
上一篇我們講到Mysql索引底層邏輯,為了瞭解後續sql知識,我們還是需要先學習一下相關“工具”得使用 一、Explain介紹 EXPLAIN是MySQl必不可少的一個分析工具,主要用來測試sql語句的性能及對sql語句的優化,或者說模擬優化器執行SQL語句。在select語句之前增加explain ...
上一篇我們講到Mysql索引底層邏輯,為了瞭解後續sql知識,我們還是需要先學習一下相關“工具”得使用
一、Explain介紹
EXPLAIN是MySQl必不可少的一個分析工具,主要用來測試sql語句的性能及對sql語句的優化,或者說模擬優化器執行SQL語句。在select語句之前增加explain關鍵字,執行後MySQL就會返回執行計劃的信息,而不是執行sql。
註意:如果from中包含子查詢,仍會執行子查詢,將結果放入到臨時表中
Explain的用法還是很簡單的,類似一個關鍵字,無需記住什麼語法相關的東西,我們主要來看他的輸出,接下來我們看一下他的常見輸出並分情況進行討論:
首先我們創建三張表並插入一些相關數據
-- ----------------------------
-- Table structure for user
-- ----------------------------
DROP TABLE IF EXISTS `user`;
CREATE TABLE `user` (
`id` int(11) NOT NULL,
`name` varchar(45) DEFAULT NULL,
`update_time` datetime DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP,
`create_time` datetime DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
-- ----------------------------
-- Records of user
-- ----------------------------
INSERT INTO `user` VALUES ('1', '小明', '2022-09-15 15:52:18', '2022-09-13 15:52:21');
INSERT INTO `user` VALUES ('2', '小紅', '2022-09-14 15:52:35', '2022-09-06 15:52:41');
INSERT INTO `user` VALUES ('3', '小可', '2022-09-15 15:52:55', '2022-09-15 15:52:58');
INSERT INTO `user` VALUES ('4', '張三', '2022-09-13 15:53:13', '2022-09-14 15:53:17');
INSERT INTO `user` VALUES ('5', '李四', '2022-09-15 15:53:35', '2022-09-15 15:53:37');
INSERT INTO `user` VALUES ('6', '王五', '2022-09-15 15:53:47', '2022-09-15 15:53:49');
INSERT INTO `user` VALUES ('7', '小小', '2022-09-15 15:54:06', '2022-09-15 15:54:08');
-- ----------------------------
-- Table structure for address
-- ----------------------------
DROP TABLE IF EXISTS `address`;
CREATE TABLE `address` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(45) DEFAULT NULL,
PRIMARY KEY (`id`),
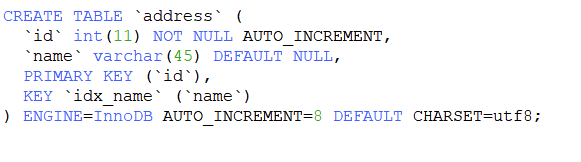
KEY `idx_name` (`name`)
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of address
-- ----------------------------
INSERT INTO `address` VALUES ('2', '上海');
INSERT INTO `address` VALUES ('1', '北京');
INSERT INTO `address` VALUES ('3', '北京');
INSERT INTO `address` VALUES ('5', '南京');
INSERT INTO `address` VALUES ('6', '武漢');
INSERT INTO `address` VALUES ('4', '深圳');
INSERT INTO `address` VALUES ('7', '長沙');
-- ----------------------------
-- Table structure for user_address
-- ----------------------------
DROP TABLE IF EXISTS `user_address`;
CREATE TABLE `user_address` (
`id` int(11) NOT NULL,
`address_id` int(11) NOT NULL,
`user_id` int(11) NOT NULL,
`remark` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_user_address_id` (`address_id`,`user_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
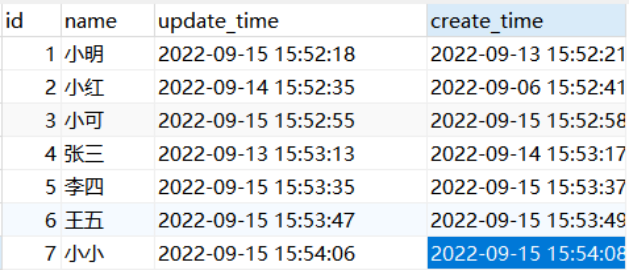
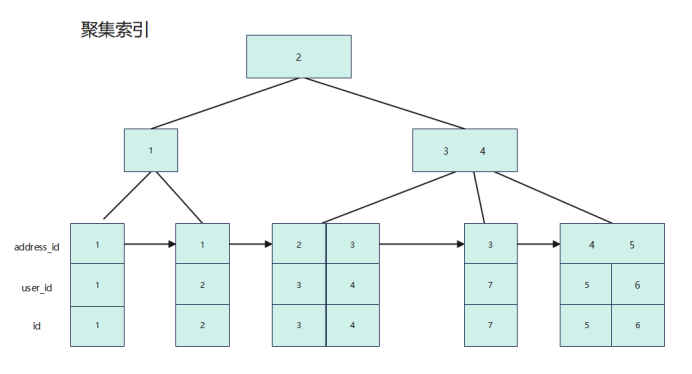
首先來分析一下我們的表結構user表我們只有一個聚集索引,其實就是主鍵索引,那他的索引結構就只是id列,如下圖所示:

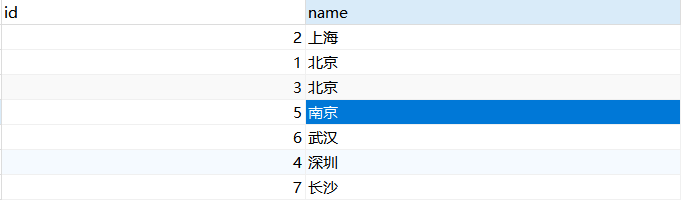
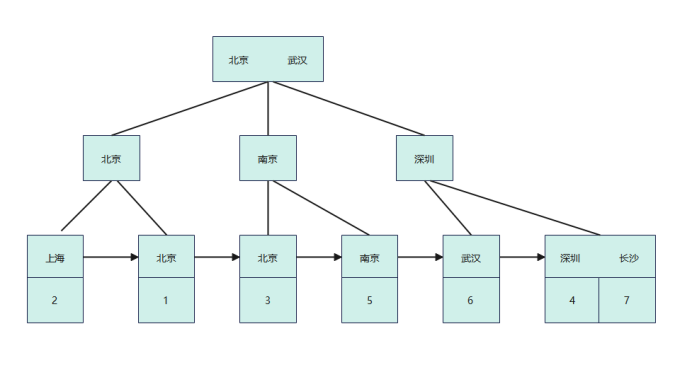
address表不單單隻有我們的聚集索引,也添加了一個二級索引,索引結構如下圖所示:

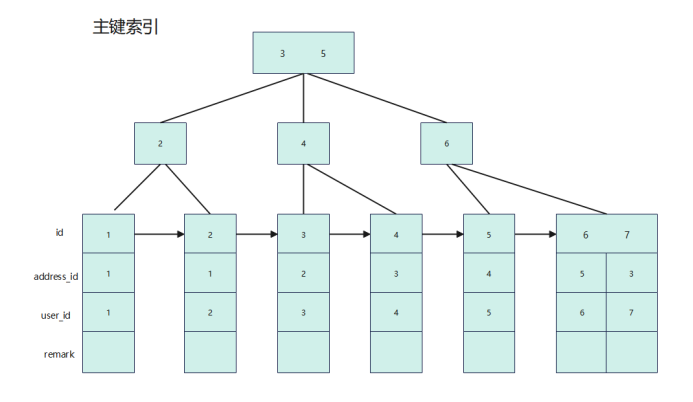
user_address也不僅只有聚集索引,也有一個聯合索引,相對應的列分別是address_id和user_id,索引結構如下圖所示:

二、Explain中的列
1、id列
id列的編號是select的序列號,有幾個select就有幾個id,並且id的順序是按select出現的順序增長的。
id列越大執行優先順序越高,id相同則從上向下執行,id為null最後執行。
2、select_type列
2.1、Simple:簡單查詢,查詢不包含子查詢和union
EXPLAIN SELECT * from `user` WHERE id = 1;

2.2、Primary:複雜查詢中最外層的select
2.3、Subquery:包含在select中的子查詢(不在from子句中)
2.4、Derived:包含在from子句中的子查詢。Mysql會將結果存放到一個臨時表中,也成為派生表(derived的英文含義)
EXPLAIN SELECT (SELECT 1 FROM `user` WHERE id = 1) FROM (SELECT * FROM address WHERE id =1) der;

註意:這裡要先關閉一下mysql5.7新特性對衍生表的合併優化
set session optimizer_switch='derived_merge=off';

3、Table
對應正在訪問的哪一個表,顯示的是表明或者是別命,可能是臨時表或者union合併結果集如果是具體的表名,則表明從實際的物理表中獲取數據,當然也可以是表的別命
表明是derived的形式,表明使用了id為N的查詢產生的衍生表,如下圖所示:

derived後面的id號為3,表明使用id為3的這個查詢產生的衍生表,也就是(SELECT * FROM address WHERE id =1)這個查詢語句結果集所在的的臨時表
當有union result的時候,表名是union n1,n2等形式, n1,n2表示參與union的id
NULL:mysql能夠在優化階段分解查詢語句,在執行階段用不著在訪問表或索引。例如:在索引列中取最小值,可以單獨查找索引來完成,不需要在執行時訪問表

上面的語句我們是通過主鍵id的方式來查找的,如果看過我們上一篇博客的讀者就能夠明白,此時直接查索引就可以了,找到最小的,無需查表。
4、possible_keys
顯示可能應用在這張表中的索引,一個或多個,查詢涉及到的欄位上若存在索引,則該索引將被列出,但不一定被查詢實際使用
5、key
實際使用的索引,如果為null,則沒有使用索引,查詢中若使用了覆蓋索引,則該索引和查詢的select欄位重疊。
如果沒有使用索引,則該列是null,如果想強制mysql使用或忽視possible_keys列中的索引,在查詢中使用force index、ignore index。
基於4、5兩個,有可能出現這種情況:possible_keys有值,key沒有值,這種情況下有可能是因為分析的時候需要用索引,真正執行的時候發現不走索引的化還會快一點。
6、Type
這一列b表示關聯類型或者訪問類型,即Mysql決定如何查找表中的行,查找數據行記錄的大概範圍。
依次從最優到最差分別為:
system>const>eq_ref>ref>range>index>ALL
一般來說,的保證查詢達到range級別,最好達到ref。
1)NULL:mysql能夠在優化階段分解查詢語句,在執行階段用不著在訪問表或索引。例如:在索引列中取最小值,可以單獨查找索引來完成,不需要在執行時訪問表

2)system:表只有一行記錄(等於系統表),這是const類型的特例,平時不會出現

3)const:這個表至多有一個匹配行,
Const為常量的意思,他可能想要表達出查詢的效率非常高,跟查一個常量式的,用我們的唯一索引,或者主鍵的時候,因為無重覆值,所以查詢效率非常高

4)eq_ref:多表連接中使用primary key或者 unique key作為關聯條件,使用唯一性索引進行數據查找,也就是被關聯表上的關聯列走的是主鍵或者唯一索引這可能是在const之外最好的聯接類型了,簡單的select查詢不會出現這種type

5)ref:使用了非唯一性索引進行數據的查找或者非唯一性索引的部分首碼
5.1)簡單查詢(非唯一索引)

5.2)關聯表查詢,idx_user_address_id是address_id和user_id的聯合索引,這裡使用到了user_address的左邊首碼address_id部分

6)ref_or_null:對於某個欄位即需要關聯條件,也需要null值的情況下,查詢優化器會選擇這種訪問方式,簡單得來說就是二級索引等值查詢也能搜索到值為null得行。(註意,此時在表中添加了一行為null得數據)

7)index_merge:在查詢過程中需要多個索引組合使用

8)range:表示利用索引查詢的時候限制了範圍,在指定範圍內進行查詢,這樣避免了index的全索引掃描,適用的操作符: =, <>, >, >=, <, <=, IS NULL, BETWEEN, LIKE, 或者 IN()

9)index:全索引掃描這個比all的效率要好,主要有兩種情況,一種是當前的查詢時覆蓋索引,即我們需要的數據在索引中就可以索取,或者是使用了索引進行排序,這樣就避免數據的重排序,一般是掃描某個二級索引,這種掃描不會從索引樹根節點開始快速查找,而是直接對二級索引的葉子節點遍歷和掃描,速度還是比較慢的,這種查詢一般為使用覆蓋索引,二級索引一般比較小,所以這種通常比All快一些

那麼這裡提出一個問題,address表中其實有兩個索引,一個是主鍵索引,一個是二級索引idx_name,那麼為什麼這裡會使用二級索引而不是主鍵索引呢?
打開address表你會發現。。Address只有兩個欄位一個id,一個name,而idx_name這個索引樹中就包含了name和id,而要查的欄位都存在於idx_name索引樹中,mysql有一個這樣的優化原則,凡是我查找結果集的分析我查找出來,如果這個結果集的幾個欄位在我們所有索引裡面都有,他會優先選擇二級索引去查,因為二級索引小不管是主鍵索引還是二級索引都是從葉子節點的第一個開始找,遍歷到最後一個
11)all:全表掃描,掃描你的聚簇索引的所有葉子節點,一般情況下出現這樣的sql語句而且數據量比較大的話那麼就需要增加索引來進行優化了。

7、key_len列
這一列顯示了mysql表示索引中使用的位元組數,通過這個值可以算出具體使用了索引中的哪些列,舉例來說,user_address的聯合索引idx_user_address_id由address_id和user_id兩個int列組成,並且每個int是4位元組。通過結果中的key_len=4可推斷出查詢使用了第一個列address_id來執行索引查詢,在不損失精度的情況下長度越短越好。

從上圖可以看出這個查詢用到了idx_user_address_id這個聯合索引,這個索引有兩個欄位,但我們這個查詢語句其實就用到了address_id,key_len是4,address_id是int類型,也就是4位元組當兩個都用到的時候,相應的key_len也就變成了8

Key_len計算規則如下:
字元串:
Char(n):n位元組長度
Varchar(n):如果是utf-8,則長度3n+2位元組,加的2位元組用來存儲字元串長度
數值類型:
Tinyint:1位元組
Smallint:2位元組
Int:4位元組
Bigint:8位元組
時間類型:
Date:3位元組
Timestamp:4位元組
Datatime:8位元組
如果欄位允許為null,需要1位元組記錄是否為null
索引的最大長度是768位元組,當字元串過長時,mysql會做一個類似左首碼索引的處理,將前半部分的字元提取出來左索引
8、ref
顯示索引的哪一列被使用了,如果可能的話,是一個常數
這一列顯示了在key列記錄的索引中,表查找值所用到的列或常量,常見的有:const(常量),欄位名(例如:address.id)
9、rows列
這一列是mysql估計要讀取並檢測的行數 ,註意這個不是結果集裡面的行數,她只是一個預估值
10、Extra列
這一列展示的是額外信息。常見的重要值如下:
1)using index:使用覆蓋索引
覆蓋索引定義:mysql執行計劃explain結果里的key有使用索引,如果select後面查詢的欄位都可以從這個索引的樹中獲取,這種情況一般說用到了覆蓋索引,extra里一般都有using index;覆蓋索引一般針對的輔助索引,整個查詢結果只通過輔助索引就能拿到結果,不需要通過輔助索引樹找到主鍵,再通過主鍵索引樹里獲取其他欄位值


2)using where:使用where語句來處理結果,並且查詢的列未被索引覆蓋

3)using index condition:查詢的列不完全被索引覆蓋,where條件中是一個前導列的範圍;

4)using temporary:mysql需要創建一張臨時表來處理查詢。出現這種情況一般是要進行優化的,首先是想到用索引來優化
user.name沒有索引,此時創建了臨時表來distinct

address.name建立了idx_name索引,此時查詢時extras是using index,沒有用臨時表

5)using filesort:將用外部排序而不是索引排序,索引較小時從記憶體排序,否則需要在磁碟完成排序。這種情況下一般也是要考慮使用索引來優化的
actor.name未創建索引,會瀏覽actor整個表,保存排序關鍵字name和對應的id,然後排序name並檢索行記錄,

address.name建立了idx_name索引,此時查詢時extra是using index

6)Select tables optimized away:使用某些聚合函數(比如max、min)來訪問存在索引的某個欄位是

附:
1、派生表
派生表,是用於存儲子查詢產生的結果的臨時表,這個子查詢特指 FROM 子句 里的子查詢,如果是出現在其它地方的子查詢,就不叫這個名字了,所以本質上來說,派生表也是臨時表。
2、物化表
物化表,也是用於存儲子查詢產生的結果的臨時表,這個子查詢特指 WHERE 子句中查詢條件里的子查詢。
前導列:
前導列,就是在創建複合索引語句的第一列或者連續的多列。比如通過:CREATE INDEX comp_ind ON table1(x, y, z)創建索引,那麼x,xy,xyz都是前導列,而yz,y,z這樣的就不是。
3、dual表
Dual表其實就是一個虛表,你可以在沒有表的情況下指定這個虛擬的表名。
4、int(1)、int(2)、int(3)...int(10)有什麼區別?
不知道大家對於上面ken_len列的計算是否有疑問,為什麼像int這類數據類型就是4位元組,而不是int(num)中的num位元組接下來就給大家解釋一下。
Mysql中int是占4個位元組,那麼對於無符號的int,最大值就是2^32-1 = 4294967295
int後面的數字不能表示欄位的長度,int(num)一般加上zerofill才有效果,它能夠實現當該欄位不足num位時補0的效果。
下麵我們給出一個例子:
首先我們創建一個測試表
CREATE TABLE `intTest` (
`id` int(1) ZEROFILL UNSIGNED NOT NULL,
`test` int(1) UNSIGNED ZEROFILL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
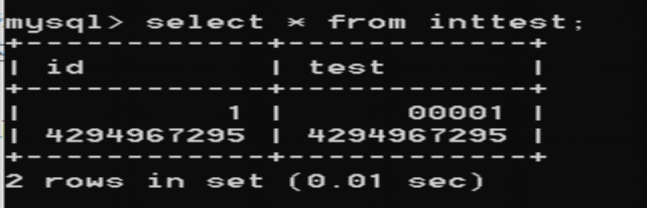
測試表中id列,test列是一個無符號整型,且設置的是int(1),那麼他是不是意味著不能插入4294967295這個4位元組的最大數字,接下來我們就插入4294967295試一下:
[SQL]INSERT INTO `inttest` VALUES(4294967295,4294967295);
受影響的行: 1
時間: 0.013s

可以看到成功插入,沒有報錯,也就說明int(1)並沒有限制只有1個位元組,接下來我們把test欄位的int中的位數改成5,id列不變並都插入數字1看一下有什麼效果,

可以看到test列為int(5),所以在不滿足5位的時候會在前面補零,因為我們加上了zerofill屬性,而id列我們設置了int(1)他就不會補零。這裡面說明一下;為什麼用命令行看:
因為在navicat中他是不顯示這個零填充(小編的navicat是顯示不出來的)

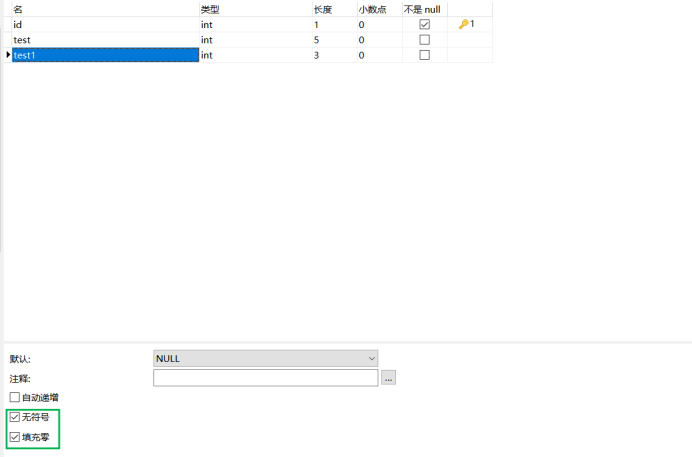
這裡面還有一個小細節:其實我們在給某一列增加zerofill屬性的時候,mysql會自動增加一個unsigned屬性,我們可以看一下:
我們新增加一列test1:
ALTER TABLE `intTest` add COLUMN `test1` int(3) ZEROFILL;
向test1中插入負數
INSERT INTO `inttest` VALUES(2,2,-2);
此時會發生報錯;因為小編的mysql處於嚴格模式下
SET sql_mode ="NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION";
修改模式,再次插入

可以看到,插入負數的時候會存儲為0,mysql會自動設置該列為無符號整數。
zerofill預設為int(10),int預設為int(11)
下麵我們做一個示例:
ALTER TABLE `intTest` add COLUMN `test2` int ZEROFILL;
ALTER TABLE `intTest` add COLUMN `test3` int;

上面就可以證明這一點。
不僅僅是int類型,上面提到的整數類型皆是如此。

