
使用BCP + Polybase 實現本地數據遷移到Azure DB 一、背景 最近因為要做一些實驗的緣故, 需要在Azure DB上準備一些帶數據的資料庫。 AdventureWorks2019 和AdventureWorksDW2019就挺合適的,官網上能提供這兩個資料庫的備份文件。 在我將其成 ...
使用BCP + Polybase 實現本地數據遷移到Azure DB
一、背景
最近因為要做一些實驗的緣故, 需要在Azure DB上準備一些帶數據的資料庫。 AdventureWorks2019 和AdventureWorksDW2019就挺合適的,官網上能提供這兩個資料庫的備份文件。 在我將其成功還原到了本地SQL 實例中, 但是怎麼把數據遷移到Azure DB上有點犯難了。
雖然辦法有很多,比如可用採用資料庫遷移工具。但我的目標是能儘量的自動化,因此更希望以腳本的方式來實現。在這個目標前提下, 成功實現了數據的上雲遷移。 我的這個方式不一定是最好的,但效率上還是挺不錯的,而且在數據遷移的過程中也趟了一些坑。因此在此記錄過程中踩過的一些問題,有需要的可以借鑒。
二、過程
以下為具體實施過程的記錄。
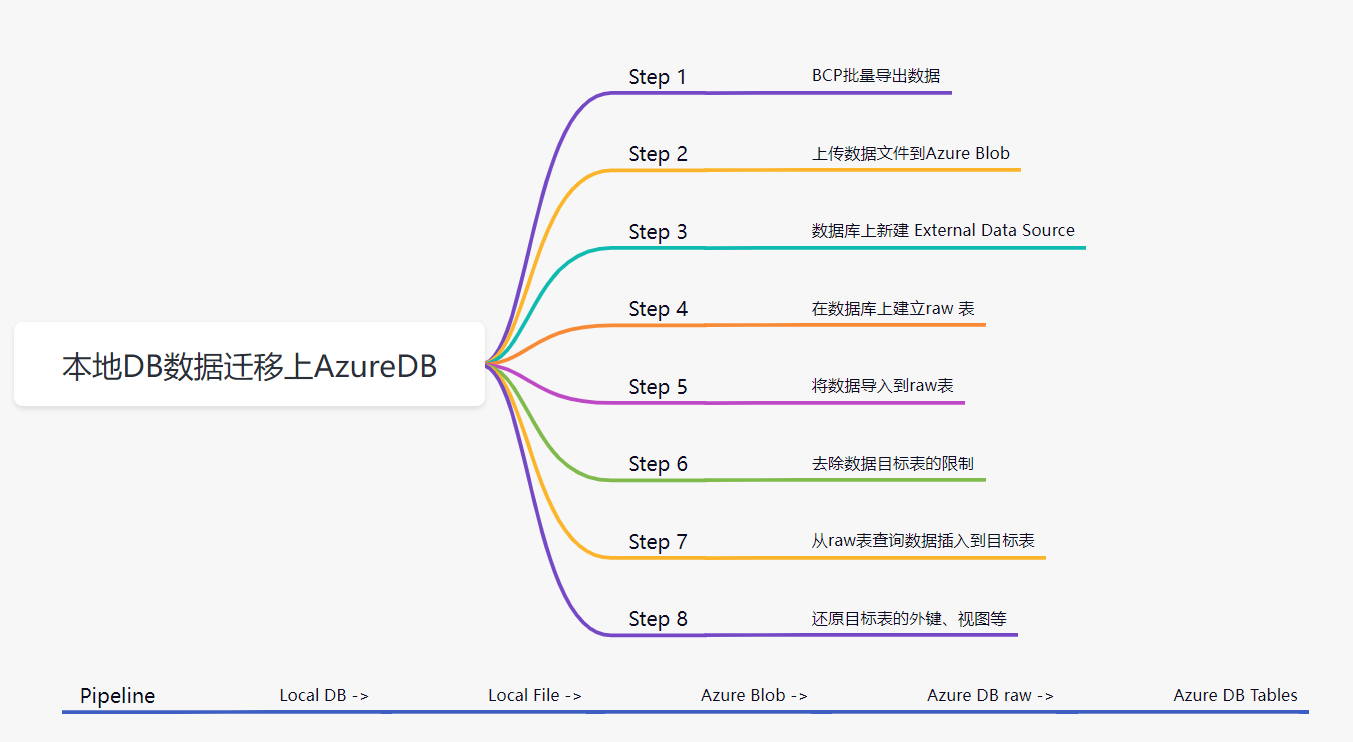
Step 1: BCP 導出數據為文件。
|
-- =============== -- bcp 批量導出數據 -- =============== select concat('bcp AdventureWorksDW2019.' , a.name,'.' , b.name , ' out ', a.name, '.', b.name, '.txt -c -t"|" -T -S. -C65001') as c from sys.schemas a inner join sys.objects b on a.schema_id = b.schema_id where (b.name like 'dim%' or b.name like 'fact%') and b.type='u' order by a.name, b.name |
|
-- 示例 bcp AdventureWorksDW2019.dbo.DimAccount out dbo.DimAccount.txt -c -t"|" -T -S. -C65001 |
1) 上面SQL的結果是形成多個BCP的命令, 將AdventureWorksDW2019的DIM表和FACT表的數據導出到獨立txt文件的命令。
2) 沒有文件頭行, 也就是沒有表頭;如果需要表頭,只能用Query的方式Union All一行出來。不過在我的實驗中,可不用要求導出表頭; 而是直接使用raw表的schema。 題外一句,這麼用,可能不太適合使用ADF的場景。
3) 沒有Quated; 因此如果使用逗號,分隔, 一定要註意現有的內容是否也會包含逗號;如果包含了, 則需要改成其他分隔符, 在此我使用的是豎線”|”作為分隔符;
4) Code page = 65001 (UTF8 Formated)。大部分情況都不需要指定Code Page, 但是我在導出DimProduct表的是時候出現了亂碼問題, 指定Code Page = 65001解決。
5) 類型問題, 比如binary, image, geometry , 這些事實上都不會造成困擾。
Step 2: 上傳數據文件到Azure Blob
1) 可用使用azcopy 工具將文件上傳,可用查閱官網示例 azcopy | Microsoft Learn
2) 也可以手動。本例中我是手動在Portal上上傳到路徑src_data/adventureworks2019dw/bcp 下的
Step3: 資料庫上新建 External Data Source
1) 參考文檔 CREATE EXTERNAL DATA SOURCE (Transact-SQL) - SQL Server | Microsoft Learn
2) 已手動建立【azblobadvtwksblob】
Step 4: 在資料庫上建立raw 表
1) 建raw表目的是為了能讓數據更好的從blob中通過polybase技術複製到SQL DB中來。
2) 創建raw schema
|
CREATE SCHEMA raw |
3) 1:1 創建raw表
|
select concat('SELECT top 0 * INTO raw.', a.name,'_', b.name , ' FROM ', a.name , '.', b.name , '; TRUNCATE table raw.', a.name,'_', b.name ) from sys.schemas a inner join sys.objects b on a.schema_id = b.schema_id where (b.name like 'dim%' or b.name like 'fact%') and b.type='u' and a.name='dbo' order by a.name, b.name
|
|
-- 示例 SELECT top 0 * INTO raw.dbo_DimAccount FROM dbo.DimAccount; TRUNCATE table raw.dbo_DimAccount SELECT top 0 * INTO raw.dbo_DimCurrency FROM dbo.DimCurrency; TRUNCATE table raw.dbo_DimCurrency
|
|
NOTES: 這樣做, 可用減少手動一個個建表的工作量。確保raw表是空表,無數據。 |
為什麼要建raw層的表? 目的就是為了減少因為DB本身的約束導致的數據導入失敗,比如外鍵、視圖綁定、類型問題等,因為raw表沒有外鍵、Identity、引用等約束條件,所以複製數據的時候不容易產生問題。數據都進入DB了, 再查詢起來就比較方便, 也就更容易找到問題所在。數據在Blob上,理論上也有工具可以查詢,但是從效率上還是SQL更高。
在本例中 ,由於是同構的資料庫,所以不會出現類型相容的問題。 但是如果有必要, 可用將raw表的所有的欄位類型都改為nvarchar(N)的,N取決於業務欄位具體的長度。這樣在上數的過程中更不容易出現類型轉換不相容導致的問題。具體的類型轉換,將在” 從raw表查詢數據插入到目標表”步驟中隱式實現也可以。
Step 5: 將數據導入到raw表
1) 使用PolyBase技術,將外部數據源的數據接入到raw表中
|
-- =============== -- 從外部文件載入數據 -- =============== declare @root nvarchar(400) = 'src-data/adventureworks2019dw/bcp/' SELECT CONCAT('TRUNCATE TABLE raw.', a.name,'_', b.name ,';BULK INSERT raw.', a.name,'_', b.name, ' FROM ''' , @root, a.name,'.', b.name,'.txt'' WITH (DATA_SOURCE = ''azblobadvtwksblob'', FIRSTROW =1,FIELDTERMINATOR = ''|'' );') from sys.schemas a inner join sys.objects b on a.schema_id = b.schema_id where (b.name like 'dim%' or b.name like 'fact%') and b.type='u' and a.name='dbo' |
|
-- 示例 TRUNCATE TABLE raw.dbo_DimAccount; BULK INSERT raw.dbo_DimAccount FROM 'src-data/adventureworks2019dw/bcp/dbo.DimAccount.txt' WITH (DATA_SOURCE = 'azblobadvtwksblob', FIRSTROW =1,FIELDTERMINATOR = '|' );
TRUNCATE TABLE raw.dbo_DimCurrency; BULK INSERT raw.dbo_DimCurrency FROM 'src-data/adventureworks2019dw/bcp/dbo.DimCurrency.txt' WITH (DATA_SOURCE = 'azblobadvtwksblob', FIRSTROW =1,FIELDTERMINATOR = '|' );
|
3) 如前所述, 如有必要加上CODEPAGE=‘65001’ (UTF8 Format)
參考 BULK INSERT (Transact-SQL) - SQL Server | Microsoft Learn
Step 6: 去除數據目標表的限制
1) 備份資料庫的DACPAC(即備份表結構的DDL)
2) 刪除外鍵約束
|
SELECT concat('ALTER TABLE ', SCHEMA_NAME(a.schema_id), '.', object_name(a.parent_object_id) , ' drop constraint ' , a.name ,';') FROM SYS.foreign_keys A WHERE TYPE='F' and (object_name(a.parent_object_id) like 'dim%' or object_name(a.parent_object_id) like 'fact%') and schema_name(a.schema_id)='dbo' order by SCHEMA_NAME(a.schema_id), object_name(a.parent_object_id)
|
3) 刪除視圖, 因為視圖有的會和表做schema binding
|
select concat('drop view ', schema_name(a.schema_id) , '.', a.name ) from sys.views a where (A.name like 'dim%' or A.name like 'fact%') and schema_name(a.schema_id)='dbo' |
|
|
Step 7: 從raw表查詢數據插入到目標表
1) 如有必要,清空目標表
2) 判斷identity 列;如果表有Identity列,則需要Set IDENTITY_INSERT ON, 並使用明確列選擇;數據入表完成後,再Set IDENTITY_INSERT OFF
|
-- =============== -- 從raw導入數據 -- =============== ; with c1 as ( SELECT isIdentity = sum(case when b.is_identity = 1 then 1 else 0 end) , schemaName = SCHEMA_NAME(a.schema_id), tableName = a.name, columnNames = STRING_AGG( '['+ b.name + ']', ',') FROM SYS.objects a left join sys.columns b on a.object_id = b.object_id WHERE a.type='u' and (A.name like 'dim%' or A.name like 'fact%') and schema_name(a.schema_id)='dbo' and b.is_computed = 0 group by a.schema_id, a.name ) SELECT pk_identity_prefix = case when (isIdentity >0 ) then concat( ' SET IDENTITY_INSERT ' , schemaName, '.',tableName, ' On;') else '' end , load_script=concat('TRUNCATE TABLE ', schemaName, '.',tableName , '; INSERT INTO ' ,schemaName, '.',tableName , '(',columnNames,')' , ' SELECT ', columnNames ,' FROM raw.',schemaName, '_',tableName,' ;') , pk_identity_prefix = case when (isIdentity >0 ) then concat( ' SET IDENTITY_INSERT ' , schemaName, '.',tableName, ' OFF;') else '' end FROM c1 order by schemaName, tableName
|
|
--打開IDENTITY_INSERT SET IDENTITY_INSERT dbo.DimAccount On; --清空 TRUNCATE TABLE dbo.DimAccount; --插入 INSERT INTO dbo.DimAccount([AccountKey],[ParentAccountKey],[AccountCodeAlternateKey],[ParentAccountCodeAlternateKey],[AccountDescription],[AccountType],[Operator],[CustomMembers],[ValueType],[CustomMemberOptions]) SELECT [AccountKey],[ParentAccountKey],[AccountCodeAlternateKey],[ParentAccountCodeAlternateKey],[AccountDescription],[AccountType],[Operator],[CustomMembers],[ValueType],[CustomMemberOptions] FROM raw.dbo_DimAccount ; --還原 SET IDENTITY_INSERT dbo.DimAccount OFF; |
Step 8: 還原外鍵、視圖等
1) 使用SQLPACKAGE工具,利用資料庫的DACPAC,對資料庫進行還原。
2) 或者使用Visual Studio的Database Project 對資料庫進行還原,本例就是用的這個方式。
附
1) BCP 工具的地址:
通常使用Visual Studio 的CMD可用自動找到, 如果沒有,可用試試類似路徑:
|
C:\Program Files\Microsoft SQL Server\Client SDK\ODBC\170\Tools\Binn\bcp.exe |
2) BCP的命令幫助
|
usage: bcp {dbtable | query} {in | out | queryout | format} datafile [-m maxerrors] [-f formatfile] [-e errfile] [-F firstrow] [-L lastrow] [-b batchsize] [-n native type] [-c character type] [-w wide character type] [-N keep non-text native] [-V file format version] [-q quoted identifier] [-C code page specifier] [-t field terminator] [-r row terminator] [-i inputfile] [-o outfile] [-a packetsize] [-S server name] [-U username] [-P password] [-T trusted connection] [-v version] [-R regional enable] [-k keep null values] [-E keep identity values][-G Azure Active Directory Authentication] [-h "load hints"] [-x generate xml format file] [-d database name] [-K application intent] [-l login timeout] |
強調一點的是, 如果是直接導出表的數據, 用指令”out”; 如果是導出查詢的數據, 用指令”queryout”。
3) AzCopy 工具的介紹:
4) SQLPACKAGE工具的介紹:
參考:SqlPackage.exe - SQL Server | Microsoft Learn


