
前言 嗨嘍~大家好呀,這裡是魔王吶 ! 閑的無聊的得我又來倒騰代碼了~ 今天給大家分享得是——122萬人的生活工作和死亡數據分析 準備好了嘛~現在開始發車嘍!! @TOC 所需素材 獲取素材點擊 代碼 import pandas as pd df = pd.read_csv('.\data\AgeD ...
前言
嗨嘍~大家好呀,這裡是魔王吶 !

閑的無聊的得我又來倒騰代碼了~
今天給大家分享得是——122萬人的生活工作和死亡數據分析
準備好了嘛~現在開始發車嘍!!
@TOC
所需素材

獲取素材點擊
代碼
import pandas as pd
df = pd.read_csv('.\data\AgeDatasetV1.csv')
df.info()
df.describe().to_excel(r'.\result\describe.xlsx')
df.isnull().sum().to_excel(r'.\result\nullsum.xlsx')
df[df.duplicated()].to_excel(r'.\result\duplicated.xlsx')
df.rename(columns=lambda x: x.replace(' ', '_').replace('-', '_'), inplace=True)
print(df.columns)
print(df[df['Birth_year'] < 0].to_excel(r'.\result\biryear0.xlsx')) # 出生負數表示公元前
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
plt.rcParams['font.sans-serif'] = ['SimHei'] # 顯示中文標簽
plt.rcParams['axes.unicode_minus'] = False
df1 = pd.read_csv('./data/AgeDatasetV1.csv')
# 列名規範化 重命名
df1.rename(columns=lambda x: x.replace(' ', '_').replace('-', '_'), inplace=True)
print(df1.columns)
# print(Data.corr()) # 相關性
# print(df1['Gender'].unique()) # 性別
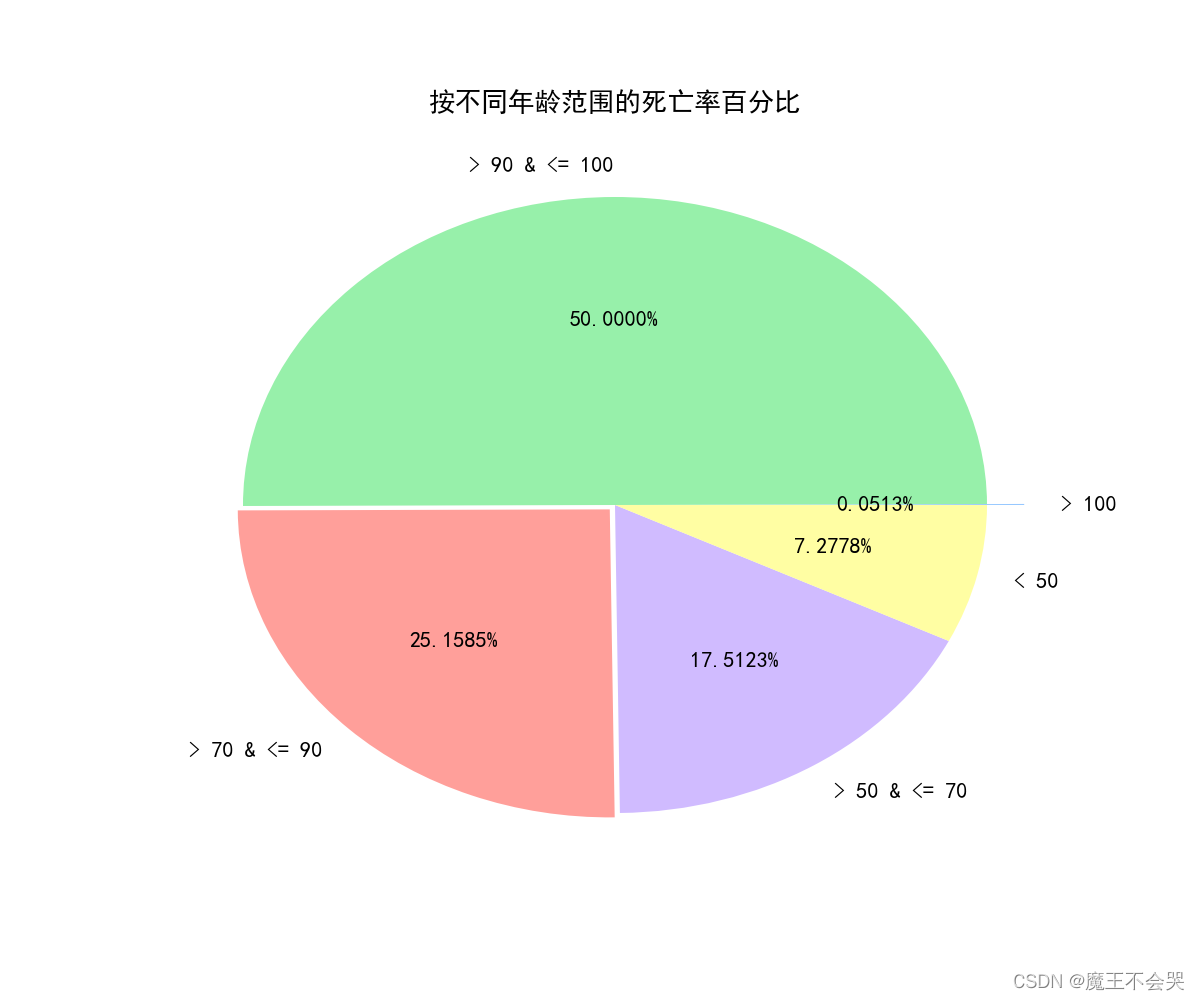
# # 按不同年齡範圍的死亡率百分比
plt.figure(figsize=(12, 10))
count = [df1[df1['Age_of_death'] > 100].shape[0],
df1.shape[0] - df1[(df1['Age_of_death'] <= 100) & (df1['Age_of_death'] > 90)].shape[0],
df1[(df1['Age_of_death'] <= 90) & (df1['Age_of_death'] > 70)].shape[0],
df1[(df1['Age_of_death'] <= 70) & (df1['Age_of_death'] > 50)].shape[0],
df1.shape[0] - (df1[df1['Age_of_death'] > 100].shape[0] +
df1[(df1['Age_of_death'] <= 100) & (df1['Age_of_death'] > 90)].shape[0]
+ df1[(df1['Age_of_death'] <= 70) & (df1['Age_of_death'] > 50)].shape[0]
+ df1[(df1['Age_of_death'] <= 90) & (df1['Age_of_death'] > 70)].shape[0])
]
age = ['> 100', '> 90 & <= 100', '> 70 & <= 90', '> 50 & <= 70', '< 50']
explode = [0.1, 0, 0.02, 0, 0] # 設置各部分突出
palette_color = sns.color_palette('pastel')
plt.rc('font', family='SimHei', size=16)
plt.pie(count, labels=age, colors=palette_color,
explode=explode, autopct='%.4f%%')
plt.title("按不同年齡範圍的死亡率百分比")
plt.savefig(r'.\result\不同年齡範圍的死亡率百分比.png')
plt.show()
# 死亡人數前20的職業
Occupation = list(df1['Occupation'].value_counts()[:20].keys())
Occupation_count = list(df1['Occupation'].value_counts()[:20].values)
plt.rc('font', family='SimHei', size=16)
plt.figure(figsize=(14, 8))
# sns.set_theme(style="darkgrid")
p = sns.barplot(x=Occupation_count, y=Occupation)
p.set_xlabel("人數", fontsize=20)
p.set_ylabel("職業", fontsize=20)
plt.title("前20的職業", fontsize=20)
plt.subplots_adjust(left=0.18)
plt.savefig(r'.\result\死亡人數前20的職業.png')
plt.show()

# 死亡人數前10的死亡方式
top_causes = df1.groupby('Manner_of_death').size().reset_index(name='count')
top_causes = top_causes.sort_values(by='count', ascending=False).iloc[:10]
fig = plt.figure(figsize=(10, 6))
plt.barh(top_causes['Manner_of_death'], top_causes['count'], edgecolor='black')
plt.title('死亡人數前10的死因.png')
plt.xlabel('人數')
plt.ylabel('死因')
plt.tight_layout() # 自動調整子圖參數,使之填充整個圖像區域
plt.savefig(r'.\result\死亡人數前10的死因.png')
plt.show()

# 死亡人數前20的出生年份
birth_year = df1.groupby('Birth_year').size().reset_index(name='count')
birth_year = birth_year.sort_values(by='count', ascending=False).iloc[:20]
fig = plt.figure(figsize=(10, 6))
plt.barh(birth_year['Birth_year'], birth_year['count'])
plt.title('死亡人數前20的出生年份')
plt.xlabel('人數')
plt.ylabel('出生年份')
plt.tight_layout() # 自動調整子圖參數,使之填充整個圖像區域
plt.savefig(r'.\result\死亡人數前20的出生年份.png')
plt.show()
# 死亡人數前20的去世年份
death_year = df1.groupby('Death_year').size().reset_index(name='count')
# print(death_year)
death_year = death_year.sort_values(by='count', ascending=False).iloc[:20]
fig = plt.figure(figsize=(10, 10))
plt.barh(death_year['Death_year'], death_year['count'])
plt.title('死亡人數前20的去世年份')
plt.xlabel('人數')
plt.ylabel('去世年份')
plt.tight_layout()
plt.savefig(r'.\result\死亡人數前20的去世年份.png')
plt.show()

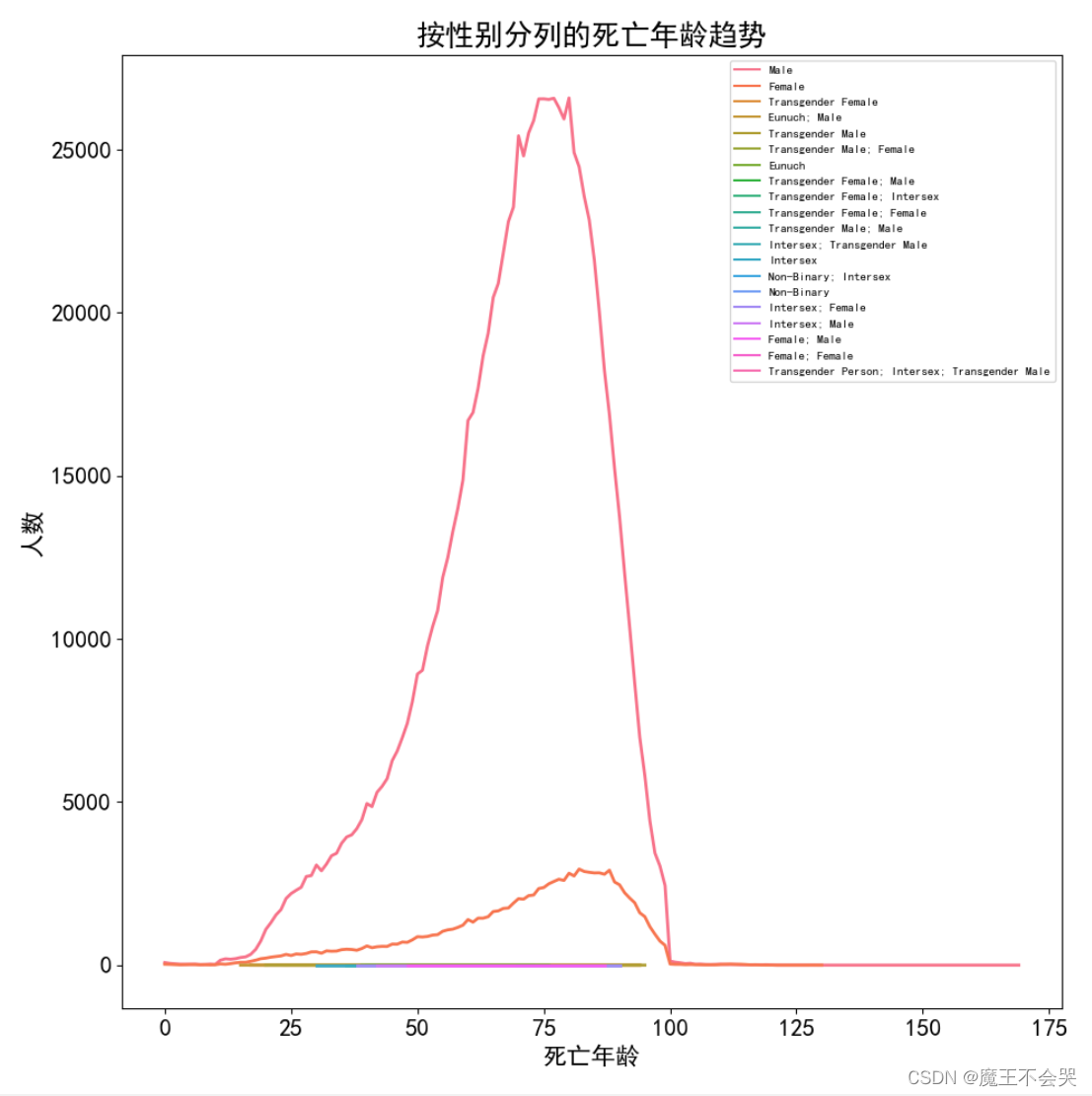
# 按性別分列的死亡年齡趨勢
data = pd.DataFrame(
df1.groupby(['Gender', 'Age_of_death']).size().reset_index(name='count').sort_values(by='count', ascending=False))
fig = plt.figure(figsize=(10, 10))
sns.lineplot(data=data, x='Age_of_death', y='count', hue='Gender', linewidth=2)
plt.legend(fontsize=8)
plt.title('按性別分列的死亡年齡趨勢')
plt.xlabel('死亡年齡')
plt.ylabel('人數')
plt.tight_layout()
plt.savefig(r'.\result\死亡人數前20的去世年份.png')
plt.show()
# 前10的職業中 男性與女性的人數
occupation = pd.DataFrame(df1['Occupation'].value_counts())
top10_occupation = occupation.head(10)
top_index = [i for i in top10_occupation.index]
age_data = df1[df1['Occupation'].isin(top_index)]
age_data = age_data[age_data['Gender'].isin(['Male', 'Female'])]
sns.catplot(data=age_data, x='Occupation', kind='count', hue='Gender', height=10)
plt.xticks(rotation=20)
plt.xlabel('職業')
plt.ylabel('人數')
plt.tight_layout()
plt.savefig(r'.\result\前10的職業中男女性人數.png')
plt.show()

尾語
讀書多了,容顏自然改變,許多時候,
自己可能以為許多看過的書籍都成了過眼雲煙,不復記憶,其實他們仍是潛在的。
在氣質里,在談吐上,在胸襟的無涯,當然也可能顯露在生活和文字里。
——三毛《送你一匹馬》
本文章到這裡就結束啦~感興趣的小伙伴可以複製代碼去試試哦


