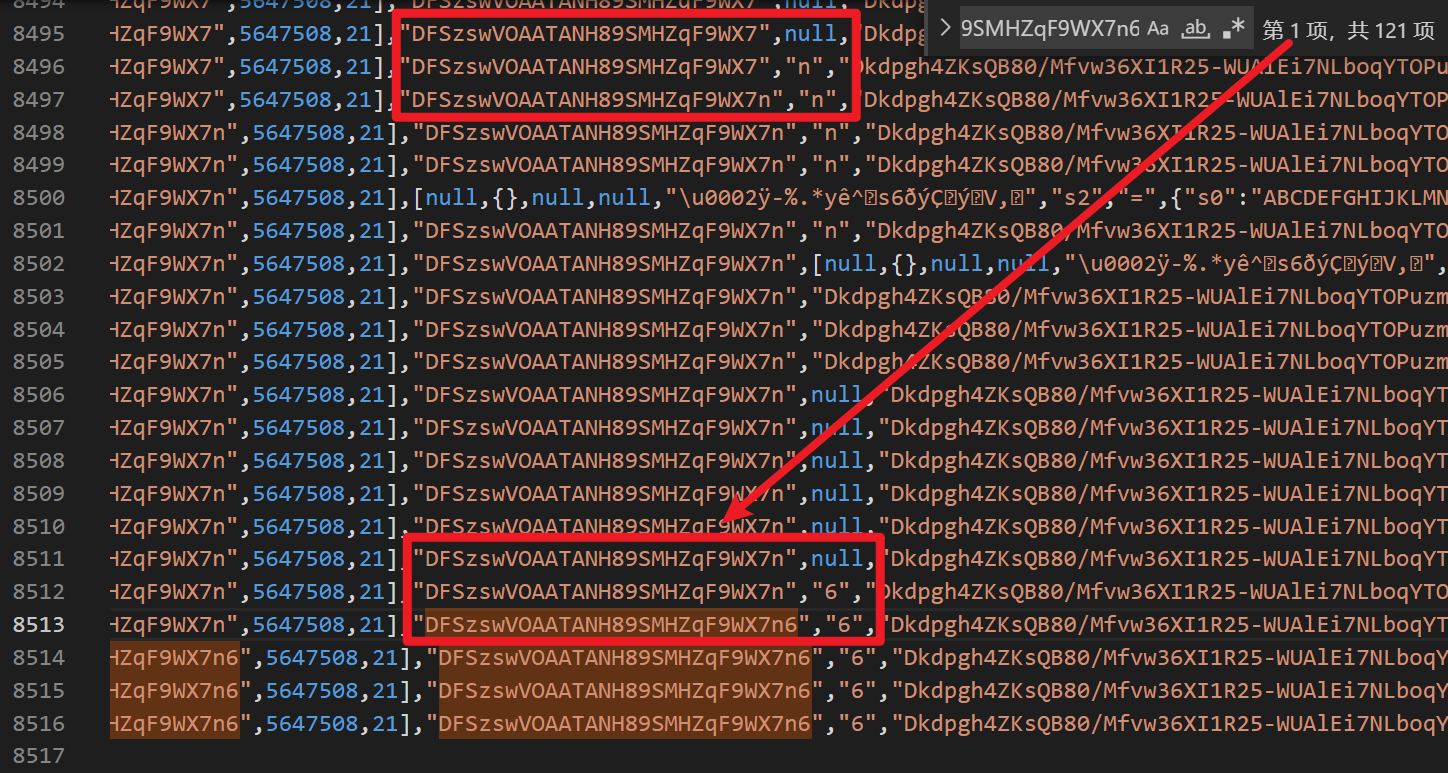
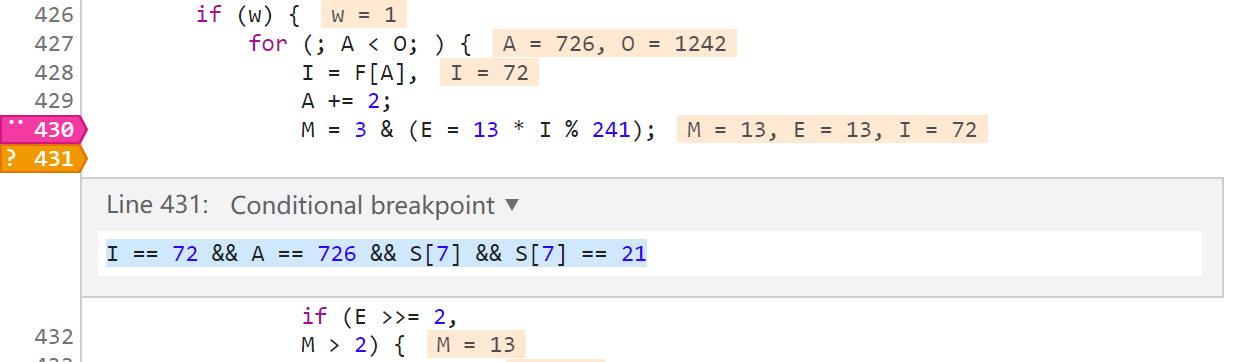
在上圖中,第8511行,X-Bogus 字元串的下一個元素是 null,到了第8512行,就生成數字6了,那麼在這兩步之間就是數字6的生成邏輯,這個時候我們看第8511行的日誌斷點是 位置 2 索引I 16 索引A 738,那麼我們回到原網頁,在位置2,下一個條件斷點(右鍵 Add conditional breakpoint),當 I == 16 && A == 738 && S[7] && S[7] == 21 時就斷下。之所以要加 S[7] 是因為 索引I 16 索引A 738 的位置有很多,在日誌里搜一下大概有40多個,多加個限制條件就可以縮小範圍,當然有可能加了多個條件仍然有多個位置都滿足,這就需要你細心觀察了,通過斷點斷下的時候看看控制台前面輸出的日誌來判斷是不是我們想要的位置。這也是一個小細節,一定要找準位置,千萬別搞混了。(提示一下,像我這樣下斷點的話,一般情況下會斷下兩次,第二次是滿足要求的)
(註意:本文描述的日誌的多少行、斷點的具體位置、變數的具體值,可能會有所變化,以你的實際情況為準,但思路是一樣的)
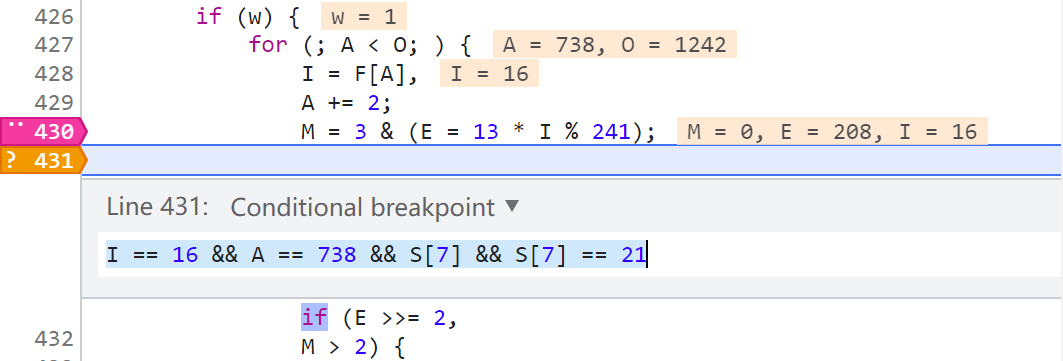
刷新網頁,斷下之後開始單步跟,來到下圖所示的地方:
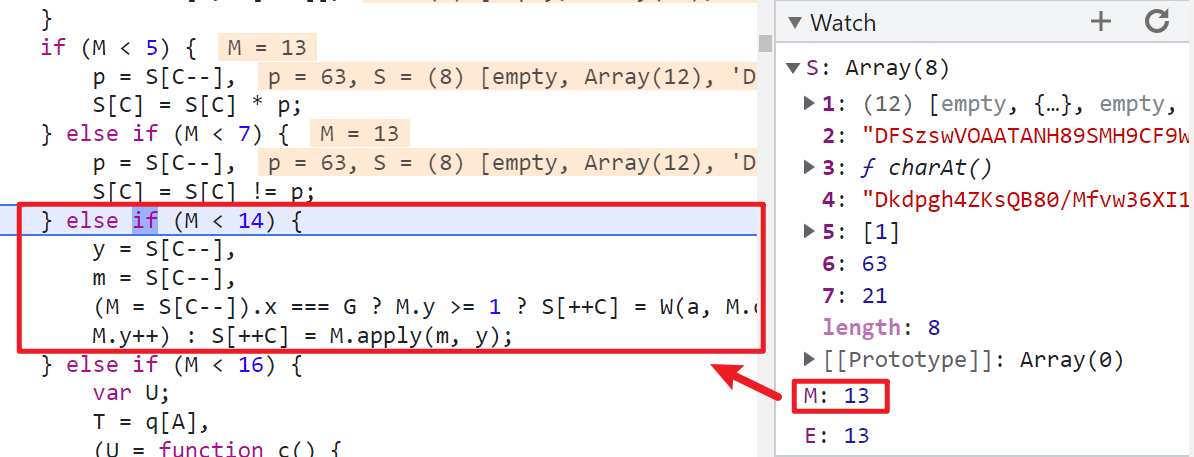
到這裡之後,就不要下一步了,再下一步有可能整個語句就執行完畢了,其中的細節你看不到,所以這裡我們在控制台挨個輸入看看:
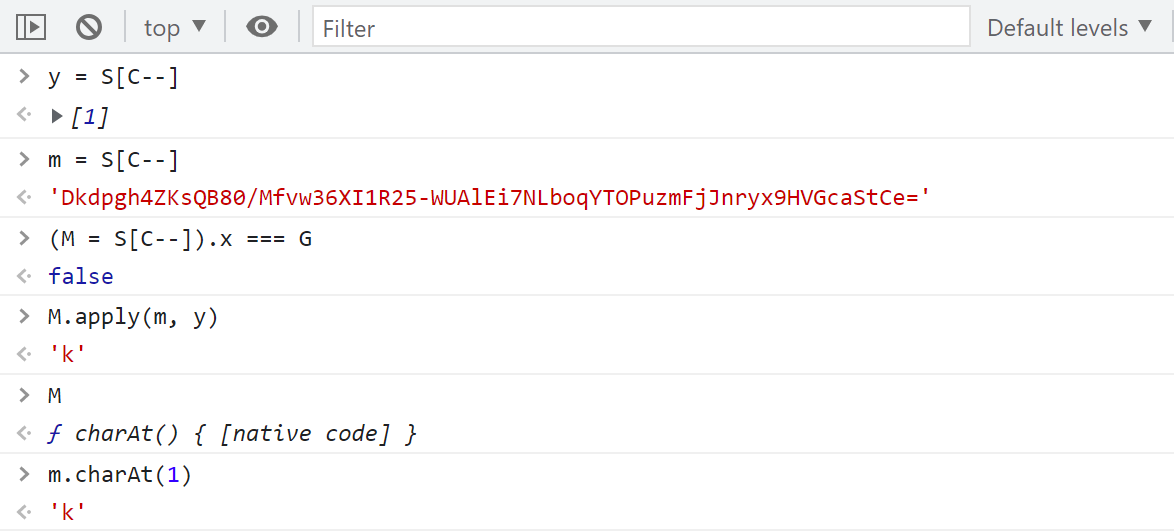
可以看到實際上的邏輯就是返回指定位置的字元,y 的值就是 S[5],m 的值就是 S[4],經過多次調試發現 m 的值是固定的,M 就是 charAt() 方法,我們再看看我們本地的日誌,S[5] 的值為 [20],charAt() 取值出來就是6,邏輯完全正確。

現在我們還需要知道這個20是怎麼來的,繼續往上看,找到20第一次出現的地方,在第8510行,那麼我們就要使其在上一步斷下,也就是第8509行,如下圖所示:

第8509行的索引信息為 位置 2 索引I 47 索引A 730,同樣的下條件斷點觀察怎麼生成的:
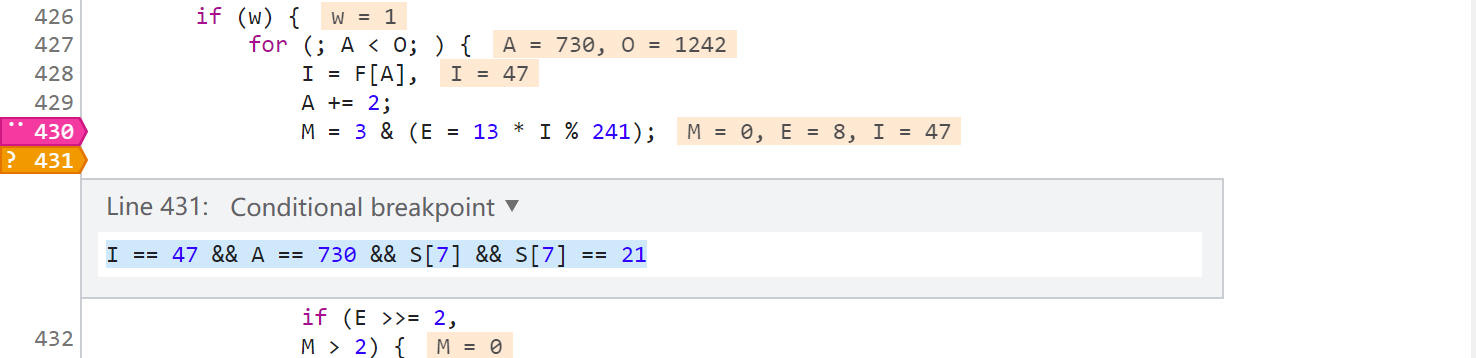
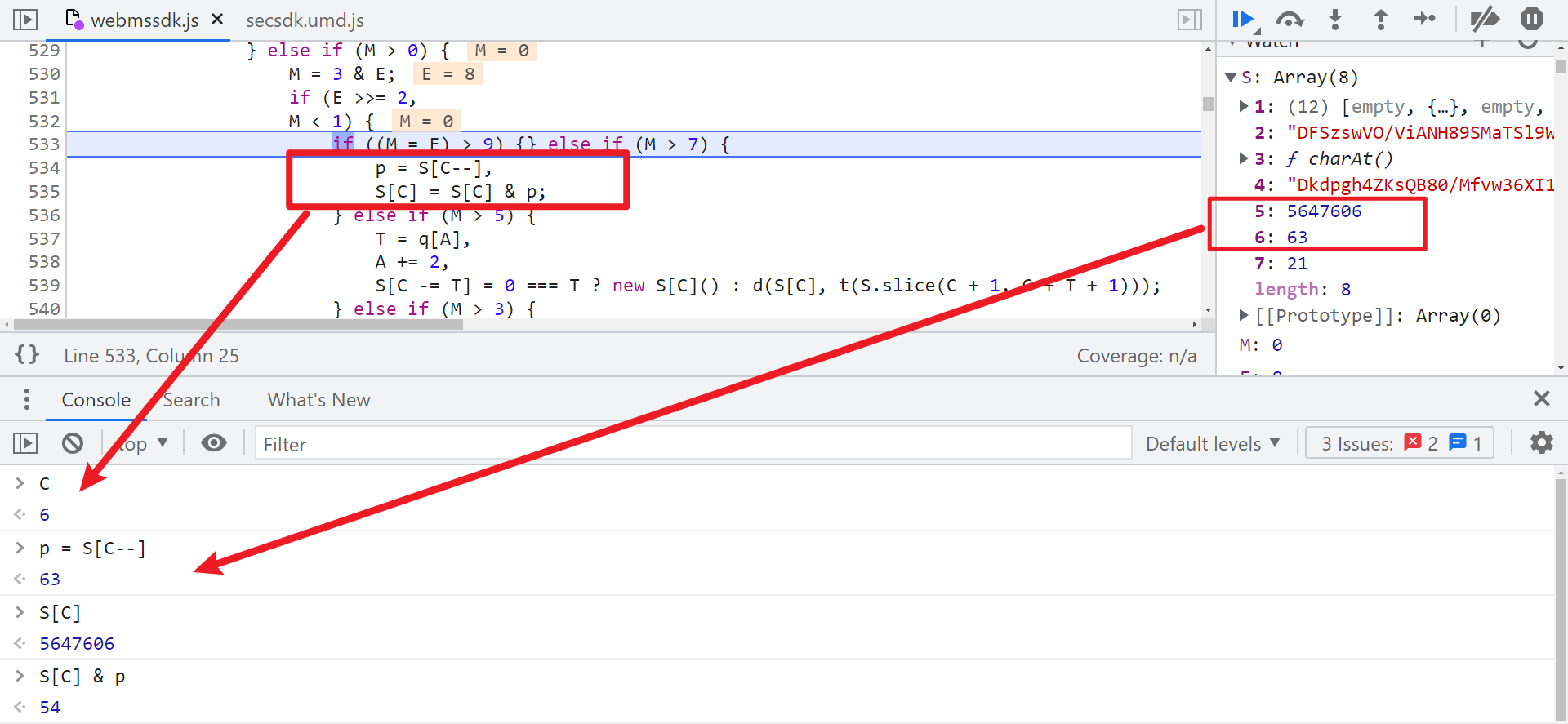
可以看到邏輯是 S[5] & S[6],再看我們本地 S[5] = 5647508、S[6] = 63 ,5647508 & 63 = 20,邏輯正確,20就是這麼來的。接下來又開始找 5647508 和 63 是怎麼生成的,同樣在生成的上一步,也就是8508行下個條件斷點,這行的索引為 位置 2 索引I 72 索引A 726。

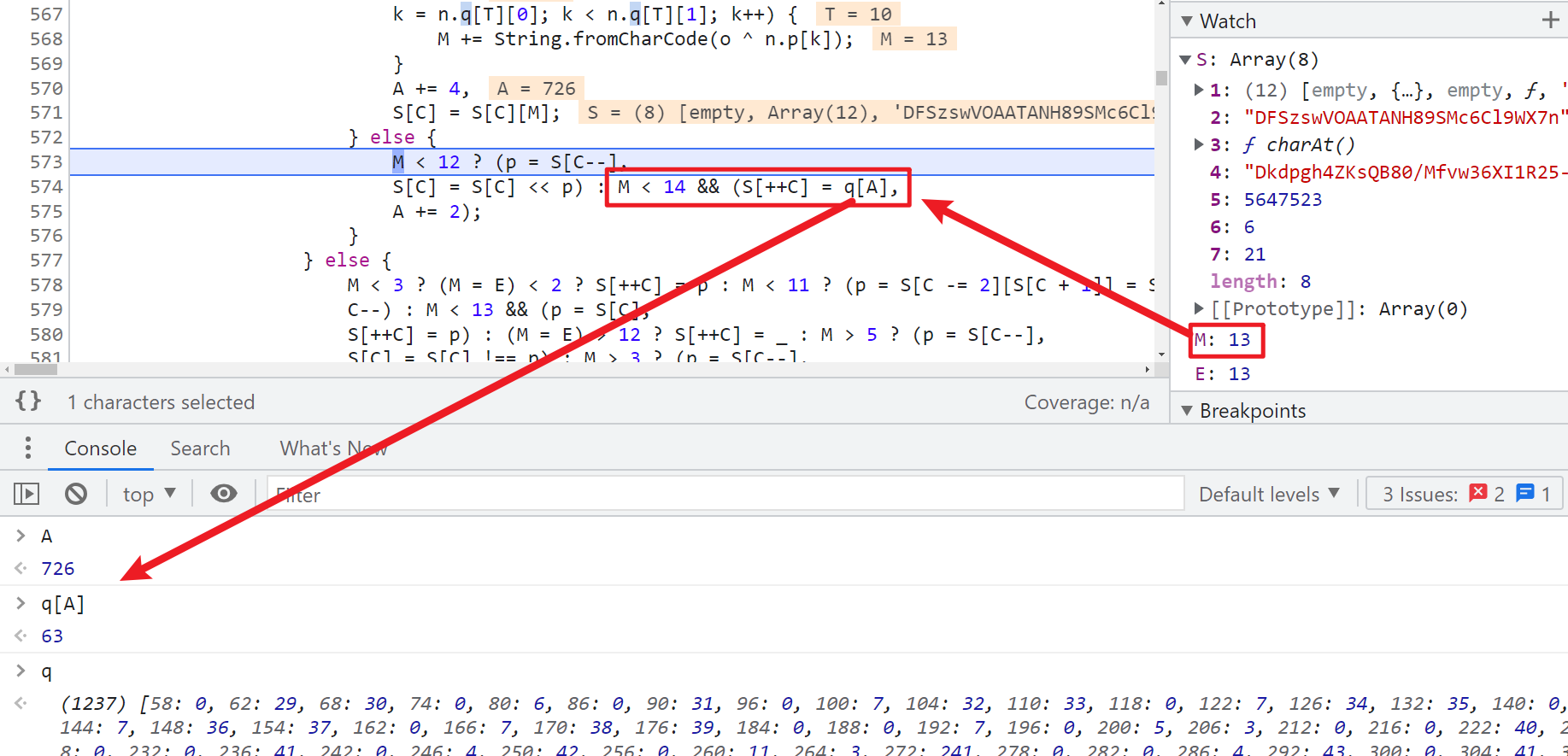
可以看到 63 是直接 q[A] 生成的,q 是一個大數組,A 就是索引為 726,q 這個大數組怎麼來的先不用管,而 5647508 這個大數字,搜索一下,發現有很多,咱們也先放著,到這裡咱們可以總結一下最後一個字元的生成步驟如下:
short_str = "Dkdpgh4ZKsQB80/Mfvw36XI1R25-WUAlEi7NLboqYTOPuzmFjJnryx9HVGcaStCe="
q[726] = 63
5647508 & 63 = 20
short_str.charAt(20) = '6'
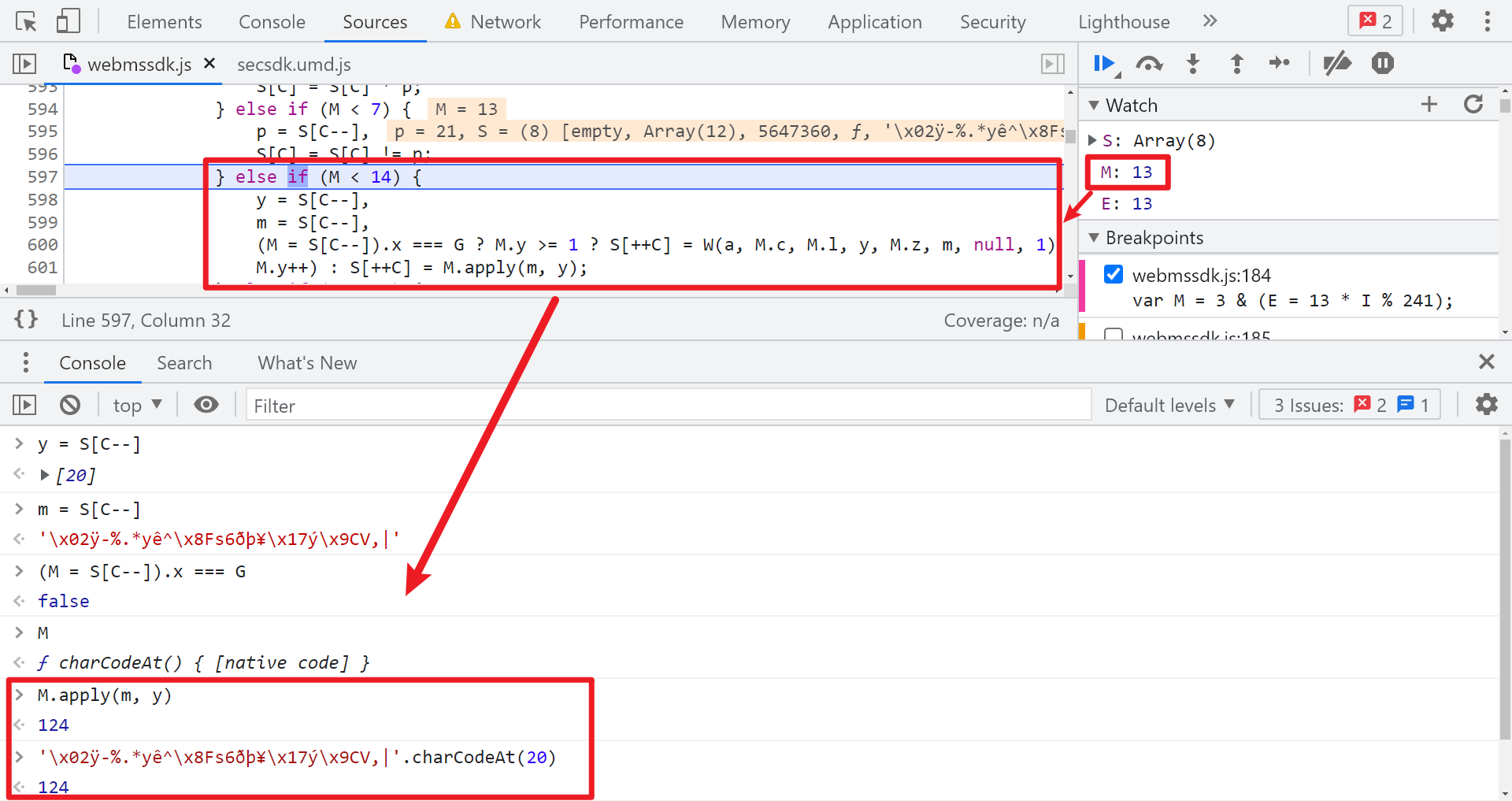
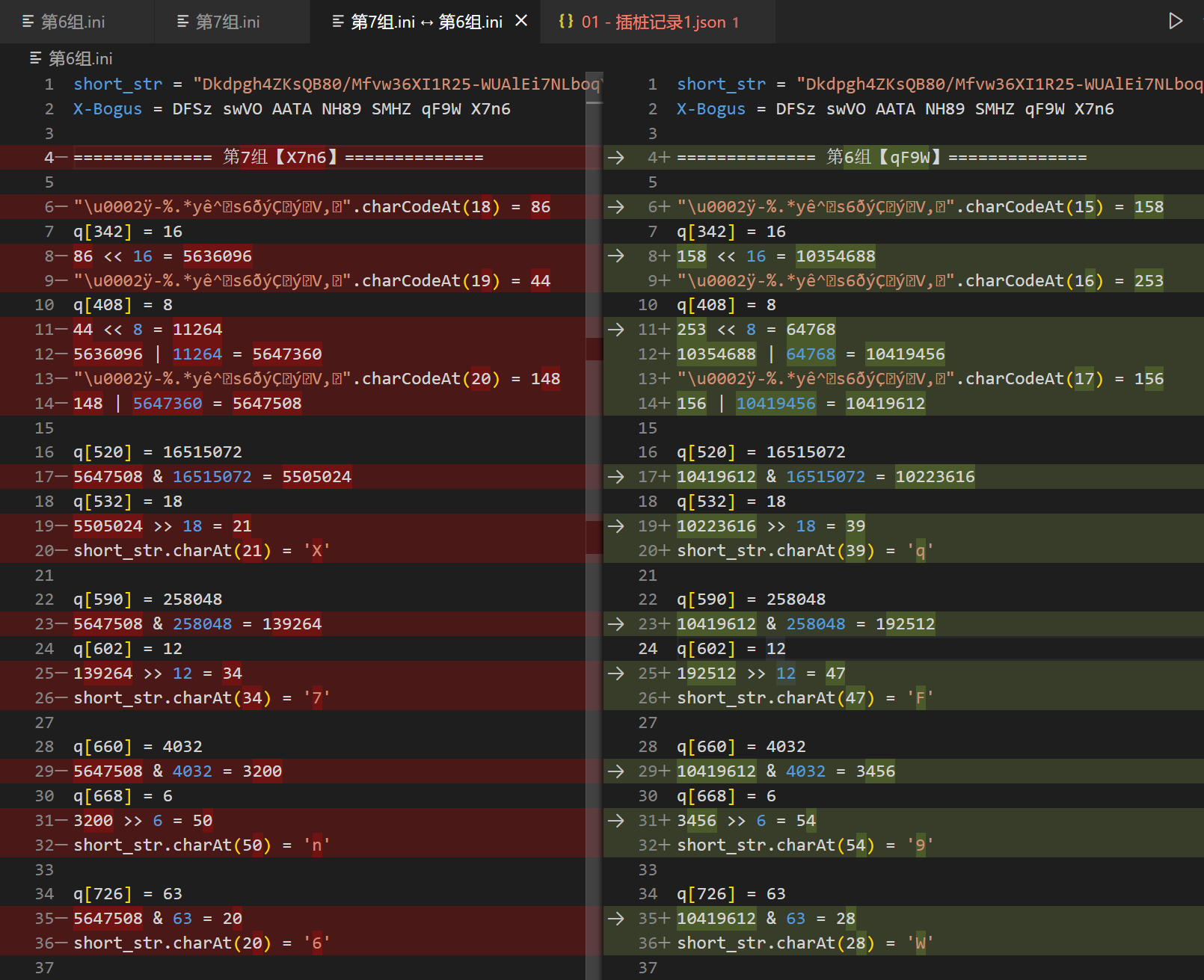
然後接日誌著往上看,看倒數第二個字母是怎麼來的,方法也和前面演示的一樣,不斷往前下條件斷點,這裡就不再逐步演示了,當你找完四個數字後,就可以開始看 5647508 這個大數字怎麼來的了,搜索這個數字,同樣的找到第一次出現的地方,在其前一步下條件斷點,步驟捋出來會發現有一個亂碼字元串經過 charCodeAt() 操作,再加上一些位運算得到的,亂碼字元串類似下圖所示:
至於這個亂碼字元串怎麼來的,我們後面再講,到這裡先總結一下,首先我們的 X-Bogus = DFSz swVO AATA NH89 SMHZ qF9W X7n6,將其看成每四個為一組,之所以這麼分組,是因為你經過分析後會發現,每一組的每一個字元生成流程都是一樣的,這裡以最後兩組為例,流程大致如下:
short_str = "Dkdpgh4ZKsQB80/Mfvw36XI1R25-WUAlEi7NLboqYTOPuzmFjJnryx9HVGcaStCe="
X-Bogus = DFSz swVO AATA NH89 SMHZ qF9W X7n6
============== 第6組【qF9W】==============
"\u0002ÿ-%.*yê^s6ðýÇýV,".charCodeAt(15) = 158
q[342] = 16
158 << 16 = 10354688
"\u0002ÿ-%.*yê^s6ðýÇýV,".charCodeAt(16) = 253
q[408] = 8
253 << 8 = 64768
10354688 | 64768 = 10419456
"\u0002ÿ-%.*yê^s6ðýÇýV,".charCodeAt(17) = 156
156 | 10419456 = 10419612
q[520] = 16515072
10419612 & 16515072 = 10223616
q[532] = 18
10223616 >> 18 = 39
short_str.charAt(39) = 'q'
q[590]= 258048
10419612 & 258048 = 192512
q[602] = 12
192512 >> 12 = 47
short_str.charAt(47) = 'F'
q[660] = 4032
10419612 & 4032 = 3456
q[668] = 6
3456 >> 6 = 54
short_str.charAt(54) = '9'
q[726] = 63
10419612 & 63 = 28
short_str.charAt(28) = 'W'
============== 第7組【X7n6】==============
"\u0002ÿ-%.*yê^s6ðýÇýV,".charCodeAt(18) = 86
q[342] = 16
86 << 16 = 5636096
"\u0002ÿ-%.*yê^s6ðýÇýV,".charCodeAt(19) = 44
q[408] = 8
44 << 8 = 11264
5636096 | 11264 = 5647360
"\u0002ÿ-%.*yê^s6ðýÇýV,".charCodeAt(20) = 148
148 | 5647360 = 5647508
q[520] = 16515072
5647508 & 16515072 = 5505024
q[532] = 18
5505024 >> 18 = 21
short_str.charAt(21) = 'X'
q[590] = 258048
5647508 & 258048 = 139264
q[602] = 12
139264 >> 12 = 34
short_str.charAt(34) = '7'
q[660] = 4032
5647508 & 4032 = 3200
q[668] = 6
3200 >> 6 = 50
short_str.charAt(50) = 'n'
q[726] = 63
5647508 & 63 = 20
short_str.charAt(20) = '6'
將流程對比一下就可以發現,每個步驟 q 裡面的取值都是一樣的,這個可以直接寫死,不同之處就在於最開始的 charCodeAt() 操作,也就是返回亂碼字元串指定位置字元的 Unicode 編碼,第7組依次是 18、19、20,第6組依次是15、16、17,以此類推,第1組剛好是0、1、2,如下圖所示:
每一組的邏輯都是一樣的,我們就可以寫個通用方法,依次生成七組字元串,最後拼接成完整的 X-Bogus,代碼如下:(亂碼字元串的生成後文會講)
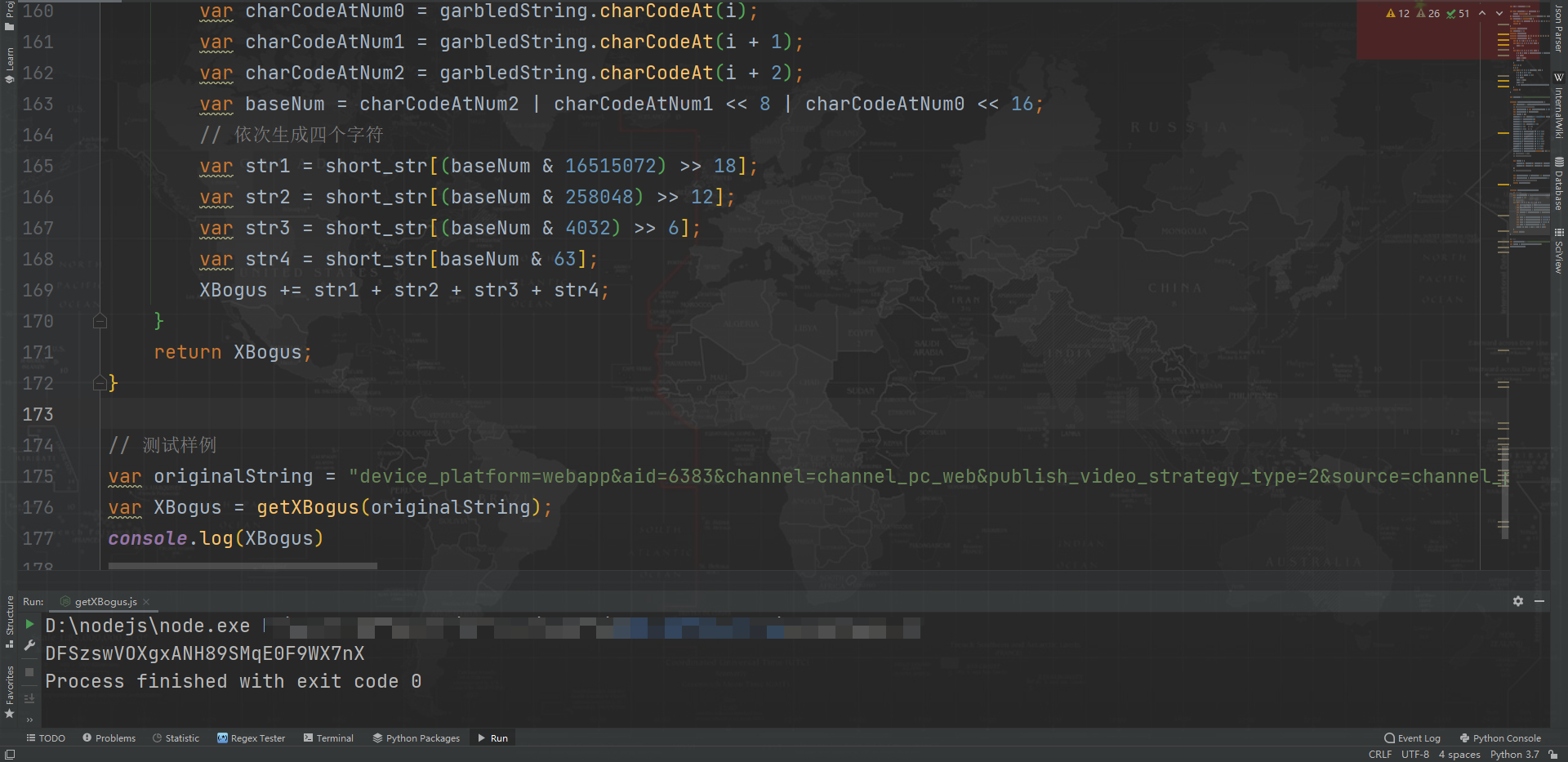
function getXBogus(originalString){
// 生成亂碼字元串
var garbledString = getGarbledString(originalString);
var XBogus = "";
// 依次生成七組字元串
for (var i = 0; i <= 20; i += 3) {
var charCodeAtNum0 = garbledString.charCodeAt(i);
var charCodeAtNum1 = garbledString.charCodeAt(i + 1);
var charCodeAtNum2 = garbledString.charCodeAt(i + 2);
var baseNum = charCodeAtNum2 | charCodeAtNum1 << 8 | charCodeAtNum0 << 16;
// 依次生成四個字元
var str1 = short_str[(baseNum & 16515072) >> 18];
var str2 = short_str[(baseNum & 258048) >> 12];
var str3 = short_str[(baseNum & 4032) >> 6];
var str4 = short_str[baseNum & 63];
XBogus += str1 + str2 + str3 + str4;
}
return XBogus;
}
亂碼字元串生成邏輯
在進行下一步之前,我們要註意兩點:
-
文章演示有些變數前後不對應,因為每次插樁的值都是會變的,看流程就行了,流程是正確的;
-
我們日誌輸出是經過
JSON.stringify處理了的,有些步驟是向某個函數傳入亂碼字元串進行處理,你會發現處理後的結果和日誌不一致,這是正常的。
亂碼字元串的生成相對來說稍微複雜一點,但思路仍然一樣,這裡就不一一截圖展示了,直接用日誌描述一下關鍵步驟,註意以下日誌是正向的步驟,就不逆著推了,建議自己先逆著把流程走一走,再來看這個步驟就看得懂了。
Step1:首先對 URL 後面的參數,也就是 Query String Parameters 進行兩次 MD5、兩次轉 Uint8Array 處理,最後得到的 Uint8Array 對象在後面的步驟中用得到,步驟如下:
位置 1 索引I 4 索引A 134:將 URL 後面的參數進行 MD5 加密得到字元串
位置 1 索引I 16 索引A 460:將上一步的字元串轉換為 Uint8Array 對象
位置 1 索引I 4 索引A 134:將上一步的 Uint8Array 對象進行 MD5 加密,得到字元串
位置 1 索引I 29 索引A 472:將上一步的字元串轉換為 Uint8Array 對象
上述步驟中,我們將最終得到的結果命名為 uint8Array,關鍵代碼實現如下:
var md5 = require("md5");
// 字元串轉換為 Uint8Array 對象,缺失的變數自行補齊
_0x5960a2 = function(a) {
for (var c = a.length >> 1, e = c << 1, b = new Uint8Array(c), d = 0, f = 0; f < e; ) {
b[d++] = _0x511f86[a.charCodeAt(f++)] << 4 | _0x511f86[a.charCodeAt(f++)];
}
return b;
}
// originalString: URL 後面的原始參數
var uint8Array = _0x5960a2(md5(_0x5960a2(md5(originalString))));
Step2:生成兩個大數,一個是時間戳,我們稱之為 fixedString1,另一個調用某個方法生成,我們稱之為 fixedString2。
fixedString1
位置 1 索引I 43 索引A 806:1663385262240 / 1000 = 1663385262.24
fixedString2
位置 1 索引I 16 索引A 834:M.apply(null, []) = 536919696
上述步驟中,M 對應以下方法,缺失的方法自行補齊(其中 _0x229792 是創建 canvas):
function _0x2996f8() {
try {
return _0x4b3b53 || (_0xb55f3e.perf ? -1 : (_0x4b3b53 = _0x229792(3735928559), _0x4b3b53));
} catch (a) {
return -1;
}
}
Step3:先後生成兩個數組,我們稱之為 array1、array2,array2 就是由 array1 的元素位置變換後得來的,嚴格來講,array1 不是一個完整的數組,而是一個個數字,這一點可以在日誌中體現出來,為了方便我們就直接將其視為一個數組,兩個數組都有19個元素,步驟如下:
array1[0] 至 array1[3] 為定值
array1[4]
位置 1 索引I 25 索引A 946:uint8Array[14]
array1[5]
位置 1 索引I 25 索引A 970:uint8Array[15]
array1[6] 至 array1[7] 為定值,8、9 與 ua 有關
array1[10]
位置 1 索引I 52 索引A 1090:fixedString1 >> 24 = 99
位置 1 索引I 47 索引A 1098:99 & 255 = 99
array1[11]
位置 1 索引I 52 索引A 1122:fixedString1 >> 16 = 25417
位置 1 索引I 47 索引A 1130:25417 & 255 = 73
array1[12]
位置 1 索引I 52 索引A 1154:fixedString1 >> 8 = 6506755
位置 1 索引I 47 索引A 1162:6506755 & 255 = 3
array1[13]
位置 1 索引I 52 索引A 1186:fixedString1 >> 0 = 241
位置 1 索引I 47 索引A 1194:241 & 255 = 241
array1[14]
位置 1 索引I 52 索引A 1218:fixedString2 >> 24 = 32
位置 1 索引I 47 索引A 1226:32 & 255 = 32
array1[15]
位置 1 索引I 52 索引A 1250:fixedString2 >> 16 = 8192
位置 1 索引I 47 索引A 1258:8192 & 255 = 0
array1[16]
位置 1 索引I 52 索引A 1282:fixedString2 >> 8 = 2097342
位置 1 索引I 47 索引A 1290:2097342 & 255 = 190
array1[17]
位置 1 索引I 52 索引A 1314:fixedString2 >> 0 = 536919696
位置 1 索引I 47 索引A 1322:536919696 & 255 = 144
array1[18]
位置 1 索引I 27 索引A 1352:array1.reduce(function(a, b) { return a ^ b; }); = 100
array1 完整值如下
位置 1 索引I 27 索引A 1538:64,1.00390625,1,8,9,185,69,63,74,125,99,73,3,241,32,0,190,144,100
array2 由 array1 元素交換位置而來:
array2 = [array1[0], array1[2], array1[4], array1[6], array1[8], array1[10], array1[12], array1[14], array1[16], array1[18], array1[1], array1[3], array1[5], array1[7], array1[9], array1[11], array1[13], array1[15], array1[17]]
array2 完整值如下
array2 = [64,1,9,69,74,99,3,32,190,100,1.00390625,8,185,63,125,73,241,0,144]
Step4:將 Step3 得到的 array2 經過轉換得到亂碼字元串,步驟如下:
位置 1 索引I 16 索引A 1706:
_0x2f2740.apply(null, array2) = "@\u0000\u0001\u000eíxE?\u0016c%>® \u0000¾ó"
位置 1 索引I 16 索引A 1760:
_0x46fa4c.apply(null, ["ÿ", "@\u0000\u0001\u000e\t¹E?J}cI\u0003ñ \u0000¾d"]) = "\u0002ÿ-%.*yê^s6ðýÇýV,"
位置 1 索引I 16 索引A 1812:
_0x2b6720.apply(null, [2, 255, "\u0002ÿ-%.*yê^s6ðýÇýV,"]) = "\u0002ÿ-%.*yê^s6ðýÇýV,"
其中用到的函數:
function _0x2f2740(a, c, e, b, d, f, t, n, o, i, r, _, x, u, s, l, v, h, g) {
let w = new Uint8Array(19);
return w[0] = a,
w[1] = r,
w[2] = c,
w[3] = _,
w[4] = e,
w[5] = x,
w[6] = b,
w[7] = u,
w[8] = d,
w[9] = s,
w[10] = f,
w[11] = l,
w[12] = t,
w[13] = v,
w[14] = n,
w[15] = h,
w[16] = o,
w[17] = g,
w[18] = i,
String.fromCharCode.apply(null, w);
}
function _0x46fa4c(a, c) {
let e, b = [], d = 0, f = "";
for (let a = 0; a < 256; a++) {
b[a] = a;
}
for (let c = 0; c < 256; c++) {
d = (d + b[c] + a.charCodeAt(c % a.length)) % 256,
e = b[c],
b[c] = b[d],
b[d] = e;
}
let t = 0;
d = 0;
for (let a = 0; a < c.length; a++) {
t = (t + 1) % 256,
d = (d + b[t]) % 256,
e = b[t],
b[t] = b[d],
b[d] = e,
f += String.fromCharCode(c.charCodeAt(a) ^ b[(b[t] + b[d]) % 256]);
}
return f;
}
function _0x583250(a) {
return String.fromCharCode(a);
}
function _0x2b6720(a, c, e) {
return _0x583250(a) + _0x583250(c) + e;
}
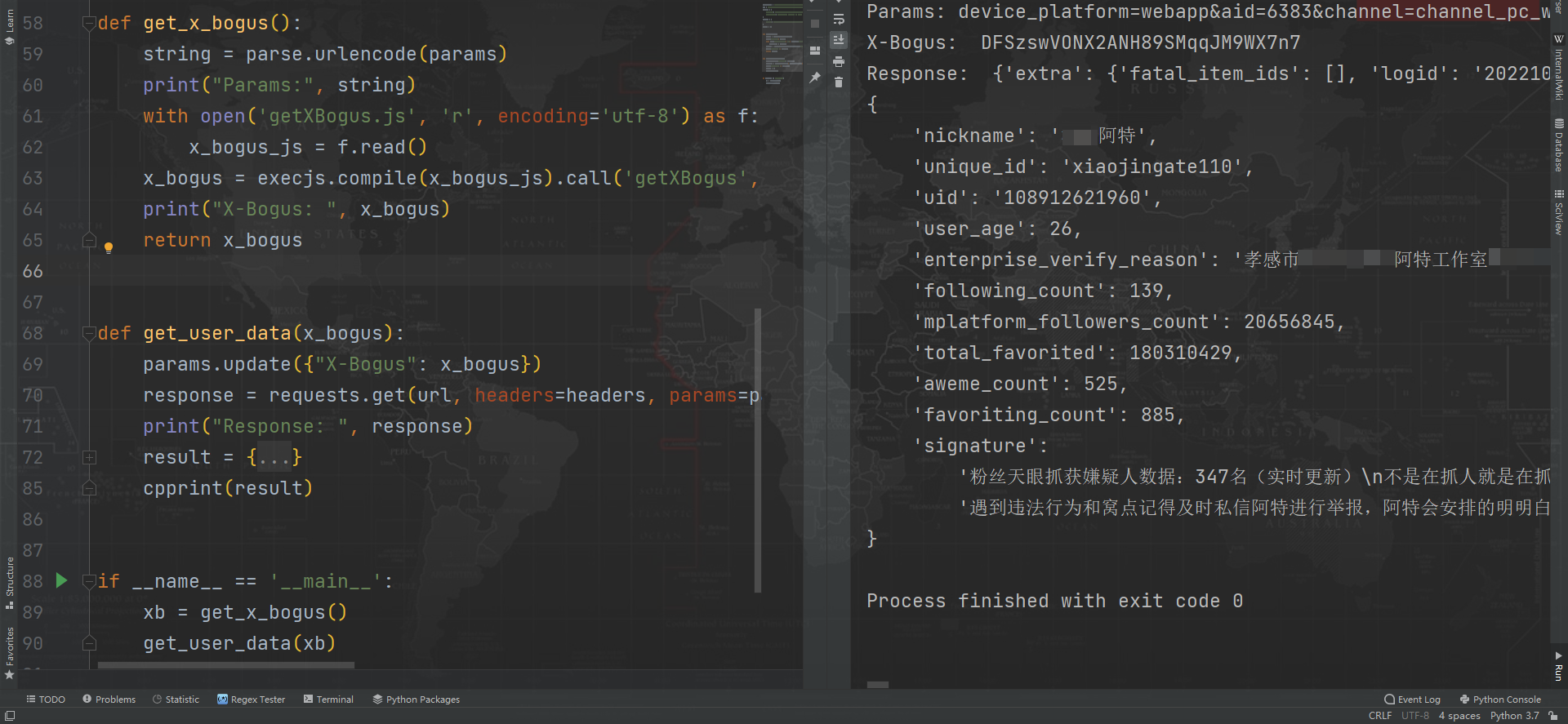
自此,整個流程就走完了。可以用 JavaScript 來實現整個演算法,用 Python 也可以,完善代碼後隨便請求一個博主主頁,簡單解析幾個數據,輸出正常: